2025年11月13
迭代曼巴扩散变化检测模型(IMDCD)
- 现有主流方法存在明显局限:CNN 长距离建模能力不足,Transformer 计算复杂度高;预 / 后变化图像的信息融合易导致信息丢失或冗余,影响边缘检测精度。(什么是长距离建模能力不足?)------高分辨率遥感图中 "1 公里外道路扩建" 与 "建筑新建" 的关联),Transformer 虽能捕捉但计算复杂度为 O (n²),无法处理超大图像;
- 预 / 后变化图像的信息融合易丢失细节(如建筑边缘)或产生冗余(如季节导致的植被颜色变化),导致边缘检测不准;
- 传统模型多为 "单次检测",无法逐步修正错误(如误判 "阴影" 为 "地物变化")。
- 遥感变化检测(CD):需精准识别不同时期地表覆盖、地形、人类活动等变化,是土地管理、环境监测等任务的关键技术。
整体框架 :基于扩散模型(DDPM)的端到端架构,通过迭代推理逐步优化变化检测图,结合曼巴(Mamba)架构与注意力机制,平衡长距离依赖捕捉与计算效率。啥是曼巴架构
DDPM+Mamba + 注意力
- DDPM:提供 "迭代去噪" 能力,通过 1000 步逐步优化检测结果,解决 "单次检测精度低" 问题;
- Mamba(SME):以线性复杂度(O (n))捕捉长距离依赖,解决 "Transformer 计算爆炸" 问题;
- 注意力(GHAT):精准融合高低维特征,解决 "信息融合失真" 问题;
- 三者通过 "端到端架构" 串联,实现 "高效特征提取→精准特征融合→迭代结果优化" 的全流程闭环。
应用:
假设我们有 2022 年("预变化图像")和 2024 年("后变化图像")某城区的卫星影像:
- 2022 年图像:某地块为空地,周边有 3 栋 6 层居民楼,地块边缘有一排树木;
- 2024 年图像:该地块新建了 2 栋 12 层公寓楼,原有 3 栋居民楼中 1 栋被拆除,树木因季节变化部分落叶(属于 "伪变化",非真实地物变更)。
- 核心需求:精准识别 "新建公寓楼""拆除居民楼" 等真实变化,排除 "树木落叶" 的伪变化,且清晰勾勒建筑边缘(避免漏检小阳台、误判道路为建筑)。
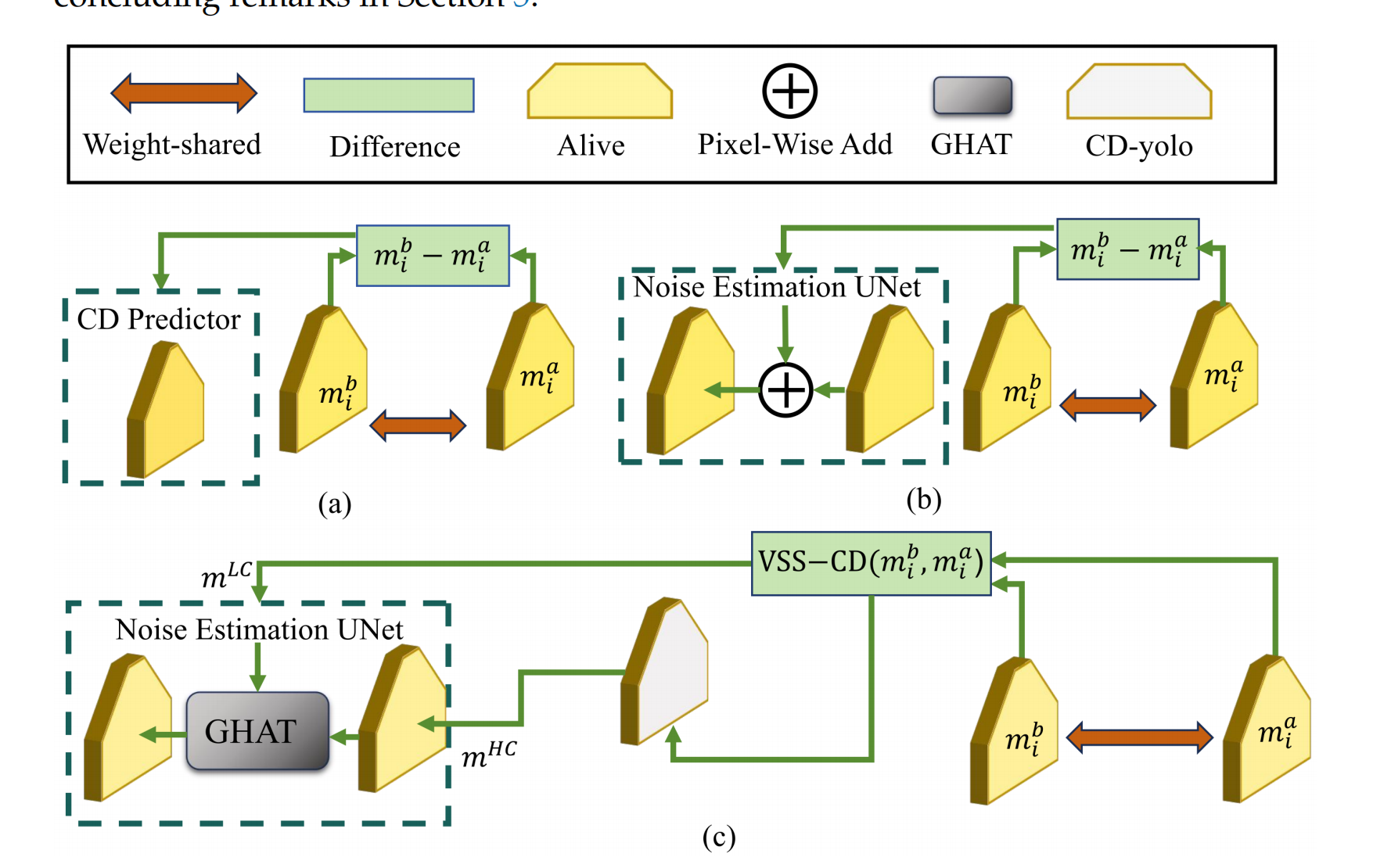
MCD 特征提取器:
1. SME(Swin-Mamba-Encoder):捕捉变化
Swin Transformer 的 "分层特征提取" 与 Mamba 的 "线性状态空间建模" 的融合
目的是在 "高效计算" 的前提下,提取遥感图像的 "全局语义特征"(如 "某区域属于'住宅区'还是'工业区'""新建建筑与周边道路的空间关联"
SME 用线性计算复杂度,能同时捕捉 "新建公寓楼的整体轮廓" 和 "拆除居民楼与周边道路的空间关系"。输入双时相图,输出高维特征图
2. VSS-CD 模块:区分 "真变化" 与 "伪变化"
3. CD-yolo 模块:补全 "细节"
CD-yolo 借鉴 YOLO 的多尺度融合能力,将 SME 提取的 "全局建筑轮廓" 与 "阳台边缘、门窗位置" 等局部细节融合,生成 低维特征图
GHAT 模块:再 "整合信息",避免偏差
把 MCD 提取的 "全局语义" 和 "局部细节" 结合, 通过 "全局混合注意力",把这两个信息 "粘合成完整线索":比如它会确认 "m^HC 中标注的'新建住宅区域',与 m^LC 中标注的'东墙边缘、阳台轮廓'完全对应",避免出现 "全局标了'新建建筑',但局部漏画阳台" 的偏差;同时,它会排除 "m^LC 中树木区域的像素变化",因为 m^HC 已标注该区域为 "植被"(无真实结构变更),从而进一步压制伪变化。
NEUNet 与迭代扩散:最后 "逐步优化",输出清晰结果
Mamba架构
挑战 Transformer:全新架构 Mamba 详解 - 知乎
SSM定义
| 符号 | 含义(通俗理解) | 维度 / 类型 |
|---|---|---|
| u(t) | 系统的输入信号(比如文本的 token、音频的波形) | 一维标量(R) |
| x(t) | 系统的隐藏状态(类似 RNN 的隐藏状态,是对历史信息的 "浓缩记忆") | N维向量(RN) |
| y(t) | 系统的输出信号(比如下一个 token 的预测、音频的生成结果) | 一维标量(R) |
| A | 状态转移矩阵(控制 "隐藏状态自身如何变化",比如记忆的衰减或保持) | N×N矩阵 |
| B | 输入到状态的矩阵(控制 "输入如何融入隐藏状态",比如新信息如何存入记忆) | N×1矩阵 |
| C | 状态到输出的矩阵(控制 "隐藏状态如何转化为输出",比如记忆如何生成结果) | 1×N矩阵 |
| D | 输入直接到输出的参数(通常取 0,即输入不直接输出,仅通过状态传递) | 标量 |
- S4(算法 1)是 "时间不变" 的 :参数
A、B、C、Δ是全局固定 的(维度不含序列长度L),整个序列的所有时间步共享同一套参数。比如B的维度是(D, N),意味着 "所有时间步的输入→状态投影规则完全一样"。 - S6(算法 2)是 "时间变化" 的 :通过
s_B(x)、s_C(x)、s_Δ(x)将参数变成依赖输入x且随时间步变化 的 ------ 参数维度引入了序列长度L,每个时间步都有专属的参数。
二、s(x)函数的具体作用:让参数 "内容感知 + 逐步调整"
s_B(x)、s_C(x)、s_Δ(x)是三个输入依赖的线性映射函数 ,它们的核心作用是 "把输入x的信息注入到 SSM 的关键参数中",实现 "每个时间步都有专属的状态转移规则":
1. sB(x)=LinearN(x):输入→状态的动态投影
- 输入
x的维度是(B, L, D)(批次、序列长度、模型维度); - 经过
Linear_N(输出维度为N的线性层)后,B的维度变为(B, L, N)------每个时间步L都有专属的 "输入→状态" 投影矩阵; - 作用:让 "当前输入如何融入隐藏状态" 的规则随输入内容变化(比如文本中遇到 "人名" 时,调整投影方式来强化记忆)。
基于扩散模型和多注意力网络的遥感图像变化描述生成(MADiffCC)
旨在解决现有遥感图像变化描述(RSICC)方法的核心缺陷
核心模型 MADiffCC 的结构
框架由三部分构成,形成 "特征提取 - 差分编码 - 描述生成" 的完整流程:
-
扩散特征提取器:
- 基于遥感图像数据集(Sentinel-2 卫星图像,约 50 万张)预训练的去噪扩散概率模型(DDPM),冻结预训练权重后提取特征;
- 输出 "多级别(1-5 级,对应不同空间分辨率)+ 多时间步(最优为 50 和 100 步)" 的多尺度特征,能学习遥感数据分布和时空语义关联,提升特征的鲁棒性和泛化性(这是首次将扩散模型应用于 RSICC)。
-
时间 - 通道 - 空间注意力(TCSA)差分编码器:
- 先融合多时间步特征,再通过通道注意力(聚焦关键特征通道)和空间注意力(定位变化区域),精准提取变化相关的判别信息;
- 结合位置嵌入和差分编码,进一步强化双时相图像的差异表征,过滤无关冗余信息。
-
门控多头交叉注意力(GMCA)引导的解码器:
- 基于改进 Transformer,通过 GMCA 机制关联文本特征与多尺度差分特征,自适应选择并融合关键层级信息;
- 采用掩码多头自注意力(MMSA)确保生成文本的时序连贯性,最终输出精准的变化描述。
遥感图像生成
- 遥感语义图像合成(SIS)旨在从土地利用 / 覆盖(LULC)标签生成高保真卫星图像,支撑地图更新、数据增强等应用。
- 现有方法存在不足:GAN 模型训练不稳定、易模式崩溃,难以生成复杂地理场景;扩散模型缺乏目标级空间关系捕捉,合成图像的结构一致性和语义连贯性欠佳。
- 关键痛点:现有方法多聚焦像素级映射,未充分建模地物间的空间布局和语义关联。
基本概念梳理
++土地覆盖对象的空间关系++指地物在地理位置上的相对位置与布局关联,语义关系指地物类别在功能、属性上的内在关联,两者共同构成地理场景的结构逻辑,是遥感图像合成中保证场景合理性的关键。
- 空间关系保证 "布局合理":比如道路不会凭空穿过湖泊,建筑不会无序堆叠。
- 语义关系保证 "类别协调":比如草原场景不会出现城市高楼,海岸带不会搭配内陆旱地。
- 论文提出的 GMDiT 模型,正是通过图结构将这两种关系建模为 "节点(地物)- 边(关系)",从而解决传统方法只关注像素、忽略整体结构的问题。
++栅格化的 LULC++ ,本质是经过栅格化处理后,以像素(栅格)形式存储和表达的土地利用 / 土地覆盖(Land Use/Land Cover, LULC)数据,是遥感与 GIS 领域中 LULC 数据的主流存在形式,核心是将 "土地类别信息" 与 "像素空间位置" 绑定。
要理解 "栅格化的 LULC",需先拆分 "栅格化" 与 "LULC" 的核心定义:
- LULC(土地利用 / 土地覆盖):指描述地球表面土地属性的数据,包含两类关键信息 ------"土地覆盖"(地表物理材质,如森林、水域、建筑)和 "土地利用"(人类使用方式,如农田、工业区、居住区),涵盖自然景观(林地、湿地)、人文区域(城市建筑区)等多种类别。
- 栅格化:指将矢量图形(如矢量格式的 LULC 边界)或非像素数据,转换为以 "像素(栅格单元)" 为基本单位的图像格式的过程。栅格化后的数据以像素阵列呈现,每个像素对应一个具体数值或属性。
栅格化就是把矢量(polygons)或分类型/矢量标注转成像素网格(raster)。对于 LULC,目标通常是:每个像素存储一个类别编码(例如 0: 水,1: 城市,2: 农田,...),形成单波段(单通道)的整型栅格。
BSQ --- Band Sequential(波段顺序存储)
-
存储顺序: 所有波段 1 的所有像素 → 所有波段 2 的所有像素 → 所有波段 3 的所有像素
-
逻辑:
[B1_r0c0, B1_r0c1, ..., B1_rLastcLast, B2_r0c0, ..., B3_rLastcLast] -
优势:按波段逐个处理读取快;适合逐波段分析(例如单波段算法)。
-
直观想象:把每个波段的整张图像连起来依次写到磁盘。
BIP --- Band Interleaved by Pixel(按像素交错)
-
存储顺序:每个像素的所有波段样本一起写,然后下一个像素。
-
逻辑:
[ (B1_r0c0,B2_r0c0,B3_r0c0), (B1_r0c1,B2_r0c1,B3_r0c1), ... ] -
优势:按像素需要同时多波段数据时(如分类器、彩色显示、像素级运算)读取快。
-
直观想象:磁盘上每个像素顺序:先写像素的三个波段值,再写下一个像素的三个波段值。
BIL --- Band Interleaved by Line(按行交错)
-
存储顺序:按行写,每行内按像素写多波段样本,然后写下一行(但波段间不是完全像 BIP 那样像素级交错的最细粒度)。
-
逻辑:
[ row0: (B1_r0c0,B2_r0c0,B3_r0c0),(B1_r0c1,B2_r0c1,B3_r0c1),... , row1: ... ] -
优势:在逐行处理或局部窗口读取时平衡读取效率(相对于 BSQ/BIP)。
-
直观想象:每一行里像素的数据是交错的,行与行之间顺序存储。
生成对抗网络(GANs)
(1 封私信) 【论文阅读】生成对抗网络(GANs)综述 - 知乎
自 2014 年Goodfellow 提出以来,GAN 已通过多种创新架构不断发展,包括原始 GAN(Vanilla GAN)、条件 GAN(Conditional GAN,cGAN)、深度卷积 GAN(Deep Convolutional GAN ,DCGAN)、循环 GAN(CycleGAN)、风格 GAN(StyleGAN)、Wasserstein GAN(WGAN)和大型 GAN(BigGAN)等
GANs由生成器(G)和判别器(D)两个核心组件构成,核心概念如图所示。生成器(G) 的任务是基于随机噪声向量生成合成数据 ,这些噪声向量通过神经网络转换为具有与训练数据集相似特征的数据。生成器不断更新,以生成越来越逼真、能够欺骗判别器的数据 。另一个组件判别器(D) 是一个神经网络,用于区分真实数据和合成数据 。其主要功能是对输入数据(包括来自原始数据集和生成器的数据)进行概率评估,判断数据是真实的还是伪造的。这两个组件之间的动态交互形成了一个竞争框架,生成器和判别器相互竞争,以提升各自在实现最优平衡方面的性能。
精确率 Precision: 用于衡量生成器生成的合成数据与原始数据的相似程度,计算公式如下:
与真实数据相似的合成数据/合成数据总数
**召回率 Recall:**衡量生成器覆盖原始数据分布中所有模式的程度,即生成器在生成数据多样性方面的表现,计算公式如下:
覆盖原始数据模式的合成数据/原始数据所有模式
核心方法:GMDiT 模型架构
核心思路:将语义标签转化为图结构,通过图建模捕捉地物间关系,结合掩码扩散 Transformer 提升合成可控性,搭配场景感知采样策略平衡质量与多样性。
- 语义图构建:将语义地图中的地物区域视为节点,以空间邻接性和语义相似性构建边矩阵,形成语义图 G=(N,E),整合空间与语义信息。
- 图 Transformer:通过 CLIP 编码节点语义,利用图 Transformer 聚合邻域节点信息,捕捉地物间的空间依赖与上下文关系。
- 图掩码扩散 Transformer 框架:基于掩码扩散 Transformer(MDiT),在去噪过程中仅处理部分 latent 令牌,通过交叉注意力融合图嵌入特征,增强结构建模能力。
- 场景感知引导策略:用 VGG16 提取语义图特征,通过 K-means 聚类(最优 K=10)划分场景簇,采样相似场景作为条件输入,提升合成多样性与语义一致性。
- 损失函数:结合掩码令牌重建损失(Lm)和未掩码令牌重建损失(Lum),优化合成图像的保真度。
流程:
1. 输入栅格语义掩码(像素1代表不同地物)
2. 划分区域形成语义节点:
将连续且类别相同的像素群(如一片完整的建筑区域、一条连续的道路)划分为一个 "地物对象"。
每个对象对应一个独立的 "语义节点
3. 语义节点初始化
为每个 "地物节点" 赋予初始特征:
- 空间属性:计算节点对应区域的中心坐标、面积、形状(如建筑区域的矩形边界);
- 语义属性:用 CLIP 模型对节点类别(如 "建筑""道路")进行文本编码,得到语义嵌入向量(捕捉 "建筑与道路相邻合理、与水域相邻不合理" 的先验知识);最终每个节点的初始特征是 "空间属性 + CLIP 语义嵌入" 的拼接向量。
论文阅读方法:
1.摘要可以稍微看一下
2.直接看流程图
- 然后直接看流程图的描述,看他应用了那些/对标(compare)了哪些论文模型,如果不知道就直接去看这篇论文,然后再回来继续看这个论文
4.直接看实验的使用算力,明白这个模型组合是需要什么样的算力,判断自己可不可以去做这个模型
-
看它实验是在哪些数据集上面做的,判断它的实验是否权威
-
看它最后实验的结果是和哪些模型去做的对比,然后看这些模型的应用期刊判断是否权威
接下来三周的主要核心目标:
1.收集近十年遥感图像生成领域是怎么去做的
2.找一个下游任务去想一下可以套在哪个故事里面
3.提出一个遥感图像的生成方法:
有一个before然后又一个map去生成一个after
参考论文:
【1】IMCD
【2】第二篇论文
【3】