思维导图
本文的思维导图如下:
一、缓存穿透
(一)什么是缓存穿透?
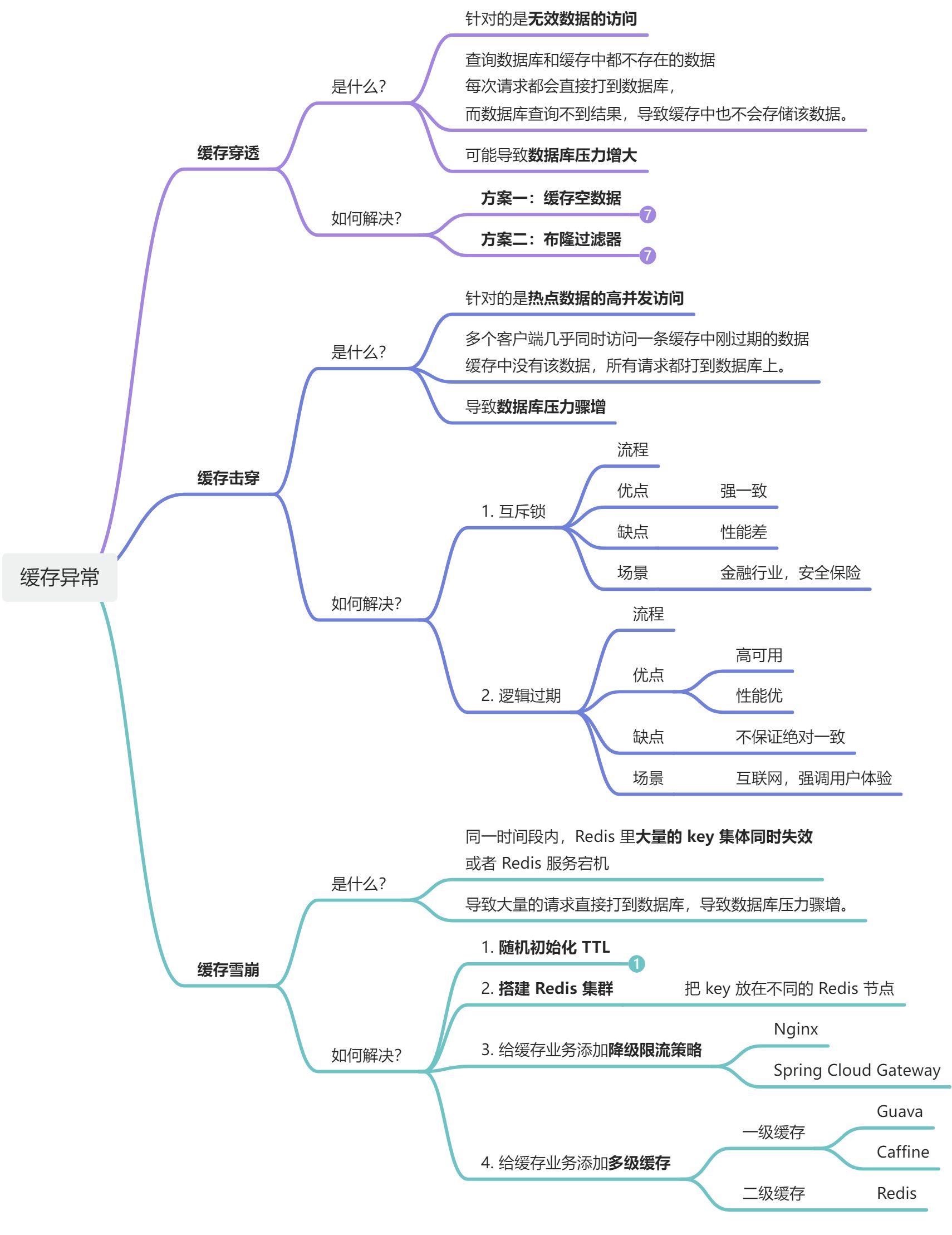
缓存穿透针对的是查询数据库和缓存中都不存在的数据,即请求的数据本身就是无效的。
这种情况下,每次请求都会直接打到数据库,而数据库查询不到结果,导致缓存中也不会存储该数据。
**比如:**有一个 GET 请求:api/news/getById/1
数据库里没有 key = 1 的数据,却有请求 key = 1 的数据,这样 Redis 差不多,再查到 DB。
(二)如何解决缓存穿透?
方案一:缓存空数据
缓存空数据:如果查询到数据库没有该数据,我们就缓存并返回空结果。
优点: 实现简单
缺点:
- 消耗内存,内存的压力会很大
- 可能发送缓存于数据库不一致的问题,比如:
- 一开始有数据库里没有 ID = 1 的数据,为了解决缓存穿透,我们把缓存里 ID = 1 的数据设置为 null;
- 后面真来了一个 ID = 1 的数据,虽然数据库里没有这个数据,缓存却有这个数据。
方案二:布隆过滤器
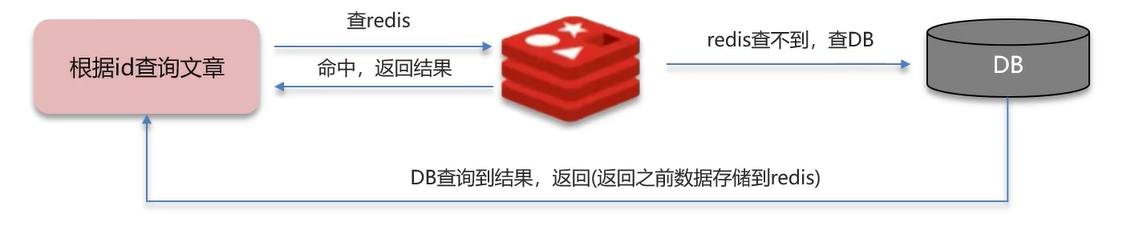
在预热缓存的同时,也预热布隆过滤器(往布隆过滤器里面添加数据)。
当有请求发来的时候,先让布隆过滤器判断一下数据是否存在:
- 存在则放行到 Reids 和 DB
- 不存在就返回
**比如:**有一个 GET 请求:api/news/getById/1
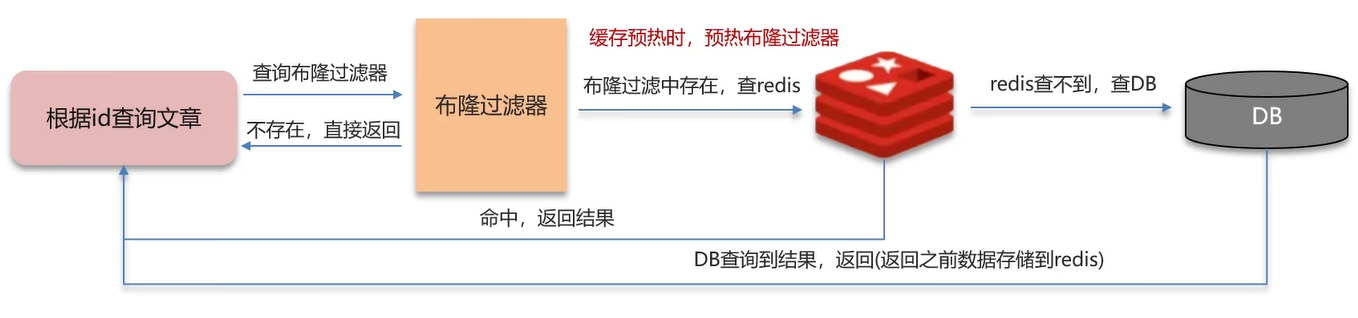
先查询布隆过滤器里面有没有 ID = 1 这个数据:
- 如果有,则往后查询并返回数据
- 如果没有,则直接返回
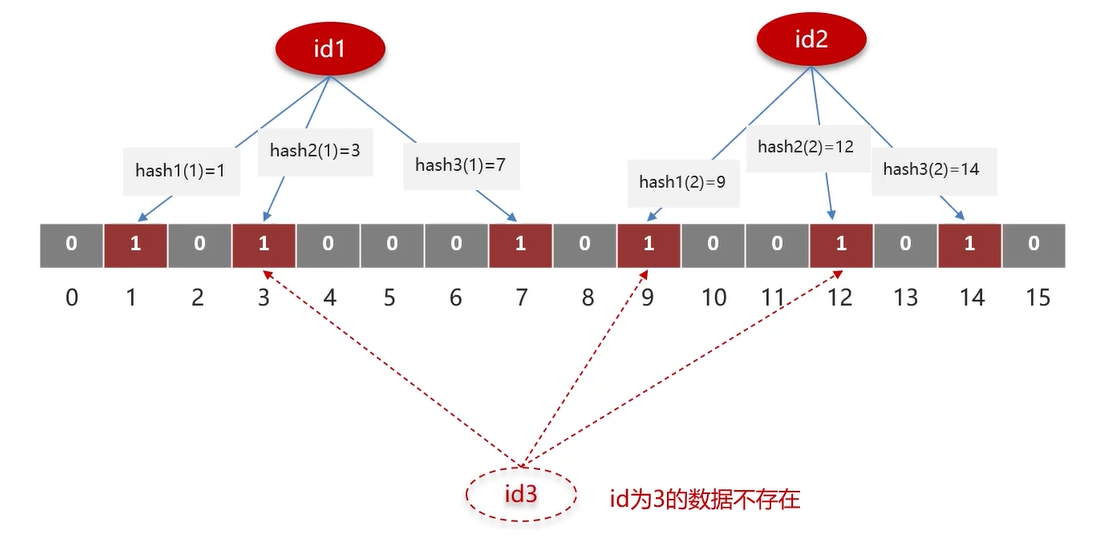
布隆过滤器的底层结构 是一个位数组 (bit array),并配合多个哈希函数。
每个哈希函数会对给定的元素生成一个哈希值,这个哈希值对应位数组中的一个位置,然后将该位置的位设置为1。
什么是位数组?
相当于一个以 位(bit) 为单位的数组,数组中每个单元只能存储二进制数 0 或 1.
作用: 布隆过滤器可以用于检索一个元素是否在一个集合中。
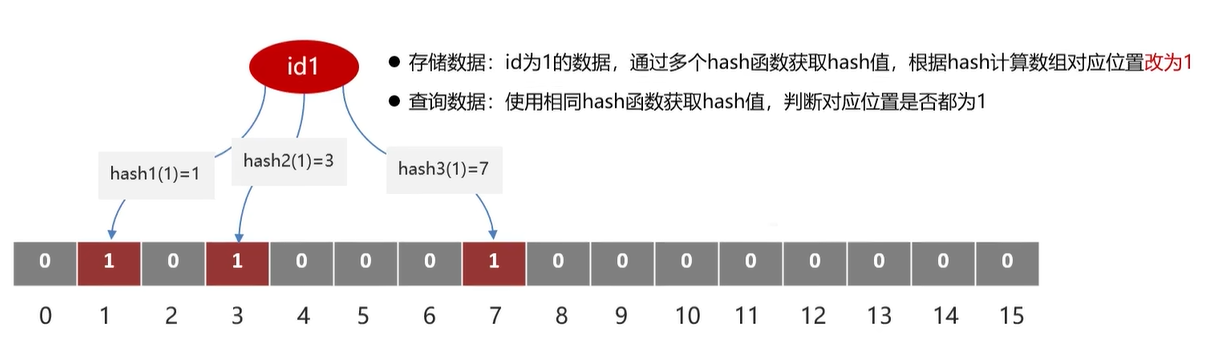
在添加元素时,每个哈希函数都会计算出一个哈希值,并将对应的位数组位置设为1。
在检查一个元素是否可能存在于集合中时,同样的哈希函数会被用来计算哈希值,如果所有计算出的位位置都是1,则认为该元素可能存在于集合中。
误判
但是,由于哈希冲突的存在,布隆过滤器可能会产生误判(false positives),即错误地认为一个元素存在于集合中,即使它实际上并不存在。
比如:id = 3 的数据是不存在的,但是经过三次 hash 计算后,Redis 发现计算的数组位置都为 1,则误判 id = 3 数据存在。
误判率的影响因素:数组大小
- 数组越大,误判率越小,但内存消耗更大
- 数组越小,误判率越大,但内存消耗低了
布隆过滤器的实现方案:
- Redisson
- Guava
我们一般在项目里会设置误判率 0.05:
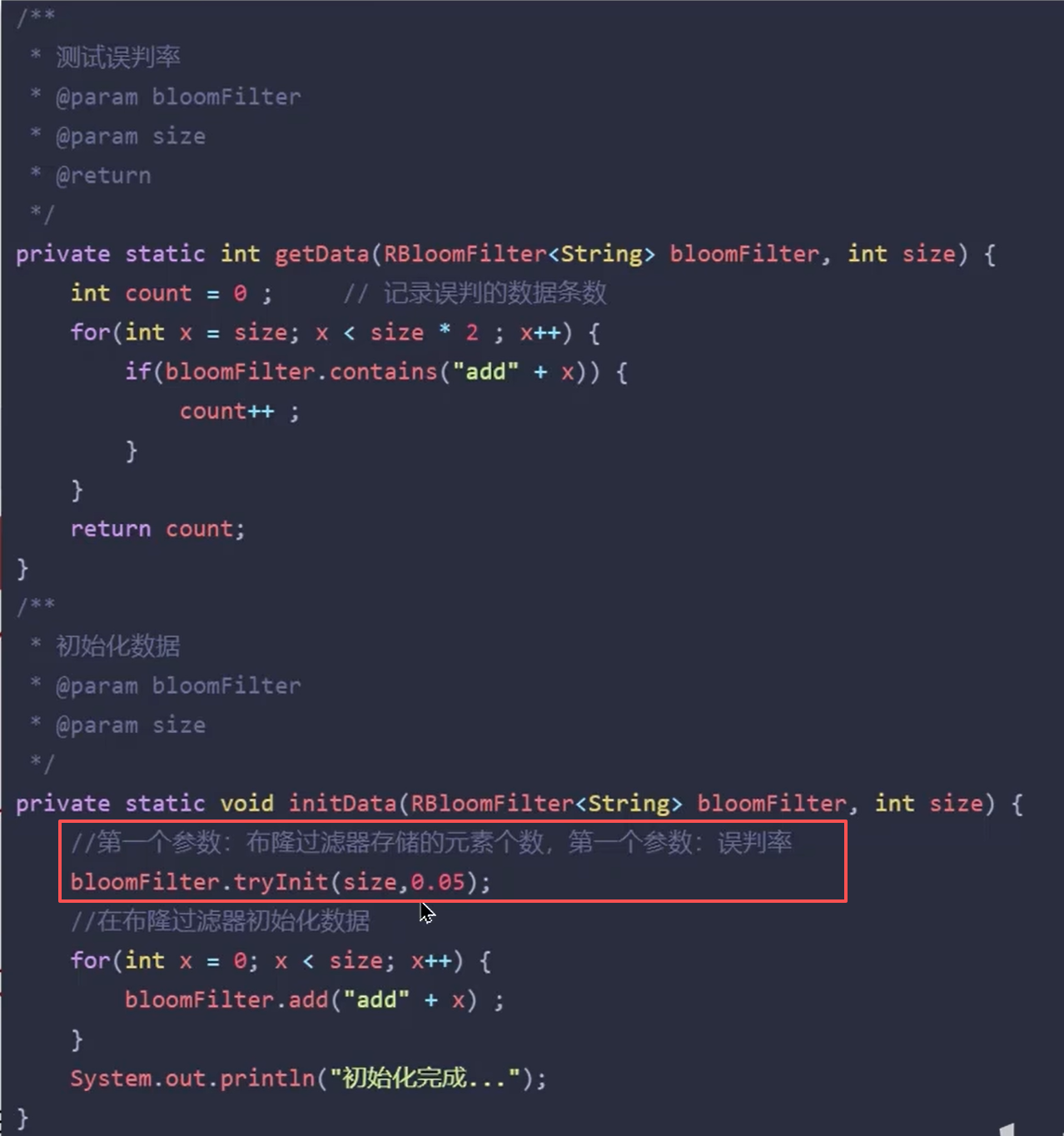
**优点:**内存占用较少,没有多余 key
缺点: 实现复杂,存在误判
二、缓存击穿
(一)什么是缓存击穿?
缓存击穿针对的是**热点数据**,通常是多个客户端几乎同时查询一条缓存中没有的数据。
这种情况下,缓存中没有该数据,所有请求都会直接打到数据库上,造成数据库压力骤增。

举例:
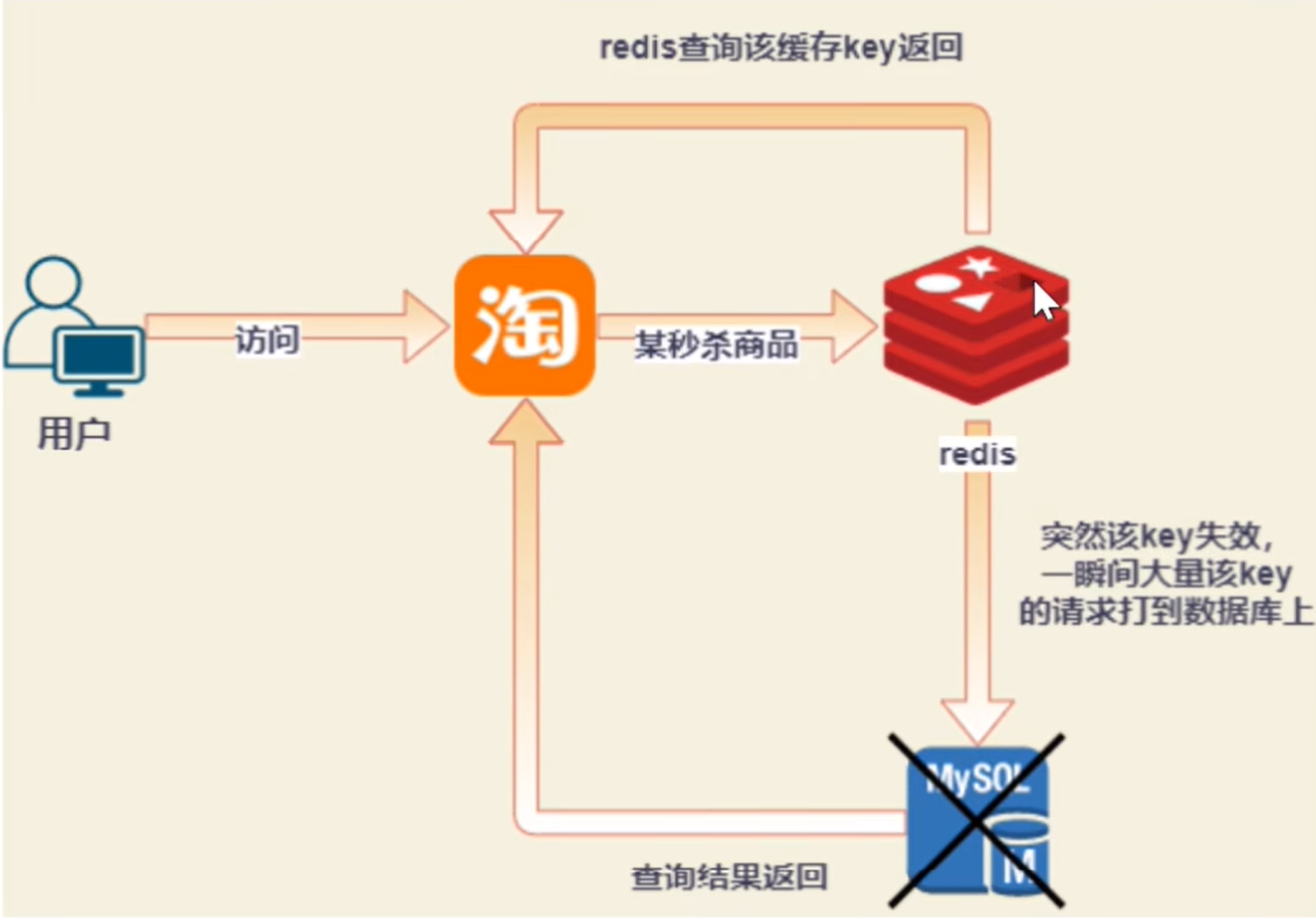
比如双十一的时候,淘宝给某一个热门商品的 key 设置了有效时间 20: 00-24: 00(四小时)
当晚上 24:00的时候,这个 key 过期失效了,但是这个时间点还有大量并发请求来读取它。
这些请求在 Redis 里面查不到数据,就会直接打到数据库 → 造成数据库响应不及时,然后挂掉
(二)如何解决缓存击穿?
方案一:互斥锁(分布式锁)
大量的用户去 Redis 里面请求数据
- Redis 如果有的话就会返回给用户,
- Redis 如果没有的话,就会请求数据库去查询数据
我们就在"请求数据库"这一步给它上锁:
- 只有一个线程可以抢到这个锁,所以也就只有一个线程可以操作这个数据库
- 当它查询到数据之后,再把缓存重新写到 Redis 里面
- 其他没有抢到锁的线程,让它们先睡眠几毫秒,然后再重新去 Redis 里面查询数据。
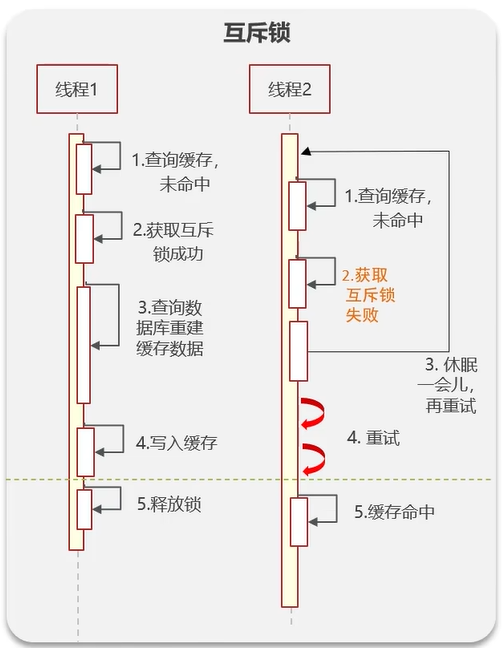
因为只有一个线程可以拿到互斥锁,进行缓存重建,其他线程需要等待。
优点: 保证数据的强一致性
缺点: 性能差
使用场景: 金融行业,需要安全保险
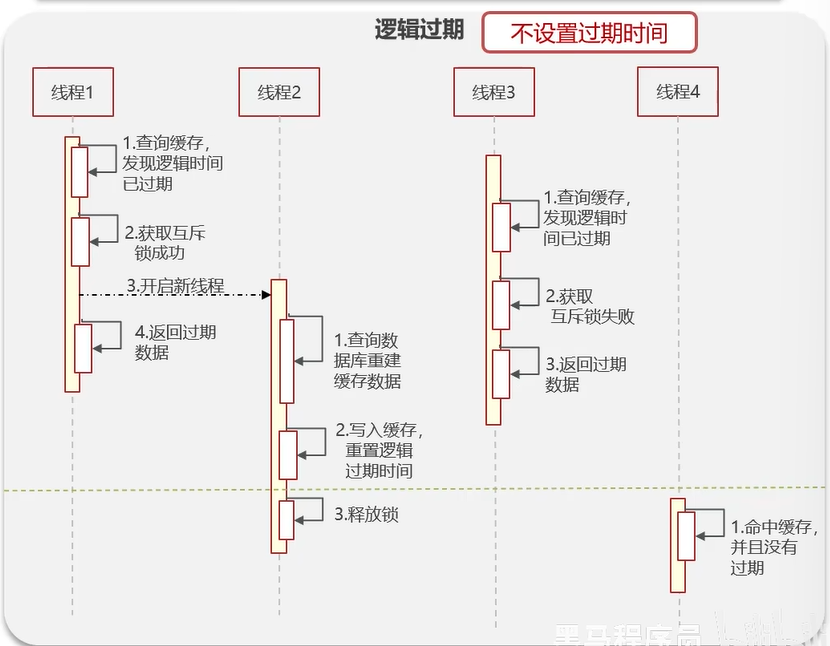
方案二:逻辑过期
线程 1 查到 Redis,发现数据已过期,就获取互斥锁,然后再开一个线程 2 来缓存重建:
- 线程 2 会到数据库里面查询数据,把数据写入 Redis,并重设逻辑过期时间,然后释放锁
- 在线程 2 进行缓存重建的过程中(没释放锁之前):其他线程(比如线程 3)来到 Redis 查询数据,发现逻辑时间过期,获取互斥锁失败,会返回一个过期数据回去。
线程 2 缓存重建完成后,其他线程(比如线程4)就可以在 Redis 里面命中缓存了。
优点:
- 高可用(别管结果可不可用,先返回结果再说)
- 性能优
缺点: 不能保证数据绝对一致性
使用场景: 互联网行业,强调用户体验感
三、缓存雪崩
(一)什么是缓存雪崩?
1. 什么是缓存雪崩
缓存雪崩就是:
- 同一时间段内 Redis 中大量的 key 集体同时失效
- 或者 Redis 服务宕机,导致大量的请求到达数据库,给数据库带来巨大压力。

2. 缓存雪崩和缓存击穿的区别
不同点:
- 缓存击穿 是针对单个热点数据,而缓存雪崩是针对大量数据。
- 缓存击穿通常是由于缓存策略或数据热度不均导致的,缓存雪崩则是由于缓存数据的过期策略导致的集体失效。
共同点:
- 缓存击穿和缓存雪崩都会导致在缓存中找不到数据,大量请求直接打到数据库,可能导致数据库压力过大。
(二)如何解决缓存雪崩?
1. 随机初始化 TTL:
可以为每个缓存项设置一个随机的过期时间,避免它们同时过期。
2. 搭建 Redis 集群
针对 Redis 服务宕机,可以搭建 Redis 集群 ,让这些 key 平均地分布在不同的 Redis 节点上,提高服务的可用性
3. 添加降级限流策略
降级和限流是应对缓存问题的有效手段。
- 降级 是指在后端服务不可用时,++主动降低服务的处理级别++ 或++关闭非核心功能++。
- 限流是限制单位时间内的请求数量,防止过多的请求同时到达后端服务。
针对缓存雪崩问题,我们也可以给缓存业务添加降级限流策略,比如:
1. 单体服务,可以在 Nginx 中设置限流规则
2. 微服务,可以在 Spring Cloud Gateway 中设置限流规则注意:这些策略不仅适用于缓存雪崩,也适用于缓存击穿和缓存穿透场景。
4. 多级缓存策略
给业务添加多级缓存(本地缓存 + 远程缓存),提高缓存命中率,减少对数据库的压力。
例如:可以将本地缓存(Guava 或者 Caffeine)作为一级缓存,Redis 作为二级缓存。
四、相关面试题
1. 什么是缓存穿透?怎么解决?
缓存穿透,大概率是遭受了恶意攻击,有人不断查询一个数据库和缓存中都不存在的数据。
这种情况下,每次请求都会直接打到数据库,数据库也查不到数据,也不会将数据写入缓存。
这个不存在的数据每次请求都要到 DB 去查询,可能会导致数据库压力过重、挂掉。
解决方案的话,我们通常都会用布隆过滤器来解决它。
2. 介绍一下布隆过滤器
布隆过滤器主要的作用就是检索一个元素是否在一个集合中。
它的底层主要就是一个位数组 ,里面用来存放二进制 0 或 1,以及多个哈希函数。
位数组里一开始都是 0,当一个 key 来了之后经过多次 hash 计算出数据在数组中的位置,
然后就把数组中原来的 0 改为 1.
这样的话,在查找该 key 的过程中,如果数组中的这些位置都为 1,就能表该 key 存在。
它的缺点是: 由于哈希冲突,布隆过滤器可能会产生一定的误判。
这个误判是必然存在的,降低误判率就是增加数组的长度。
我们一般也可以通过代码设置误判率,大概不会超过 5%,5% 以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。
3. 什么是缓存击穿?怎么解决?
缓存击穿,针对的是热点数据。
通常是 Redis 里的某个 key 在某个时间点过期的时候,恰好这个时间点又有对这个 key
有大量的并发请求过来,这些请求发现缓存过期就会都直接打到数据库上,造成数据库压力骤增,可能会瞬间把数据库压垮。
解决方案有两种方式:
- 第一是使用互斥锁: 当缓存失效时,不立即去 load db,先使用如 Redis 的 setnx 去设置一个互斥锁,当操作成功返回时再进行 load db 的操作并回设缓存,否则重试 get 缓存的方法
- 第二是可以设置当前 key 逻辑过期 ,大概是思路如下:
- ① 在设置 key 的时候,设置一个过期时间字段一块存入缓存中,不给当前 key 设置过期时间
- ② 当查询的时候,从 redis 取出数据后判断时间是否过期
- ③ 如果过期则开通另外一个线程进行数据同步,当前线程正常返回数据,这个数据不是最新
当然两种方案各有利弊:
- 如果选择数据的强一致性,建议使用分布式锁的方案,性能上可能没那么高,锁需要等,也有可能产生死锁的问题。
- 如果选择 key 的逻辑删除,则优先考虑的高可用性,性能比较高,但是数据同步这块做不到强一致。
4. 什么是缓存雪崩?怎么解决?
缓存雪崩,就是设置缓存时采用了相同的过期时间,导致大量 key 在某一时刻集体失效,
或者是 Redis 服务宕机,导致大量请求全部打到数据库,导致数据库的瞬时压力过重雪崩。
缓存雪崩与缓存击穿的区别:
- 雪崩是很多 key同一时刻大面积失效;
- 击穿是针对某一个热点数据的 key。
解决思路就是将这些 key 的缓存失效时间分散开。
- 比如可以在原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
- 或者搭建 Reids 集群,让这些 key 平均地分布在不同的 Redis 节点上。
- 此外,还可以给缓存业务添加降级限流策略、多级缓存。
这就是缓存雪崩的一些解决方案。