- DataFrame 是 pandas 中用于存储和操作二维表格数据的核心数据结构;
- mean() 用于计算数据的平均值;
- groupby() 实现按列分组后进行聚合分析;
- fillna() 用于填充缺失值(NaN),保证数据完整性 。
python
import pandas as pd
import numpy as np
data = {
'姓名':['张三','李四','王五'],
'年龄':[25,30,35],
'城市':['北京','上海','广州'],
'工资':[5000,8000,6000]}
df = pd.DataFrame(data)
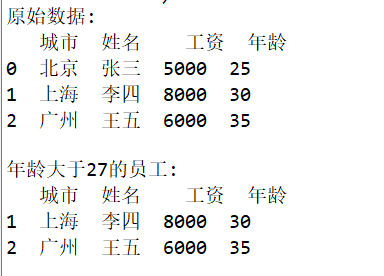
print("原始数据:")
print(df)
#数据筛选
print("\n年龄大于27的员工:")
print(df[df['年龄']>27])
#分组统计
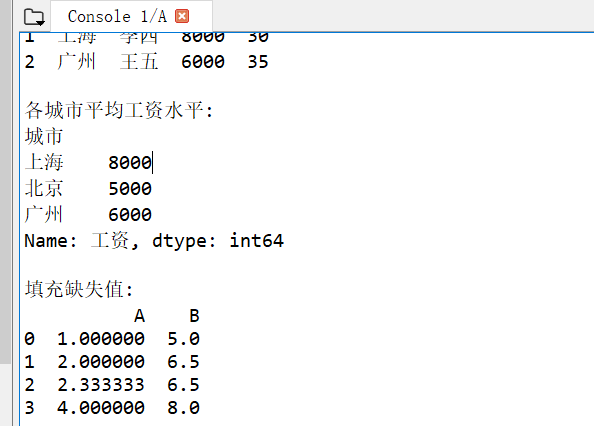
print("\n各城市平均工资水平:")
print(df.groupby('城市')['工资'].mean())
#处理缺失值
df_with_na = pd.DataFrame({'A':[1,2,np.nan,4],'B':[5,np.nan,np.nan,8]})
print("\n填充缺失值:")
print(df_with_na.fillna(df_with_na.mean()))运行效果图: