最近在IEEE TPAMI上刷到了不少关于多模态图像融合的研究,比较亮眼的就有FreeFusion,一种红外与可见光图像融合方法,以及SFINet及改进版SFINet++(见下文)。
这俩属于当前多模态图像融合最具潜力的两类创新方向:与大模型/基础模型结合、解决"未对齐"与"退化"真实难题。如果你打算冲顶会顶刊,完全可以沿着这两个方向深入,比如为新问题找到全新视角,或者用自驱学习机制取代旧有手工范式。
另外还有一些非常值得学习的成果,如果你毫无思路,那我建议你先看看它们。为了节省你查阅的时间,我已经打包整理好了13篇前沿论文,附代码,相信你看着看着idea自然就有了。
全部论文+开源代码需要的同学看文末
FreeFusion: Infrared and Visible Image Fusion via Cross Reconstruction Learning
**方法:**论文提出 FreeFusion 方法,通过跨重建学习解耦融合特征以实现源图像跨模态重建,结合动态交互融合策略构建融合特征与目标语义特征的相关矩阵并强化强相关特征,实现红外与可见光多模态图像的自适应互补信息融合,同时提升下游分割和检测任务性能。
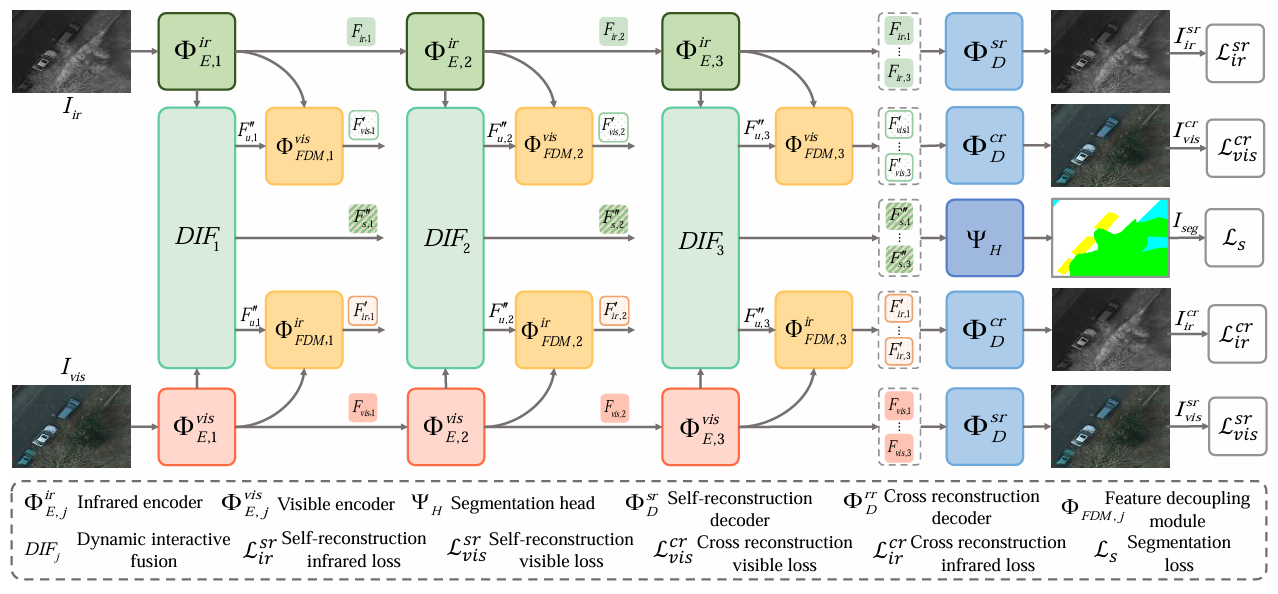
创新点:
-
无需手工设计融合损失,通过跨重建学习解耦融合特征,实现红外与可见光图像的跨模态重建,自适应融合两者互补信息。
-
设计动态交互融合策略,构建融合特征与目标语义特征的相关矩阵,强化强相关特征以解决语义失配问题。
-
共享解码器参数提升模型鲁棒性,融合结果能有效助力下游语义分割和目标检测任务。
A General Spatial-Frequency Learning Framework for Multi-Modal Image Fusion
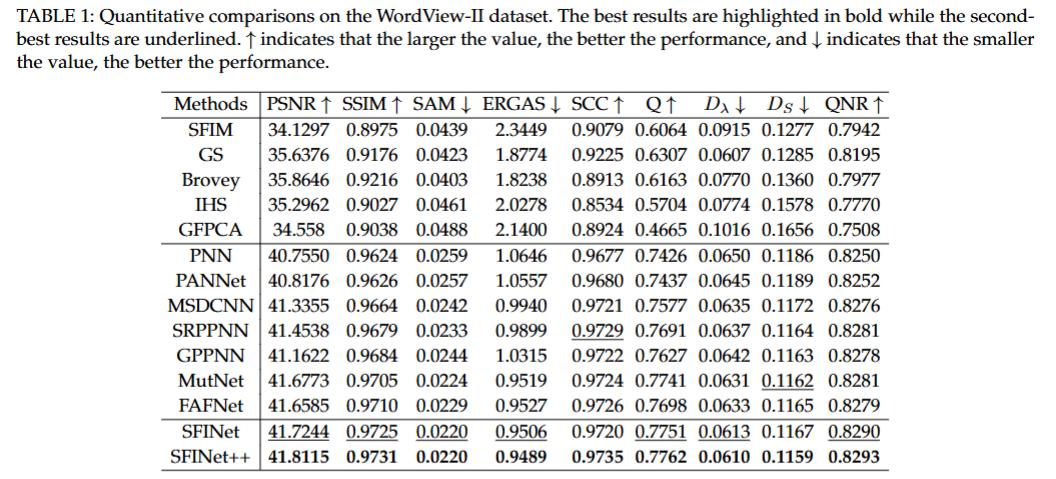
**方法:**论文提出空间 - 频率信息融合网络(SFINet 及其改进版 SFINet++),通过空间域分支、频率域分支及双域交互机制促进信息流动与互补表征学习,结合空间 - 频率联合损失函数,实现全色锐化、深度超分辨率等多模态图像融合任务中高分辨率目标图像的生成。
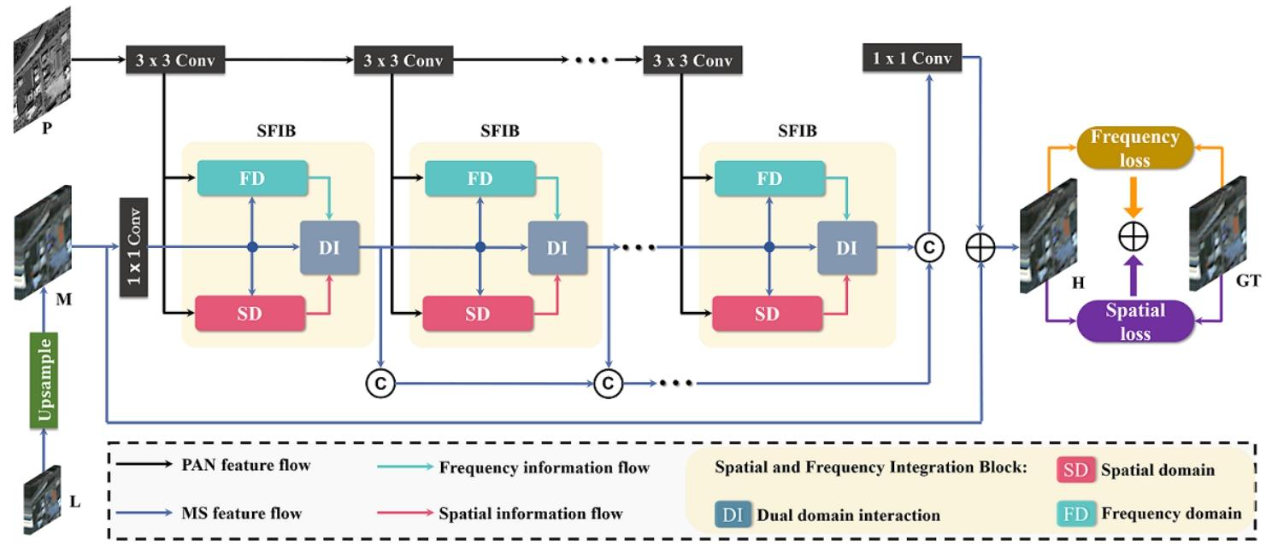
创新点:
-
首次从空间和频率双域探索多模态图像融合,提出SFINet及改进版SFINet++,突破单空间域处理局限。
-
设计核心模块SFIB,含空间、频率双分支及双域交互机制,分别捕捉局部和全局信息并实现互补学习。
-
构建空间-频率联合损失函数,强化高频率成分学习,提升全色锐化、深度超分辨率任务的融合效果。
FS-Diff: Semantic Guidance and Clarity-Aware Simultaneous Multimodal Image Fusion and Super-Resolution
**方法:**论文提出 FS-Diff 方法,以双模态低分辨率图像和语义引导为条件,通过清晰度感知机制、双向特征 Mamba提取全局与跨模态特征,结合改进 U-Net 网络执行随机迭代去噪,在多模态图像融合的同时实现超分辨率,生成含丰富语义和高保真细节的高分辨率融合结果。
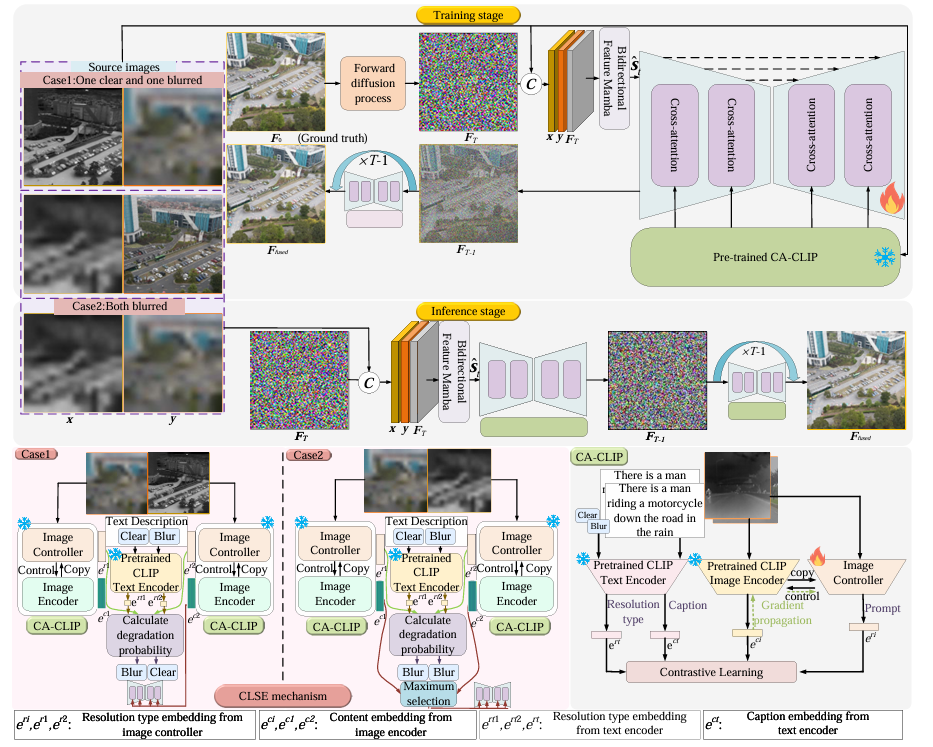
创新点:
-
提出FS-Diff框架,首次实现多倍率下低分辨率多模态图像的同步融合与超分辨率,无需分步处理。
-
引入CLSE机制与CA-CLIP模型,自适应感知图像清晰度并提取语义信息,为融合提供精准语义引导。
-
设计双向特征Mamba(BFM),构建多模态图像联合表征,强化全局与跨模态特征提取能力。
Open-source AI-assisted rapid 3D color multimodal image fusion and preoperative augmented reality planning of extracerebral tumors
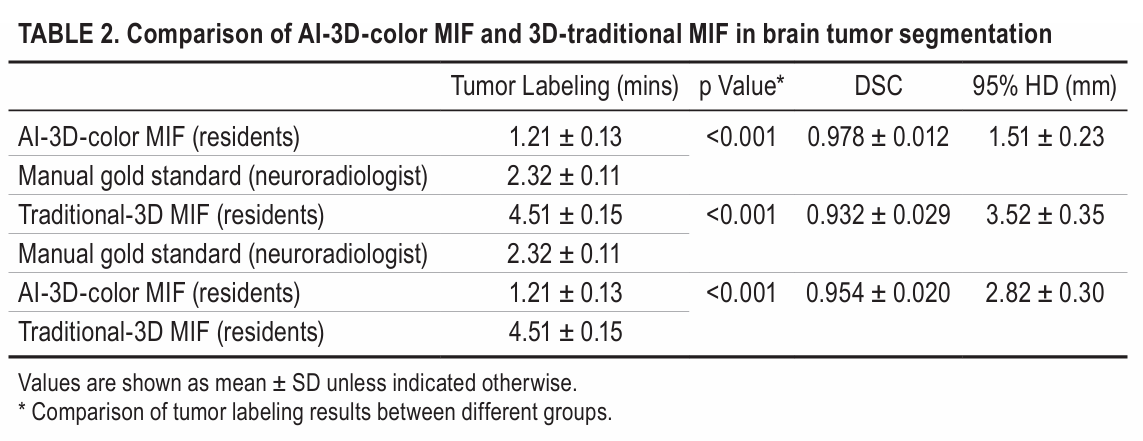
**方法:**研究提出一种基于开源 AI 工具的方法,整合 FastSurfer(AI 脑分区)、Raidionics-Slicer(深度学习肿瘤分割)与 Sina AR 投影技术,实现快速 3D 彩色多模态图像融合,通过彩色编码功能映射和血管关系可视化优化脑外肿瘤术前规划与手术引导,提升手术精准度并降低围手术期风险。
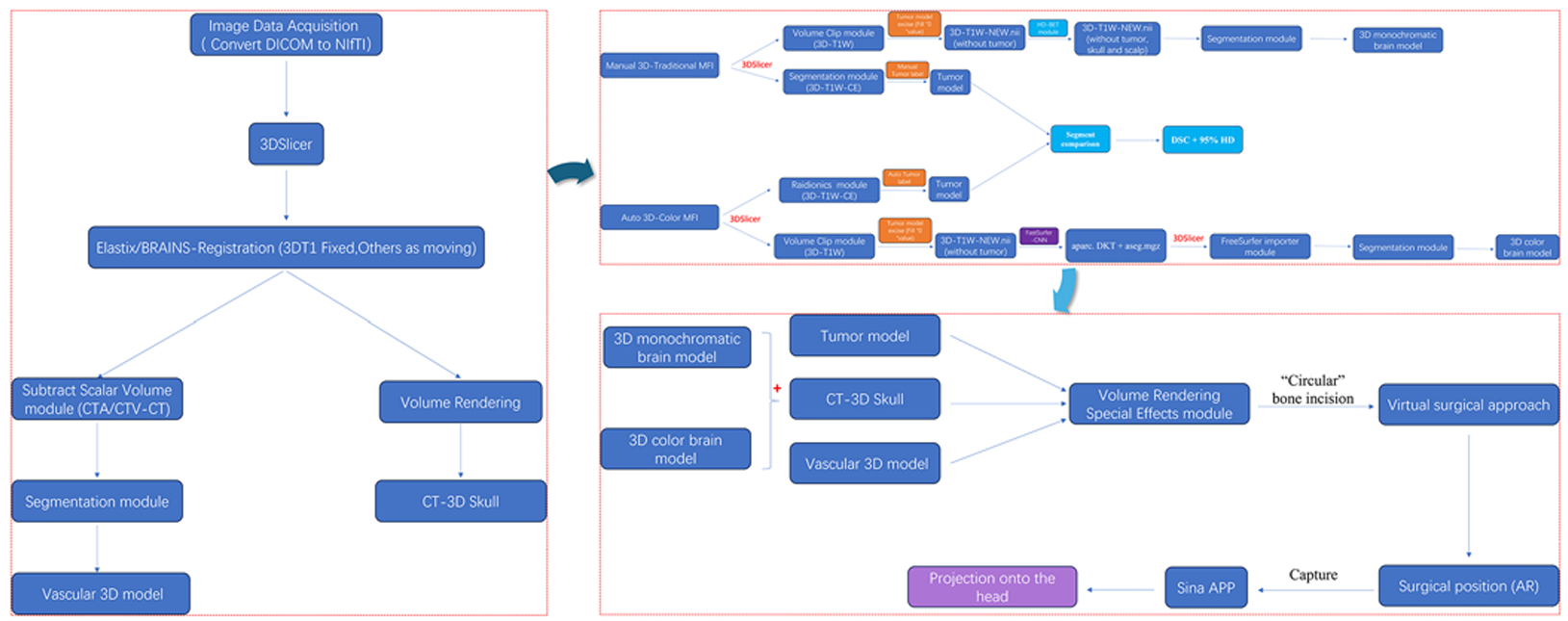
创新点:
-
整合开源AI工具(FastSurfer、Raidionics-Slicer)与AR技术,构建快速3D彩色多模态图像融合工作流,替代传统单色融合方式。
-
借助AI实现快速精准的脑分区与肿瘤分割,大幅缩短处理时间,提升分割准确率(DSC更高、95%HD更小)。
-
通过彩色编码功能映射和血管关系可视化,增强解剖结构理解,优化术前规划与手术引导,降低围手术期风险。
关注下方《学姐带你玩AI》🚀🚀🚀
回复"222"获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏