论文名称:Beyond Self-Attention: Deformable Large Kernel Attention for Medical Image Segmentation
论文原文 (Paper) :https://arxiv.org/abs/2309.00121
代码 (code) :https://github.com/xmindflow/deformableLKA
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
-
- 论文精度:deformableLKA
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
- [3. 主要贡献点](#3. 主要贡献点)
- [4. 方法细节(最重要)](#4. 方法细节(最重要))
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验分析总结:D-LKA Net 的全面领先与效能优势](#6. 实验分析总结:D-LKA Net 的全面领先与效能优势)
- [7. 获取即插即用代码关注 【AI即插即用】](#7. 获取即插即用代码关注 【AI即插即用】)
论文精度:deformableLKA
1. 核心思想
- 本文提出了一种名为可变形大核注意力(Deformable Large Kernel Attention, D-LKA)的新型注意力机制,其核心思想是将大核卷积(LKA)的"全局上下文"能力与可变形卷积(Deformable Conv)的"形状自适应"能力相结合。
- 它通过"分解"大核卷积(分解为深度可分离卷积和空洞卷积)来模拟自注意力(Self-Attention)的大感受野,但避免了自注意力机制 O ( N 2 ) O(N^2) O(N2) 的高计算复杂度。
- 通过引入可变形(Deformable)特性,该模块的采样网格可以动态"扭曲",以适应医学图像中常见的不规则病变和器官形态。
- 基于此模块,论文构建了 2D 和 3D 的 D-LKA Net 架构,旨在高效处理 2D 图像并(更重要地)解决 3D 伪切片(pseudo 3D)方法中丢失的层间上下文信息。
2. 背景与动机
-
文本角度总结
- 现有模型的两难困境:
- CNNs (如 U-Net) 擅长捕捉局部细节,但受限于固定的、较小的感受野,难以理解全局上下文。
- Transformers (ViT) 擅长通过自注意力捕捉长程依赖(全局上下文),但计算复杂度与图像大小(Token 数量)平方相关,导致其在处理高分辨率医学图像(尤其是 3D)时计算量过大。
- 医学图像的特定挑战:
- 3D 上下文丢失(核心痛点): 大多数现有的 3D Transformer 模型为了节省计算量,采用"伪 3D"(pseudo 3D)方式,即逐个切片(slice-by-slice)处理 3D 容积数据。这完全忽略了切片之间的上下文信息(例如一个肿瘤在 Z 轴上的连续性),导致分割结果在 3D 空间中出现断层和不一致。
- 形状不规则: 肿瘤和器官(如胰腺)的形态极不规则且多变(deformed),标准卷积核和 ViT 的刚性网格(Patch)难以精确贴合其边界。
- 待解决的问题: 如何设计一个计算高效 (非平方复杂度)、能捕捉全局 上下文、能处理真实 3D 数据(而非切片)、并且能自适应不规则形状的分割模型?
- 现有模型的两难困境:
-
动机图解分析:
- 图表 A (论文附录 Figure 11):伪 3D vs. 真实 3D 的对比
- "看图说话": 这张图是本文 3D 架构的核心动机。它对比了"2D D-LKA Net"和"3D D-LKA Net"在同一 3D 容积数据上的分割结果。
- 分析: 在"2D D-LKA Net"(伪 3D)的结果中,我们可以清晰地看到(尤其是在肝脏-粉色、肾脏-青色和红色区域)分割体素是一层一层孤立的、破碎的 ,在 Z 轴上缺乏连续性,产生了严重的"断层"伪影。
- 结论: 这直观地暴露了 2D 切片处理 3D 问题的根本缺陷------丢失了切片间的上下文。而右侧的"3D D-LKA Net"结果则是平滑、完整且连续的,与"Ground Truth"高度一致。这强有力地证明了开发一个真正的 3D 上下文感知模型(如 3D D-LKA Net)的必要性。
- 图表 B (论文正文 Figure 6):不规则形状的挑战
- "看图说话": 这张图展示了对胰腺(Pancreas)的分割结果,胰腺是一个形态极不规则的器官。
- 分析:
UNETR的结果是破碎、不完整的。UNETR++的结果虽然连续,但在精细的边缘处仍有粘连和缺失。 - 结论: 这说明即使是先进的 Transformer 模型,在处理这种高度不规则和"可变形"的结构时依然面临挑战。这直接引出了本文的第二个核心动机:模型不仅需要大感受野,还需要灵活的、非刚性的采样能力,这正是"Deformable"(可变形)卷积的用武之地。
- 图表 A (论文附录 Figure 11):伪 3D vs. 真实 3D 的对比
3. 主要贡献点
-
提出 D-LKA 注意力模块(Figure 2):
- 本文提出了一种新颖的**可变形大核注意力(D-LKA)**模块。它巧妙地将大核注意力(LKA)和可变形卷积(Deformable Conv)的优势结合起来。
- LKA 提供了类自注意力的全局感受野 (通过分解大核实现),但计算成本远低于自注意力(线性复杂度)。Deformable Conv 提供了形状自适应能力。
- 因此,D-LKA 是一个计算高效、能捕捉全局上下文、且能自适应不规则形状的全新注意力模块。
-
构建了 3D D-LKA-former 架构(Figure 1a):
- 针对医学 3D 数据(如 CT/MRI)中"伪 3D"处理丢失层间信息的核心痛点,本文设计了一个真正的 3D 架构。
- 该架构是一个基于 3D D-LKA 模块的 U-Net 形态编码器-解码器,它在所有阶段都使用 3D 卷积和 3D 注意力,能够充分学习和利用切片间的上下文信息,解决了 Figure 11 所示的断层问题。
-
构建了 2D D-LKA-former 架构(Figure 1c):
- 本文还提供了一个高效的 2D 混合模型。它创新地使用
MaxViT(一个 CNN-Transformer 混合体)作为编码器来高效提取多尺度特征。 - 在解码器中,它使用 2D D-LKA 模块来上采样和优化分割边界 。这种设计结合了
MaxViT的效率和 D-LKA 的全局及自适应能力。
- 本文还提供了一个高效的 2D 混合模型。它创新地使用
-
在多项基准上达到 SOTA:
- 所提出的 2D 和 3D D-LKA Net 在多个公开的医学分割数据集上(包括 Synapse 多器官、NIH 胰腺和 Skin Lesion 皮肤病变)均取得了 SOTA(State-of-the-art)或具有竞争力的表现。
- 特别是在 Synapse 3D 和 NIH 胰腺 3D 数据集上,3D D-LKA Net 在参数量和计算量(GFLOPs)远低于
Swin-UNETR和nnFormer的情况下,取得了更优的分割精度(DSC),展示了其卓越的效率和性能。
4. 方法细节(最重要)
-
整体网络架构(Figure 1) :
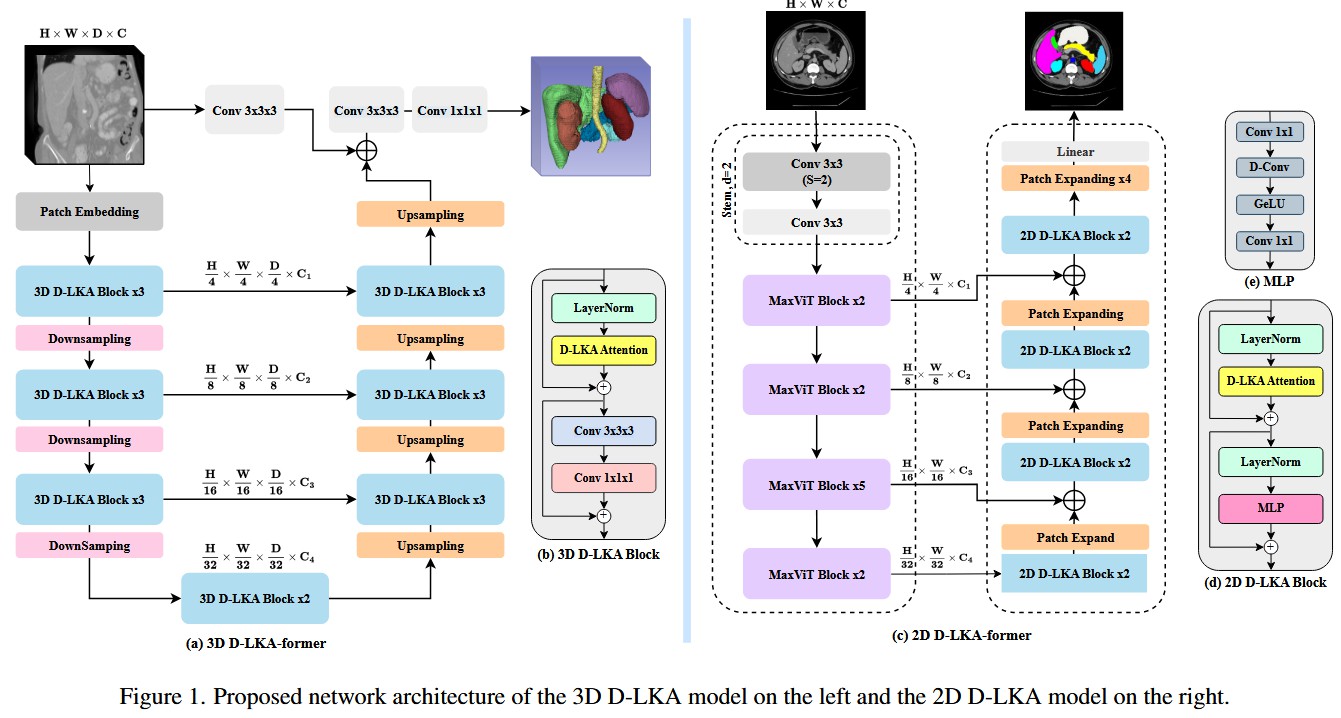
- 模型名称: D-LKA Net (或 D-LKA-former)
- © 2D D-LKA-former (混合架构):
- 数据流: 这是一个 U 形的编码器-解码器架构。
- 编码器 (Encoder, 紫色路径): 使用
MaxViT作为主干网络。MaxViT是一个 CNN 和 Transformer 的混合体,它通过 4 个 Stage 产生 H 4 , H 8 , H 16 , H 32 \frac{H}{4}, \frac{H}{8}, \frac{H}{16}, \frac{H}{32} 4H,8H,16H,32H 四个层级的特征。 - 解码器 (Decoder, 蓝色路径): 解码器包含 4 个 Stage。在每个 Stage,来自编码器的特征(通过跳跃连接)与上一层上采样的特征相加。
- 解码模块: 融合后的特征被送入
2D D-LKA Block(包含 2 个) 进行特征提炼。 - 上采样:
Patch Expanding层负责将分辨率提高 2 倍,同时减少通道数。
- (a) 3D D-LKA-former (纯 D-LKA 架构):
- 数据流: 这是一个纯粹基于 3D D-LKA Block 构建的 3D U-Net 架构。
- 编码器 (Encoder, 蓝色路径): 输入的 3D 容积数据首先经过
Patch Embedding( 4 × 4 × 2 4 \times 4 \times 2 4×4×2 的 3D 卷积)进行降采样。然后依次通过 4 个 Stage 的3D D-LKA Block(每个 Stage 包含 3 或 2 个 Block) 和Downsampling层(3D 卷积)。 - 解码器 (Decoder, 蓝色路径): 结构与编码器对称。
Upsampling(转置卷积)负责恢复分辨率,3D D-LKA Block负责提炼特征。 - 跳跃连接 (Skip Connections): 编码器和解码器之间通过简单的特征相加进行连接。
- 特殊设计: 注意在最顶层有一个从输入直接到输出的远跳跃连接 (经过两个
Conv 3x3x3),这有助于网络将原始的低级特征(如边缘)直接传递到最后,辅助精细分割。
-
核心创新模块详解(Figure 2, 1b, 1d) :
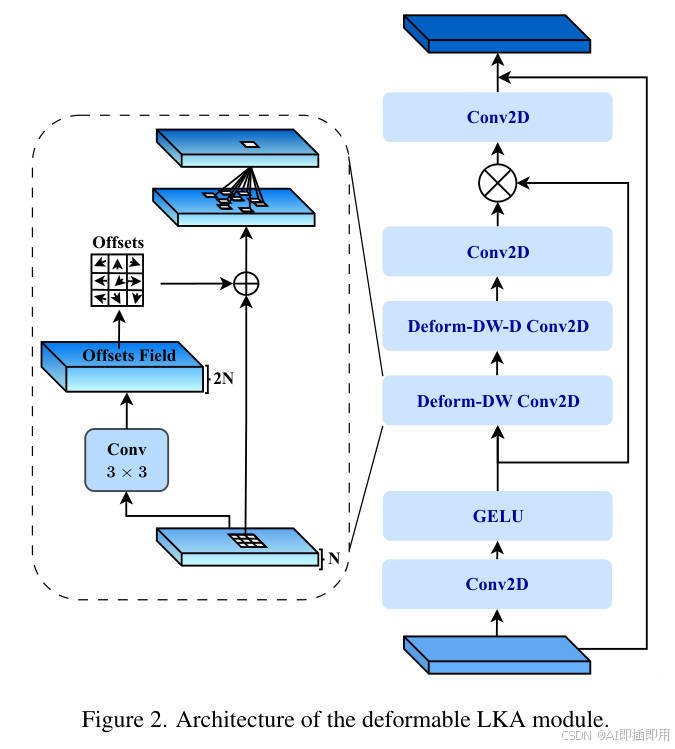
- 模块 A:2D D-LKA 注意力模块 (Figure 2)
- 理念: 这是论文的核心创新。它在 LKA(大核注意力)的基础上,将标准卷积替换为了可变形卷积。
- 数据流 (右半部分):
- 输入特征首先经过
Conv2D和GELU激活,得到特征 F ′ F' F′。 - F ′ F' F′ 接着连续 经过两个可变形卷积:
Deform-DW Conv2D(可变形深度可分离卷积) 和Deform-DW-D Conv2D(可变形深度可分离空洞卷积)。这一步是 LKA 的核心,通过"深度可分离+空洞"的组合,用很少的计算量模拟了一个巨大的感受野。 - 结果再经过一个
Conv2D,生成Attention图。 - 该
Attention图与 F ′ F' F′(来自 GELU)进行逐元素相乘 ( ⊗ \otimes ⊗),实现注意力加权。 - 最后通过一个
Conv2D输出(并加上残差连接,未在 Figure 2 右侧显示,但在 Eq 8 中明确)。
- 输入特征首先经过
- 可变形机制 (左侧气泡):
Deform-DW卷积如何知道往哪里偏移?- F ′ F' F′(GELU 的输出)被送入一个并行的
Conv 3x3小卷积层。 - 这个小卷积层专门负责生成
Offsets Field(偏移场),该偏移场告诉Deform-DW卷积层上的每个采样点应该向 ( x , y ) (x, y) (x,y) 方向偏移多少。
- 设计目的: 同时获得 LKA 的大感受野(全局上下文)和 Deformable Conv 的形状自适应能力。
- 模块 B:2D D-LKA Block (Figure 1d)
- 理念: 这是一个标准的 Transformer Block 结构,但把自注意力(Self-Attention)换成了 D-LKA 模块。
- 数据流: 这是一个"前归一化"(Pre-Norm)结构。
LayerNorm→ \rightarrow →D-LKA Attention(即模块 A) → \rightarrow → 残差连接 → \rightarrow →LayerNorm→ \rightarrow →MLP(Figure 1e 所示,由 1x1, D-Conv, 1x1 组成) → \rightarrow → 残差连接
- 设计目的: 将 D-LKA 注意力封装成一个可堆叠、可重复使用的标准模块。
- 模块 C:3D D-LKA Block (Figure 1b)
- 理念: 2D Block 的 3D 版本,但在 MLP 部分有所不同。
- 数据流:
LayerNorm→ \rightarrow →D-LKA Attention(3D 版) → \rightarrow → 残差连接 → \rightarrow →Conv 3x3x3→ \rightarrow →Conv 1x1x1→ \rightarrow → 残差连接
- 设计目的: 它用一个标准的 CNN 模块 ( 3 × 3 × 3 3 \times 3 \times 3 3×3×3 和 1 × 1 × 1 1 \times 1 \times 1 1×1×1 卷积)替换了 2D Block 中的 MLP。这种 CNN + Attention 混合的 Block 设计在 3D 任务中更常见,有助于增强 3D 空间中的局部特征提取能力。
- 模块 A:2D D-LKA 注意力模块 (Figure 2)
-
理念与机制总结:
- D-LKA 如何取代自注意力?
- 自注意力(Self-Attention, SA)通过 Q × K T Q \times K^T Q×KT 计算全局相关性,复杂度为 O ( N 2 ) O(N^2) O(N2)。
- LKA(大核注意力)通过 K × K K \times K K×K 的大卷积核(分解为 D W - C o n v DW \text{-} Conv DW-Conv + D W - D - C o n v DW \text{-} D \text{-} Conv DW-D-Conv)实现等效的大感受野 ,复杂度仅为 O ( N ) O(N) O(N)( N N N 是像素/体素总数)。
- D-LKA 继承了 LKA 的 O ( N ) O(N) O(N) 复杂度,同时通过可变形卷积(Deformable Conv)增加了 SA 所不具备的空间采样灵活性(形状自适应)。
- 公式解读 (Eq 8):
- A t t e n t i o n = C o n v 1 × 1 ( D D W - D - C o n v ( D D W - C o n v ( F ′ ) ) ) Attention = Conv1 \times 1(DDW\text{-}D\text{-}Conv(DDW\text{-}Conv(F'))) Attention=Conv1×1(DDW-D-Conv(DDW-Conv(F′)))
- O u t p u t = C o n v 1 × 1 ( A t t e n t i o n ⊗ F ′ ) + F Output = Conv1 \times 1(Attention \otimes F') + F Output=Conv1×1(Attention⊗F′)+F
- 第一行公式展示了 Attention Map 是如何通过 LKA 结构(
DDW-Conv+DDW-D-Conv)从特征 F ′ F' F′ 中生成的。 - 第二行公式是标准的主干流程:将生成的 A t t e n t i o n Attention Attention 施加( ⊗ \otimes ⊗)到 F ′ F' F′ 上(Value),并通过残差连接( + F + F +F)输出。
- 3D 与 2D 的关键差异 (Ablation Table 5):
- 在 2D 中,D-LKA 直接将标准 D W DW DW 卷积替换 为
Deform-DW卷积 (如图 Figure 2)。 - 在 3D 中,由于 3D 偏移场的计算量巨大,作者做了一个妥协(见 Table 5)。3D D-LKA Net 采用的是"3D LKA + 3D deform. conv.",即它在标准 LKA 模块之后,额外添加了一个 3D 可变形卷积层,以此在控制计算量的同时引入形状自适应能力。
- 在 2D 中,D-LKA 直接将标准 D W DW DW 卷积替换 为
- D-LKA 如何取代自注意力?
-
图解总结:
- 问题 1 (Figure 11): 2D 伪 3D 方法导致 Z 轴"断层"。
- 解决方案 1 (Figure 1a):
3D D-LKA-former架构使用纯 3D 模块,强制网络学习**跨切片(Volumetric)**的上下文,完美解决了断层问题。 - 问题 2 (Figure 6): 器官和病变形状不规则,难以贴合。
- 解决方案 2 (Figure 2):
D-LKA Attention模块的核心是可变形 卷积,它通过学习Offsets Field来使采样网格动态扭曲,从而精确地适应不规则的器官边界。 - 问题 3 (ViT 通病): 自注意力计算复杂度高 ( O ( N 2 ) O(N^2) O(N2))。
- 解决方案 3 (Eq 1-8): D-LKA 采用"分解大核"的 LKA 策略,将计算复杂度降至线性 ( O ( N ) O(N) O(N)),使其在 3D 高分辨率数据上依然高效。
5. 即插即用模块的作用
- 本文的核心创新 D-LKA 注意力模块(Figure 2) 和 D-LKA Block(Figure 1b/1d) 被设计为即插即用的组件。
- 适用场景 1:替代标准自注意力(Self-Attention)
- 应用: 在任何标准的 Vision Transformer 架构中(如 ViT, Swin-Unet, UNETR),D-LKA Block 可以直接替代原有的自注意力模块(MSA 或 W-MSA)。
- 优势: (1) 极大降低计算复杂度(从 O ( N 2 ) O(N^2) O(N2) 降至 O ( N ) O(N) O(N));(2) 额外提供了标准 SA 所不具备的"形状自适应"能力。
- 适用场景 2:升级现有 CNN 解码器
- 应用: 在任何 U-Net 型架构(如标准 U-Net, Res-UNet)中,可以用 2D 或 3D D-LKA Block 替换解码器中的标准卷积块。
- 优势: 这能为原本只具备局部感受野的 CNN 解码器,赋予捕捉"全局上下文"和"形状自适应"的能力,有助于优化大尺度目标的分割完整性和不规则边缘的精细度。
- 适用场景 3:构建新型 3D 分割网络(如本文 Figure 1a)
- 应用: D-LKA Block 是一个高效的 3D 基础模块。研究者可以像搭乐高一样,使用它来构建各种新型的、端到端的 3D 容积感知网络(U-Net, FPN 等)。
- 优势: 它是解决"伪 3D"问题的一个高性能、高效率的组件,特别适用于 CT 和 MRI 容积数据的分割。
6. 实验分析总结:D-LKA Net 的全面领先与效能优势
D-LKA Net 在 2D 和 3D 的医学图像分割任务中均表现出了超越当前 SOTA 方法的性能。
-
2D 性能领先: 在 Synapse 多器官分割数据集上,D-LKA Net 在 DSC 指标上超越了 ScaleFormer、DAEFormer 等先进模型,特别是在胰腺、胆囊等难以分割的小器官上提升显著(DSC 分别提升 2.04% 和 1.64%)。同时,在 ISIC 和 PH² 皮肤病变数据集上,D-LKA Net 也展现出了稳定的优越性和强大的泛化能力。
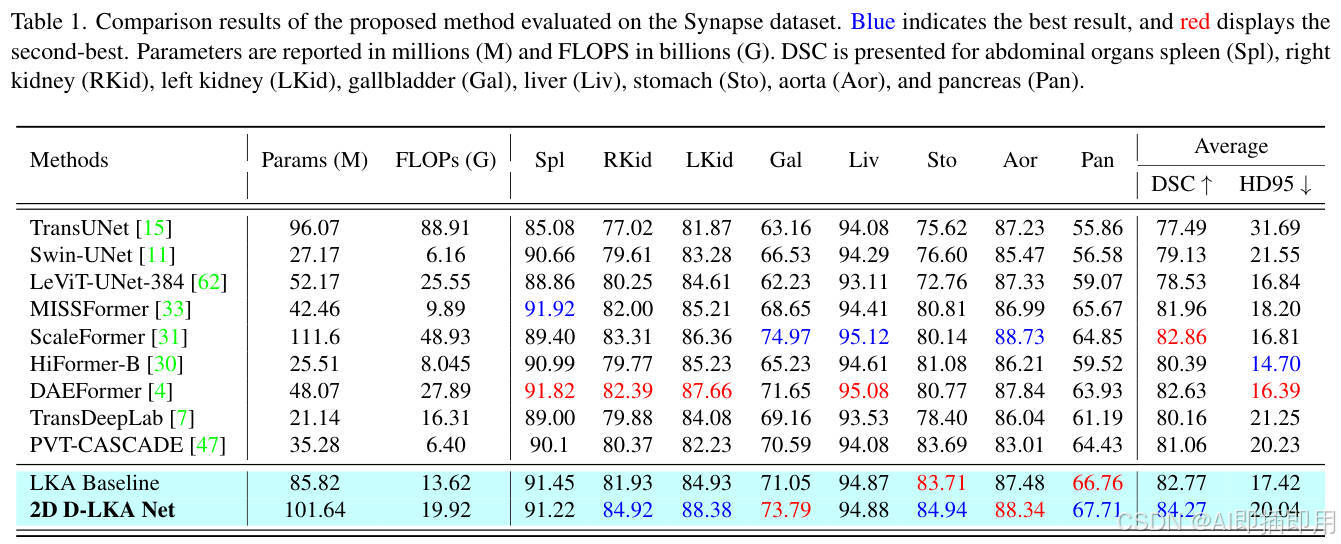
-
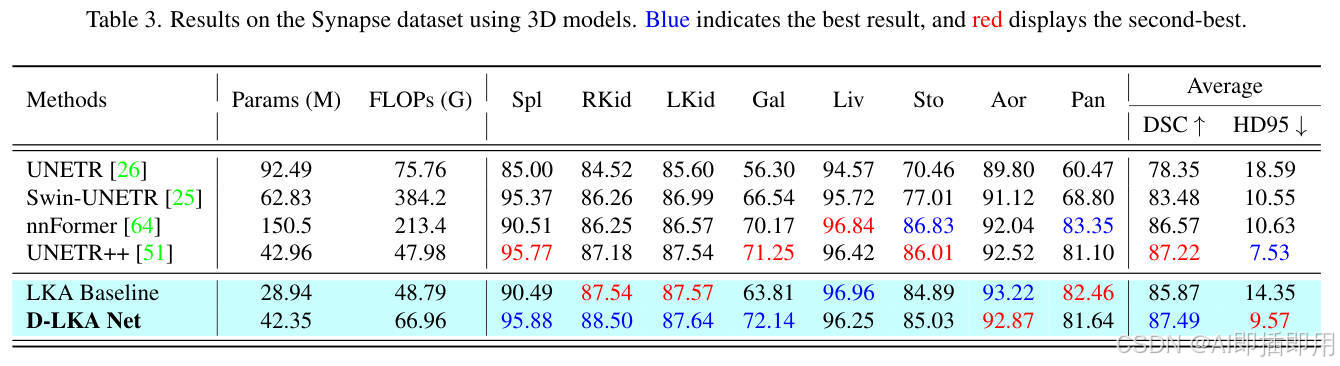
3D 性能与效率兼顾: 3D D-LKA Net 在 Synapse 数据集上以仅 42.35M 的参数量(最低)和 66.96G 的 FLOPs(第二低),取得了比 UNETR++ 更高的 DSC(提升 0.27%)。在 NIH 胰腺数据集上,它同样在 DSC、Jaccard、HD95 和 ASD 所有指标上全面领先,且参数量远低于竞争对手。
-
消融实验验证: 实验证实了可变形卷积(Deformable Convolution)和最高层级跳跃连接(Skip Connections)对性能提升的关键作用,分别带来了 0.63% 和 0.42% 的 DSC 增益 cite: 3290-3293, 3301。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。