视频讲解1:Bilibili视频讲解
视频讲解2:https://www.douyin.com/video/7580616343997648179
论文下载:https://arxiv.org/abs/2208.13721
代码下载:https://github.com/Verg-Avesta/CounTR
https://github.com/KeepTryingTo
基于Zero-Shot的计数算法详解(T2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting)
统一的人群计数训练框架(PyTorch)------基于主流的密度图模型训练框架
算法VLCount详解(VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting)
人群计数中常用数据集的总结以及使用方式(Python/PyTorch)
基于Zero-Shot的目标计数算法详解(Open-world Text-specified Object Counting)
基于zero-shot目标计数方法详解(Zero-Shot Object Counting)
本文提出基于Transformer的广义视觉计数框架CounTR,突破传统方法在类别特定和泛化能力上的局限。创新点包括:1)基于ViT的架构设计,通过注意力机制显式捕获图像块相似性;2)两阶段训练策略,结合自监督预训练和监督微调;3)可扩展MOS数据增强技术,缓解数据长尾分布问题;4)测试时优化策略,包括归一化校准和滑动窗口预测。该方法在零样本设置下展现出优越性能,为跨模态计数任务提供了新思路。相关代码和论文已开源。
目录
[1 传统计数方法的类别特定限制](#1 传统计数方法的类别特定限制)
[2 类别无关计数方法的结构限制](#2 类别无关计数方法的结构限制)
[1 基于Transformer的创新架构](#1 基于Transformer的创新架构)
[2 两阶段训练策略的创新](#2 两阶段训练策略的创新)
[3 可扩展MOS数据增强](#3 可扩展MOS数据增强)
[4 测试时优化策略 测试时归一化](#4 测试时优化策略 测试时归一化)

现有方法的局限性
1****传统计数方法的类别特定限制
传统视觉计数方法主要分为两类:基于检测的计数和基于回归的计数。这些方法存在明显的局限性:基于检测的方法(如Faster-RCNN、RetinaNet)依赖视觉对象检测器来定位图像中的对象实例。然而,这种方法需要为不同的对象训练单独的检测器,并且在只有少量标注的情况下检测问题仍然具有挑战性。基于回归的方法避免了解决困难的检测问题,而是学习从全局图像特征到标量(对象数量)的映射,或者从密集图像特征到密度图的映射。虽然在对重叠实例计数方面取得了更好的结果,但这两类方法都只能计数特定类别的对象(如车辆、细胞、人群)。
2****类别无关计数方法的结构限制
现有的类别无关计数方法(如GMN、FamNet、BMNet+)主要基于卷积神经网络架构,存在以下局限性:特征交互能力有限:传统CNN架构在显式比较图像块之间或与"样例"之间的相似性方面存在固有局限,无法充分利用图像中的自相似性先验。泛化能力不足:现有方法在处理全新类别时泛化能力有限,特别是在零样本设置下性能显著下降。长尾分布挑战:现有计数数据集高度偏向于包含少量对象的图像,导致模型在处理包含大量对象的图像时性能不佳。
提出方法
针对上述局限性,本文提出了基于Transformer的广义视觉计数框架,其核心创新体现在架构设计、训练策略和数据增强三个方面。
1基于Transformer****的创新架构
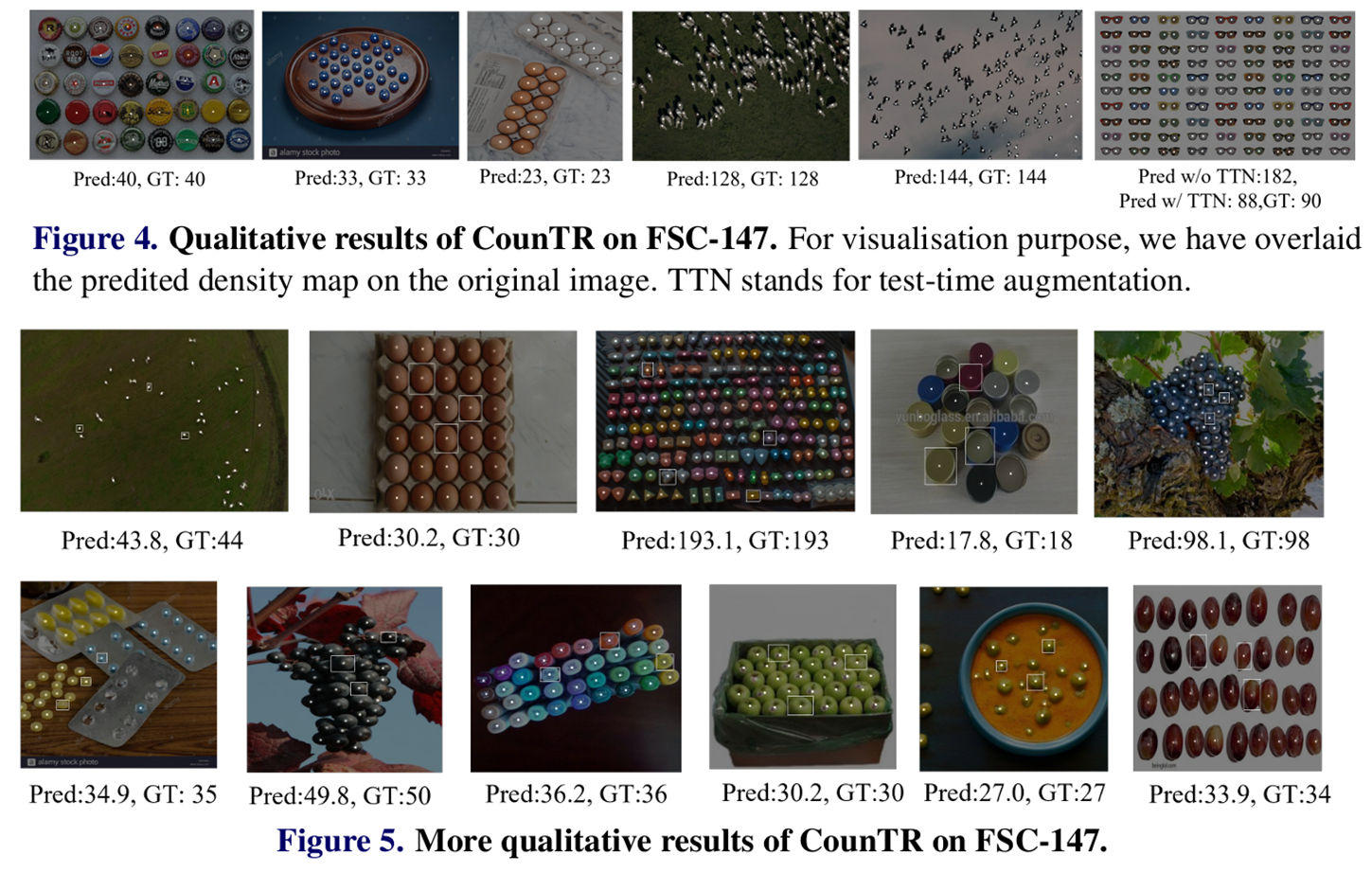
CounTR架构通过注意力机制显式捕获图像块之间的相似性,完美反映了计数问题中的自相似性先验。如图1所示,该架构包含三个关键组件:视觉编码器:使用Vision Transformer处理输入图像,将其映射到高维特征空间。输入图像被分割为16×16像素的块,通过12层Transformer编码器处理。特征交互模块:这是CounTR的核心创新,使用Transformer解码器层显式比较查询图像与示例之间的相似性。图像特征作为Query,示例特征的线性投影作为Key和Value。解码器:采用渐进式上采样设计,将特征交互模块的输出恢复至原始图像分辨率,生成密度热图。
2****两阶段训练策略的创新
本文提出了创新的两阶段训练方案,有效解决了数据稀缺和模型泛化问题:自监督预训练阶段:采用掩码自编码器方法,随机丢弃50%的视觉标记,让模型从部分观察中重建输入图像。这种预训练使模型能够学习计数任务的视觉表示。监督微调阶段:使用均方误差损失函数,在生成的密度图与真实密度图之间进行优化。通过60倍的损失缩放和随机丢弃20%像素的策略,缓解样本不平衡问题。
3可扩展MOS****数据增强
为了解决现有计数数据集中的长尾分布问题,本文提出了创新的MOS数据增强 流水线,两种合成模式:A****型:使用四张不同图像合成,显著提高训练图像的背 景多样性; B****型:使用单张图像合成,增加图像中包含的对象数量;边界融合技术:通过α通 道融合技 术消除合成图像边界处的尖锐伪影,使图像合成更加真实。
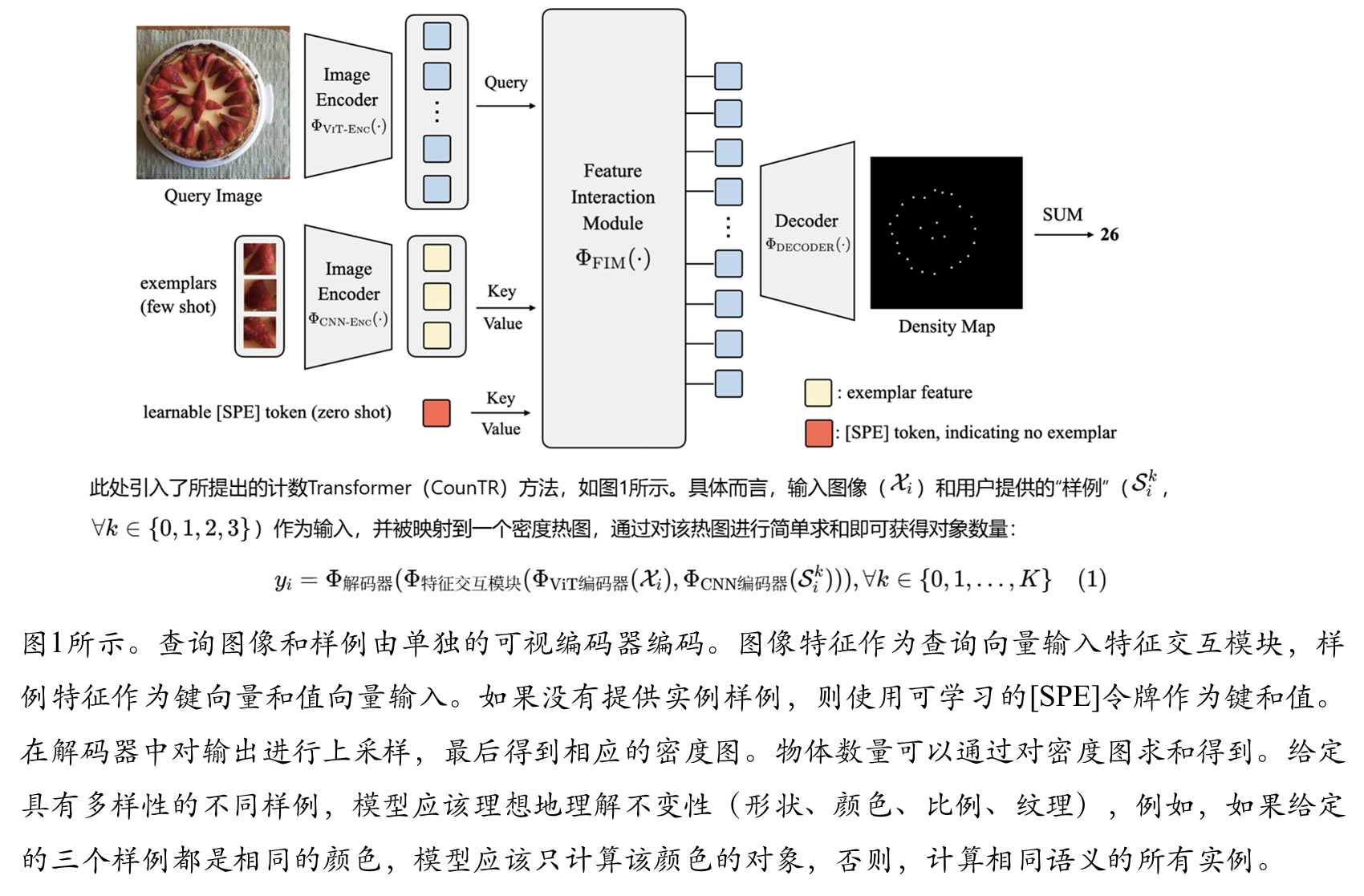
4 测试时优化策略 测试时归一化
针对少样本计数场景,提出了测试时归一化策略来校准输出密 度图。该方法基于示例位置的对象计数应为1.0的先验知识,通过除以示例位置 当前预测 计数来校准密度图;**滑动窗口预测:**对于包含微小对象的图像(示例边长小于10像 素),采用等分九块的滑动窗口预测策略,将图像分割后分别处理,最后汇总计数结果
具体方法细节
符号定义

视觉编码器模块

特征交互模块

解码器模块

两阶段训练方案

可缩放的MOS数据增强

**拼贴:**首先从图像中裁剪一个随机大小的正方形区域,并将其缩放至统一尺寸,例如原始图像大小的四分之一。在多次重复区域裁剪后,将裁剪的区域拼贴在一起,并更新相应的密度图。这有两种不同的形式:仅使用一张图像或使用四张不同的图像。如果仅使用一张图像,可以增加图像中包含的物体数量,这有助于解决长尾问题。如果使用四张不同的图像,可以显著提高训练图像的背景多样性,并增强模型区分不同类别物体的能力。为充分利用这两种优势,进行以下设置:如果图像中包含的物体数量超过某个阈值,则使用同一张图像进行拼贴;如果没有超过,则使用四张不同的图像。如果使用四张不同的图像,则只能在推理时使用少样本设置,否则模型将不知道要计数哪个物体。如果使用同一张图像,则MOS处理后的图像可用于训练少样本和零样本设置。
**融合:**简单的裁剪和拼贴无法合成完美的图像,因为在边界处会存在一些伪影。为解决这些伪影,利用图像连接处的α通道融合技术。在实践中,裁剪的图像尺寸略大于原始图像尺寸的四分之一,以便在边界处留出特定空间进行α通道融合。使用随机的α通道边界宽度,使图像合成更加真实。需要注意的是,仅对原始图像进行融合而不对密度图进行融合,以保持点标注的形式(只有0和1)。由于融合边界内的物体很少,并且使用单张图像的马赛克仅应用于包含大量物体的图像,因此由融合引起的误差几乎可以忽略不计。
测试阶段
训练和微调细节
MAE****预训练阶段:输入图像尺寸为384×384,首先被分割为16×16的图像块,并投影为576维向量。视觉编码器使用12个Transformer编码器块,隐藏维度为768,多头自注意力层的头数为12。解码器使用8个Transformer层,隐藏维度为512。在MAE预训练中,随机丢弃50%的视觉标记,任务目标是通过像素级均方误差重建被遮蔽的图像块。预训练批处理大小为16,在FSC-147数据集上训练300个周期,学习率为5×10⁻⁶。
微调****阶段:特征交互模块使用2个Transformer解码器层,隐藏维度为512。ConvNet编码器采用4个卷积层和全局平均池化层,提取512维的示例特征。图像解码器使用4个上采样层,隐藏维度为256。优化目标是最小化模型预测与真实密度图(以高斯分布标注物体中心生成)之间的均方误差。将损失函数缩放60倍,并随机丢弃20%像素以缓解样本不平衡问题。使用AdamW优化器,在FSC-147训练集上以1×10⁻⁵的学习率和批处理大小8进行训练。模型在NVIDIA GeForce RTX 3090上进行训练和测试。
实验结果
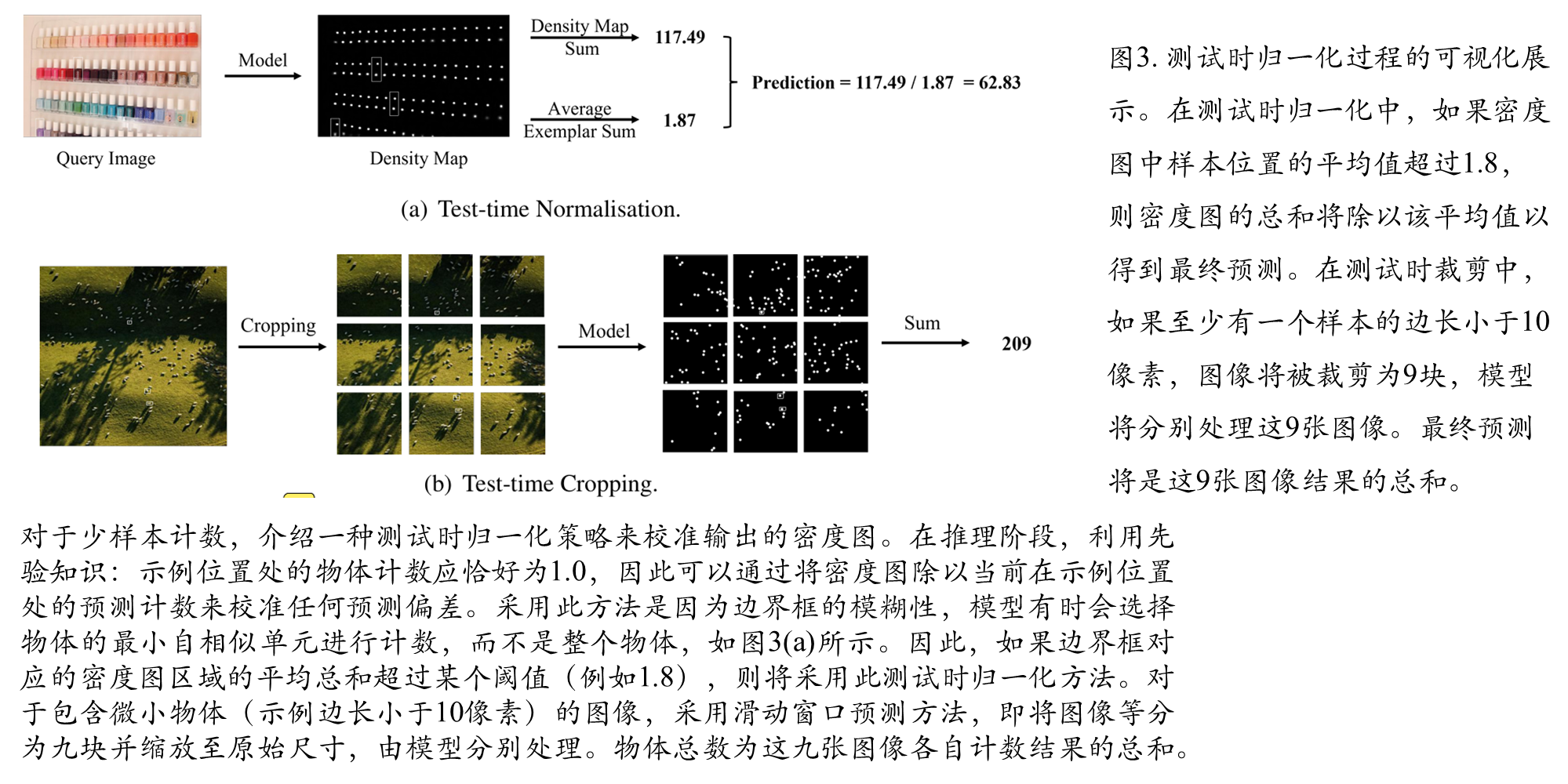
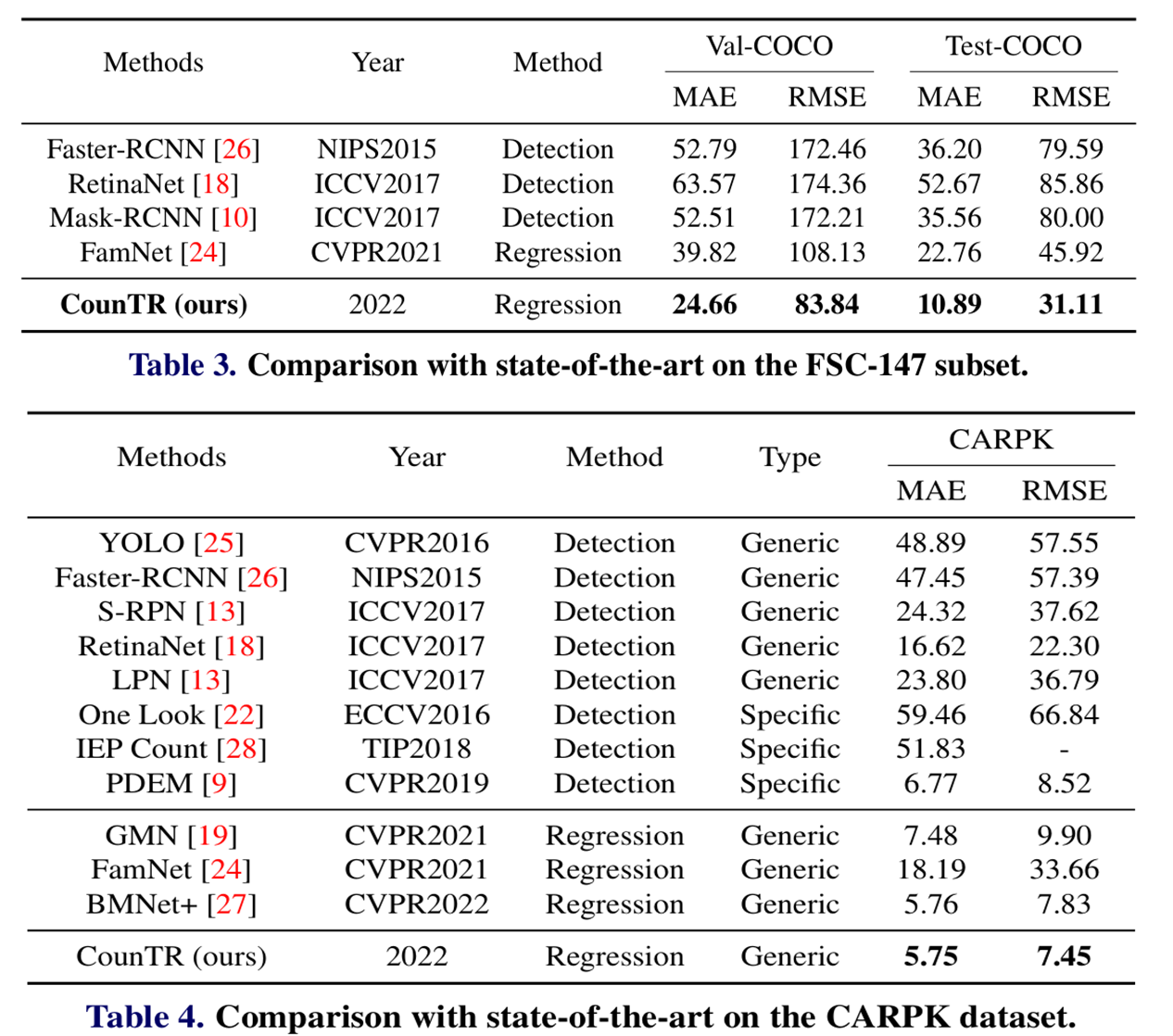
综合比较
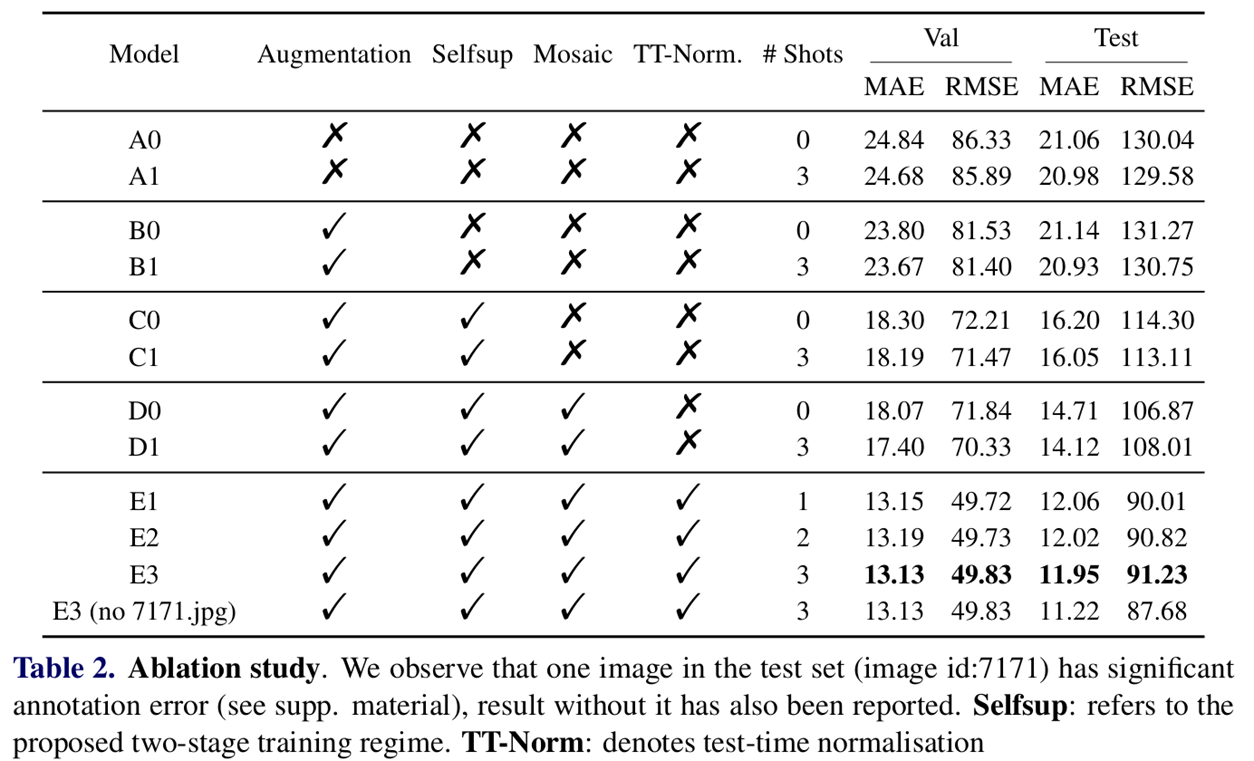
消融实验

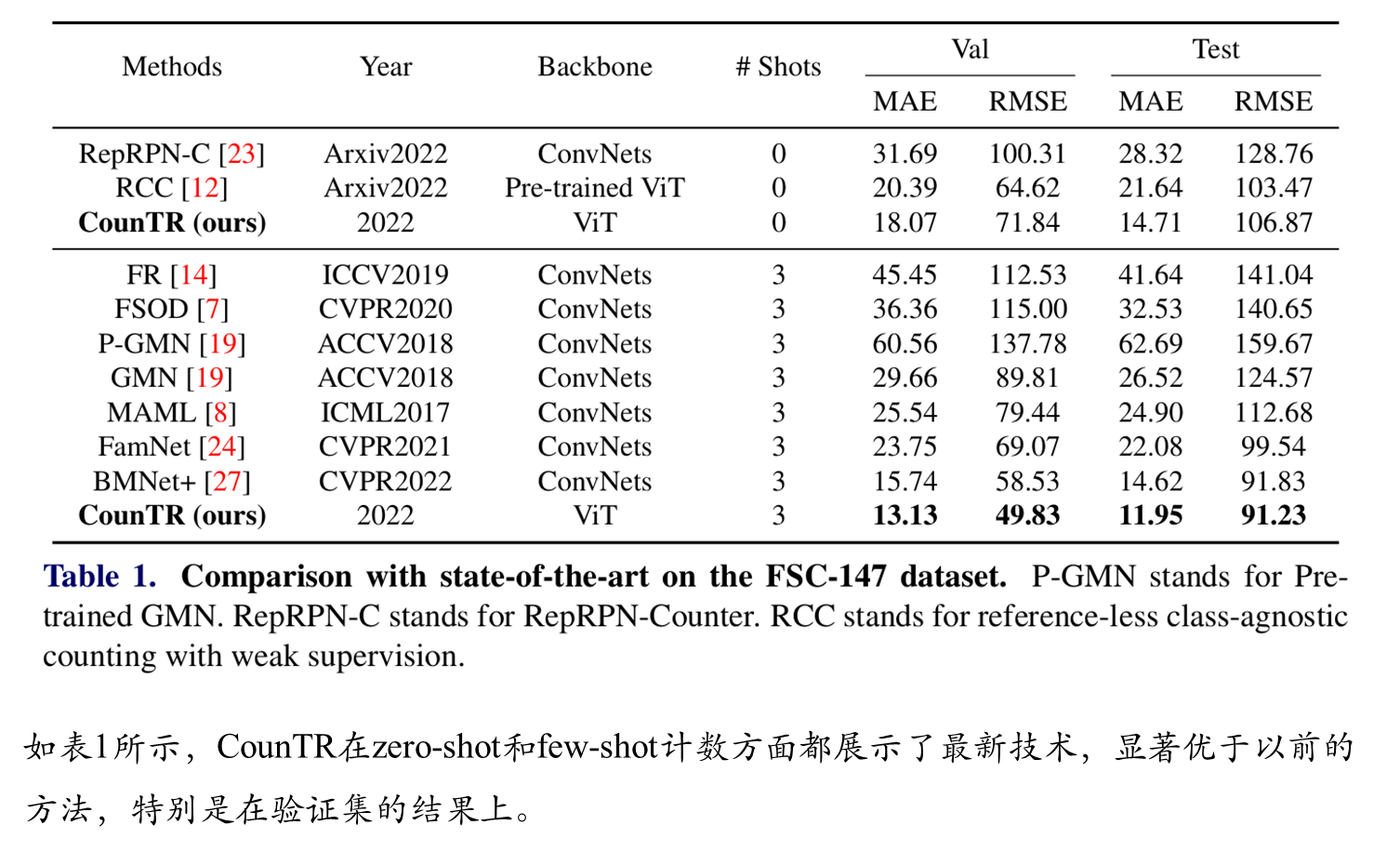
可视化结果