这个过程就像一个人看到一页书:先认出纸上有很多黑点(感知),再看出这些黑点组成了文字和图表(识别),最后理解这些文字讲述了一个完整的故事(理解)。
下图清晰地展示了这一转化的完整技术流程与两大实现范式:
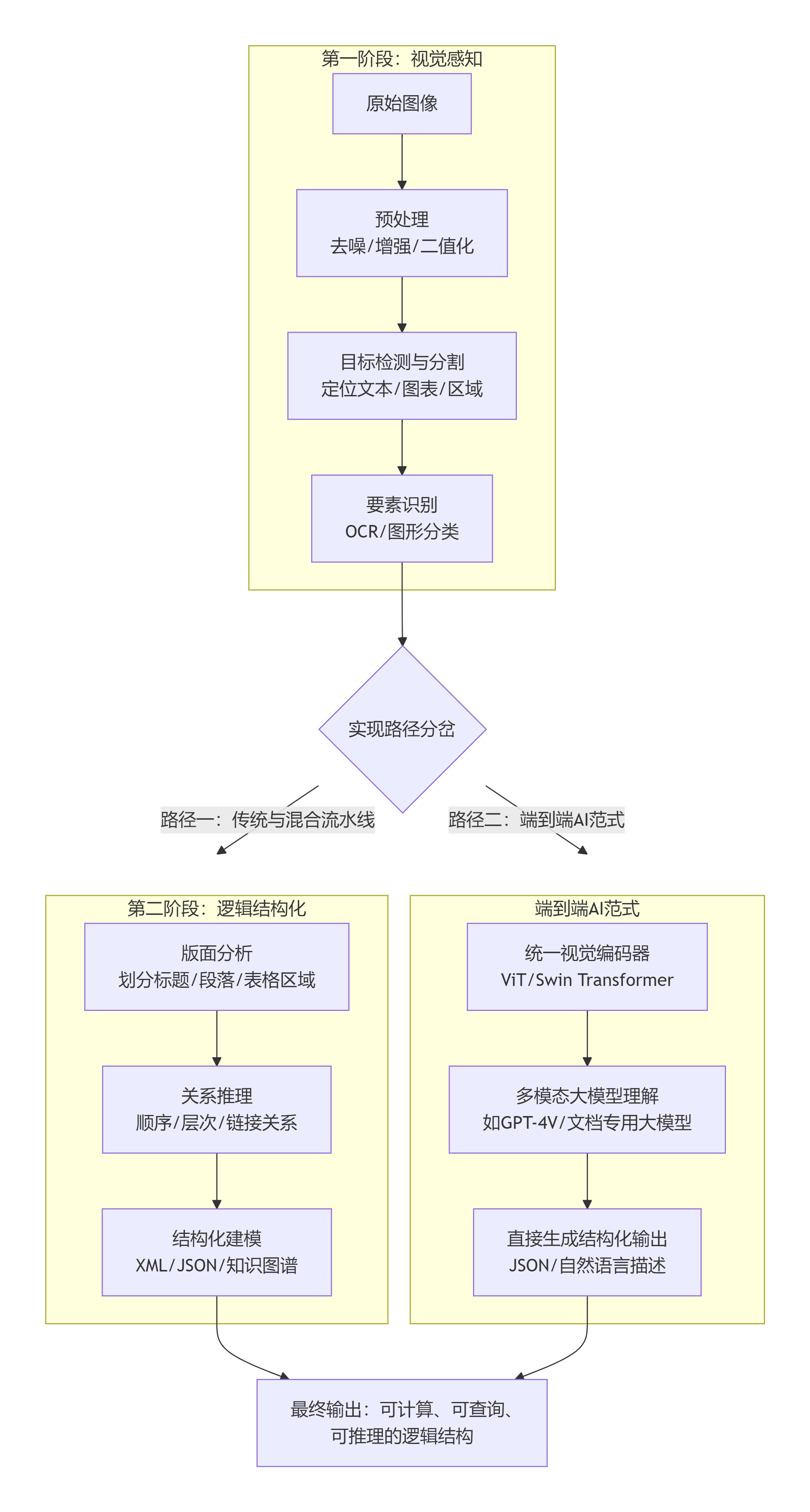
以下是这两个阶段及两条技术路径的详细拆解:
第一阶段:视觉感知 ------ "看见并认出"
这一阶段的目标是将像素转换为机器可处理的符号化元素。
-
图像预处理与增强:
-
目的:优化输入质量,为后续步骤扫清障碍。
-
操作:降噪、对比度增强、纠偏、二值化等。
-
输出:一张更"干净"的图像。
-
-
目标检测与分割:
-
目的 :回答"在哪里?有什么?"
-
操作:
-
文本检测:定位图像中所有文本区域(文本框)。
-
图表检测:定位表格、柱状图、流程图等区域。
-
区域分割:区分页眉、页脚、主体、侧边栏等。
-
-
输出:一系列带有位置和类别标签的边界框或像素级掩码。
-
-
要素识别:
-
目的 :回答"是什么?"
-
操作:
-
光学字符识别(OCR):将文本区域的图像转换为编码文本(字符串)。
-
图形/图标分类:识别出检测到的图表是"饼图"还是"组织结构图"。
-
手写体识别、公式识别等专项识别。
-
-
输出 :机器可读的符号,如文本字符串、图表类型标签。
-
至此,计算机完成了"感知",它得到了一堆离散的、带位置和类型标签的数据片段,但还不知道这些片段之间有何关联。
第二阶段:逻辑结构化 ------ "组织并理解"
这一阶段的目标是根据领域知识,将离散的元素构建成有意义的逻辑关系。
路径一:传统/混合流水线(主流工业界方案)
-
版面分析与文档对象识别:
-
目的 :理解元素的空间布局逻辑。
-
操作 :基于位置、大小、字体等特征,将OCR结果分类为:标题(第1/2/3级)、段落、列表项、表格单元格、图注、页码等。
-
关键:判断哪些文字属于同一个逻辑单元(如一个段落可能由多行组成)。
-
-
关系推理与关联:
-
目的 :建立元素间的语义连接。
-
操作:
-
阅读顺序判定:确定文本的阅读流(对于中文,通常是左上到右下)。
-
层级关系构建:建立"章->节->小节->段落"的树形结构。
-
引用关系链接:将"如图1所示"中的"图1"链接到实际的图表及其标题。
-
表格结构恢复:将单元格按行、列、表头进行关联,重建二维数据结构。
-
-
-
结构化建模与输出:
-
目的 :将关系固化为标准化的数据结构。
-
操作:
-
映射到标准格式 :将分析结果输出为 JSON、XML (如PAGE, ALTO) 或 HTML。
-
填充数据库/知识图谱:将实体(如人名、公司名、产品名)及其关系(如"任职于"、"生产")提取出来,构建知识图谱。
-
还原为可编辑格式:如生成结构清晰的 Word、PDF 或 Excel 文件。
-
-
路径二:端到端AI范式(前沿研究与应用)
以大模型(尤其是多模态大模型)为代表,极大地压缩甚至重构了上述流程。
-
核心思想:不明确划分"感知"与"结构"步骤,而是用一个统一的模型,直接从像素输入,生成结构化理解。
-
如何工作:
-
统一编码:使用视觉Transformer等架构,将图像和文本(如果已有)编码为统一的特征表示。
-
理解与生成:模型基于海量数据训练出的"世界知识"和"文档常识",直接理解图像内容。
-
指令化输出 :通过提示工程,让模型按需输出结构。例如,给一张发票图片并提示:"请将这张发票的信息提取为JSON格式,包含'卖方名称'、'总金额'、'开票日期'等字段。" 模型可以直接生成:
{ "seller_name": "XX科技有限公司", "total_amount": "¥5, 280.00", "invoice_date": "2023年10月26日" }
-
-
优势:简化流程、对不规则版式鲁棒性强、能结合常识进行深度推理。
-
挑战:需要巨大算力和数据、输出可能不稳定("幻觉")、成本高、过程不可控(黑盒)。
总结与对比
| 特性 | 传统/混合流水线 | 端到端AI范式(大模型) |
|---|---|---|
| 过程 | 分步骤,模块化,可解释性强。 | 端到端,一体化,黑盒性较强。 |
| 优势 | 稳定、可控、对算力要求相对低、在格式规范场景精度高。 | 灵活、智能、能处理复杂版式和模糊逻辑、无需精细特征工程。 |
| 劣势 | 流程复杂、误差会累积、对不规则版式适应性差。 | 成本高、可能产生"幻觉"、需要大量数据、部署复杂。 |
| 适用场景 | 海量、格式相对固定的文档处理(如银行票据、表单)、对准确率和可控性要求极高的场景。 | 版式复杂多变、需要深度语义理解、小批量或探索性的场景(如法律合同分析、研究论文信息抽取)。 |
实践中的最佳路径往往是二者的结合 :用大模型 解决复杂理解、上下文关联和模糊推理问题;用传统流水线处理大量规范化、高精度要求的任务,并作为大模型输出的验证和纠错层。