
基于多模态大模型的IQA Benchmark:Q-BENCH(2024 ICLR)
- 专题介绍
- 一、研究背景
- [二、Q-Bench 三大评估任务设计](#二、Q-Bench 三大评估任务设计)
-
- [2.1 低层次视觉感知任务(A1:Perception)](#2.1 低层次视觉感知任务(A1:Perception))
- [2.2 低层次视觉描述任务(A2:Description)](#2.2 低层次视觉描述任务(A2:Description))
- [2.3 视觉质量评估任务(A3:Assessment)](#2.3 视觉质量评估任务(A3:Assessment))
- 三、实验
-
- [3.1 低层次感知能力(A1):整体准确率](#3.1 低层次感知能力(A1):整体准确率)
- [3.2 低层次描述能力(A2):总分(3 维度之和)](#3.2 低层次描述能力(A2):总分(3 维度之和))
- [3.3 质量评估能力(A3):平均 SRCC/PLCC](#3.3 质量评估能力(A3):平均 SRCC/PLCC)
- 四、总结
本文将围绕《Q-BENCH: A BENCHMARK FOR GENERAL-PURPOSE
FOUNDATION MODELS ON LOW-LEVEL VISION》展开完整解析。
为填补多模态大型语言模型(MLLMs)在低层次视觉感知与理解能力评估上的空白,研究团队提出Q-Bench 基准,从低层次视觉感知、低层次视觉描述、整体视觉质量评估三大维度系统评估 MLLMs 能力:构建含 2,990 张图像的LLVisionQA 数据集评估感知能力(通过问答正确性衡量),创建含 499 张图像及专家标注黄金描述的LLDescribe 数据集并结合 GPT 对比 pipeline 评估描述能力(从完整性、精确性、相关性维度),还设计基于 softmax 的策略让 MLLMs 预测可量化质量分数以评估质量评估能力;实验显示 MLLMs 具备初步低层次视觉技能,但稳定性和精确性不足,其中InternLM-XComposer-VL在多项任务中表现最优,GPT-4V接近初级人类水平但仍落后于资深人类,该基准旨在推动 MLLMs 低层次视觉能力的研究与提升。参考资料如下:
1. 项目地址
论文整体结构思维导图如下:
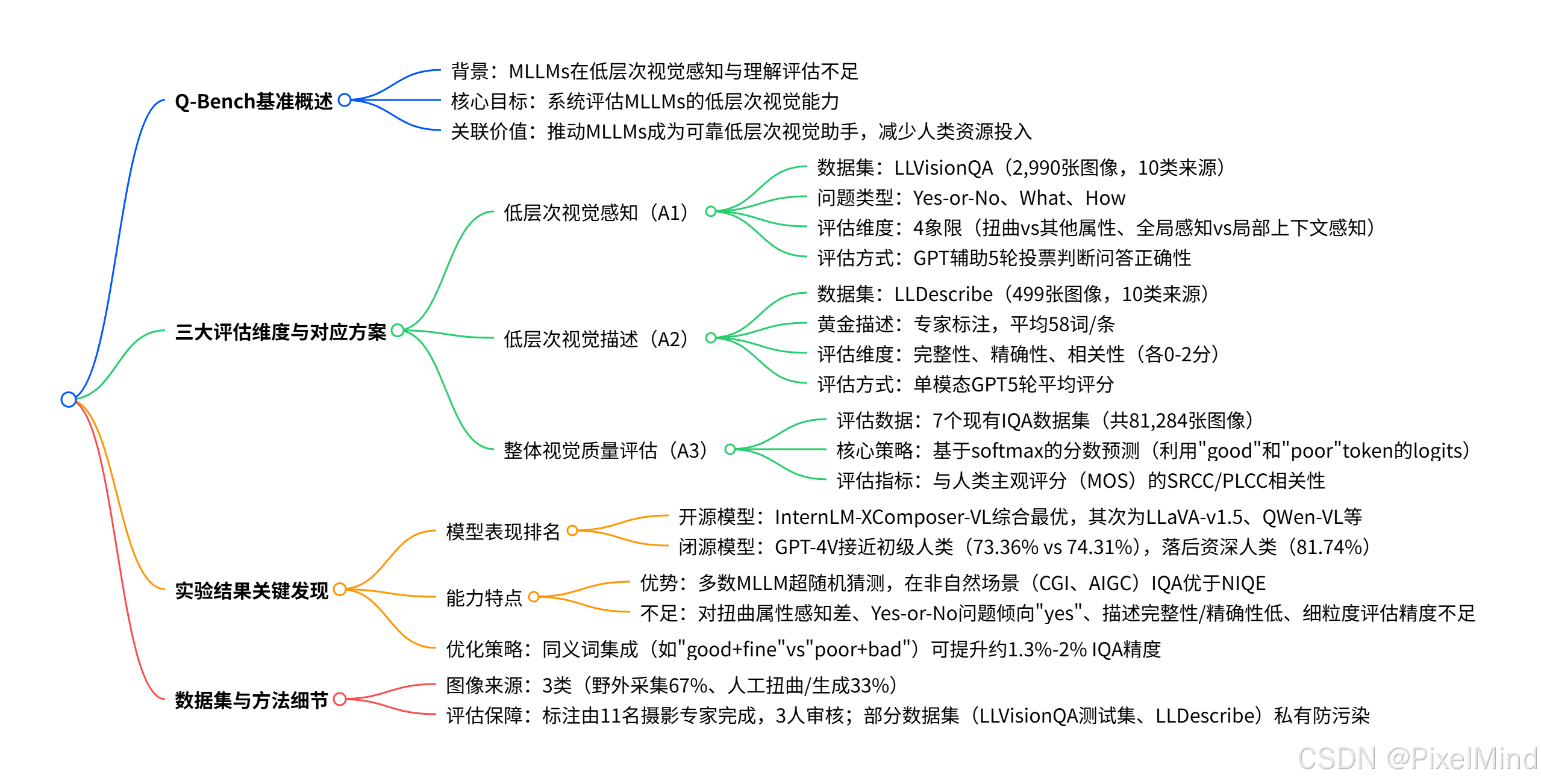
专题介绍
图像质量评价(Image Quality Assessment, IQA)是图像处理、计算机视觉和多媒体通信等领域的关键技术之一。IQA不仅被用于学术研究,更在影像相关行业内实现了完整的商业化应用,涉及影视、智能手机、专业相机、安防监控、工业质检、医疗影像等。IQA与图像如影随形,其重要程度可见一斑。
但随着算法侧的能力不断突破,AIGC技术发展火热,早期的IQA或已无法准确评估新技术的能力。另一方面,千行百业中各类应用对图像质量的需求也存在差异和变化,旧标准也面临着适应性不足的挑战。
本专题旨在梳理和跟进IQA技术发展内容和趋势,为读者分享有价值、有意思的IQA。希望能够为底层视觉领域内的研究者和从业者提供一些参考和思路。
系列文章如下:
【1】🔥IQA综述
【2】PSNR&SSIM
【3】Q-Insight
【4】VSI
【5】LPIPS
【6】DISTS
【7】Q-align
【8】GMSD
【9】NIQE
【10】MUSIQ
【11】CDI
一、研究背景
多模态大型语言模型(MLLMs,如 LLaVA、MiniGPT4)在高层次视觉任务(图像 captioning、VQA)中表现突出,但低层次视觉感知与理解能力的评估存在空白,而该能力对图像质量评估(IQA)、视觉失真检测、美学分析等关键应用至关重要。
为了填补这部分空白,Q-bench首个针对 MLLMs 低层次视觉能力的系统性基准,围绕核心问题 ------"MLLMs 如何模拟人类低层次视觉感知与理解能力" 展开,聚焦三大能力维度,且遵循两大设计原则:
-
任务需涉及图像低层次属性的感知 / 理解,例如清晰度、噪声、亮度等;
-
不依赖推理能力或外部知识。
二、Q-Bench 三大评估任务设计
分为3大块,并基于每一块提出一个数据集,整体如下图所示。
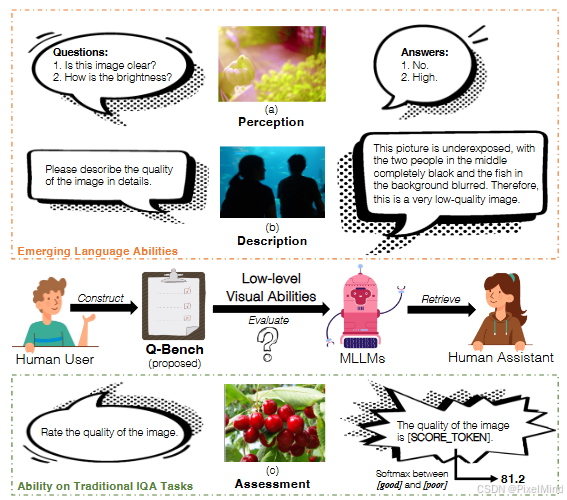
感知、描述和评估三大块。
2.1 低层次视觉感知任务(A1:Perception)
提出一个数据集LLVisionQA,共 2,990 张图像,涵盖 10 类来源(含野外采集如 KONiQ-10K、生成图像如 AGIQA-3K、人工扭曲图像如 KADID-10K),确保多样性,如下表所示:
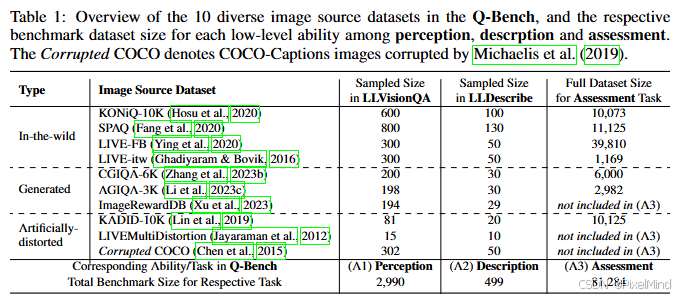
每张图像对应 1 个(问题 Q + 正确答案 C+1-3 个错误答案 F)元组,支持多选择问答评估。
作者针对这个数据集,设计了3类不同的问题:
- Yes-or-No(判断类,如 "图像清晰吗?"):平衡 40% 答案为 "No" 以减少模型偏向性;
- What(分类类,如 "图像存在哪种失真?"):考察多属性理解;
- How(程度类,如 "图像清晰度如何?"):覆盖非极端属性,支持细粒度评估。
评估基于两大维度划分,确保评估全面性,如下图所示:
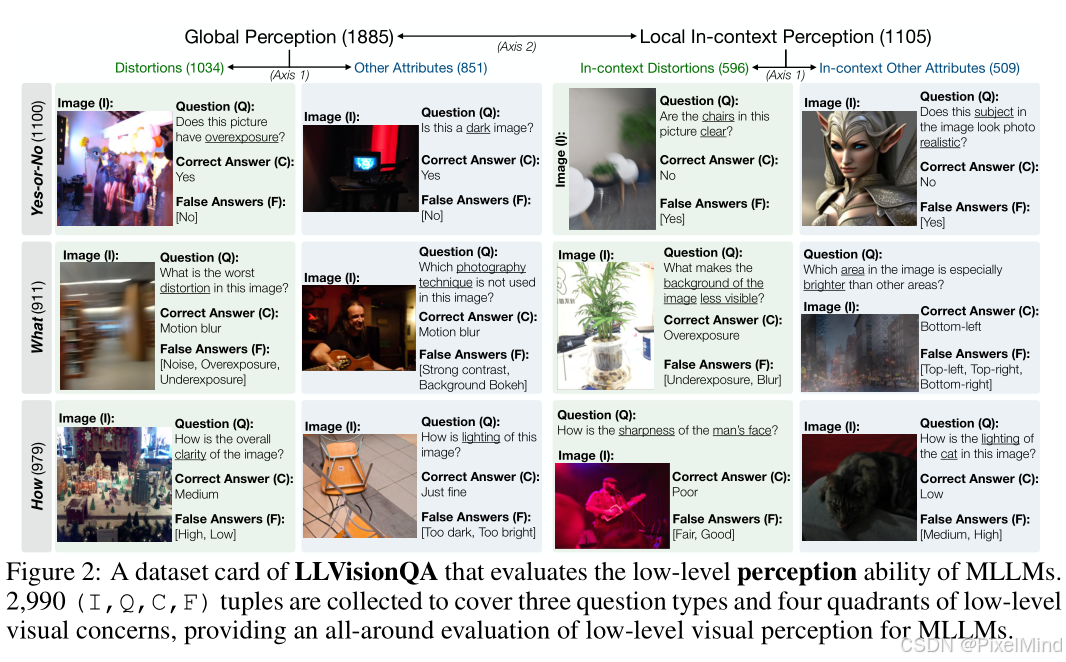
- 属性类型(Axis 1):包含第一个扭曲(模糊、噪声等)以及第二个其他属性(颜色、光照等)。
- 感知范围(Axis 2):包含全局感知(整体清晰度)以及局部上下文感知(花朵是否对焦),例如上图的左右侧,分别代表了整体和局部一个评估。
最后是评估方法:向 MLLM 输入 "问题 + 图像 + 选项"(选项随机打乱),如下图所示。
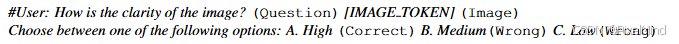
但是MLLM的输出可能不一致,因此作者后续采用GPT 辅助 5 轮投票机制,解决 MLLM 输出格式不统一问题(如 "High""A. High" 均视为正确),评估准确率提升至 98.4%。
2.2 低层次视觉描述任务(A2:Description)
提出了一个数据集LLDescribe,共 499 张图像,与 LLVisionQA 共享 10 类图像来源,确保任务一致性。它的生成是由摄影专家标注,平均58 词 / 条(远长于传统图像 caption 的 10-11 词),需覆盖图像所有低层次关注点(如失真、颜色、光照)。如下图所示:

评估方法,从 3 个核心维度对 MLLM 输出的描述打分(0-2 分 / 维度),具体定义如下:
- 完整性:2 分(完全覆盖黄金描述信息)、1 分(部分覆盖)、0 分(未覆盖)。
- 精确性 :2 分(无争议信息)、1 分(争议信息少于匹配信息)、0 分(争议信息更多)。
- 相关性:2 分(完全围绕低层次属性)、1 分(部分相关)、0 分(完全无关)。
作者采用单模态 GPT 进行 5 轮平均评分,降低评估随机性,确保结果可复现。
2.3 视觉质量评估任务(A3:Assessment)
采用 7 个现有 IQA 数据集,覆盖 3 类图像场景,总规模81,284 张图像,具体可参见2.1节中表的第三列。为了完成这个操作,作者设计了以下的策略:
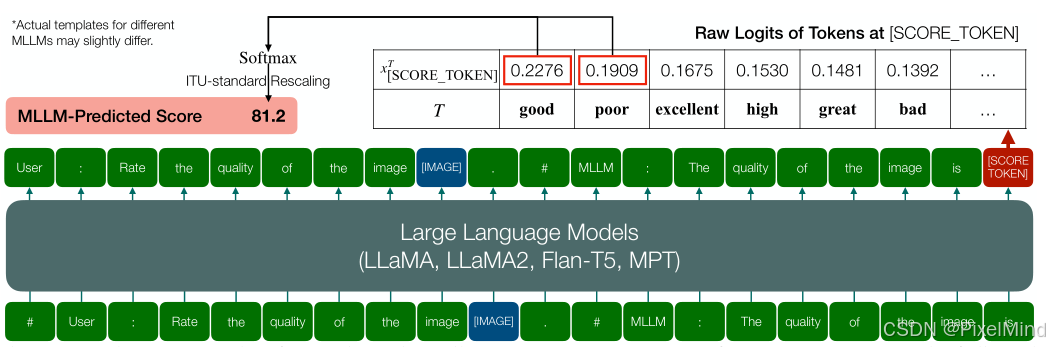
具体来说是运用了softmax-based 质量预测策略,但MLLM 直接输出存在 "正向偏向"(78% 输出 "good")和 "极端偏向"(84% 输出 "5" 分),可测量性弱,因此考虑取 MLLM 输出中 "good" 和 "poor" 两个高频 token 的 logits,通过 softmax 计算概率并映射为可量化分数,公式如下所示: q p r e d = e x S C O R E _ T O K E N g o o d e x S C O R E _ T O K E N g o o d + e x S C O R E _ T O K E N p o o r q_{pred} = \frac{e^{x_{SCORE\TOKEN}^{good}}}{e^{x{SCORE\TOKEN}^{good}} + e^{x{SCORE\_TOKEN}^{poor}}} qpred=exSCORE_TOKENgood+exSCORE_TOKENpoorexSCORE_TOKENgood
该策略与人类评分的相关性显著优于 argmax 策略(如 LLaVA-v1 在 KONiQ-10K 上 SRCC 从 0.038 提升至 0.462)。
三、实验
实验同样也分为3块。
3.1 低层次感知能力(A1):整体准确率
如下图所示:
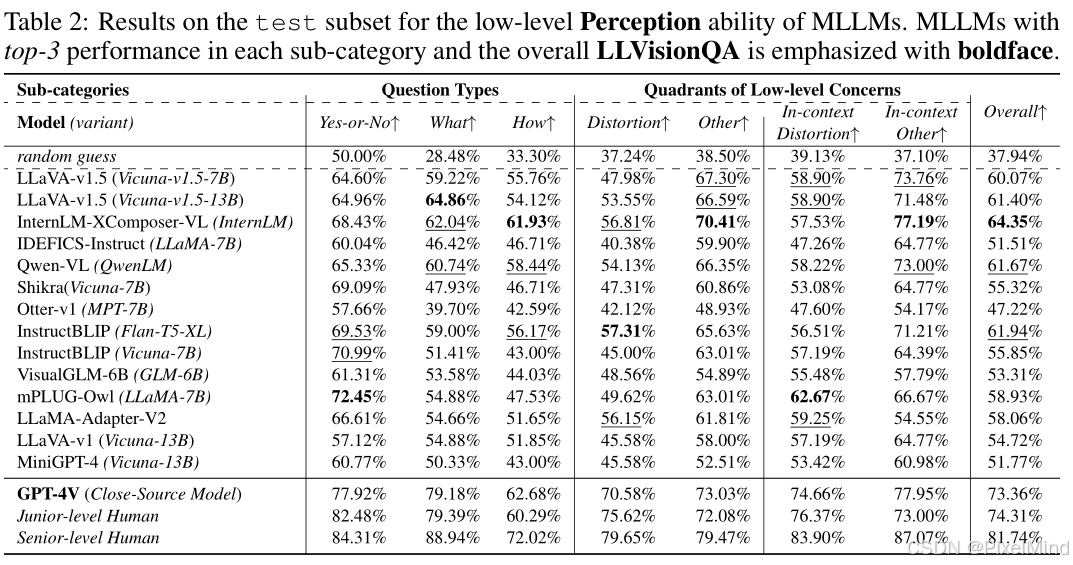
其中:资深人类(Senior-level)整体准确率81.74%,所有维度均最优;GPT-4V(闭源)整体准确率 73.36%排名第一,What 类问题(79.18% 准确率);InternLM-XComposer-VL整体准确率64.35%排名第二,In-context Other 属性(77.19%);随机猜测整体准确率37.94%。
3.2 低层次描述能力(A2):总分(3 维度之和)
如下图所示:
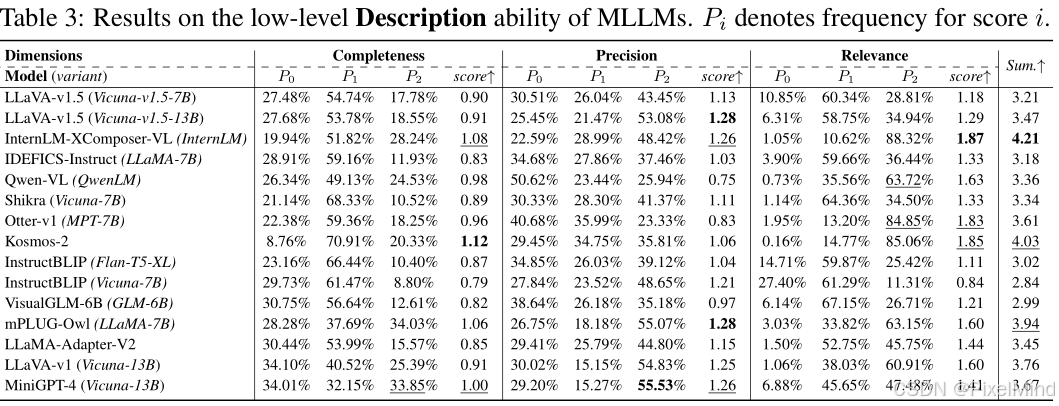
其中:InternLM-XComposer-VL整体得分4.21排名第一,最大优势为相关性(1.87 分);Kosmos-2整体得分4.03排名第二,最大优势为完整性(1.12 分);平均水平(所有模型)整体得分~3.5,相关性普遍高于完整性 / 精确性。
3.3 质量评估能力(A3):平均 SRCC/PLCC
如下图所示:
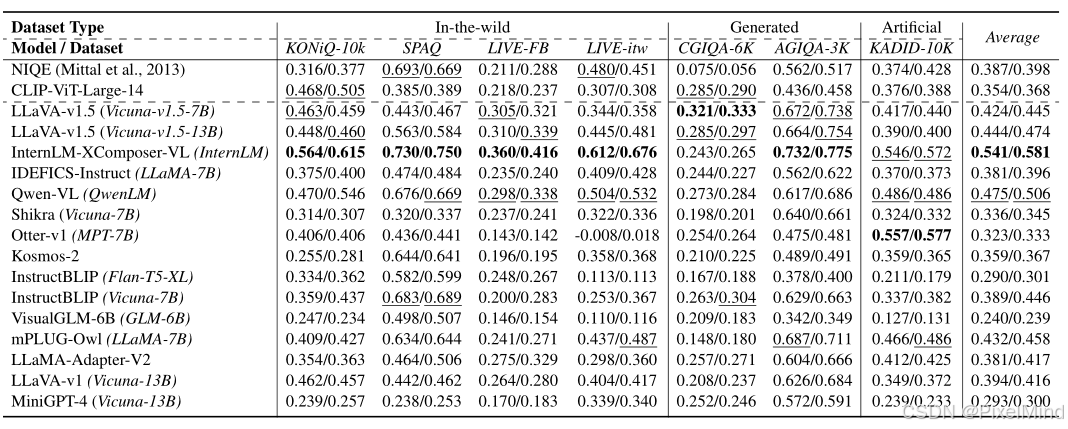
其中:InternLM-XComposer-VL 平均 SRCC/PLCC为0.541/0.581排名第一,NIQE(传统 IQA 方法)平均 SRCC/PLCC为0.387/0.398 。
作者对多个MLLM评估下来,结论总结如下,分为优势和不足,优势如下:
- 基础能力:多数 MLLM 在 A1/A2/A3 任务中显著超随机猜测,证明具备初步低层次视觉技能;
- 场景适应性:在生成图像(CGIQA-6K、AGIQA-3K)和人工扭曲图像(KADID-10K)的 IQA 任务中,性能普遍优于传统方法 NIQE;
- 可优化性:通过同义词集成策略(如 "good+fine"vs"poor+bad"),Top5 模型的 IQA 精度平均提升 1.3%-2%。
劣势如下:
- 感知偏差:所有 MLLM 对 "扭曲属性" 的感知准确率低于 "其他属性"(如 LLaVA-v1.5 扭曲类 47.98% vs 其他类 67.30%),且 Yes-or-No 问题普遍偏向 "yes"(如 IDEFICS-Instruct 的 Yes 准确率 88.65% vs No 准确率 13.09%);
- 描述短板:即使最优模型,描述的完整性和精确性也仅处于 "可接受水平"(平均 0.8-1.2 分 / 2 分),存在信息遗漏或错误;
- 细粒度评估差:在高相似度图像场景(如 LIVE-FB 含 95% 高质量图像)中,MLLM 难以区分细微质量差异,相关性指标显著下降。
四、总结
该论文探索了MLLMs在低级视觉能力方面的进展,期望这些大型基础模型能够成为通用智能,最终减轻人类的工作负担。提出 MLLMs 应该具备三项重要且独特的能力:对低级视觉属性的准确感知,对低级视觉信息的精确且完整的语言描述,以及对图像质量的量化评估。
为了评估这些能力,论文收集了两个用于低级视觉的多模态基准数据集,并提出了一种基于 softmax 的统一 MLLMs 量化 IQA 策略。评估证明,即便在没有任何低级特定训练的情况下,一些卓越的 MLLMs 仍然具备可观的低级能力。尽管如此,MLLMs 要成为真正可靠的通用低级视觉助手仍有很长的路要走,需要进一步的优化。
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。