Transformer实战(8)------BERT模型详解与实现
-
- [0. 前言](#0. 前言)
- [1. BERT 模型介绍](#1. BERT 模型介绍)
-
- [1.1 BERT 语言模型预训练任务](#1.1 BERT 语言模型预训练任务)
- [2. 深入理解 BERT 语言模型](#2. 深入理解 BERT 语言模型)
- [3. 自编码语言模型训练](#3. 自编码语言模型训练)
-
- [3.1 文本分词](#3.1 文本分词)
- [3.2 构建 BERT 模型](#3.2 构建 BERT 模型)
- [3.3 实现预训练任务](#3.3 实现预训练任务)
- [3.4 模型训练](#3.4 模型训练)
- 相关链接
0. 前言
BERT (Bidirectional Encoder Representations from Transformers) 是 Google 在提出的预训练语言模型,它通过Transformer编码器结构和掩码语言模型 (Masked Language Model, MLM) 任务,实现了真正的双向上下文理解。在本节中,我们将学习如何从零开始训练自编码语言模型。训练过程包括模型的预训练和针对特定任务的训练。首先,学习 BERT (Bidirectional Encoder Representations from Transformer) 模型及其工作原理,然后,使用一个简单的小型语料库来训练语言模型。
1. BERT 模型介绍
BERT (Bidirectional Encoder Representations from Transformer) 是最早利用编码器 Transformer 堆栈,并对其进行修改以用于语言建模的自编码语言模型之一。BERT 架构是基于原始 Transformer 实现的多层编码器。Transformer 模型最初是为机器翻译任务设计的,但 BERT 的主要改进是利用 Transformer 的编码器部分来提供更好的语言建模。语言模型经过预训练后,能够提供对其训练语言的全局理解。
1.1 BERT 语言模型预训练任务
为了清楚地理解 BERT 使用的掩码语言模型 (Masked Language Model, MLM),我们将对其进行更详细的定义。MLM 是在输入(包含一些掩码词元的句子)上训练模型,并输出填补了掩码词元的完整句子。这种方法能够帮助模型在下游任务(例如分类)中取得更好的结果,因为如果模型能够进行完型填空测试(这是一种通过填空来评估语言理解的语言学测试),那么它就有了对语言本身的广泛理解。对于其他任务,模型已经通过语言建模进行了预训练,因此能够表现得更好。
以下是一个完形填空测试的例子:George Washington was the first President of the ___ States。预期 "United" 应该填入空白处。对于掩码语言模型,会应用同样的任务,要求模型填补掩码词元,但掩码词元是从句子中随机选择的。
BERT 训练的另一个任务是下句预测 (Next Sentence Prediction, NSP)。这个预训练任务确保 BERT 不仅学习所有词元 (token) 之间的关系(通过预测掩蔽词元),还可以理解两句话之间的关系。选择一对句子并将其提供给 BERT,并在它们之间插入一个 [SEP] 分隔词元。数据集中也会告知第二个句子是否紧接在第一个句子之后。
以下是一个 NSP 的例子:It is required that the reader fill in the blanks. Make sure to check the compatibility and support status before using them in your projects.。在这个例子中,模型需要输出预测结果为负相关,即这两句话之间没有关系。
这两种预训练任务使 BERT 能够理解语言本身。BERT 的词元嵌入为每个词元提供了一个上下文嵌入,上下文嵌入意味着每个词元的嵌入完全依赖于其周围的词元。与 word2vec 等模型不同,BERT 为每个词元嵌入提供了更丰富的信息。NSP 任务则使 BERT 能够为 [CLS] 词元提供更好的嵌入,[CLS] 提供了整个输入的信息,能够用于分类任务,并在预训练阶段学习输入的整体嵌入。下图显示了 BERT 模型的概览以及 BERT 模型的输入和输出:
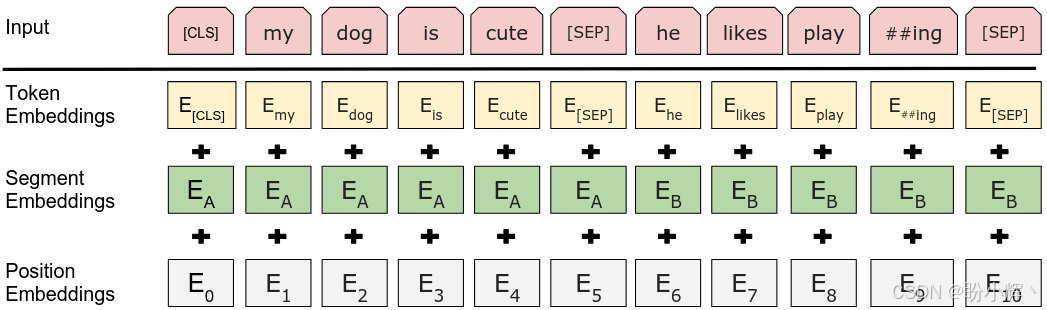
2. 深入理解 BERT 语言模型
分词器是许多自然语言处理 (Natural Language Processing, NLP) 应用程序中最重要的部分之一,在工作流程中起着关键作用。对于 BERT 来说,使用的是 WordPiece 分词技术。WordPiece、SentencePiece 和字节对编码 (Byte Pair Encoding, BPE) 是三种最常见的分词器,用于不同的 Transformer 架构。这些分词器的主要区别在于它们的合并策略、单元表示(字节、字符或子词单元)以及在分词方案和分割模式上的灵活性。这些算法各有优缺点,可以根据具体任务的需求来选择。BERT 或任何其他基于 Transformer 的架构使用子词分词的主要原因在于,这类分词器能够处理未知的词汇。
BERT 使用位置编码以确保模型能够获取到词元 (token) 的位置。BERT 和类似的模型使用的是非顺序操作,而传统模型,如基于长短期记忆 (Long Short Term Memory, LSTM) 和循环神经网络 (Recurrent Neural Network, RNN) 的模型,关注自然语言中的顺序问题。为了向 BERT 提供额外的位置信息,引入了位置编码技术。
BERT 的预训练为模型提供了语言层面的信息,但在实际应用中,在处理不同问题时,如序列分类、词元分类或问答任务,会使用模型输出的不同部分。
例如,在序列分类任务中,如情感分析或句子分类,原始 BERT 中建议使用最后一层的 [CLS] 嵌入作为输入。然而,其他模型则使用不同的技术进行分类,例如使用所有词元的平均嵌入、在最后一层上部署 LSTM 或者卷积神经网络 (Convolutional Neural Network, CNN)。序列分类时,可以使用最后的 [CLS] 嵌入作为任意分类器的输入,但最常用的做法是使用一个全连接层,输入大小等于最终词元嵌入的大小,输出大小等于类别的数量,并使用 softmax 激活函数。当输出是多标签且问题本身是多标签分类问题时,使用 sigmoid 激活函数也是另一种可选方法。
为了更详细地说明 BERT 的工作原理,下图展示了一个 NSP 任务的示例。需要注意的是,这里对分词进行了简化,以便更好的理解:
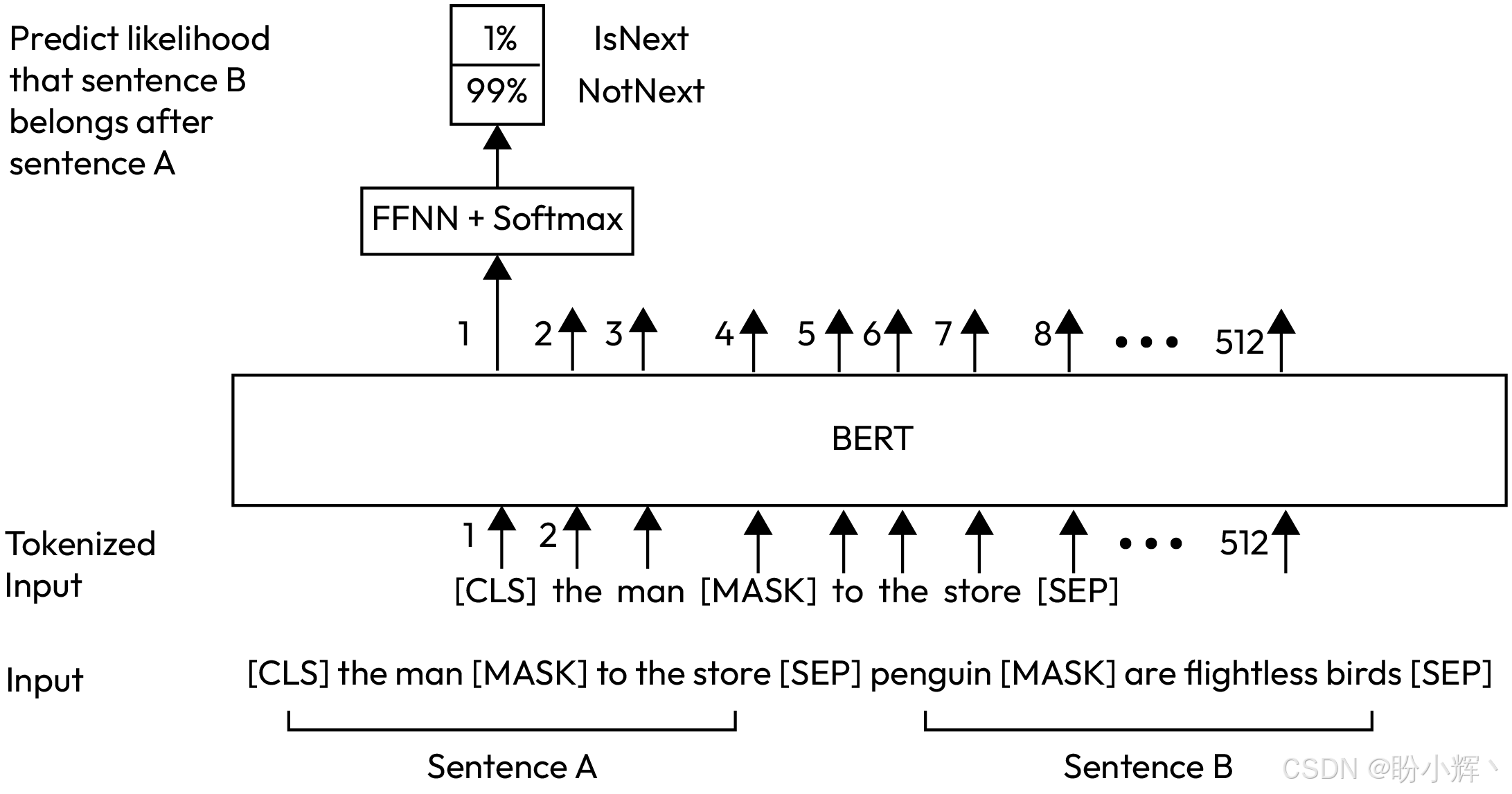
BERT 模型有多种不同的变体和设置。例如,输入的大小是可变的。在上述示例中,输入大小设置为 512,模型可以处理的最大序列长度为 512,但这个大小包括了特殊词元 [CLS] 和 [SEP],所以实际输入的序列长度为 510。另一方面,使用 WordPiece 作为分词器会生成子词词元,序列大小在分词之前可能会包含较少的单词,但经过分词后,大小会增加,因为当分词器遇到在预训练语料库中不常见的词汇时,会将其拆分为子词。
下图展示了 BERT 在不同任务中的应用示例。在命名实体识别 (Named Entity Recognition, NER) 任务中,会使用每个词元的输出,而不是 [CLS]。在问答任务中,问题和答案会通过 [SEP] 分隔符词元连接起来,答案会使用 "Start/End" 标注,并且通过最后一层的输出进行标注。在这种情况下,段落是问题所询问的上下文:
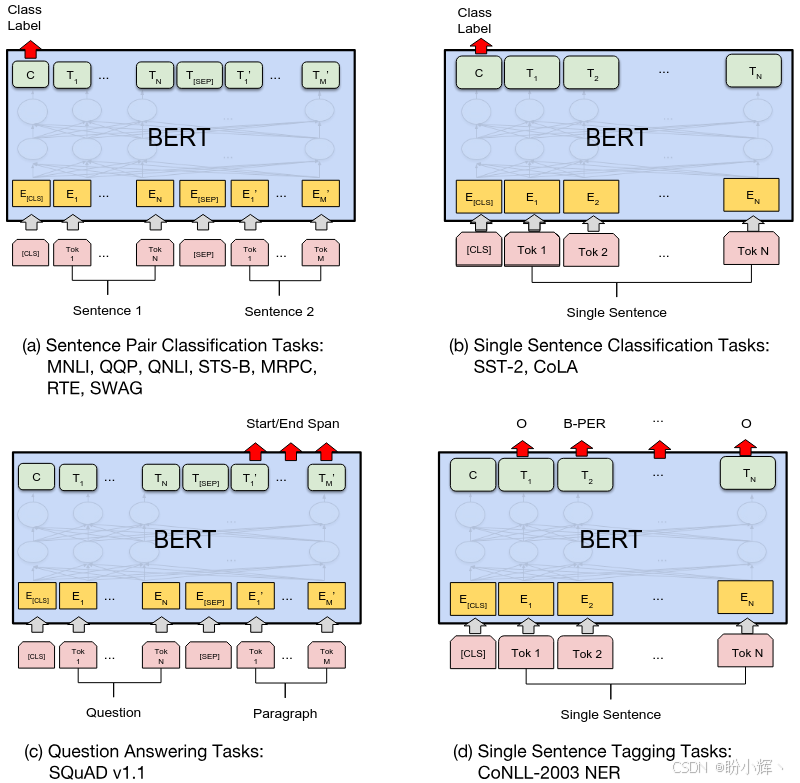
无论是在哪种任务中,BERT 最重要的能力是其对文本的上下文表示。BERT 能够成功的运用于各种任务中的关键原因是其基于 Transformer 编码器架构,Transformer 架构将输入表示为密集向量,这些向量可以通过非常简单的分类器轻松转换为输出。
位置编码在保持单词顺序方面至关重要,通过向词嵌入中添加非常小的数值,以确保它们在语义上接近其含义,同时也保持特定的顺序。
我们已经了解了 BERT 及其工作原理,掌握了 BERT 用于不同任务的详细信息,并了解了该架构中的重要机制。接下来,我们将学习如何 BERT 进行预训练,并在训练后进行使用。
3. 自编码语言模型训练
我们已经讨论了 BERT 的工作原理,接下来,将学习如何使用 PyTorch 训练 BERT 模型。
在开始之前,首先需要有训练数据用于语言建模。训练数据也称为语料库,通常是一个大规模的数据集。所选的语料库必须适合希望训练语言模型的使用场景,例如,如果希望为英语语言训练一个 BERT 模型,可以选择 Common Crawl 数据集。
在本节中,为了加快训练速度,我们使用一个较小的数据集,使用海明威的三部小说的文本文件:《老人与海》、《永别了,武器》和《丧钟为谁而鸣》,可以直接从GitHub 下载文件,下载后放在 ./files/ 文件夹中。
3.1 文本分词
(1) 首先,导入所需库:
python
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from tokenizers import Tokenizer
from tokenizers.models import WordPiece
from tokenizers.trainers import WordPieceTrainer
from tokenizers.pre_tokenizers import Whitespace
from tqdm import tqdm
import math(2) 读取海明威小说文本数据。读取过程与轻量级 GPT 模型一节相同:
python
def load_hemingway_novels(file_path="./files/"):
with open("files/OldManAndSea.txt","r", encoding='utf-8-sig') as f:
text=f.read()
# 加载原始文本并将其拆分为单个字符
text=list(text)
for i in range(len(text)):
if text[i]=='"':
if text[i+1]==' ' or text[i+1]=='\n':
# 如果直引号后跟一个空格或换行符,则将其更改为 " 引号
text[i]='"'
if text[i+1]!=' ' and text[i+1]!='\n':
# 否则,将其更改为 " 引号
text[i]='"' #C
if text[i]=="'":
if text[i-1]!=' ' and text[i-1]!='\n':
# 将直单引号转换为 ' 号
text[i]='''
# 将单个字符重新连接回文本
text="".join(text)
# 从第二本小说读取文本
with open("files/ToWhomTheBellTolls.txt","r", encoding='utf-8-sig') as f:
text1=f.read()
# 从第三本小说读取文本
with open("files/FarewellToArms.txt","r", encoding='utf-8-sig') as f:
text2=f.read()
# 合并三本小说的文本
text=text+" "+text1+" "+text2 #C
with open("files/ThreeNovels.txt","w",
encoding='utf-8-sig') as f:
# 保存合并后的文本
f.write(text)
text=text.lower().replace("\n", " ")
chars=set(text.lower())
# 识别所有标点符号
punctuations=[i for i in chars if i.isalpha()==False
and i.isdigit()==False]
print(punctuations)
for x in punctuations:
# 在标点符号周围插入空格
text=text.replace(f"{x}", f" {x} ")
return text(3) 训练 WordPiece 分词器:
python
def train_tokenizer(text, vocab_size=30000):
# 初始化分词器
tokenizer = Tokenizer(WordPiece(unk_token="[UNK]"))
tokenizer.pre_tokenizer = Whitespace()
# 配置训练器
trainer = WordPieceTrainer(
vocab_size=vocab_size,
special_tokens=["[UNK]", "[PAD]", "[CLS]", "[SEP]", "[MASK]"]
)
# 训练分词器
tokenizer.train_from_iterator([text], trainer=trainer)
return tokenizer
# 加载并预处理数据
text_data = load_hemingway_novels()
tokenizer = train_tokenizer(text_data)3.2 构建 BERT 模型
(1) 实现 BERT 的嵌入层,包括词元嵌入、位置嵌入和段嵌入:
python
class BertEmbedding(nn.Module):
def __init__(self, vocab_size, hidden_size, max_seq_length, layer_norm_eps=1e-12):
super(BertEmbedding, self).__init__()
self.token_embeddings = nn.Embedding(vocab_size, hidden_size)
self.position_embeddings = nn.Embedding(max_seq_length, hidden_size)
self.segment_embeddings = nn.Embedding(2, hidden_size) # 只有两个segment
self.LayerNorm = nn.LayerNorm(hidden_size, eps=layer_norm_eps)
self.dropout = nn.Dropout(0.1)
def forward(self, input_ids, segment_ids):
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
# 计算三种嵌入
words_embeddings = self.token_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
segment_embeddings = self.segment_embeddings(segment_ids)
# 合并嵌入并应用层归一化和dropout
embeddings = words_embeddings + position_embeddings + segment_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings(2) 实现 BERT 的自注意力机制:
python
class BertSelfAttention(nn.Module):
def __init__(self, hidden_size, num_attention_heads, attention_probs_dropout_prob=0.1):
super(BertSelfAttention, self).__init__()
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(hidden_size, self.all_head_size)
self.key = nn.Linear(hidden_size, self.all_head_size)
self.value = nn.Linear(hidden_size, self.all_head_size)
self.dropout = nn.Dropout(attention_probs_dropout_prob)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states, attention_mask=None):
# 线性变换
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
# 调整形状用于多头注意力
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# 计算注意力分数
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# 应用注意力掩码
if attention_mask is not None:
attention_scores = attention_scores + attention_mask
# 计算注意力概率
attention_probs = nn.Softmax(dim=-1)(attention_scores)
attention_probs = self.dropout(attention_probs)
# 应用注意力到value上
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
# 合并多头输出
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer(3) 实现 BERT 的 Transformer 层:
python
class BertLayer(nn.Module):
"""
功能:实现BERT的单个Transformer层
"""
def __init__(self, hidden_size, num_attention_heads, intermediate_size, hidden_dropout_prob=0.1):
super(BertLayer, self).__init__()
self.attention = BertSelfAttention(hidden_size, num_attention_heads)
self.attention_output = nn.Linear(hidden_size, hidden_size)
self.attention_layer_norm = nn.LayerNorm(hidden_size)
self.attention_dropout = nn.Dropout(hidden_dropout_prob)
self.intermediate = nn.Linear(hidden_size, intermediate_size)
self.intermediate_act = nn.GELU()
self.output = nn.Linear(intermediate_size, hidden_size)
self.output_layer_norm = nn.LayerNorm(hidden_size)
self.output_dropout = nn.Dropout(hidden_dropout_prob)
def forward(self, hidden_states, attention_mask=None):
# 自注意力子层
attention_output = self.attention(hidden_states, attention_mask)
attention_output = self.attention_output(attention_output)
attention_output = self.attention_dropout(attention_output)
attention_output = self.attention_layer_norm(attention_output + hidden_states)
# 前馈网络子层
intermediate_output = self.intermediate(attention_output)
intermediate_output = self.intermediate_act(intermediate_output)
layer_output = self.output(intermediate_output)
layer_output = self.output_dropout(layer_output)
layer_output = self.output_layer_norm(layer_output + attention_output)
return layer_output(4) 实现完整的 BERT 模型:
python
class BertModel(nn.Module):
def __init__(self, vocab_size, hidden_size=768, num_hidden_layers=12,
num_attention_heads=12, intermediate_size=3072,
max_seq_length=512, hidden_dropout_prob=0.1):
super(BertModel, self).__init__()
self.embeddings = BertEmbedding(vocab_size, hidden_size, max_seq_length)
self.layers = nn.ModuleList([
BertLayer(hidden_size, num_attention_heads, intermediate_size, hidden_dropout_prob)
for _ in range(num_hidden_layers)
])
def forward(self, input_ids, segment_ids, attention_mask=None):
# 获取嵌入表示
embedding_output = self.embeddings(input_ids, segment_ids)
# 处理注意力掩码
if attention_mask is not None:
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
attention_mask = (1.0 - attention_mask) * -10000.0
# 通过所有Transformer层
hidden_states = embedding_output
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
return hidden_states3.3 实现预训练任务
(1) 定义 BERT 预训练任务的输出头 (包括 MLM 和 NSP):
python
class BertPreTrainingHeads(nn.Module):
def __init__(self, hidden_size, vocab_size):
super(BertPreTrainingHeads, self).__init__()
# MLM头
self.mlm_dense = nn.Linear(hidden_size, hidden_size)
self.mlm_activation = nn.GELU()
self.mlm_layer_norm = nn.LayerNorm(hidden_size)
self.mlm_decoder = nn.Linear(hidden_size, vocab_size)
# NSP头
self.nsp_dense = nn.Linear(hidden_size, hidden_size)
self.nsp_activation = nn.Tanh()
self.nsp_classifier = nn.Linear(hidden_size, 2)
def forward(self, sequence_output, pooled_output):
# MLM预测
mlm_output = self.mlm_dense(sequence_output)
mlm_output = self.mlm_activation(mlm_output)
mlm_output = self.mlm_layer_norm(mlm_output)
mlm_scores = self.mlm_decoder(mlm_output)
# NSP预测
nsp_output = self.nsp_dense(pooled_output)
nsp_output = self.nsp_activation(nsp_output)
nsp_scores = self.nsp_classifier(nsp_output)
return mlm_scores, nsp_scores(2) 定义用于预训练的完整 BERT 模型:
python
class BertForPreTraining(nn.Module):
def __init__(self, vocab_size, hidden_size=768, num_hidden_layers=12,
num_attention_heads=12, intermediate_size=3072,
max_seq_length=512):
super(BertForPreTraining, self).__init__()
self.bert = BertModel(vocab_size, hidden_size, num_hidden_layers,
num_attention_heads, intermediate_size, max_seq_length)
self.cls = BertPreTrainingHeads(hidden_size, vocab_size)
# 用于池化输出的线性层
self.pooler = nn.Linear(hidden_size, hidden_size)
self.pooler_activation = nn.Tanh()
def forward(self, input_ids, segment_ids, attention_mask=None):
# 获取BERT输出
sequence_output = self.bert(input_ids, segment_ids, attention_mask)
# 池化输出(取第一个token的表示)
pooled_output = self.pooler(sequence_output[:, 0])
pooled_output = self.pooler_activation(pooled_output)
# 预训练任务预测
mlm_scores, nsp_scores = self.cls(sequence_output, pooled_output)
return mlm_scores, nsp_scores3.4 模型训练
(1) 创建 BERT 预训练数据集:
python
class BertDataset(Dataset):
def __init__(self, text, tokenizer, max_seq_length=128, mlm_probability=0.15):
self.tokenizer = tokenizer
self.max_seq_length = max_seq_length
self.mlm_probability = mlm_probability
self.vocab_size = tokenizer.get_vocab_size()
# 将文本分割成句子
sentences = text.split('. ')
self.sentences = [s.strip() for s in sentences if len(s.strip()) > 0]
def __len__(self):
return len(self.sentences) - 1
def random_word(self, tokens):
output_label = []
output_tokens = []
for i, token in enumerate(tokens):
prob = torch.rand(1)
# 15%的概率进行掩码
if prob < self.mlm_probability:
prob /= self.mlm_probability
# 80%用[MASK]替换
if prob < 0.8:
output_tokens.append(self.tokenizer.token_to_id("[MASK]"))
# 10%用随机token替换
elif prob < 0.9:
output_tokens.append(torch.randint(5, self.vocab_size-1, (1,)).item())
# 10%保持不变
else:
output_tokens.append(token)
output_label.append(token)
else:
output_tokens.append(token)
output_label.append(-100) # 忽略的token
return output_tokens, output_label
def __getitem__(self, idx):
# 50%的概率使用连续句子,50%的概率使用随机句子
if torch.rand(1) > 0.5:
# 连续句子
is_next = 1
sentence_a = self.sentences[idx]
sentence_b = self.sentences[idx + 1]
else:
# 不连续句子
is_next = 0
sentence_a = self.sentences[idx]
random_idx = torch.randint(0, len(self.sentences)-1, (1,)).item()
while random_idx == idx:
random_idx = torch.randint(0, len(self.sentences)-1, (1,)).item()
sentence_b = self.sentences[random_idx]
# 编码句子
tokens_a = self.tokenizer.encode(sentence_a).ids
tokens_b = self.tokenizer.encode(sentence_b).ids
# 截断和填充
self._truncate_seq_pair(tokens_a, tokens_b, self.max_seq_length - 3)
# 构建输入序列:[CLS] A [SEP] B [SEP]
tokens = [self.tokenizer.token_to_id("[CLS]")] + tokens_a + \
[self.tokenizer.token_to_id("[SEP]")] + tokens_b + \
[self.tokenizer.token_to_id("[SEP]")]
segment_ids = [0] * (len(tokens_a) + 2) + [1] * (len(tokens_b) + 1)
# 应用MLM
tokens, mlm_labels = self.random_word(tokens)
# 填充到最大长度
padding_length = self.max_seq_length - len(tokens)
tokens = tokens + [self.tokenizer.token_to_id("[PAD]")] * padding_length
segment_ids = segment_ids + [0] * padding_length
mlm_labels = mlm_labels + [-100] * padding_length
# 创建注意力掩码
attention_mask = [1 if token != self.tokenizer.token_to_id("[PAD]") else 0 for token in tokens]
return {
'input_ids': torch.tensor(tokens, dtype=torch.long),
'segment_ids': torch.tensor(segment_ids, dtype=torch.long),
'attention_mask': torch.tensor(attention_mask, dtype=torch.long),
'mlm_labels': torch.tensor(mlm_labels, dtype=torch.long),
'is_next': torch.tensor(is_next, dtype=torch.long)
}
def _truncate_seq_pair(self, tokens_a, tokens_b, max_length):
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_length:
break
if len(tokens_a) > len(tokens_b):
tokens_a.pop()
else:
tokens_b.pop()(2) 定义模型训练过程,并执行模型训练:
python
def train_bert():
# 超参数设置
max_seq_length = 128
batch_size = 64
learning_rate = 1e-4
num_epochs = 50
hidden_size = 256 # 为了训练效率使用较小的模型
# 准备数据
dataset = BertDataset(text_data, tokenizer, max_seq_length)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 初始化模型
vocab_size = tokenizer.get_vocab_size()
model = BertForPreTraining(
vocab_size=vocab_size,
hidden_size=hidden_size,
num_hidden_layers=6, # 使用6层
num_attention_heads=8,
intermediate_size=512,
max_seq_length=max_seq_length
)
# 优化器和损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
mlm_criterion = nn.CrossEntropyLoss(ignore_index=-100)
nsp_criterion = nn.CrossEntropyLoss()
# 训练循环
model.train()
for epoch in range(num_epochs):
total_loss = 0
mlm_loss_sum = 0
nsp_loss_sum = 0
progress_bar = tqdm(dataloader, desc=f'Epoch {epoch+1}/{num_epochs}')
for batch in progress_bar:
# 获取批次数据
input_ids = batch['input_ids']
segment_ids = batch['segment_ids']
attention_mask = batch['attention_mask']
mlm_labels = batch['mlm_labels']
is_next = batch['is_next']
# 前向传播
mlm_scores, nsp_scores = model(input_ids, segment_ids, attention_mask)
# 计算损失
mlm_loss = mlm_criterion(
mlm_scores.view(-1, vocab_size),
mlm_labels.view(-1)
)
nsp_loss = nsp_criterion(nsp_scores, is_next)
loss = mlm_loss + nsp_loss
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计信息
total_loss += loss.item()
mlm_loss_sum += mlm_loss.item()
nsp_loss_sum += nsp_loss.item()
progress_bar.set_postfix({
'Total Loss': f'{loss.item():.4f}',
'MLM Loss': f'{mlm_loss.item():.4f}',
'NSP Loss': f'{nsp_loss.item():.4f}'
})
# 打印epoch统计信息
avg_loss = total_loss / len(dataloader)
avg_mlm_loss = mlm_loss_sum / len(dataloader)
avg_nsp_loss = nsp_loss_sum / len(dataloader)
print(f'Epoch {epoch+1}: Average Loss: {avg_loss:.4f}, '
f'MLM Loss: {avg_mlm_loss:.4f}, NSP Loss: {avg_nsp_loss:.4f}')
# 保存模型
torch.save(model.state_dict(), 'bert_hemingway.pth')
print("模型训练完成并已保存!")
return model
trained_model = train_bert()(3) 模型训练完成后,可以使用 BERT 模型预测被掩码的词语:
python
def predict_masked_sentence(model, tokenizer, text, mask_position):
model.eval()
# 准备输入
tokens = tokenizer.encode(text).ids
original_token = tokens[mask_position]
tokens[mask_position] = tokenizer.token_to_id("[MASK]")
# 添加特殊token
input_ids = [tokenizer.token_to_id("[CLS]")] + tokens + [tokenizer.token_to_id("[SEP]")]
segment_ids = [0] * len(input_ids)
# 转换为tensor
input_ids = torch.tensor([input_ids], dtype=torch.long)
segment_ids = torch.tensor([segment_ids], dtype=torch.long)
# 预测
with torch.no_grad():
mlm_scores, _ = model(input_ids, segment_ids)
# 获取预测结果
predicted_token_id = mlm_scores[0, mask_position + 1].argmax().item()
predicted_token = tokenizer.id_to_token(predicted_token_id)
original_token_str = tokenizer.id_to_token(original_token)
print(f"原文: {text}")
print(f"掩码位置 {mask_position}: 原始词 '{original_token_str}' -> 预测词 '{predicted_token}'")
# 使用示例
sample_text = "The old man was thin and gaunt with deep wrinkles in the back of his neck"
predict_masked_sentence(trained_model, tokenizer, sample_text, mask_position=2)输出结果如下所示:
shell
原文: The old man was thin and gaunt with deep wrinkles in the back of his neck
掩码位置 2: 原始词 'man' -> 预测词 'man'本节完整介绍了 BERT 的核心原理和实现方法。在实际应用中,可以使用更大的语料库和更长的训练时间来获得更好的效果。
相关链接
生成模型实战 | 生成模型(Generative Model)基础
生成模型实战 | Transformer详解与实现
生成模型实战 | GPT-2(Generative Pretrained Transformer 2)详解与实现
生成模型实战 | 轻量级GPT模型