文章目录
-
-
- [1. 引言:时序数据的浪潮与选型的挑战](#1. 引言:时序数据的浪潮与选型的挑战)
-
- [1.1. 研究背景:大数据时代下的时序数据洪流](#1.1. 研究背景:大数据时代下的时序数据洪流)
- [1.2. 评估维度:如何科学地选择时序数据库?](#1.2. 评估维度:如何科学地选择时序数据库?)
- [2. 主流国外时序数据库概览与分析](#2. 主流国外时序数据库概览与分析)
-
- [2.1. InfluxDB:监控领域的先行者](#2.1. InfluxDB:监控领域的先行者)
- [2.2. TimescaleDB:基于 PostgreSQL 的关系型时序扩展](#2.2. TimescaleDB:基于 PostgreSQL 的关系型时序扩展)
- [2.3. OpenTSDB:为海量规模而生的Hadoop生态组件](#2.3. OpenTSDB:为海量规模而生的Hadoop生态组件)
- [3. Apache IoTDB:为物联网与大数据而生的新一代TSDB](#3. Apache IoTDB:为物联网与大数据而生的新一代TSDB)
-
- [3.1. IoTDB 架构与核心设计理念](#3.1. IoTDB 架构与核心设计理念)
- [3.2. IoTDB 在大数据场景下的核心优势](#3.2. IoTDB 在大数据场景下的核心优势)
- [3.3. IoTDB 应用场景分析](#3.3. IoTDB 应用场景分析)
- [4. Apache IoTDB 实践指南:部署](#4. Apache IoTDB 实践指南:部署)
-
- [4.1. 环境准备](#4.1. 环境准备)
- [4.2. 使用 Docker Compose 部署单机版 IoTDB](#4.2. 使用 Docker Compose 部署单机版 IoTDB)
- [4.3. 客户端连接与数据](#4.3. 客户端连接与数据)
- [5. 选型结论与建议](#5. 选型结论与建议)
-
- [5.1. 综合对比总结](#5.1. 综合对比总结)
- [5.2. 为什么选择 Apache IoTDB?](#5.2. 为什么选择 Apache IoTDB?)
-
随着物联网(IoT)、工业4.0和大数据技术的飞速发展,时序数据已成为增长最快的数据类型。海量的设备、传感器和系统以前所未有的频率生成包含时间戳的数据点,为企业带来了巨大的机遇与挑战。如何高效地存储、管理和分析这些时序数据,成为决定企业数字化转型成败的关键。时序数据库应运而生,专为应对这些挑战而设计。本报告旨在提供一份全面的时序数据库选型指南,将系统性地分析当前主流的国外时序数据库产品,并着重阐述 Apache IoTDB 作为面向物联网与大数据场景的下一代开源TSDB的核心优势、架构设计与应用实践。本报告的目标读者为数据工程师、系统架构师、数据库管理员以及物联网领域的开发者,他们正面临着为大规模时序数据场景选择合适技术栈的挑战 。

1. 引言:时序数据的浪潮与选型的挑战
1.1. 研究背景:大数据时代下的时序数据洪流
我们正处在一个万物互联的时代。从智能制造产线上的传感器、智慧城市中的监控设备,到车联网中的车辆状态信息和金融交易中的 tick 数据,时序数据无处不在。这类数据的核心特征是:数据点必然包含时间戳,数据以极高的频率持续生成,且通常以追加方式写入,很少更新。这些特征对底层数据存储和管理系统提出了独特的要求:
- 极高的写入吞吐能力:需要支持每秒百万甚至千万级别数据点的写入。
- 极致的数据压缩率:海量数据对存储成本构成巨大压力,高效的压缩算法至关重要。
- 高效的聚合与降采样查询:分析场景通常关注数据的趋势和周期性,而非单个数据点。
- 与大数据生态的无缝集成:数据需要被上层的分析和机器学习框架(如 Spark、Flink)消费。
传统的通用关系型数据库或大数据存储方案(如 HBase)在应对这些特定需求时往往力不从心,因此,专业的时序数据库成为必然选择。
1.2. 评估维度:如何科学地选择时序数据库?
为了进行公正和全面的评估,本报告将从以下几个关键维度对时序数据库进行考量:
- 架构与可扩展性:系统的核心设计是分布式的还是单体的?是否易于水平扩展以应对业务增长?
- 性能(写入与查询) :在高并发场景下的写入吞-吐量如何?对于时间范围查询、聚合查询的响应速度怎样?
- 数据模型与存储效率:数据模型是否灵活?数据压缩能力如何?
- 生态系统与集成:是否提供与主流大数据工具、可视化软件和编程语言的连接器?
- 社区活跃度与许可模式:开源社区是否活跃?商业支持是否可用?许可协议是否符合企业要求?
- 运维复杂度:部署、监控和维护的难度如何?
2. 主流国外时序数据库概览与分析
为了更好地理解市场格局并凸显 IoTDB 的差异化优势,我们选取了三款在国际上具有广泛影响力的开源时序数据库进行分析:InfluxDB、TimescaleDB 和 OpenTSDB。
2.1. InfluxDB:监控领域的先行者
InfluxDB 是目前 DB-Engines 排名最高的时序数据库,以其高性能和易用性在 DevOps 监控和实时分析领域获得了广泛应用 。
- 核心特性与架构:InfluxDB 采用 Go 语言开发,拥有一个名为 TSM (Time-Structured Merge Tree) 的自研存储引擎,针对时序数据写入和压缩进行了深度优化 。它提供了一个类 SQL 的查询语言 InfluxQL 以及更强大的脚本查询语言 Flux,并内置了数据处理和监控告警功能。
- 优势与局限:
- 优势:部署简单,单机写入性能非常出色,拥有成熟的生态套件(TICK Stack)。
- 局限:开源版本的集群功能受限,对于需要大规模水平扩展的场景可能成为瓶颈。其 Flux 查询语言虽然功能强大,但学习曲线相对陡峭。
- 典型应用场景:服务器与应用性能监控、物联网传感器数据采集、实时分析仪表盘 。
- 许可模式与社区:采用开源(MIT License)和商业版并行的模式。社区非常活跃,文档和教程丰富。
2.2. TimescaleDB:基于 PostgreSQL 的关系型时序扩展
TimescaleDB 独树一帜,它并非一个全新的数据库,而是作为 PostgreSQL 的一个扩展插件存在,这使得它能够完美地继承 PostgreSQL 成熟的生态和强大的 SQL 功能 。
- 核心特性与架构:TimescaleDB 的核心概念是"Hypertable",它是一个自动按时间和空间进行分区的抽象表 。数据被写入时,会自动路由到对应的物理子表(Chunk)中。这种设计使得它既能保持 PostgreSQL 的稳定性和功能丰富性,又能获得处理大规模时序数据的能力。
- 优势与局限:
- 优势:完全兼容 SQL,学习成本低。可以轻松地将时序数据与关系型数据进行 JOIN 查询。受益于 PostgreSQL 强大的生态系统 。
- 局限:由于其架构基于通用的 PostgreSQL,在写入性能和数据压缩率上,相较于为时序场景从零设计的原生引擎(如 IoTDB 的 TsFile),可能存在一定差距。
- 典型应用场景:金融数据分析、需要复杂关联查询的商业智能(BI)、物联网数据与设备元数据混合分析 。
- 许可模式与社区:核心功能采用 Timescale License(一种源代码可用许可证),同时提供基于 Apache-2.0 许可证的社区版和功能更强的企业版。
2.3. OpenTSDB:为海量规模而生的Hadoop生态组件
OpenTSDB 是一个构建在 Apache HBase 之上的分布式时序数据库,其设计初衷就是为了存储和处理海量的监控数据 。
- 核心特性与架构:OpenTSDB 自身不存储数据,而是将时序数据编码后存储在 HBase 表中。它利用 HBase 的分布式能力实现了高可用和水平扩展。其数据模型基于度量(Metric)和标签(Tag),非常灵活。
- 优势与局限:
- 优势:可扩展性极强,能够管理数万亿级别的数据点 。与 Hadoop 和 HBase 生态系统紧密集成。
- 局限:严重依赖外部系统(Hadoop、HBase、ZooKeeper),部署和运维非常复杂,不适合中小型应用。查询功能相对基础,不支持复杂的分析函数。
- 典型应用场景:超大规模的基础设施监控、网络监控系统 。
- 许可模式与社区:采用 Apache License 2.0,是一个完全开源的项目。
3. Apache IoTDB:为物联网与大数据而生的新一代TSDB
在了解了上述产品的特点后,我们来深入探讨本次报告的主角------Apache IoTDB。IoTDB 是一个由清华大学发起并贡献给 Apache 基金会的顶级开源项目,它从设计之初就精准地定位于物联网(IoT)和工业互联网(IIoT)场景,致力于解决端-边-云协同计算下的海量时序数据管理问题 。
3.1. IoTDB 架构与核心设计理念
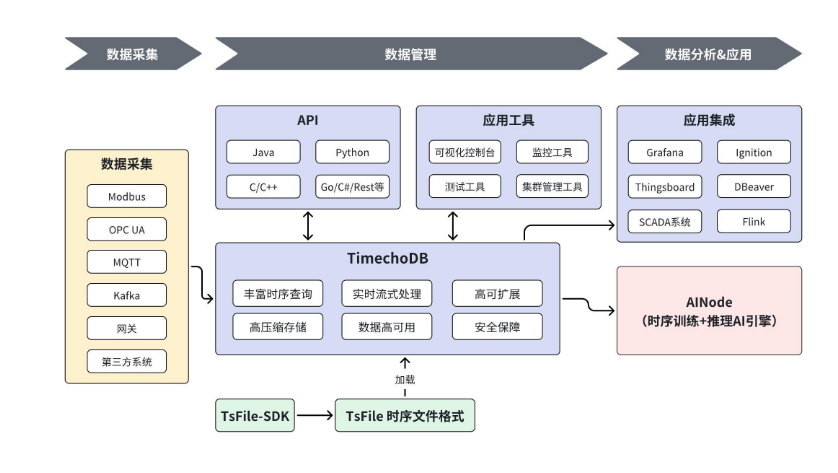
IoTDB 采用了一种轻量化、高可扩展的架构,其核心组件包括数据节点(DataNode)和配置节点(ConfigNode)。这种架构使其能够灵活地部署为单机版或分布式集群 。
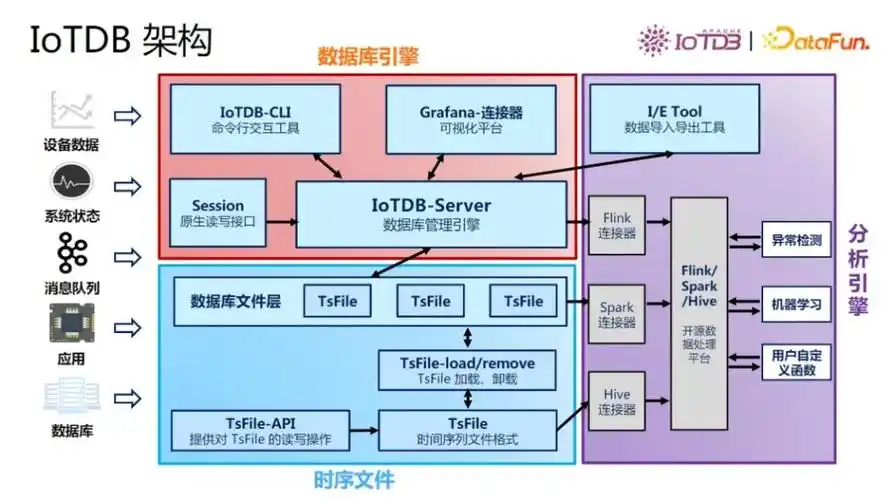
其设计的核心亮点在于其自研的列式存储文件格式------TsFile。TsFile 专为时序数据设计,融合了多种高效的数据编码和压缩技术,实现了极高的数据压缩率和查询性能 。
3.2. IoTDB 在大数据场景下的核心优势
相较于其他 TSDB,IoTDB 在大数据和物联网集成方面展现出了独特的优势:
- 极致的存储效率:得益于 TsFile 的列存、专有编码(如 RLE, DIFF, GORILLA)和压缩算法(如 SNAPPY, LZ4),IoTDB 通常可以实现超过10:1甚至更高的压缩比,极大地降低了海量数据的存储成本 。
- 卓越的读写性能:IoTDB 的存储引擎为高并发写入和长周期范围查询进行了深度优化,在多个公开的性能评测中表现优异,能够满足工业级应用对数据实时性的严苛要求 。
- 与大数据生态的深度融合:IoTDB 提供与 Apache Spark、Flink、Hadoop MapReduce 等主流计算框架的无缝连接器。这意味着企业可以将海量的时序数据存储在 IoTDB 中,并直接利用现有的大数据技术栈进行复杂的分析、ETL 和机器学习任务,无需繁琐的数据迁移。
- 端-边-云协同能力:IoTDB 的轻量化设计使其不仅可以部署在云端数据中心,还可以运行在资源受限的边缘网关甚至终端设备上。其 TsFile 文件格式的统一性,使得数据可以高效地从端、边同步到云,形成完整的数据协同链路。
- "SQL-Like"的友好体验:IoTDB 提供了标准的 JDBC 接口和类 SQL 的查询语言,大大降低了开发人员和数据分析师的学习和使用门槛。
3.3. IoTDB 应用场景分析
IoTDB 的特性使其成为以下场景的理想选择:
-
工业物联网 (IIoT) :在高端制造、电力、石化等行业,需要对成千上万台设备的运行状态进行实时监控和历史数据分析,以实现故障预警和预测性维护。IoTDB 的高性能写入和高压缩率能够完美应对这一挑战。
-
智慧能源:对智能电网中的用户用电数据、发电厂机组运行参数进行大规模采集和分析,优化能源调度和设备管理。
-
车联网 (IoV) :收集数百万辆网联汽车的行驶轨迹、电池状态、驾驶行为等数据,进行实时监控、里程计算和驾驶行为分析。
4. Apache IoTDB 实践指南:部署
为了让读者对 IoTDB 有更直观的认识,本节将指导您如何在 Ubuntu 22.04 LTS 环境下,使用 Docker Compose 快速部署一个单机版的 IoTDB 服务,并进行简单的数据写入和查询。
4.1. 环境准备
-
操作系统:Ubuntu 22.04 LTS
-
Java环境:确保已安装 JDK 1.8 或更高版本,推荐 OpenJDK 11 。
bash# 检查Java版本 java -version -
Docker 与 Docker Compose:确保已安装最新版本的 Docker 和 Docker Compose 。
4.2. 使用 Docker Compose 部署单机版 IoTDB
-
创建 Docker Compose 配置文件
创建一个名为
docker-compose.yml的文件,并填入以下内容。这个配置会启动一个 IoTDB 服务,并将数据和日志目录挂载到宿主机的./data和./logs目录,方便数据持久化和日志查看 。yamlversion: '3.8' services: iotdb-standalone: image: apache/iotdb:1.3.1-standalone container_name: iotdb-service ports: - "6667:6667" # RPC 端口 - "31999:31999" # InfluxDB Protocol 端口 - "5555:5555" # MQTT 端口 volumes: - ./data:/iotdb/data - ./logs:/iotdb/logs environment: - IOTDB_DATA_NODE_RPC_ADDRESS=0.0.0.0 -
启动 IoTDB 服务
在
docker-compose.yml文件所在的目录下,执行以下命令启动服务:bashdocker-compose up -d -
终端输出(启动过程)
首次启动时,Docker 会拉取镜像。启动过程如下:

-
检查服务状态
使用以下命令查看容器是否正常运行,并检查日志确认启动成功。
bash# 查看容器状态 docker-compose ps # 查看启动日志 docker-compose logs -f -
终端输出(日志确认)
当您在日志中看到类似 "Congratulations, IoTDB DataNode is set up successfully." 的信息时,表示 IoTDB 服务已成功启动 。

4.3. 客户端连接与数据
-
连接到 IoTDB CLI
通过
docker exec命令进入正在运行的容器,并启动 IoTDB 的命令行客户端 (CLI)。bashdocker exec -it iotdb-service /iotdb/sbin/start-cli.sh -
终端输出(CLI 登录)
成功连接后,您将看到 IoTDB 的欢迎界面。
-
执行数据操作(写入与查询)
在
IoTDB>提示符后,您可以输入类 SQL 命令进行操作。以下是一个场景:为一个风力发电厂的turbine1号风机创建数据序列,并插入一些传感器读数(转速和功率)。sql-- 1. 创建存储组 (类似于数据库) IoTDB> CREATE DATABASE root.windfarm; Msg: The statement is executed successfully. -- 2. 创建时间序列 (类似于表中的列) IoTDB> CREATE TIMESERIES root.windfarm.turbine1.speed WITH DATATYPE=DOUBLE, ENCODING=GORILLA; Msg: The statement is executed successfully. IoTDB> CREATE TIMESERIES root.windfarm.turbine1.power WITH DATATYPE=DOUBLE, ENCODING=GORILLA; Msg: The statement is executed successfully. -- 3. 插入数据 IoTDB> INSERT INTO root.windfarm.turbine1(timestamp, speed, power) VALUES(1731481200000, 10.5, 2.1); Msg: The statement is executed successfully. IoTDB> INSERT INTO root.windfarm.turbine1(timestamp, speed, power) VALUES(1731481201000, 10.8, 2.2); Msg: The statement is executed successfully. -- 4. 查询数据 IoTDB> SELECT * FROM root.windfarm.turbine1; +-----------------------------+----------------------------+----------------------------+ | Time|root.windfarm.turbine1.power|root.windfarm.turbine1.speed| +-----------------------------+----------------------------+----------------------------+ |2025-11-13T07:00:00.000+00:00| 2.1| 10.5| |2025-11-13T07:00:01.000+00:00| 2.2| 10.8| +-----------------------------+----------------------------+----------------------------+ Total line number = 2 It costs 0.023s -- 5. 执行聚合查询,计算平均功率 IoTDB> SELECT avg(power) FROM root.windfarm.turbine1; +------------------------------------+ |avg(root.windfarm.turbine1.power)| +------------------------------------+ | 2.15| +------------------------------------+ Total line number = 1 It costs 0.015s
通过以上简单的步骤,您便完成了一个 IoTDB 实例的部署和基本的数据操作,直观地体验了其易用性和强大的查询功能。
5. 选型结论与建议
5.1. 综合对比总结
| 维度 | InfluxDB | TimescaleDB | OpenTSDB | Apache IoTDB |
|---|---|---|---|---|
| 核心架构 | 自研TSM引擎 | PostgreSQL扩展 | 基于HBase | 自研TsFile列式存储 |
| 可扩展性 | 开源版受限 | 良好 | 极强 | 良好,原生分布式 |
| 性能 | 写入性能高 | 均衡 | 依赖HBase | 写入和查询性能均优 |
| 存储效率 | 良好 | 中等 | 依赖HBase | 极高,压缩比领先 |
| 查询语言 | InfluxQL/Flux | 标准SQL | 自定义API/SQL | 类SQL,支持JDBC |
| 生态集成 | TICK生态成熟 | PostgreSQL生态 | Hadoop生态 | 深度集成Spark/Flink等 |
| 运维复杂度 | 低 | 中 | 高 | 低(单机)/中(集群) |
| 最佳场景 | DevOps监控 | 关系型数据融合 | 超大规模监控 | 物联网/工业大数据 |
5.2. 为什么选择 Apache IoTDB?
在进行时序数据库选型时,没有"银弹",只有"最适合"。
- 如果您的业务强依赖于现有的 PostgreSQL 生态,且需要频繁地进行时序数据与关系型数据的复杂关联查询,TimescaleDB 是一个值得考虑的选项。
- 如果您的主要场景是中等规模的 DevOps 监控,并且希望开箱即用,InfluxDB 依然是一个强有力的竞争者。
- 如果您已经拥有成熟的 Hadoop/HBase 技术栈,并且需要管理PB级别的监控数据,OpenTSDB 的可扩展性是其核心优势。
然而,如果您正在为物联网、工业互联网、车联网等新兴大数据场景构建技术平台,Apache IoTDB 则展现出了无与伦比的综合优势:
- 为物联网而生:其数据模型、存储引擎、端-边-云协同架构都是为物联网场景量身定制的,这是其他通用型 TSDB 所不具备的基因优势。
- 极致的成本效益:其领先的数据压缩能力,意味着在同等数据量下,企业可以节省大量的存储成本,这对于动辄产生TB、PB级数据的物联网应用至关重要。
- 拥抱大数据生态:与 Spark/Flink 的深度集成为上层的数据分析和价值挖掘铺平了道路,使 IoTDB 不仅仅是一个存储系统,更是一个强大的时序数据平台。
- 活跃的顶级开源社区:作为 Apache 顶级项目,IoTDB 拥有一个全球化、充满活力的社区,技术演进迅速,能够为用户提供长期的技术保障。
Apache IoTDB 凭借其先进的架构设计、卓越的性能表现以及与大数据生态的紧密结合,正在成为物联网和工业大数据领域时序数据库选型的理想答案。我们强烈建议相关领域的企业和技术团队,将 Apache IoTDB 作为核心备选方案进行深入评估和测试。
下载和官网链接:下载链接:https://iotdb.apache.org/zh/Download/
企业版官网链接:https://timecho.com