论文名称:SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications
> 论文原文 (Paper) :https://arxiv.org/abs/2303.15446
> 代码 (code) :https://github.com/Amshaker/SwiftFormer
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
-
- 论文精读:SwiftFormer
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
- [3. 主要贡献点](#3. 主要贡献点)
- [4. 方法细节](#4. 方法细节)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验结果总结与分析](#6. 实验结果总结与分析)
- [7. 获取即插即用代码关注 【AI即插即用】](#7. 获取即插即用代码关注 【AI即插即用】)
论文精读:SwiftFormer
1. 核心思想
- 本文提出了一种名为 SwiftFormer 的、专为移动端实时应用设计的高效 Transformer 架构。
- 其核心创新是高效加法注意力(Efficient Additive Attention)机制,它彻底解决了标准自注意力(Self-Attention)中 O ( N 2 ) O(N^2) O(N2) 的平方复杂度瓶颈。
- 该机制通过将昂贵的矩阵乘法( Q ⋅ K T Q \cdot K^T Q⋅KT)替换为廉价的逐元素乘法(element-wise multiplication) ,并用一个简单的线性(Linear)层取代 了显式的"键-值"(Key-Value)交互,从而实现了 O ( N ) O(N) O(N) 的线性复杂度。
- 这种高效的设计使得 Transformer 模块(
SwiftFormer Encoder)可以被部署在网络的所有阶段(包括高分辨率的早期阶段),从而在实现 SOTA 级别的移动端延迟(例如 iPhone 14 上 0.8ms)的同时,达到了比 MobileViT-v2 和 EfficientFormer 等模型更高(或相当)的精度。
2. 背景与动机
-
在移动视觉应用领域,长期存在一个**"效率与性能"**的权衡:
- CNNs (如 MobileNets) :计算高效,在移动设备上延迟极低。但其固有的局部性(local connections)使其难以捕捉长程依赖和全局上下文,限制了性能上限。
- Transformers (ViTs) :通过自注意力实现强大的全局上下文 建模能力,性能卓越。但其平方计算复杂度 ( O ( N 2 ) O(N^2) O(N2),随图像分辨率)使其在移动端运行极其缓慢,不切实际。
为了解决这个"效率瓶颈",现有的混合模型(Hybrid approaches) (如 EfficientFormer, MobileViT)通常只敢在网络的最后、分辨率最低 的阶段才使用自注意力,而在高分辨率的早期阶段仍然完全依赖 CNN。然而,即便如此,自注意力中的矩阵乘法( Q ⋅ K T ⋅ V Q \cdot K^T \cdot V Q⋅KT⋅V)本身在移动 GPU 上仍然是一个显著的延迟瓶颈。
因此,本文的核心动机 是:设计一种全新的注意力机制 ,其复杂度必须是线性的( O ( N ) O(N) O(N)) ,并且必须用移动端友好的操作 (如逐元素运算)来替代昂贵的矩阵乘法,从而使其可以被廉价地、一致地部署在网络的所有阶段。
-
动机图解分析(Figure 1 & 2):
-
图表 A (Figure 1):揭示"效率瓶颈"问题
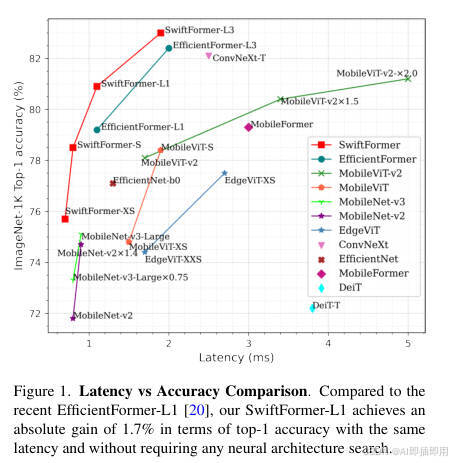
- "看图说话": 这张图(延迟 vs. 准确率)直观地展示了当前移动端模型的"效率边界"(Pareto frontier)。X 轴是延迟(越低越好),Y 轴是准确率(越高越好)。
- 分析:
- 现有模型的权衡: 我们可以看到一个清晰的权衡。
MobileNet-v2很快(<1ms),但准确率低(72%)。ConvNeXt-T准确率高(82%),但延迟是SwiftFormer-L3的 1.3 倍。MobileViT-v2系列(绿色)在准确率和延迟上均劣于SwiftFormer系列(红色)。 - 本文的解决方案:
SwiftFormer(红线)明显**"碾压"了所有竞争对手,创造了一个 新的、更优的效率边界**。例如,SwiftFormer-S不仅比MobileViT-v2快 2 倍以上(0.8ms vs 1.7ms),准确率还高 0.4%。
- 现有模型的权衡: 我们可以看到一个清晰的权衡。
- 结论: Figure 1 明确指出了问题 :现有模型在速度和精度上的权衡不佳。并用
SwiftFormer的红线直接给出了本文的最终成果:一个在速度和精度上均达到 SOTA 的新模型。
-
图表 B (Figure 2):揭示"矩阵乘法"这一"效率瓶颈"
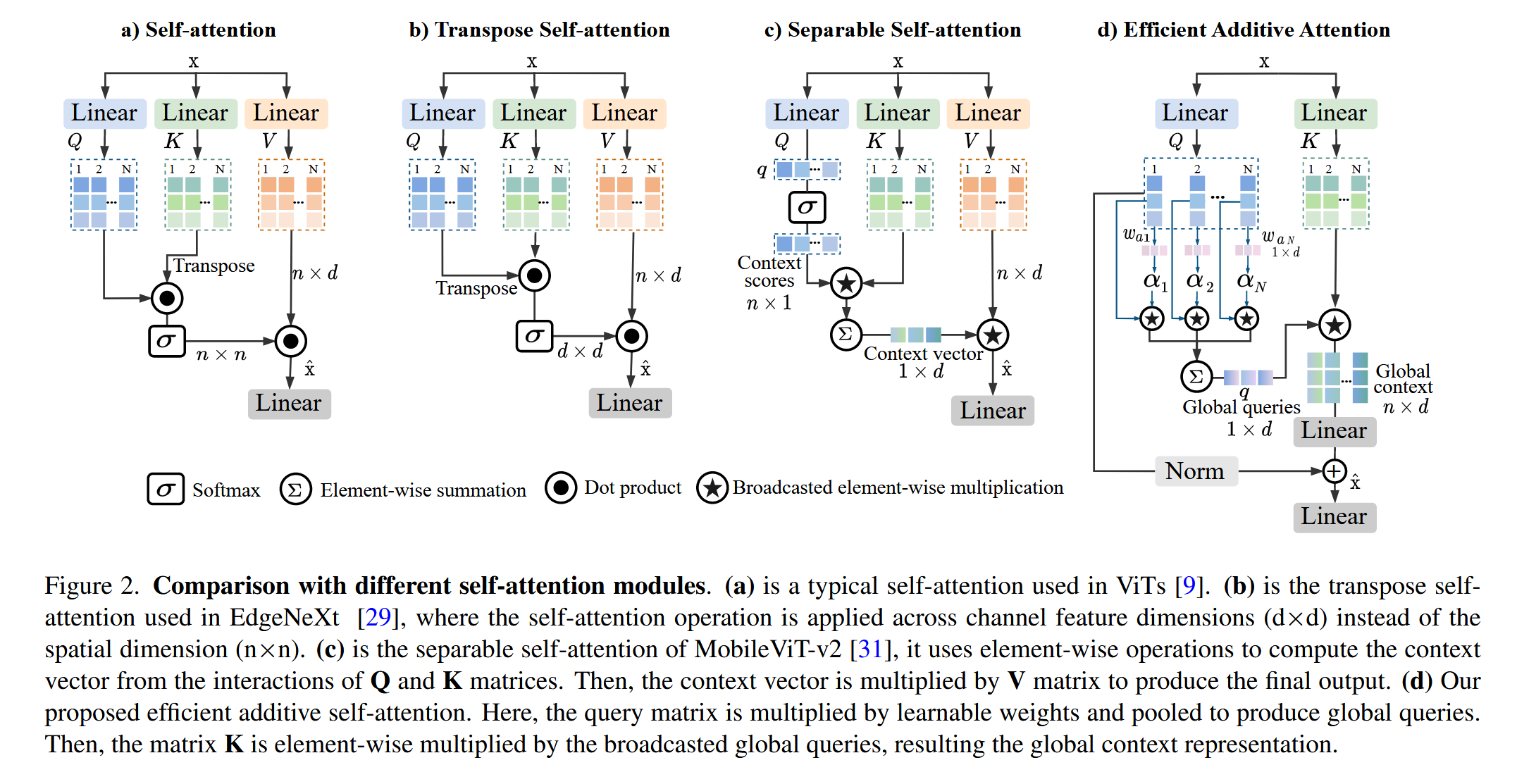
- "看图说话": 这张图对比了四种注意力机制的计算流,是本文最核心的动机图。
- (a) Self-attention (标准 ViT): 瓶颈在于 Q ⋅ K T Q \cdot K^T Q⋅KT 这一步,它创建了一个 n × n n \times n n×n 的大矩阵,复杂度为 O ( n 2 ) O(n^2) O(n2)。
- (b) Transpose Self-attention (EdgeNeXt): 它将注意力转移到通道维度( d × d d \times d d×d),虽然对 n n n 呈线性,但对 d d d 呈平方,且仍依赖矩阵乘法。
- © Separable Self-attention (MobileViT-v2): 这是一种先进的移动端注意力。它避免 了 n × n n \times n n×n 矩阵,但其计算流依然复杂 :它需要 Q → Context scores Q \rightarrow \text{Context scores} Q→Context scores, K K K 与 scores 逐元素相乘 ( ⋆ \star ⋆),然后求和 ( ∑ \sum ∑)得到
Context vector,最后再与 V V V 逐元素相乘 ( ⋆ \star ⋆)。它仍然保留了 Q , K , V Q, K, V Q,K,V 三者的完整交互。 - (d) Efficient Additive Attention (Ours, SwiftFormer): 这是本文的解决方案,其设计极其激进和高效 :
- 它彻底抛弃了 V V V (Value) 矩阵的交互。
- 它彻底抛弃了 Q ⋅ K T Q \cdot K^T Q⋅KT 矩阵乘法。
- 取而代之 的是:用 Q Q Q 和一个可学习权重 w a w_a wa 计算出一个 1 × d 1 \times d 1×d 的"全局查询" q q q。然后用这个 q q q 和 K K K 进行逐元素乘法 ( ⊙ \odot ⊙)。
- 它将 (a) 和 © 中的 K ⋅ V K \cdot V K⋅V 交互替换 为一个简单的**
Linear(全连接)层**。
- 结论: Figure 2 深刻地揭示了为什么 SwiftFormer 如此之快。它不是对 O ( N 2 ) O(N^2) O(N2) 的自注意力进行"修补",而是从根本上将其替换 为一个基于逐元素运算( ⊙ \odot ⊙)和 线性层(Linear)的加法注意力新范式,从而在源头上消除了昂贵的矩阵乘法瓶颈。
-
3. 主要贡献点
-
提出高效加法注意力 (Efficient Additive Attention):
- 这是本文的核心创新。它用逐元素乘法 (element-wise multiplication)替换了标准自注意力中昂贵的矩阵乘法(matrix multiplication)。
- 这种设计将注意力的计算复杂度从 O ( N 2 ) O(N^2) O(N2) 降低到了 O ( N ) O(N) O(N)( N N N 为 Token 数量)。
-
重构 QKV 交互:
- 论文大胆地论证并实现了**"键-值"(Key-Value)交互的非必要性**。
- 在 SwiftFormer 中,
Global Context仅由 Q Q Q 和 K K K 的交互(通过逐元素乘法)产生,而 V V V (Value) 矩阵被完全移除 ,其作用被一个**Linear(全连接)层**所取代。这极大地简化了计算流并降低了延迟。
-
一致的混合架构 (Consistent Hybrid Design):
- 由于"高效加法注意力"的线性复杂度 (即极低的计算成本),SwiftFormer 能够**在网络的所有四个阶段(Stage 1-4)**都部署 Transformer 模块(
SwiftFormer Encoder)。 - 这与 EfficientFormer 等竞品形成了鲜明对比,后者因成本高昂,只敢在最后(Stage 4)一个阶段使用注意力。这种"一致的"全局上下文建模能力是 SwiftFormer 性能更强的关键。
- 由于"高效加法注意力"的线性复杂度 (即极低的计算成本),SwiftFormer 能够**在网络的所有四个阶段(Stage 1-4)**都部署 Transformer 模块(
-
构建 SOTA 的 SwiftFormer 系列模型:
- 基于上述创新,本文构建了一系列名为 SwiftFormer 的模型(XS, S, L1, L3)。
- 实验证明(Figure 1),SwiftFormer 在 ImageNet-1K 上实现了 SOTA 级别的速度-精度权衡。例如,SwiftFormer-L1 与 EfficientFormer-L1 延迟相同(1.1ms),但精度高出 1.7%。SwiftFormer-S 比 MobileViT-v2 快 2 倍,且精度更高。
4. 方法细节
-
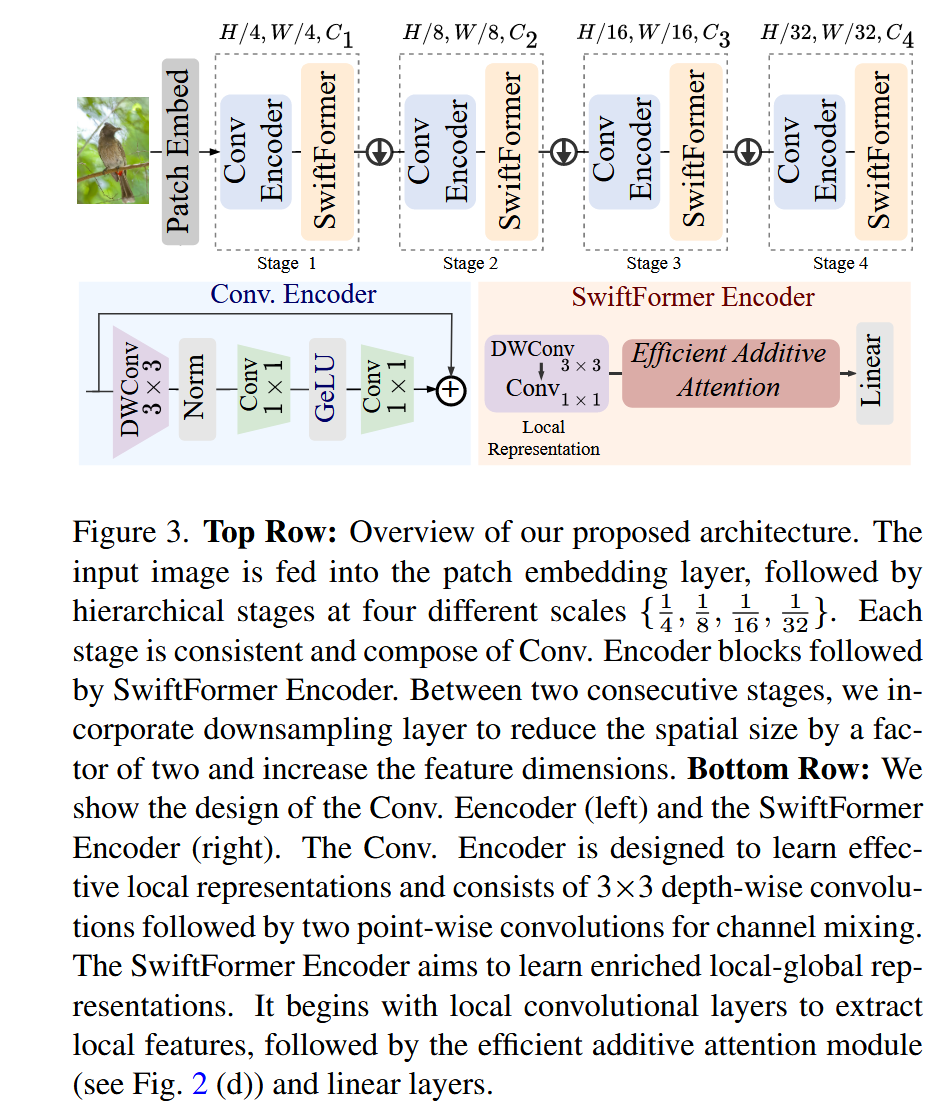
整体网络架构(Figure 3 上半部分):
- 模型名称: SwiftFormer
- 数据流: 这是一个四阶段金字塔(Pyramidal)架构,是 CNN 和 Transformer 的混合设计。
Patch Embed: 输入图像( H × W H \times W H×W)首先通过一个"补丁嵌入"层(由两次 3 × 3 3 \times 3 3×3 步进卷积实现),将分辨率降为 H / 4 × W / 4 H/4 \times W/4 H/4×W/4,通道数变为 C 1 C_1 C1。Stage 1→ \rightarrow →Stage 4: 网络由 4 个阶段堆叠而成,每个阶段之间有一个下采样层( 3 × 3 3 \times 3 3×3 步进卷积),逐步将分辨率从 H / 4 H/4 H/4 降低到 H / 32 H/32 H/32,同时增加通道数( C 1 → C 4 C_1 \rightarrow C_4 C1→C4)。- 阶段内部: 这是关键 。在每一个 Stage 内部,都由 N N N 个
Conv. Encoder模块和 M M M 个SwiftFormer Encoder模块串联组成。 - 输出: 经过 4 个 Stage 后,输出的特征图用于分类或下游任务。
-
核心创新模块详解(Figure 3 下半部分 & Figure 2d):
-
对于 模块 A:Conv. Encoder (Figure 3 左下角)
- 理念: 这是模型中的纯 CNN 模块 ,负责高效的局部特征提取 和空间归纳偏置。
- 内部结构: 这是一个标准的倒置残差块(Inverted Residual Block),与 MobileNetV2 的设计一致。
- 数据流:
DWConv 3x3(深度可分离卷积) → \rightarrow →Norm(归一化) → \rightarrow →Conv 1x1(逐点卷积,扩展通道) → \rightarrow →GeLU(激活) → \rightarrow →Conv 1x1(逐点卷积,压缩通道) → \rightarrow →+(残差连接)。 - 设计目的: 在 Transformer 模块之前,使用高效率的 CNN 模块来提取强大的局部表征。
-
对于 模块 B:SwiftFormer Encoder (Figure 3 右下角)
- 理念: 这是模型中的核心 Transformer 模块 ,负责高效的全局上下文建模。
- 内部结构: 它是一个混合块,由一个局部模块和一个全局模块串联而成。
- 数据流:
- Local Representation (局部): 输入特征首先经过一个
DWConv 3x3和一个Conv 1x1,这部分与Conv. Encoder的前半部分类似,用于提取局部特征。 - Global Attention (全局): 局部特征随后被送入**
Efficient Additive Attention模块**(即 Figure 2d 中的核心创新)。 - FFN (混合): 注意力模块的输出最后经过一个
Linear层(即标准 Transformer 中的 FFN/MLP),用于通道混合和非线性变换。 - (残差连接): 最终输出会与该模块的输入相加(Figure 3 中未画出,但 Eq. 8 有提及)。
- Local Representation (局部): 输入特征首先经过一个
- 设计目的: 将高效的局部特征提取(Conv)和高效的全局上下文建模(Efficient Additive Attention)紧密耦合在一个单一的 Transformer 块中。
-
-
理念与机制总结 (Figure 2d & Eq. 4-6):
Efficient Additive Attention(Figure 2d) 是SwiftFormer Encoder的核心。- 机制(数据流):
- 全局查询 q q q (Eq. 4, 5): 输入 Q Q Q ( n × d n \times d n×d) 首先与一个可学习的权重向量 w a w_a wa ( d × 1 d \times 1 d×1) 相乘,得到一个"重要性"分数 α \alpha α ( n × 1 n \times 1 n×1)。然后,通过这个 α \alpha α 对 Q Q Q 中的所有 n n n 个 Token 进行加权求和(池化) ,最终得到一个 1 × d 1 \times d 1×d 的"全局查询"向量 q q q。
- 全局上下文 G l o b a l c o n t e x t Global context Globalcontext (Eq. 6): 将这个 1 × d 1 \times d 1×d 的全局查询 q q q 广播(broadcast)回 n × d n \times d n×d 的维度,并与 K K K ( n × d n \times d n×d) 进行 逐元素乘法( ⊙ \odot ⊙) 。这一步替代 了 Q ⋅ K T Q \cdot K^T Q⋅KT 矩阵乘法。
- 线性变换 T T T (Eq. 6): 得到的"全局上下文"被送入一个
Linear(全连接)层 T T T。这一步替代 了与 V V V (Value) 矩阵的交互。 - 输出 (Eq. 6): 最终输出 x ^ \hat{x} x^ 是线性变换 T T T 的结果与一个残差连接( Q ^ \hat{Q} Q^,即归一化的 Q Q Q)相加。
- 总结: 整个过程的计算瓶颈从 O ( n 2 ⋅ d ) O(n^2 \cdot d) O(n2⋅d)(矩阵乘法)降低到了 O ( n ⋅ d 2 ) O(n \cdot d^2) O(n⋅d2)(逐元素乘法和线性层),由于 n n n(Token 数)通常远大于 d d d(通道数),这是一个巨大的效率提升。
-
图解总结:
- Figure 1 (问题): 现有模型(绿、蓝线)在移动端的"速度-精度"权衡曲线不佳。
- Figure 2 (瓶颈): 瓶颈在于 (a) Q ⋅ K T Q \cdot K^T Q⋅KT 矩阵乘法和 © 复杂的 Q − K − V Q-K-V Q−K−V 交互。
- Figure 2d (解决方案):
Efficient Additive Attention(1) 移除 V ,** (2) 用逐元素乘法 ⊙ \odot ⊙ 替换矩阵乘法 ⋅ \cdot ⋅**。 - Figure 3 (架构): 将这个高效的注意力(Fig 2d)封装进
SwiftFormer Encoder模块,并与Conv. Encoder模块串联 ,在所有 4 个阶段 中一致地部署,构建出最终的SwiftFormer架构。 - 这一系列设计协同工作,完美地解决了"效率瓶颈",从而在 Figure 1 中画出了那条红色的、处于统治地位的 SOTA 曲线。
5. 即插即用模块的作用
-
本文的核心创新是
Efficient Additive Attention机制,以及封装它的SwiftFormer Encoder模块。 -
Efficient Additive Attention(机制):- 作用: 这是一个超高效的注意力计算内核 ,可作为标准自注意力(MHSA)的低延迟替代品。
- 适用场景: 任何对延迟(Latency)极度敏感的实时应用,尤其是资源受限的移动设备(如手机、无人机、边缘 AI 设备)。
- 具体应用:
- 替换标准 ViT 中的 MHSA: 在任何 ViT 架构中,将昂贵的 MHSA 模块替换为此机制,可以极大降低延迟。
- 替换 MobileViT 中的 Separable SA: 如本文所示,它比 MobileViT-v2 的可分离注意力(Figure 2c)更简单、更快。
-
SwiftFormer Encoder(模块):- 作用: 这是一个完整的 Transformer 块,它已经包含了(CNN 驱动的)局部特征提取和(加法注意力驱动的)全局特征提取。
- 适用场景: 作为构建混合(Hybrid)CNN-Transformer 架构的基础模块。
- 具体应用:
- 构建 SOTA 移动端骨干网: 如本文(Figure 3)所示,通过堆叠
Conv. Encoder和SwiftFormer Encoder模块,可以构建出在速度和精度上均占优的新一代移动端骨干网。 - 升级纯 CNN 模型: 可以在一个纯 CNN 架构(如 MobileNet)的深层阶段,插入几个
SwiftFormer Encoder模块,以低成本为其增加全局上下文建模能力,从而提升其在分类、检测和分割任务上的性能。
- 构建 SOTA 移动端骨干网: 如本文(Figure 3)所示,通过堆叠
6. 实验结果总结与分析
SwiftFormer 在多个视觉任务中均展现了其作为高效移动端主干网络的 SOTA 性能,兼顾了高精度与低延迟。
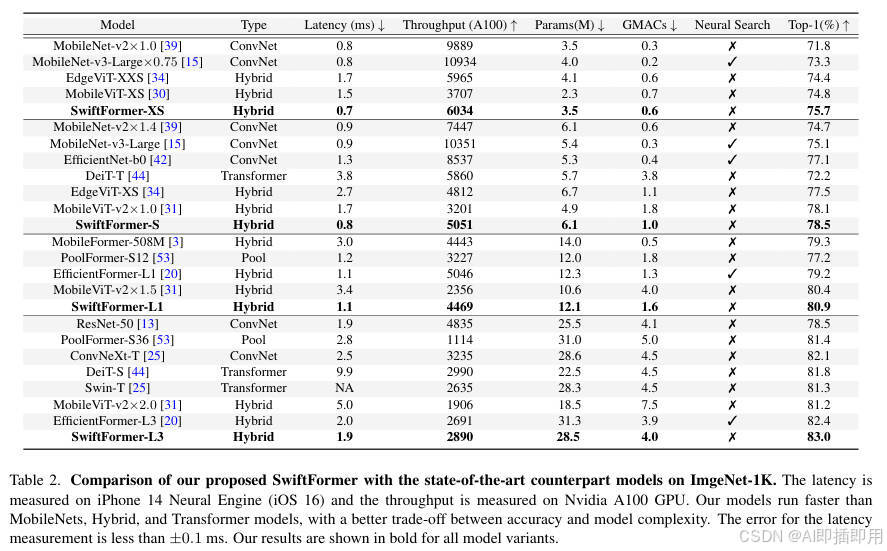
ImageNet-1K 图像分类: SwiftFormer 在准确率和推理速度上全面超越了 MobileNet、MobileViT 等经典轻量级模型。例如,SwiftFormer-S 在 iPhone 14 上的推理延迟仅为 0.8ms,Top-1 准确率却高达 78.5%,比 MobileViT-v2 快 2 倍且精度更高。SwiftFormer-L3 更是达到了 83.0% 的 Top-1 准确率,性能优于 ResNet-50 和 ConvNeXt-T,同时保持了极具竞争力的推理速度。
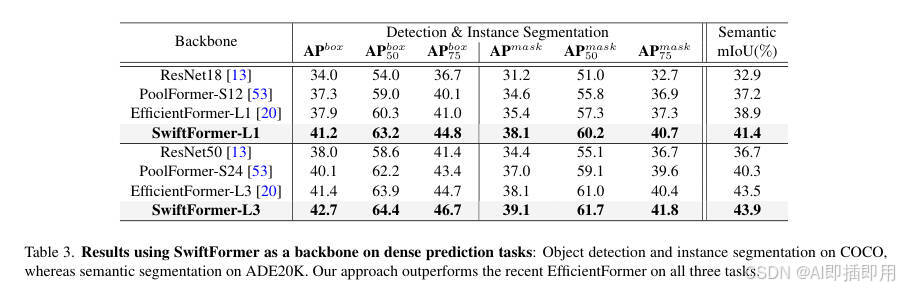
- COCO 目标检测与实例分割: 作为 Mask-RCNN 的主干网络,SwiftFormer-L1 在目标检测(AP box 41.2)和实例分割(AP mask 38.1)上均显著优于 ResNet18 和 PoolFormer-S12,同时也超越了之前的 SOTA 模型 EfficientFormer-L1。L3 版本同样保持了对 EfficientFormer-L3 的领先优势。

到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。