在自动驾驶感知系统中,3D 检测与跟踪是两大核心任务,直接决定了车辆对周围环境的理解能力。基于稀疏表示的算法凭借无视图变换需求、检测头计算量恒定、易于端到端集成下游任务等优势,逐渐成为该领域的研究热点。本文将对 Sparse4D 系列的最新升级版本 ------Sparse4D v3 进行全面精读,深入剖析其技术创新、网络架构、实验验证及核心优势,带大家完整理解这一先进的 3D 感知框架。
原文链接:https://arxiv.org/pdf/2311.11722
代码链接:https://github.com/linxuewu/Sparse4D
沐小含持续分享前沿算法论文,欢迎关注...
一、论文概述
1.1 研究背景与动机
近年来,稀疏算法(Sparse-based)在时序多视图感知研究中取得了显著进展,其性能已可与稠密 BEV(Dense-BEV)算法相媲美,但在训练收敛性和检测精度上仍有提升空间。具体而言:
- 稀疏算法采用一对一正样本匹配策略,训练初期稳定性差,正样本数量有限,导致解码器训练效率偏低;
- Sparse4D 采用稀疏特征采样而非全局交叉注意力,进一步加剧了编码器因正样本稀缺带来的收敛问题;
- 现有 3D 跟踪方法多基于检测后跟踪(Tracking-by-Detection)框架,需复杂的数据关联和轨迹过滤,无法充分发挥神经网络的端到端能力。
基于上述问题,Sparse4D v3 以 Sparse4D v2 为基线,通过引入辅助训练任务、优化注意力机制、扩展端到端跟踪功能,实现了检测与跟踪性能的显著提升。
1.2 核心贡献
论文的核心贡献可概括为以下三点:
- 提出 Sparse4D v3 框架,集成三大有效策略 ------ 时序实例去噪(Temporal Instance Denoising)、质量估计(Quality Estimation)和解耦注意力(Decoupled Attention),大幅提升 3D 检测性能;
- 将 Sparse4D 扩展为端到端跟踪模型,无需修改训练过程和损失函数,无需提供跟踪 ID 的真实标签,即可直接输出目标运动轨迹;
- 在 nuScenes 基准测试中验证了改进的有效性,在 3D 检测和多目标跟踪任务中均达到当前最优性能(SOTA)。
1.3 整体框架概览
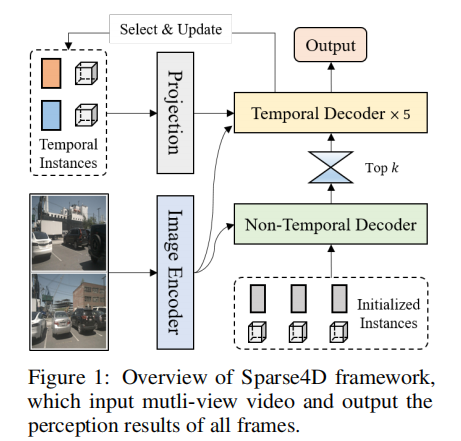
Sparse4D v3 的整体框架延续了 Sparse4D 系列的核心结构,输入为多视图视频,输出为所有帧的感知结果(检测框或跟踪轨迹)。其核心流程如图 1 所示:
- 图像编码器(Image Encoder):将多视图图像转换为多尺度特征图;
- 解码器模块(Decoder Blocks):包含非时序解码器(Non-Temporal Decoder)和 5 个时序解码器(Temporal Decoder),利用图像特征优化实例并生成感知结果;
- 时序传播:将前一帧的实例投影到当前帧,作为时序输入参与当前帧的感知计算。
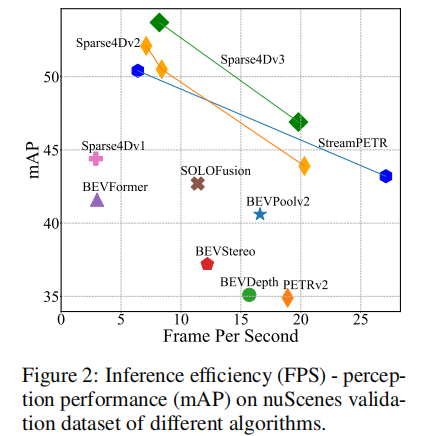
从性能 - 效率权衡来看,Sparse4D v3 在 nuScenes 验证集上的表现如图 2 所示。与 BEVFormer、PETRv2 等主流算法相比,Sparse4D v3 在保持较高推理效率(FPS)的同时,实现了更优的检测精度(mAP),展现出极强的实用性。
二、相关工作回顾
2.1 端到端检测的改进
端到端检测的核心突破源于 DETR(End-to-End Object Detection with Transformers),其采用 Transformer 架构和一对一匹配训练策略,摒弃了传统的非极大值抑制(NMS)。后续改进主要集中在以下方向:
- 注意力机制优化:Deformable DETR 将全局注意力改为基于参考点的局部注意力,降低计算复杂度;Conditional DETR 分离查询中的内容和空间信息,加速收敛;
- 训练匹配策略改进:DN-DETR 通过向解码器输入带噪声的真实标签编码,引入去噪任务作为辅助监督;DINO 进一步引入噪声负样本和混合查询选择,提升性能;
- 3D 检测扩展:DETR3D 将可变形注意力应用于多视图 3D 检测;PETR 系列引入 3D 位置编码,利用全局注意力进行多视图特征融合;Sparse4D 系列通过实例特征解耦、多点特征采样等优化,提升 3D 感知性能。
2.2 多目标跟踪
多目标跟踪(MOT)方法主要分为两类:
- 检测后跟踪(Tracking-by-Detection):依赖检测器输出,通过数据关联、轨迹过滤等后处理完成跟踪,流程复杂且需调优大量超参数;
- 端到端跟踪:基于 DETR 框架,将跟踪功能直接集成到检测器中。如 MOTR 实现了完全端到端跟踪,MUTR3D 将基于查询的跟踪框架应用于 3D 场景。这类方法通常需要在训练中引入跟踪约束,且仅传递高置信度查询到下一帧。
Sparse4D v3 的跟踪方案与现有端到端方法不同:无需修改检测器训练流程,无需跟踪 ID 的真实标签,仅通过推理时的 ID 分配即可实现跟踪,且允许传递低置信度实例,灵活性更高。
三、核心技术细节
3.1 时序实例去噪(Temporal Instance Denoising)
3.1.1 核心问题
稀疏算法的收敛困难主要源于一对一正样本匹配的不稳定性和正样本数量不足。在 2D 检测中,去噪任务已被证明是解决该问题的有效手段,Sparse4D v3 将其扩展到 3D 时序检测场景。
3.1.2 实现方案
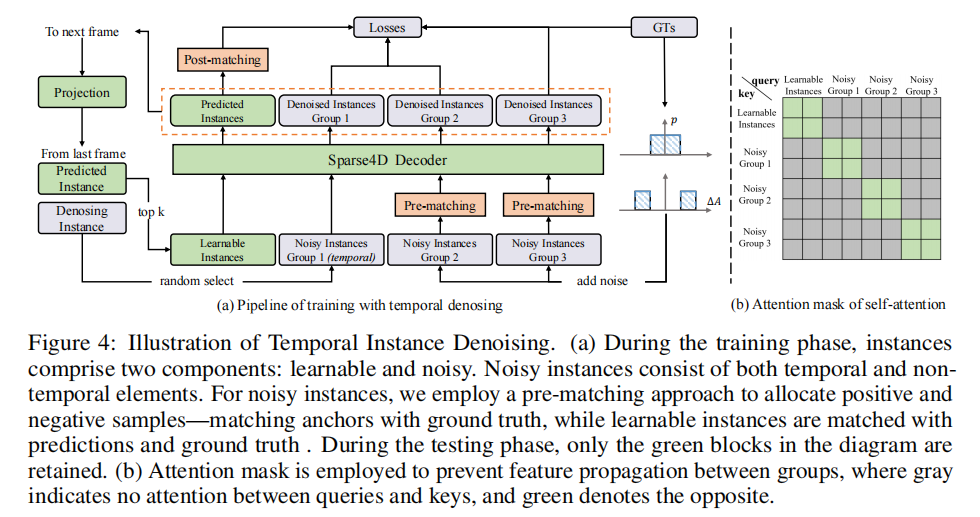
Sparse4D 中,实例(查询)被解耦为隐式实例特征和显式锚点(Anchor)。训练过程中,锚点分为两类:
- 可学习锚点:通过 K-Means 方法在检测空间中均匀分布,作为可学习参数;
- 带噪声锚点:对真实标签(GT)添加噪声生成,具体公式如下:
- 设 N 为真实标签数量,M 为噪声实例组数,
为随机噪声;
- 设 N 为真实标签数量,M 为噪声实例组数,
为避免噪声样本的正负样本分配歧义(如 DINO 中可能更接近真实标签),Sparse4D v3 对每组带噪声锚点(
)和真实标签锚点(
)采用二分图匹配,明确划分正负样本。
3.1.3 时序传播扩展
为适配稀疏循环训练过程,Sparse4D v3 将单帧噪声实例通过时序传播扩展到多帧:
- 每帧训练时,随机选择
- 传播策略与非噪声实例一致:锚点经过自车姿态和速度补偿,实例特征直接作为下一帧特征的初始化;
- 各组实例保持相互独立,噪声实例与正常实例之间无特征交互,避免歧义(如图 4 (b) 所示)。
时序实例去噪的训练流程如图 4 (a) 所示,测试阶段仅保留可学习实例相关的计算模块。
3.2 质量估计(Quality Estimation)
3.2.1 核心问题
现有稀疏方法主要通过分类置信度衡量预测框与真实标签的对齐程度,但不同正样本的匹配质量差异较大,分类置信度无法准确反映预测框的实际质量,导致检测结果排序不合理,影响最终性能。
3.2.2 质量指标定义
为让网络理解正样本质量,Sparse4D v3 引入两个 3D 检测专属质量指标:
- 中心度(Centerness):衡量预测框中心与真实标签中心的对齐程度;
- 朝向一致性(Yawness):通过预测朝向的正弦和余弦值定义,公式为:
3.2.3 损失函数设计
网络除输出分类置信度外,还需预测中心度和朝向一致性,对应的损失函数分别为:
- 中心度损失:交叉熵损失(Cross-Entropy Loss);
- 朝向一致性损失:焦点损失(Focal Loss),用于缓解类别不平衡问题。
通过质量估计,检测结果的排序更加合理,收敛速度和检测精度均得到提升。
3.3 解耦注意力(Decoupled Attention)
3.3.1 传统注意力的问题
Sparse4D v2 中,锚点嵌入(Anchor Embedding)和实例特征(Instance Feature)通过加法融合后参与注意力计算,导致注意力权重出现异常值(如图 3 第一行所示)。例如,红色圆圈中的行人与绿色框中的目标车辆产生非预期关联,无法准确反映目标特征间的相关性,进而影响特征聚合效果。

3.3.2 解耦注意力设计
为解决特征干扰问题,Sparse4D v3 提出解耦注意力机制,核心改进是将 "加法融合" 改为 "拼接融合",具体架构如图 5 所示:
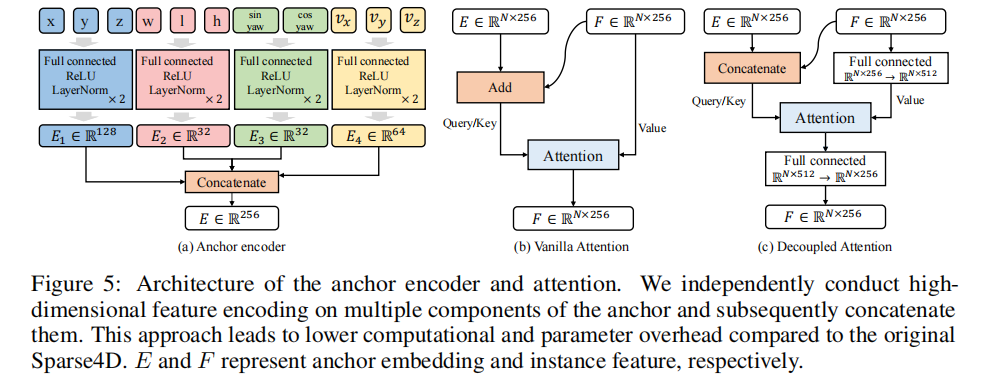
- 锚点编码器(Anchor Encoder):对锚点的多个组件分别进行高维特征编码,再进行拼接,相比原始 Sparse4D 降低了计算量和参数开销;
- 注意力计算:在查询间注意力(而非查询 - 图像特征的交叉注意力)中,采用拼接方式融合锚点嵌入(E)和实例特征(F),避免特征叠加导致的干扰。
与 Conditional DETR 的区别:
- 改进对象不同:Conditional DETR 优化查询与图像特征的交叉注意力,而 Sparse4D v3 聚焦查询间注意力;
- 编码层级不同:Conditional DETR 在单头注意力层面拼接位置嵌入和查询特征,Sparse4D v3 在多头注意力层面进行外部修改,赋予网络更大灵活性。
3.4 端到端跟踪扩展(Extend to Tracking)
3.4.1 核心思路
Sparse4D v2 的时序建模采用循环形式,前一帧的实例会被投影到当前帧作为输入,这些时序实例与基于查询的跟踪器中的 "跟踪查询" 类似,但无需高置信度阈值筛选,包含大量冗余实例。Sparse4D v3 利用这一特性,将 "检测框" 重新定义为 "轨迹"(包含 ID 和每帧的检测框),通过简单的 ID 分配实现端到端跟踪。
3.4.2 跟踪流程
跟踪流程如算法 1 所示,核心步骤如下:
- 输入:传感器数据、时序实例(包含置信度 c、锚点框 a、ID)、当前帧实例;
- 模型前向传播:生成检测结果
- ID 分配:若实例置信度超过阈值
- 时序实例更新:从
- 生命周期管理:通过 Sparse4D v2 原有的 top-k 策略自动处理实例的增减,无需额外修改。
3.4.3 关键优势
- 无需修改训练过程:跟踪功能完全在推理阶段实现,检测器训练与跟踪任务解耦;
- 无需跟踪标签:无需提供 ID 的真实标签,仅通过置信度阈值触发 ID 分配;
- 兼容性强:可直接复用检测模型的时序建模能力,无需额外微调。
算法 1 Sparse4D v3 的跟踪流程

四、实验验证
4.1 实验设置
4.1.1 基准数据集
采用 nuScenes 数据集,包含 1000 个场景,训练集 700 个、验证集 150 个、测试集 150 个。每个场景为 20 秒的视频片段(2 FPS),包含 6 个视角的图像,标注了 3D 边界框、车辆运动状态和相机参数。
4.1.2 评价指标
- 3D 检测指标:平均精度(mAP)、平移误差(mATE)、尺度误差(mASE)、朝向误差(mAOE)、速度误差(mAVE)、属性误差(mAAE)、nuScenes 检测分数(NDS,其他指标的加权平均);
- 多目标跟踪指标:平均多目标跟踪精度(AMOTA)、平均多目标跟踪误差(AMOTP)、召回率(Recall)、ID 切换次数(IDS)、多目标跟踪准确率(MOTA)等。
4.1.3 实现细节
- 解码器:6 层结构,包含 900 个实例和 600 个时序实例,嵌入维度 256;
- 关键点:7 个固定关键点 + 6 个可学习关键点;
- 跟踪参数:置信度阈值 T=0.25,置信度衰减系数 S=0.6;
- 去噪参数:噪声实例组数 M=5,随机选择 3 组作为时序去噪实例;
- 训练配置:AdamW 优化器,训练 100 个 epoch,采用顺序迭代训练方式,无需 CBGS(Class-Balanced Grouping and Sampling)。
4.2 3D 检测性能
4.2.1 验证集结果
表 1 展示了 nuScenes 验证集上的 3D 检测结果,对比不同骨干网络和图像尺寸的性能:
- 基础配置(ResNet50+256×704):Sparse4D v3 的 mAP 达到 46.9%(+3.0% vs Sparse4D v2),NDS 达到 56.1%(+2.2% vs Sparse4D v2),同时保持 19.8 FPS 的推理速度,与 Sparse4D v2 接近;
- 增强配置(ResNet101+512×1408):Sparse4D v3 的 mAP 提升至 53.7%(+3.2% vs Sparse4D v2),NDS 达到 62.3%(+2.9% vs Sparse4D v2),推理速度 8.2 FPS,优于采用全局注意力的 StreamPETR(6.4 FPS)。
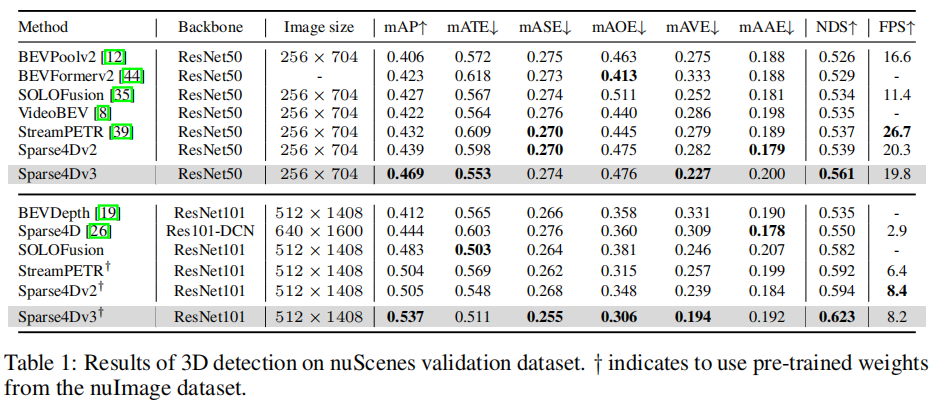
注:†表示使用 nuImage 数据集的预训练权重。
4.2.2 测试集结果
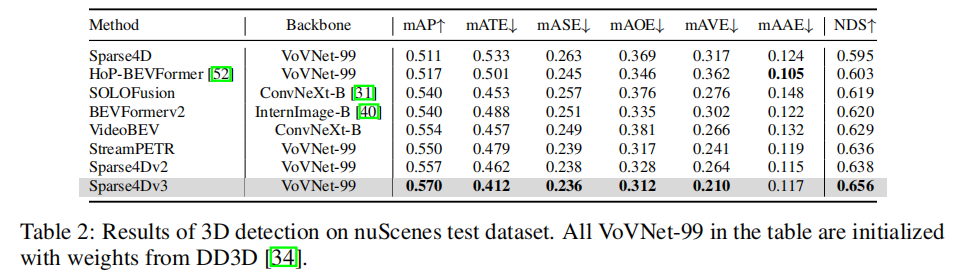
表 2 展示了 nuScenes 测试集的 3D 检测结果(骨干网络为 VoVNet-99,预训练权重来自 DD3D,图像尺寸 640×1600):
- Sparse4D v3 的 mAP 达到 57.0%(+1.3% vs Sparse4D v2),NDS 达到 65.6%(+1.8% vs Sparse4D v2),在所有对比方法中排名第一;
- 平移误差(mATE)表现突出(0.412),显著优于密集 BEV 算法,这主要归功于质量估计带来的置信度排序稳定性提升。
4.3 3D 多目标跟踪性能
4.3.1 验证集结果
表 3 展示了 nuScenes 验证集的跟踪结果,Sparse4D v3 在不同配置下均表现优异:
- 基础配置(ResNet50+256×704):AMOTA 达到 49.0%,比 SOTA 方法 DORT 高 6.6%,比端到端方法 DQTrack 高 16.0%,ID 切换次数仅 430(比 DQTrack 减少 44.5%);
- 增强配置(ResNet101+512×1408):AMOTA 提升至 56.7%,召回率达到 65.8%,AMOTP 降至 1.027,各项指标均为当前最优。
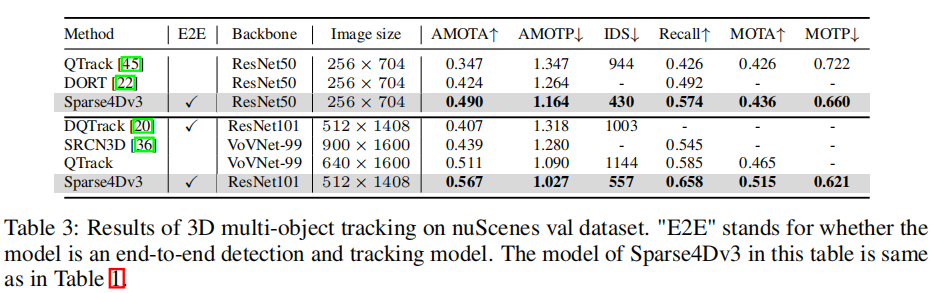
注:E2E 表示是否为端到端模型。
4.3.2 测试集结果
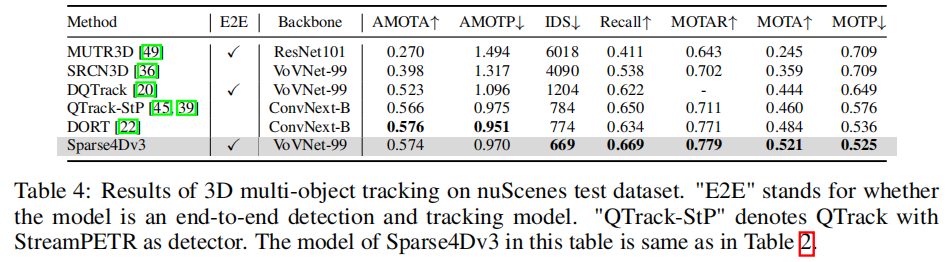
表 4 展示了 nuScenes 测试集的跟踪结果,Sparse4D v3(骨干网络 VoVNet-99)的表现如下:
- AMOTA 达到 57.4%,与 SOTA 方法 DORT(57.6%)接近,且是唯一的端到端模型;
- ID 切换次数仅 669,显著低于 DQTrack(1204)和 QTrack-StP(784);
- 召回率(66.9%)和 MOTA(521%)均为当前最优,展现出极强的跟踪稳定性。
4.4 消融实验
为验证各改进策略的有效性,论文进行了消融实验(基础模型为 Sparse4D v2,配置 ResNet50+256×704),结果如表 5 所示:
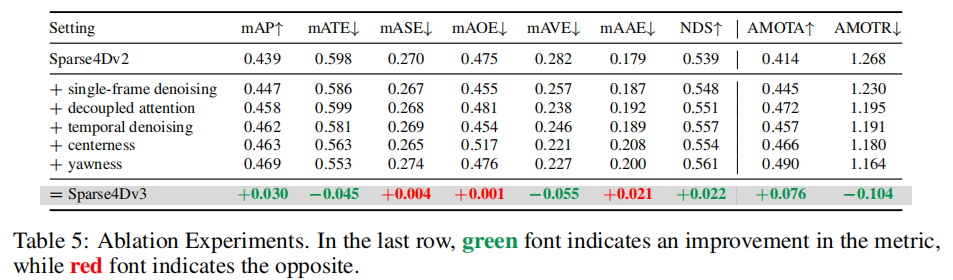
注:最后一行绿色表示指标提升,红色表示指标下降。
消融实验结论:
- 去噪任务:单帧去噪使 mAP 提升 0.8%、NDS 提升 0.9%;时序去噪使 mAP 提升 0.4%、NDS 提升 0.6%,两者共同作用稳定了正样本匹配并增加了正样本数量;
- 解耦注意力:主要提升 mAP(+1.1%)和 mAVE(-1.9%),有效减少了特征干扰;
- 质量估计:中心度使平移误差减少 1.8%,但恶化了朝向误差;朝向一致性缓解了这一问题,两者结合使 mAP 提升 0.8%、mATE 减少 2.8%、mAVE 减少 1.9%;
- 综合效果:三大策略结合后,mAP 提升 3.0%,NDS 提升 2.2%,AMOTA 提升 7.6%,验证了各模块的协同作用。
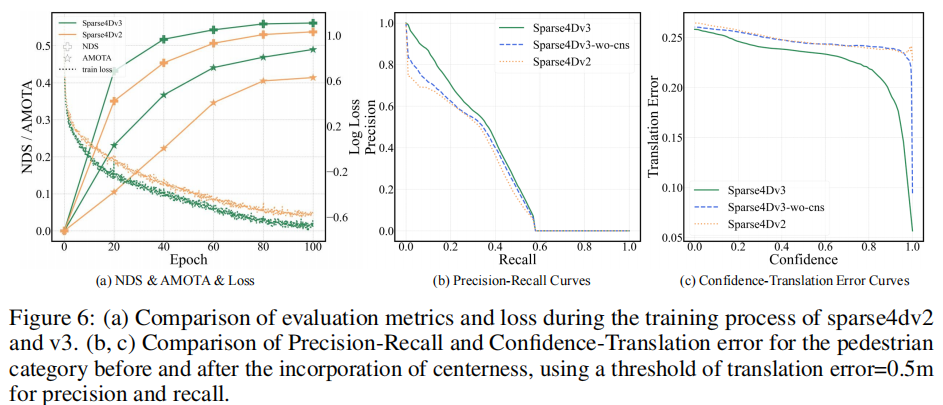
此外,训练曲线对比(图 6 (a))显示,Sparse4D v3 的收敛速度和最终收敛精度均显著优于 Sparse4D v2。引入中心度后,检测结果的 Precision-Recall 曲线(图 6 (b))和置信度 - 平移误差曲线(图 6 (c))均得到优化,尤其在低召回率和高阈值场景下,平移误差显著降低。
4.5 云环境性能提升
在云环境中,可利用更大的计算资源进一步提升性能。论文采用两种优化方式:
- 融合未来帧特征:借鉴 Sparse4D v1 的多帧采样方法,融合后续 8 帧的特征;
- 采用更大骨干网络:使用预训练更充分的 EVA02-Large 作为骨干网络,增强语义特征提取能力。
实验结果如表 6 所示(图像尺寸 640×1600):
- EVA02-Large + 未来 8 帧:mAP 达到 66.8%,NDS 达到 71.9%,AMOTA 达到 67.7%;
- 性能超越部分激光雷达模型:NDS 和 mAVE 指标优于纯激光雷达模型 TransFusion-L,验证了纯视觉方案的潜力。
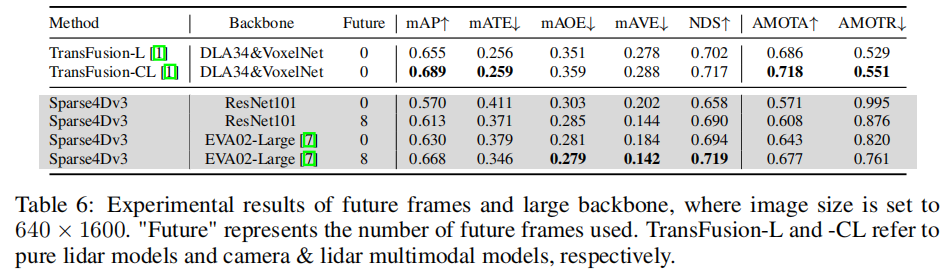
注:TransFusion-L 为纯激光雷达模型,TransFusion-CL 为激光雷达 - 相机多模态模型。
五、结论与未来展望
5.1 结论
Sparse4D v3 通过三大核心改进,实现了 3D 检测与端到端跟踪性能的显著提升:
- 时序实例去噪解决了稀疏算法正样本不足和收敛不稳定的问题;
- 质量估计优化了检测结果的置信度排序,降低了平移和速度误差;
- 解耦注意力减少了特征干扰,提升了特征聚合的准确性;
- 端到端跟踪扩展无需修改训练流程,实现了检测与跟踪的无缝融合。
在 nuScenes 基准测试中,Sparse4D v3 在纯视觉方案中达到 SOTA 性能,同时保持了较高的推理效率,为自动驾驶感知系统提供了高效、准确的解决方案。
5.2 未来展望
论文提出了以下四个值得进一步研究的方向:
- 跟踪性能优化:当前跟踪方案较为基础,可进一步提升跟踪精度和稳定性;
- 多模态扩展:将 Sparse4D 扩展为纯激光雷达或激光雷达 - 相机多模态模型;
- 下游任务集成:在端到端跟踪基础上,引入预测、规划等下游任务;
- 更多感知任务融合:集成在线地图构建、2D 交通标志和信号灯检测等任务。
六、总结
Sparse4D v3 作为 Sparse4D 系列的最新版本,通过对训练策略、注意力机制和跟踪功能的深度优化,构建了一个高效、精准的端到端 3D 感知框架。其核心创新在于将 2D 检测中的去噪思想扩展到 3D 时序场景,并通过解耦注意力和质量估计解决了稀疏表示带来的固有问题,同时以极简的方式实现了端到端跟踪。实验结果证明,该框架在性能和效率上均具备显著优势,为自动驾驶纯视觉感知系统的落地提供了重要参考。