在Elasticsearch(简称ES)的分布式架构中,索引分片是支撑海量数据存储、高并发查询的核心基石。它将一个庞大的索引拆分为多个独立的"数据单元",实现数据的分布式存储与并行处理。本文将从源码角度出发,剖析索引分片的创建、分配、路由及迁移全流程,结合核心类与流程图,揭开ES分片机制的底层逻辑。
一、索引分片的核心概念与价值
在深入源码前,需先明确分片的核心定义:ES的索引分片分为主分片(Primary Shard) 和副本分片(Replica Shard),主分片负责数据的写入与核心处理,副本分片作为主分片的冗余备份,承担查询负载与故障恢复功能。分片的核心价值体现在三点:
-
分布式存储:突破单节点存储上限,将数据分散到集群多节点;
-
并行处理:查询请求可分散到多个分片并行执行,提升响应速度;
-
高可用:副本分片可在主分片故障时自动切换,保障服务稳定性。
ES分片机制的源码核心集中在org.elasticsearch.cluster.routing(路由管理)、org.elasticsearch.indices(索引服务)和org.elasticsearch.cluster.service(集群服务)包中,后续解析将围绕这些核心包展开。
二、索引分片的创建流程:从配置到实例化
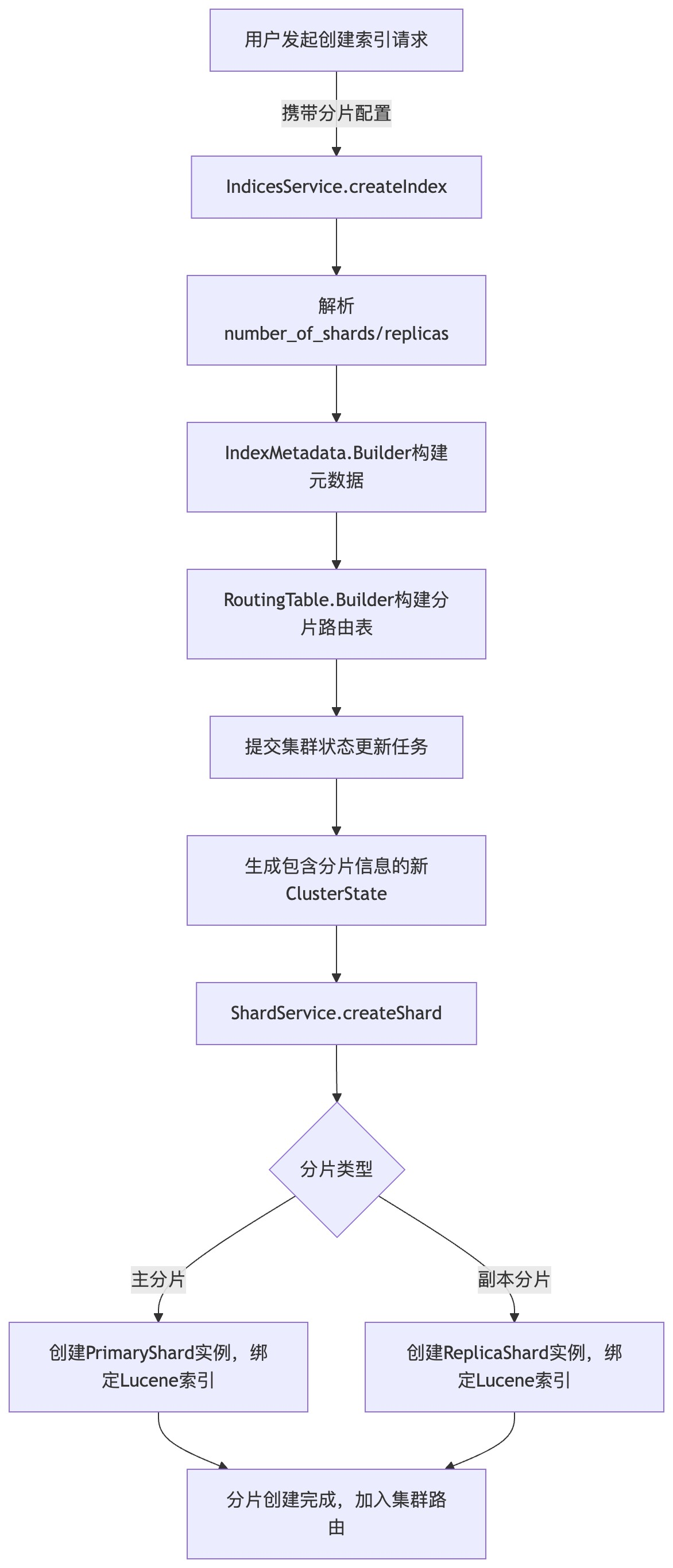
索引分片的创建始于索引创建请求,当用户执行PUT /index_name并指定分片配置(如number_of_shards)时,ES会完成分片的元数据构建与实例化。其核心流程分为"元数据定义"和"分片实例创建"两步。
2.1 核心触发入口:IndicesService
索引创建的核心服务类是IndicesService,其createIndex方法接收索引创建请求后,首先会解析请求中的分片配置:
// 简化版核心代码,来自IndicesService.java
public CreateIndexResponse createIndex(CreateIndexRequest request, ClusterState state) {
// 1. 解析分片配置:主分片数、副本数
int numberOfShards = request.numberOfShards();
int numberOfReplicas = request.numberOfReplicas();
// 2. 构建索引元数据,包含分片布局
IndexMetadata.Builder indexMetadataBuilder = IndexMetadata.builder(request.index())
.settings(settingsBuilder.put(IndexMetadata.SETTING_NUMBER_OF_SHARDS, numberOfShards)
.put(IndexMetadata.SETTING_NUMBER_OF_REPLICAS, numberOfReplicas));
// 3. 触发集群状态更新,生成分片信息
ClusterState newState = clusterService.submitStateUpdateTask(
"create-index [" + request.index() + "]",
ClusterStateTaskConfig.build(Priority.URGENT),
(currentState, task) -> {
// 构建分片路由表(ShardRoutingTable)
RoutingTable.Builder routingTableBuilder = RoutingTable.builder(currentState.routingTable());
routingTableBuilder.addAsNew(indexMetadataBuilder.build());
return ClusterState.builder(currentState)
.routingTable(routingTableBuilder.build())
.build();
}
);
// 4. 基于新集群状态创建分片实例
createShards(newState, indexMetadataBuilder.build());
return new CreateIndexResponse(true, request.index(), request.index());
}从代码可见,分片创建的核心是先通过RoutingTable.Builder构建分片路由表,再通过createShards方法实例化分片。
2.2 分片实例化:ShardService的核心作用
IndicesService的createShards方法会调用ShardService的createShard方法,完成分片的实际实例化。核心逻辑是为每个主分片创建PrimaryShard实例,为副本分片创建ReplicaShard实例,并绑定对应的Lucene索引(ES的分片本质是封装了Lucene索引)。
2.3 创建流程流程图
三、分片分配:分布式核心的路由策略
分片创建后,需要分配到集群的具体节点上,这一过程由ES的分片分配器(Allocator)负责,核心目标是"均衡负载、保障高可用"。分片分配的源码核心在org.elasticsearch.cluster.routing.allocation包中。
3.1 核心分配器:AllocationService
AllocationService是分片分配的总入口,其allocate方法接收当前集群状态(包含节点信息、分片状态),通过分配策略计算每个分片的目标节点。核心代码逻辑如下:
java
// 简化版核心代码,来自AllocationService.java
public ClusterState allocate(ClusterState clusterState, AllocationDeciders deciders) {
RoutingAllocation allocation = new RoutingAllocation(deciders, clusterState, null);
// 1. 计算需要分配的分片(未分配的主分片/副本分片)
List<ShardRouting> unassignedShards = allocation.routingNodes().unassignedShards();
// 2. 为每个未分配分片选择目标节点
for (ShardRouting shard : unassignedShards) {
if (shard.primary()) {
// 主分片分配:优先选择有数据副本的节点(如恢复场景),否则选负载低的节点
allocatePrimaryShard(allocation, shard);
} else {
// 副本分片分配:避免与主分片在同一节点,均衡分布
allocateReplicaShard(allocation, shard);
}
}
// 3. 生成新的路由表,更新集群状态
return ClusterState.builder(clusterState)
.routingTable(allocation.routingTable())
.build();
}3.2 分配策略:AllocationDeciders的规则校验
分片分配并非随意选择节点,而是需要通过AllocationDeciders的一系列规则校验,核心规则包括:
-
SameShardAllocationDecider:同一分片的主副分片不能在同一节点; -
DiskThresholdDecider:节点磁盘使用率超过阈值(默认85%)则不分配分片; -
ClusterRebalanceAllocationDecider:控制集群再平衡的频率,避免频繁迁移。
这些规则通过decide方法判断节点是否适合分配分片,只有通过所有规则校验的节点才会被纳入候选列表。
3.3 分配流程流程图

四、分片路由:文档与分片的"绑定逻辑"
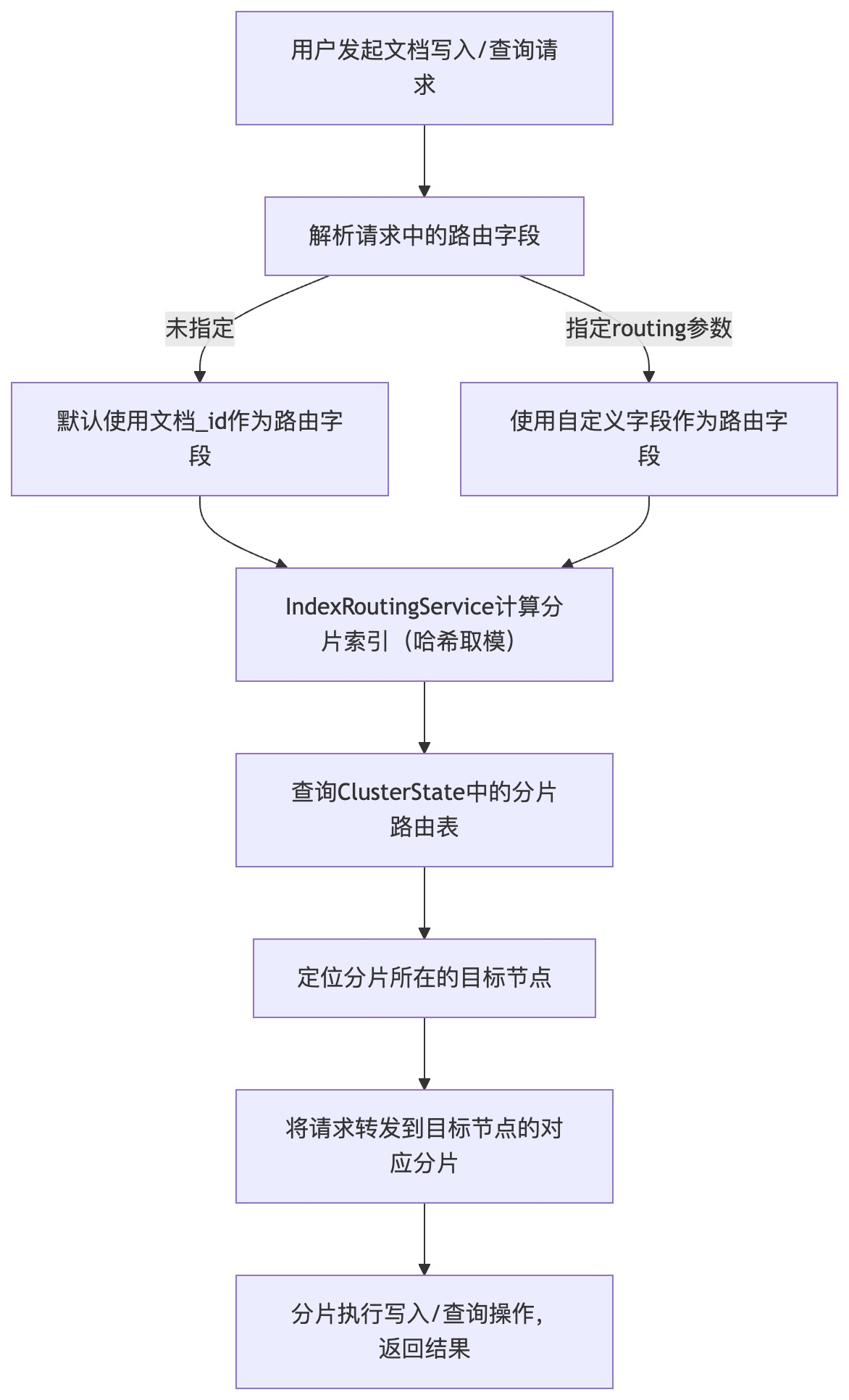
当用户写入或查询文档时,ES需要快速定位文档所在的分片,这一过程称为"分片路由"。路由的核心是通过哈希算法将文档与分片绑定,确保同一文档始终路由到固定分片(除非分片数变化)。
4.1 核心路由算法:哈希取模
ES默认使用文档的_id字段作为路由关键字,路由算法的源码实现位于IndexRoutingService中,核心公式为:
java
// 简化版路由算法,来自IndexRoutingService.java
public int route(String id, int numberOfShards) {
// 1. 对_id进行哈希计算(使用MurmurHash3算法)
long hash = MurmurHash3.hash128(id.getBytes(StandardCharsets.UTF_8))[0];
// 2. 取模得到分片索引(确保结果非负)
return Math.abs((int) (hash % numberOfShards));
}该算法的核心特点是"确定性"------相同的_id和分片数,必然得到相同的分片索引。若用户需要自定义路由字段,可通过routing参数指定,算法逻辑一致,仅将_id替换为自定义字段。
4.2 路由流程:从请求到分片定位
文档写入的路由流程为:用户发起写入请求→解析路由字段(默认_id)→计算分片索引→通过集群路由表找到分片所在节点→将请求转发到目标节点的对应分片。
需要注意的是,分片数一旦确定(索引创建后不可修改),路由算法的结果就会固定,因此ES不允许修改已创建索引的主分片数------否则会导致哈希取模结果变化,所有文档的路由位置失效。
4.3 路由流程流程图
五、分片迁移:集群动态平衡的保障
当集群节点发生变化(如新增节点、节点故障)时,ES需要通过分片迁移实现负载均衡,核心源码在org.elasticsearch.cluster.routing.allocation.allocator包中。
5.1 迁移触发条件
分片迁移由RebalanceService定时触发(默认每10秒检查一次),触发条件包括:
-
新增节点:集群存在空闲节点,需将部分分片迁移过去平衡负载;
-
节点故障:故障节点上的分片需迁移到健康节点;
-
负载不均:某节点分片数量远超其他节点(默认差值超过1)。
5.2 迁移核心逻辑:先同步再切换
分片迁移的核心是"数据一致性",主分片迁移和副本分片迁移逻辑略有不同,但均遵循"先同步数据,再切换状态"的原则:
-
副本分片迁移:直接在目标节点创建新副本,通过
RecoveryService同步主分片数据,同步完成后加入路由表; -
主分片迁移:先将主分片降级为副本,在目标节点创建新主分片,同步数据完成后,将新主分片激活,旧分片标记为删除。
六、核心总结与实践建议
ES索引分片的源码逻辑围绕"创建-分配-路由-迁移"的生命周期展开,核心依赖IndicesService(创建)、AllocationService(分配)、IndexRoutingService(路由)三大服务类,通过集群状态同步实现分布式协调。结合源码解析,给出以下实践建议:
-
分片数规划:主分片数需结合数据量和节点数设计(如3节点集群建议主分片数为3或6),避免分片过多导致资源浪费,或分片过少无法水平扩展;
-
副本配置:副本数建议为1-2个,过多会增加写入压力,过少则降低可用性;
-
路由优化:查询频繁的场景可自定义路由字段(如用户ID),实现数据按业务维度分片,减少跨分片查询开销;
-
迁移控制:通过调整
cluster.routing.rebalance.enable参数控制再平衡频率,避免业务高峰期分片迁移影响性能。