博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
58同城房产数据分析与预测项目介绍
本项目以58同城房产数据为核心,基于Python语言构建,融合MySQL、Flask、Echarts等多技术栈,打造集数据采集、分析、预测于一体的综合房产数据平台。通过requests爬虫定向抓取房产信息,经MySQL高效存储后,依托Flask框架搭建稳定交互界面,实现全流程数据处理与可视化展示。
平台核心功能涵盖多维度数据分析与智能预测:利用Echarts生成房源数量、房屋均价、房价时序变化等直观图表,通过词云图、朝向分布、居室占比等可视化结果呈现房产市场特征;基于scikit-learn的CART分类回归树算法,构建房价预测模型,为用户提供精准房价参考。
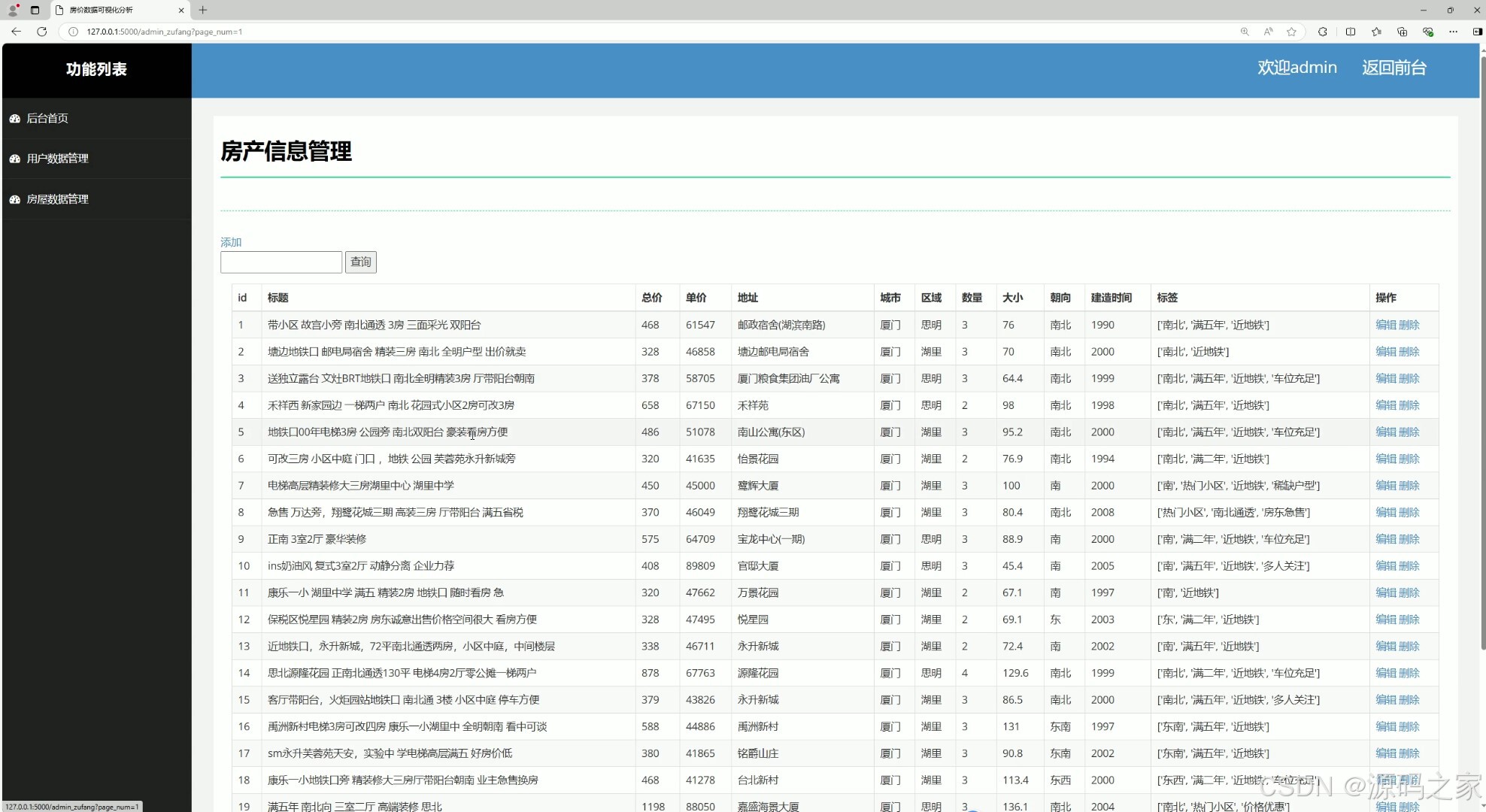
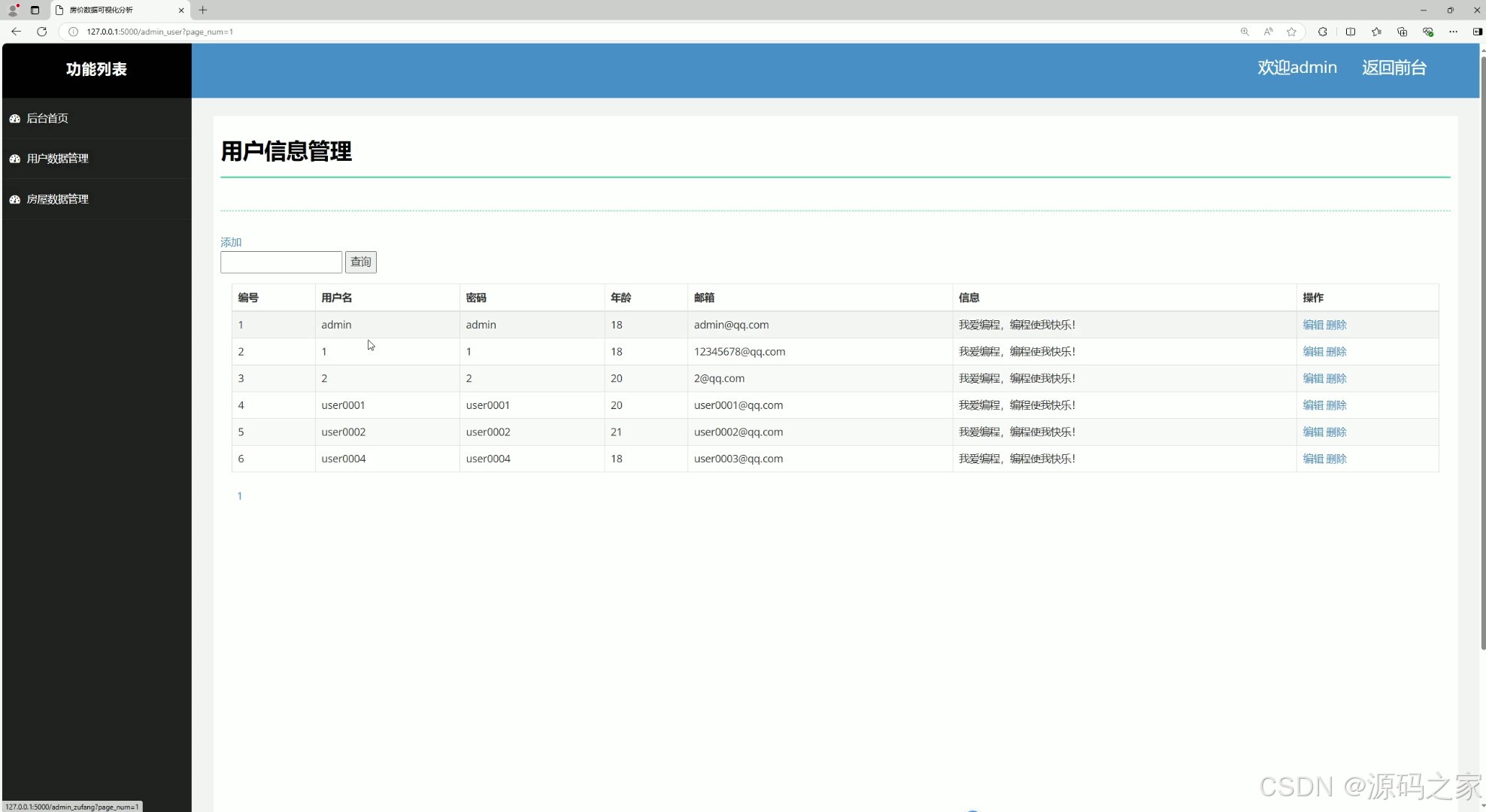
系统支持注册登录权限管理,配备房屋与用户信息管理模块,实现数据增删改查高效操作。数据采集模块可灵活获取最新房产数据,房屋数据列表清晰呈现房源详情,满足用户查询需求。项目兼具数据可视化的直观性与机器学习的预测能力,为购房者、房产从业者提供数据支撑,助力理性决策与市场研判。
技术栈:
python语言、MySQL数据库、Flask框架、Echarts可视化、scikit-learn机器学习、决策树预测算法、requests爬虫、58同城房产
58同城房产
房价预测 scikit-learn机器学习 (决策树预测算法-CART分类回归树)
2、项目界面
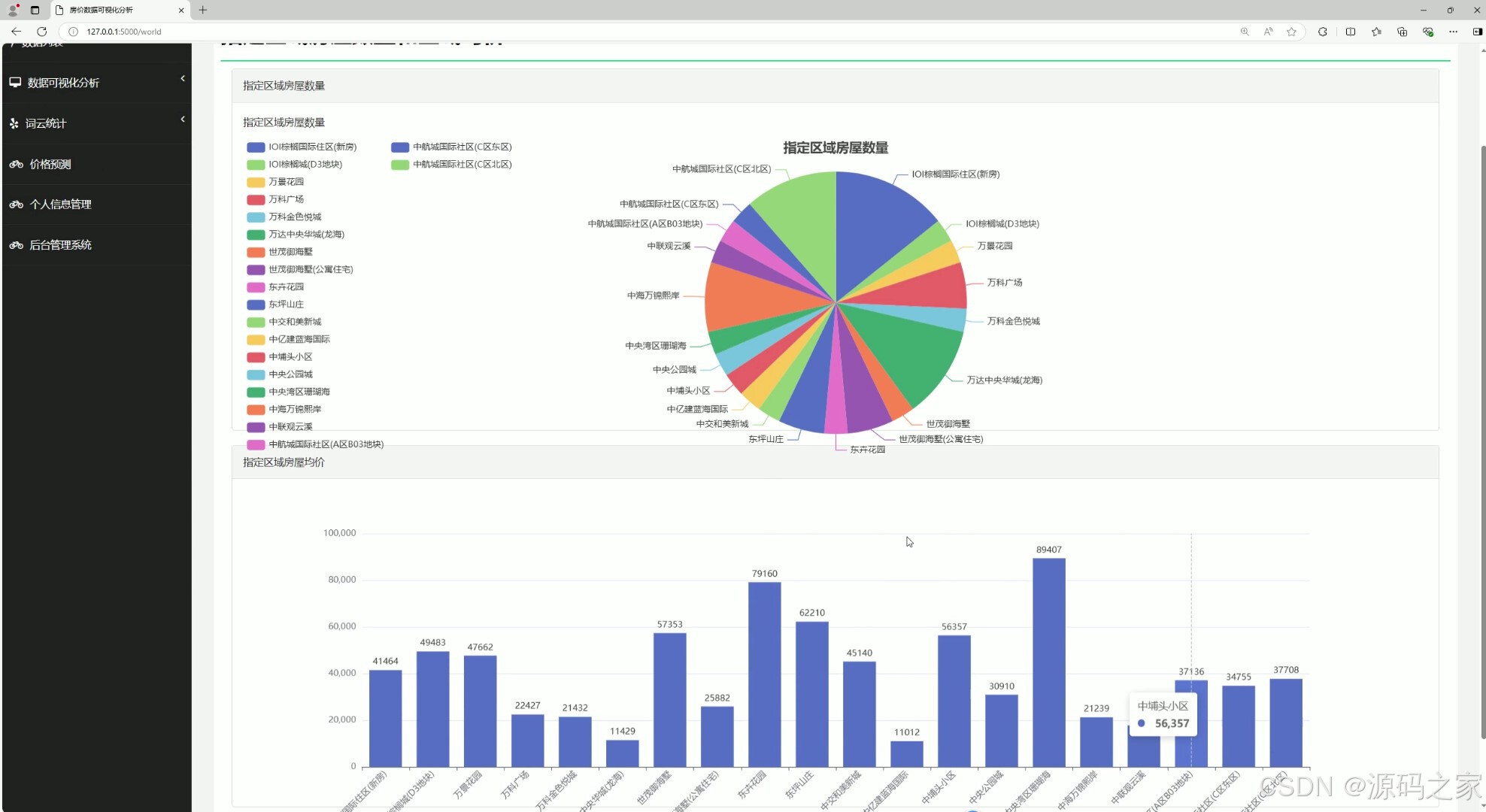
(1)房源数量分析、房屋均价分析
(2)首页
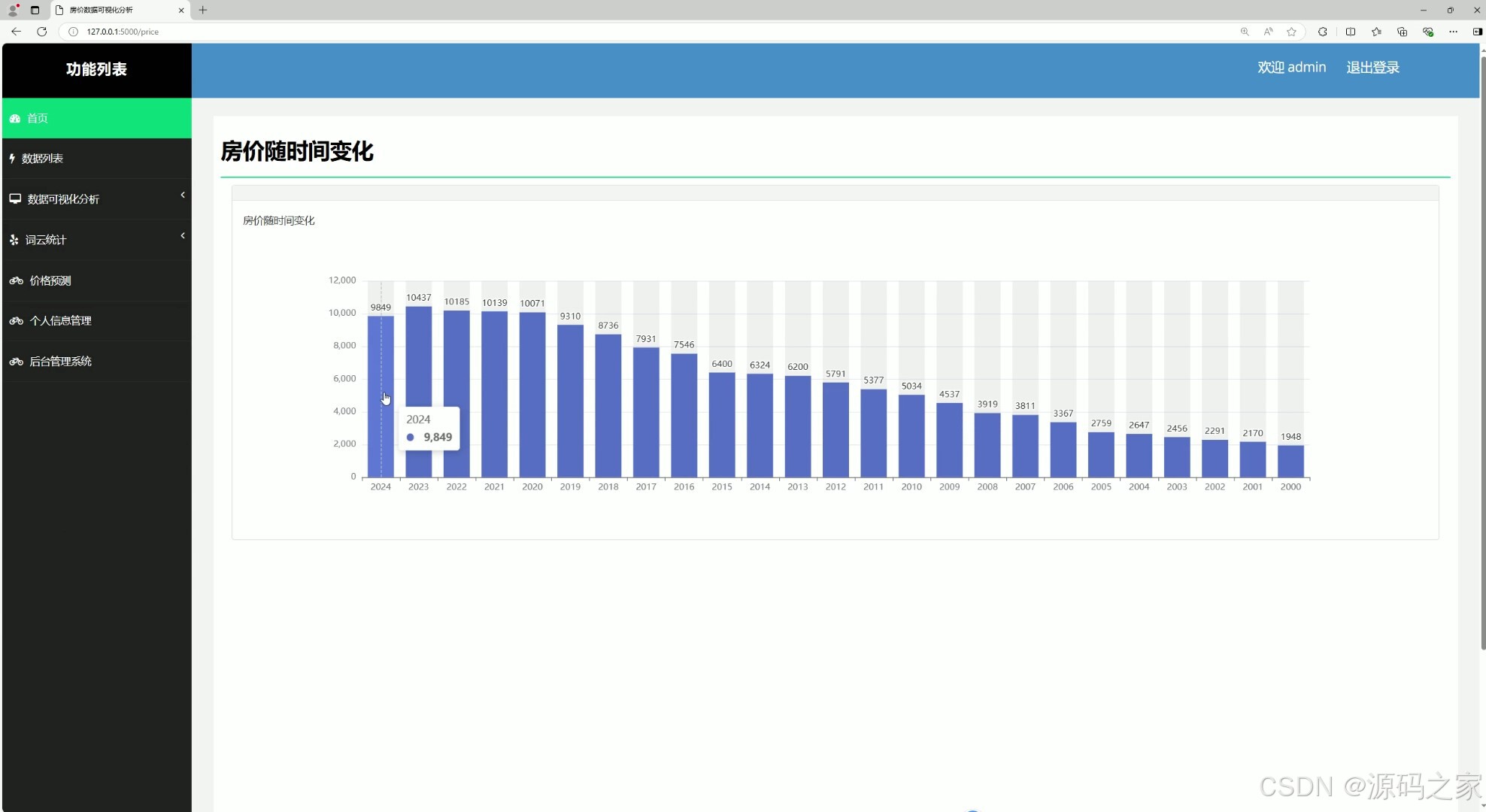
(3)房价随时间变化分析
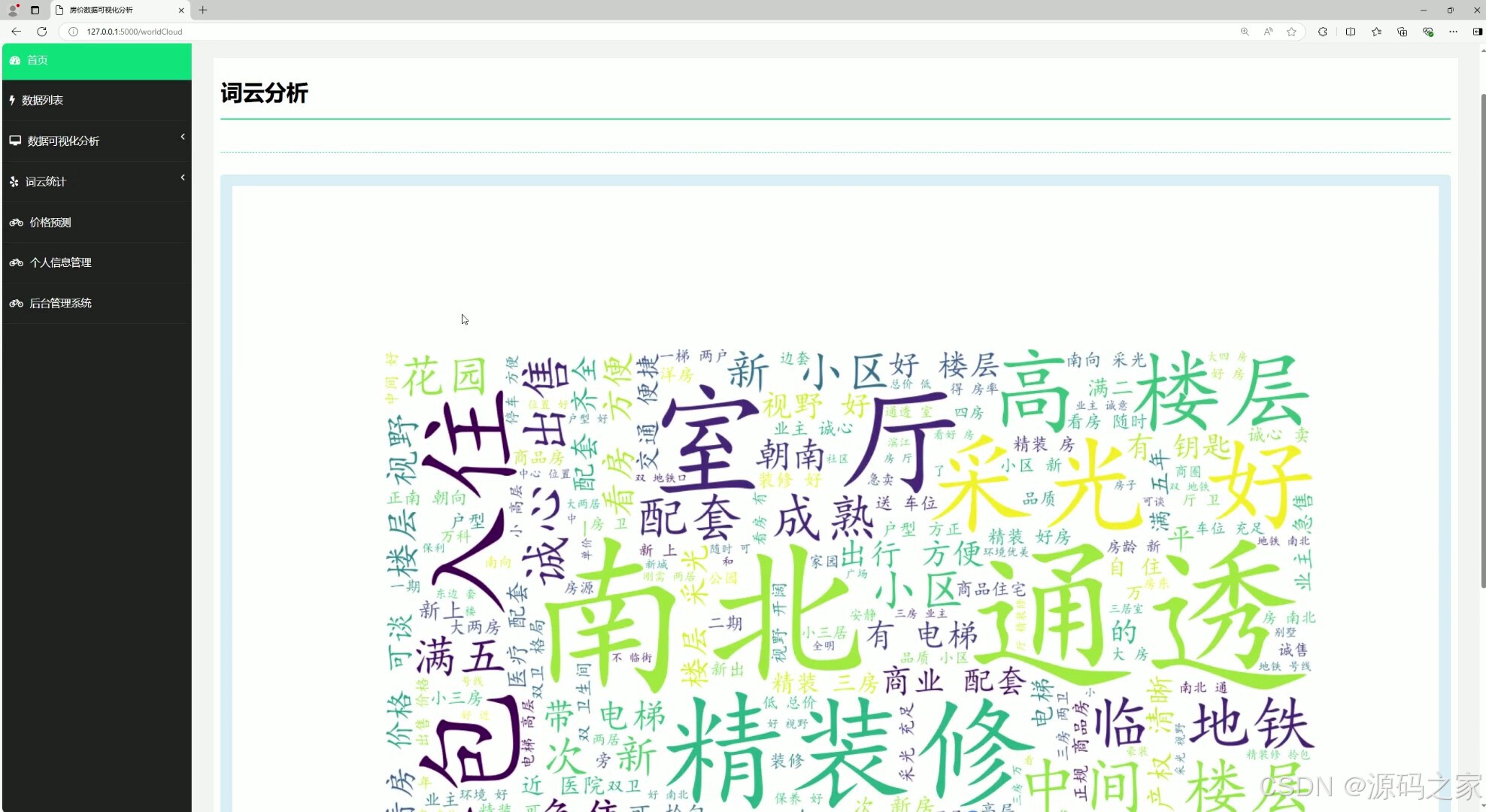
(4)词云图分析
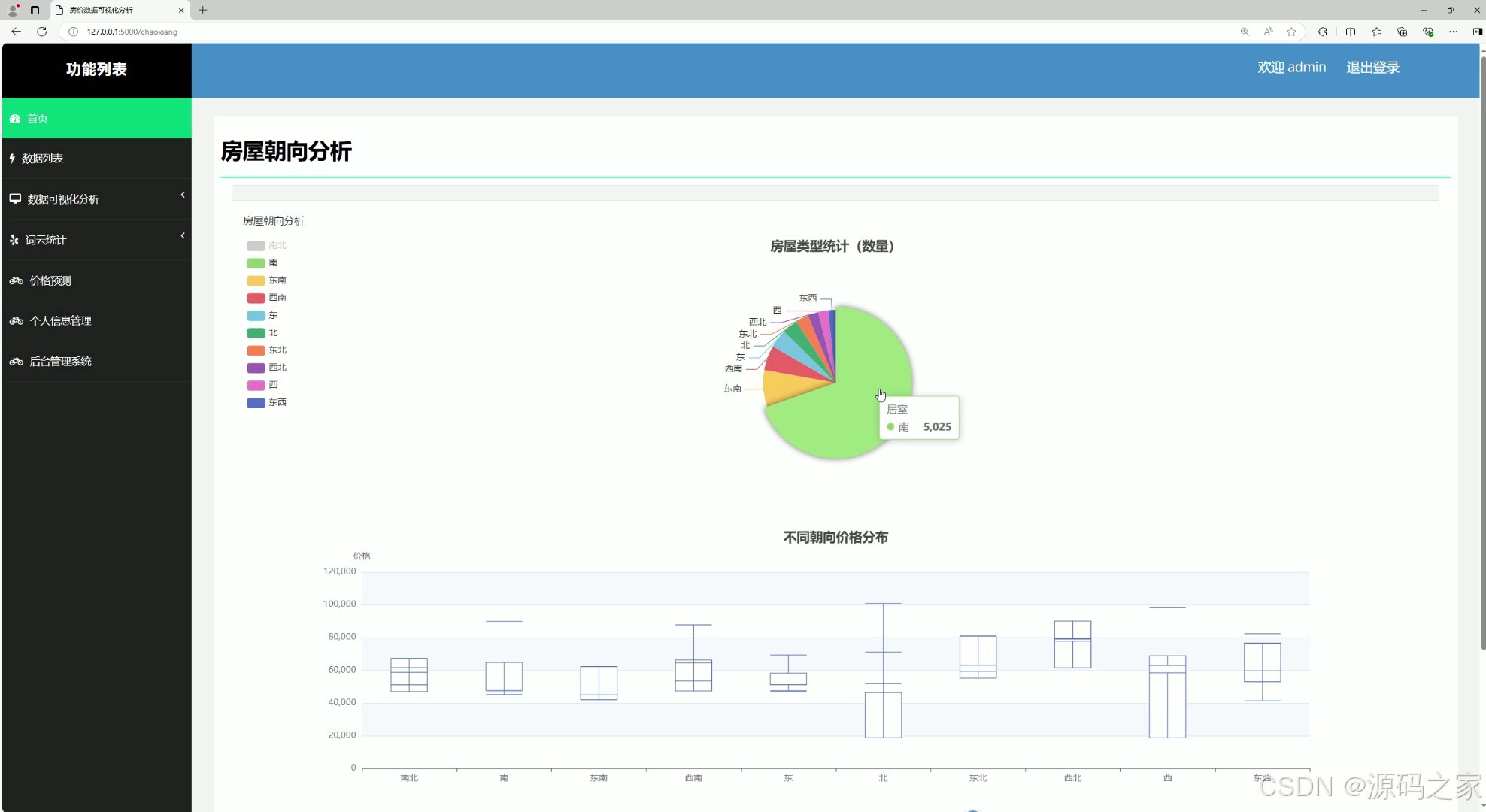
(5)房屋朝向分析
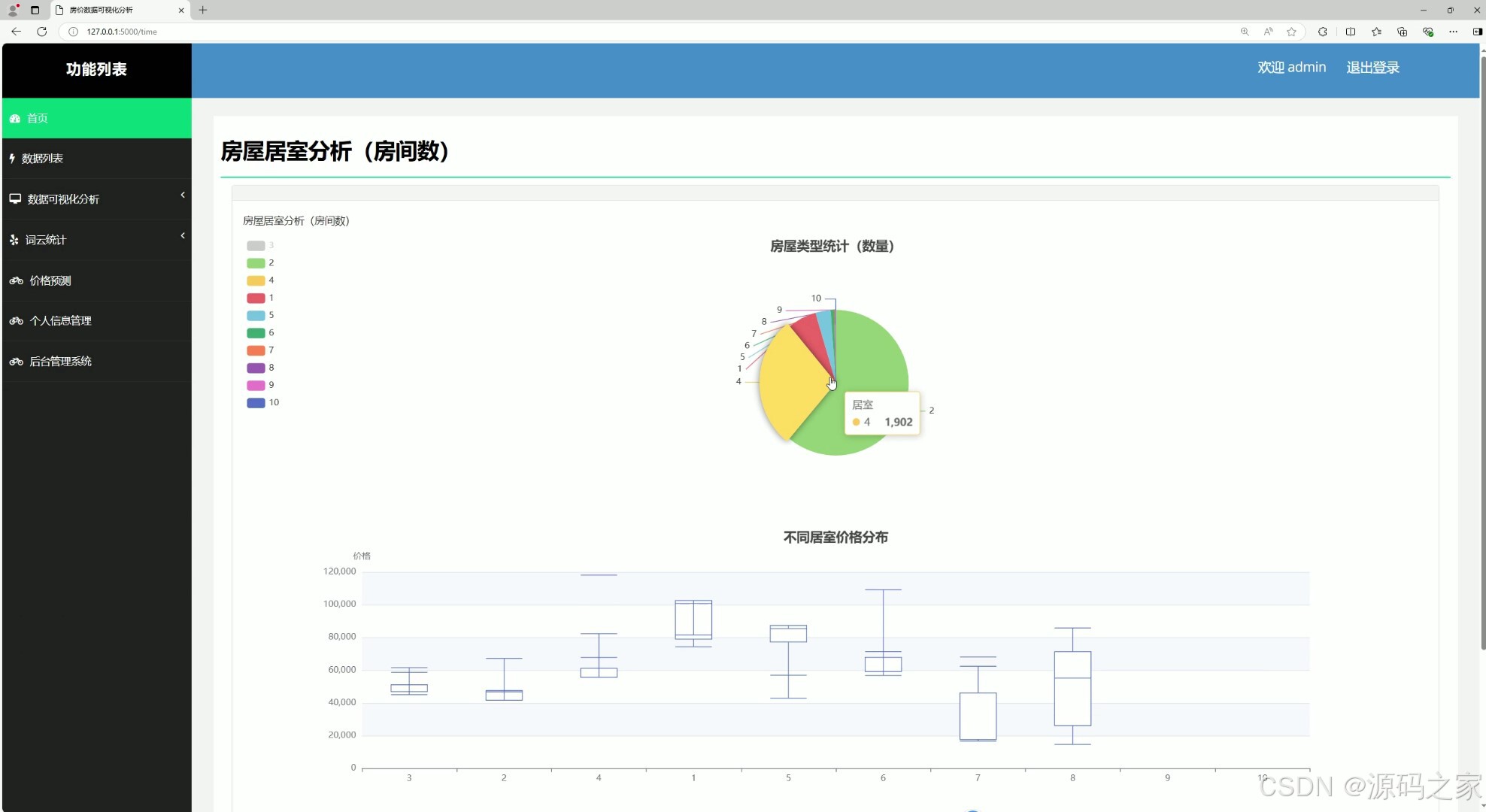
(6)房屋居室分析
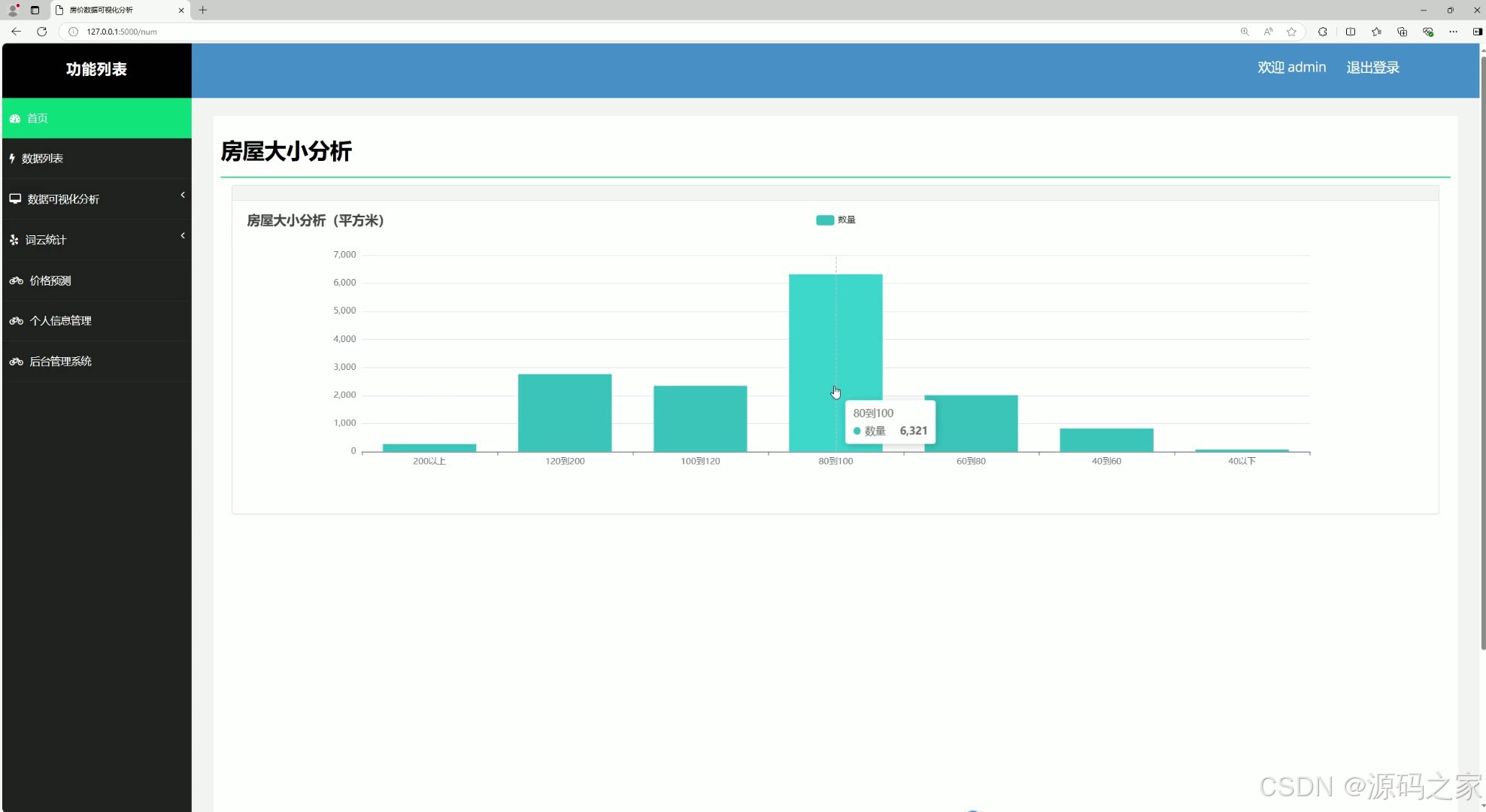
(7)房屋面积大小分析
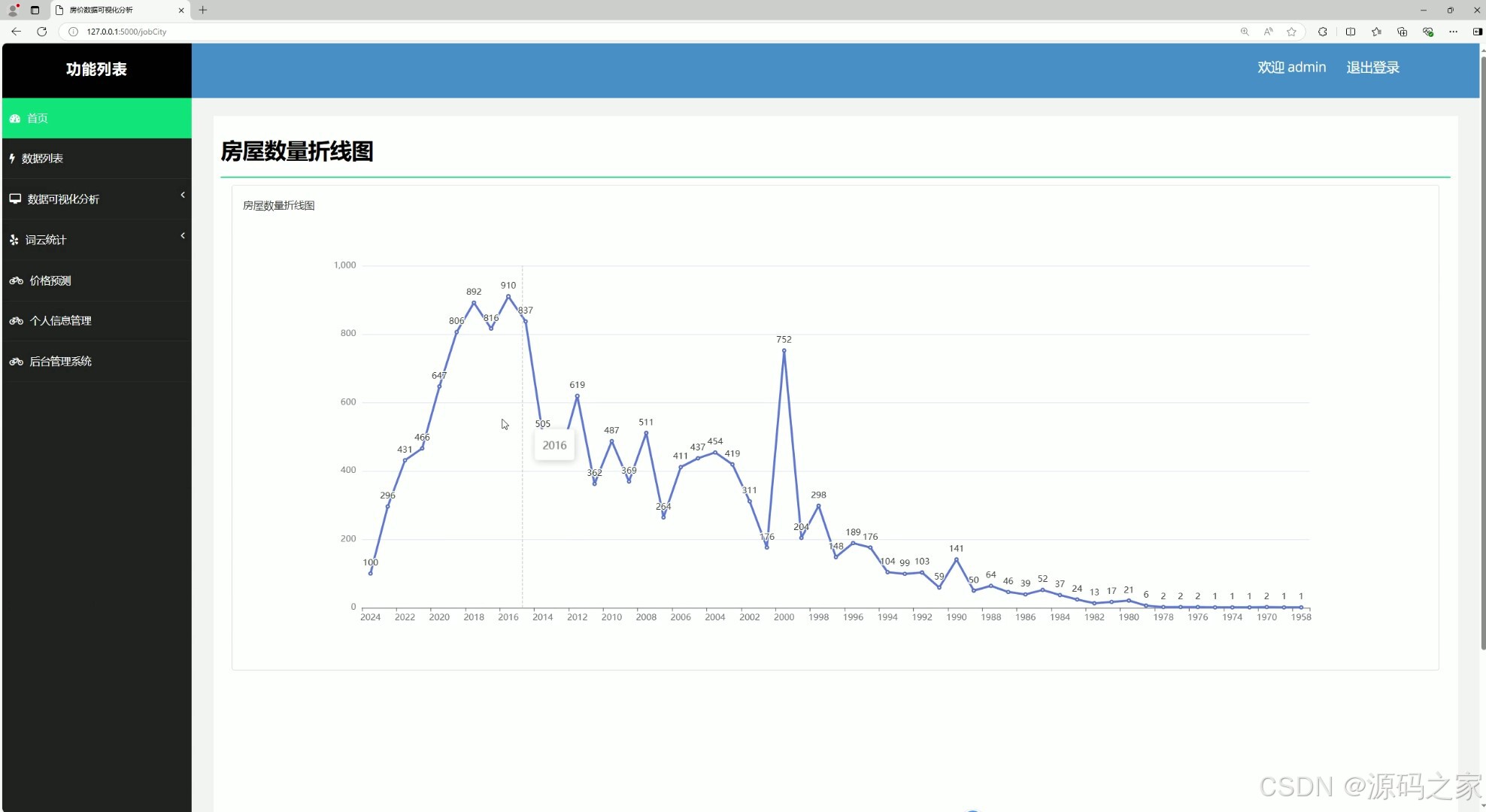
(8)房屋数量折线图分析
(9)房屋数据列表
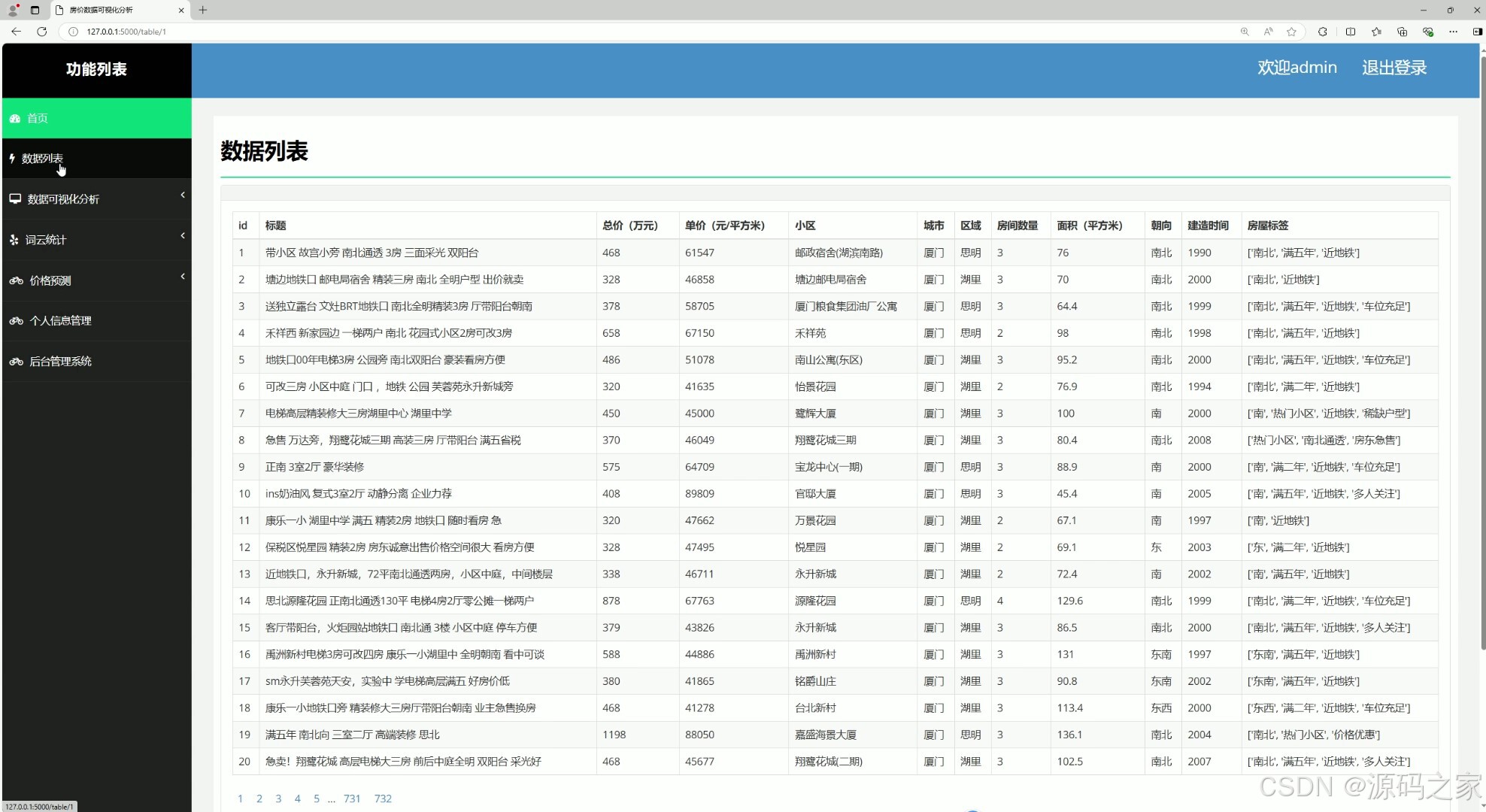
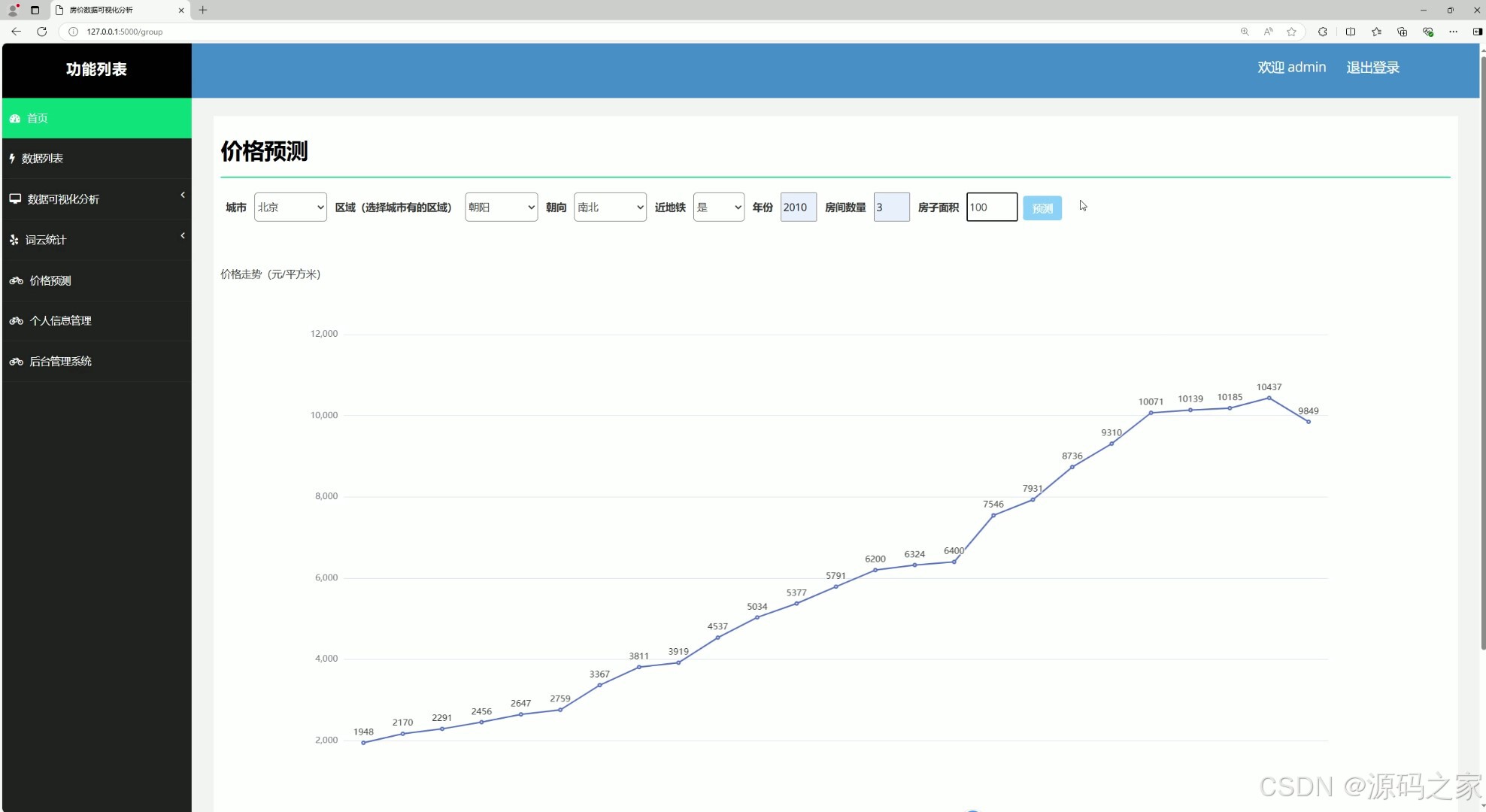
(10)房价预测
(11)房屋信息管理
(12)用户信息管理
(13)注册登录
(14)数据采集
3、项目说明
摘 要
随着房地产市场的快速发展,房价分析成为公众和决策者关注的焦点。本文提出了一个基于大数据技术的房价数据采集及可视化分析系统,该系统利用网络爬虫技术获取房价数据,并通过数据清洗和可视化技术,将影响房价的因素以直观的图表形式展现给用户。系统采用Python语言进行开发,结合了beautifulsoup框架进行数据采集、pandas库进行数据处理、MySQL数据库进行数据存储,以及pyecharts库进行数据可视化展示。通过对广州等地区的房价数据进行实证分析,验证了系统的有效性和实用性。与传统的数据采集和分析方法相比,本系统在数据量处理、实时性、用户交互等方面具有明显优势。
关键词: 大数据分析;房价数据采集;数据清洗;可视化技术;Python开发
本研究提出了一个基于Web的房地产价格预测系统,该系统通过集成机器学习算法和数据库技术,为用户提供了一个直观的房价预测工具。系统后端采用Flask框架处理HTTP请求,并通过决策树回归模型(DecisionTreeRegressor)对用户提交的房屋特征进行分析,从而预测房价。该模型通过历史房价数据进行训练,利用决策树的直观性和可解释性为用户提供准确的预测结果。系统前端则通过渲染模板将预测结果和相关的统计数据展示给用户,增强了用户的交互体验
房地产市场作为国民经济的重要支柱,其价格波动对经济发展、居民生活以及社会稳定都具有深远的影响。近年来,房价的快速上涨引起了社会各界的广泛关注,如何科学分析房价走势,为政府调控、投资者决策和居民购房提供参考,成为了一个迫切需要解决的问题。随着大数据技术的发展,海量的房地产交易数据为房价分析提供了新的视角和可能性。利用大数据技术,可以更全面地收集和分析房价数据,挖掘影响房价的深层次因素,从而为各方提供决策支持。
本研究旨在开发一个基于大数据技术的房价数据采集及可视化分析系统,通过自动化的数据采集、科学的数据处理方法和直观的可视化展示,提高房价分析的效率和准确性。系统的开发不仅能够为政府和市场参与者提供一个基于数据的房价分析工具,有助于制定更加合理的政策和市场策略,而且能够通过可视化技术提升市场透明度,帮助消费者更清晰地了解房价分布和趋势。此外,系统收集的大量房价数据为学术研究提供了丰富的数据资源,有助于深化对房地产市场规律的认识。同时,本研究实践了大数据技术在房地产市场的应用,为其他领域的大数据应用提供了参考。
系统的实时更新能力保证了用户能够获取最新的市场信息,而集成的预测模型则为房价走势提供了前瞻性分析。总体而言,本研究不仅具有重要的理论研究价值,而且在实际应用中具有广阔的前景,对于促进房地产市场的健康发展、提升市场分析工具的现代化水平具有重要作用。
4、核心代码
python
# 房屋数量折线图
@app.route("/jobCity")
def jobCity():
sql = 'select * from part1'
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
sj_list = []
zj_list = []
for item in list:
sj_list.append(item[0])
zj_list.append(item[1])
print(sj_list)
return render_template("jobCity.html", sj_list=sj_list, zj_list=zj_list, list=list)
# 指定区域房屋数量和区域均价
@app.route("/world")
def world():
sql = 'select * from part2 limit 20'
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
qy_list = []
sl_list = []
mean = []
for item in list:
qy_list.append(item[0])
sl_list.append(item[1])
mean.append(item[2])
return render_template("world.html", mean=mean, qy_list=qy_list, sl_list=sl_list, list=list)
# 房价随时间变化
@app.route("/price")
def price():
sql = 'select * from part3'
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
sj_list = []
mean = []
for item in list:
sj_list.append(item[0])
mean.append(float(item[1]))
print(mean)
return render_template("price.html", mean=mean, x_list=sj_list)
# 房屋大小分析 size
@app.route("/num")
def num():
# df = pd.read_csv('clean.csv')
df = pd.read_csv('clean.csv', encoding='utf-8')
# 删除id列和tags列,并在原地修改df
df.drop(columns=['id', 'tags'], inplace=True)
df['size'] = df['size'].astype(int)
res_dict = {
'200以上': 0,
'120到200': 0,
'100到120': 0,
'80到100': 0,
'60到80': 0,
'40到60': 0,
'40以下': 0
}
for item in list(df['size']):
if item > 200:
res_dict['200以上'] += 1
elif 200 > item >= 120:
res_dict['120到200'] += 1
elif 120 > item >= 100:
res_dict['100到120'] += 1
elif 100 > item >= 80:
res_dict['80到100'] += 1
elif 80 > item >= 60:
res_dict['60到80'] += 1
elif 60 > item >= 40:
res_dict['40到60'] += 1
elif item < 40:
res_dict['40以下'] += 1
x_list = []
y_list = []
for k, v in res_dict.items():
x_list.append(k)
y_list.append(v)
return render_template("num.html", x_list=x_list, y_list=y_list)
# 房型分析 home_num 房间数
@app.route("/time")
def time():
# df = pd.read_csv('clean.csv')
df = pd.read_csv('clean.csv', encoding='utf-8')
# 删除id列和tags列,并在原地修改df
df.drop(columns=['id', 'tags'], inplace=True)
v_list = list(df['home_num'].value_counts().sort_values(ascending=False))[:30]
k_list = list(df['home_num'].value_counts().sort_values(ascending=False).index)[:30]
result = []
for item in range(len(v_list)):
result.append((v_list[item], k_list[item]))
xiangxing = []
for n in k_list:
xiangxing.append(list(df[df['home_num'] == n]['price']))
return render_template("time.html", result=result, k_list=k_list, xiangxing=xiangxing)
# 朝向分析 chaoxiang
@app.route("/chaoxiang")
def chaoxiang():
# df = pd.read_csv('clean.csv')
df = pd.read_csv('clean.csv', encoding='utf-8')
# 删除id列和tags列,并在原地修改df
df.drop(columns=['id', 'tags'], inplace=True)
v_list = list(df['chaoxiang'].str.split(' ', expand=True)[0].value_counts())
k_list = list(df['chaoxiang'].str.split(' ', expand=True)[0].value_counts().index)
result = []
for item in range(len(v_list)):
result.append((v_list[item], k_list[item]))
xiangxing = []
for n in k_list:
xiangxing.append(list(df[df['chaoxiang'] == n]['price']))
return render_template("chaoxiang.html", result=result, k_list=k_list, xiangxing=xiangxing)
# 词云
@app.route("/worldCloud")
def worldCloud():
return render_template("worldCloud.html")
# 价格预测
@app.route("/group")
def group():
sql = 'select * from line'
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
qy_list = []
mean = []
for item in list:
qy_list.append(item[1])
mean.append(item[2])
return render_template("group.html", k_list=qy_list, p_list=mean)
# 房产推荐
@app.route("/rec")
def rec():
uname = session['uname']
user1 = User.query.filter(User.username == uname)[0]
sql = 'select * from rec where userid=' + str(user1.id)
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
f_list = []
for f in list:
f_list.append(Fangwu.query.filter(Fangwu.id == f[2]).first())
print(f_list)
return render_template("rec.html", k_list=f_list)
# 后台房产添加api
@app.route("/admin_zufangaddapi", methods=['POST'])
def admin_zufangaddapi():
fangwuid = request.values.get("fangwuid")
title = request.values.get("title")
price_count = request.values.get("price_count")
price = request.values.get("price")
xiaoqu = request.values.get("xiaoqu")
quyu = request.values.get("quyu")
home_num = request.values.get("home_num")
size = request.values.get("size")
chaoxiang = request.values.get("chaoxiang")
jianzao = request.values.get("jianzao")
tags = request.values.get("tags")
result = Fangwu.query.filter(Fangwu.title == title)
if result.count():
print('error')
return json.dumps({"id": False})
try:
fangwu = Fangwu(title=title, price_count=price_count, size=size, chaoxiang=chaoxiang, home_num=home_num,
price=price, xiaoqu=xiaoqu,
quyu=quyu, jianzao=jianzao, tags=tags)
db.session.add(fangwu)
db.session.commit()
return json.dumps({"id": True})
except:
return json.dumps({"id": False})
# 后台房产修改
@app.route("/admin_zufangedit")
def admin_zufangedit():
room_id = request.args.get("room_id")
fangwu1 = Fangwu.query.filter(Fangwu.id == room_id)[0]
print(room_id)
return render_template("admin/admin_zufangedit.html", fangwu1=fangwu1)
@app.route("/admin_zufangeditapi", methods=['POST'])
def admin_zufangeditapi():
fangwuid = request.values.get("fangwuid")
title = request.values.get("title")
price_count = request.values.get("price_count")
price = request.values.get("price")
xiaoqu = request.values.get("xiaoqu")
quyu = request.values.get("quyu")
home_num = request.values.get("home_num")
size = request.values.get("size")
chaoxiang = request.values.get("chaoxiang")
jianzao = request.values.get("jianzao")
tags = request.values.get("tags")
fangwuid = int(fangwuid)
try:
fangwu1 = Fangwu.query.get(fangwuid)
print(fangwu1.title)
fangwu1.title = title
fangwu1.price_count = price_count
fangwu1.price = price
fangwu1.xiaoqu = xiaoqu
fangwu1.quyu = quyu
fangwu1.home_num = home_num
fangwu1.size = size
fangwu1.chaoxiang = chaoxiang
fangwu1.tags = tags
fangwu1.jianzao = jianzao
db.session.add(fangwu1)
db.session.commit()
return json.dumps({"id": True})
except:
return json.dumps({"id": False})
# 后台房产删除
@app.route("/admin_zufangdel")
def admin_zufangdel():
room_id = request.values.get("room_id")
try:
fangwu = Fangwu.query.get(room_id)
db.session.delete(fangwu)
db.session.commit()
return json.dumps({"id": True})
except:
return json.dumps({"id": False})
# 价格预测
@app.route('/calculate', methods=['POST'])
def calculate():
sql = 'select * from line'
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
qy_list = []
mean = []
for item in list:
qy_list.append(item[1])
mean.append(item[2])
# 从前端接收数据
if request.form['city'] and request.form['area'] and request.form['chaoxiang'] and request.form['tags'] and \
request.form['yaer'] and request.form['num'] and request.form['size']:
city = int(request.form['city'])
area = int(request.form['area'])
chaoxiang = int(request.form['chaoxiang'])
tags = int(request.form['tags'])
year = int(request.form['yaer'])
num = int(request.form['num'])
size = int(request.form['size'])
# if area in [0, 1, 2, 3, 4, 5, 6]: # 区域字段
if 19 <= area <= 62:
# if area in [0, 1, 2, 3, 4, 5, 6]: # 区域字段
X = [[area, num, size, chaoxiang, year, tags, city]]
X = pd.DataFrame(X, columns=['quyu', 'home_num', 'size', 'chaoxiang', 'jianzao', 'tags', 'city'])
a = recommend(X)
result = f'预测结果为:{a} 元/每平方'
return render_template('group.html', result=result, k_list=qy_list, p_list=mean)
else:
result = f'区域选择错误'
return render_template('group.html', result=result, k_list=qy_list, p_list=mean)
else:
result = f'输入框不可为空'
return render_template('group.html', result=result, k_list=qy_list, p_list=mean)
# 决策树预测算法
def recommend(X):
dataX = pd.read_csv("./forecast/data.csv", index_col=0)
dataY = pd.read_csv("./forecast/target.csv", index_col=0)
trainX, testX, trainY, testY = train_test_split(dataX, dataY, test_size=0.3)
# 创建CART回归树
dtr = DecisionTreeRegressor(max_depth=13, min_impurity_decrease=0.02, min_samples_leaf=10)
# 拟合构造CART回归树
dtr.fit(trainX, trainY)
# 设置列名
X.columns = dataX.columns
# 将X的值转换为数值类型
X = X.astype(float)
a = float(str(dtr.predict(X))[1:-1])
a = '{:.2f}'.format(a)
return a
if __name__ == '__main__':
app.run(debug=True)
# db.create_all()🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻
