【地址空间】目录
- 前言:
-
- [1. 我们都被骗了,嘤嘤嘤!](#1. 我们都被骗了,嘤嘤嘤!)
- [2. 具体如何实现虚拟地址<->物理地址的映射?](#2. 具体如何实现虚拟地址<->物理地址的映射?)
- [3. 被骗的真相?](#3. 被骗的真相?)
- [4. 写实拷贝本质是什么?](#4. 写实拷贝本质是什么?)
- [5. 进一步探究虚拟地址是什么?](#5. 进一步探究虚拟地址是什么?)
- [6. mm_struct到底长什么样?](#6. mm_struct到底长什么样?)
- [7. 建立映射关系的过程是什么样的?](#7. 建立映射关系的过程是什么样的?)
- [8. 为什么需要页表?](#8. 为什么需要页表?)
- [9. 如何理解缺页中断?](#9. 如何理解缺页中断?)
- [10. vm_area_structs是什么鬼啊?](#10. vm_area_structs是什么鬼啊?)

往期《Linux系统编程》回顾:/------------ 入门基础 ------------/
【Linux的前世今生】
【Linux的环境搭建】
【Linux基础 理论+命令】(上)
【Linux基础 理论+命令】(下)
【权限管理】/------------ 开发工具 ------------/
【软件包管理器 + 代码编辑器】
【编译器 + 自动化构建器】
【版本控制器 + 调试器】
【实战:倒计时 + 进度条】/------------ 系统导论 ------------/
【冯诺依曼体系结构 + 操作系统基本概述】/------------ 进程基础 ------------/
【进程入门】
【进程状态】
【进程优先级】
【进程切换 + 进程调度】/------------ 进程环境 ------------/
【环境变量】
前言:
hi~,小伙伴们大家好呀!(ノ≧∀≦)ノ
哎怎么没人了(⊙o⊙),难道......,按照约定鼠鼠如期而至了,不知道知道这个约定的小伙们都还在吗?(´• ω •̥`)❄️
从年初到年末,一路上小伙伴们换了一批又一批,不知道鼠鼠能不能坚持到最后啊!或许离别就在这个月,谁也说不定嘛📅⛄......(っ- ‸ -- ς)
| ----- 2025 年 12 月 1 日(十月十二)周一,最后一月的第一天 |
|---|
好了,我们开始学习今天的内容吧:进程学习中最关键的 "抽象魔法":【地址空间】 !(〜 ̄▽ ̄)〜🔮
地址空间:不是物理内存本身,而是操作系统给进程画的 "虚拟内存地图",💡 进程学习的质变装,这将会使我们重新认识进程🤯,以及颠覆我们之前对地址的认知,从底层通透程序运行的核心逻辑,后期学习的坚实保障🛡️
1. 我们都被骗了,嘤嘤嘤!

现在鼠鼠想问问你上面的程序打印的内容是内存吗?
难道不是吗?他还真不是!啊为什么啊?
为什么会这样?我们可以从两个关键角度来想:
首先,要是这些 "地址" 直接对应真实内存,意味着:
- 每个进程的内存都得按 "代码段→数据段→堆→栈" 这种固定、规律的方式排布。
- 可系统里同时运行着成百上千个进程(比如:你的浏览器、终端、后台服务),每个进程需要的内存大小、功能模块都不一样,怎么可能保证所有进程都 "乖乖地" 按同一种规律占用真实内存?
- 一旦两个进程的 "规律排布" 重叠,就会出现内存冲突,轻则程序崩溃,重则整个系统出问题。
其次,更核心的点在于:
- 其实我们上面说的是"程序地址空间"(比如:C/C++ 里学的代码段、数据段划分),其实是个 "语言层的概念"
- 在"系统层的概念"中它又被称为是:进程地址空间(也叫虚拟地址空间),正如其名和真实物理内存完全是两回事
简单来说:
- 操作系统会给每个进程分配一个独立的
"虚拟地址空间",这个空间里的地址(就是我们代码里打印的&gval、&heap_mem这类值)都是 "假的",是操作系统给进程画的"内存地图"(切记只是个地图罢了)- 当进程要访问某个虚拟地址时,操作系统会通过
"内存管理单元(MMU)"把虚拟地址翻译成真实的物理内存地址,再去操作真实内存
c
#include <stdio.h>
#include <stdlib.h> // 提供malloc等内存分配函数的声明
//1.未初始化的全局变量,会被存放在"BSS段"
int g_unval;
//2.已初始化的全局变量,会被存放在"数据段"
int g_val = 100;
int main(int argc, char* argv[], char* env[])
{
//3.定义一个字符串常量,存储在"只读数据段"
const char* str = "helloworld";
//4.定义静态局部变量,存储在"数据段"(与全局变量同区域)
static int test = 10;
//5.在堆上分配内存,返回的地址属于堆区域
char* heap_mem = (char*)malloc(10);
char* heap_mem1 = (char*)malloc(10);
char* heap_mem2 = (char*)malloc(10);
char* heap_mem3 = (char*)malloc(10);
//6.打印main函数代码的地址(代码段)
printf("code addr: %p\n", main);
//7.打印已初始化全局变量g_val的地址(数据段)
printf("init global addr: %p\n", &g_val);
//8.打印未初始化全局变量g_unval的地址(BSS段)
printf("uninit global addr: %p\n", &g_unval);
//9.打印堆上分配的内存地址(堆区域)
printf("heap addr: %p\n", heap_mem);
printf("heap addr: %p\n", heap_mem1);
printf("heap addr: %p\n", heap_mem2);
printf("heap addr: %p\n", heap_mem3);
//10.打印静态局部变量test的地址(数据段)
printf("test static addr: %p\n", &test);
//11.打印栈上变量heap_mem的地址(栈区域)
printf("stack addr: %p\n", &heap_mem);
printf("stack addr: %p\n", &heap_mem1);
printf("stack addr: %p\n", &heap_mem2);
printf("stack addr: %p\n", &heap_mem3);
//12.打印字符串常量str的地址(只读数据段)
printf("read only string addr: %p\n", str);
//13.遍历命令行参数数组,打印每个参数的地址
for (int i = 0; i < argc; i++)
{
printf("argv[%d]: %p\n", i, argv[i]);
}
//14.遍历环境变量数组,打印每个环境变量的地址(环境变量通常在栈或特定区域)
for (int i = 0; env[i]; i++)
{
printf("env[%d]: %p\n", i, env[i]);
}
//15.程序正常退出,返回0
return 0;
}

什么你说你还是不信,好吧,那鼠鼠就只能用实时说话了!
在之前那段
fork()创建子进程的代码里,有个非常关键的现象:
- 父进程和子进程打印的全局变量
gval的地址完全相同 (比如都是0x556b8f7fc010)- 但实际运行时,父进程读取的
gval始终是初始值 100,而子进程的gval却在不断自增(101、102......105)
这就很矛盾了 ------ 如果这个地址是真实的物理内存地址,那同一个内存地址里的数据怎么可能同时是两个不同的值?你可别狡辩,遇事不决,量子力学哦!
所以:从这个事实我们可以大胆推断:
- 这些地址绝对不是真实的物理内存地址
- 它们其实是操作系统给每个进程分配的虚拟地址------ 父进程和子进程看到的 "相同地址",只是虚拟地址空间里的 "表象",操作系统会通过内存管理单元(MMU)把这两个 "相同的虚拟地址" 映射到物理内存中完全不同的位置
这也意味着:我们在 C/C++ 中用到的所有指针地址,从本质上来说都是虚拟地址。
操作系统通过这种
"虚拟地址 + 映射"的机制:
- 既保证了每个进程能 "独立" 使用连续的地址空间(方便程序开发)
- 又避免了多进程直接操作物理内存导致的冲突(保证系统稳定)
这种虚拟地址的设计,正是现代操作系统内存管理的核心智慧 ------
让程序以为自己独占内存,实则由系统在背后巧妙地调度和隔离
2. 具体如何实现虚拟地址<->物理地址的映射?
实际上,当你的代码被编译后,程序中的变量名在严格意义上大多已经 "消失" 了 ------ 它们要么
被转化为具体的内存地址,要么被编译成特定的寻址方式这意味着:当我们在程序中访问栈上或堆上的数据时,本质上都是通过地址进行操作,这个层面的内存访问属于 "用户空间" 的范畴。
现代操作系统会为 每个进程分配一个独立的虚拟地址空间,这是进程 "看到" 的内存全貌。
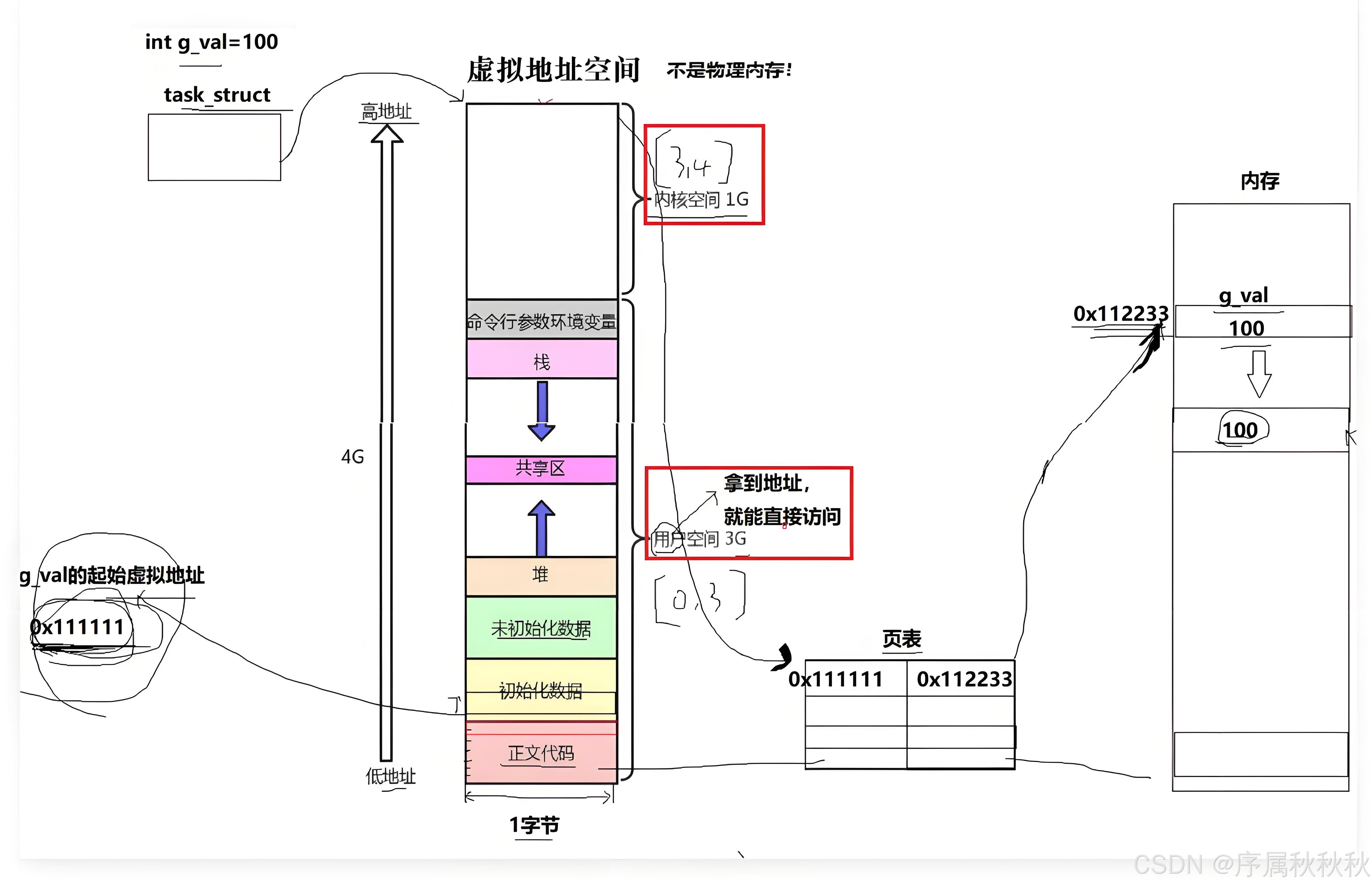
- 举个例子:如果我们定义了一个全局变量
gval并赋值为 100,它在物理内存中必然有一个实际的存储位置(比如:物理地址0x112233)- 同时,在进程的虚拟地址空间里,也会为这个变量预留一块 4 字节的空间,并分配一个虚拟地址(比如:
0x111111)为了让虚拟地址能对应到真实的物理内存,操作系统会为每个进程维护一个 "页表"
- 这个页表就像一本翻译词典:左侧记录的是进程的虚拟地址(比如:
0x111111),右侧则对应着该虚拟地址映射到的物理地址(比如:0x112233)- 当进程想要访问
gval时,它会先通过虚拟地址0x111111发起请求- 此时操作系统会自动触发 "地址翻译" 过程:通过查找页表,找到
0x111111对应的物理地址0x112233,然后再去访问物理内存中的数据整个过程对进程来说是完全透明的 ------ 进程只需要操作虚拟地址,无需关心真实的物理内存位置。
所以 :页表的核心作用就是实现 "虚拟地址到物理地址的映射",它是虚拟内存机制的关键组成部分,既让每个进程拥有独立的地址空间(避免冲突),又能高效地管理物理内存的分配与回收。
思考与探究:
首先我们要明确 :虚拟地址空间中,每一个字节都有唯一的地址。无论变量占据多少字节,其包含的每个字节都会经过页表映射到真实的物理内存地址。
这时可能有小伙伴会产生疑问:比如我们定义的
int g_val是整数类型,众所周知 int 类型通常占用 4 个字节,照理说应该对应 4 个地址才对,但为什么我们对g_val取地址时,只得到了一个地址呢?
- 其实我们通过
&g_val拿到的,是这 4 个字节中地址值最小的那个(也就是起始地址)- 而剩下的 3 个字节的地址,会根据变量的类型(这里是 int,占 4 字节)自动计算得出 ------ 本质上就是在起始地址的基础上,通过 "偏移量" 来确定后续字节的位置
也就是说:
- 编译器通过 "起始地址 + 类型对应的长度(偏移量)" 的方式,帮我们隐含了对后续字节地址的计算
- 所以虽然变量实际占用多个字节、对应多个地址,但我们只需要通过取地址操作拿到起始地址,再结合变量类型,就能确定该变量所占据的所有字节的地址了
3. 被骗的真相?
要理解
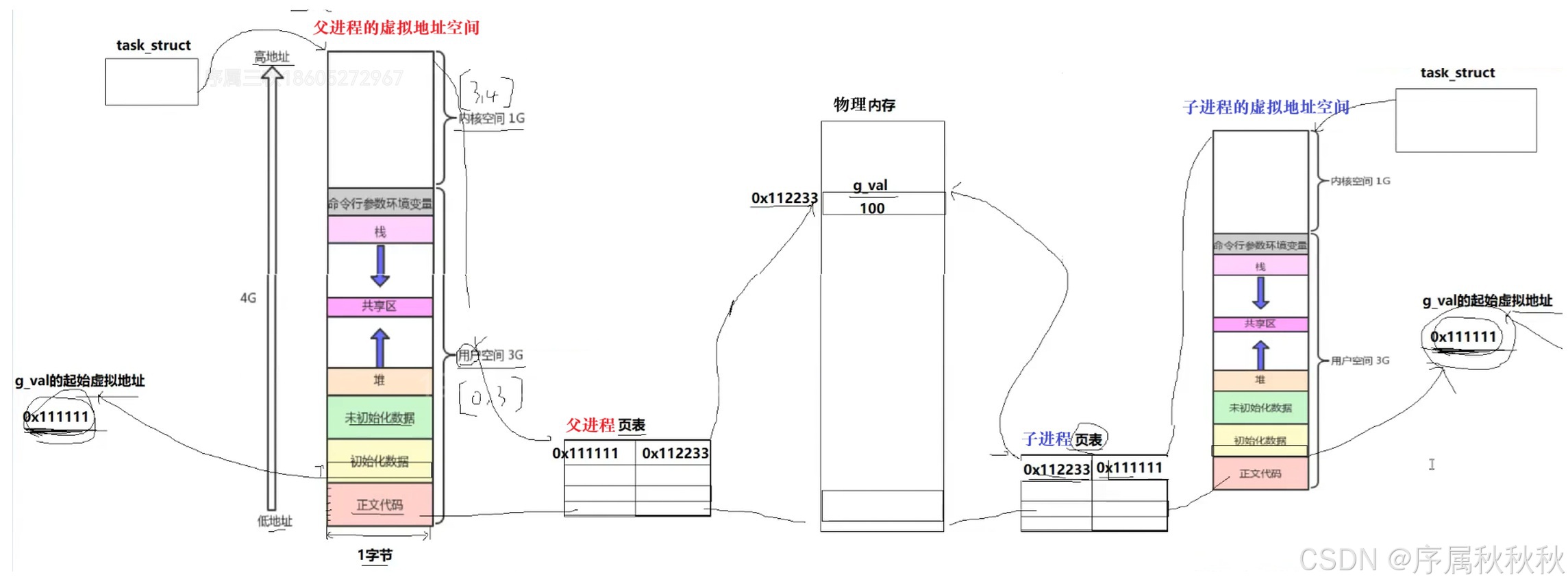
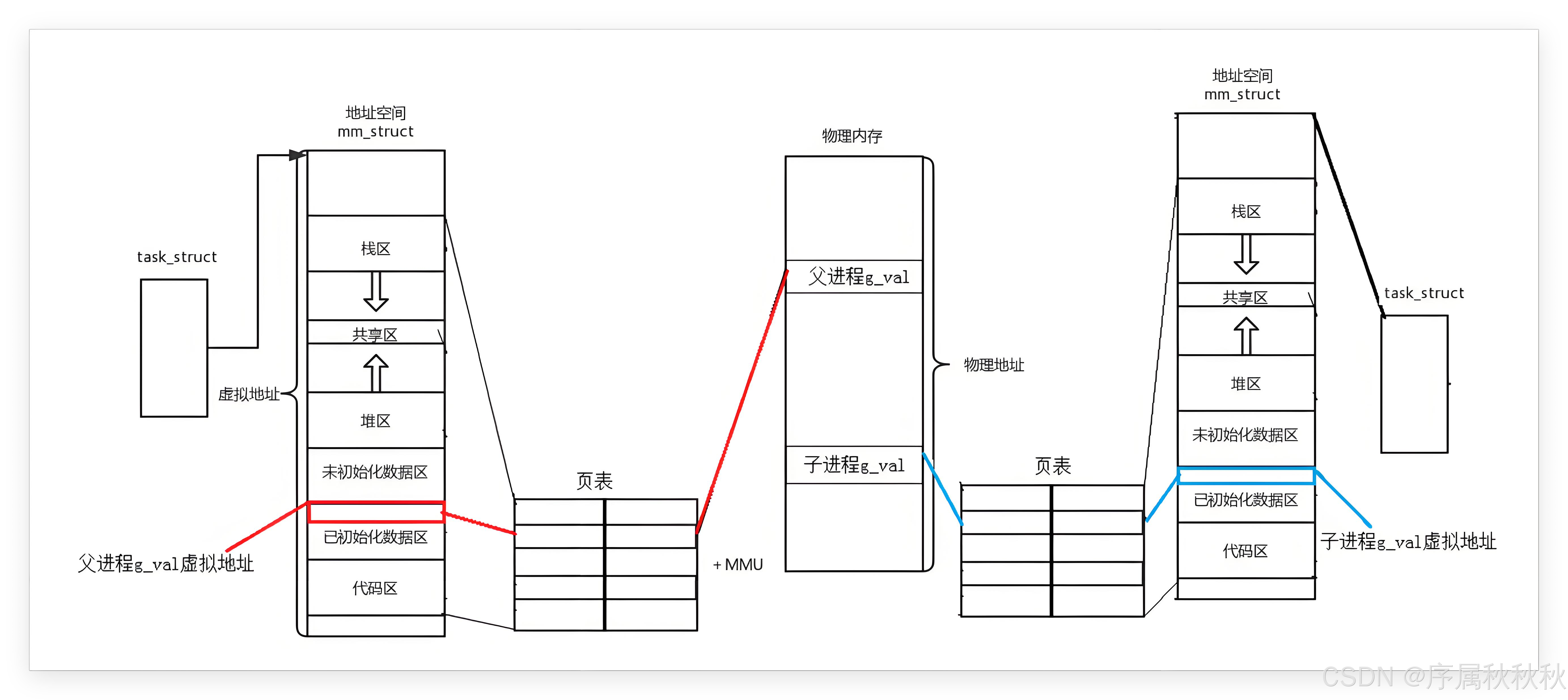
fork()创建子进程后 "地址相同却能独立操作" 的核心逻辑,需要从 "进程资源继承" 的底层机制说起:首先现代操作系统会为每个进程分配一套独立的 "核心资源",包括虚拟地址空间和页表
- 父进程有自己的虚拟地址空间和页表,子进程被创建时,这些资源也会完整地从父进程拷贝过来
- 不仅如此,子进程的进程控制块(PCB,记录进程状态的核心数据结构),同样是基于父进程的 PCB 拷贝生成的,目的是让子进程初始状态与父进程保持一致
不过这里的 "拷贝" 有个关键细节:对于虚拟地址空间中的 "地址映射关系"(也就是页表内容),子进程进行的是浅拷贝
- 简单说,子进程页表中记录的 "虚拟地址→物理地址" 映射规则,和父进程完全相同
- 比如说,父进程中全局变量
g_val的虚拟地址是0x111111,映射到物理地址0x112233;子进程的页表也会原样记录 "0x111111→0x112233"这就解释了为什么父子进程打印的
g_val虚拟地址完全相同:
- 因为子进程的虚拟地址空间是从父进程拷贝来的,变量的虚拟地址自然和父进程一致
- 而默认情况下,父子进程的
g_val会 "共享同一块物理内存",也是因为页表的映射关系相同 ------ 两者通过相同的虚拟地址,最终都会指向物理内存中0x112233这个位置
更重要的是,这种 "共享" 不仅限于数据(比如:全局变量、局部变量),连程序的代码段也是如此。
- 代码段存储的是可执行指令,这些指令的虚拟地址和物理地址映射关系,同样会通过页表浅拷贝传递给子进程
- 所以从底层看,fork() 刚创建子进程时,父子进程的代码和数据是完全共享物理内存的,只有当子进程尝试修改数据(比如:
g_val++)时,操作系统才会触发"写时拷贝"机制,为子进程分配新的物理内存并更新其页表,让子进程拥有独立的数据副本 ------ 这也是操作系统为了节省内存资源设计的高效策略总结来说:
- 子进程通过拷贝父进程的 PCB 、虚拟地址空间 和页表,确保了初始状态与父进程一致
- 而页表的浅拷贝既让父子进程的虚拟地址保持相同,又实现了代码和数据的默认共享,这正是
fork()机制中 "继承与共享" 的底层逻辑
4. 写实拷贝本质是什么?
现在我们来聚焦一个关键场景:当子进程要修改变量(比如:对
g_val执行++操作)时,背后会发生什么?首先要明确一个核心原则:进程具有独立性------ 每个进程的操作不该影响其他进程的运行。
- 如果子进程直接顺着自己的虚拟地址,找到对应的物理地址(比如:之前和父进程共享的
0x112233)并修改- 那父进程访问
g_val时,看到的值也会被改变,这就破坏了进程的独立性,显然不符合操作系统的设计逻辑
所以 :当子进程试图修改 g_val 时,操作系统会立刻介入,触发一种名为 "写时拷贝(Copy-On-Write,简称 COW)" 的机制,具体过程是这样的:
- 检测修改行为:子进程发起
g_val++时,会先通过虚拟地址查找页表,找到对应的物理地址(此时还是和父进程共享的0x112233)。操作系统会检测到 "子进程要修改共享的物理内存数据",于是暂停子进程的修改操作- 分配新的物理内存:操作系统会在物理内存中为子进程重新开辟一块新空间(比如:地址为
0x223344),然后把原来物理地址0x112233中g_val的值(比如:初始的 100)完整拷贝到新空间0x223344中。这一步之后,子进程就有了g_val的独立副本- 更新子进程的页表:接下来,操作系统会修改子进程的页表映射关系 ------ 把原来 "虚拟地址
0x111111→ 物理地址0x112233" 的条目,更新为 "虚拟地址0x111111→ 物理地址0x223344"。也就是说,子进程的虚拟地址没有任何变化,还是0x111111,但它对应的物理地址已经换成了新的0x223344- 恢复子进程修改:完成页表更新后,操作系统会让子进程继续执行
g_val++操作。此时子进程修改的,就是自己独立的物理内存副本(0x223344中的数据),父进程的g_val依然对应原来的物理地址0x112233,数据不会受到任何影响
到这里,我们就能清晰理解写时复制的核心逻辑了:
- 它既保证了进程的独立性(子进程修改数据不影响父进程)
- 又避免了
fork()时直接拷贝所有物理内存(节省了内存资源和创建进程的时间)只有当真正需要修改数据时,才会为子进程分配独立的物理内存并更新映射。
5. 进一步探究虚拟地址是什么?
小故事:富豪的私生子
在遥远的北美大陆,住着一位身家 50 亿美元的富豪。他有三个私生子,这三个孩子彼此毫不知情 ------ 毕竟 "私生子" 的身份。
某天,富豪单独召见了大儿子。看着眼前对经商充满热情的少年,他许诺道:"你既然喜欢做生意,就好好闯。等你做出一番成绩,我的这 50 亿美元家产,就都是你的。"
不久后,他又私下找到了二儿子。得知这个孩子痴迷钢琴,便笑着鼓励:"你弹钢琴很有天赋,好好练,将来成了享誉世界的音乐家,我的那 50 亿美元,就留给你。"
最后见到三女儿时,富豪看着这个成绩优异的小姑娘,同样给出了承诺:"女儿,你学习这么好,继续加油。要是能考上哈佛大学,我的 50 亿美元,就归你了。"
听到这里,大家想必都明白了 ------ 这位富豪分明是在给三个孩子 "画大饼" 啊!他之所以敢这么说,核心在于他断定:孩子们当下只会朝着目标努力,绝不会立刻张口就要这 50 亿美元。
而这个有趣的故事,恰好能用来比喻操作系统的
虚拟内存机制:
- 故事里的大富豪,就相当于我们的操作系统,掌握着最核心的 "资源分配权"
- 那笔让孩子们向往的50 亿美元,就是计算机里实实在在的物理内存(容量有限,就像富豪的家产总量固定)
- 富豪给每个孩子许下的 "家产承诺",就是操作系统给每个进程画的 "大饼"------虚拟地址空间
- 那三个彼此隔绝的私生子,则对应着系统中运行的进程(进程间相互独立,就像私生子们互不相识)
就像富豪让每个孩子都以为 "50 亿最终会归自己",操作系统也会让每个进程都产生一种 "错觉":
- 自己独占了一整块连续的内存空间(比如:32 位系统下,每个进程都认为自己拥有 4GB 虚拟内存)
- 但实际上,这些虚拟地址空间只是 "纸面承诺",只有当进程真正需要访问数据时,操作系统才会悄悄将虚拟地址映射到实际的物理内存 ------ 就像只有等孩子真的达成目标(虽然故事里是 "大饼"),富豪才需要兑现承诺一样
这个比喻恰好戳中了虚拟内存的精髓:用 "虚拟的地址表象" 让进程方便地管理内存,同时通过操作系统的底层调度,高效且安全地共享有限的物理内存资源。
小故事:我是项目经理
公司里有个爱 "画饼" 的老板:某天他找到小王,拍着肩膀说:"小王啊,好好干,等项目做出成绩,我就让你当项目经理!" 转头见到小李,又换了套说辞:"小李,你技术扎实,好好打磨业务,干好了我给你涨工资!" 接着,小赵、小钱、小孙...... 几乎每个员工都收到了老板量身定制的 "饼"
过了一阵子,老板又来 "画饼" 了。他走到小王面前,张口就说:"小王,最近表现不错,好好干,给你涨工资!" 小王一听就愣了,连忙追问:"老板,您上次明明说让我当项目经理,怎么今天改口了?" 老板瞬间语塞,心里犯起了嘀咕:"哎,员工太多,画的饼记混了......"
这一幕恰好暴露了一个问题:如果老板要给几十上百个员工画饼,每个饼的内容、对象、时间都不一样,要是不专门管理,迟早会乱成一锅粥。怎么解决这个问题?
其实思路和操作系统管理进程的逻辑如出一辙 ------"先描述,再组织"
所谓 "先描述",就是给每个 "饼" 建立一份 "档案"
老板可以专门定义一个 "饼" 的结构体(比如:用代码里的
struct表示),把关键信息都记下来:
cppstruct Cake { char *employee; // 给谁画的饼(比如:"小王""小李") char *time; // 什么时间画的(比如:"2025年9月16日") char *place; // 在哪里画的(比如:"办公室茶水间") char *content; // 画的什么饼(比如:"当项目经理""涨工资") struct Cake *next; // 指针,用来连接下一个"饼"的档案 };每个员工的 "饼" 都对应一个这样的结构体实例,把 "给谁画、何时画、画了啥" 都描述清楚,就不会再记混细节。
然而 "再组织",就是把这些零散的 "饼档案" 串起来管理
利用结构体里的
next指针,把所有struct Cake实例连成一个链表 ------ 这样老板想查哪个员工的饼,只要从链表头开始遍历,顺着指针就能找到对应的档案;想新增、修改或删除某个饼,直接操作链表节点就行,管理起来既清晰又高效。
其实,老板管理 "饼" 的逻辑,和操作系统管理虚拟地址空间的逻辑完全一致:
- 操作系统里的 "饼" ,就是每个进程的虚拟地址空间(让进程以为自己独占内存的 "假象")
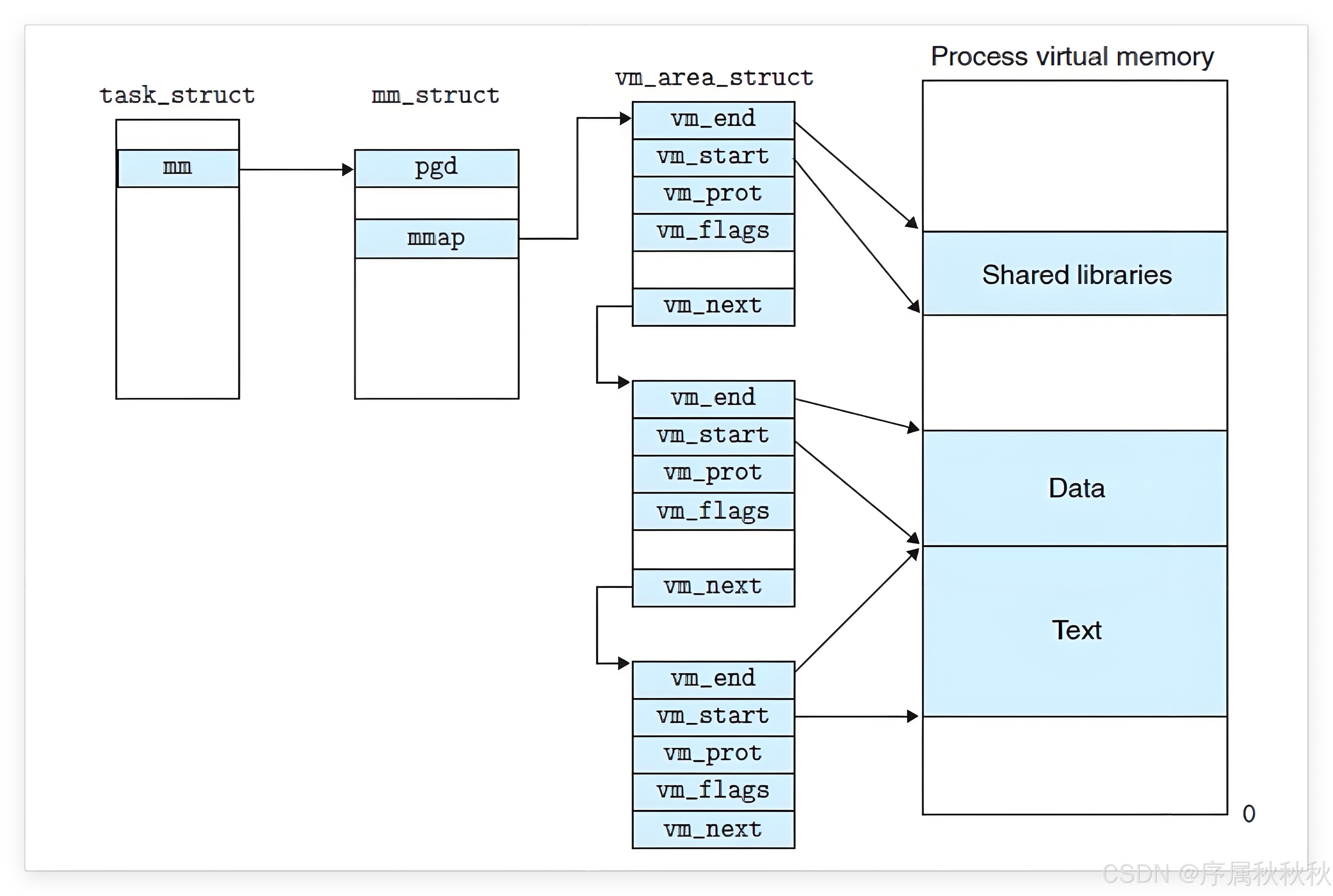
- 用来描述虚拟地址空间的 "结构体档案",在 Linux 系统中叫做 mm_struct(全称 "memory descriptor",内存描述符)
- 这个结构体里记录了虚拟地址空间的所有关键信息:
代码段、数据段、堆、栈的起止地址、页表的指针、内存使用状态等,就像 "饼档案" 里记满了细节一样- 而我们之前学过的 task_struct(进程控制块 PCB),则是描述进程本身的 "档案"------ 每个
task_struct里都会包含一个指向mm_struct的指针,就像 "员工档案" 里会关联他的 "饼档案" 一样😄
最终 :操作系统通过 mm_struct 描述每个进程的虚拟地址空间,再通过链表等数据结构将这些 mm_struct 组织起来,实现了对所有进程虚拟内存的高效管理 ------ 这和老板用 "结构体 + 链表" 管理 "画的饼",本质上是同一个 "先描述,再组织" 的智慧。
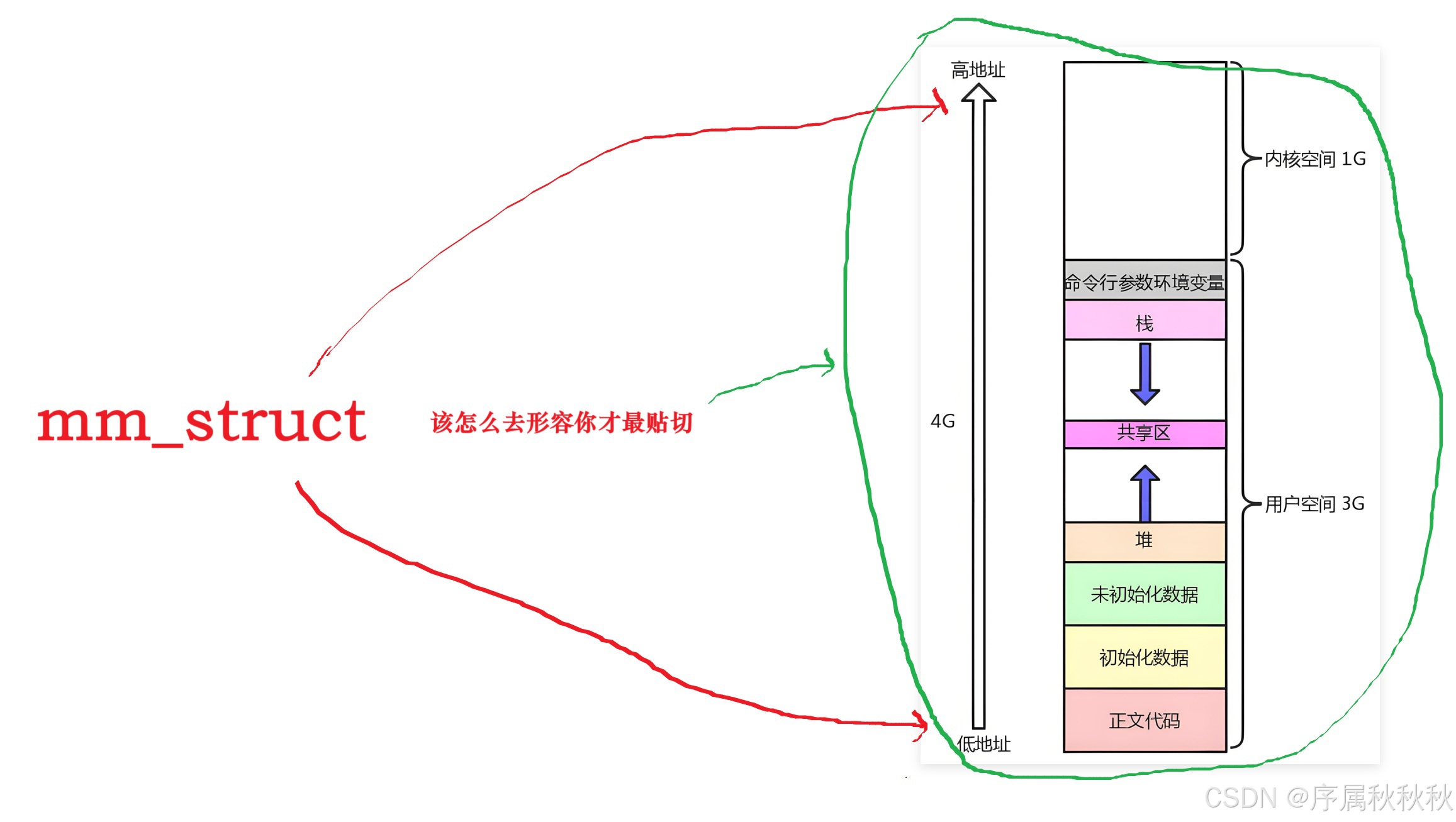
在 Linux 系统里,
mm_struct(内存描述符)这个结构体负责描述进程地址空间的所有信息
- 每个进程都仅有一个
mm_struct结构,并且在每个进程的task_struct(进程控制块)结构里,存在一个指针,该指针指向对应进程的mm_struct结构体- 正因为如此,每个进程才能拥有各自独立的地址空间,从而做到相互之间不产生干扰
6. mm_struct到底长什么样?
小故事:桌上的三八线
假如你正在上幼儿园,平时总爱流鼻涕、不讲卫生,是个小邋遢鬼。但幸运的是,你和班里的班花小美分到了同一张课桌 ------ 这张课桌长 100 厘米,本是两人共用的空间。
可小美特别嫌弃你,一坐下就掏出铅笔,在课桌正中间画了一条清清楚楚的 "三八线",还叉着腰警告你:"不许越过这条线,你的东西只能放你那边!"
讲到这儿,大家可以先想一想:小美在课桌上画 "三八线",本质上是在做什么?
答案很简单 ------区域划分。她通过一条线,把一张完整的课桌分成了 "你的地盘" 和 "她的地盘" 两个独立区域,明确了各自的 "使用边界",避免互相干扰。
如果把这个场景抽象成编程里的逻辑,其实就像我们定义了一个名为 "课桌" 的结构体(
struct Desk)。这个结构体里不需要真的 "画一条线",只需要用两个 "位置参数" 就能圈定各自的区域:
cpp// 抽象的"课桌"结构体 struct Desk { int your_start; // 你的区域起始刻度 int your_end; // 你的区域结束刻度 int xiaomei_start; // 小美的区域起始刻度 int xiaomei_end; // 小美的区域结束刻度 };比如小美画的 "三八线" 在 50 厘米处,那你的区域就是
your_start=0、your_end=49,她的区域就是xiaomei_start=51、xiaomei_end=100(留 1 厘米的 "线" 当边界)通过 "起始 + 结束" 的数值,就能清晰划分出两个互不重叠的空间 ------ 这就是 "区域划分" 的核心逻辑:只要明确一个区域的 "开始位置" 和 "结束位置",就能实现对空间的精准分割与管理
有了这个划分,你就能在自己的区域里自由安排物品了:比如在 25 厘米的刻度处放铅笔,46 厘米的刻度处放橡皮,只要不超过 0 到 49 的范围,小美就不会生气。
而这个场景,恰好能完美对应我们之前讲的 "虚拟地址空间" 和
mm_struct:
- 那张 100 厘米的课桌,就相当于进程的虚拟地址空间(一个完整的、供进程使用的 "内存容器")
- 课桌上的每一个刻度(0 厘米、1 厘米、...、100 厘米),就是虚拟地址空间里的虚拟地址(每个字节都有唯一的地址标识)
- 你、小美,则对应虚拟地址空间里的不同功能区域(比如:代码段、数据段、堆、栈)
- 而描述 "课桌区域划分" 的 struct Desk,本质上就是 Linux 里描述虚拟地址空间的 mm_struct(内存描述符)
所以 :
mm_struct里最核心的内容,其实就是记录虚拟地址空间中各个功能区域的 "起始地址" 和 "结束地址"。
c// mm_struct 中记录各区域边界的核心字段(简化版) struct mm_struct { long code_start; // 代码段起始虚拟地址 long code_end; // 代码段结束虚拟地址 long init_start; // 已初始化数据段起始虚拟地址 long init_end; // 已初始化数据段结束虚拟地址 long uninit_start; // 未初始化数据段(BSS)起始虚拟地址 long uninit_end; // 未初始化数据段(BSS)结束虚拟地址 long heap_start; // 堆区起始虚拟地址 long heap_end; // 堆区结束虚拟地址 long stack_start; // 栈区起始虚拟地址 long stack_end; // 栈区结束虚拟地址 };就像小美用 "0-49" 和 "51-100" 划分课桌一样,
mm_struct用 "start-end" 的成对字段,把虚拟地址空间分割成代码段、数据段、堆、栈等独立区域。
这样一来,操作系统就能清晰地知道:
- 哪个地址范围是存放指令的(代码段,只读)
- 哪个范围是存放全局变量的(数据段)
- 哪个范围是给动态内存分配用的(堆)
既避免了不同区域的内存冲突,也让内存管理变得有序又高效。
7. 建立映射关系的过程是什么样的?
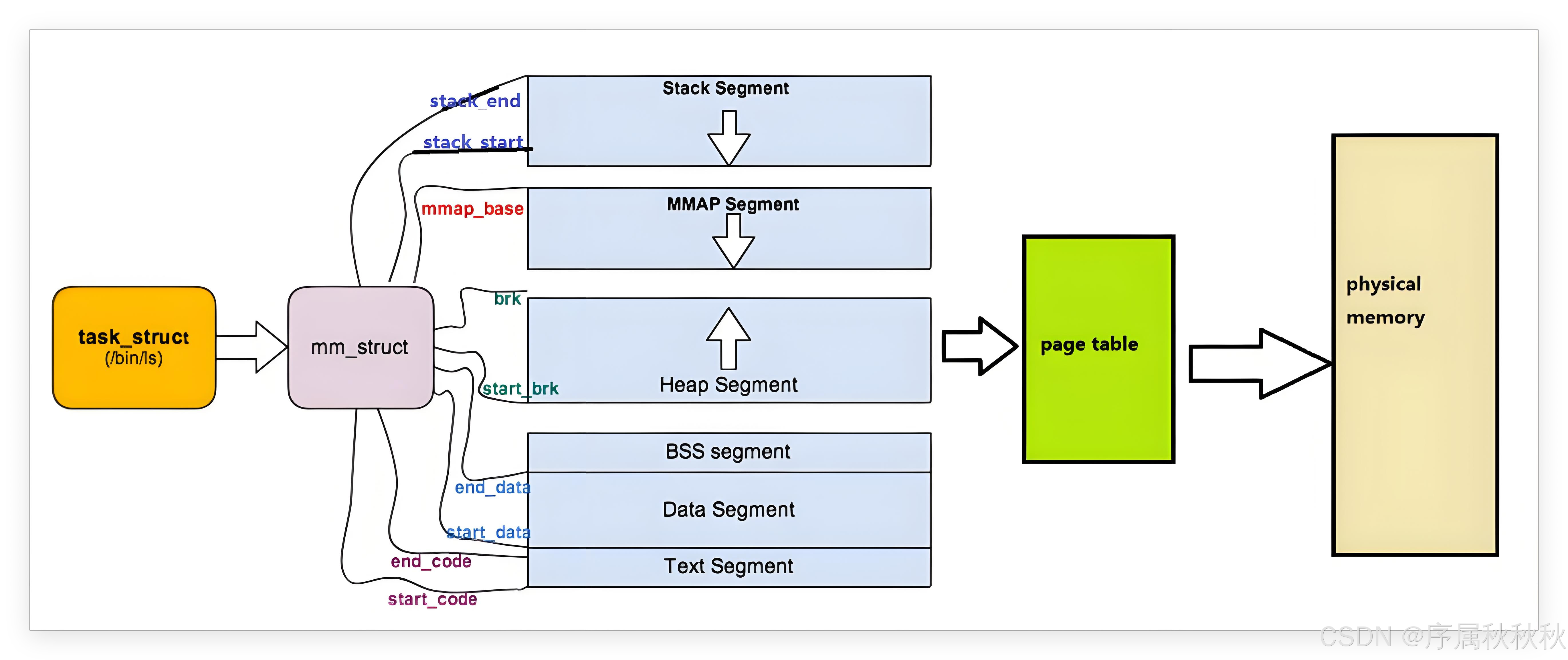
我们的代码最终需要加载到物理内存中运行,所以代码在物理内存中占据多少字节,就得在虚拟地址空间中也预留出相同大小的空间。
- 具体来说,假如物理内存中为代码分配了 100 个字节的空间,那我们也会在虚拟地址空间里划出 100 个字节的区域
- 接着,通过填充页表,让这 100 个虚拟地址和 100 个物理地址一一对应,这样代码的虚拟地址与物理内存中的实际存储位置就建立起了映射关系
这个过程可以拆解为以下步骤:
- 在虚拟地址空间中,申请一块与代码大小相匹配的空间
- 加载程序时,在物理内存中也申请相应大小的空间
- 利用页表,把虚拟地址空间的这块区域和物理内存中申请的空间进行映射
如此一来,就相当于把物理内存 "转化" 成了可供上层用户直接操作的虚拟内存。之后,上层用户程序只需要使用虚拟地址,就能间接访问到物理内存中的数据了。
而所谓
"在虚拟地址空间中申请指定大小的空间",其实就是对虚拟地址空间的区域进行重新划分。具体怎么划分呢?很简单,只需要调整对应区域的起始地址(start)和结束地址(end)就可以了。
8. 为什么需要页表?
这个问题其实可以转化为:如果程序能直接操作物理内存,会引发什么问题?
- 在早期的计算机系统里,运行一个程序时,得把整个程序都加载到内存中
- 程序直接在物理内存上运行,也就是说程序里访问的内存地址都是实际的物理内存地址
- 当计算机要同时运行多个程序时,必须确保这些程序所使用的内存总量不超过计算机实际物理内存的大小
那当同时运行多个程序时,操作系统是怎么给这些程序分配内存的呢?
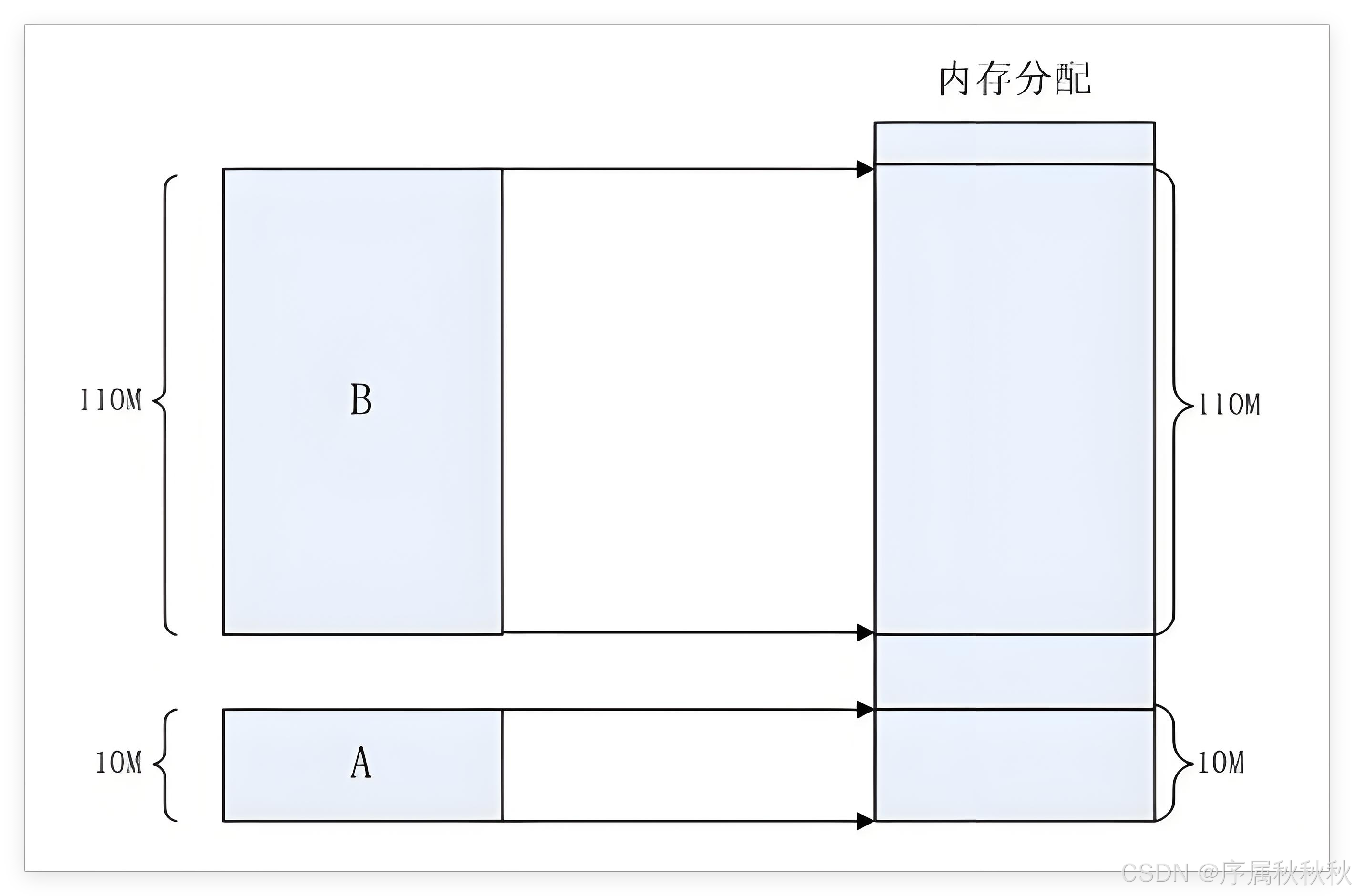
- 举个例子,假设某台计算机的总内存大小是 128M,现在要同时运行程序 A 和程序 B,程序 A 需要占用 10M 内存,程序 B 需要占用 110M 内存
- 计算机在给程序分配内存时,会采用这样的方式:先把内存中最前面的 10M 分配给程序 A,接着再从剩余的 118M 内存里划分出 110M 分配给程序 B
页表的存在具有多方面关键意义,可从以下三点总结其必要性:
1. 地址管理更有序
物理内存的地址分布是相对
零散、无序的,而虚拟地址空间能对这些物理地址进行规整,将其映射为连续、有序的虚拟地址。这样一来,上层应用程序在访问内存时:
- 无需关心复杂的物理内存布局
- 只需基于简洁有序的虚拟地址进行操作,极大简化了内存访问的逻辑
2. 保障内存安全
在虚拟地址向物理地址转换的过程中,操作系统可以对地址以及相关操作的合法性进行判定。
- 例如像字符常量区这类本应只读的内存区域,在页表中会被设置为只读权限
- 当程序试图向该区域写入数据(如:
char *str = "helloworld"; *str = 'H';这种操作)时- 页表在地址转换时会检测到权限违规,进而拦截非法操作,防止物理内存被错误修改,有效避免了野指针等问题引发的内存安全风险,保护了物理内存的完整性
3. 解耦进程与内存管理
页表使得进程管理 和内存管理在一定程度上相互独立。
- 进程只需关注虚拟地址空间的逻辑布局和使用,而内存管理的具体细节(如:物理内存的
分配、回收、碎片整理等)则由操作系统通过虚拟地址与物理地址的映射机制来处理- 这种解耦让进程的开发和内存的高效管理可以各自优化,提升了系统的整体灵活性与可维护性
8.1:在字符串常量区写入崩溃的本质是什么?
首先我们需要澄清一个关键细节:
页表中的每一个 "页表项"(描述虚拟地址与物理地址映射关系的最小单元),并非只存储
虚拟地址和对应的物理地址------ 它还包含了内存访问权限的标识这种权限标识是操作系统保护物理内存的核心手段之一:
- 当进程试图通过某个虚拟地址访问物理内存时,操作系统会先查询页表,找到该虚拟地址对应的页表项
- 此时系统不仅会进行 "虚拟地址→物理地址" 的翻译,还会严格检查进程的操作(如:读、写、执行)是否符合页表项中设定的权限
举个具体的例子:
- 如果某个页表项对应的是程序的 "只读数据段"(比如:存储字符串常量的区域),权限被标记为 "只读"
- 当进程试图向这个虚拟地址写入数据(比如:修改字符串常量的值)时,操作系统会立刻检测到 "操作权限不匹配"------ 进程想要执行 "写操作",但页表只允许 "读操作"
- 此时,系统会直接拒绝地址转换,并触发一个内存访问错误(如:Linux 下的 Segmentation Fault,即段错误),终止进程的非法操作
正是通过这种
"地址映射 + 权限校验"的双重机制,页表实现了对物理内存的精准保护:
- 它既能确保进程只能访问自己有权限的内存区域
- 又能限制进程对特定区域的操作类型(比如:代码段只允许执行、只读数据段不允许修改)
从根本上避免了非法操作对物理内存中其他数据(甚至操作系统内核数据)的破坏,保障了系统的内存安全。
8.2:野指针的本质是什么?
所谓的野指针,可以这样理解:
在进程的虚拟地址空间中,每个区域(如:堆区、栈区、代码段)都有明确的边界 ------ 比如:堆区有其最高可用地址,超出这个地址的虚拟空间并未被操作系统分配(即未在页表中建立对应的映射关系)
- 如果一个指针错误地指向了这类 "未分配的虚拟地址"(比如:堆区边界之外的地址,或是从未被申请过的随机地址)
- 那么当进程试图通过这个指针访问内存时,操作系统会去查询页表,结果必然是 "找不到该虚拟地址对应的映射条目"------ 也就是查找页表失败
这种指向未分配虚拟地址、导致页表查询失败的指针,就被称为野指针。
8.3:怎么理解解耦进程与内存管理?
假设现在要访问程序的代码段,但代码段非常大,比如有 2 个 GB,而系统总共只有 4GB 内存,还要运行其他程序和服务,所以只能先把代码段的四分之一(比如:512MB)加载到物理内存中。
- 这时候,我们可以先在虚拟地址空间的代码段区域,完整地分配出 2GB 的虚拟空间,但只对前 512MB 的虚拟地址建立好与物理内存的映射关系,剩下的 1.5GB 虚拟地址暂时不进行映射
- 如此一来,当程序运行到需要访问后 1.5GB 代码段的指令时,操作系统会发现:虚拟地址是存在的,但对应的物理内存中并没有这些内容(因为没加载)
- 这时,操作系统就会触发缺页中断机制:先把需要访问的那部分代码(比如又一块 512MB)从磁盘加载到物理内存中,然后在页表中补充对应的映射关系,最后让程序继续执行
从系统模块的角度看:
- 物理内存与磁盘之间的交互(加载、置换数据) ,更像是操作系统的内存管理模块负责的工作
- 虚拟地址空间的规划、页表的维护 ,则更偏向于操作系统的进程管理模块的范畴
对进程而言:
- "代码和数据被加载到物理内存的哪个位置"
- "物理内存不够时该怎么处理"
它完全不用操心这类底层细节 ------ 因为虚拟地址空间 和页表已经把这些复杂的内存管理逻辑 "屏蔽" 了。
如果去掉页表,进程控制块(PCB)就得直接记录物理内存的地址。这样一来,程序加载数据 的过程就会和进程管理强绑定:
- 进程每申请一次内存,都得去修改 PCB 里的指针
- 进程调度时,也得考虑物理内存的分配状态
但有了页表后,进程的调度、管理等操作,和物理内存的具体分配几乎没了直接关联 ------ 要调整内存映射,只需要修改页表即可,进程本身的管理逻辑能保持独立。
9. 如何理解缺页中断?
我们先来思考一个问题:
创建进程时,能不能只生成 PCB(
task_struct)和虚拟地址空间(mm_struct),然后从磁盘读取程序的大小信息,但一行代码、一点数据都不加载到物理内存,甚至页表也只填写一部分(比如只记录虚拟地址范围,不关联实际物理地址)?
答案是:这完全是合法的
- 因为此时虽然物理内存中没有程序的任何数据,但虚拟地址空间已经规划好了(比如:代码段、数据段的范围已通过
mm_struct定义),只是页表中尚未建立完整的映射- 为了应对这种情况,页表中会有一个专门的标记位,用来标识 "该虚拟地址对应的物理内存数据是否已加载"
- 当进程后续需要访问这些未加载的数据时,操作系统会检测到标记位的状态,自动触发缺页中断
- 暂停当前进程,从磁盘加载所需的代码或数据到物理内存,然后更新页表完成映射,最后让进程恢复运行
- 整个过程对进程来说是透明的,只需等待中断处理完成即可继续执行
从这个过程中我们能明确 :创建进程时,是先构建 task_struct(进程控制块)、mm_struct(虚拟地址空间描述符)等核心数据结构,再逐步加载代码和数据
这种 "先描述、后加载" 的机制,大幅提升了进程创建的效率 ------ 无需等所有资源就绪,只要核心管理结构就绪,进程就算 "创建完成",后续按需加载即可。
再联系之前学过的
"进程阻塞挂起"状态,用今天的知识就能更深入理解:
- 当系统内存严重不足时,操作系统会将某些进程的代码和数据从物理内存 "换出" 到磁盘的交换分区(Swap),同时清空这些数据在页表中的映射关系(只保留虚拟地址范围和 "未加载" 标记),此时进程进入阻塞挂起状态,不再占用物理内存资源
- 而当进程需要被唤醒时,操作系统会通过缺页中断,将磁盘中的数据重新 "换入" 物理内存,重建页表映射,让进程恢复运行,这正是
虚拟内存机制与进程状态管理协同工作的典型场景
10. vm_area_structs是什么鬼啊?
在进程的虚拟地址空间中,代码段、数据段(已初始化/未初始化)等区域的范围是相对固定的 ------ 它们在程序编译、加载时就已确定,运行过程中不会随意变更大小或位置
- 但栈区有明确的栈顶和栈底,内存增长方向是从高地址向低地址 "向下生长"
- 而堆区的管理逻辑更为灵活,这就需要更精细的结构来跟踪其动态变化
这就要提到
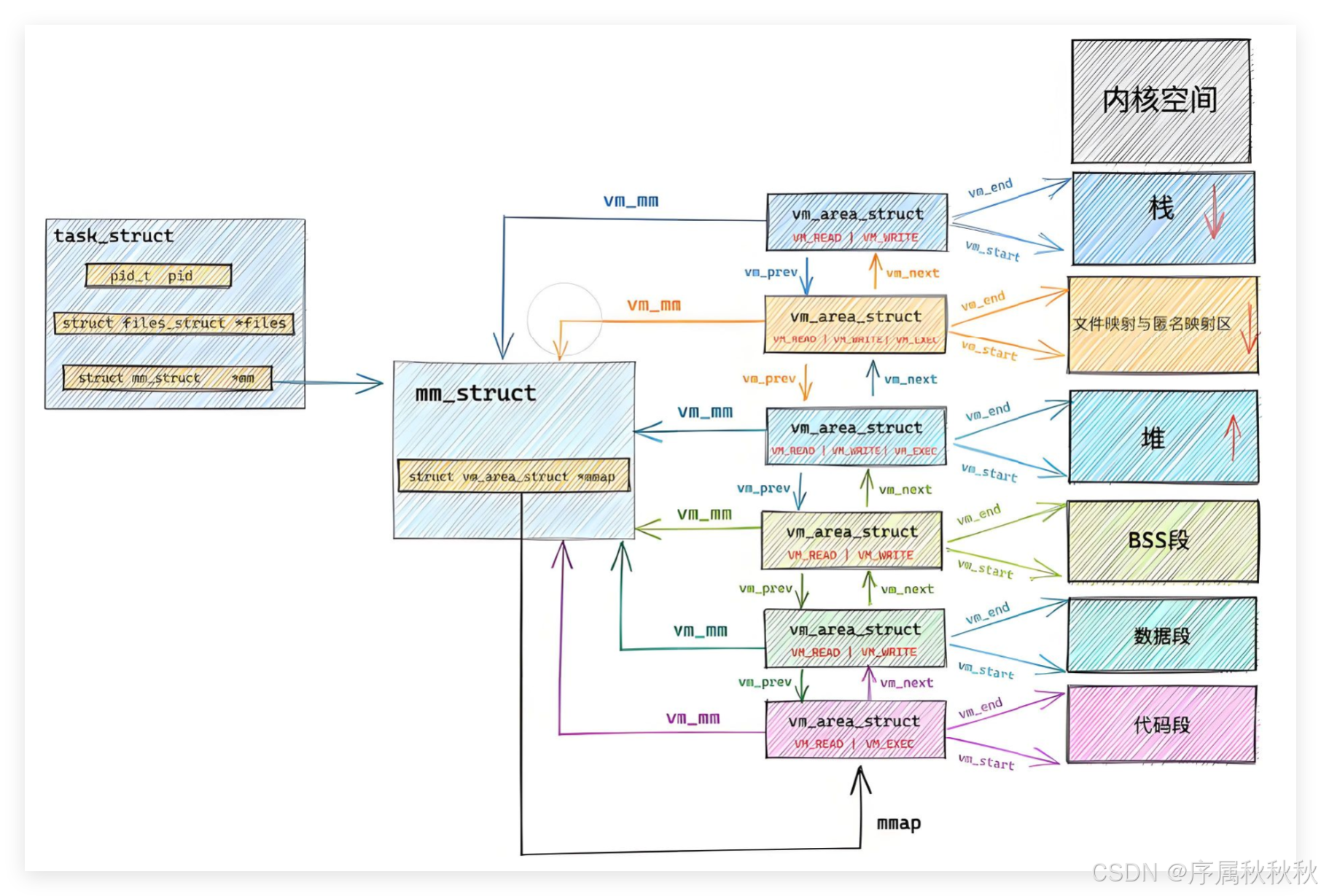
mm_struct(内存描述符)的核心作用了:每个进程的 task_struct(PCB)都会指向其专属的 mm_struct,而 mm_struct 会通过两种数据结构管理虚拟地址空间中的所有 "子区域"(即:独立的虚拟内存块 ,VMA):
- 当虚拟内存区域较少时,采用单链表来组织,由
mmap指针指向链表头- 当虚拟内存区域较多时,采用红黑树来管理,由
mm_rb指针指向树根(红黑树可提升查找、插入效率)
这些子区域都由
vm_area_struct结构体来描述:
- 每个 vm_area_struct 都会精确记录一个子区域的
起始地址(start)和结束地址(end)- 以及该区域的
权限(如:可读、可写)、类型(如:堆、栈、代码段)等信息以堆区为例:
我们用
malloc动态申请内存时,可能会先后申请 10 字节、20 字节的空间,这些小内存块在虚拟地址空间中可能并不连续。但这完全不影响管理 ------每一块独立的堆内存,都会对应一个 vm_area_struct 实例
也就是说,堆区本质是由多个
vm_area_struct共同描述的 "分散区域集合",而非一个连续的大区块。
- 虽然
mm_struct中也会记录代码段、堆区、栈区等大区域的粗略起止地址,但这些更多是 "宏观范围标记"- 对于进程的内存访问、内存分配等具体操作,操作系统根本不需要直接依赖
mm_struct中的粗略地址 ------只需通过遍历链表或查询红黑树,找到对应的 vm_area_struct,读取其中的 start 和 end,就能明确目标区域的精确范围
简单来说:
vm_area_struct是虚拟地址空间的"精细化描述单元"mm_struct是这些单元的"总管理器"进程的内存管理逻辑,最终都落于对
vm_area_struct的操作上。