AOM-2721是一款开放标准模块(OSM),其采用OSM 1.1标准。作为紧凑且高度集成的计算平台,AOM-2721尤其适用于嵌入式应用与边缘人工智能场景。
一 准备
1.硬件:
AOM-2721 OSM开发套件,采用 高通跃龙 QCS6490处理器
- 高通8核Kryo CPU,高达2.7GHz
- Hexagon Tensor处理器,12 TOPS AI算力
- Adreno VPU 633, 4K30 编码/ 4K60解码 H.264/265
- Adreno GPU 643, OpenGL ES3.2/OpenCL 2.0
- 板载8GB LPDDR5 内存, 8533MT/s
- 板载128GB UFS + 128GB eMMC存储
- I/O接口: 1 x HDMI 1920 x 1080 @60Hz, 1 x DP 1920x1080 @60Hz, 2 x 4-Lan MIPI-CSI, 1 x USB 3.2 Gen1, 2 x PCIe Gen3x1, 1 x PCIe Gen3 x2, and 2 x GbE
一套x86开发机,16GB RAM和350GB存储空间
一个全高清HDMI显示器和一根HDMI电缆
一套USB键盘和鼠标
2.软件:
用于x86开发机器的Ubuntu 20.04或22.04
Docker引擎用于x86机器的开发
研华Edge AI SDK/推理套件用于AOM-2721(下载;安装说明)
本文涵盖了三个主要主题以及详细的方法:
1. 如何在AOM-2721上启用AI运行
- 编译Yocto OS镜像(通过开发机)
- 安装Yocto操作系统(通过Windows主机)
- 在AOM- 2721上设置AI运行时
2. 如何使用研华Edge AI SDK中的无代码工具快速评估AI性能
- 在AOM-2721上启动Edge AI SDK/Inference Kit
- 启动用于检测物体的视觉AI
- 监控工作负荷并运行基准
3. 如何为实际应用开发AI示例工作流:
- 使用高通AI Hub云服务
- 在AOM-2721上部署Qualcomm AI Hub模型,用于AI任务
- 在AOM-2721上集成开源的YOLO模型,用于AI任务
二 Edge Impulse 设计脉冲(Impulse)
1.导航至"实验"页面,通过点击"创建新脉冲"来准备创建新的脉冲流。
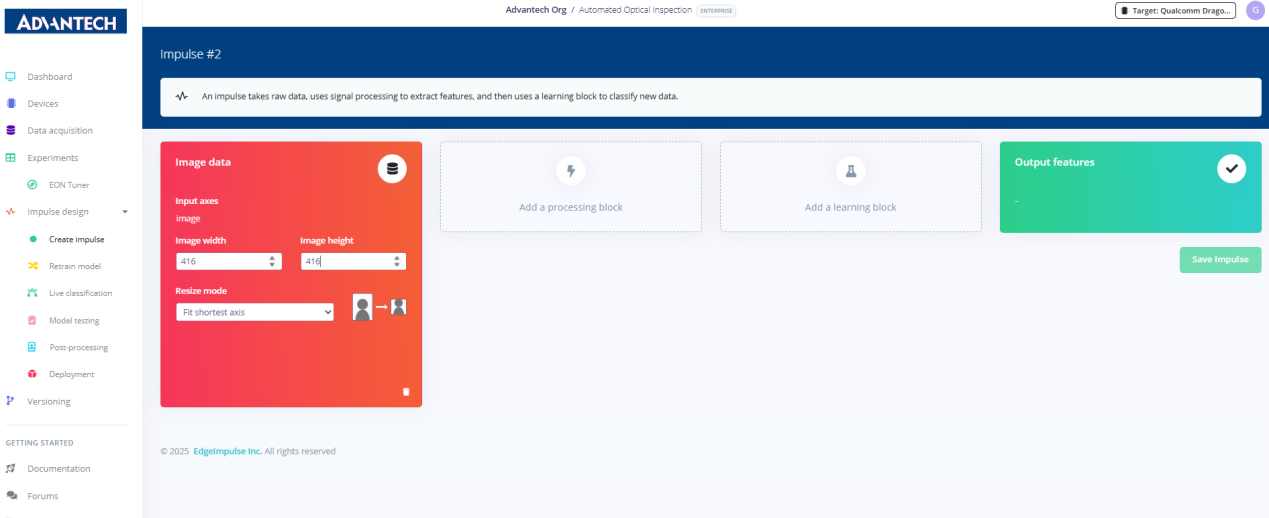
2.在脉冲配置页面中,将输入图像尺寸(416x416)及缩放模式作为后续图像处理与学习的基础参数进行设置。
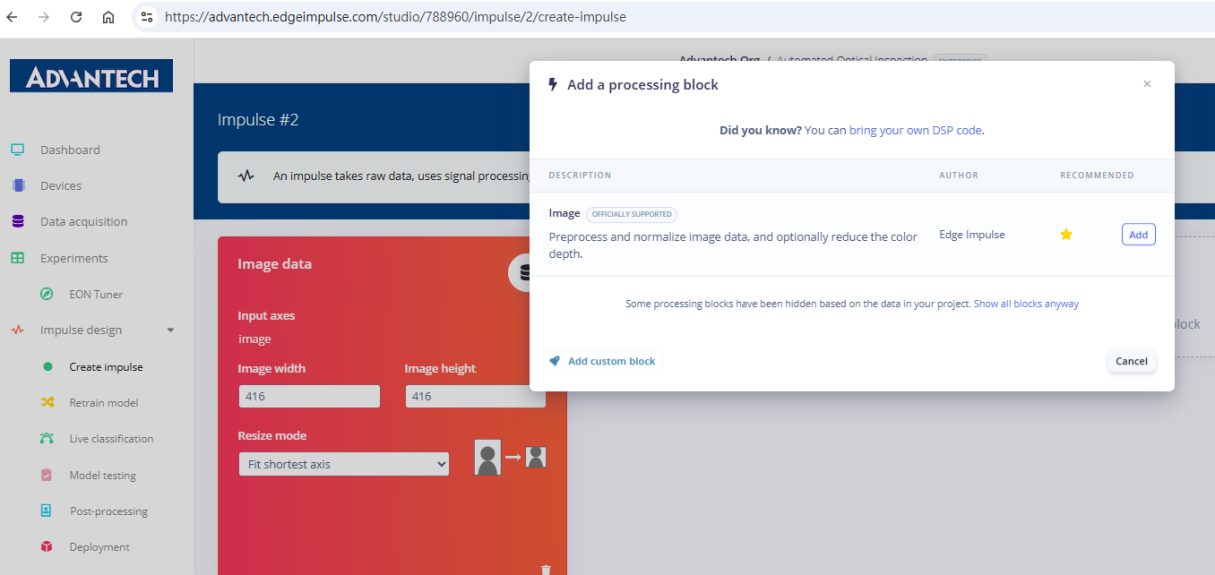
3.在Impulse中添加一个"处理模块",选择图像模块对图像进行预处理和归一化。
4.脉冲配置通过左侧输入图像参数进行更新,中间为图像处理模块。
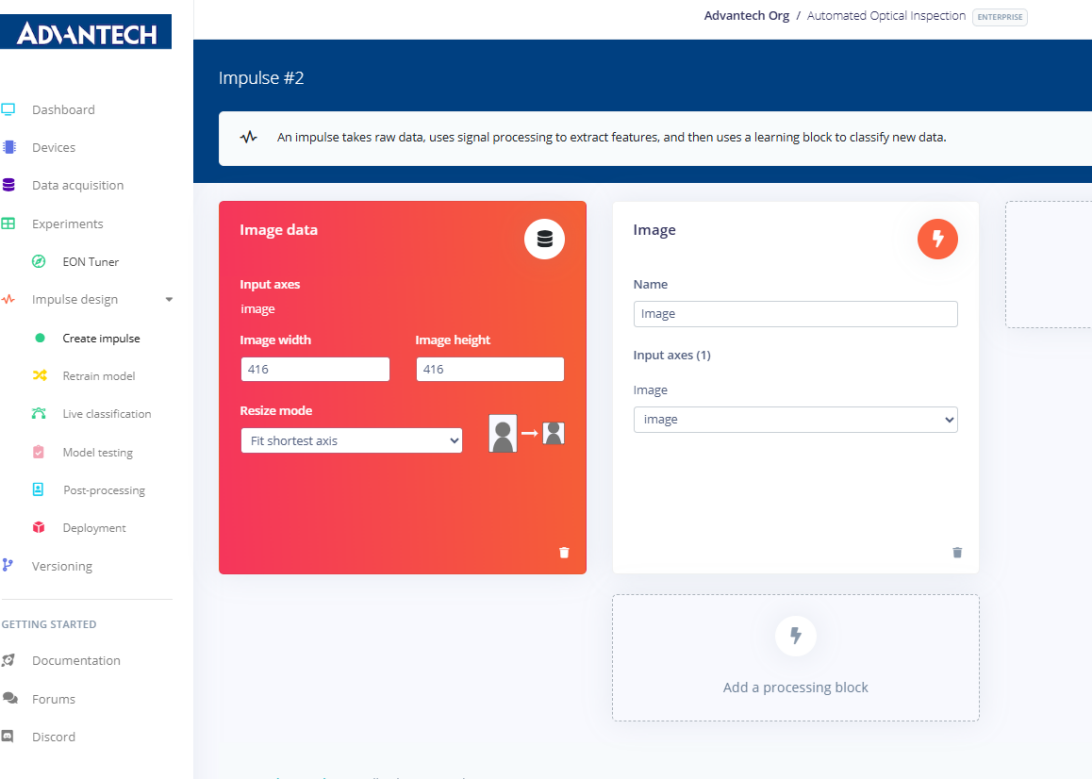
5.添加一个"学习模块",提供诸如目标检测、FOMO异常检测或YOLOv5模型等选项。
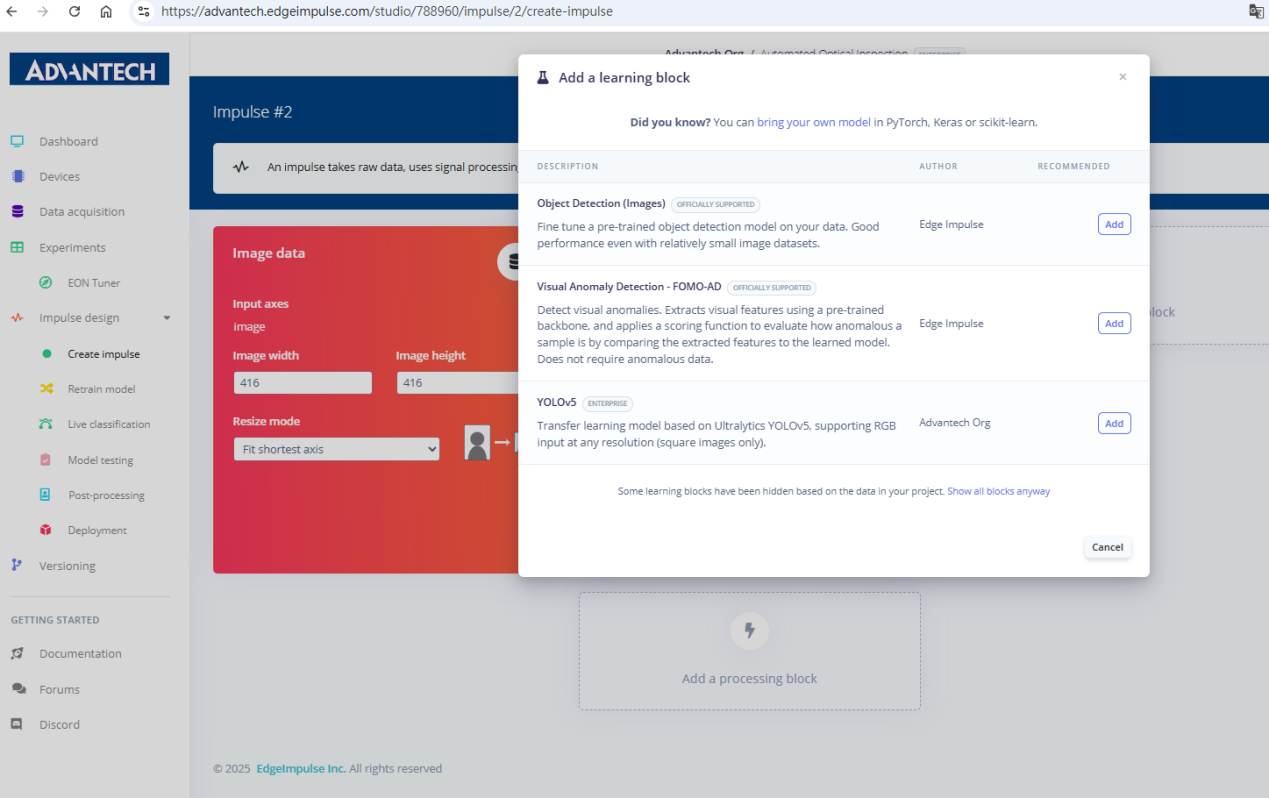
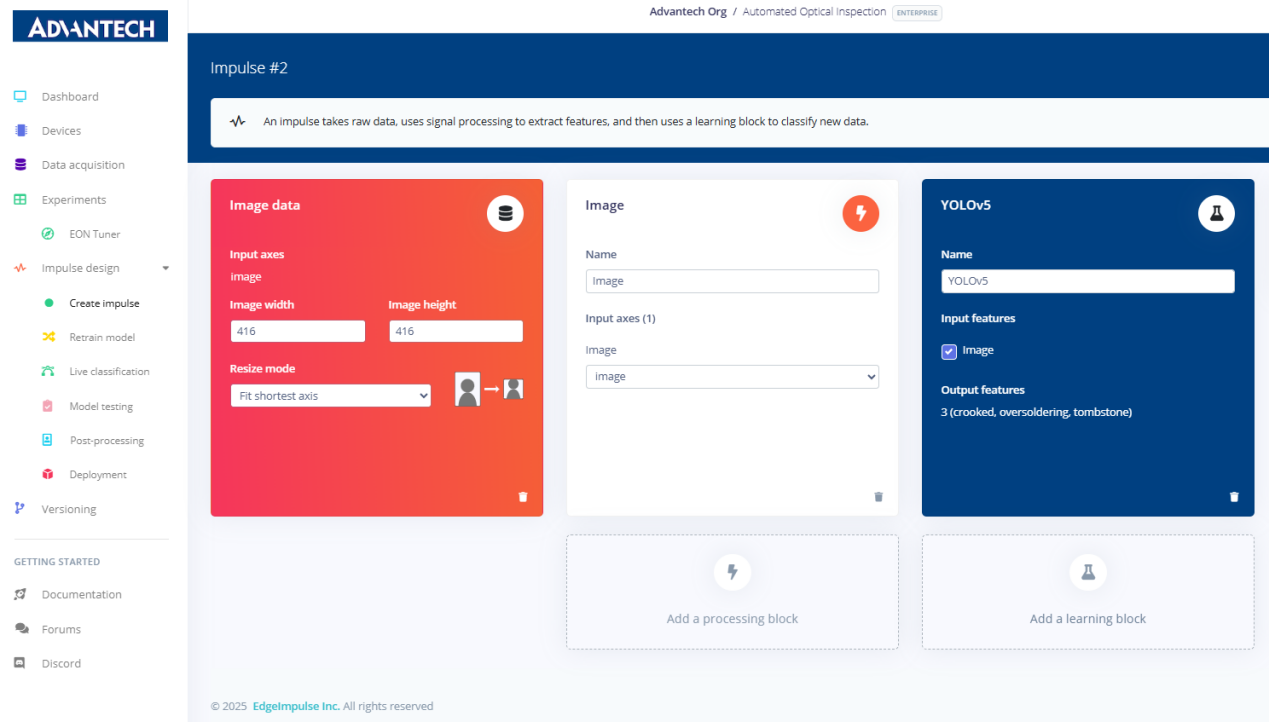
6.脉冲设置已完成,包括图像输入模块和YOLOv5学习模块,输出特征涵盖歪斜、过焊和立碑不良。
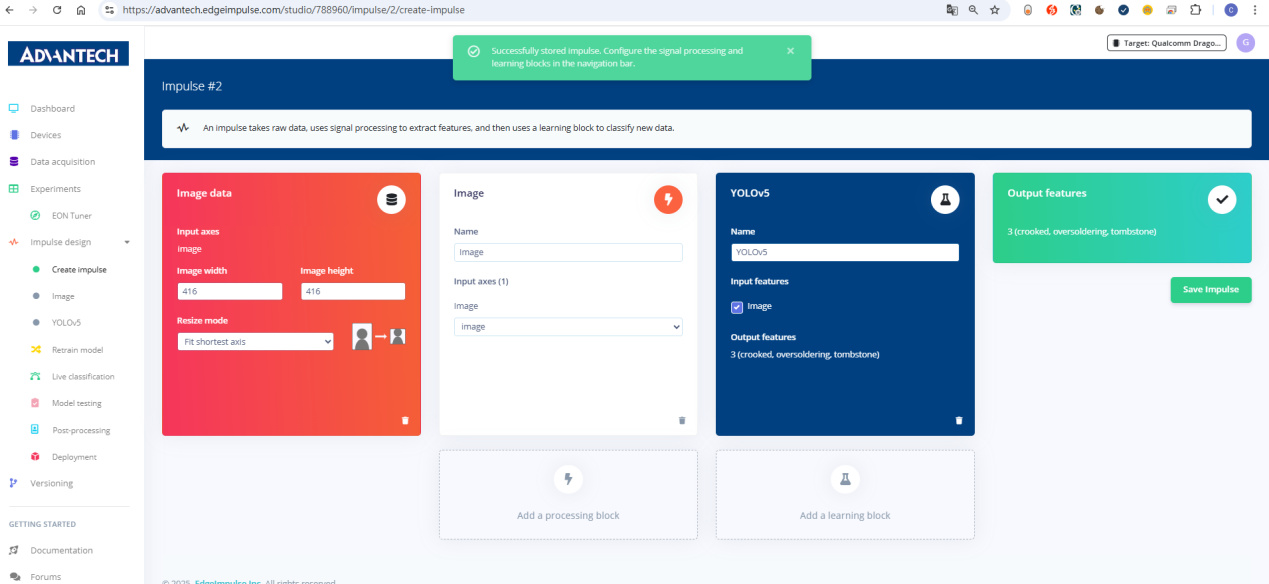
7.成功保存脉冲配置,输入模块与学习模块已建立,准备进行后续训练。
三 特征生成
8.在图像模块设置页面中,可查看原始图像、RGB色彩深度以及处理后的特征结果。
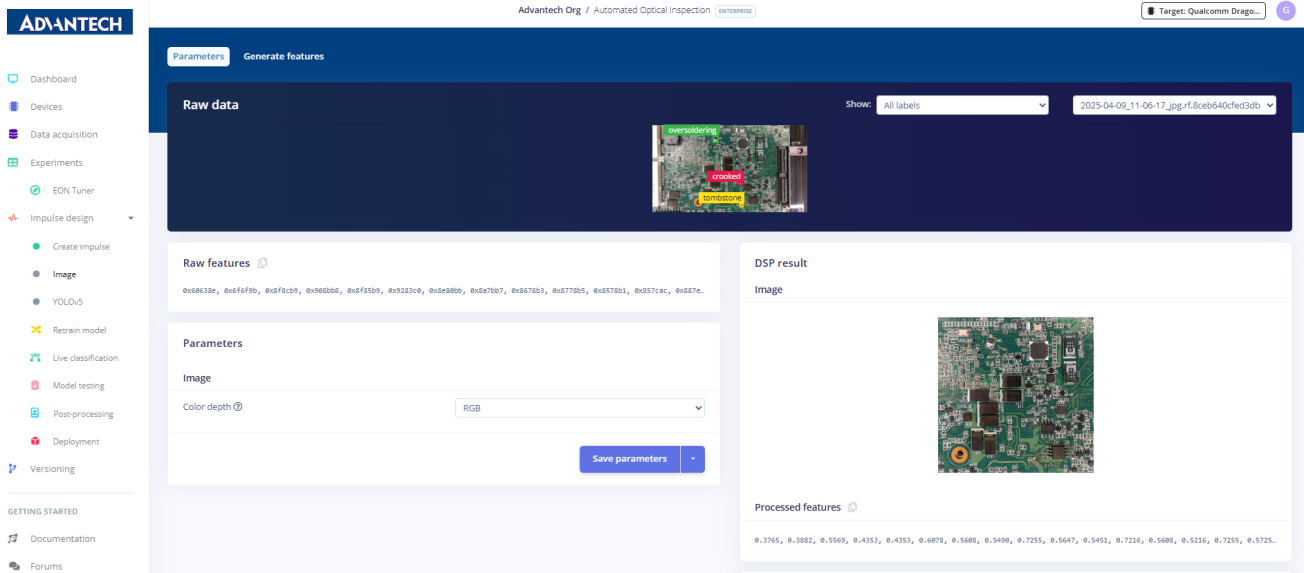
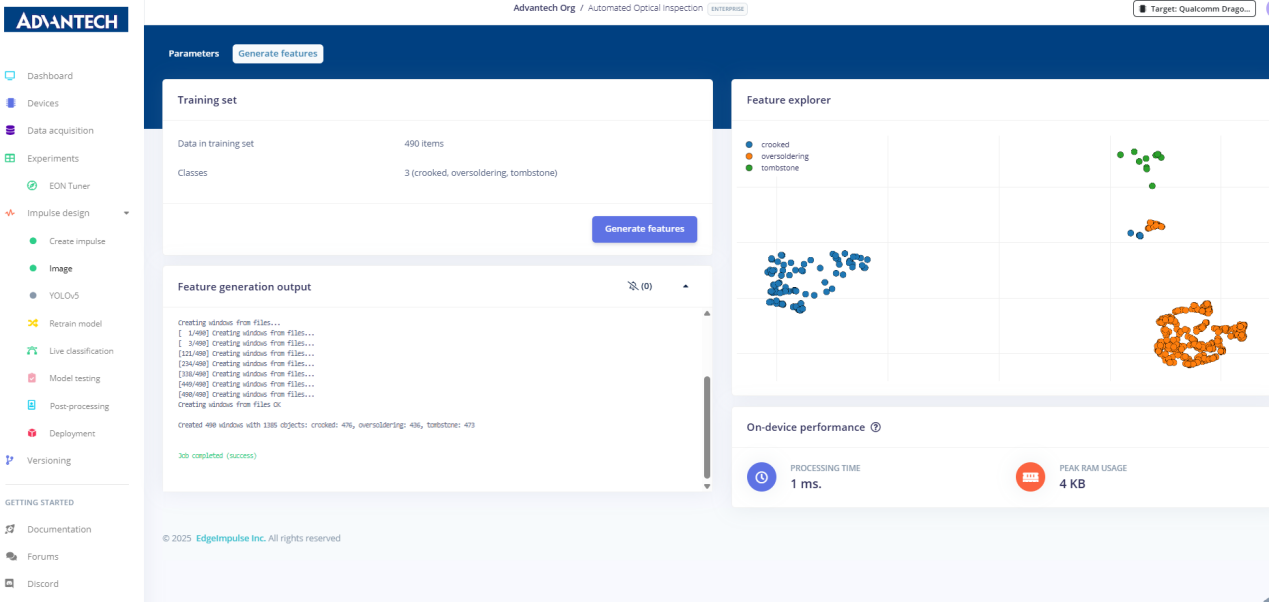
9.准备生成特征,系统显示490个训练样本,分为弯曲、过量焊接和立碑不良三类。
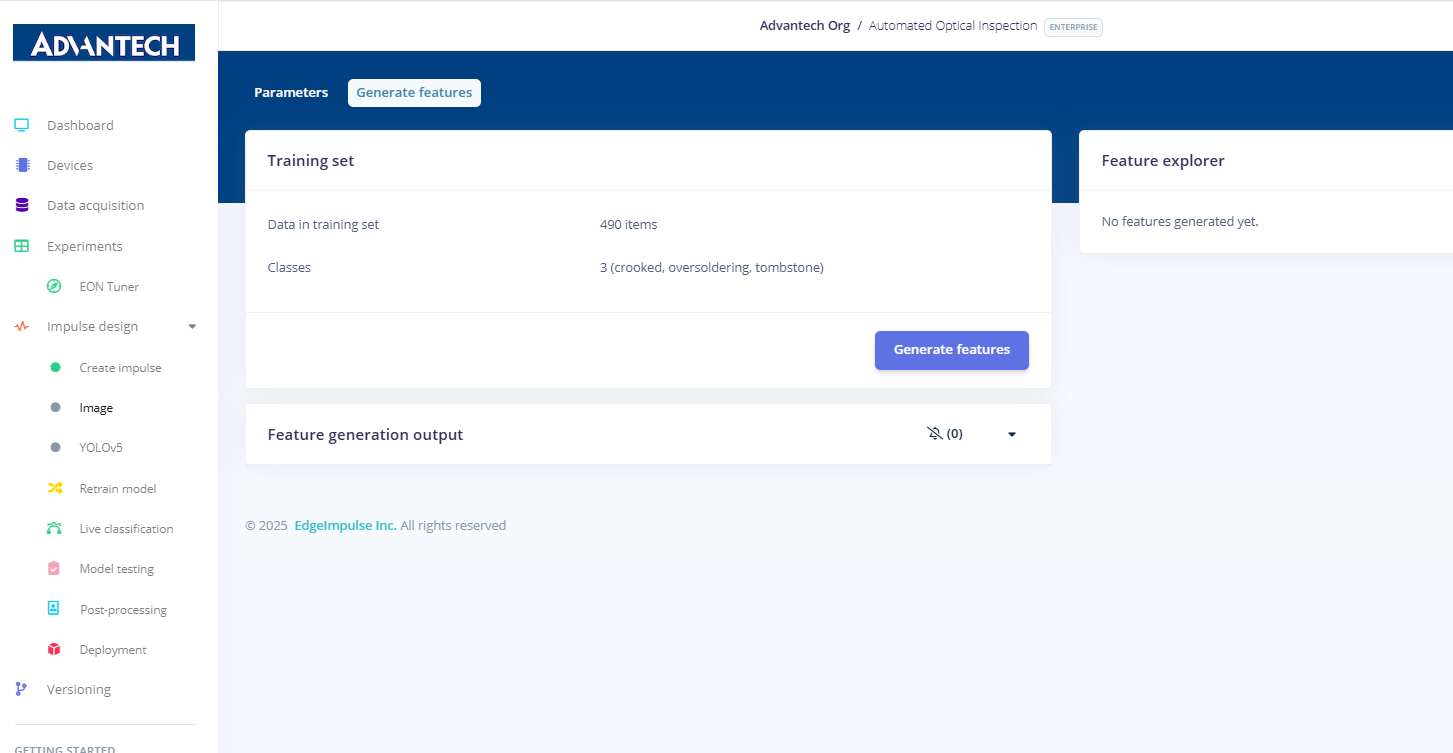
10.在特征生成过程中,系统处理数据集并显示作业调度和进度。
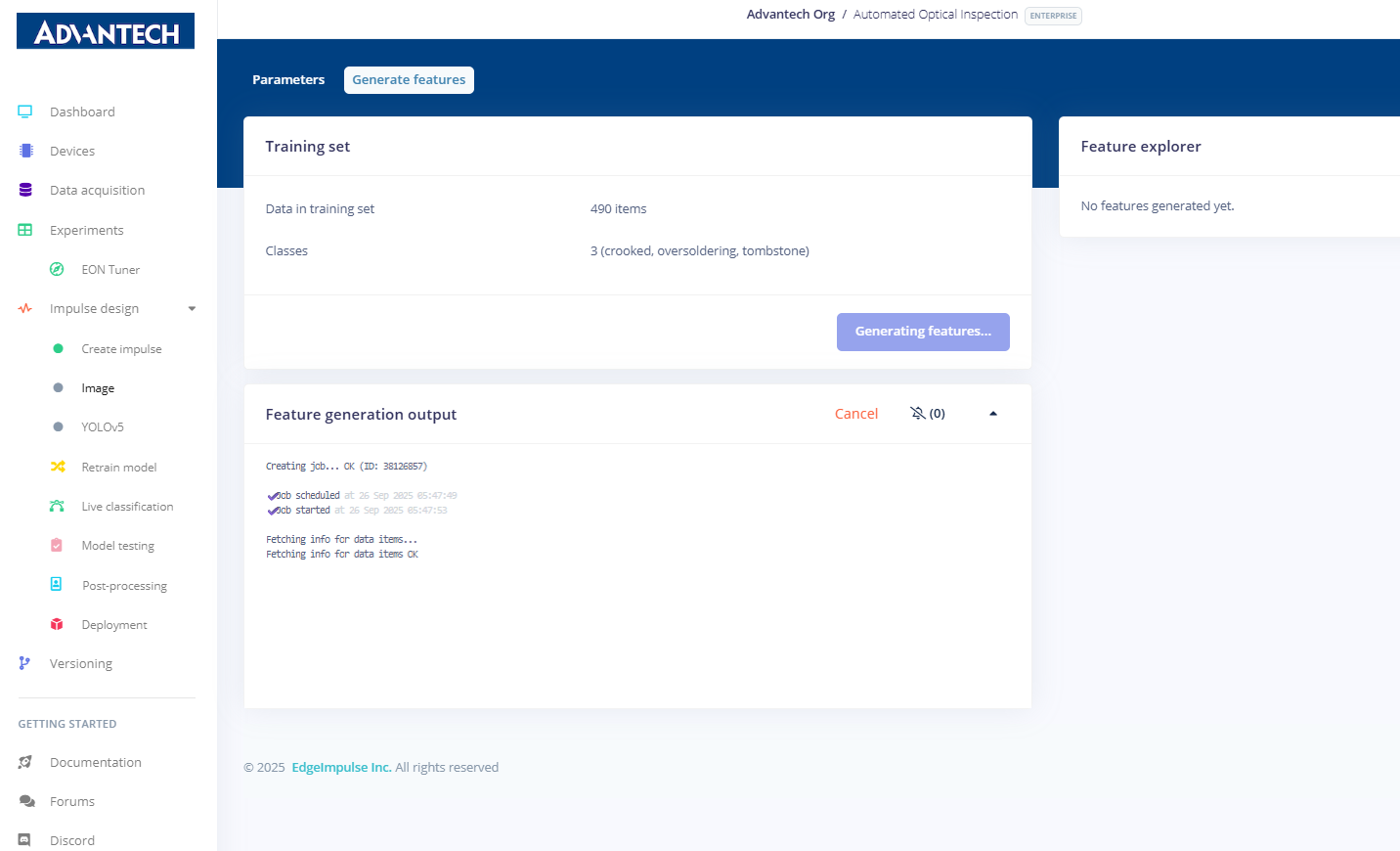
11.特征生成完成,显示各类别的样本数量,以及设备端性能信息(如处理时间和内存使用情况)。
- 特性可视化结果,以彩色散点图形式展示弯曲、过量焊接及坟墓样本。
四 模型训练(YOLOv5)
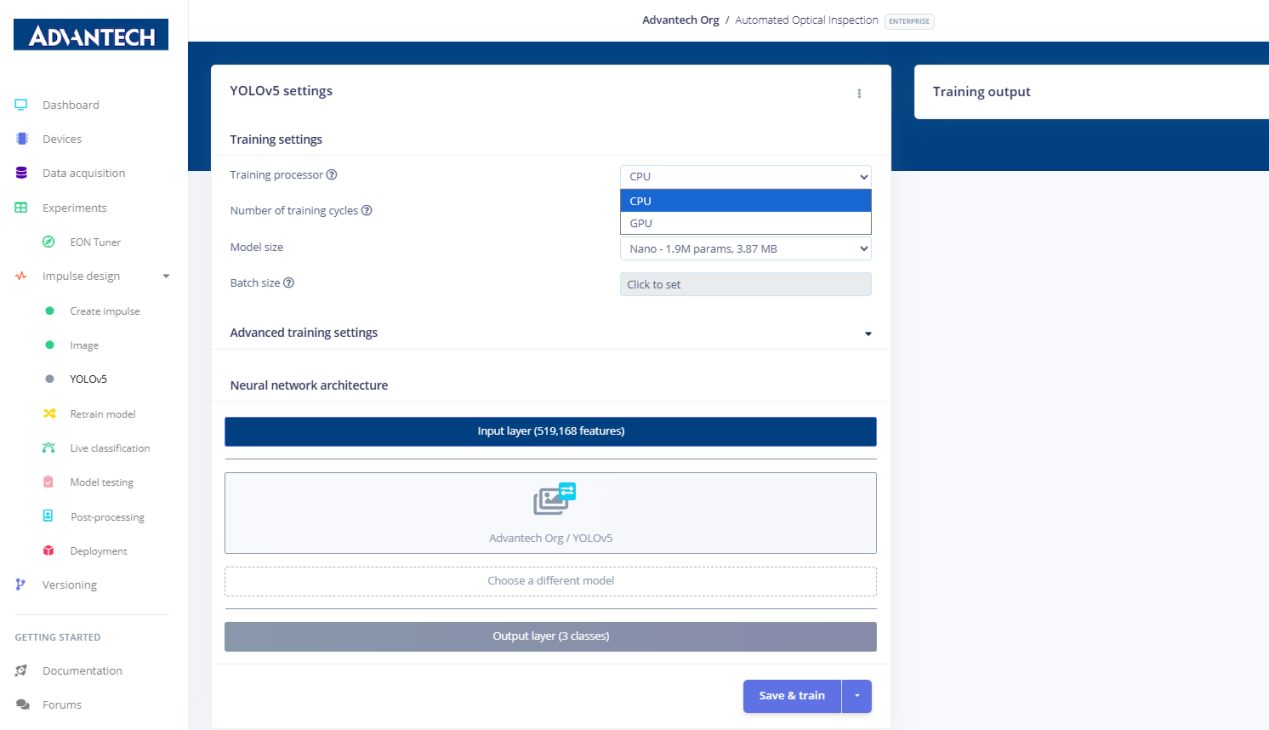
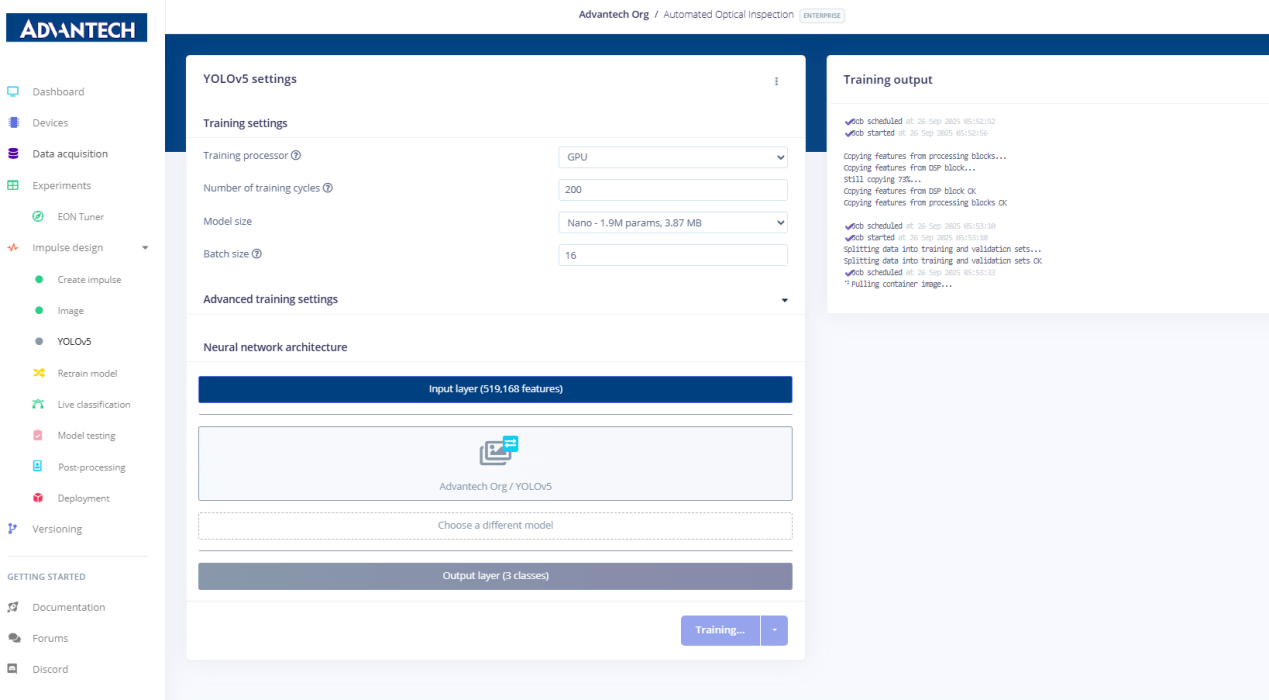
13.YOLOv5设置页面,用户可在其中配置训练处理器(CPU/GPU)、训练循环次数、模型大小及批量大小。
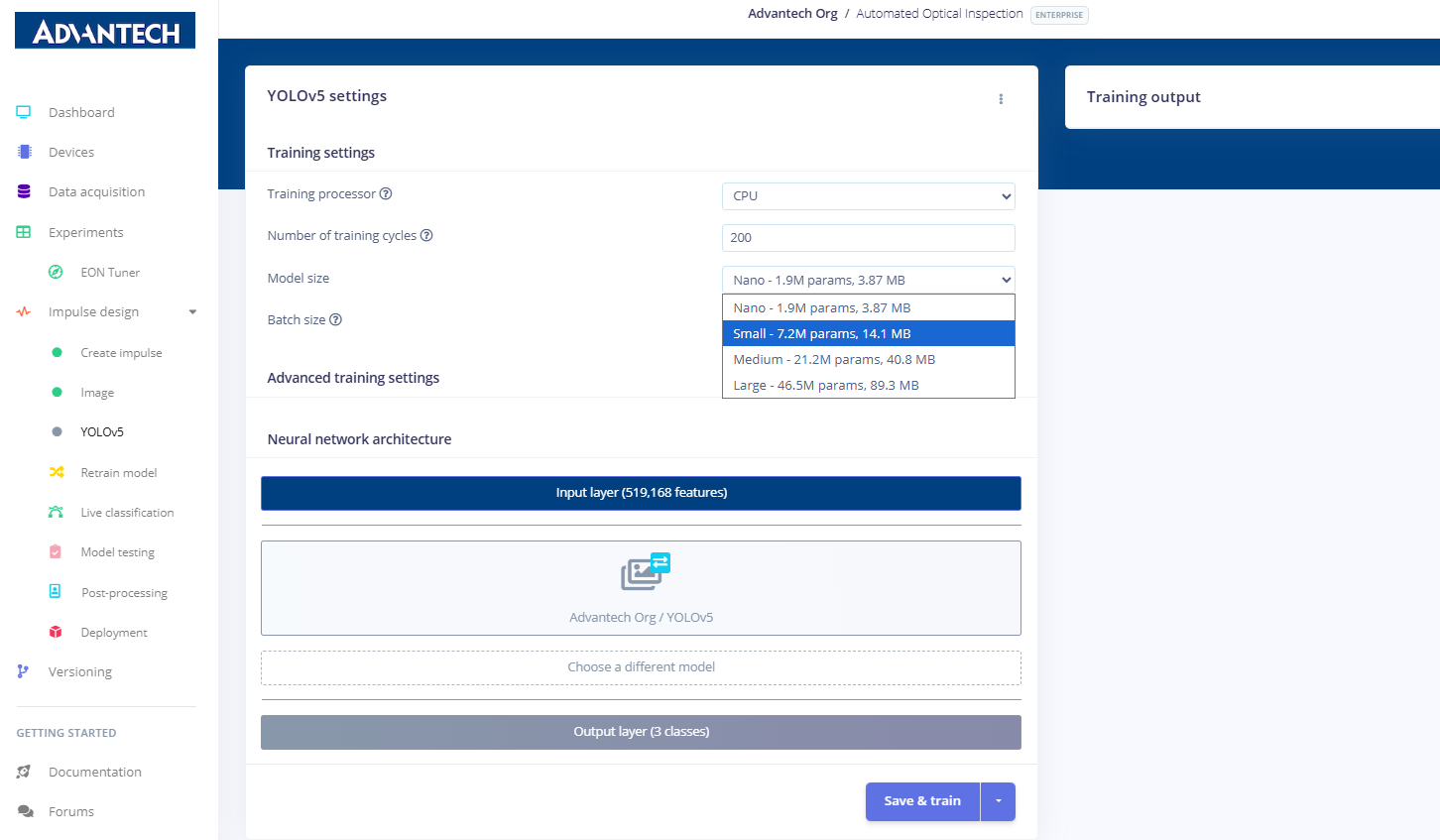
14.配置YOLOv5训练参数,将训练循环次数设置为200次,并选择小型模型(720万参数)。
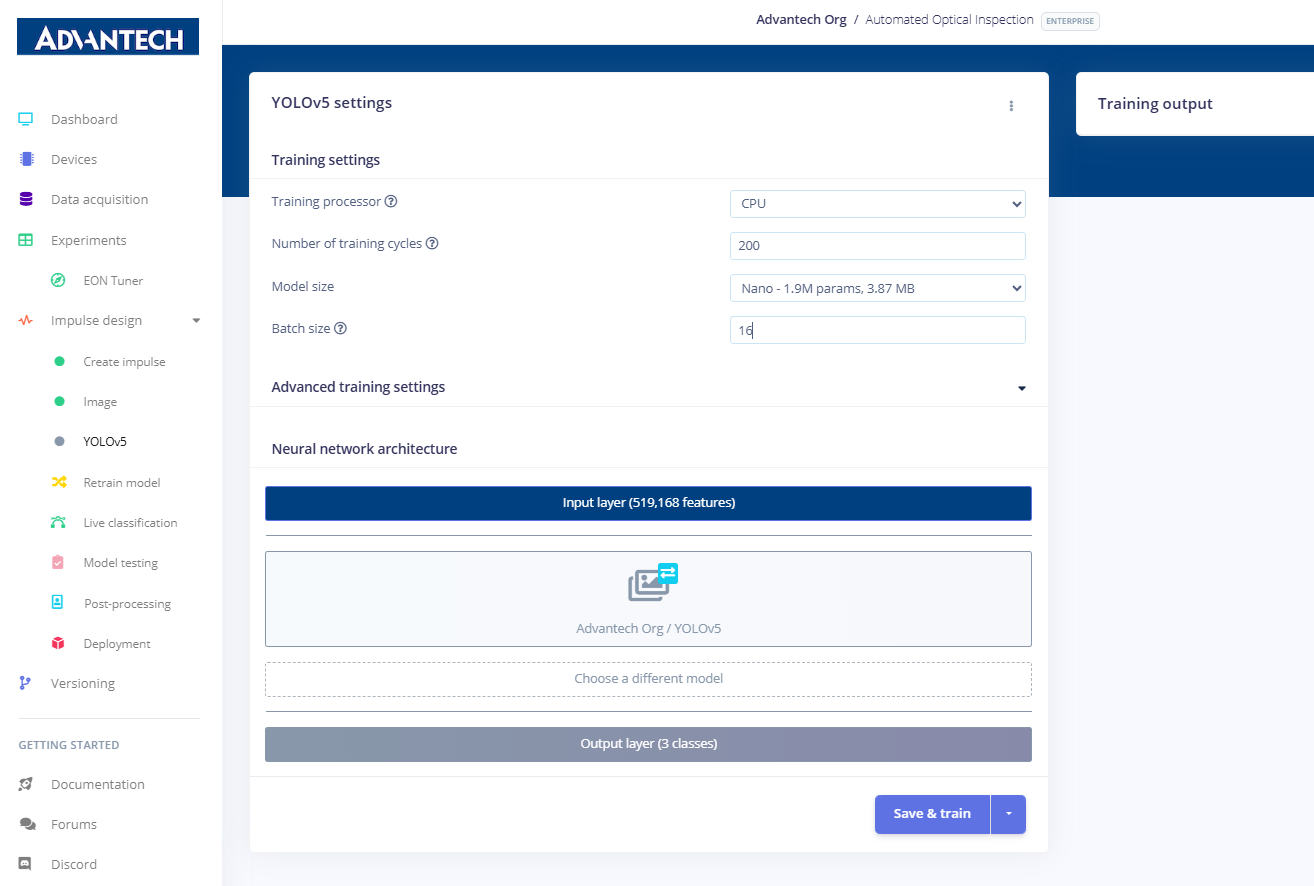
15.将批量大小调整为16,以匹配训练资源和数据集规模。
16.开始训练YOLOv5模型,系统将显示训练进度和实时日志。
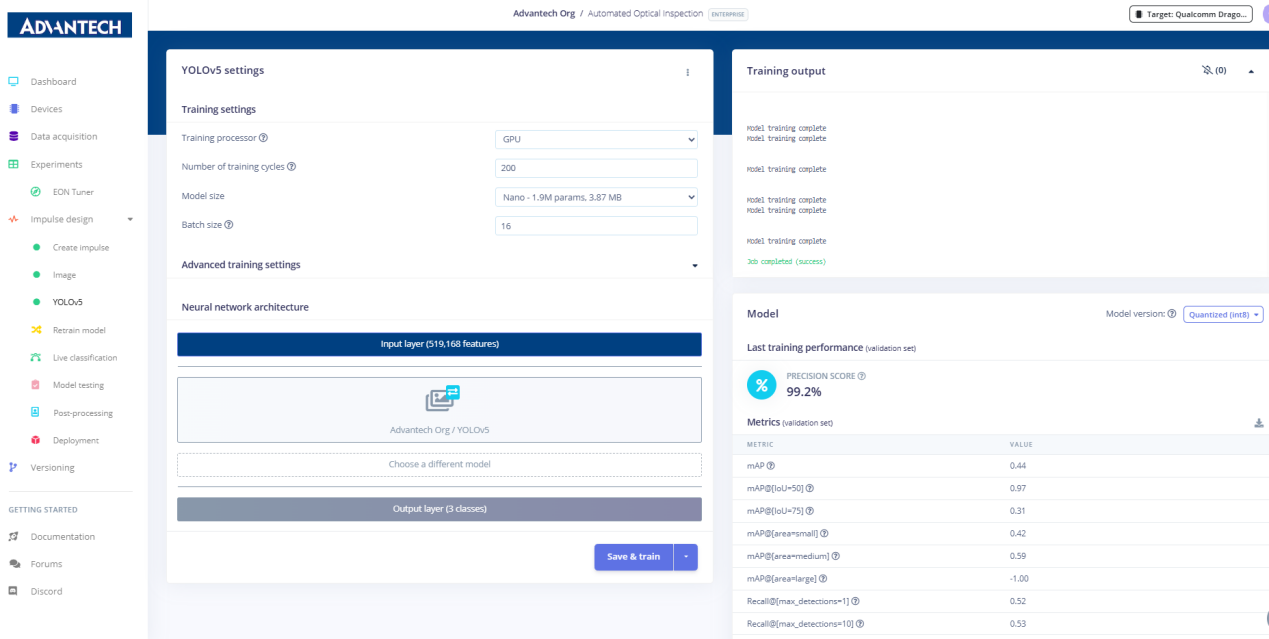
17.训练结果页面显示精度得分达99.2%,同时呈现详细性能指标,包括平均点准确率(mAP)和召回率。
五 再训练和测试
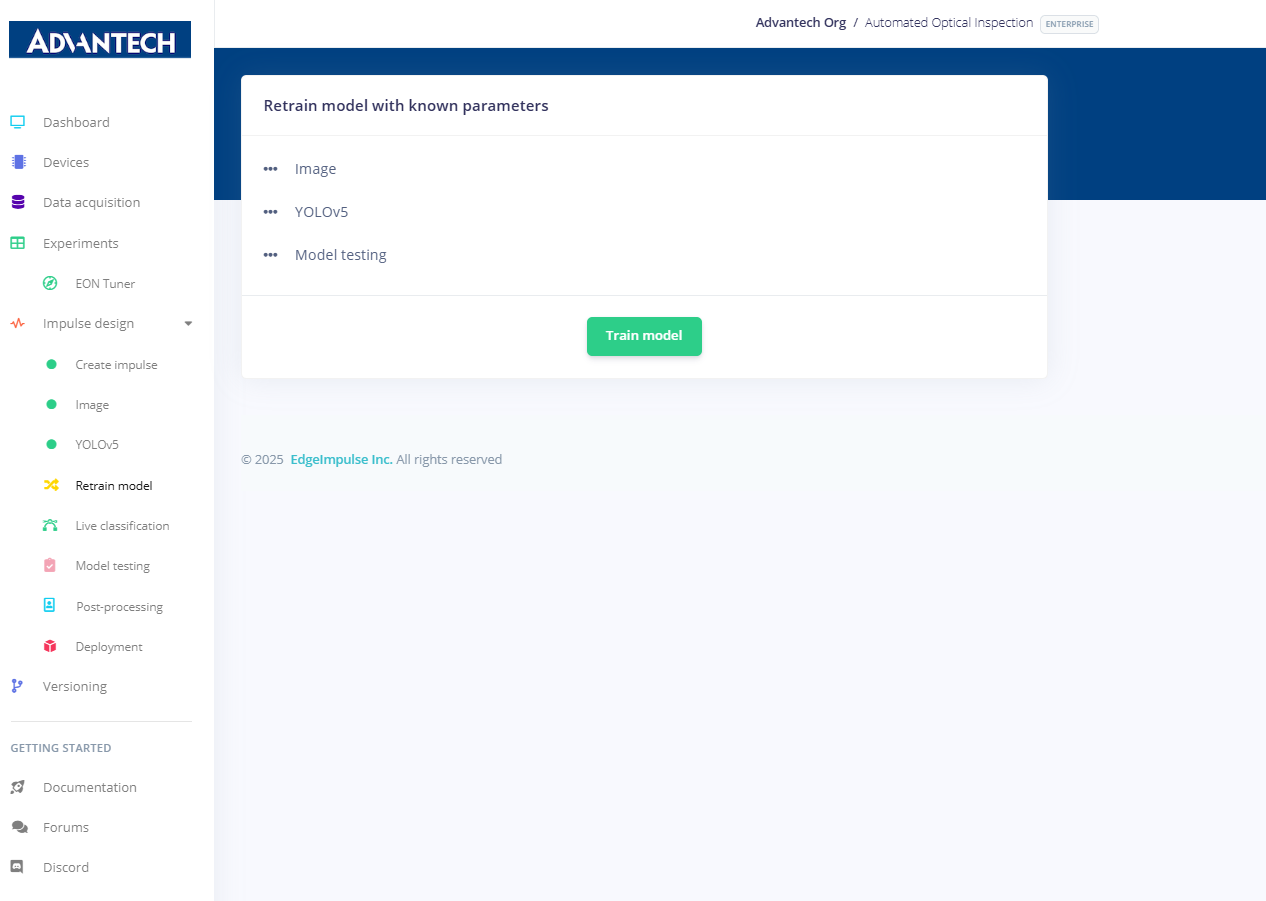
18.在"模型再训练"页面,选择现有的图像模块和YOLOv5学习模块,为模型再训练做准备。
19.在模型再训练过程中,系统持续显示特征处理和YOLOv5训练状态。
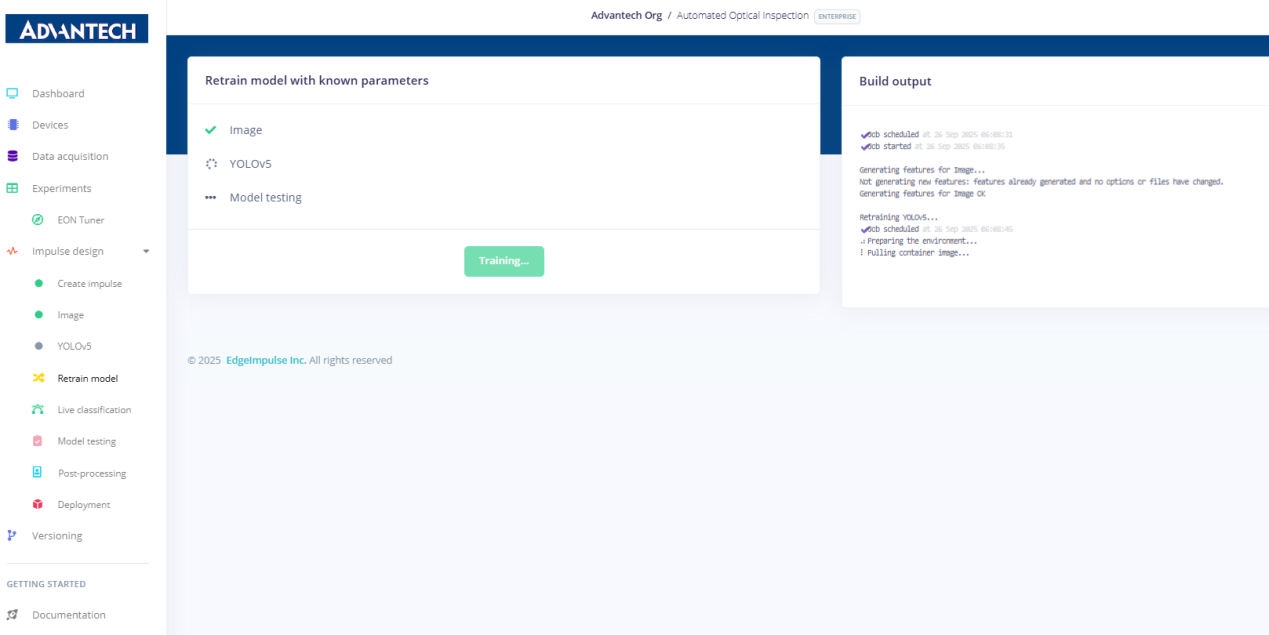
20.系统在再训练后显示所有模块均执行成功,模型测试已完成。
21.在"实时分类"页面,选择设备和摄像头源后,点击"开始采样"即可启动实时图像处理。
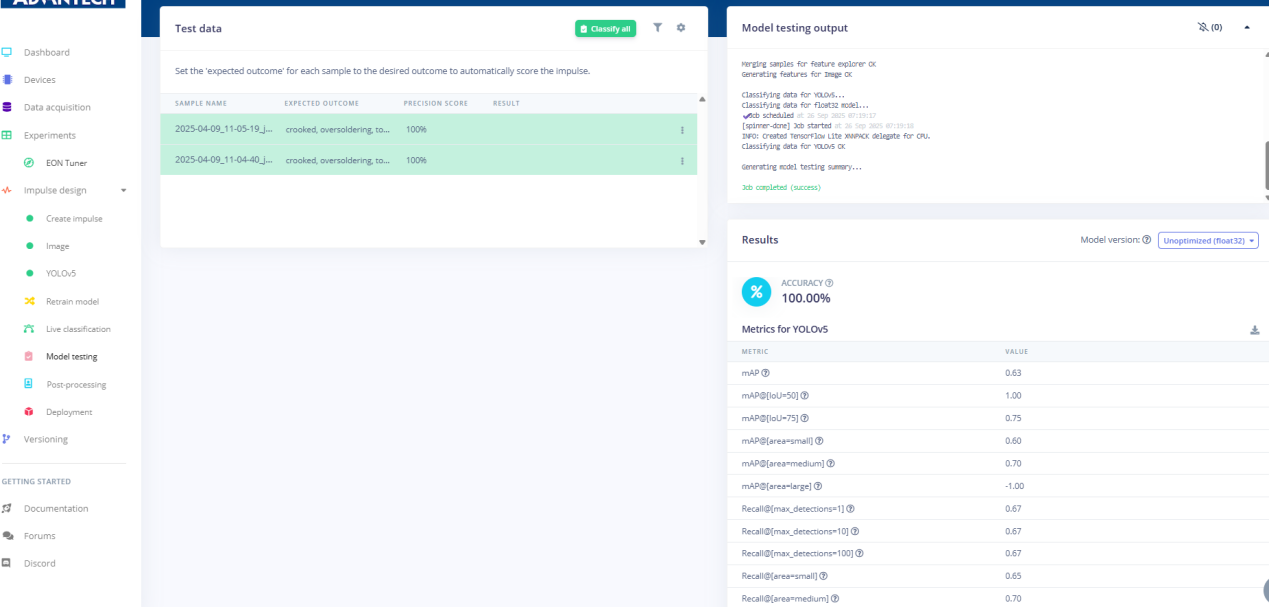
22.模型测试结果显示,测试图像的准确率达到100%,并提供了精确率和召回率等详细指标。
六 部署
23.在"部署"页面上,选择部署目标为Linux(搭载高通QNN的AARCH64架构),并配置模型优化选项。
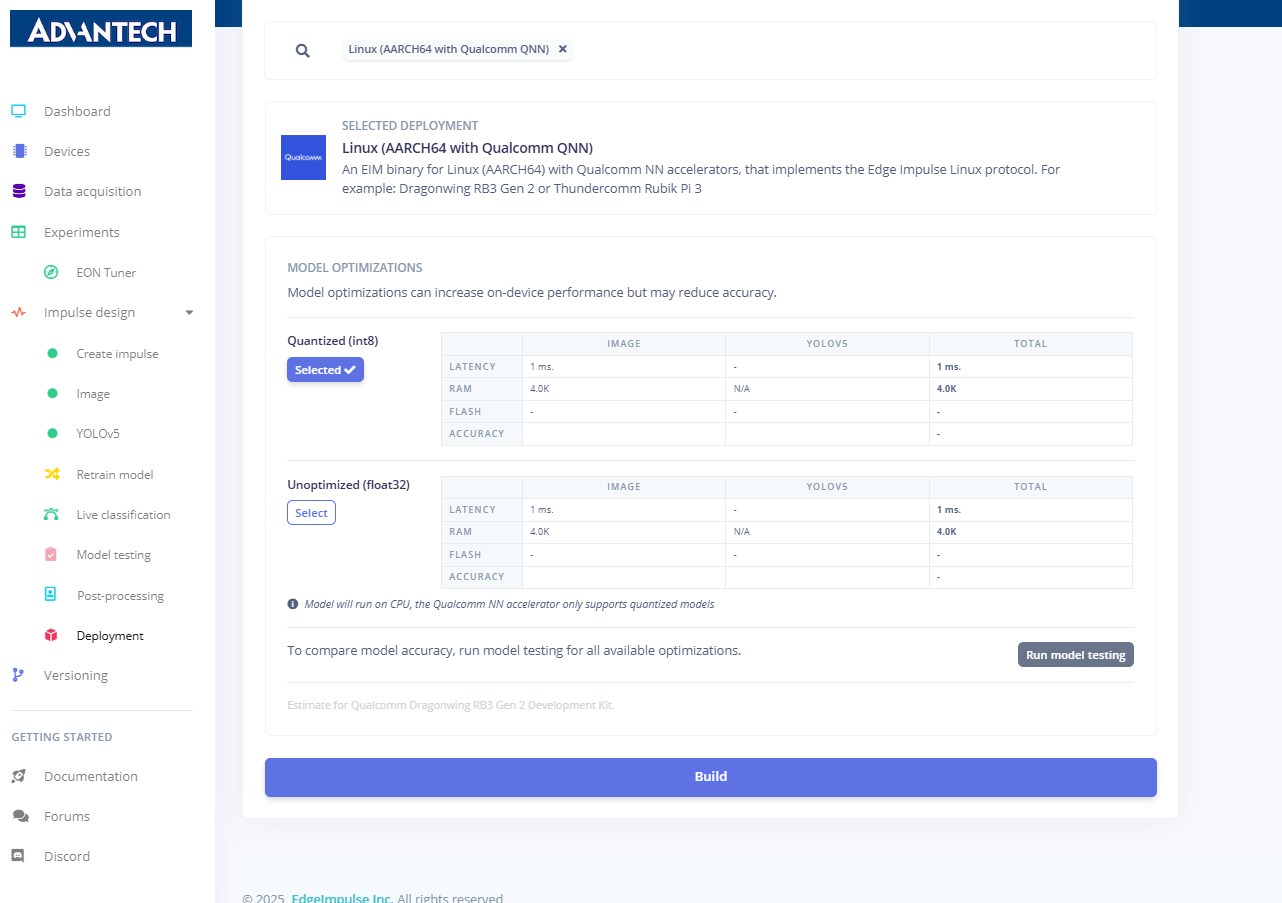
24.通过选择量化(int8)或浮点32(float32)模式配置模型部署,并可选运行模型测试。
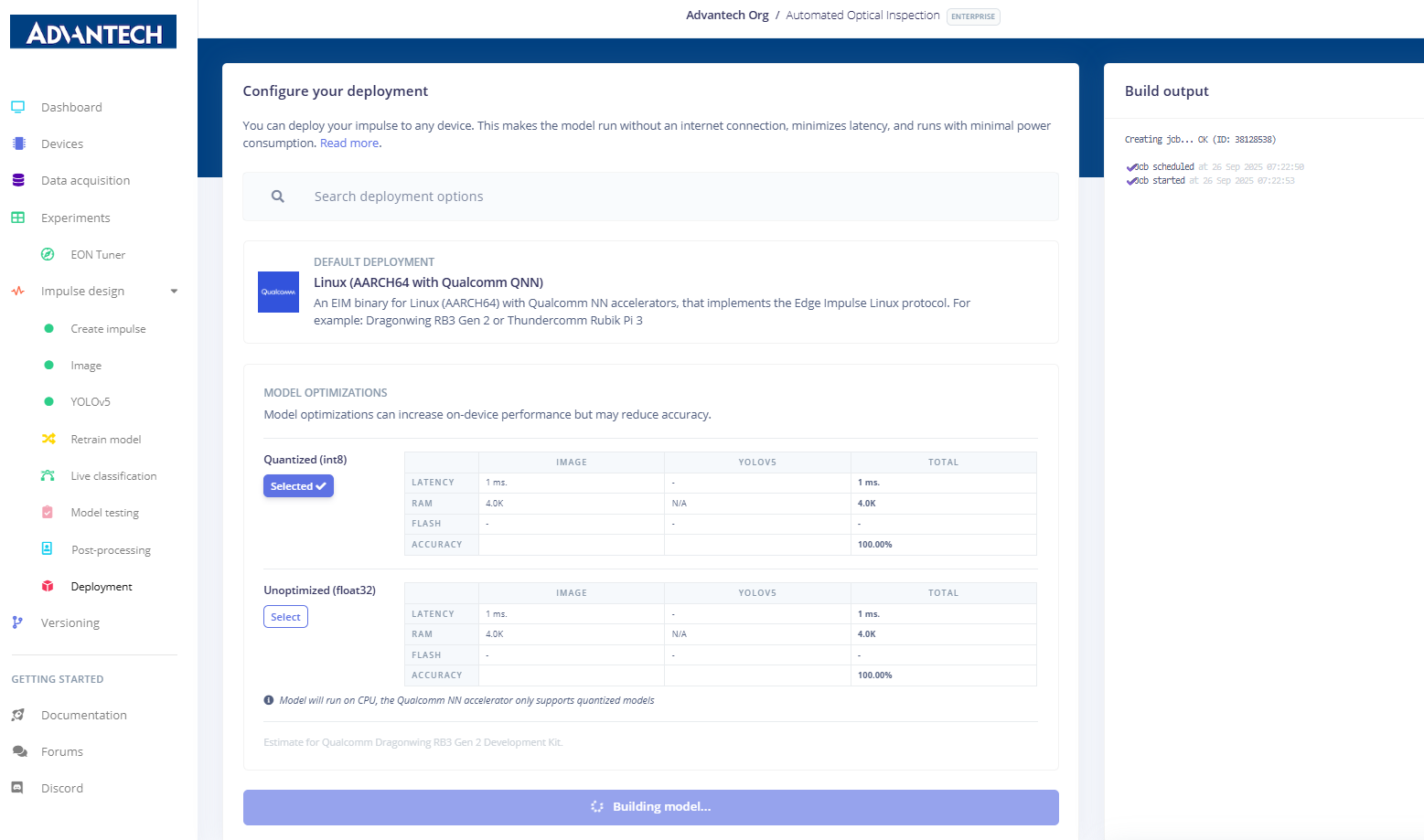
25.在模型构建和部署过程中,系统会显示部署文件的生成情况。
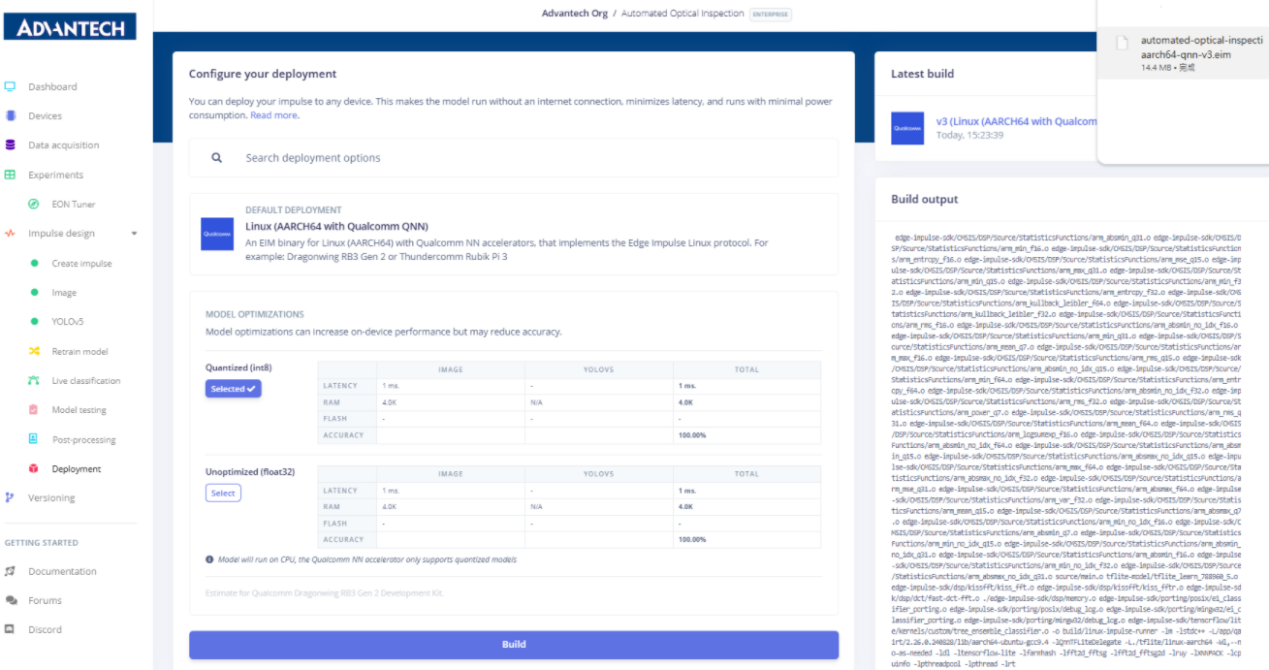
26.模型构建已成功完成,可下载的 .eim 部署文件现已提供。
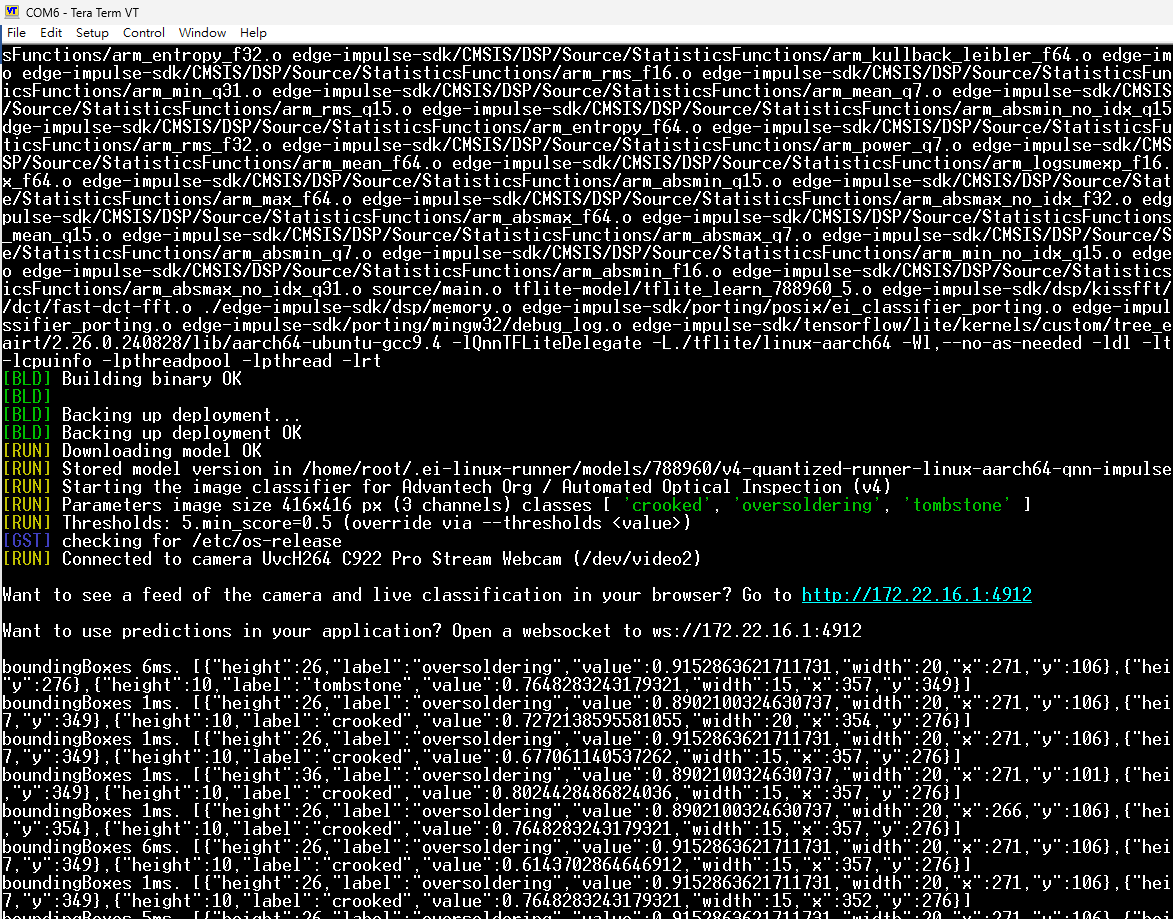
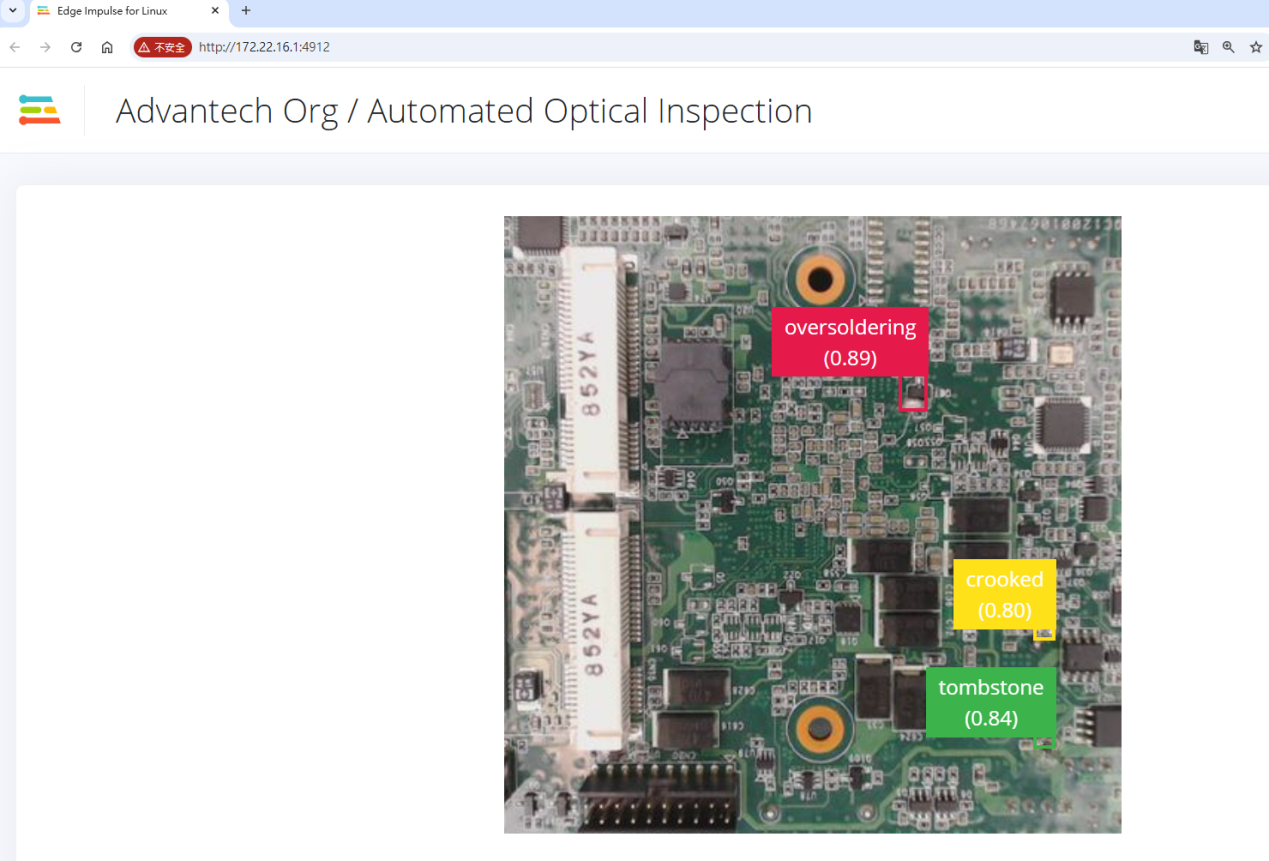
27.在QCS6490开发板上运行编译后的Edge Impulse模型文件(.eim),以启动推理过程。
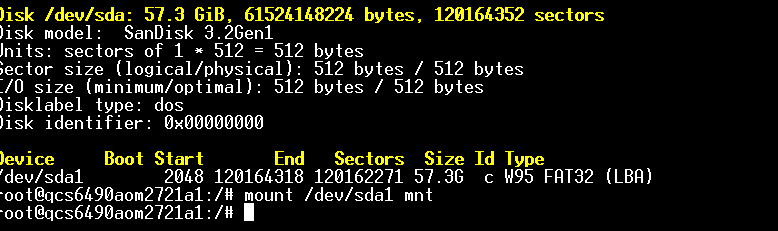
28.将编译后的.eim模型文件从已挂载的USB磁盘复制到QCS6490开发板文件系统。

29.使用 edge-impulse-linux-runner 命令在开发板上运行 .eim 模型文件。

30.系统会提示选择模型变体,用户可选择未优化(float32)或量化(int8)版本。

31.选择量化(int8)模型后,系统将下载并部署该模型。
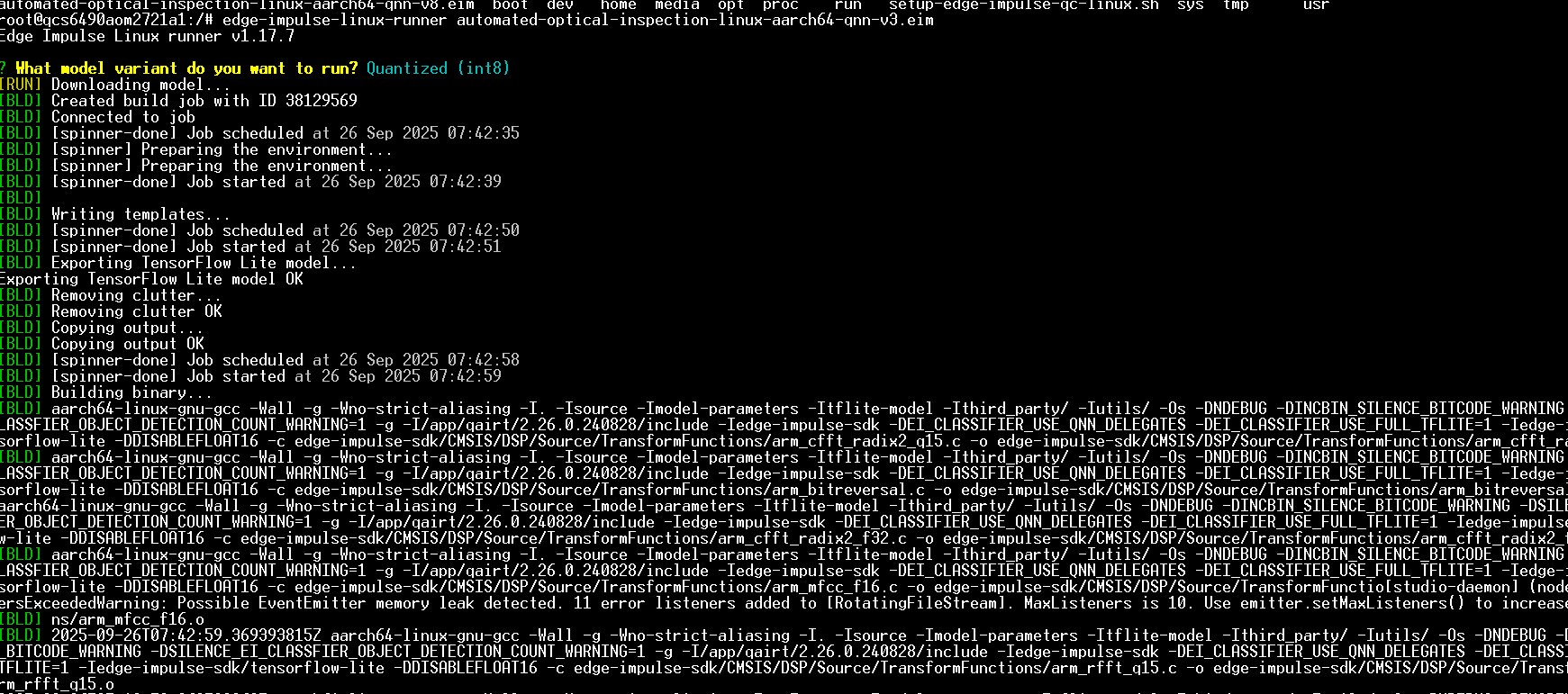
32.模型构建与部署完成,显示"二进制构建成功"并正在备份部署文件。

七 EON Tuner优化
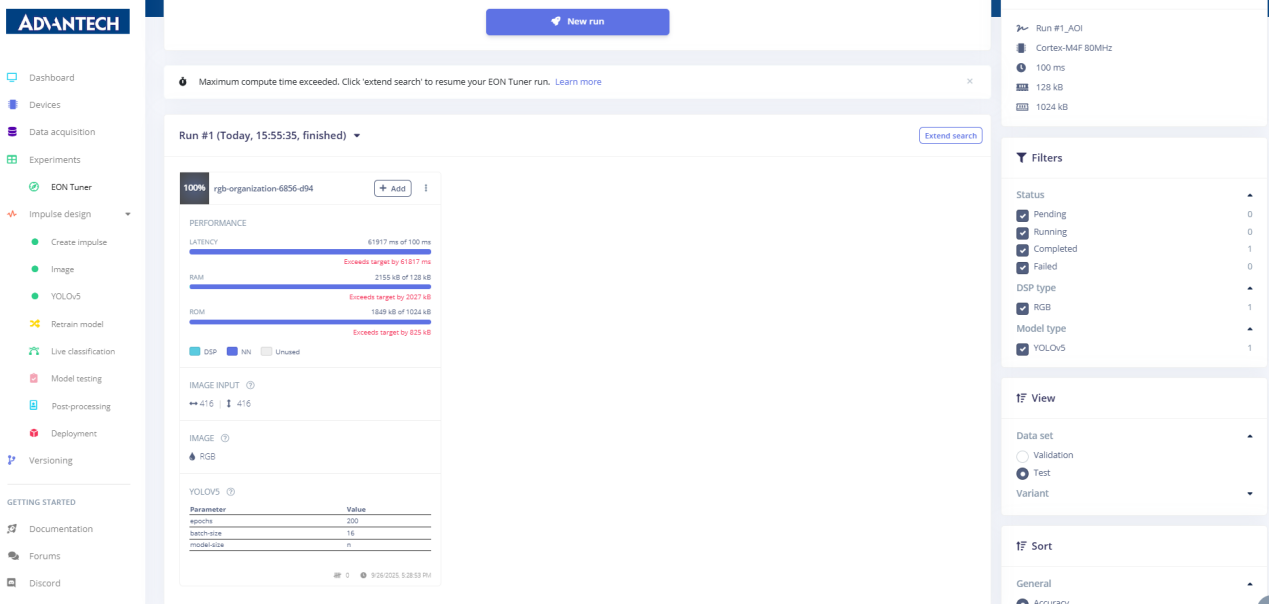
33.进入EON Tuner页面,配置模型优化的超参数搜索。
34.在EON Tuner中配置名为Run #1的新实验,目标设定为最小化验证损失。
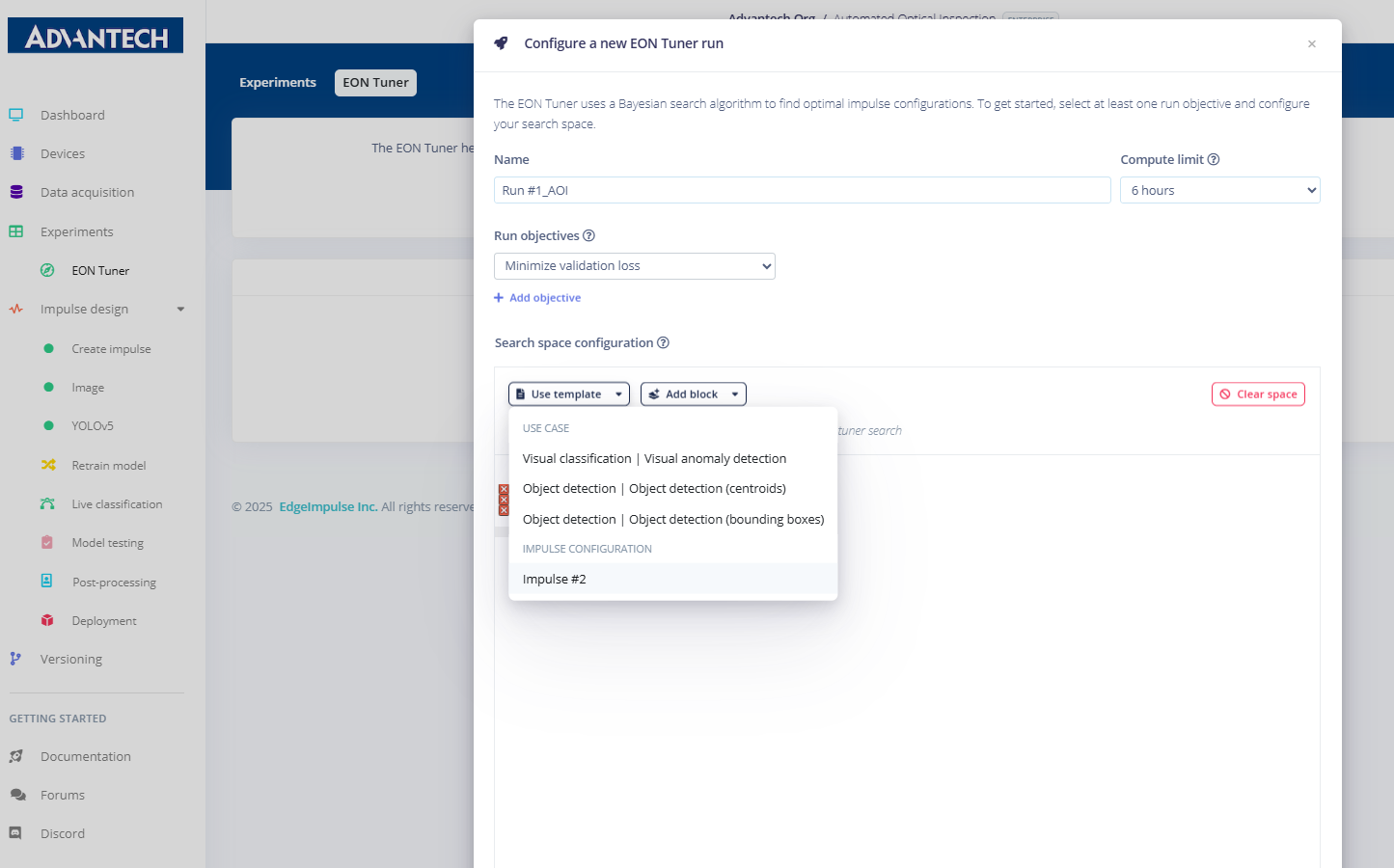
35.在EON Tuner设置中,将实验命名为Run #1_AOI,并将用例选为目标检测(边界框)。
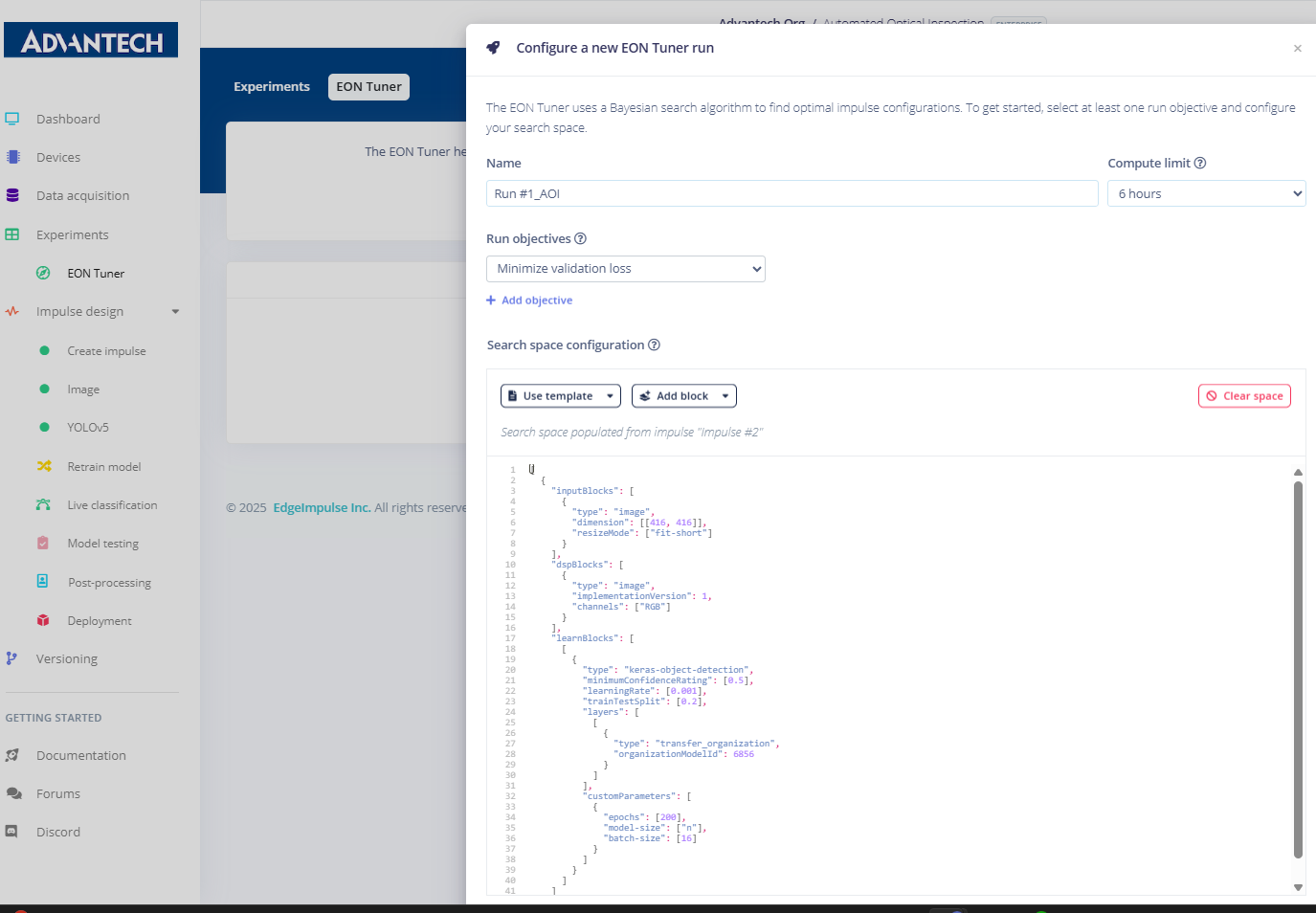
37.EON调谐器实验开始运行,系统自动搜索最佳配置方案。
38.EON Tuner 显示搜索进度,包括不同超参数组合的测试结果。
39.EON调谐器结果页面,展示不同模型配置间的性能对比。
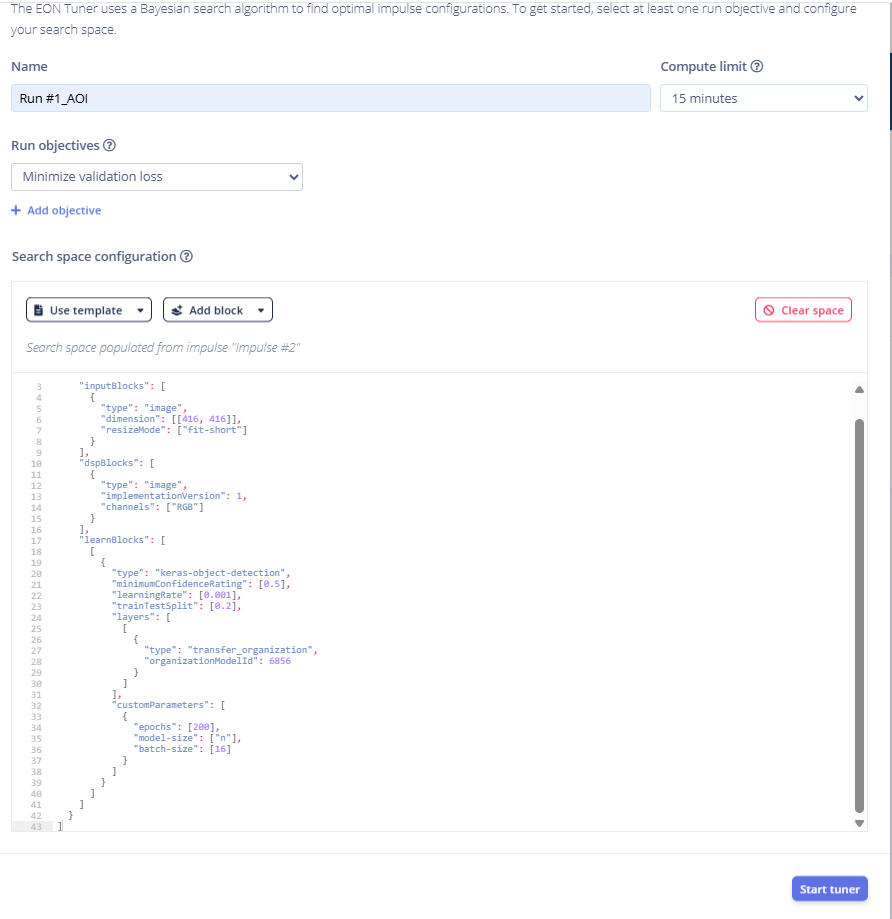
40.EON Tuner 选择最佳模型配置,并突出显示推荐的优化设置。
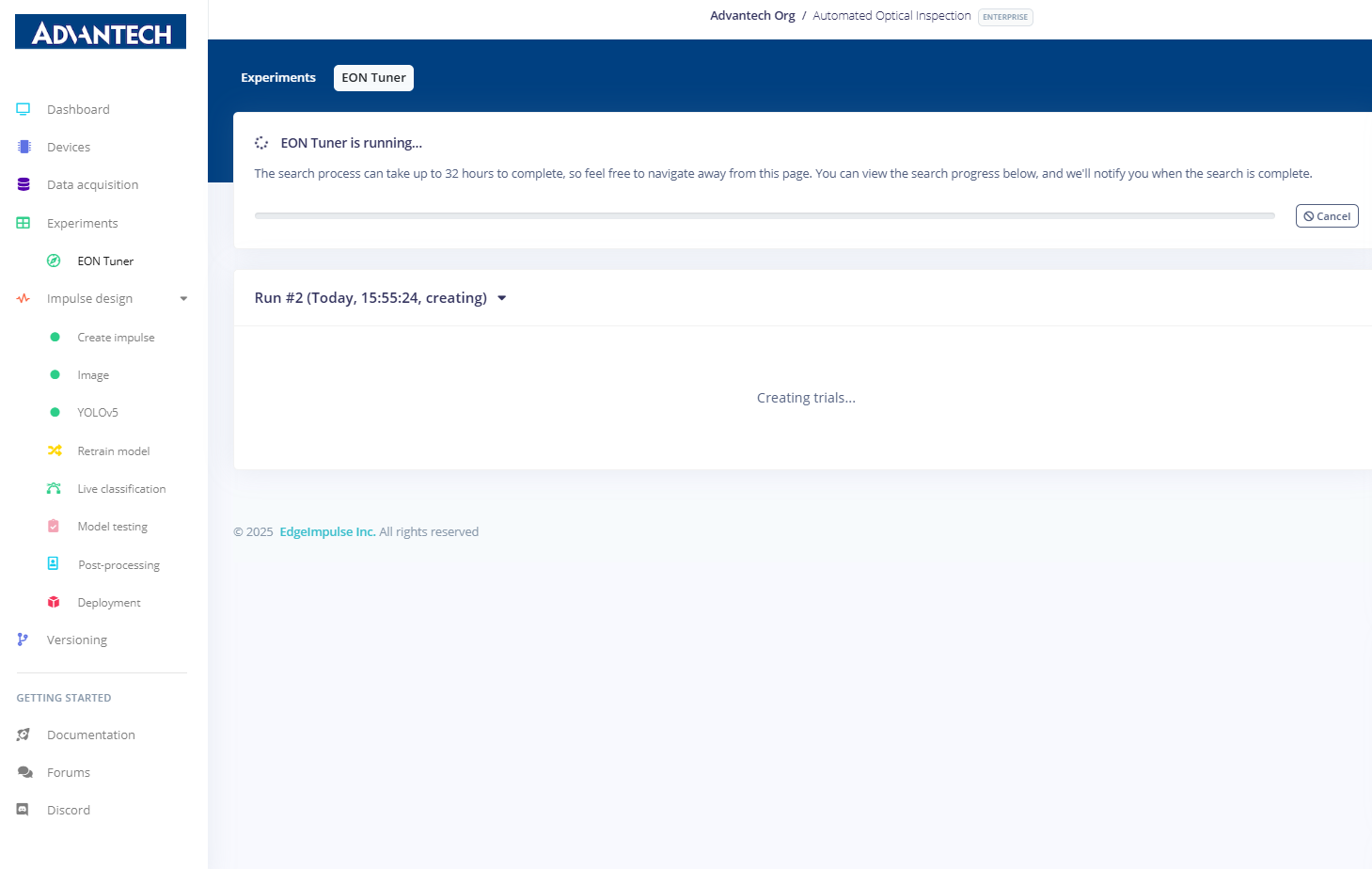
41.优化完成后,系统提示重新训练并部署新的模型配置。
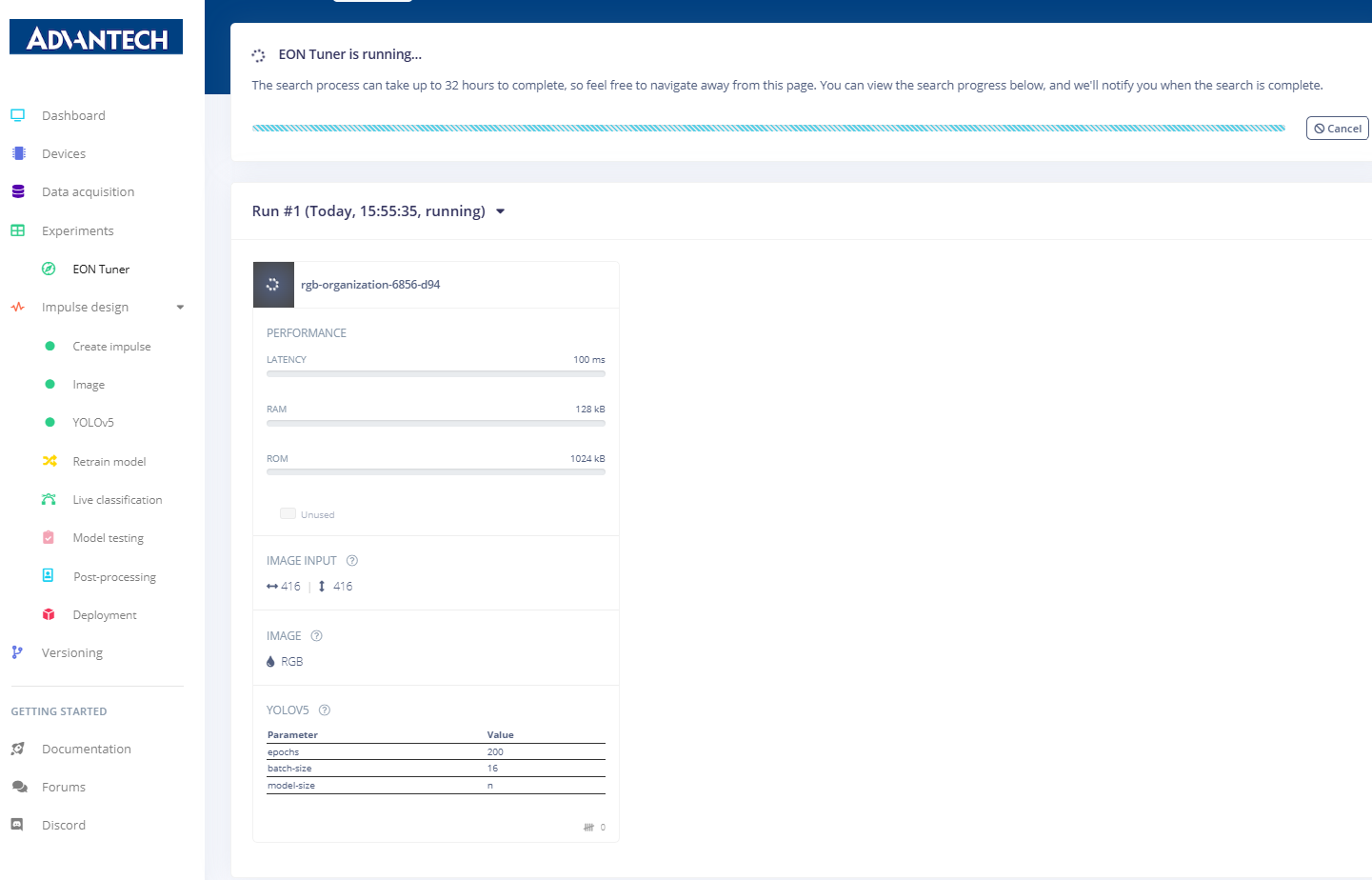
42.AOI模型部署已完成,Edge Impulse平台显示优化后的模型已成功构建并准备就绪,可进行推理。最后,您可将此优化模型添加至项目中,确保获取最佳训练数据。