

🔥@晨非辰Tong: 个人主页
👀专栏:《C语言》、《数据结构与算法入门指南》
💪学习阶段:C语言、数据结构与算法初学者
⏳"人理解迭代,神理解递归。"
文章目录
- 引言
- 一、介绍交换排序
- 二、高效交换--快速排序":递归版
-
- [2.1 介绍:创造背景以及基本思想](#2.1 介绍:创造背景以及基本思想)
- [2.2 基于二叉树结构的主体框架](#2.2 基于二叉树结构的主体框架)
- 三、找基准值key的三种==递归版==实战方法
-
- [3.1 快排核心构成:寻找key的算法之"hoare"版本](#3.1 快排核心构成:寻找key的算法之"hoare"版本)
-
- [3.3.1 画图理解算法](#3.3.1 画图理解算法)
- [3.3.2 代码实战](#3.3.2 代码实战)
- [3.1.3 ==**代码分析**==](#3.1.3 ==代码分析==)
- [3.2 快排核心构成:寻找key的算法之"挖坑法"](#3.2 快排核心构成:寻找key的算法之“挖坑法”)
-
- [3.2.1 画图理解算法](#3.2.1 画图理解算法)
- [3.2.2 代码实战](#3.2.2 代码实战)
- [3.3 快排核心构成:寻找key的算法之"lomuto前后指针"](#3.3 快排核心构成:寻找key的算法之“lomuto前后指针”)
-
- [3.3.1 画图理解算法](#3.3.1 画图理解算法)
- [3.3.2 代码实战](#3.3.2 代码实战)
- [3.3.3 ==代码分析==](#3.3.3 ==代码分析==)
- 四、高校交换--快速排序:非递归版(面试必会)
-
- [4.1 画图理解算法](#4.1 画图理解算法)
- [4.2 代码实战](#4.2 代码实战)
-
- [4.2.1 代码分析](#4.2.1 代码分析)
- 五、低效交换--冒泡排序
- 六、高效与简易的抉择:两种典型排序算法性能评估
-
- [6.1 多维度对比](#6.1 多维度对比)
- [6.2 代码运行时效对比](#6.2 代码运行时效对比)
- 总结
引言
交换排序是算法世界的重要组成,其中快速排序以其高效著称 ,而冒泡排序则以简单闻名 。本文将深入解析快速排序的三种递归实现和非递归版本,通过图示代码 详细讲解分区过程,并与冒泡排序进行多维度性能对比,帮助读者全面理解两种算法的优劣与适用场景。
点击》》 Gitee--本章代码托管
一、介绍交换排序
基本思想:所谓交换,就是比较序列中的两个元素,如果它们的顺序错误就交换它们的位置,从而逐步将元素移动到其正确位置。
排序特点:
- 对数组元素进行原地操作;
- 排序的过程是构建升序数组的过程。
二、高效交换--快速排序":递归版
2.1 介绍:创造背景以及基本思想
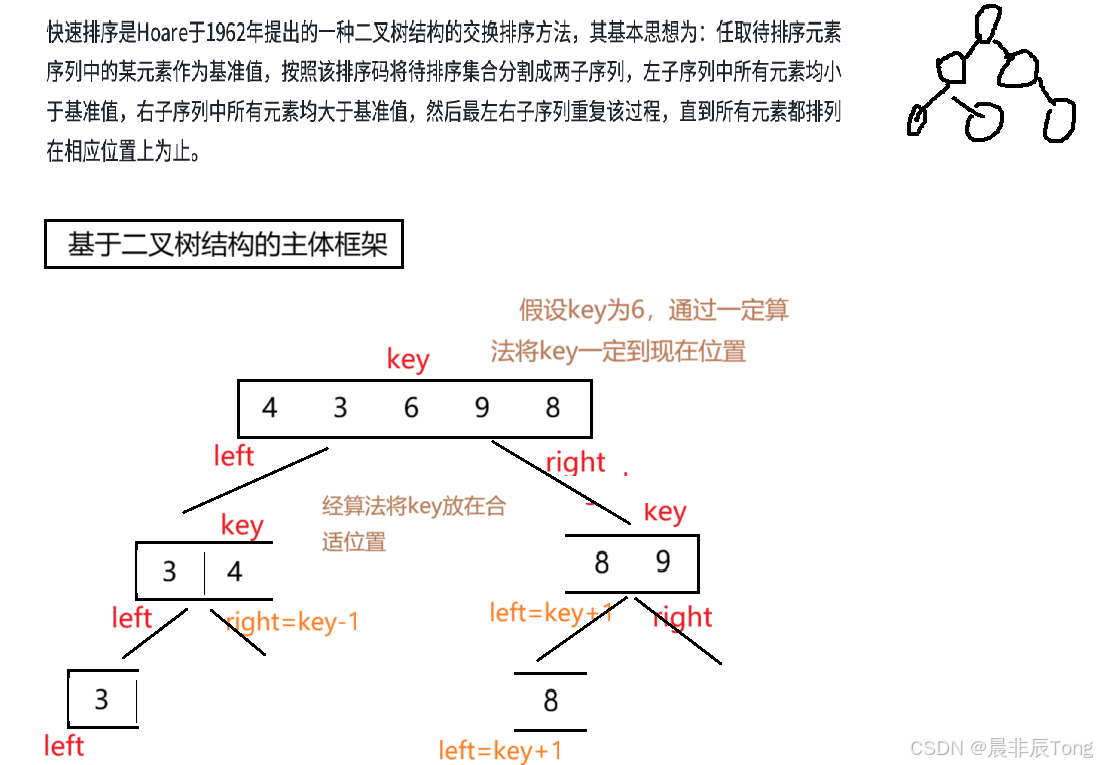
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法。其诞生的背景是为了解决当时主流排序算法的两大痛点:
- 冒泡排序等简单算法效率低下 -- O(N2);
- 归并排序等高效算法占用额外空间太大。
其基本思想为:任取待排序元素序列中的某元素 作为基准值 (key) ,按照基准值该将待排序集合分割成两子序列 ,左 子序列中所有元素均小于基准值 ,右 子序列中所有元素均大于基准值 ,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
2.2 基于二叉树结构的主体框架
因为算法是建立在二叉树的的基础上,那么可以知道的是:会使用到函数的递归结构 ,对于如何进行递归稍后再聊。
在上面提到 --> 要根据key将序列进行分割成左右子序列(类似于二叉树),对于左右子序列的界定就需要定义两个变量:left、right。
大致框架已经有了,对于找key的多种方法会 一 一 介绍。
画图进行演示算法思想:
c
//快速排序-二叉树结构
//主体框架
void QuickSort(int* arr, int left, int right)
{
if (left >= right)
{
return;
}
//获取key:单次
int key = _QuickSort(arr, left, right);
//递归排序
QuickSort(arr, left, key - 1);//左子序列
QuickSort(arr, key + 1, right);//右子序列
}三、找基准值key的三种递归版实战方法
3.1 快排核心构成:寻找key的算法之"hoare"版本
- 算法思路:
- 创建左右"指针",确定基准值;
- 从右向左找出比基准值小的数据,从左向右找出比基准值大的数据,左右指针数据交换,进入下次循环
3.3.1 画图理解算法

- 具体解析
前面提到要定义left、right来界定左右子序列,则初始在序列的最左边与最右边。对于key的选定,默认为初始的left ,那么left就需要++来到下一位,在left++与right之间寻找合适基准值的位置。
接下来就是在整体的大循环中各自进行循环:left找比key大的数,right找比key小的数。因为是一小一大 ,那么循环条件就是 left<=right,不能越界重复寻找 。当二者都处在各自的循环外就代表都找到了,那么就交换二者的数值,当然看图了解到交换条件是left<=right。
最后left>right,大循环结束,此时就要交换key、right完成基准值的寻找。
3.3.2 代码实战
c
//获取基准值--hoare版本
int _QuickSort(int* arr, int left, int right)
{
//定义基准值
int key = left;//默认为初始left值
left++;
//整体循环:left、right遍历寻找
while (left <= right)
{
//right:从右往左找比key小的
while (left <= right && arr[right] > arr[key])
{
//没找到,--
right--;
}
//循环外:right找到了
//left:从左往右找比key大的
while (left <= right && arr[left] < arr[key])
{
//没找到,++
left++;
}
//循环外:left找到了
//二者都找到了,进行交换
if (left <= right)
{
Swap(&arr[right], &arr[left]);
}
}
//交换key、right
Swap(&arr[key], &arr[right]);
return right;
}- 验证函数功能
--大家自行将代码分为不同文件(Sort.h / Sort.c / test.c)。
c
//获取基准值--hoare版本
int _QuickSort(int* arr, int left, int right)
{
//定义基准值
int key = left;//默认为初始left值
left++;
//整体循环:left、right遍历寻找
while (left <= right)
{
//right:从右往左找比key小的
while (left <= right && arr[right] > arr[key])
{
//没找到,--
right--;
}
//循环外:right找到了
//left:从左往右找比key大的
while (left <= right && arr[left] < arr[key])
{
//没找到,++
left++;
}
//循环外:left找到了
//二者都找到了,进行交换
if (left < right)
{
Swap(&arr[right], &arr[left]);
}
}
//交换key、right
Swap(&arr[key], &arr[right]);
return right;
}
//快速排序-二叉树结构
//主体框架
void QuickSort(int* arr, int left, int right)
{
if (left >= right)
{
return;
}
//获取key:单次
int key = _QuickSort(arr, left, right);
//递归排序
QuickSort(arr, left, key - 1);//左子序列
QuickSort(arr, key + 1, right);//右子序列
}
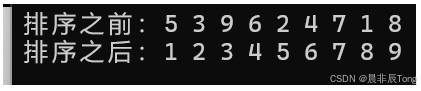
test01()
{
int arr[] = { 5,3,9,6,2,4, 7, 1, 8 };
int n = sizeof(arr) / sizeof(arr[0]);
printf("排序之前:");
PrintArr(arr, n);
QuickSort(arr, 0, n - 1);
printf("排序之后:");
PrintArr(arr, n);
}
int main()
{
test01();
return 0;
}
3.1.3 代码分析
-
找
key算法的时间复杂度:O(N)。虽然看着有循环的嵌套,但是经过作图发现循环始终是继承上回遍历的进度继续开始。也就是循环嵌套是"伪嵌套",实质是协同完成一次遍历,而不是多次独立遍历。
-
快速排序算法时间复杂度:O(n logn)。
递归的时间复杂度 = 单词递归时间复杂度(O (N)) * 递归次数(logn) 。
-
对于内层循环比如:
while (left <= right && arr[right] > arr[key]),条件为什么不换成>=?

根据一种最坏的情况演示,递归次数会从
logn退化为n,最终导致时间复杂度变大。 -
为什么最后的right的位置一定是基准值的位置?
因为最后right的右边的元素已经验证为
>=key的。
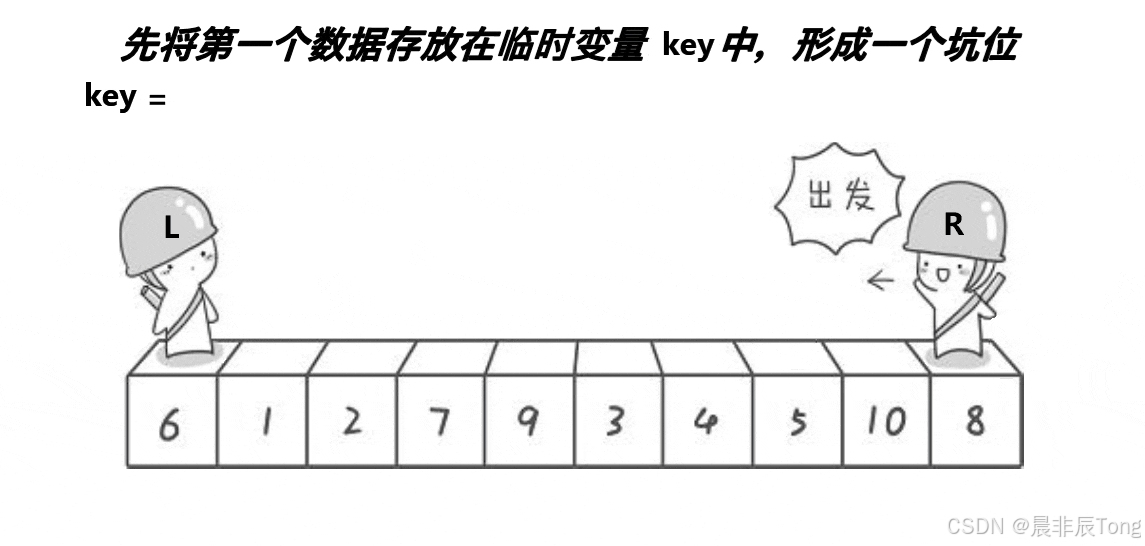
3.2 快排核心构成:寻找key的算法之"挖坑法"
- 算法思路
- 创建左右"指针",(left不++)首先从右向左找出比基准小的数据,找到后立即放入坑中,当前位置变为新"坑";
- 然后从左到右找出比基准大的数据,找到后立即放到右边"坑"中,当前位置变为新"坑";
- 结束循环后将最开始存储的分界值放入当前的坑中,返回当前"坑"的下标。
3.2.1 画图理解算法

- 具体解析
初始将hole放置在最左侧,同时key将元素保存空出"坑" 。接着就是循环内的两个内层循环开始遍历,先是right从右向左找出比基准值小 的数据3再放入hole中,并且right指向的位置变为"新坑"。同理,left从左向右找比基准值大 的数据7再放入hole,并且left指向的位置变为"新坑"。
最终观察发现,当left == right时就是key要放入的"坑"的位置。
3.2.2 代码实战
c
//版本2--"挖矿法"
int _QuickSort(int* arr, int left, int right)
{
//初始将"坑"放在最左侧
int hole = left;
//key保存基准值
int key = arr[left];
while (left < right)
{
//先right进行寻找比key小的数据
while (left < right && arr[right] > key)
{
right--;
}
//循环外right找到了
//交换数据、位置
arr[hole] = arr[right];
//right成为新"坑"
hole = right;
//再left找比key大的数据
while (left < right && arr[left] < key)
{
left++;
}
//循环外left找到了
//交换数据、位置;
arr[hole] = arr[left];
//right成为新"坑"
hole = left;
}
//循环外left == right
arr[hole] = key;
return right;
}- 验证函数功能
--大家自行将代码分为不同文件(Sort.h / Sort.c / test.c)。
c
//版本2--"挖矿法"
int _QuickSort(int* arr, int left, int right)
{
//初始将"坑"放在最左侧
int hole = left;
//key保存基准值
int key = arr[left];
while (left < right)
{
//先right进行寻找比key小的数据
while (left < right && arr[right] > key)
{
right--;
}
//循环外right找到了
//交换数据、位置
arr[hole] = arr[right];
//right成为新"坑"
hole = right;
//再left找比key大的数据
while (left < right && arr[left] < key)
{
left++;
}
//循环外left找到了
//交换数据、位置;
arr[hole] = arr[left];
//right成为新"坑"
hole = left;
}
//循环外left == right
arr[hole] = key;
return right;
}
//快速排序-二叉树结构
//主体框架
void QuickSort(int* arr, int left, int right)
{
if (left >= right)
{
return;
}
//获取key:单次
int key = _QuickSort(arr, left, right);
//递归排序
QuickSort(arr, left, key - 1);//左子序列
QuickSort(arr, key + 1, right);//右子序列
}
test01()
{
int arr[] = { 5,3,9,6,2,4, 7, 1, 8 };
int n = sizeof(arr) / sizeof(arr[0]);
printf("排序之前:");
PrintArr(arr, n);
QuickSort(arr, 0, n - 1);
printf("排序之后:");
PrintArr(arr, n);
}
int main()
{
test01();
return 0;
}
3.3 快排核心构成:寻找key的算法之"lomuto前后指针"
- 算法思路
创建前后指针,从左往右找比基准值小的进行交换,使得小的都排在基准值的左边。
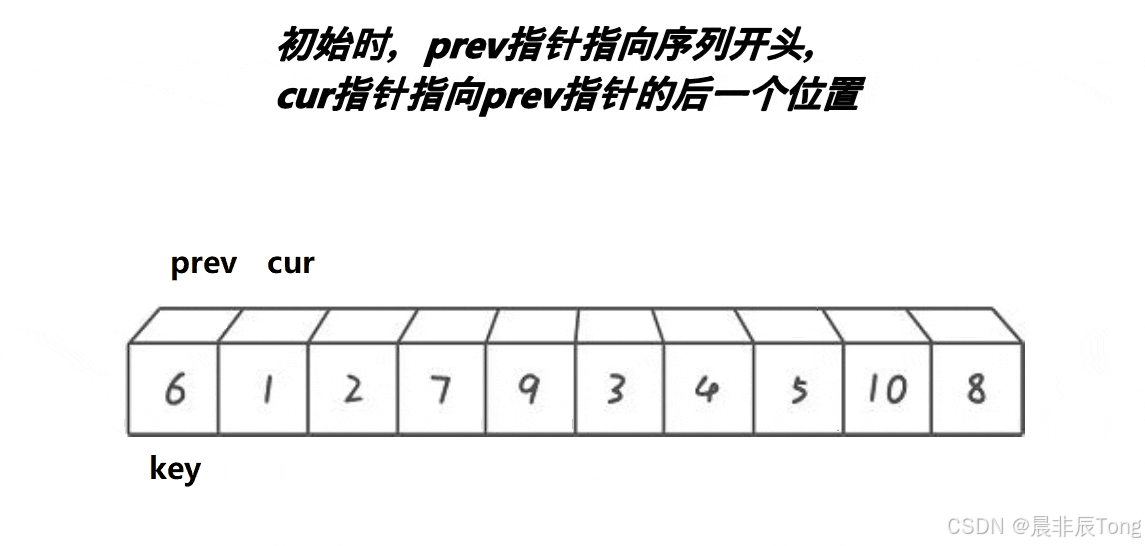
3.3.1 画图理解算法

- 具体解析
该方法与前面作算法题时用的"前后指针"的思想类似,让前指针cur向前寻找比基准值小的数据,找到后后指针 prev++ 与 cur 交换数据后,cur++。
重复进行以上过程,根据作图可知:循环终止条件为cur > right访问越界。
3.3.2 代码实战
c
//基准值版本3:lomuto前后指针
int _QuickSort(int* arr, int left, int right)
{
int prev = left, cur = prev + 1;
int key = left;
while (cur <= right)
{
//cur数据和基准值比较
if (arr[cur] < arr[key] && ++prev != cur )//注意条件的设置
{
Swap(&arr[cur], &arr[prev]);
}
++cur;
}
Swap(&arr[key], &arr[prev]);
return prev;
}- 验证函数功能
c
//基准值版本3:lomuto前后指针
int _QuickSort(int* arr, int left, int right)
{
int prev = left, cur = prev + 1;
int key = left;
while (cur <= right)
{
//cur数据和基准值比较
if (arr[cur] < arr[key] && ++prev != cur )//注意条件的设置
{
Swap(&arr[cur], &arr[prev]);
}
++cur;
}
Swap(&arr[key], &arr[prev]);
return prev;
}
//快速排序-二叉树结构
//主体框架
void QuickSort(int* arr, int left, int right)
{
if (left >= right)
{
return;
}
//获取key:单次
int key = _QuickSort(arr, left, right);
//递归排序
QuickSort(arr, left, key - 1);//左子序列
QuickSort(arr, key + 1, right);//右子序列
}
test01()
{
int arr[] = { 5,3,9,6,2,4, 7, 1, 8 };
int n = sizeof(arr) / sizeof(arr[0]);
printf("排序之前:");
PrintArr(arr, n);
QuickSort(arr, 0, n - 1);
printf("排序之后:");
PrintArr(arr, n);
}
3.3.3 代码分析
-
对于条件语句
if (arr[cur] < arr[key] && ++prev != cur )的设置问题!这个条件设置的很巧妙~ ,首先看后面的
++prev != cur,该表达式实质上完成了两个任务:一个是 prev的前移 ,另一个是判断是否相等。另外前后顺序的设置,因为是&&有"短路"特性 。所以如果顺序颠倒导致prev前移,但是没有交换,导致错误。 -
定义了"前后指针",为什么不直接传"指针"位置?
为什么传
left、right,因为循环条件需要判断是否访问越界用到了right。
四、高校交换--快速排序:非递归版(面试必会)
非递归版本的快速排序需要借助数据结构:栈
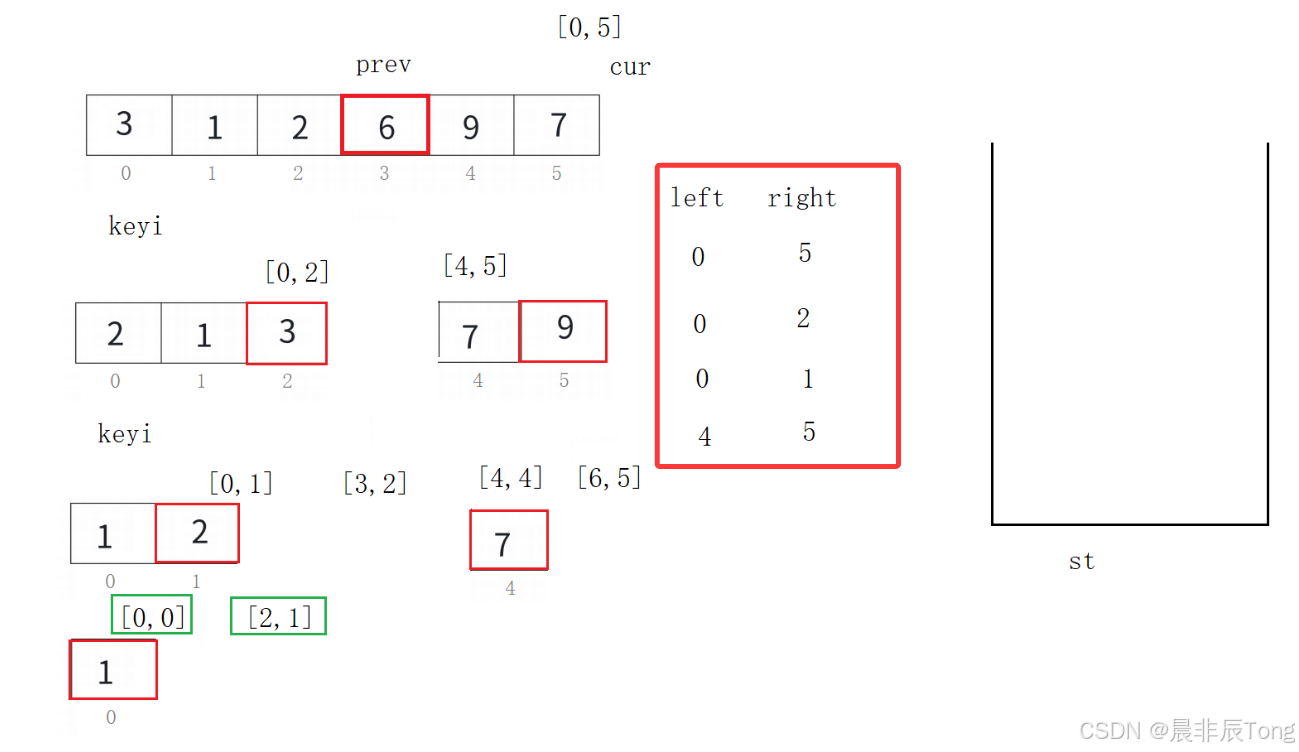
- 算法思路
- 初始化阶段 :创建一个栈并初始化,将初始排序区间的边界
[left, right]压入栈中。(要注意:先压入右边界,再压入左边界(后进先))- 主循环阶段(循环条件:栈不为空时继续执行) 每次循环的操作:
- 弹出区间:从栈中弹出两个元素:begin(区间起点)和 end(区间终点)弹出顺序与压入顺序相反;
- 分区操作:调用 _QuickSort3 函数(或者重新定义)对 begin, end 区间进行分区,返回基准元素的位置 keyi
- 处理子区间: 右子区间:如果 keyi+1, end 长度大于1,压入栈中 左子区间:如果 begin, keyi-1 长度大于1,压入栈中
- 终止条件:当栈为空时,说明所有需要排序的子区间都已处理完毕,销毁栈
4.1 画图理解算法
4.2 代码实战
c
//非递归版本快速排序----栈
void QuickSortNorR(int* arr, int left, int right)
{
ST st;
STInit(&st);
STPush(&st, right);
STPush(&st, left);
while (!STEmpty(&st))
{
//取栈顶两次
int begin = STTop(&st);
STPop(&st);
int end = STTop(&st);
STPop(&st);
//[begin,end]-----找基准值
int keyi = begin;
int prev = begin, cur = prev + 1;
while (cur <= end)
{
if (arr[cur] < arr[keyi] && ++prev != cur)
{
Swap(&arr[prev], &arr[cur]);
}
++cur;
}
Swap(&arr[prev], &arr[keyi]);
keyi = prev;
//begin keyi end
//左序列[begin,keyi-1]
//右序列[keyi+1,end]
if (keyi + 1 < end)
{
STPush(&st, end);
STPush(&st, keyi + 1);
}
if (begin < keyi - 1)
{
STPush(&st, keyi - 1);
STPush(&st, begin);
}
}
STDesTroy(&st);
}
4.2.1 代码分析
-
边界条件检查:避免不必要的栈操作
keyi + 1 < end确保右区间至少有两个元素;begin < keyi - 1确保左区间至少有两个元素。(当区间只有一个元素或没有元素 时(keyi+1 >= end 或 begin >= keyi-1),该区间已经有序。)
-
压栈顺序是(右,左),弹出顺序是(左,右),这种操作的对称性要保证。
五、低效交换--冒泡排序
冒泡排序是一种简单的排序算法。它重复地遍历要排序的数列,一次比较两个相邻元素,如果它们的顺序错误就把它们交换过来。遍历会重复进行,直到没有需要交换的元素,这时数列排序完成。
对于冒泡排序,这个经典的教学产物都不陌生,这里就不过多介绍。
c
void BubbleSort(int* arr, int n)
{
int exchange = 1;
for (int i = 0; i < n - 1; i++)
{
for (int j = 0; j < n - 1 - i; j++)
{
if (arr[j] > arr[j+1])
{
swap(&arr[j], &arr[j+1]);
exchange = 0;
}
}
if (exchange == 1)
{
break;
}
}
}六、高效与简易的抉择:两种典型排序算法性能评估
6.1 多维度对比
| 特性维度 | 快速排序 | 冒泡排序 |
|---|---|---|
| 平均时间复杂度 | O(n log n) | O(n²) |
| 最坏时间复杂度 | O(n²) | O(n²) |
| 空间复杂度 | O(log n) | O(1) |
| 算法思想 | 分区策略 | 相邻比较交换 |
6.2 代码运行时效对比
c
#include"Sort.h"
void PrintArr(int* arr, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void test1()
{
int a[] = { 5, 3, 9, 6, 2, 4, 7, 1, 8 };
int size = sizeof(a) / sizeof(a[0]);
printf("排序前:");
PrintArr(a, size);
//直接插入排序
//InsertSort(a, size);
//希尔排序
//ShellSort(a, size);
//直接选择排序
//SelectSort(a, size);
//堆排序
//HeapSort(a, size);
//冒泡排序
//BubbleSort(a, size);
//快速排序
//QuickSort(a, 0, size - 1);
//非递归快速排序
QuickSortNoare(a, 0, size - 1);
printf("排序后:");
PrintArr(a, size);
}
// 测试排序的性能对比
void TestOP()
{
srand(time(0));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N - 1);
int end5 = clock();
int begin6 = clock();
//MergeSort(a6, N);
int end6 = clock();
int begin7 = clock();
BubbleSort(a7, N);
int end7 = clock();
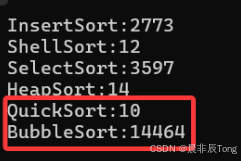
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
//printf("MergeSort:%d\n", end6 - begin6);
printf("BubbleSort:%d\n", end7 - begin7);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
//free(a6);
free(a7);
}
int main()
{
TestOP();
//test1();
return 0;
}
总结
html
🍓 我是晨非辰Tong!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!相关系列:
【数据结构初阶】从"最小值筛选"到代码落地,解锁选择排序的核心思想!
【数据结构初阶】--从排序算法原理分析到代码实现操作,参透插入排序的奥秘!
结语:
快速排序与冒泡排序展现了效率与简洁的鲜明对比。快速排序的三种分区方法和递归/非递归实现,通过与冒泡排序的多维对比,揭示了算法设计的核心权衡:在性能与复杂度、效率与可读性之间寻求最优解。
掌握这些经典算法,不仅在于理解其实现原理,更在于培养根据场景选择合适工具的工程思维。这正是算法学习的真正价值------在理论深度与实践需求间建立智慧桥梁。