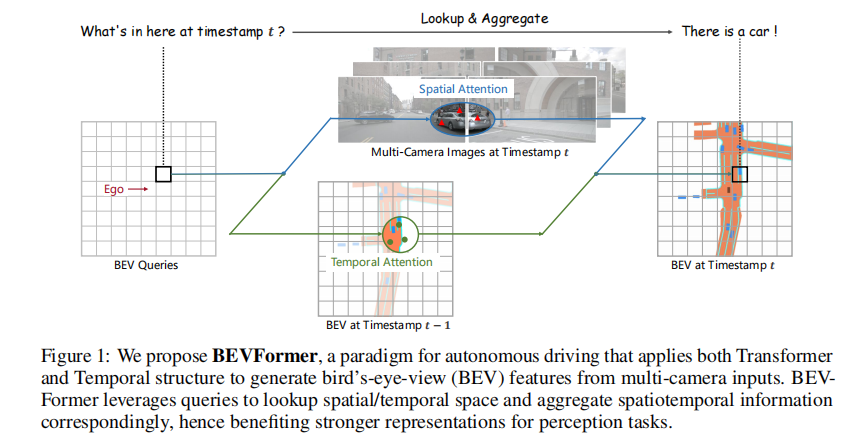
在自动驾驶感知任务中,基于多相机图像的 3D 目标检测和地图分割等任务是核心支撑技术。传统方法要么依赖激光雷达(LiDAR)导致部署成本高昂,要么基于单目相机框架无法有效融合多视角信息,要么在 BEV(Bird's-Eye-View,鸟瞰图)特征生成中过度依赖深度信息导致误差累积。针对这些痛点,上海 AI 实验室、南京大学等机构联合提出了 BEVFormer 框架,通过时空 Transformer 从多相机图像中学习统一的 BEV 表征,为自动驾驶多感知任务提供了高效解决方案。
原文链接:https://arxiv.org/pdf/2203.17270
代码链接:https://github.com/fundamentalvision/BEVFormer
沐小含持续分享前沿算法论文,欢迎关注...
一、论文核心背景与动机
1.1 自动驾驶 3D 感知的核心挑战
自动驾驶系统需要精准理解周围环境的 3D 结构,包括目标位置、尺寸、速度以及道路拓扑等信息。当前 3D 感知方案主要分为两类:
- LiDAR-based 方法:精度高、直接获取 3D 点云,但硬件成本昂贵,且在识别交通灯等视觉语义元素时存在局限。
- Camera-based 方法:成本低、覆盖范围广、语义信息丰富,但从 2D 图像推断 3D 结构属于病态问题,传统方案存在诸多缺陷:
- 单目相机框架 + 跨相机后处理:无法捕捉多视角关联信息,性能和效率低下;
- 基于深度估计的 BEV 生成方法:依赖深度值或深度分布的准确性,误差累积严重;
- 缺乏有效的时序信息利用:现有多相机 3D 检测方法大多忽略时序线索,难以准确估计目标速度和检测遮挡目标。
1.2 核心动机
BEVFormer 的设计动机源于两个关键洞察:
- BEV 表征的统一性价值:BEV 视角能清晰呈现目标的位置和尺度关系,是连接感知与规划的理想桥梁,可同时支撑 3D 检测、地图分割等多个任务;
- 时空信息的互补性:空间信息(多相机视角)提供当前环境的全局结构,时序信息(历史 BEV 特征)辅助推断目标运动状态和遮挡区域,二者结合可显著提升感知鲁棒性;
- Transformer 的动态聚合能力:Transformer 的注意力机制能够动态聚合关键特征,无需依赖固定的 3D 先验或精确深度估计,适合自适应学习 BEV 特征。
二、BEVFormer 核心技术原理
BEVFormer 的核心目标是通过时空 Transformer 编码器,将多相机图像特征和历史 BEV 特征聚合为统一的 BEV 表征,同时支撑 3D 检测和地图分割任务。其整体架构如图 2 所示,主要包含三大核心组件:BEV 查询(BEV Queries)、空间交叉注意力(Spatial Cross-Attention)和时序自注意力(Temporal Self-Attention)。
2.1 整体架构流程
在时间戳 时刻,BEVFormer 的工作流程如下:
- 多相机图像经骨干网络(如 ResNet-101)提取特征
,其中
- 保存前一时刻
- 6 个堆叠的编码器层对 BEV 查询进行迭代优化:
- 时序自注意力:BEV 查询从历史 BEV 特征
- 空间交叉注意力:BEV 查询从多相机特征
- 前馈网络(Feed Forward):对聚合后的特征进行非线性变换;
- 时序自注意力:BEV 查询从历史 BEV 特征
- 最终生成当前时刻的统一 BEV 特征
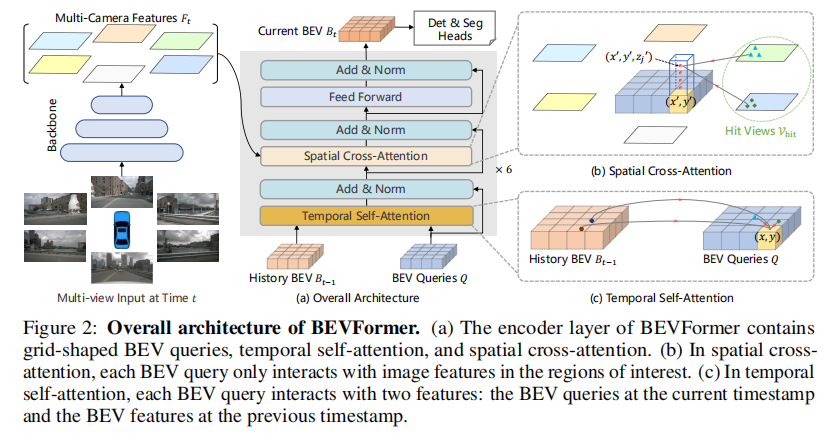
- (a) 编码器层包含网格状 BEV 查询、时序自注意力和空间交叉注意力;
- (b) 空间交叉注意力中,每个 BEV 查询仅与多相机图像中的感兴趣区域交互;
- (c) 时序自注意力中,每个 BEV 查询同时与当前查询和历史 BEV 特征交互。
2.2 核心组件详解
2.2.1 BEV 查询(BEV Queries)
BEV 查询是预定义的网格状可学习参数,形式为,其中:
- C为特征维度(默认 256);
- 每个查询
- BEV 网格的每个单元对应真实世界的尺寸为
- 为增强位置感知能力,在输入编码器前为 BEV 查询添加可学习的位置嵌入(Positional Embedding)。
2.2.2 空间交叉注意力(Spatial Cross-Attention, SCA)
空间交叉注意力的核心目标是高效聚合多相机图像中的空间特征,解决传统全局注意力计算成本过高的问题。其设计基于可变形注意力(Deformable Attention),并针对 3D 场景进行适配,具体流程如下:
-
3D 参考点生成 :将 BEV 查询
-
相机视角投影 :通过相机的投影矩阵
-
有效视角筛选 :仅保留投影点落在图像有效区域内的相机(称为 "命中视角"
-
可变形注意力聚合:对每个命中视角,围绕投影点采样局部区域特征,通过可变形注意力计算加权和,最终聚合为该 BEV 查询的空间特征。
空间交叉注意力的数学表达为
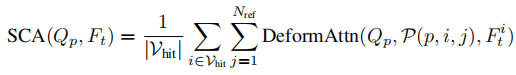
其中DeformAttn为可变形注意力函数,通过预测参考点偏移量和注意力权重
,高效聚合局部特征,平衡感受野与计算成本。
2.2.3 时序自注意力(Temporal Self-Attention, TSA)
时序自注意力旨在利用历史 BEV 特征提升当前感知性能,解决目标速度估计和遮挡检测问题,其设计灵感源于循环神经网络(RNN)的隐藏状态传递机制,具体流程如下:
-
历史 BEV 特征对齐 :由于自车在
-
时序特征聚合 :BEV 查询
-
边界情况处理 :对于序列的第一帧(无历史BEV特征),时序自注意力退化为普通自注意力,即当前BEV查询
时序自注意力的数学表达为:
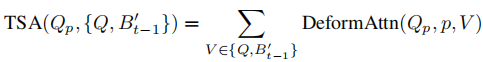
其中偏移量由当前查询
和历史特征
的拼接结果预测,确保时序关联的准确性。
2.3 任务头设计
BEVFormer 的 BEV 特征具有极强的通用性,可通过简单适配的任务头支持 3D 检测和地图分割:
2.3.1 3D 检测头
基于可变形 DETR 设计端到端检测头,主要修改包括:
- 输入:单尺度 BEV 特征
- 输出:3D 边界框(中心坐标
- 损失函数:仅使用
- 推理时保留置信度最高的 300 个预测框。
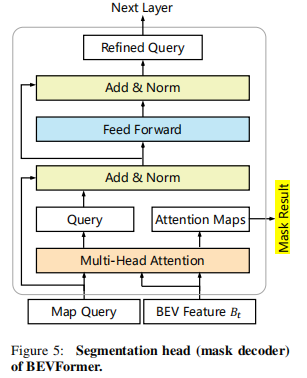
2.3.2 地图分割头
基于 Panoptic SegFormer 的掩码解码器设计,核心思路:
-
为每个语义类别(如车辆、道路、车道线)分配一个可学习的类别查询;
-
通过多头注意力机制,从 BEV 特征
-
支持的语义类别包括车辆、可行驶区域、车道线等自动驾驶关键元素。
2.4 训练与推理细节
2.4.1 训练阶段
- 数据采样:对每个时间戳
- 梯度计算:仅对
- 优化器:AdamW,权重衰减
- 学习率:初始学习率
- 训练轮次:24 个 epoch。
2.4.2 推理阶段
- 按时间顺序处理视频序列,保存前一帧的 BEV 特征供当前帧使用;
- 推理速度高效,与主流相机 - based 方法(如 DETR3D、FCOS3D)相当。
三、实验验证与结果分析
3.1 实验设置
3.1.1 数据集
- nuScenes:1000 个场景(每个约 20 秒),6 个相机(360° 水平视场),1.4M 个 3D 标注框(10 个类别),评估指标包括 NDS(nuScenes 检测分数)、mAP、mATE(平均平移误差)等;
- Waymo Open Dataset:798 个训练序列、202 个验证序列,5 个相机(252° 水平视场),仅评估车辆类别,评估指标包括 APH(带航向信息的平均精度)、3D IoU(阈值 0.5/0.7)。
3.1.2 基线模型
- VPN:基于多层感知器(MLP)的跨视角语义分割方法;
- Lift-Splat:基于深度分布的 BEV 生成方法;
- DETR3D:基于 3D 查询的多相机 3D 检测方法;
- BEVFormer-S:BEVFormer 的静态版本(时序自注意力替换为普通自注意力,不使用历史 BEV 特征)。
3.1.3 模型配置
- 骨干网络:ResNet101-DCN 或 VoVnet-99;
- FPN 输出:多尺度特征(1/16、1/32、1/64),特征维度 256;
- BEV 查询尺寸:nuScenes(200×200)、Waymo(300×220);
- 3D 参考点数量
3.2 核心实验结果
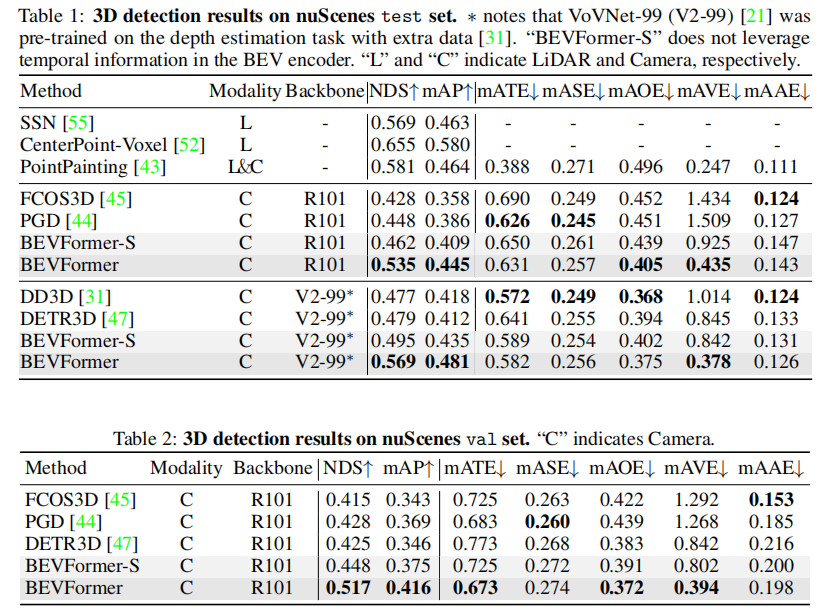
3.2.1 3D 目标检测性能(nuScenes)
表 1 和表 2 展示了 nuScenes 测试集和验证集的 3D 检测结果,核心结论如下:
- BEVFormer 在测试集上达到 56.9% NDS,比之前的 SOTA 方法 DETR3D 高 9.0 个百分点(56.9% vs. 47.9%);
- 在验证集上,BEVFormer 的 NDS 达到 51.7%,比 DETR3D 高 9.2 个百分点(51.7% vs. 42.5%);
- 速度估计性能突出:mAVE(平均速度误差)仅为 0.378 m/s,远超其他相机 - based 方法,接近 LiDAR-based 方法(如 PointPainting 的 0.35 m/s);
- BEVFormer-S(无时序信息)的 NDS 为 44.8%,验证了时序自注意力的显著增益(51.7% - 44.8% = 6.9 个百分点)。
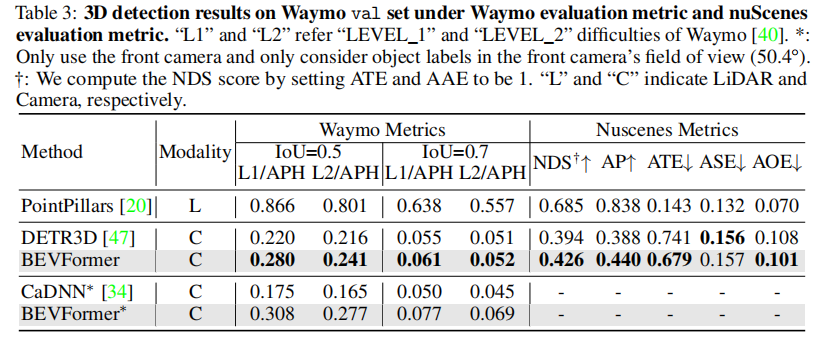
3.2.2 Waymo 数据集性能
表 3 展示了 Waymo 验证集的车辆检测结果,核心结论:
- 在 IoU=0.5 的 LEVEL_1 和 LEVEL_2 难度下,BEVFormer 的 APH 分别比 DETR3D 高 6.0% 和 2.5%(0.280 vs. 0.220,0.241 vs. 0.216);
- 采用 nuScenes 指标评估时,BEVFormer 的 NDS 比 DETR3D 高 3.2 个百分点(0.426 vs. 0.394);
- 与单目 3D 检测方法 CaDNN 相比,BEVFormer 在 LEVEL_1 和 LEVEL_2 难度下的 APH 分别高 13.3% 和 11.2%,验证了多相机融合的优势。
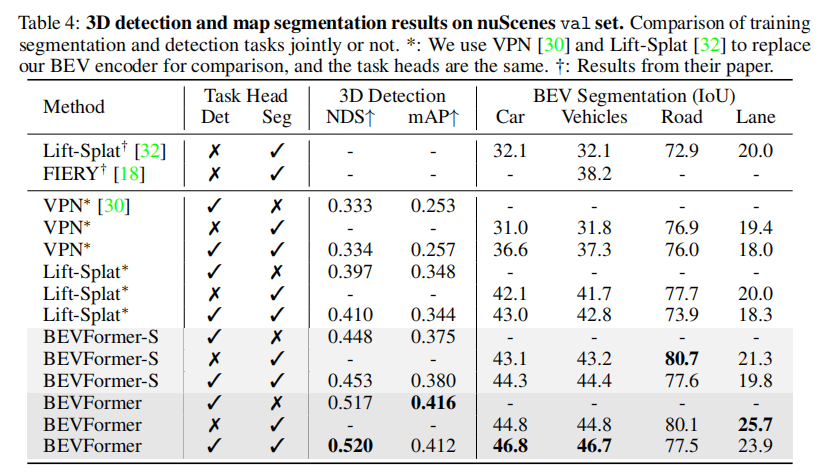
3.2.3 多任务感知性能
表 4 展示了 3D 检测和地图分割联合训练的结果,核心结论:
- BEVFormer 在联合训练下仍保持优异性能,NDS 达到 52.0%,比 Lift-Splat * 高 11.0 个百分点(52.0% vs. 41.0%);
- 车道分割 IoU 达到 23.9%,比 Lift-Splat * 高 5.6 个百分点(23.9% vs. 18.3%);
- 多任务训练通过共享骨干网络和 BEV 编码器,节省了计算成本和推理时间,但存在轻微的负迁移现象(道路和车道分割性能略低于单独训练)。
3.3 消融实验分析
3.3.1 空间交叉注意力的有效性
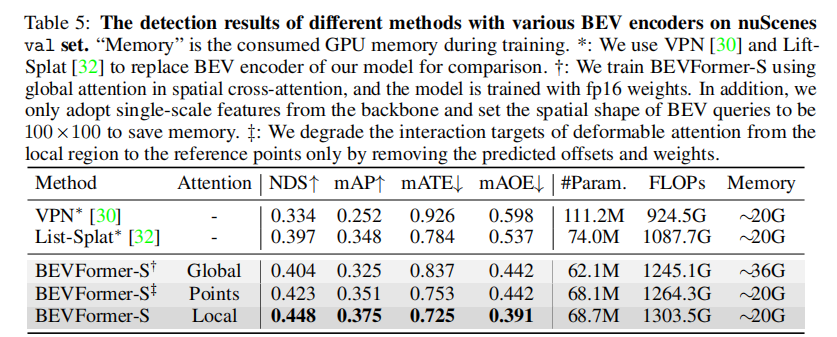
表 5 对比了不同注意力机制在 BEVFormer-S 上的性能,核心结论:
- 可变形注意力(BEVFormer-S)的 NDS(0.448)显著高于全局注意力(0.404)和点交互注意力(0.423);
- 全局注意力虽鲁棒性强,但计算成本极高(GPU 内存消耗~36G);
- 点交互注意力仅关注参考点特征,感受野有限,性能受限;
- 可变形注意力通过采样局部感兴趣区域,平衡了感受野、计算成本和鲁棒性。
3.3.2 时序自注意力的有效性
图 3 展示了不同可见度子集(0-40%、40-60%、60-80%、80-100%)的检测性能,核心结论:
- 时序信息显著提升低可见度目标的召回率:在 0-40% 可见度子集上,BEVFormer 的召回率比 BEVFormer-S 和 DETR3D 高 6 个百分点以上;
- 时序信息改善目标平移误差(mATE)、航向角误差(mAOE)和速度误差(mAVE),但对尺度误差(mASE)影响较小;
- 验证了时序信息在遮挡检测和运动状态估计中的核心作用。
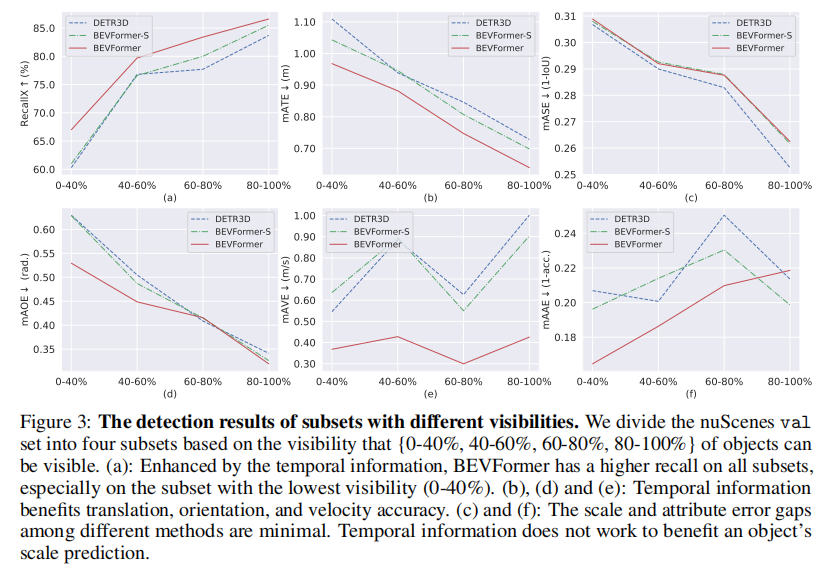
- (a) 召回率对比(低可见度子集差距最显著);
- (b)(d)(e) 平移、航向角、速度误差对比;
- (c)(f) 尺度、属性误差对比(差距较小)。
3.3.3 模型尺度与推理 latency 权衡
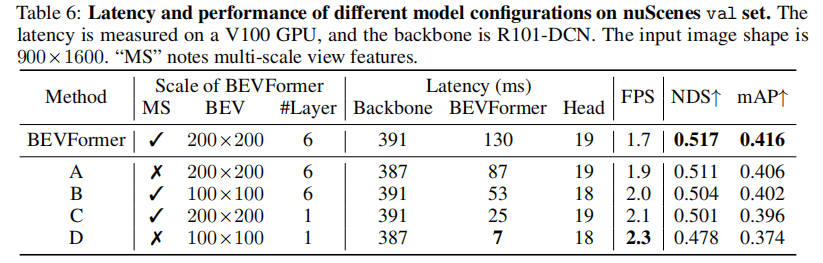
表 6 展示了不同模型配置的性能与 latency 对比(V100 GPU,输入图像 900×1600),核心结论:
- 默认配置(多尺度特征、200×200 BEV 查询、6 层编码器):latency 130ms,NDS 51.7%;
- 轻量化配置 D(单尺度特征、100×100 BEV 查询、1 层编码器):latency 仅 7ms,NDS 47.8%(仅下降 3.9 个百分点);
- 模型具有极强的灵活性,可通过调整 BEV 查询尺寸、编码器层数、特征尺度等参数,在性能和效率间灵活权衡。
3.3.4 对相机外参噪声的鲁棒性
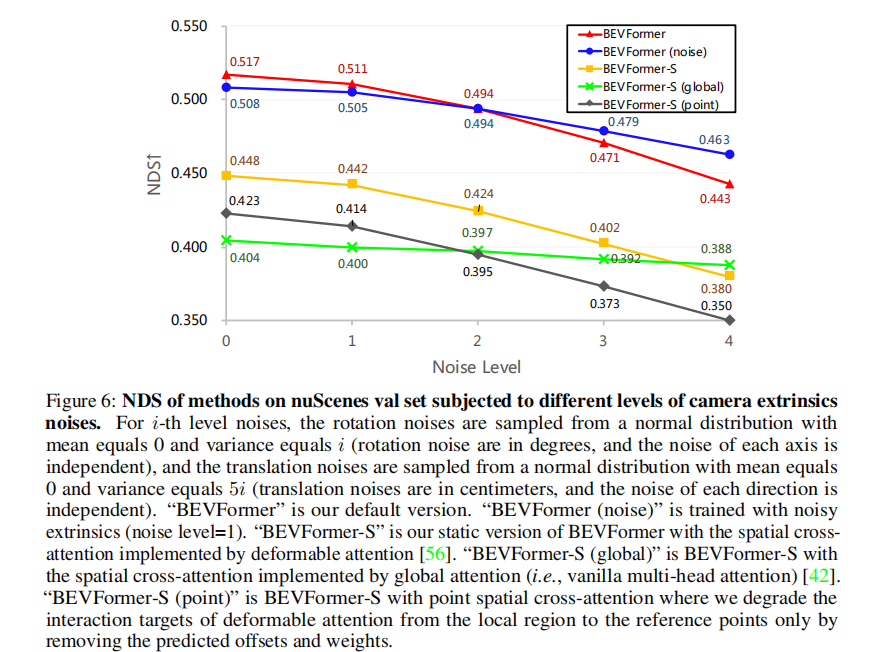
图 6 展示了不同相机外参噪声水平下的 NDS 变化,核心结论:
- 随着噪声水平提升(0-4 级),所有方法的性能均下降,但 BEVFormer 的鲁棒性最优;
- 噪声水平为 4 时,BEVFormer 的 NDS 仅下降 14.3%(从 0.517 降至 0.443),低于 BEVFormer-S(15.2%)和 BEVFormer-S(point)(17.3%);
- 若训练时引入噪声(BEVFormer (noise)),鲁棒性进一步提升,噪声水平 4 时 NDS 下降仅 8.9%;
- 采用全局注意力的 BEVFormer-S(global)鲁棒性最强,噪声水平 4 时 NDS 下降仅 4.0%,验证了全局注意力对相机标定误差的耐受性。
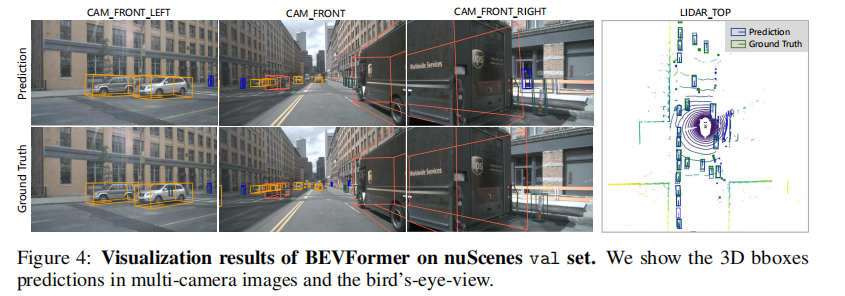
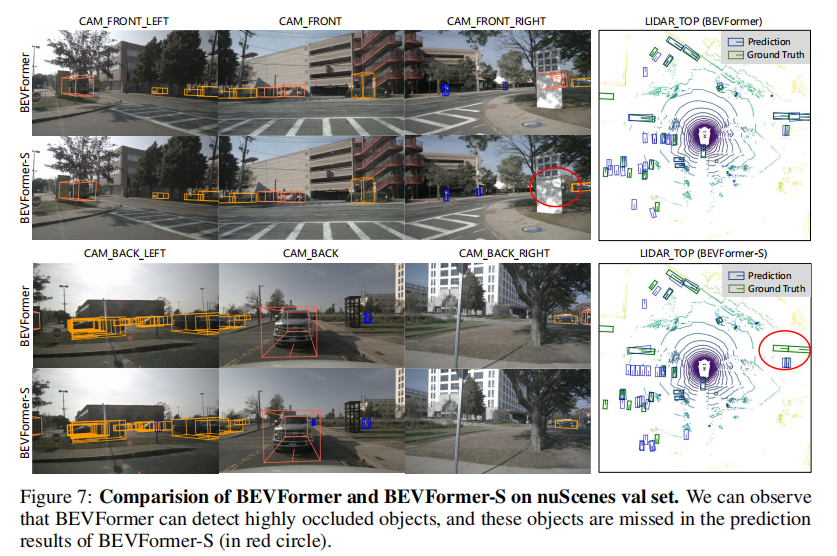
3.4 可视化结果
图 4 和图 7 展示了 BEVFormer 的定性结果,核心结论:
- BEVFormer 能准确检测多相机图像中的 3D 目标,生成的 BEV 边界框与真实场景高度吻合;
- 时序信息帮助 BEVFormer 检测到 BEVFormer-S 遗漏的遮挡目标(如图 7 中被广告牌遮挡的两辆公交车);
- 地图分割结果与 3D 检测结果高度一致,验证了 BEV 特征的统一性和有效性。
四、核心贡献与局限性
4.1 核心贡献
- 提出 BEVFormer 框架,首次将时空 Transformer 用于多相机 BEV 表征学习,统一支撑 3D 检测和地图分割任务;
- 设计网格状 BEV 查询,结合空间交叉注意力和时序自注意力,高效聚合多相机空间特征和历史时序特征;
- 在 nuScenes 和 Waymo 数据集上取得 SOTA 性能,NDS 达到 56.9%(nuScenes 测试集),接近 LiDAR-based 方法,同时显著提升速度估计和低可见度目标检测性能;
- 模型具有极强的灵活性和鲁棒性,可通过调整配置权衡性能与效率,对相机标定误差具有较强耐受性。
4.2 局限性
- 与 LiDAR-based 方法仍存在性能差距,尤其在复杂天气(如雨、雾)和极端光照条件下,3D 位置估计精度有待提升;
- 推理速度仍受限于骨干网络,多相机图像特征提取的计算成本较高,难以满足毫秒级实时性需求;
- 多任务训练存在负迁移现象,道路和车道分割性能略低于单独训练,需进一步优化任务融合策略。
五、总结与展望
BEVFormer 通过时空 Transformer 的创新设计,突破了传统相机 - based 3D 感知的诸多瓶颈,为自动驾驶感知提供了一种低成本、高性能的统一解决方案。其核心洞察 ------BEV 表征作为时空信息的融合载体------ 为后续研究指明了重要方向。未来可进一步探索:
- 高效骨干网络设计,降低多相机特征提取的计算成本;
- 更先进的时序融合策略,如引入 Transformer-XL 等长效依赖建模机制;
- 多模态融合(如融合雷达、超声波传感器数据),进一步提升恶劣环境下的感知鲁棒性;
- 端到端感知 - 规划一体化,利用 BEV 表征的统一性连接感知与决策模块,推动自动驾驶系统的全栈优化。
BEVFormer 的开源代码(https://github.com/fundamentalvision/BEVFormer)为后续研究提供了强大的基线,有望成为自动驾驶 3D 感知领域的里程碑工作。