近年来,大语言模型(LLM)在推理能力上突飞猛进,特别是通过强化学习(RL)激发的"思维链"(Chain of Thought)技术,使模型能够进行多步推理以解决复杂问题。受此启发,研究人员尝试将这种语言推理范式引入多模态大模型(MLLM)的视觉感知任务中。然而,实证研究表明,简单的语言中间推理往往会导致感知性能下降,甚至产生与图像内容无关的"幻觉"。
为什么会出现这种现象?来自南京理工大学、新加坡科技设计大学、阿德莱德大学、百度、Data61-CSIRO以及商汤科技的研究团队在最新论文《Artemis: Structured Visual Reasoning for Perception Policy Learning》中给出了深刻的见解。核心问题不在于"推理"本身,而在于"推理的形式"。视觉感知的本质要求在空间和以对象为中心(Object-Centric)的结构化环境中进行推理,而不在非结构化的语言空间中进行"空谈"。

论文标题:Artemis: Structured Visual Reasoning for Perception Policy Learning
论文链接:
代码仓库: ****
问题洞察:语言推理的局限与结构化视觉推理的必然
当现有MLLM面对如"找出最矮的运动员"这类指令时,它们往往依赖类似语言模型的"内部独白"进行推理。这种纯语义的推理过程缺乏视觉基础,容易产生无关或错误的中间描述,最终导致定位失败。相比之下,人类的感知过程是典型的结构化视觉推理:我们首先快速扫描整个场景,定位可能相关的区域,然后逐步聚焦、比较,最终锁定目标对象。
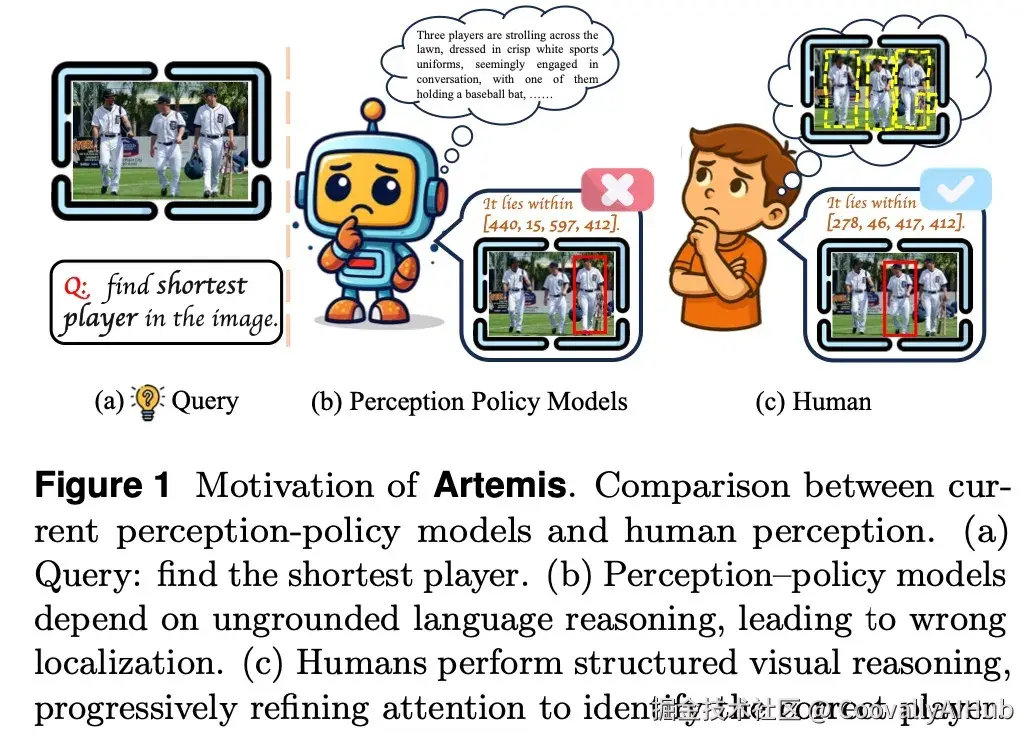
Artemis的诞生:让MLLM学会"先看后想,边看边推"
为了克服上述局限,研究团队提出了 Artemis ------ 一个基于强化学习的感知策略学习框架。该框架的命名灵感来源于古希腊神话中的狩猎女神阿尔忒弥斯,以其敏锐的视觉和百发百中的精准度著称,寓意着模型所追求的核心能力。
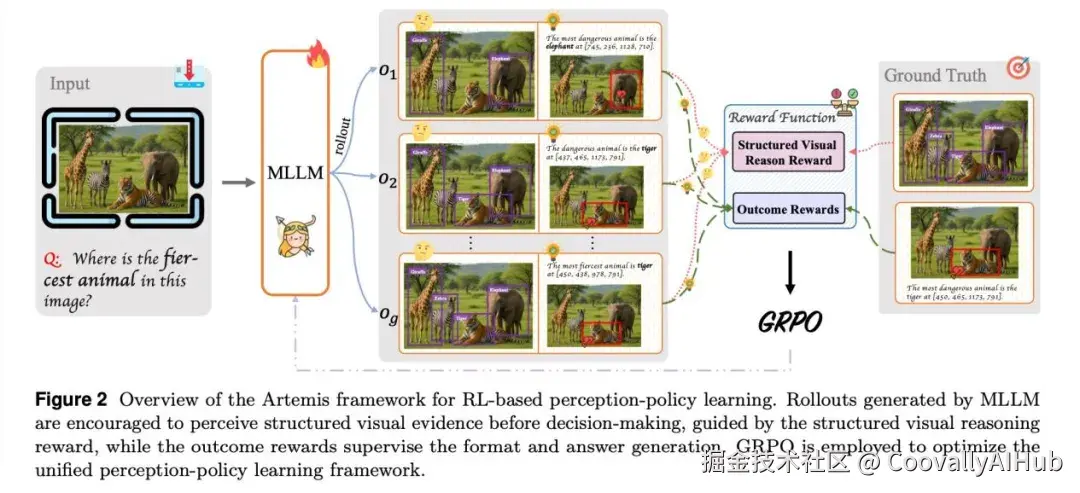
Artemis的核心创新在于要求模型提供结构化的视觉推理证据。在生成最终答案前,模型必须在特定的思考阶段输出一系列 (标签,边界框) 对。这些对直接代表了模型在图像中定位到的视觉实体,构成了可验证、可追踪的中间视觉状态。
- 结构化视觉推理奖励: 这是Artemis的灵魂。它设计了一套精细的奖励机制,不仅鼓励模型找出最终答案的关键对象,也奖励其识别出相关的上下文对象。这就像解题时,不仅要求答案正确,还要求列出关键的已知条件和推导步骤。
- 统一的结果奖励: 包括格式奖励(确保输出结构规范)和答案奖励(基于预测框与真值框的重叠度及标签一致性)。
- 高效的训练算法: 采用群组相对策略优化(Group Relative Policy Optimization, GRPO) 算法,高效地优化整个感知策略。
强大的训练基础:Artemis-RFT数据集
为了训练Artemis,团队构建了Artemis-RFT数据集。该数据集基于MS-COCO构建,包含约7.7万个实例,统一了视觉定位(Visual Grounding)和目标检测(Object Detection) 两种任务格式。模型被训练在给出最终答案(绿色框)之前,先输出中间推理步骤(紫色框)来标识相关对象,从而学会结构化的视觉推理流程。

Artemis-RFT数据示例。该数据集包含两种任务类型:视觉定位和对象检测,统一的Artemis感知策略学习框架在两者上联合训练。紫色框表示推理对象,绿色框表示答案。
如上图所示,Artemis 要求模型在给出最终答案(绿色框)之前,先通过推理(紫色框)识别出场景中的相关对象。这种训练方式让模型学会了"先看后答"。
卓越的性能表现:全面领先,泛化惊人
Artemis基于Qwen2.5-VL-3B模型构建,在多个基准测试中取得了突破性成果:
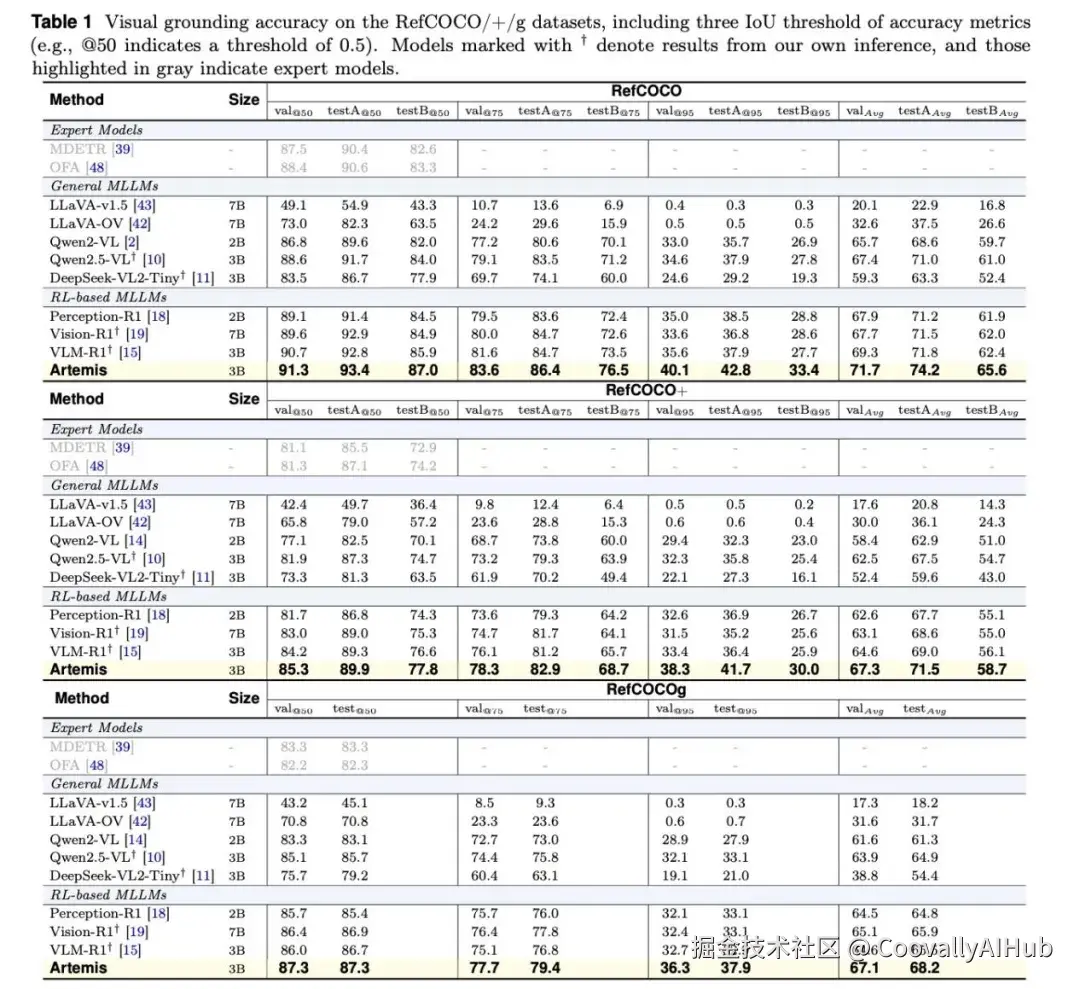
- 视觉定位与检测任务
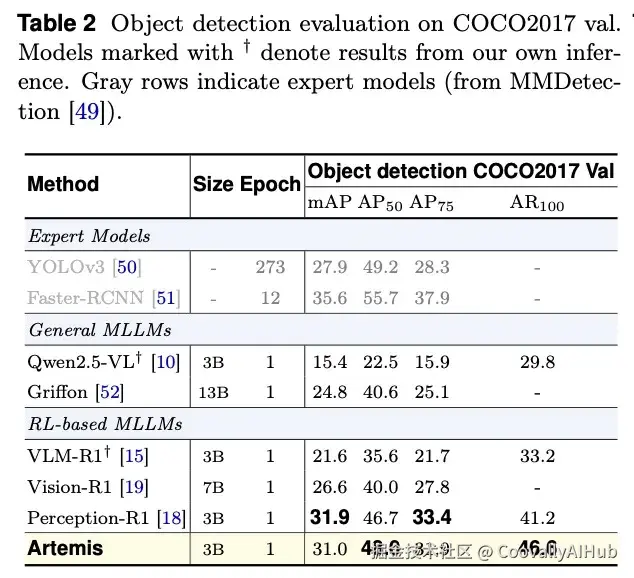
在RefCOCO/+/g系列基准测试中,Artemis在所有指标上均达到领先水平,尤其在要求极高的IoU@0.95指标上优势显著,证明了其边界框预测的精准度。在COCO目标检测任务上,其mAP达到31.0,远超基座模型的15.4。
-
惊艳的零样本泛化能力
-
视觉计数: 在从未接受过计数任务训练的情况下,Artemis在Pixmo-Count数据集上的零样本准确率高达81.4,甚至超过了专门为计数设计的模型。它通过结构化地"列举"出图像中的目标对象来完成计数,模仿了人类的点数行为。
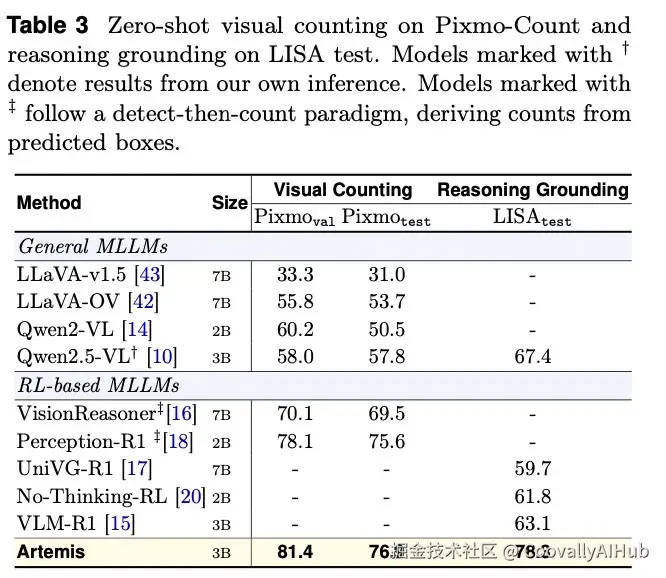
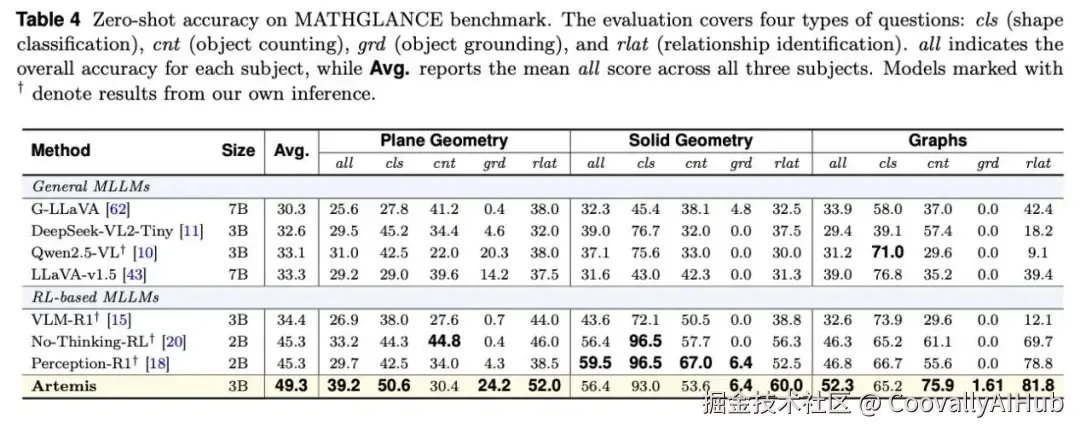
- 几何图形感知: Artemis能够将其在自然图像中学到的结构化感知能力,稳健地迁移到数学几何图形领域。在MATHGLANCE基准测试(涵盖平面几何、立体几何、图表题)中,它同样表现出色,实现了从真实场景到抽象图示的跨域泛化。
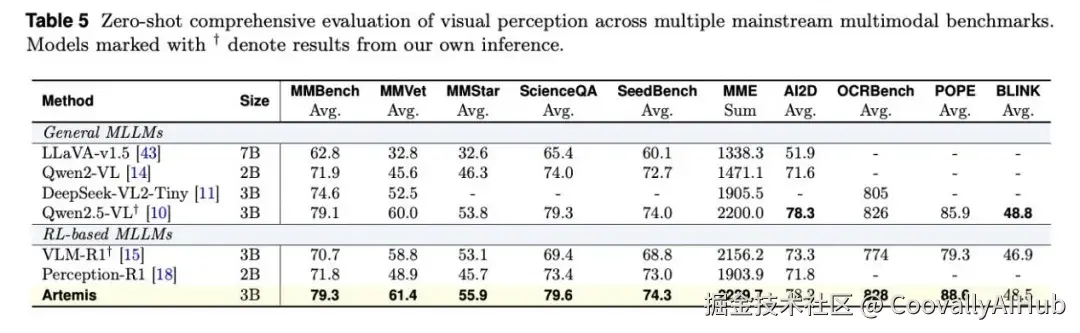
- 综合多模态能力
在MMBench、MMVet等主流多模态理解基准测试中,Artemis保持了竞争优势,表明其增强的感知能力有益于整体的多模态推理。
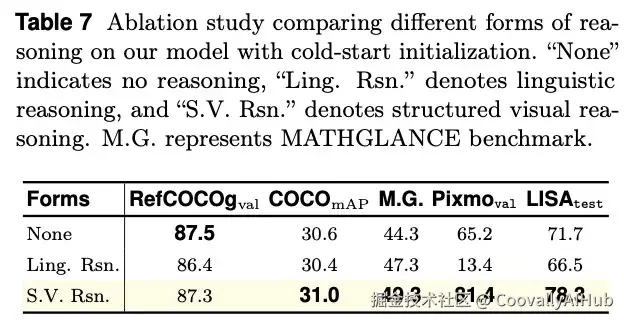
消融分析:验证结构化推理的核心价值
研究团队通过系统的消融实验证实:
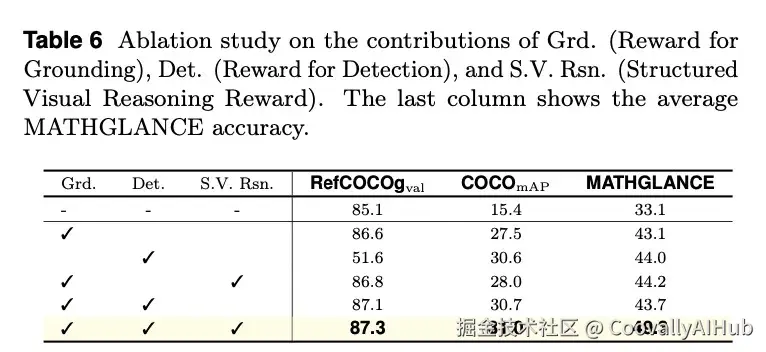
- 无推理: 域内任务尚可,但域外泛化能力极差。
- 纯语言推理: 会干扰感知过程,导致性能下降,尤其在计数等任务上。
- 结构化视觉推理: 是性能全面提升和获得强大零样本泛化能力的关键。
- 可视化展示

Artemis 通过紫色的推理框精准地定位了场景中的关键要素,从而给出了正确的红色答案框。相比之下,其他模型要么定位错误,要么完全偏离目标。

在计数任务中,Artemis 展现了类似人类的"点数"行为,通过逐个标记目标(紫色框)来得出正确的总数,而基座模型 Qwen2.5-VL 则出现了严重的幻觉,标记了大量重复或错误的框。
技术贡献与产业影响
Artemis的工作首次系统性地证明:通过单一、统一的结构化视觉推理训练,可以使MLLM获得跨任务、跨领域的强大感知泛化能力。这项研究为MLLM的感知能力与空间推理能力的对齐指明了新方向。
结论
Artemis的出现标志着MLLM感知研究的一个重要转折点:它告诉我们,对于视觉任务,"如何思考"与"思考什么"同样重要,甚至更为关键。将推理过程空间化、结构化、可验证化,是解锁MLLM可靠感知与推理能力的关键。这项工作为构建下一代真正理解物理世界、能进行复杂空间交互的智能体奠定了坚实的基础。