Elasticsearch专用的ES|QL语法指令整理
- 什么是ES|QL?
- [ES|QL 基础语法结构](#ES|QL 基础语法结构)
-
- [1 基本查询格式](#1 基本查询格式)
- [2 完整查询示例](#2 完整查询示例)
- 语法关键字整理
-
- [1. 数据获取命令](#1. 数据获取命令)
- [2. 数据筛选命令](#2. 数据筛选命令)
- [3. 数据处理命令](#3. 数据处理命令)
- [4. 聚合与分组命令](#4. 聚合与分组命令)
- [5. 结果输出命令](#5. 结果输出命令)
- 简单示例
- 常用语句详解
-
- [一、FROM 子句](#一、FROM 子句)
- [二、WHERE 子句(条件筛选)](#二、WHERE 子句(条件筛选))
- [2.1 精确匹配查询](#2.1 精确匹配查询)
- [2.2 模糊查询](#2.2 模糊查询)
- [2.3 范围查询](#2.3 范围查询)
- [2.4 多条件组合](#2.4 多条件组合)
- [2.5 IN 查询](#2.5 IN 查询)
- [2.6 存在性检查](#2.6 存在性检查)
- [三、EVAL 子句(字段计算)](#三、EVAL 子句(字段计算))
-
- [3.1 基本计算](#3.1 基本计算)
- [3.2 类型转换](#3.2 类型转换)
- [四、STATS 子句(聚合统计)](#四、STATS 子句(聚合统计))
- [五、SORT、KEEP、LIMIT 子句](#五、SORT、KEEP、LIMIT 子句)
-
- [5.1 排序](#5.1 排序)
- [5.2 字段选择](#5.2 字段选择)
- [5.3 限制结果](#5.3 限制结果)
- [传统的Query DSL查询方式](#传统的Query DSL查询方式)
- 性能优化建议
- 注意事项
什么是ES|QL?
ES|QL(Elasticsearch Query Language)是一种专为 Elasticsearch设计的、管道式的数据查询语言。它于2023年正式推出,Elasticsearch 8.11+ 引入的一种新的查询语言,类似于传统的 SQL但更专注于流式数据处理,旨在提供比传统 Query DSL 更直观、更强大且更易于学习的数据探索和转换能力。
核心设计哲学
1. 管道式处理 :数据像在流水线上一样,依次通过一系列命令(称为"操作符")进行处理,每个操作符接收上一个操作符的输出作为输入。
2. 声明式 :只需描述"想要什么结果",而无需编写"如何一步步执行"的指令。
3. 统一查询与处理:将数据检索、转换、聚合、丰富化等多个步骤合并到一条流畅的查询中。
ES|QL 基础语法结构
1 基本查询格式
bash
FROM index_name
[WHERE condition]
[EVAL expression]
[STATS ...]
[KEEP fields]
[LIMIT n]
[SORT fields]
...2 完整查询示例
bash
FROM logs-*
| WHERE timestamp >= NOW() - 1 DAY
| EVAL duration_sec = duration / 1000
| STATS avg_duration = AVG(duration_sec),
count = COUNT(*) BY service.name
| WHERE count > 100
| SORT avg_duration DESC
| KEEP service.name, avg_duration, count
| LIMIT 20
语法关键字整理
1. 数据获取命令
| 命令 | 描述 | 示例 |
|---|---|---|
| FROM <index_pattern> | 从指定索引模式读取数据。 | FROM logs-* |
| FROM <index1>, <index2> | 从多个索引读取数据。 | FROM logs-nginx, logs-apache |
| ROW | 生成静态的行数据,用于测试或构造数据。 | ROW a = 1, b = "test" |
2. 数据筛选命令
| 命令 | 描述 | 示例 |
|---|---|---|
| WHERE <condition> | 根据条件过滤行。支持 AND, OR, NOT。 | WHERE status == 200 |
| 条件表达式 | =, !=, <, <=, >, >=, LIKE, NOT LIKE, IN, IS NULL, IS NOT NULL | WHERE url LIKE "/api/%" AND status >= 400 |
| DISSECT | 使用分隔符模式从字符串中提取字段。 | FROM logs | DISSECT raw "%{clientip} %{ident} %{auth} %{timestamp} \"%{verb} %{request}" |
3. 数据处理命令
用于转换、丰富和操作列数据。
| 命令 | 描述 | 示例 |
|---|---|---|
| EVAL <field> = <expression> | 计算新字段或更新现有字段。 | EVAL total = price * quantity |
| RENAME <old> AS <new> | 重命名字段。 | RENAME user AS username |
| DROP <field> | 删除字段。 | DROP temp_field |
| KEEP <field_list> | 保留指定字段 | KEEP timestamp, user, action |
| GROK | 使用正则表达式从非结构化文本中提取字段。 | | GROK message "%{IP:client} %{WORD:method} %{URIPATHPARAM:request}" |
4. 聚合与分组命令
用于数据汇总和统计分析。
| 命令 | 描述 | 示例 |
|---|---|---|
| STATS <agg> BY \ |
计算聚合统计(类似 SQL 的 GROUP BY)。 | STATS avg_response = AVG(response_time) BY service |
| 聚合函数 | COUNT(), SUM(), AVG(), MIN(), MAX(), COUNT_DISTINCT() | STATS user_count = COUNT_DISTINCT(user_id), total_sales = SUM(amount) BY region |
5. 结果输出命令
| 命令 | 描述 | 示例 |
|---|---|---|
| LIMIT <number> | 限制返回的行数。 | LIMIT 100 |
| SORT <field> ASC/DESC | 按字段排序。 | SORT timestamp DESC |
| MV_EXPAND <field> | 将多值字段(数组)展开为多行。 | MV_EXPAND tags |
简单示例
假设有 club_user 索引,包含 nick(昵称)、clubid(俱乐部ID)、status(状态)、join_date(加入日期)、login_count(登录次数)等字段。
查找特定俱乐部中状态活跃、昵称包含"abc"的会员,按加入日期倒序排列。
bash
FROM club_user
| WHERE clubid == 123456 AND status == 1 AND nick LIKE "*abc*"
| SORT join_date DESC
| KEEP nick, clubid, join_date, login_count
| LIMIT 50常用语句详解
一、FROM 子句
bash
-- 查询单个索引
FROM products
-- 查询多个索引
FROM products,orders
-- 使用通配符
FROM logs-2024.01.*
-- 查询所有索引(谨慎使用)
FROM *
-- 跨集群查询(如果有多个集群)
FROM cluster_one:logs-*, cluster_two:logs-*二、WHERE 子句(条件筛选)
📚 ES|QL 支持的比较操作符完整列表
目前,ES|QL 支持以下用于 WHERE 子句的比较操作符:
| 操作符 | 含义 | 示例 |
|---|---|---|
| == | 等于 | status == 1 |
| != | 不等于 | clubid != 0 |
| > | 大于 | login_count > 100 |
| >= | 大于等于 | endline >= 1000 |
| < | 小于 | age < 18 |
| <= | 小于等于 | endline <= 5000000 |
| LIKE | 文本匹配 | nick LIKE "ac*" |
| RLIKE | 正则匹配 | email RLIKE "@example\\.com$" |
| IN | 多值匹配 | status IN (1, 2, 3) |
| IS NULL / IS NOT NULL | 空值检查 | nick IS NOT NULL |
2.1 精确匹配查询
bash
-- 字符串精确匹配
FROM products
| WHERE category == "electronics"
-- 数字精确匹配
FROM orders
| WHERE total_amount == 100.50
-- 布尔值匹配
FROM users
| WHERE is_active == true
-- NULL 值检查
FROM products
| WHERE description IS NOT NULL2.2 模糊查询
bash
-- LIKE 操作符(简单模式)
FROM products
| WHERE name LIKE "*laptop*"
-- 使用 RLIKE(正则表达式)
FROM logs
| WHERE message RLIKE ".*error.*|.*fail.*"
-- 开头匹配
FROM products
| WHERE sku LIKE "PROD-*"
-- 结尾匹配
FROM files
| WHERE filename LIKE "*.log"2.3 范围查询
bash
-- 数字范围
FROM orders
| WHERE price >= 100 AND price <= 5002.4 多条件组合
bash
-- AND 操作
FROM orders
| WHERE status == "completed"
AND total > 1000
AND customer.country == "US"
-- OR 操作
FROM products
| WHERE category == "electronics"
OR category == "computers"2.5 IN 查询
bash
-- 枚举匹配
FROM products
| WHERE category IN ("electronics", "books", "clothing")2.6 存在性检查
bash
-- 字段存在检查
FROM documents
| WHERE tags IS NOT NULL三、EVAL 子句(字段计算)
3.1 基本计算
bash
-- 数学运算
FROM orders
| EVAL tax = price * 0.08
| EVAL total = price + tax
-- 字符串操作
FROM users
| EVAL full_name = CONCAT(first_name, " ", last_name)
| EVAL email_domain = TO_STRING(SPLIT(email, "@")[1])3.2 类型转换
bash
-- 显式类型转换
FROM data
| EVAL
price_int = TO_INT(price_string),
is_active_bool = TO_BOOLEAN(is_active_str),
timestamp_date = TO_DATETIME(timestamp_str)
-- 自动转换
FROM mixed_data
| EVAL total = quantity * unit_price四、STATS 子句(聚合统计)
bash
-- 单指标聚合
FROM sales
| STATS
total_sales = SUM(amount),
avg_sale = AVG(amount),
min_sale = MIN(amount),
max_sale = MAX(amount),
sale_count = COUNT(*)
-- 分组聚合
FROM orders
| STATS
order_count = COUNT(*),
total_revenue = SUM(total),
avg_order_value = AVG(total)
BY customer_id, DATE_TRUNC(order_date, "MONTH")
-- 去重计数
FROM logs
| STATS unique_users = COUNT_DISTINCT(user_id)五、SORT、KEEP、LIMIT 子句
5.1 排序
bash
-- 简单排序
FROM products
| SORT price DESC
-- 多字段排序
FROM employees
| SORT department ASC, salary DESC
-- 空值处理
FROM data
| SORT COALESCE(score, 0) DESC5.2 字段选择
bash
-- 选择特定字段
FROM logs
| KEEP level, message, service.name
-- 重命名字段
FROM orders
| EVAL order_total = total_amount
| KEEP order_id, customer_id, order_total, status
-- 排除字段
FROM users
| DROP password_hash, ssn5.3 限制结果
bash
-- 基本限制
FROM logs
| LIMIT 1000
-- 分页模拟
FROM products
| SORT price ASC
| LIMIT 20 -- 第一页传统的Query DSL查询方式
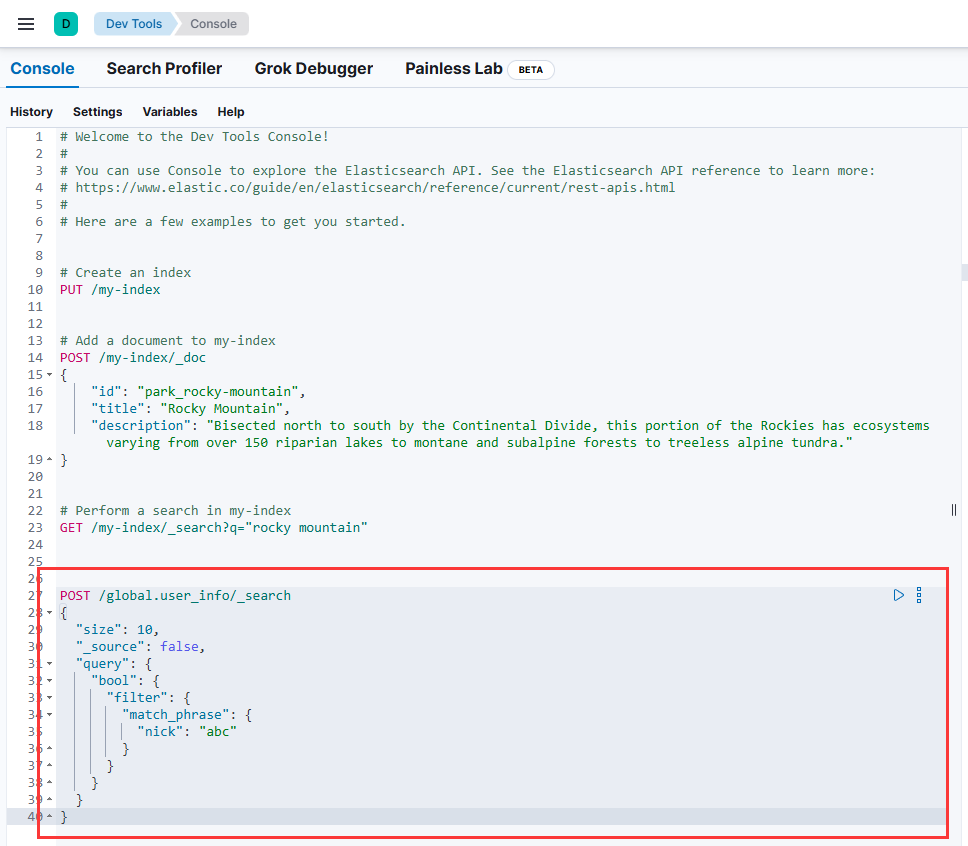
步骤:
打开 Kibana Dev Tools
点击顶部的 Console 标签
在左侧面板输入查询语句
点击右侧的 ► 按钮或按 Ctrl/Cmd + Enter
性能优化建议
查询优化技巧
bash
-- 1. 尽早过滤数据
FROM large_index
| WHERE timestamp >= NOW() - 1 DAY -- 首先过滤时间范围
| WHERE status == "active" -- 然后过滤状态
-- 2. 减少字段传输
FROM logs
| KEEP level, message -- 只选择需要的字段
| WHERE level == "ERROR"注意事项
1. 版本要求 :ES|QL 需要 Elasticsearch 8.11.0 或更高版本,并在 Kibana 中启用。请确保环境满足要求。
2. 性能优化:
- 在管道最前端使用 WHERE 进行过滤,尽量减少后续处理的数据量。
- 只 KEEP 必要的字段,减少数据传输。
- 对大型数据集进行聚合时,合理使用 LIMIT 和 SORT。
3. 调试技巧 :从简单的 FROM index | LIMIT 10 开始,逐步添加操作符,并使用 KEEP * 查看中间结果。
4. 与 SQL 的对比:虽然部分语法类似,但 ES|QL 不是 SQL。它没有 JOIN(但可通过LOOKUP丰富数据),其管道模型更接近 Shell。
ES|QL语法还在不断的迭代中,整理如有不对 欢迎指出!
查看官方文档:访问 Elastic 官网的 ES|QL 文档,这是最权威的信息源