PyTorch实战(15)------基于Transformer的文本生成技术
-
- [0. 前言](#0. 前言)
- [1. 基于 Transformer 的文本生成器](#1. 基于 Transformer 的文本生成器)
-
- [1.1 训练基于 Transformer 的语言模型](#1.1 训练基于 Transformer 的语言模型)
- [1.2 语言模型的保存与加载](#1.2 语言模型的保存与加载)
- [2. 使用语言模型生成文本](#2. 使用语言模型生成文本)
- [3. 使用 GPT 模型进行文本生成](#3. 使用 GPT 模型进行文本生成)
-
- [3.1 使用预训练模型进行文本生成](#3.1 使用预训练模型进行文本生成)
- [3.2 文本生成策略](#3.2 文本生成策略)
- [4. 使用 GPT-3 进行文本生成](#4. 使用 GPT-3 进行文本生成)
- 小结
- 系列链接
0. 前言
我们已经学习了多种分类模型(包括图像分类、情感分类和节点分类等),分类任务监督学习范畴。然而,深度学习模型在无监督学习任务中同样展现出卓越性能,深度生成模型就是典型代表。这类模型通过大量无标注数据进行训练,最终能够学习输入数据的底层结构和模式,从而生成具有相似语义的新数据。
在本节中,我们将实现文本生成器。在文本生成方面,我们将基于训练好的Transformer语言模型进行扩展,使用 PyTorch 将其改造为文本生成器。此外,还将演示如何通过少量代码调用 GPT-2/GPT-3 等预训练 Transformer 模型快速搭建文本生成系统。
1. 基于 Transformer 的文本生成器
我们已经学习了如何使用 PyTorch 构建基于 Transformer 的语言模型。由于语言模型本质上是通过计算词序列概率分布来预测后续词汇,这为构建文本生成器奠定了良好基础。本节将学习如何将该模型扩展为深度生成模型------只需给定初始文本提示(以词序列的形式),即可生成语义连贯的任意长度文本。
1.1 训练基于 Transformer 的语言模型
在Transformer一节中,我们对语言模型进行了 5 个 epoch 的训练。本节将采用完全相同的训练步骤,但将训练时长延长至 50 个 epoch,旨在获得性能更优、能生成逼真语句的语言模型:
python
min_validation_loss = float("inf")
eps = 50
best_model_so_far = None
for ep in range(1, eps + 1):
ep_time_start = time.time()
train_model()
validation_loss = eval_model(transformer_model, validation_data)
print()
print(f"epoch {ep:}, validation loss {validation_loss:.2f}, validation perplexity {math.exp(validation_loss):.2f}")
print()
if validation_loss < min_validation_loss:
min_validation_loss = validation_loss
best_model_so_far = transformer_model
sched_module.step()完成 50 个 epoch 训练后,输出结果如下:
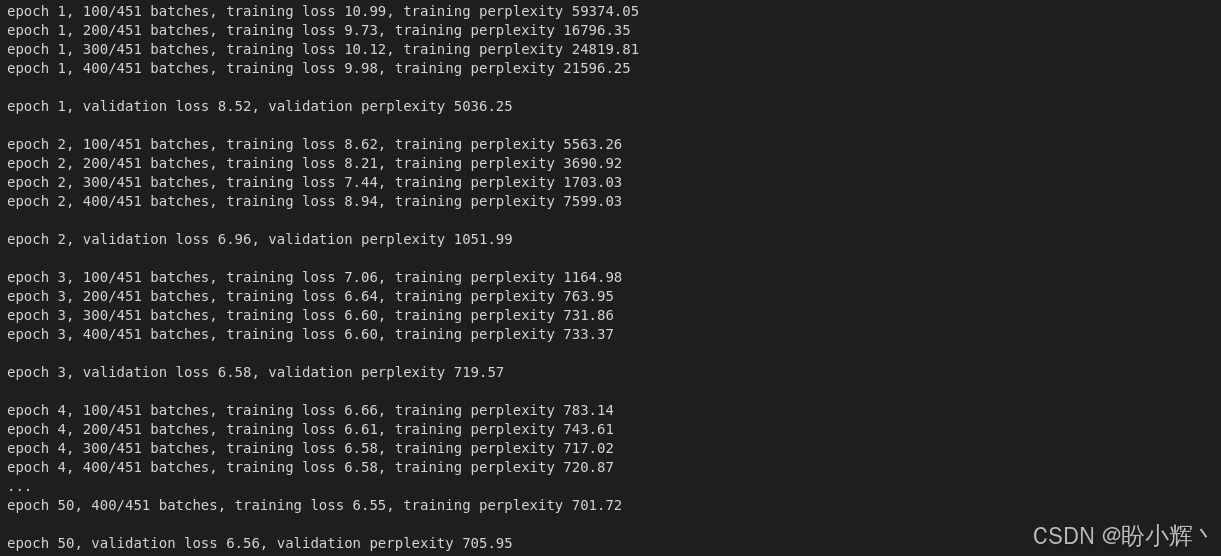
成功完成 Transformer 模型 50 个 epoch 的训练后,接下来进入核心实践环节------将该训练好的语言模型扩展为文本生成模型。
1.2 语言模型的保存与加载
完成训练后,我们将保存性能最优的模型检查点,以便后续加载预训练模型。
(1) 训练完成后,将模型保存到本地,以避免每次都需要从头开始训练:
python
mdl_pth = './transformer.pth'
torch.save(best_model_so_far.state_dict(), mdl_pth)(2) 加载保存的模型,以便将其扩展为一个文本生成模型:
python
transformer_cached = Transformer(num_tokens, embedding_size, num_heads, num_hidden_params, num_layers,
dropout).to(device)
transformer_cached.load_state_dict(torch.load(mdl_pth, weights_only=False))本节中,我们首先重新实例化了一个 Transformer 模型对象,随后将预训练好的模型权重加载至该新对象中。接下来,我们将利用该模型实现文本生成功能。
2. 使用语言模型生成文本
模型保存并加载后,我们可以扩展训练好的语言模型来生成文本。
(1) 首先需要定义待生成的文本长度,并为模型提供初始文本作为生成提示:
python
ln = 5
sntc = 'They are _'
sntc_split = sntc.split()
mask_source = gen_sqr_nxt_mask(max_seq_len).to(device)(2) 通过循环逐词生成文本。在每次迭代中,将当前预测出的单词追加到输入序列末尾,这个扩展后的序列将作为下一次迭代的输入,如此循环往复,直到生成指定长度的文本:
python
with torch.no_grad():
for i in range(ln):
sntc = ' '.join(sntc_split)
txt_ds = Tensor(vocabulary(sntc_split)).unsqueeze(0).to(torch.long)
num_b = txt_ds.size(0)
txt_ds = txt_ds.narrow(0, 0, num_b)
txt_ds = txt_ds.view(1, -1).t().contiguous().to(device)
ev_X, _ = return_batch(txt_ds, i+1)
sequence_length = ev_X.size(0)
if sequence_length != max_seq_len:
mask_source = mask_source[:sequence_length, :sequence_length]
op = transformer_cached(ev_X, mask_source)
op_flat = op.view(-1, num_tokens)
res = vocabulary.get_itos()[op_flat.argmax(1)[0]]
sntc_split.insert(-1, res)
print(sntc[:-2])输出结果如下所示:
shell
They are often used for the 借助 PyTorch 可以训练语言模型(本节为基于 Transformer 的模型),仅需添加少量代码即可实现文本生成功能。虽然生成的文本语义通顺,但其质量受限于两个关键因素:基础语言模型的训练数据量以及模型本身的性能表现。本节我们完整实现了从零构建文本生成器的全过程。
下一节将采用预训练语言模型作为文本生成器,使用 Transformer 模型的变体------生成式预训练 Transformer (GPT-2 和 GPT-3)。展示如何用不到 10 行 PyTorch 代码快速搭建开箱即用的高级文本生成系统,同时探讨语言模型文本生成的相关策略。
3. 使用 GPT 模型进行文本生成
通过结合 PyTorch 与 Hugging Face 的 transformers 或 openai 等库,我们可以加载大多数最新的先进 Transformer 模型,用于执行各种任务,如语言建模、文本分类、机器翻译等。
本节将首先使用 transformers 库加载 GPT-2 语言模型( 15 亿参数),并将其扩展为文本生成器。随后我们将探索预训练语言模型的多种文本生成策略,并通过 PyTorch 实现这些策略。最后,我们将通过 openai 加载 1750 亿参数的 GPT-3 模型,展示其生成自然流畅文本的能力。
3.1 使用预训练模型进行文本生成
使用 transformers 库加载 GPT-2 语言模型,并将其扩展为能生成语义连贯文本的生成模型。
(1) 首先,导入所需库,导入 GPT-2 语言模型及其对应的分词器来构建词汇表:
python
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch(2) 接下来,实例化 GPT2Tokenizer 和语言模型。然后,为模型提供一组初始文本提示:
python
tkz = GPT2Tokenizer.from_pretrained("gpt2")
mdl = GPT2LMHeadModel.from_pretrained('gpt2')
ln = 10
cue = "They"
gen = tkz(cue, return_tensors="pt")
to_ret = gen["input_ids"][0](3) 最后,通过语言模型逐步预测给定输入词序列的下一个词。在每次迭代中,预测的词会被附加到输入词序列中,作为下一次迭代的输入:
python
prv=None
for i in range(ln):
outputs = mdl(**gen)
next_token_logits = torch.argmax(outputs.logits[-1, :])
to_ret = torch.cat([to_ret, next_token_logits.unsqueeze(0)])
gen = {"input_ids": to_ret}
seq = tkz.decode(to_ret)
print(seq)输出结果如下所示:
shell
They are not the only ones who are being targeted.这种文本生成方式称为贪婪搜索 (greedy search)。下一节我们将详细探讨贪婪搜索及其他文本生成策略。
3.2 文本生成策略
在使用训练好的文本生成模型时,我们通常以逐词预测的方式进行文本生成,最终将这些预测结果组合成完整的文本序列。在循环迭代预测每个单词的过程中,需要指定根据已有文本预测下一个单词的方法,这些方法即称为文本生成策略,接下来我们将讨论一些常见的策略。
3.2.1 贪婪搜索 (Greedy Search)
贪婪搜索 (Greedy Search) 的名称源于模型在每次迭代时仅选择当前概率最高的单词,而不会考虑这一选择对后续多步预测的影响。这种"短视"行为可能导致模型错过全局更优的单词序列------某个当前低概率的单词若被选中,后续可能会引出更高概率的单词组合。如下图所示,文本生成模型在每个时间步都会输出候选单词及其对应概率:
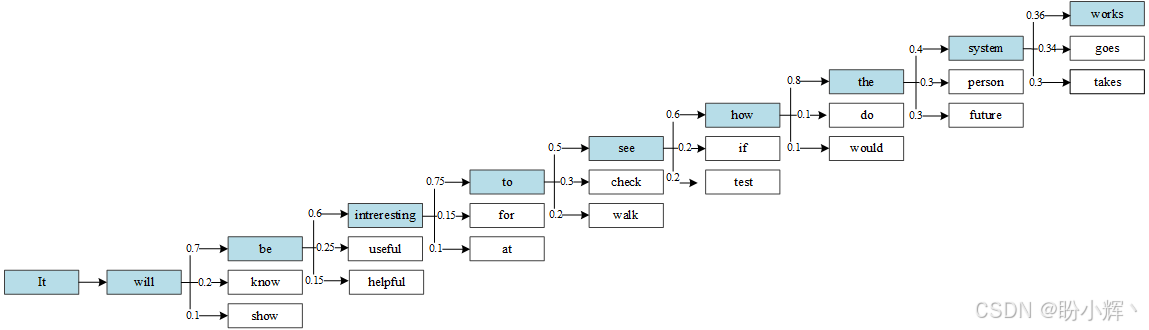
如图所示,在贪婪搜索策略下,模型每一步都选择概率最高的单词。值得注意的是在倒数第二步,模型预测出的单词 system、person 和 future 具有相近的概率值,而贪婪搜索仅因 system 的微小概率优势就将其选中。实际上,选择 person 或 future 可能会生成语义更优的文本------这正是贪婪搜索的核心缺陷。此外,由于缺乏随机性,贪婪搜索还可能导致生成结果的重复性。
在上一小节中,我们手动实现了文本生成循环。而借助 transformers 库,只需 3 行代码即可完成:
python
ip_ids = tkz.encode(cue, return_tensors='pt')
op_greedy = mdl.generate(ip_ids, max_length=ln, pad_token_id=tkz.eos_token_id)
seq = tkz.decode(op_greedy[0], skip_special_tokens=True)
print(seq)输出结果如下所示:
shell
They are not the only ones who are being targeted需要注意的是,生成的句子比手动文本生成循环生成的句子少了一个标点符号(句号)。这这种差异是因为在后者的代码中,max_length 参数包含了提示词。因此,如果我们有一个提示词,那么只会预测九个新单词。
3.2.2 束搜索 (Beam Search)
束搜索是对贪婪搜索方法的改进,它通过维护一个基于整体序列预测概率(而非仅下一个单词概率)的潜在候选序列列表来实现。所追踪的候选序列数量即为单词预测树中的束宽度 (beam size)。
如下图所示,当束宽度设为 3 时,系统会生成三个候选序列(按整体序列概率排序),每个序列包含 5 个单词:
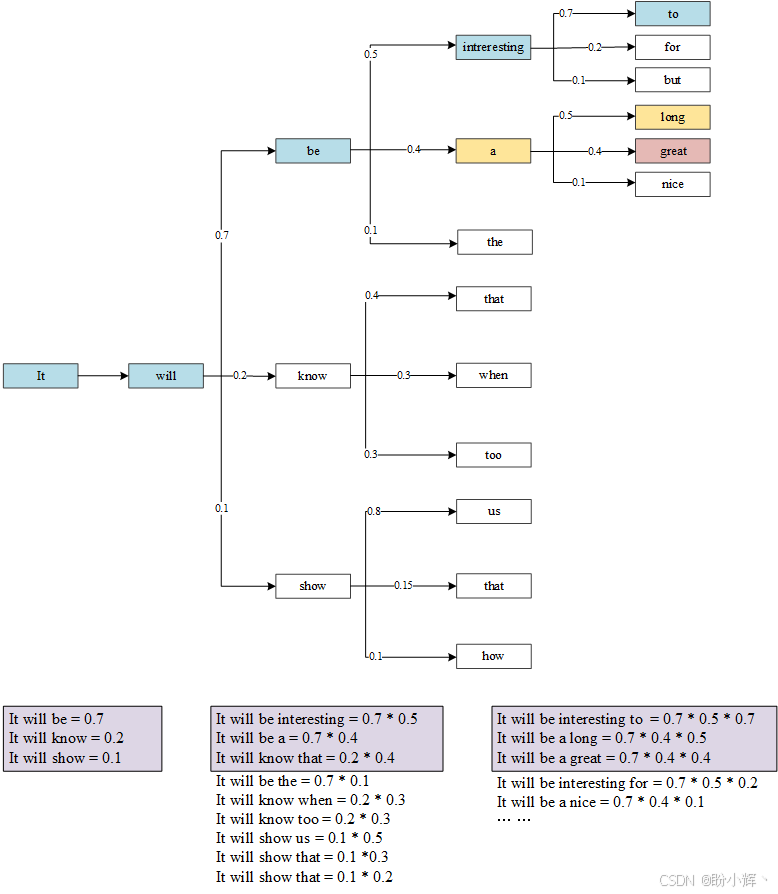
在这个束搜索的示例中,每次迭代都会保留 3 个最可能的候选序列。随着序列生成的推进,潜在的候选序列数量会呈指数级增长。但我们始终只关注排名前 3 的序列。这种方式避免了贪婪搜索可能错失更优序列的问题。
在 PyTorch 中,我们可以通过以下代码使用束搜索。以下代码演示了基于束搜索的文本生成过程:设置束宽度为 3,最终输出 3 个最可能的句子,每个句子包含 5 个单词:
python
op_beam = mdl.generate(
ip_ids,
max_length=5,
num_beams=3,
num_return_sequences=3,
pad_token_id=tkz.eos_token_id
)
for op_beam_cur in op_beam:
print(tkz.decode(op_beam_cur, skip_special_tokens=True))输出结果如下所示:
shell
They have a lot of
They have a lot to
They are not the only束搜索仍存在重复性和单调性问题。不同的运行可能会产生相同的结果,因为它确定性地选择整体概率最高的序列。接下来,我们将探讨如何使生成文本更具不可预测性和创意性。
3.2.3 Top-k 和 Top-p 采样
我们可以根据相对概率从候选词中随机采样,而不是总是选择具有最高概率的下一个单词。例如,单词 "be"、"know" 和 "show" 的概率分别为 0.7、0.2 和 0.1。我们可以随机从这 3 个单词中采样,而不是总选择 "be"。如果我们重复这一过程 10 次来生成 10 个独立的文本,"be" 会大约被选择 7 次,而 "know" 和 "show" 分别会被选择 2 次和 1 次。这种方法能产生束搜索或贪婪搜索无法生成的丰富词序组合。
使用采样技术生成文本的两种最流行方法是 Top-k 采样和 Top-p 采样。在 Top-k 采样中,预先定义一个参数 k,它表示在采样下一个单词时应该考虑的候选单词的数量。其他单词将被丢弃,概率会在 Top-k 个单词之间进行归一化。在以上示例中,如果 k 为 2,那么单词 "show" 将被丢弃,"be" 和 "know" 的概率从 (0.7, 0.2) 归一化为 (0.78, 0.22)。
使用 PyTorch 实现 Top-k 文本生成方法:
python
for i in range(3):
op = mdl.generate(
ip_ids,
do_sample=True,
max_length=5,
top_k=2,
pad_token_id=tkz.eos_token_id
)
seq = tkz.decode(op[0], skip_special_tokens=True)
print(seq)输出结果如下所示:
shell
They are the only ones
They have been in the
They have a lot of为了从所有可能的词汇中进行采样,而不仅仅是前 k 个词汇,我们应在代码中将 top_k 参数设置为 0。如前面代码输出所示,与每次运行都会产生完全相同结果的贪婪搜索(如下列代码所示)不同,这种方法每次运行都会生成不同的结果:
python
for i in range(3):
op_greedy = mdl.generate(ip_ids, max_length=5, pad_token_id=tkz.eos_token_id)
seq = tkz.decode(op_greedy[0], skip_special_tokens=True)
print(seq)输出结果如下所示:
shell
They are not the only
They are not the only
They are not the only在 Top-p 采样策略下,我们不再限定只考虑前 k 个词,而是设定一个累积概率阈值 (p),保留概率总和达到 p 的词。继续使用以上示例,如果 p 在 0.7 到 0.9 之间,丢弃 "know" 和 "show";如果 p 在 0.9 到 1.0 之间,会丢弃 "show";如果 p 为 1.0,会保留全部单词,即 "be"、"know" 和 "show"。
top-k 策略在概率分布较平缓时可能不够合理,因为它会直接截断那些概率与保留词相近的词。在这种情况下,Top-p 策略会保留更多候选词供采样,而在概率分布较陡峭时,top-p 策略则会自动减少候选词数量。
使用 PyTorch 实现 Top-p 采样方法:
python
for i in range(3):
op = mdl.generate(
ip_ids,
do_sample=True,
max_length=5,
top_p=0.75,
top_k=0,
pad_token_id=tkz.eos_token_id
)
seq = tkz.decode(op[0], skip_special_tokens=True)
print(seq)输出结果如下所示:
shell
They in the jail know
They live on a budget
They
Says我们可以同时设置 top-k 和 top-p 策略。在本节中,我们将 top_k 设为 0 以禁用 top-k 策略,并将 top_p 设置为 0.75。与贪婪搜索或束搜索不同,这种方法每次运行都会生成不同的句子,从而产生更具创意性的文本。
我们可以尝试使用 transformers 库中提供的各种文本生成策略,接下来,我们介绍 GPT-3,并通过 openai 库使用该模型来生成文本。
4. 使用 GPT-3 进行文本生成
接下来,加载预训练的 GPT-3 模型作为文本生成器。访问 GPT-3 模型,需要一个 OpenAI API 密钥,需要先创建一个 OpenAI 账户。拥有 API 密钥后,就可以使用 GPT-3 进行文本生成。
(1) 获得 API 密钥后,导入必要的库并设置环境变量:
python
import os
from openai import OpenAI
client = OpenAI(api_key = "<your-open-ai-api-key-here>") (2) 然后,定义提示词:
python
prompt = "They"(3) 最后,使用 OpenAI 的 Completion.create API 提示 GPT-3 模型生成文本:
python
response = client.chat.completions.create(
model="gpt-3.5-turbo-instruct",
response_format={ "type": "json_object" },
messages=[
{"role": "user", "content": prompt}
],
temperature=0.5,
max_tokens=5,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0
)参数 temperature 和 top_p 用于调节序列中下一个词的采样策略------这两个参数的值越高,采样随机性就越大。但需要注意,建议每次只调整其中一个参数,而非同时修改两个。本节使用的具体模型是 gpt-3.5-turbo-instruct。
(4) 打印响应结果:
python
print(response.choices[0].message.content)输出结果如下所示:
shell
are an important part of由于我们将 top_p 参数设为 1,可能会看到不同但同样有意义的结果。不过,生成的单词数量会限制在 5 个(由 max_tokens 参数指定)。
(5) 实际上,GPT-3 的能力远不止于此:
python
prompt = "Write a poem starting with they"
response = client.chat.completions.create(
model="gpt-3.5-turbo-instruct",
response_format={ "type": "json_object" },
messages=[
{"role": "user", "content": prompt}
],
temperature=0.5,
max_tokens=100,
top_p=1.0,
)
print(response.choices[0].message.content)输出结果如下所示:

小结
本节系统介绍了基于 Transformer 架构的文本生成技术。首先通过 PyTorch 构建并训练了 Transformer 语言模型,展示了从模型训练、保存到文本生成的全流程。随后引入预训练模型 GPT-2,详细解析了贪婪搜索、束搜索、Top-k 和 Top-p 等文本生成策略的特点与实现方法,其中 Top-p 采样在保持语义连贯性的同时展现出更好的创造性。最后通过 OpenAI API 演示了 GPT-3 的强大生成能力,实验表明,随着模型规模的扩大和生成策略的优化,文本生成质量显著提升。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)