文章目录
- 1.RNN理论及实例计算推导
-
- [1.1 理论介绍](#1.1 理论介绍)
- [1.2 实例计算推导](#1.2 实例计算推导)
- [1.3 RNN的几种结构](#1.3 RNN的几种结构)
-
- [1.3.1 RNN的 1 to 1](#1.3.1 RNN的 1 to 1)
- [1.3.2 RNN的 N to N](#1.3.2 RNN的 N to N)
- [1.3.3 RNN的 N to 1](#1.3.3 RNN的 N to 1)
- [1.3.4 RNN的 1 to N](#1.3.4 RNN的 1 to N)
- [1.3.5 RNN的 N to M](#1.3.5 RNN的 N to M)
- [1.4 RNN 的优缺点](#1.4 RNN 的优缺点)
- [2.Python 实现RNN](#2.Python 实现RNN)
RNN(Recurrent Neural Network,循环神经网络)是专为序列数据(如文本、时间序列、语音)设计的神经网络,核心解决传统前馈神经网络无法捕捉 "时序依赖""变长序列" 的问题,通过 "循环传递隐藏状态" 实现对序列历史信息的记忆,也是理解LSTM以及Transformer模型的一个基础模型。下面关于RNN的基础架构 Vanilla RNN进行理论介绍以及实例计算推导,帮助"模糊"的人更清晰理解一下。
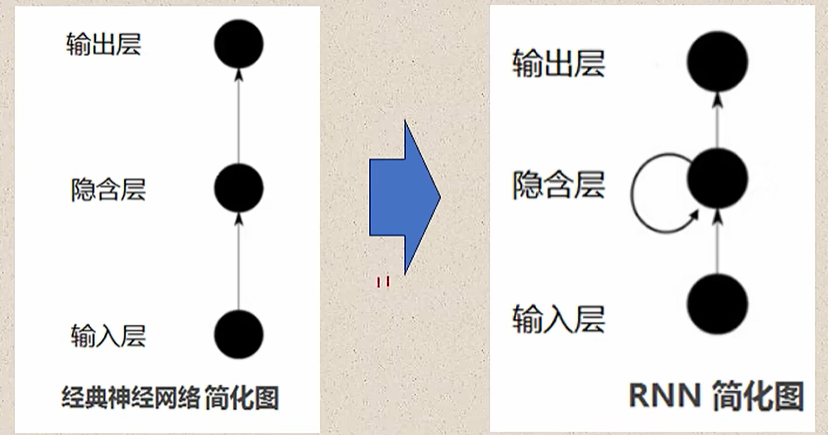
经典神经网络采用单向前馈结构,数据从输入层→隐藏层→输出层单向传递,层与层之间无反馈 / 循环连接;层内参数独立,不同层(或同一层的不同神经元)使用不同权重,无参数共享;每次输入的处理相互独立,无法利用历史信息。而循环神经网络RNN采用循环结构,隐藏层的输出不仅传递给输出层,还会反馈给自身作为下一时刻的输入,形成 "循环";所有时刻共用同一套权重;且有短期记忆能力,通过隐藏状态(h_t)累积历史信息,当前输出依赖 "当前输入 + 历史记忆"。经典神经网络与RNN的核心对比见下图:
1.RNN理论及实例计算推导
在学习RNN公式推导时,在B站看到了这个视频,分别讲解了RNN前向传播和反向传播的推导公式,很清洗。结合实例,简化一下过程
1.1 理论介绍
1.2 实例计算推导


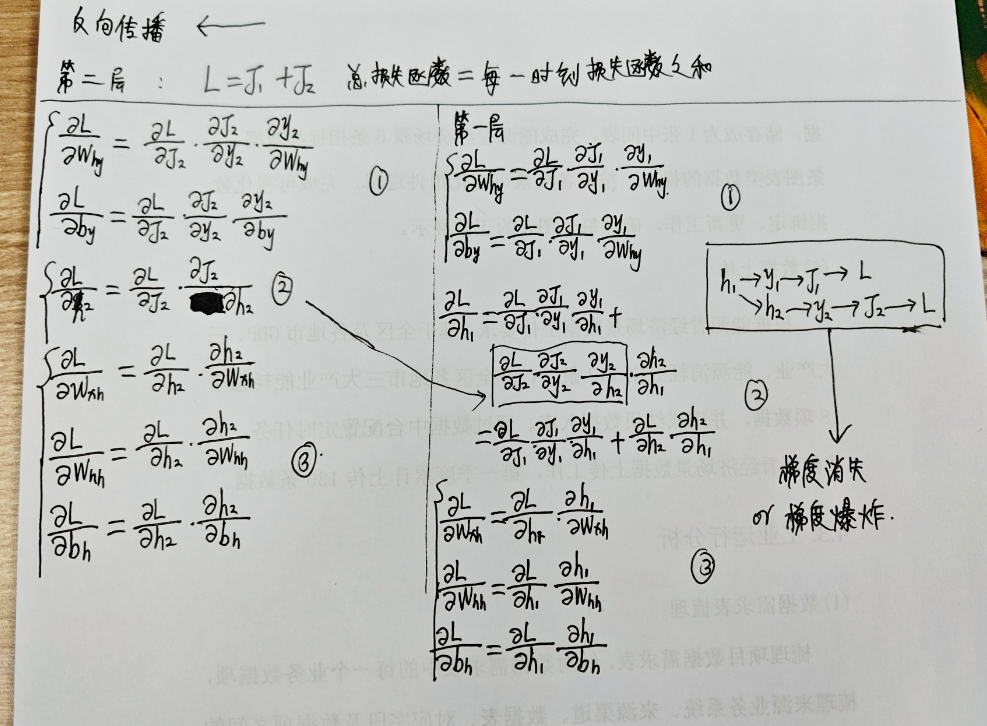
反向传播的推导
1.3 RNN的几种结构
参考文章二十张图带你彻底弄懂RNN!,RNN的几种结构主要是从输入元素数量和输出元素数量来分为以下几种。
1.3.1 RNN的 1 to 1
1.3.2 RNN的 N to N
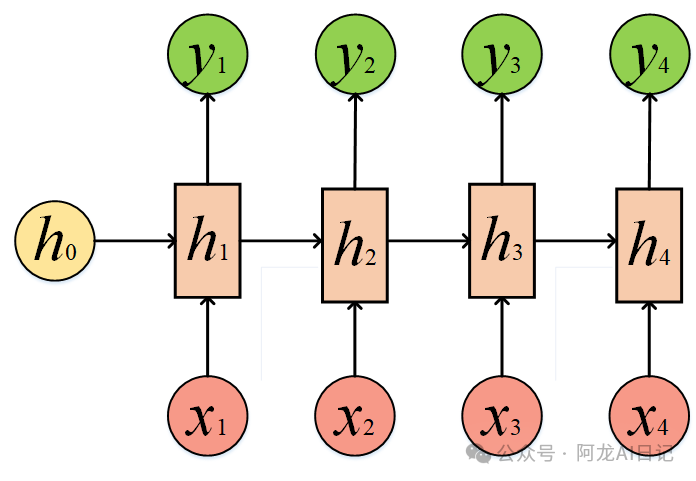
1.3.3 RNN的 N to 1
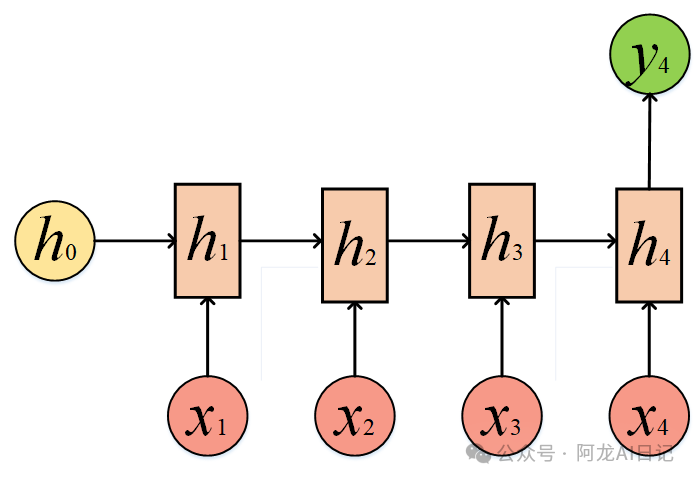
1.3.4 RNN的 1 to N
这种结构事实上就是把x2、x3以及x4全部置零了,这种1 to N可以被用来给一个词,让他来造句。
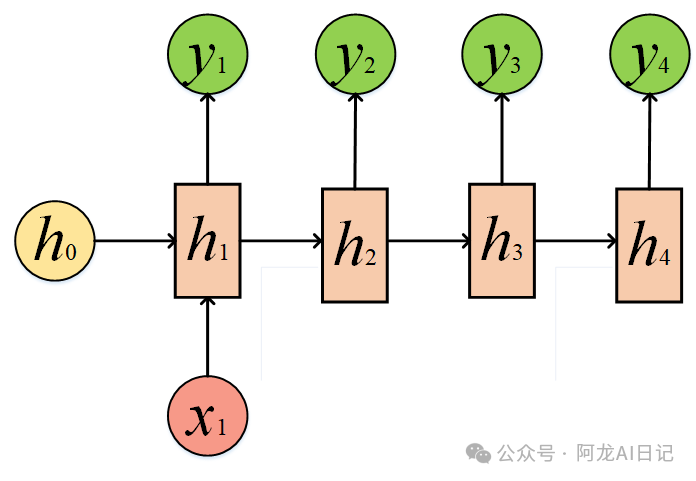
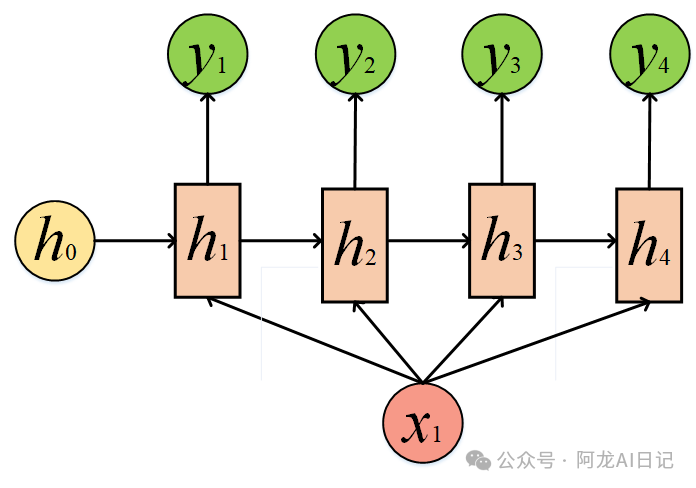
我们也可以给同一个x,某种程度上也是1 to N:
1.3.5 RNN的 N to M
N to M要复杂一些:这种结构也是Encoder-Decoder模型,也可以称之为Seq2Seq模型。在真实的环境中,我们处理的输入和输出的长度往往是不同的,比如翻译问题,源语言和目标语言的句子往往并没有相同的长度。所以,Encoder-Decoder结构先将输入数据编码成一个上下文向量c,拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
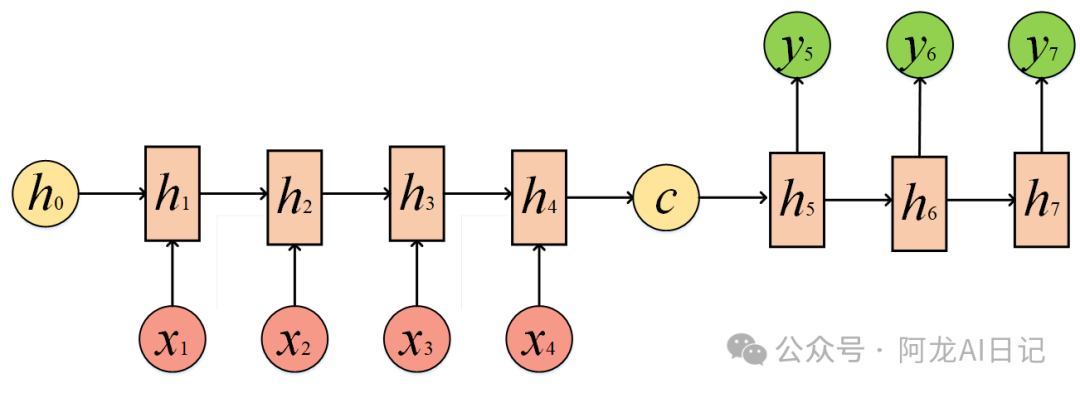
1.4 RNN 的优缺点
优点
1. 天然适配序列数据,捕捉时序依赖
RNN 通过 "隐藏状态循环传递" 的设计,直接建模序列的前后关联(如文本中词的顺序、时序数据的趋势),这是传统前馈神经网络(如 CNN、全连接网络)无法实现的 ------ 前馈网络需将序列固定长度输入,且无法捕捉动态时序关系。
2. 权重共享,参数效率高
RNN 在所有时刻共享同一套权重((W_{xh})、(W_{hh})、(W_{hy})),而非为每个时刻单独设置参数。例如处理 100 步的序列,RNN 仅需 "输入→隐藏 + 隐藏→隐藏 + 隐藏→输出"3 套权重,而前馈网络需为每个时刻设计独立权重,参数数量呈线性增长。
3. 支持变长序列输入 / 输出
RNN 可处理任意长度的序列(如 10 个词的短句、100 个词的长句),且输出长度可与输入长度不同(如 Seq2Seq 架构的机器翻译:输入英文句子长度≠输出中文句子长度),适配 NLP、时序分析等领域的 "变长序列" 核心需求。
4. 结构灵活,易扩展为复合架构
RNN 可通过堆叠(深层 RNN)、双向(Bi-RNN)、编码器 - 解码器(Seq2Seq)等方式扩展,适配更复杂的序列任务:
缺点
1. 基础 RNN 存在严重的梯度消失 / 爆炸问题
基础 RNN 的隐藏状态更新依赖(\tanh)激活,梯度在反向传播时会随序列长度指数衰减(梯度消失)或指数增长(梯度爆炸)------ 超过 10 步的序列,模型几乎无法学习到早期信息的影响。
2. 并行性差,训练速度慢
RNN 的循环结构要求 "按时刻顺序计算"(t 时刻的计算依赖 t-1 时刻的隐藏状态),无法像 CNN 那样对输入数据并行处理。例如处理 100 步的序列,必须从 t=1 到 t=100 依次计算,GPU 的并行算力无法充分利用。
3. 对长序列的记忆能力仍有限(即使是 LSTM/GRU)
LSTM/GRU 虽缓解了梯度问题,但对超长篇序列(如 > 1000 步的文本、年度时序数据)仍会出现 "信息饱和"------ 细胞状态 / 隐藏状态无法无限存储信息,早期关键信息可能被后期信息覆盖。
4. 对输入噪声敏感,鲁棒性不足
RNN 的隐藏状态是 "累积式更新",若输入序列存在噪声(如时序数据的异常值、文本中的错别字),噪声会随循环传递不断放大,导致后续预测 / 输出偏差。
5. 难以捕捉长期依赖中的 "跳跃关联"
RNN 的隐藏状态按顺序传递,若序列中存在 "非连续的长距离关联"(如文本中第 1 词与第 50 词的关联),模型需逐次传递信息,易出现损耗;而 Transformer 的自注意力机制可直接捕捉任意位置的关联,效率更高。
2.Python 实现RNN
敬请期待
python
敬请期待