导读:
在日语教学过程中,选择难易度合适的日文文本作为教学材料有利于提高日语学习者的学习兴趣及效率。日语具有词汇量大、语法复杂等特征,对文本难易度分类提出了挑战。本文尝试采用多种基于神经网络的日语预训练语言模型,通过收集历年日本语能力测试真题以及模拟题作为数据集以训练日文文本难易度自动分类模型。实验结果表明,预训练语言模型在日文文本难易度自动分类任务上能够表现出较好的性能。基于预训练语言模型的日文文本难易度自动分类方法将为计算机辅助日语学习系统以及电子化教材开发等提供有力的技术保障。
作者信息:
刘 君:广西大学外国语学院,广西 南宁
论文详情
数据收集与预处理
本文收集的日语文本数量统计说明如表1所示:

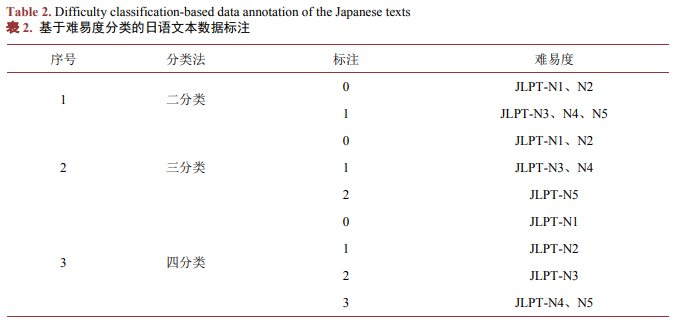
本文根据实际教学过程中大学日语专业学习者的学习进阶情况以及日文文本难易度自动分类实验设计需求,进一步对JLPT的难易度进行了四种不同分类,并对对应JPLT不同难度的文本进行了相应标注。具体分类及标注说明如表2所示:
此外,为了有效训练日语文本难易度分类模型,本文将标注后的数据集按照8:2的比例划分为训练集和测试集。
实验设计
本文分别选取了由日本京都大学、日本情报通信研究机构以及日本东北大学发布的日语预训练语言模型,共计14种。这些模型采用双向Transformer编码器表征(Bidirectional Encoder Representations from Transformers, BERT) 算法训练而成。日语预训练语言模型信息如表3所示:

实验结果与分析
从二分类实验结果(如表4所示)来看,除了模型4 (NICT-100K)之外,其他模型取得的F1值均超过了0.8。其中,模型12 (tohoku-bert-large-japanese-v2)在精确率、召回率以及F1值三项指标上均获得最高值,其分值均为0.926。实验结果表明,该模型在将日文文本分类为高级难度文本(JLPT-N1、N2)和低级难度文本(JLPT-N3、N4、N5)两个级别上表现出了最优的性能。

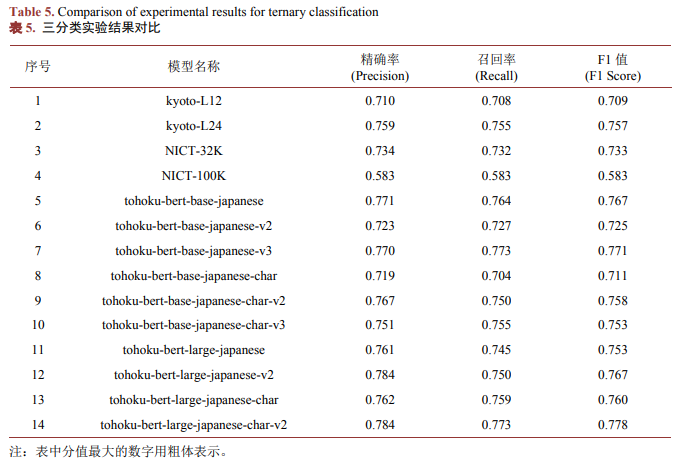
从三分类实验结果(如表5所示)来看,模型12 (tohoku-bert-large-japanese-v2)以及模型14 (tohoku-bert-large-japanese-char-v2)的精确率最高,分值均为0.784;模型7 (tohoku-bert-base-japanese-v3)以及模型14 (tohoku-bert-large-japanese-char-v2)的召回率最高,分值均为0.773;模型14 (tohoku-bert-large-japanese-char-v2)的F1值最高,分值为0.778。综合三分类结果来看,模型14 (tohoku-bert-large-japanese-char-v2)在将日文文本分类为高级难度文本(JLPT-N1、N2)、中级难度文本(JLPT-N3、N4)和低级难度文本(JLPT-N5)三个级别上表现出了最优的性能。
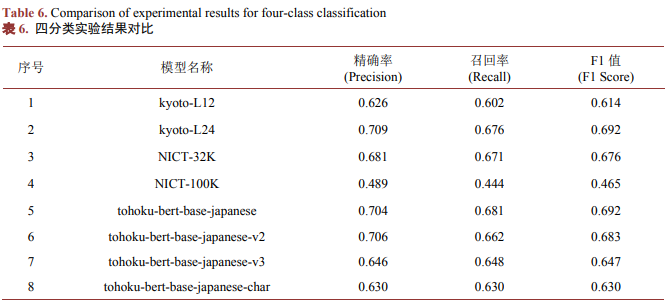
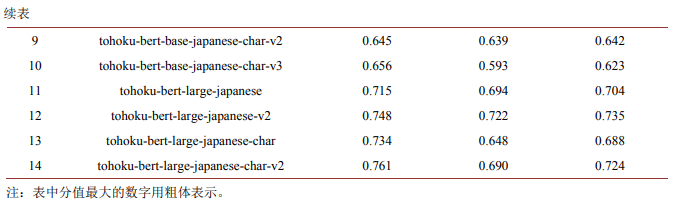
从四分类实验结果(如表6所示)来看,模型14 (tohoku-bert-large-japanese-char-v2)取得了最高的精确率,分值均为0.761;模型12 (tohoku-bert-large-japanese-v2)取得了最高的召回率,分值均为0.722;模型12 (tohoku-bert-large-japanese-v2)的F1值最高,分值为0.735。综合四分类结果来看,模型12 (tohoku-bert-large-japanese-v2)在将日文文本分类为高级上等难度文本(JLPT-N1)、高级下等难度文本(JLPT-N2)、中级难度文本(JLPT-N3、N4)和低级难度文本(JLPT-N5)四个级别上表现出了更好的性能。
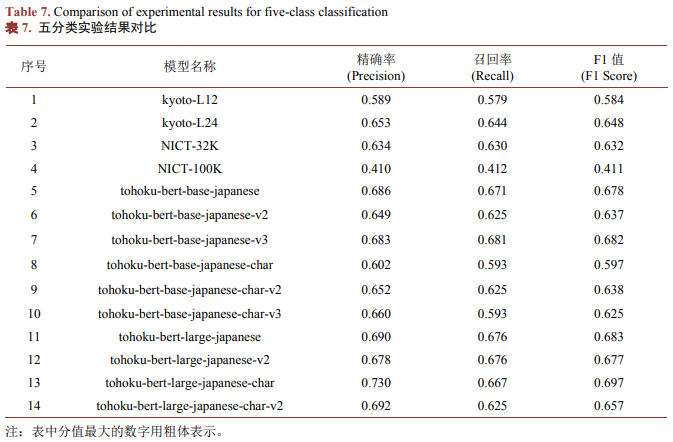
从五分类实验结果(如表7所示)来看,模型13 (tohoku-bert-large-japanese-char)取得了最高的精确率,分值均为0.73;模型7 (tohoku-bert-base-japanese-v3)取得了最高的召回率,分值均为0.681;模型11 (tohoku-bert-large-japanese)的F1值最高,分值为0.683,其次为模型7,分值为0.682。综合四分类结果来看,模型7 (tohoku-bert-base-japanese-v3)在将日文文本分类为高级上等难度文本(JLPT-N1)、高级下等难度文本(JLPT-N2)、中级上等难度文本(JLPT-N3)、中级下等难度文本(JLPT-N4)和低级难度文本(JLPT-N5)五个级别上表现出了更好的性能。
结论
本文提出基于预训练语言模型的方法,通过多项分类实验评估了14中日语BERT预训练语言模型在日文文本难易度自动分类任务中的表现。实验结果表明,该方法具有一定的有效性,尤其是在二分类任务上表现最优;各种模型随着分类的进一步细化,其性能也随之降低;不同机构发布的模型在难易度分类性能方面也表现出了一定的差异。综合来看,日本东北大学发布的BERT预训练语言模型在本次日文文本难易度分类任务中表现更优。BERT预训练语言模型因其强大的表示能力,能够适应日文文本难易度分类任务,在日语教学领域展现出了较大的应用价值。今后,将继续探索针对日文的语言数据标注、文本分类的标准化、日语语言特征挖掘等系列问题,以构建更加精细化的模型,为智能化、个性化日语教学提供有力的技术保障。例如,可借助实时动态建模技术,模型不断输出与学习者日语能力相匹配的文本,并接受学习者的反馈,达到优化文本分类结果。
基金项目:
广西哲学社会科学规划研究课题:日语文本易读性评估中融合神经网络技术的语言学特征优化组合研究(批准号:22FYY011)
原文链接: