博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
技术栈:
python3语言、Django框架、numpy、matplotlib库、HTML
requests网络爬虫、采集京东商品数据、后台数据管理、MySQL/sqlite数据库
python语言、Django框架、numpy、matplotlib库、HTML、requests网络爬虫、采集京东商品数据、后台数据管理、MySQL/sqlite数据库
2、项目界面
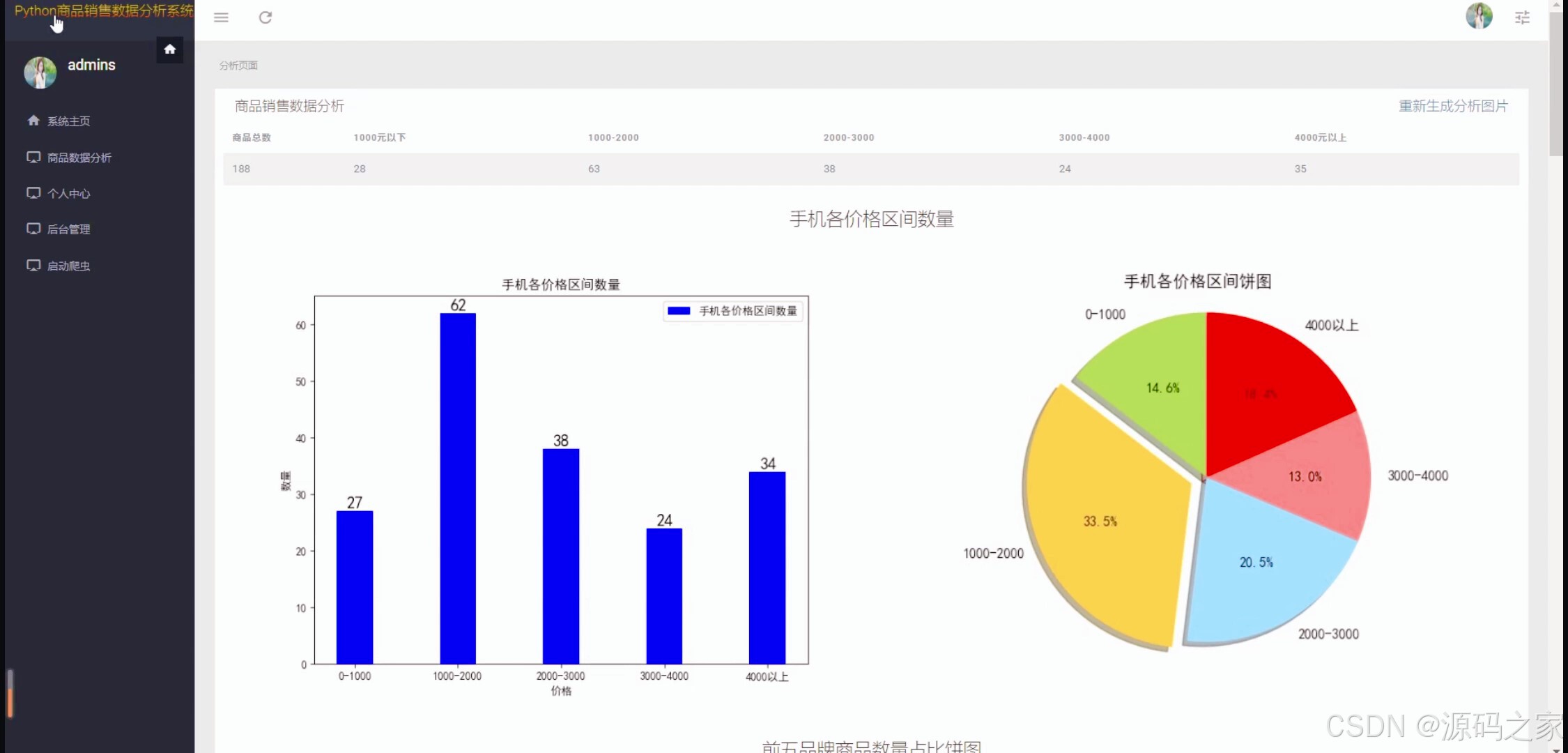
(1)商品销售数据概况(个价格区间柱状图、占比饼图)
(2)商品销售数据(数据中心)

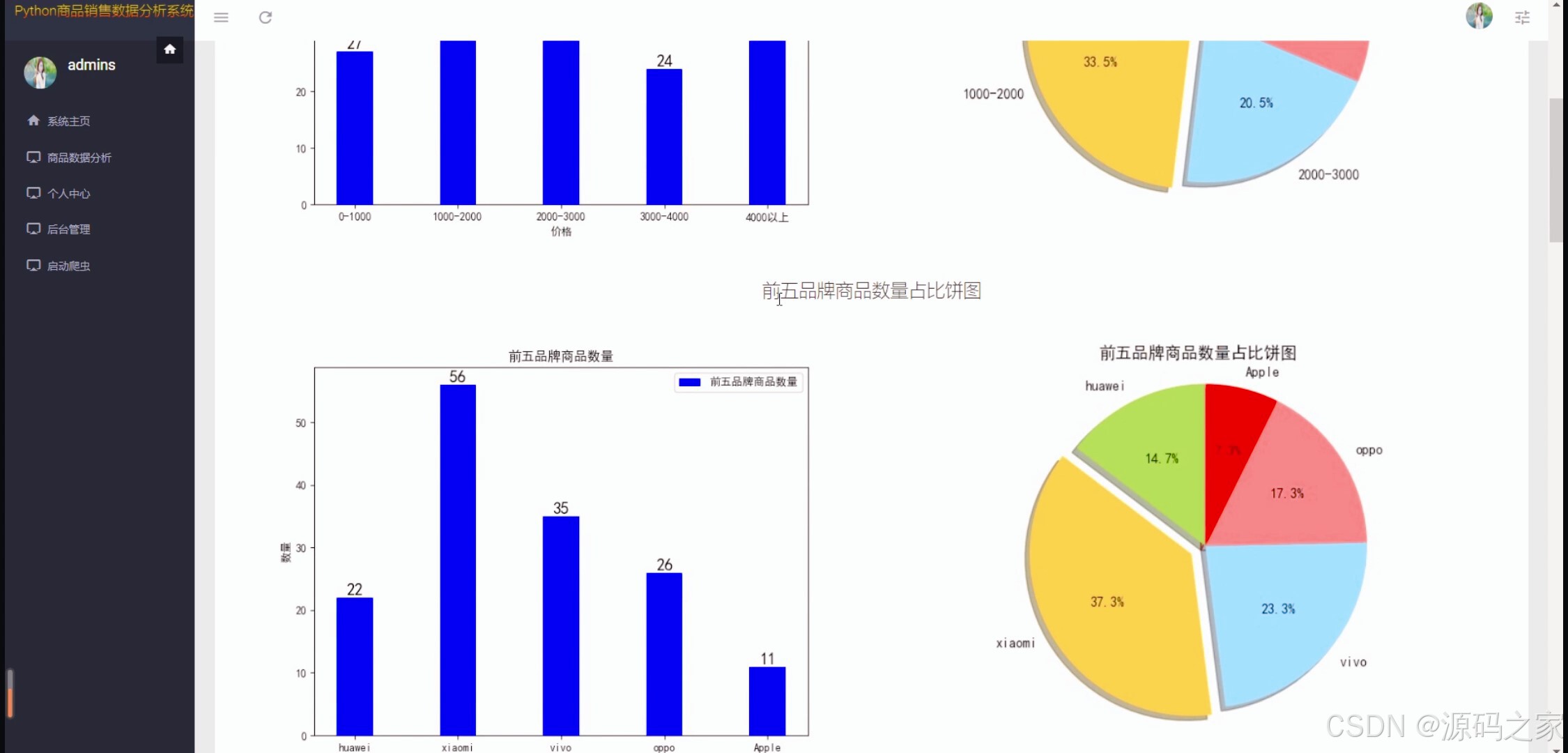
(3)商品数据可视化
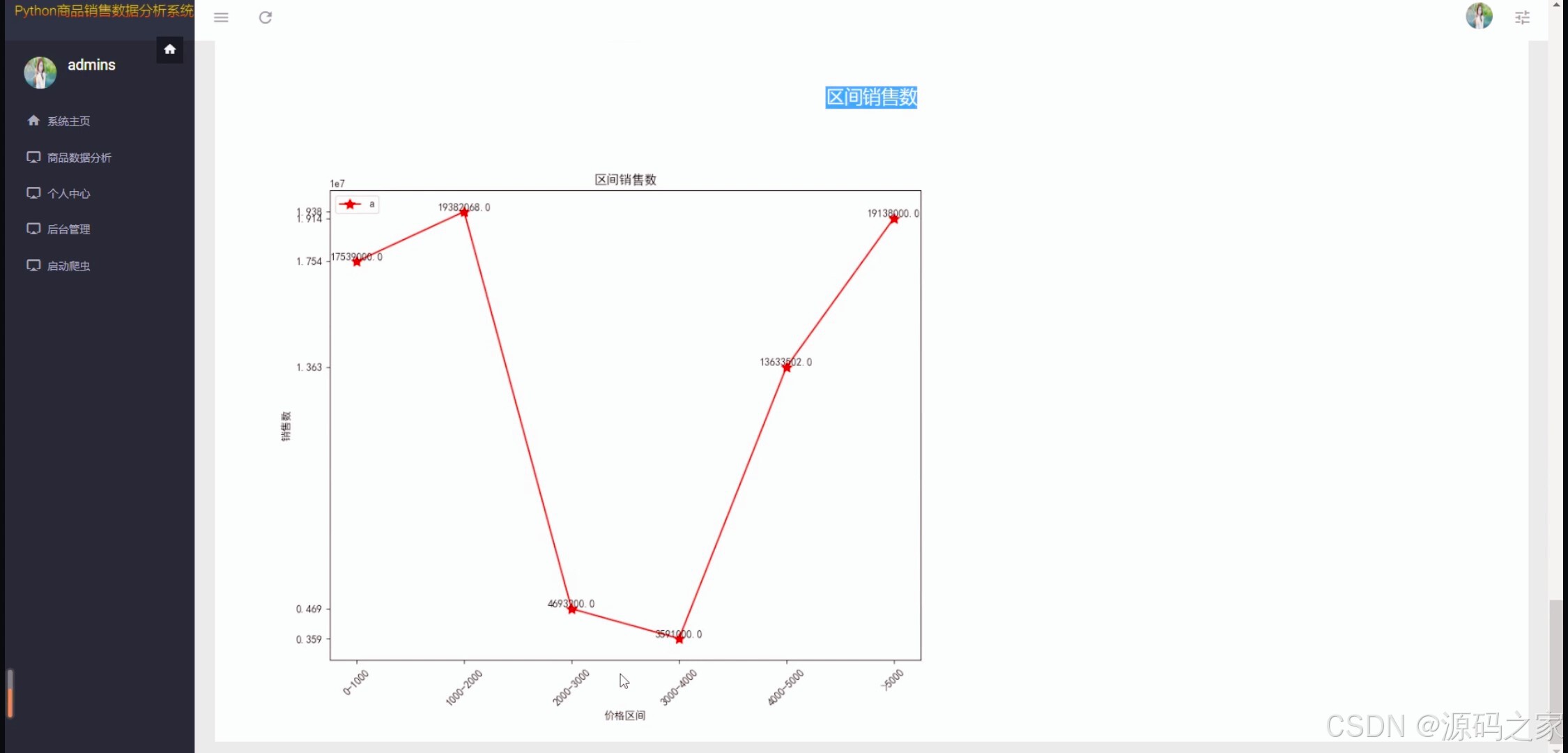
(4)商品数据可视化2(区间销售数据折线图)
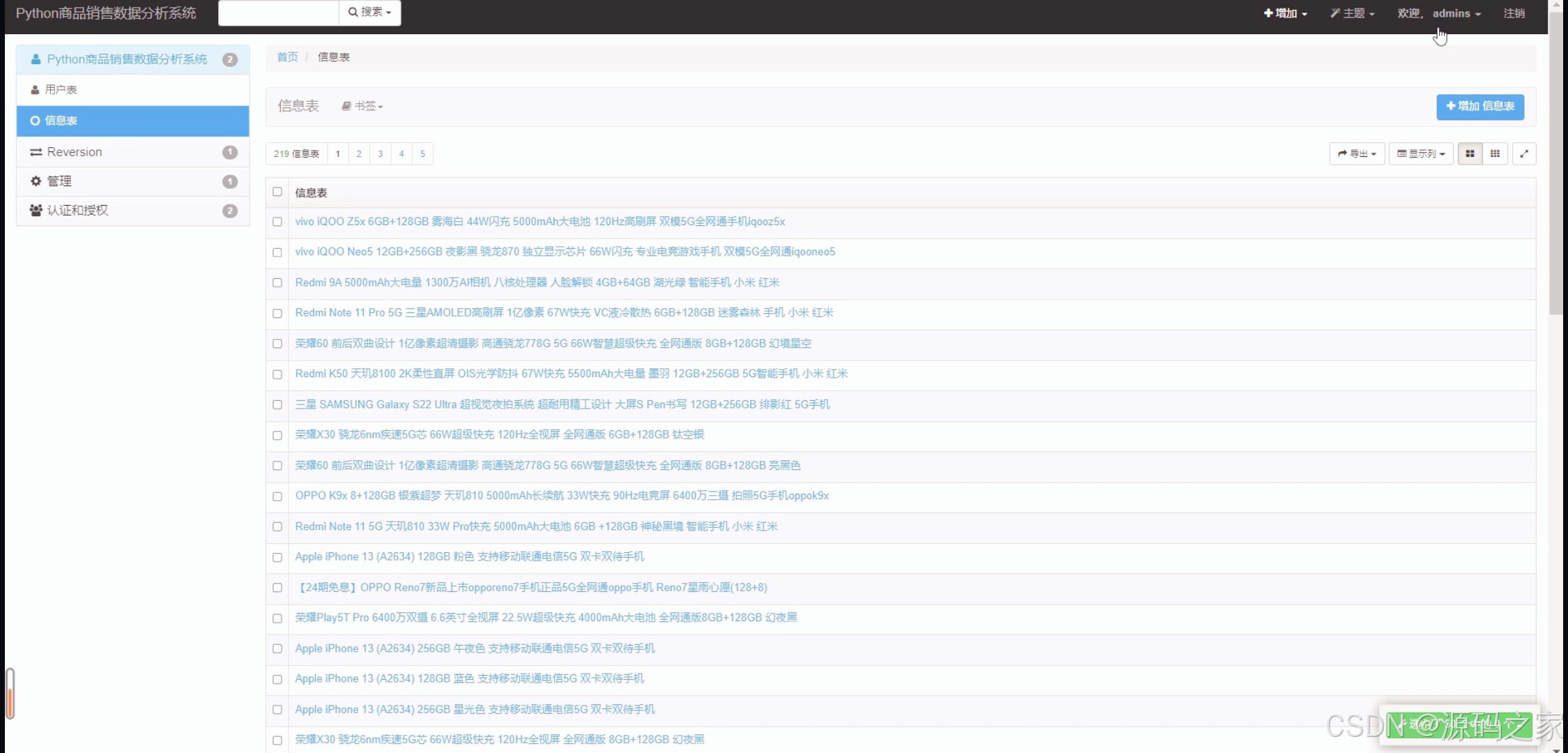
(5)后台数据管理
(6)注册登录
3、项目说明
本系统是一款基于京东商品数据的轻量化分析与管理工具,以Python3为开发核心,融合Django框架、requests网络爬虫、MySQL/sqlite数据库及numpy、matplotlib数据处理库,构建起"数据采集-分析-可视化-管理"全流程功能体系,助力用户高效挖掘京东商品销售价值、管控数据资产。
技术层面,系统采用requests爬虫精准采集京东商品数据,保障数据源的时效性与完整性;以Django框架搭建后端服务,实现功能模块的灵活扩展与稳定运行;前端通过HTML构建交互界面,结合matplotlib生成价格区间柱状图、销售占比饼图、区间销售折线图等可视化图表,让数据趋势直观可感;数据库支持MySQL与sqlite双选择,适配不同用户的部署环境与数据规模需求。
核心功能围绕"数据驱动决策"设计:一是数据采集与整合 ,自动爬取京东商品信息并结构化存储,为后续分析奠定基础;二是多维度可视化分析 ,通过"商品销售数据概况"页展示价格区间分布(柱状图)、销量占比(饼图),"商品数据可视化"页以折线图呈现区间销售趋势,帮助用户快速把握商品销售核心特征;三是数据中心与管理 ,"商品销售数据中心"提供商品详细数据查询,"后台数据管理"模块支持数据增删改查,实现数据全生命周期管控;四是用户权限保障,通过注册登录功能划分用户权限,确保数据访问与操作的安全性。
界面设计兼顾实用性与易用性:各功能页布局清晰,图表色彩协调、数据标注明确,后台管理页操作逻辑简洁,注册登录流程便捷,无论是数据分析师、电商运营还是个人用户,都能快速上手使用。
整体而言,系统以"轻量化、高实用"为特色,既解决了京东商品数据采集的效率问题,又通过可视化与管理功能降低数据应用门槛,为电商运营决策、商品竞品分析提供有力的数据支撑。
4、核心代码
python
from django.shortcuts import render,HttpResponse,reverse,redirect
from django.contrib.auth.decorators import login_required
from Electronics import models
from django.db.models import Q
from django.shortcuts import get_object_or_404,HttpResponseRedirect
import json
import random
# from .xietong import UserCf
# Create your views here.
@login_required
def index(request):
if request.method == 'GET':
datas = models.XinXi.objects.all().order_by('-id')[:10]
return render(request,r"projects\table_s.html",locals())
@login_required
def user_profile(request):
if request.method == 'GET':
return render(request,'projects/user-profile.html',locals())
@login_required
def update_user(request):
if request.method == 'GET':
data = models.Users.objects.get(username=request.user.username)
return render(request,'projects/form_validations.html',locals())
elif request.method == 'POST':
datas = models.Users.objects.get(username=request.user.username)
error = {}
data = request.POST
email = data.get('email','')
if email != '' and '@' in str(email):
email = email
else:
error['email'] = '邮箱格式错误'
age = data.get('age','')
try:
int(age)
if age != '' and 0 < int(age) and int(age) < 120:
age = age
else:
raise Exception('年龄错误')
except:
error['age'] = '年龄错误'
set = data.get('set','')
if set != '' and str(set) in ['男','女']:
set = set
else:
error['set'] = '性别格式错误'
if error != {}:
return render(request,'projects/form_validations.html',context={'data':datas,'error':error})
else:
models.Users.objects.filter(username=request.user.username).update(email=email,age=age,set=set)
user = request.user
return render(request, 'projects/user-profile.html', locals())
@login_required
def select_all(request):
if request.method == 'POST':
data = request.POST.get('projects_name', '')
if data == '':
datas = models.XinXi.objects.all().order_by('-id')[:10]
elif data == 'all':
datas = models.XinXi.objects.all()
else:
datas = models.XinXi.objects.filter(Q(name__icontains=data)|Q(shopname__icontains=data)|Q(pinpai__icontains=data)|Q(xinghao__icontains=data)).order_by('-count')
return render(request,'projects/table_s.html',context={'datas':datas})
import os
import subprocess
@login_required
def spiders(request):
if request.user.is_superuser:
paths = os.path.dirname(os.path.abspath(__file__)) + os.sep + 'spider.py'
cmd = "python " + paths
print(cmd)
res = subprocess.Popen(cmd,shell=True)
dicts = {
"state": True,
"content": "启动成功 ",
}
return HttpResponse(json.dumps(dicts))
@login_required
def fenxi(request):
if request.method == 'GET':
datas = models.XinXi.objects.all()
num1 = len(models.XinXi.objects.filter(Q(price__gt=0) & Q(price__lte=1000)))
num2 = len(models.XinXi.objects.filter(Q(price__gt=1000) & Q(price__lte=2000)))
num3 = len(models.XinXi.objects.filter(Q(price__gt=2000) & Q(price__lte=3000)))
num4 = len(models.XinXi.objects.filter(Q(price__gt=3000) & Q(price__lte=4000)))
num5 = len(models.XinXi.objects.filter(Q(price__gt=4000) & Q(price__lte=100000)))
chaping_datas = models.XinXi.objects.all().order_by('-chaping')[:5]
haoping_datas = models.XinXi.objects.all().order_by('haoping')[:5]
return render(request,'projects/fenxi.html',locals())
@login_required
def spiders1(request):
if request.user.is_superuser:
paths = os.path.dirname(os.path.abspath(__file__)) + os.sep + 'fenxi.py'
cmd = "python " + paths
print(cmd)
res = subprocess.Popen(cmd,shell=True)
dicts = {
"state": True,
"content": "启动成功 ",
}
return HttpResponse(json.dumps(dicts))
@login_required
def item(request,id):
if request.method == 'GET':
data = get_object_or_404(models.XinXi,pk=id)
datas = models.DianZan.objects.all()
dicts = {}
for dat1 in datas:
if dicts.get(dat1.user.username, '') == '':
dicts[dat1.user.username] = {}
dicts[dat1.user.username][dat1.xinxi.id] = dat1.xinxi.avgScore
else:
dicts[dat1.user.username][dat1.xinxi.id] = dat1.xinxi.avgScore
print(dicts)
try:
userCf = UserCf(data=dicts)
recommandList=userCf.recomand(request.user.username, 2)
# # print("最终推荐:%s"%recommandList)
r = userCf.recommend(request.user.username)
datas = []
for rs in r:
datas.append(get_object_or_404(models.XinXi,pk=rs[0]))
except:
datas = models.XinXi.objects.all().order_by('-avgScore')[:3]
return render(request,'projects/detailed.html',locals())
@login_required
def dianzan(request,id):
if request.method == 'GET':
data = get_object_or_404(models.XinXi,pk=id)
if not models.DianZan.objects.filter(Q(user=request.user)&Q(xinxi=data)):
models.DianZan.objects.create(
user=request.user,
xinxi=data
)
dicts = {
"state": True,
"content": "点赞成功 ",
}
return HttpResponse(json.dumps(dicts))🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻