什么是Elasticsearch?
- Elasticsearch是一个基于Lucence的分布式存储搜索引擎,能从海量数据中快速找到所需内容
- Lucene:Java语言搜索引擎,也就是个jar包,es是基于它做的二次开发
- 结合kibana,Logstash,Beats,也就是ELK技术栈,被广泛用于日志数据分析(将日志数据可视化的展示出来),实时监控(项目的运行情况)等领域

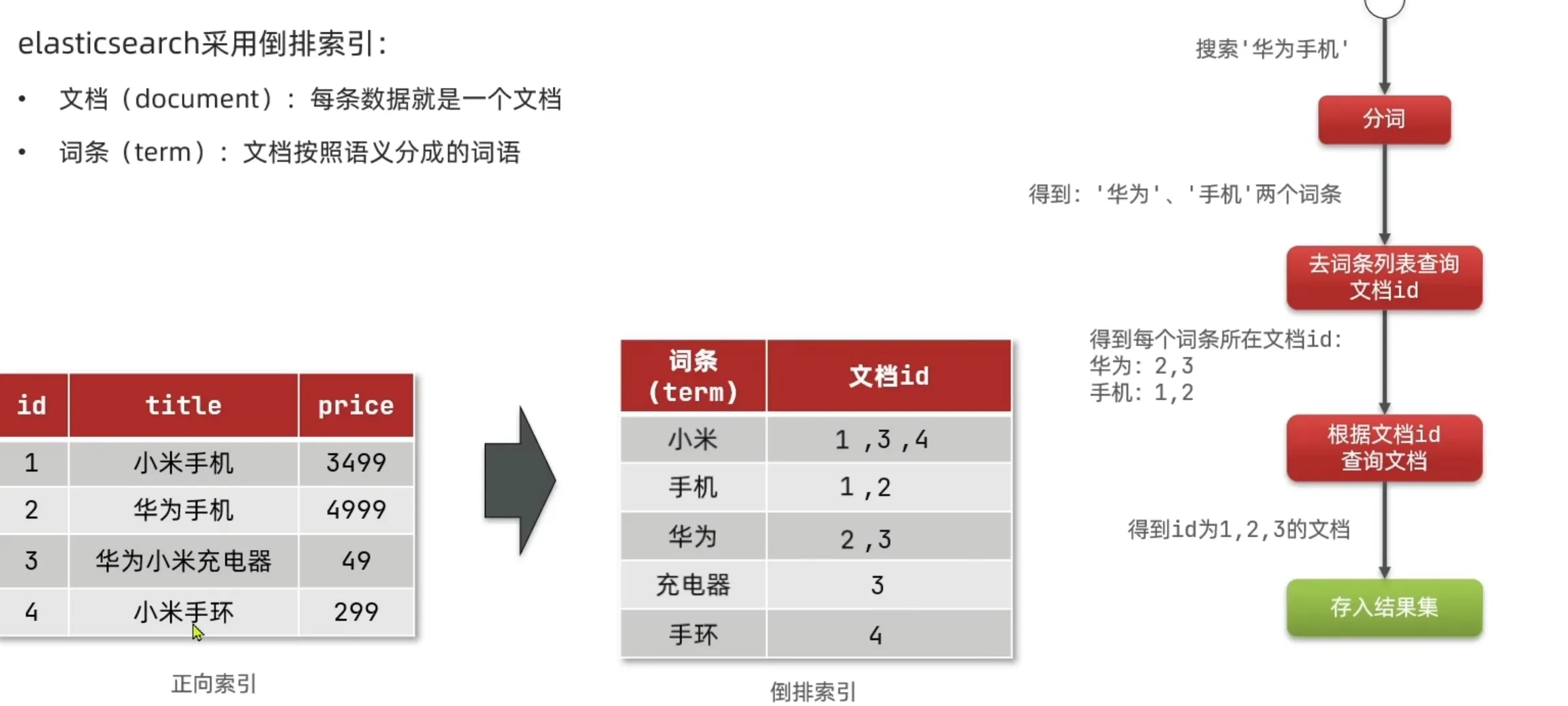
倒排索引
数据库采用正向索引:一般情况下会根据id创建索引,形成B+树,如果根据id检索效率就会比较高
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语------------词条不会重复
ES中相关概念
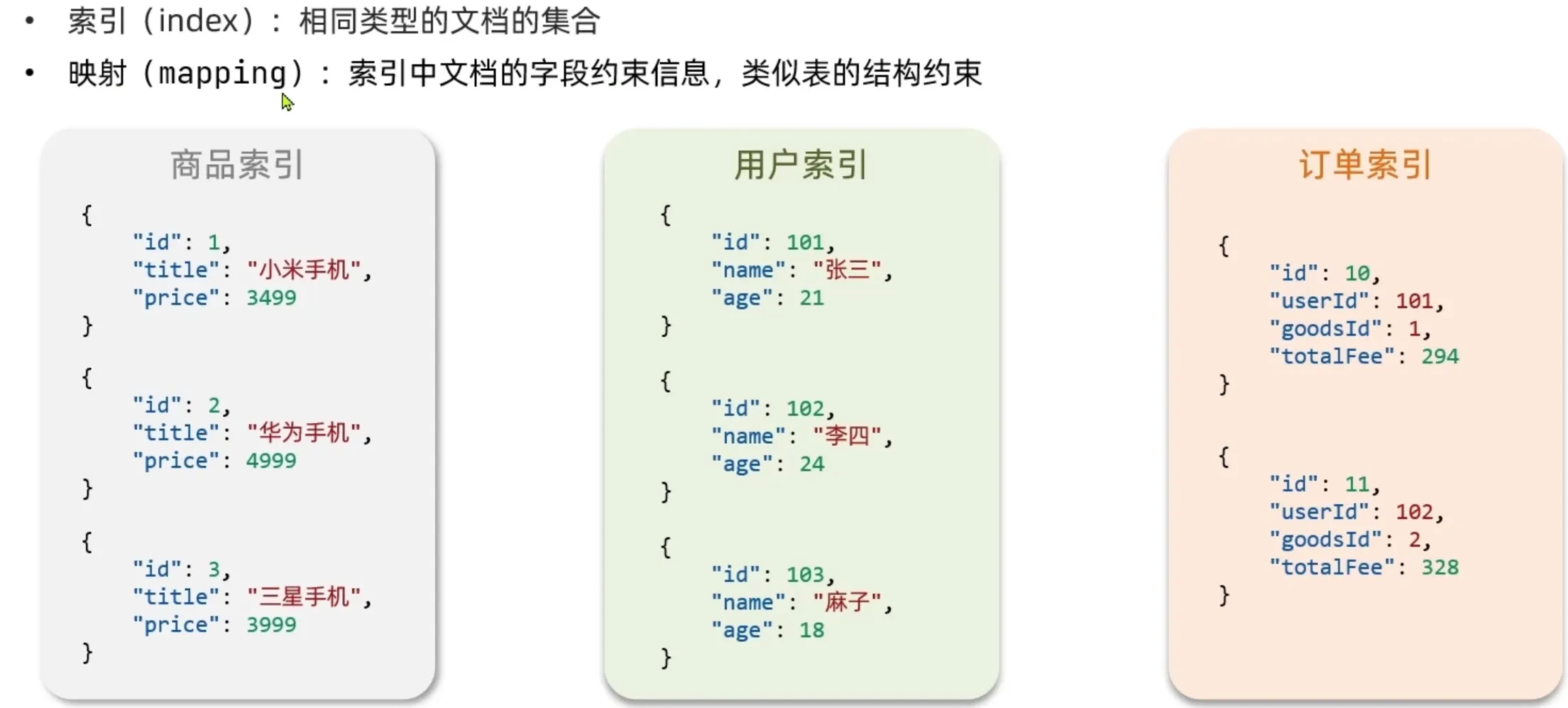
文档

索引,映射
es与数据库关系
- 数据库负责事务类型操作
- es负责海量数据的搜索,分析,计算
索引库操作
mapping映射属性
常见的mapping属性包括:

创建索引库操作

索引库其他操作

不能修改索引库已有的字段,因为之前创建好的倒排索引跟分词会受到干扰,对索引库影响很大。只能添加新的字段。
代码示例
java
PUT /test
{
"mappings": {
"properties": {
"age":{
"type": "integer"
},
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"name":{
"properties":{
"firstName":{
"type":"keyword"
},
"lastName":{
"type":"keyword"
}
}
}
}
}
}
GET /test
DELETE /test
PUT /test/_mapping
{
"properties":{
"height":{
"type":"float"
},
"weight":{
"type":"double"
}
}
}文档操作
新增文档

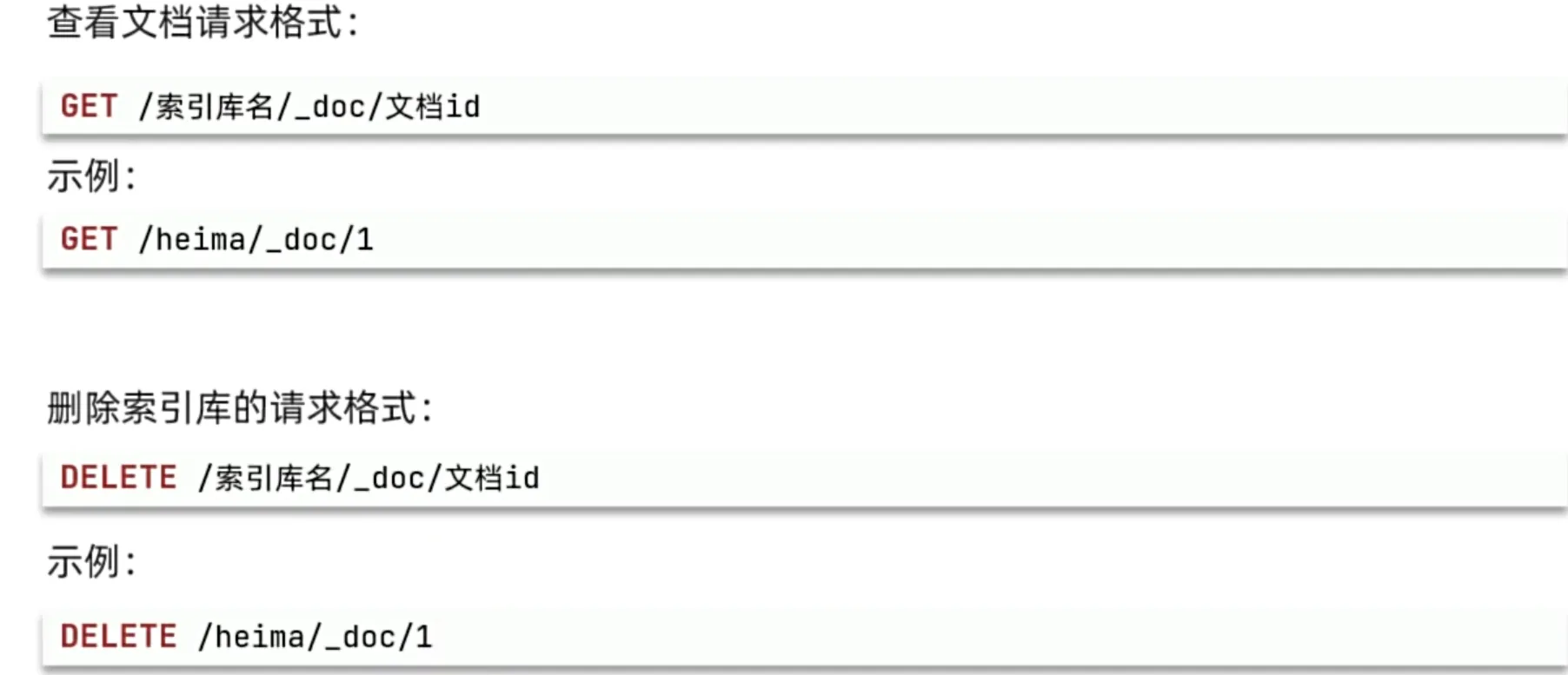
查询、删除文档
修改文档

代码示例
java
POST /test/_doc/1
{
"age":"18",
"height":"180",
"name":{
"firstName":"云",
"lastName":"赵"
}
}
GET /test/_doc/1
DELETE /test/_doc/1
PUT /test/_doc/1
{
"age":"18",
"height":"180",
"name":{
"firstName":"张飞",
"lastName":"张飞"
}
}
POST /test/_update/1
{
"doc": {
"name":{
"firstName":"关羽",
"lastName":"关羽"
}
}
}批量处理


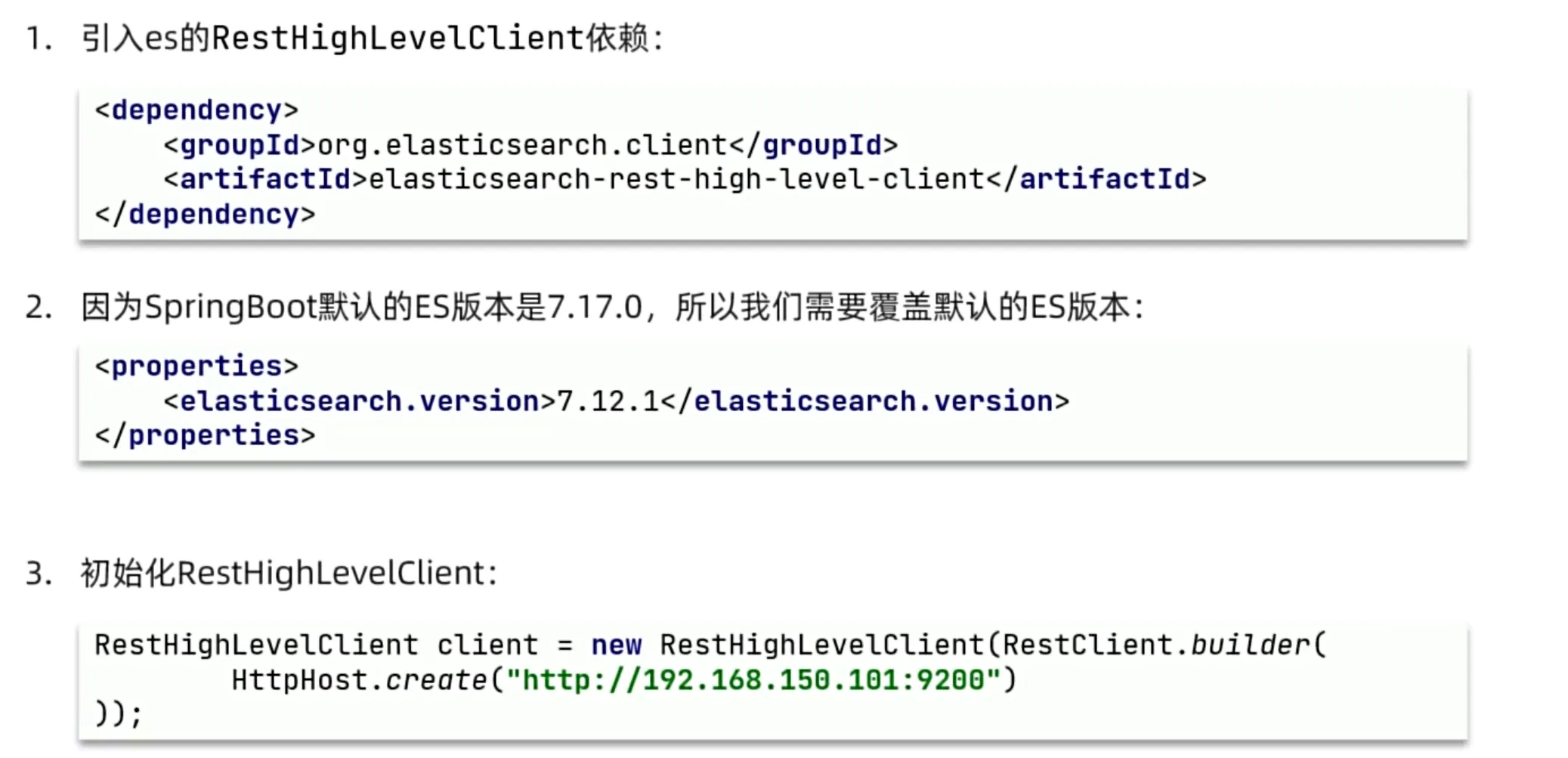
JavaRestClient(Java客户端)
客户端初始化
商品的mapping映射
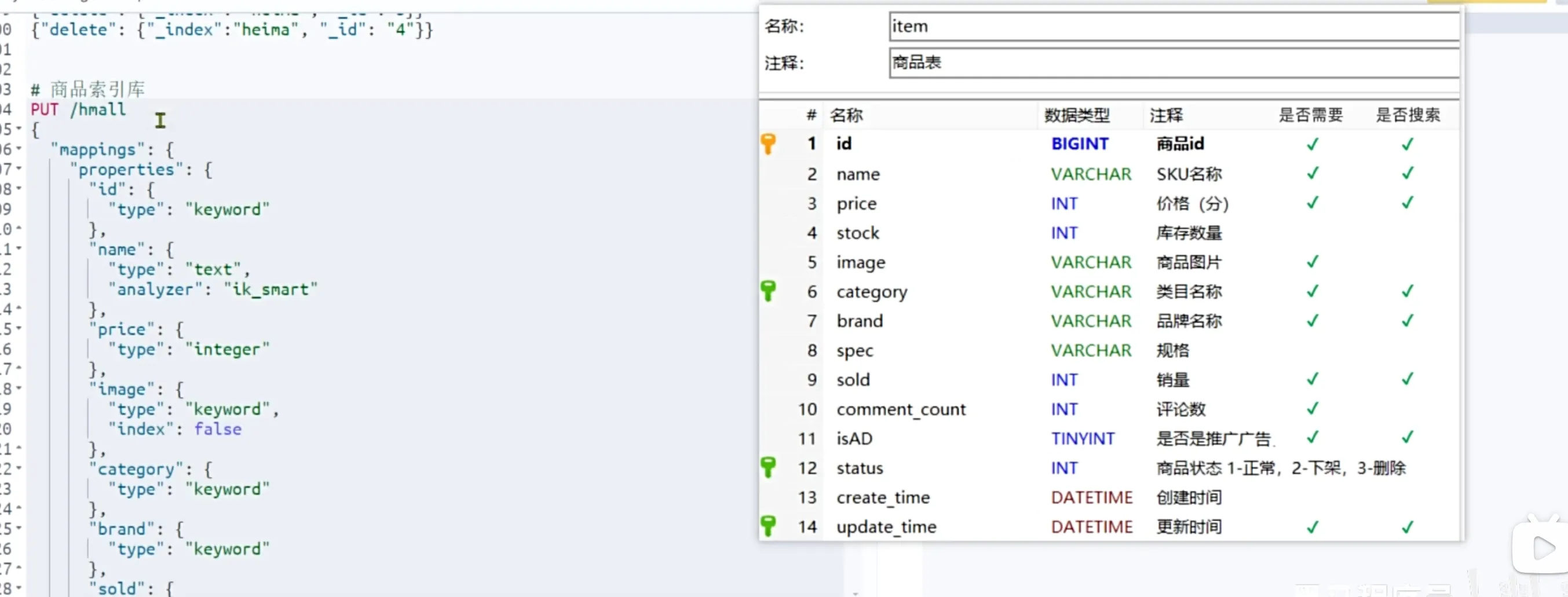
先创建好mapping映射,在Java客户端创建索引库。
客户端索引库操作
创建索引库

删除索引库

查询索引库

客户端文档操作
新增文档

删除文档

查询文档

修改文档(方式一跟新增文档代码一样)

批量新增

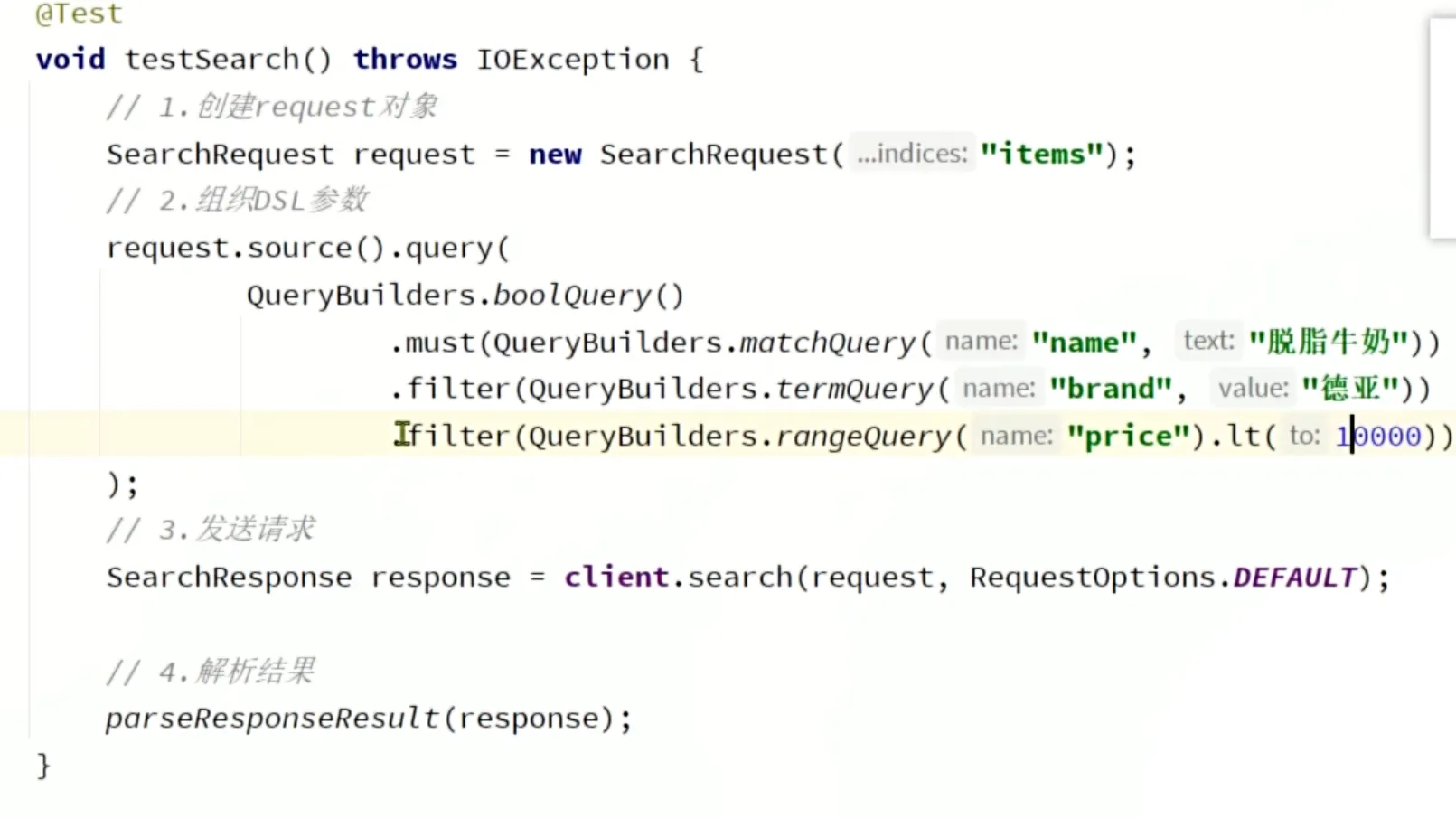
DSL查询
DSL查询分类

快速入门

叶子查询



复合查询

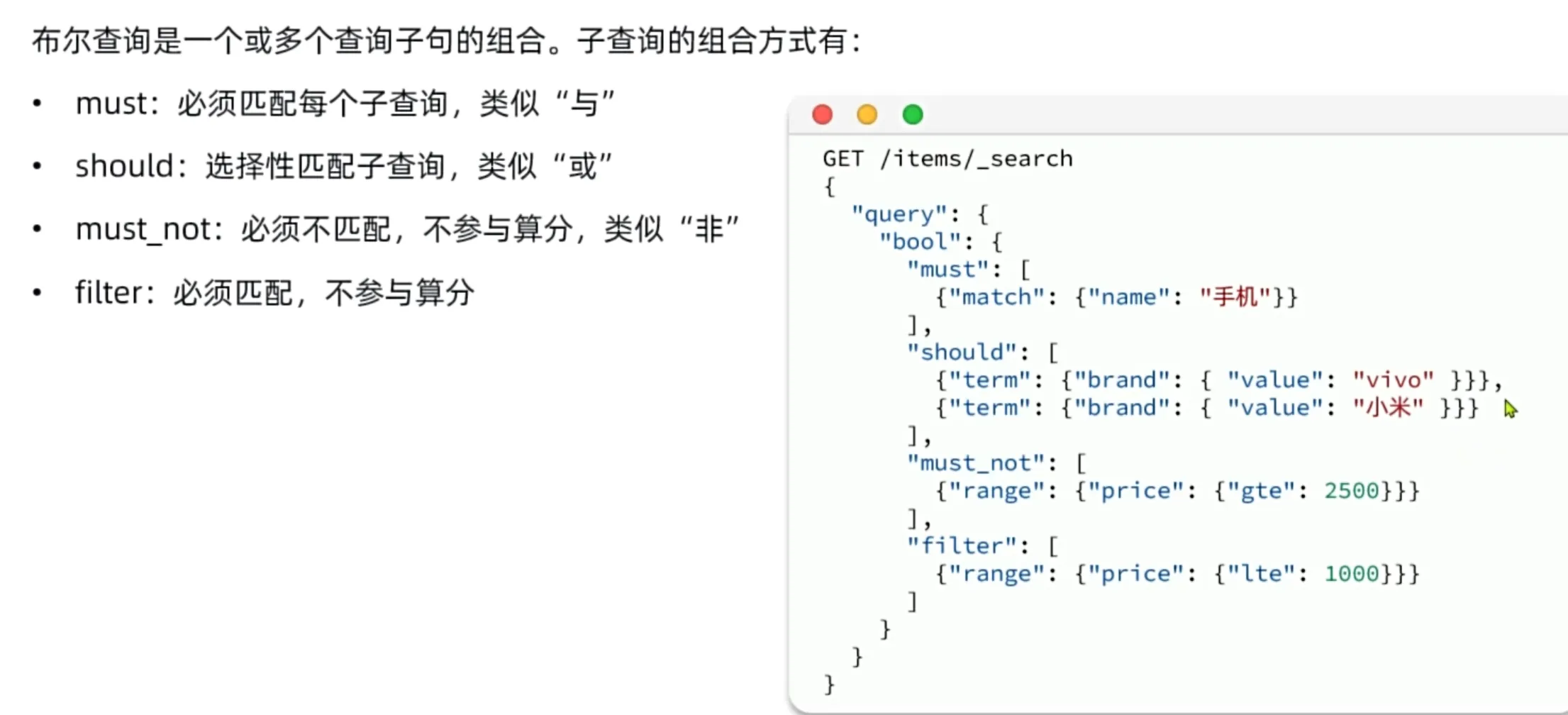
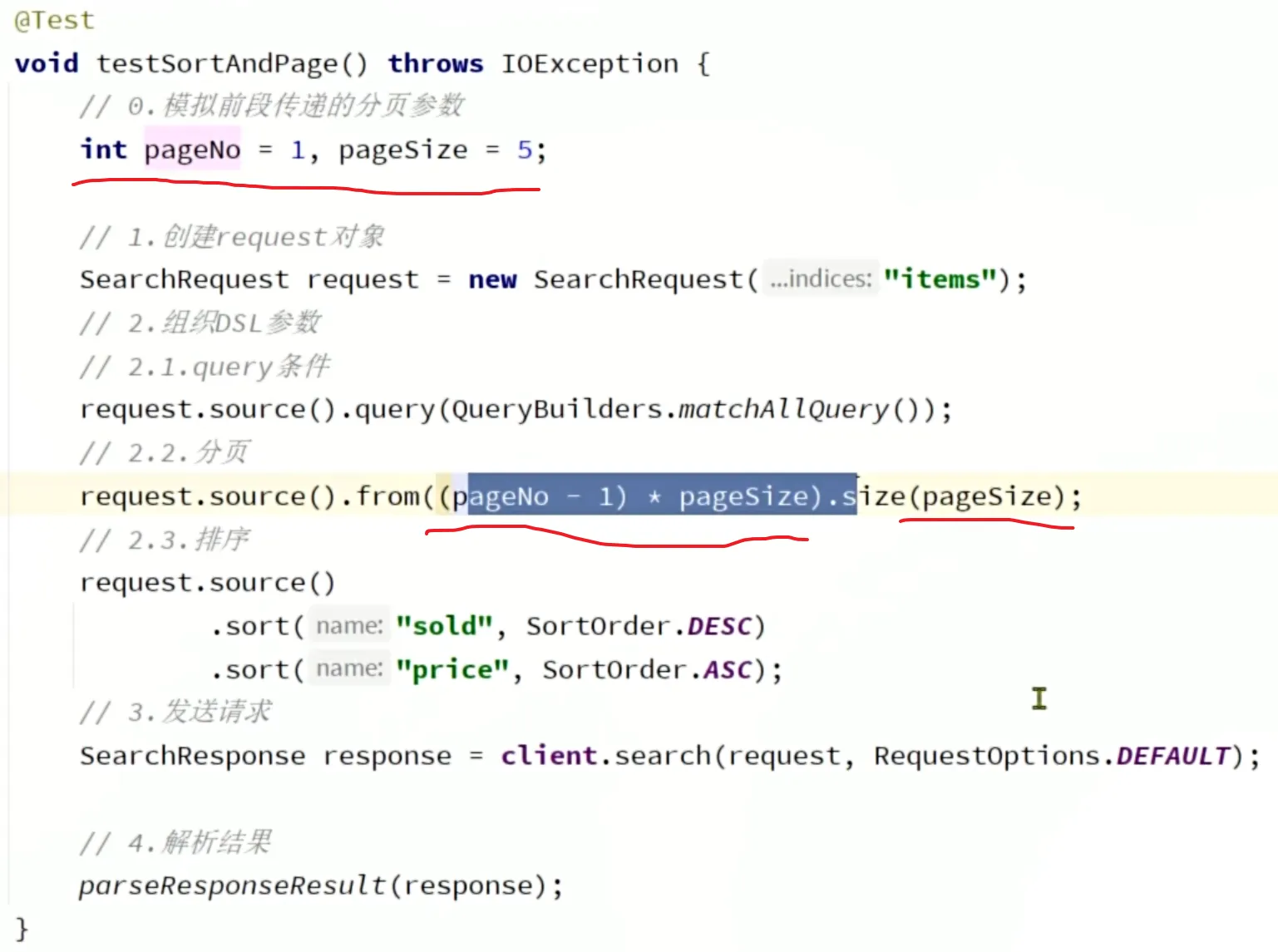
排序和分页
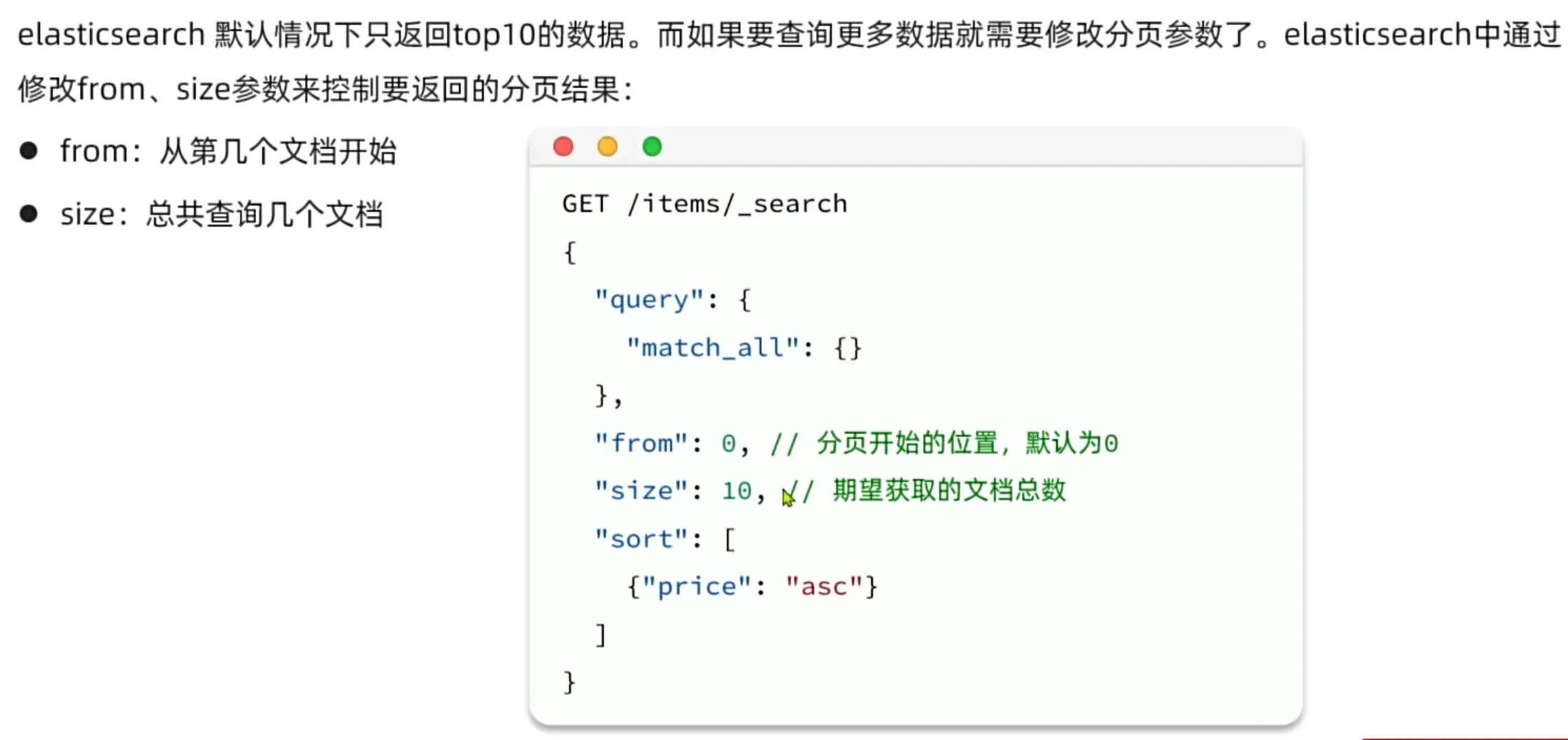
排序:

分页:
深度分页问题

假如我们要查第100页数据,每页查十条,也就是查第990到1000这十条数据。但并不是简单的查到这1000条数据然后返回最后十条,而是把每个分片前1000条数据都拿出来合并到一起排序,选出前1000条然后返回最后十条。当要查询第一万页数据时,数据量极大,可能会导致内存炸裂。
解决方案:

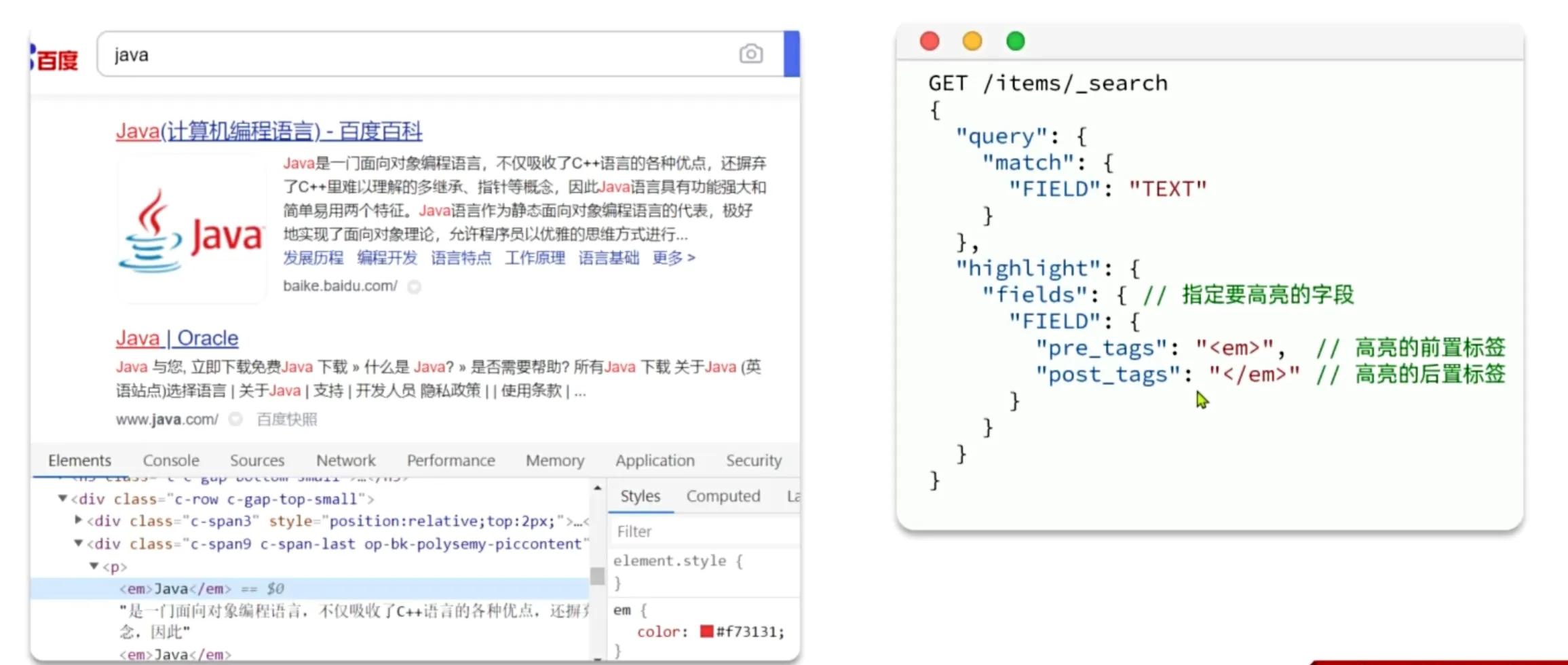
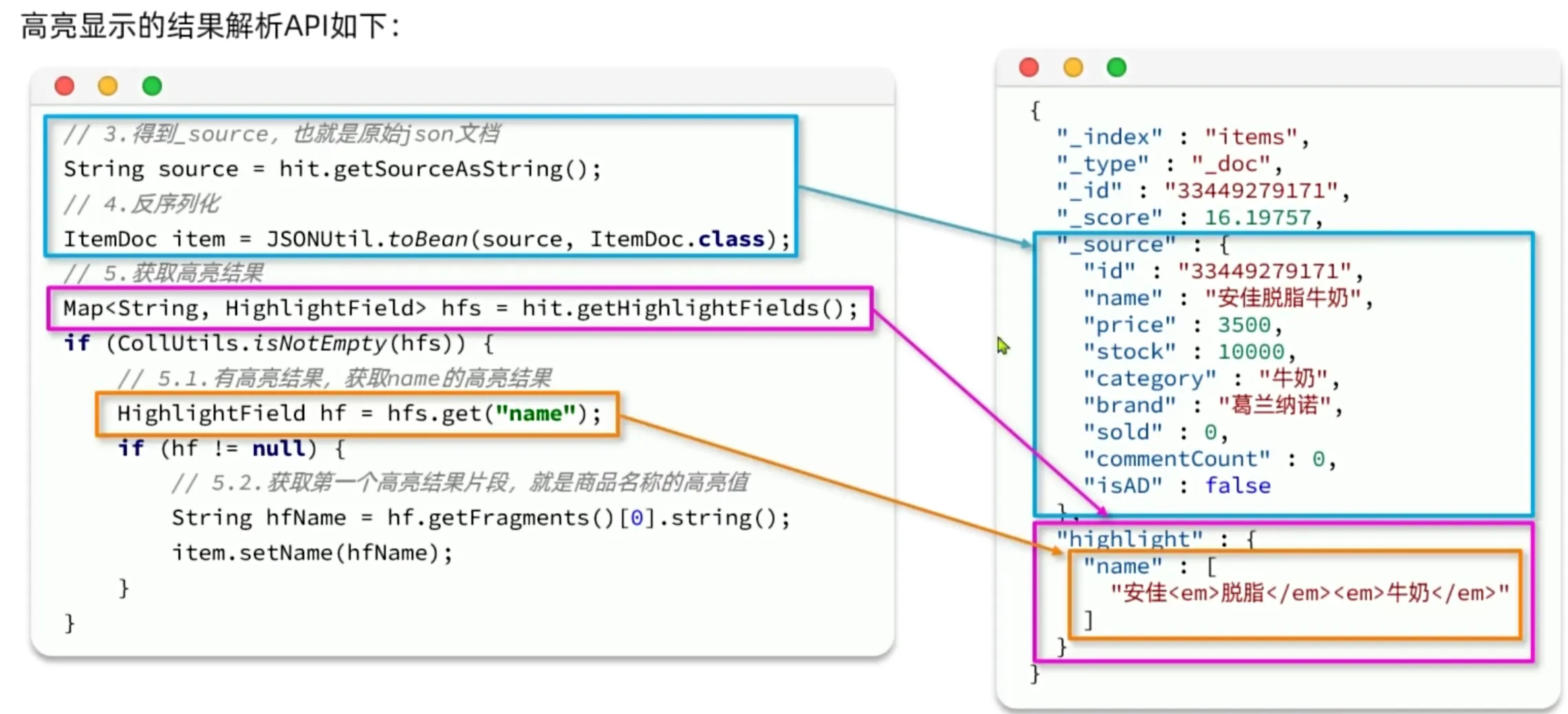
高亮显示
再搜索结果中把搜索关键字突出显示
JavaRestClient查询
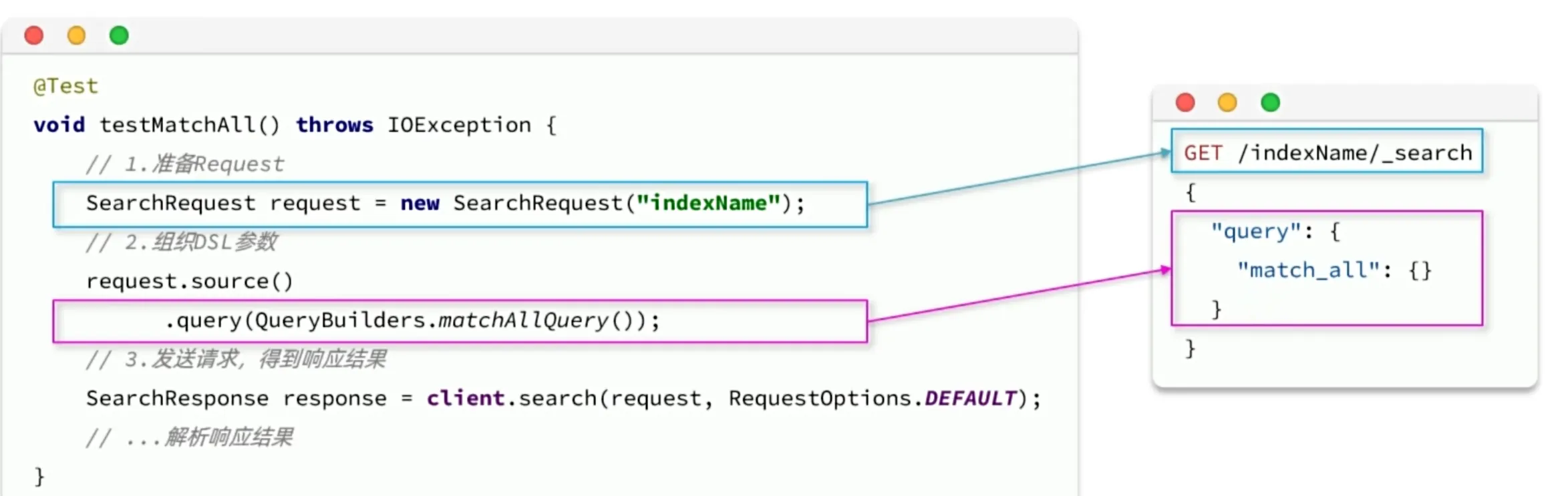
快速入门
构建并发起请求
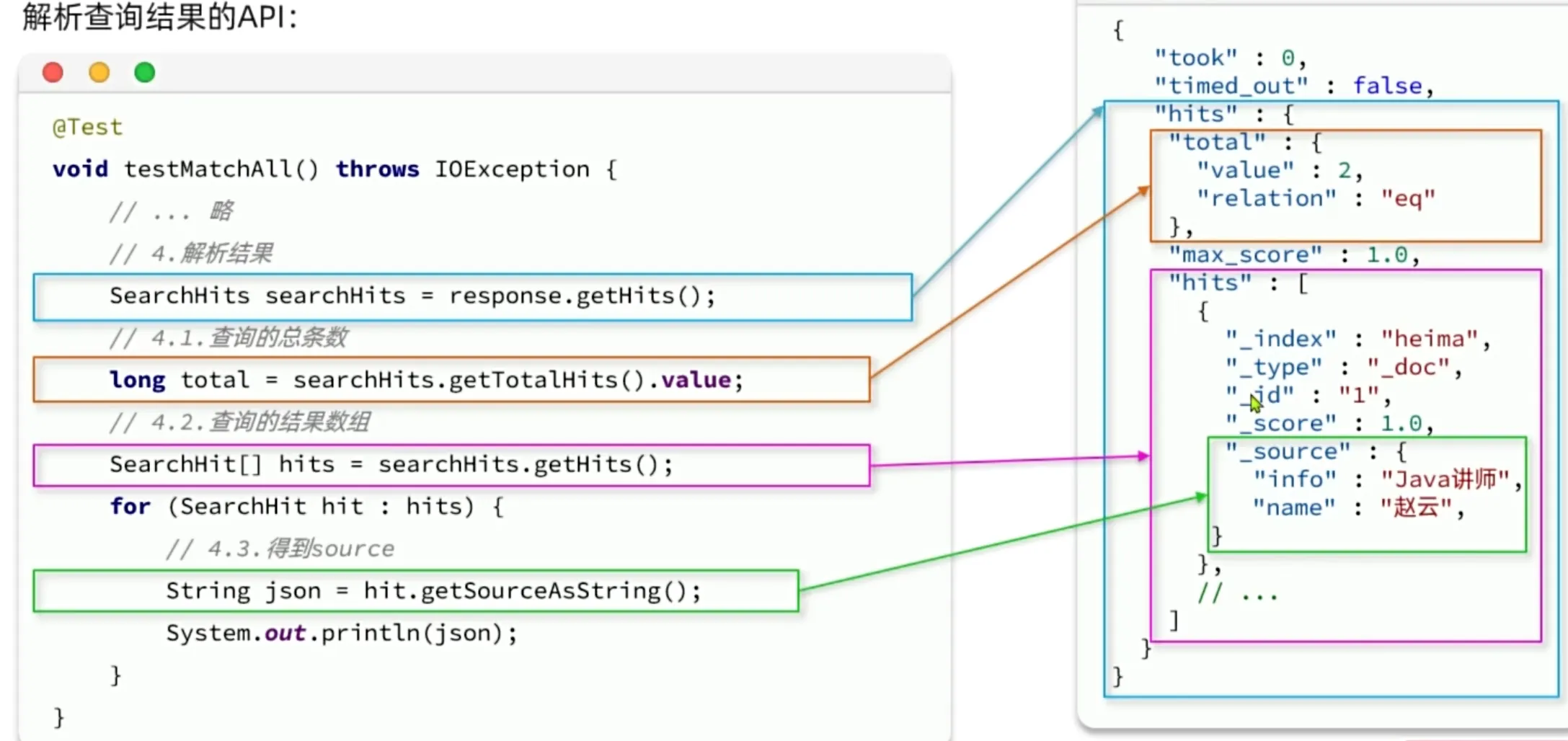
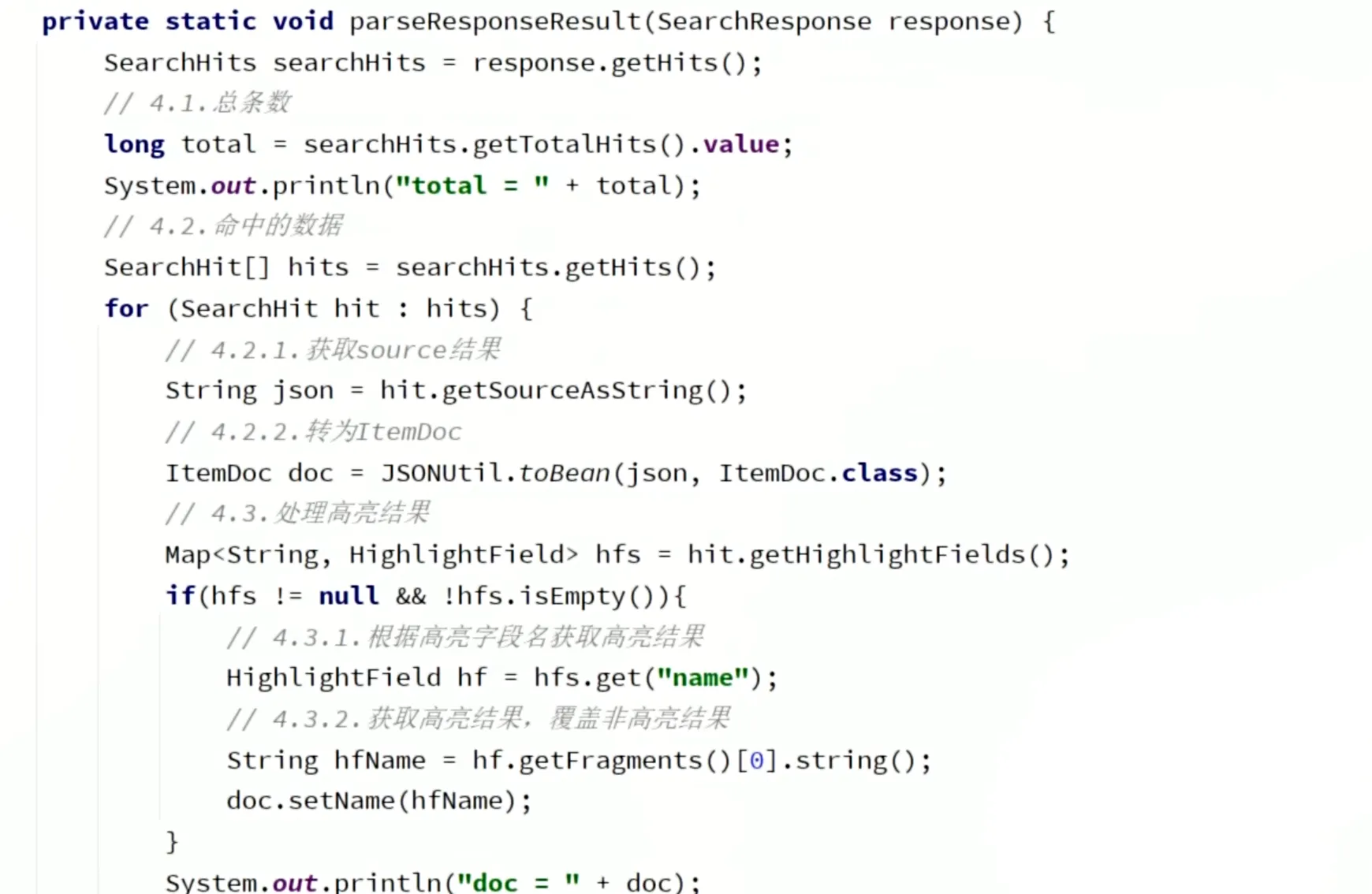
解析查询结果
构建查询条件

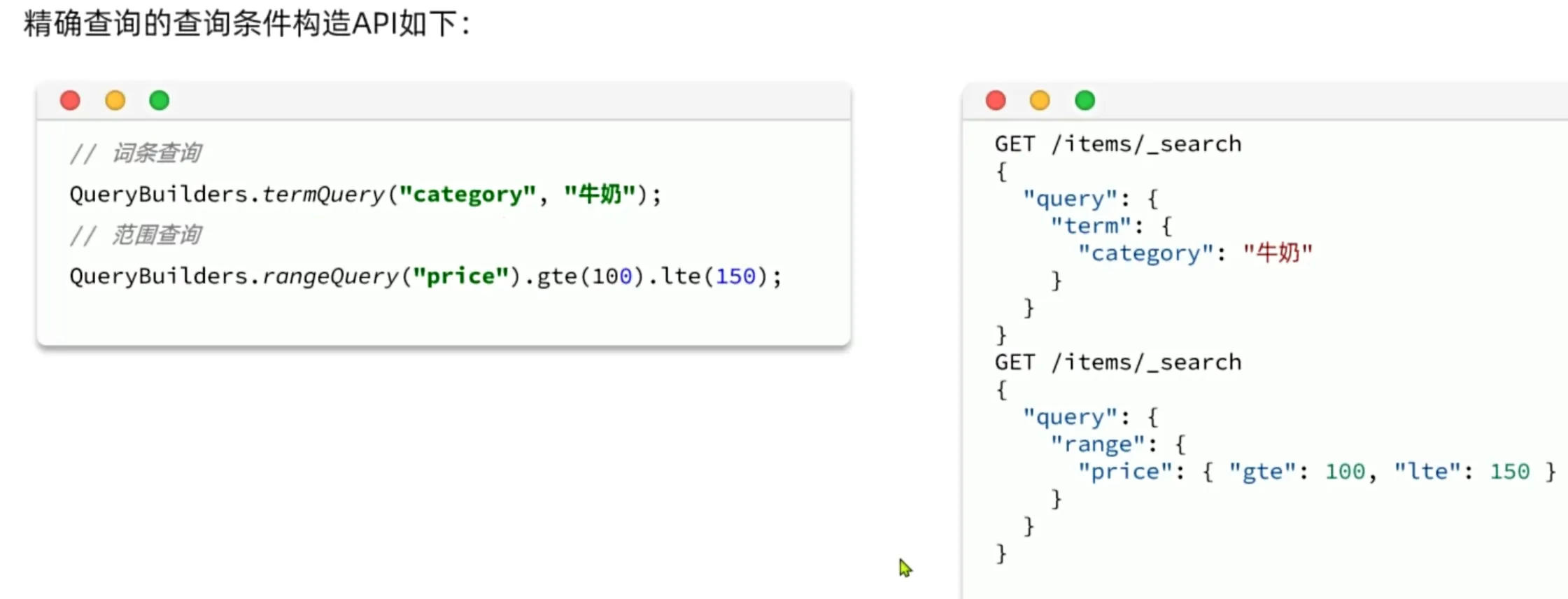
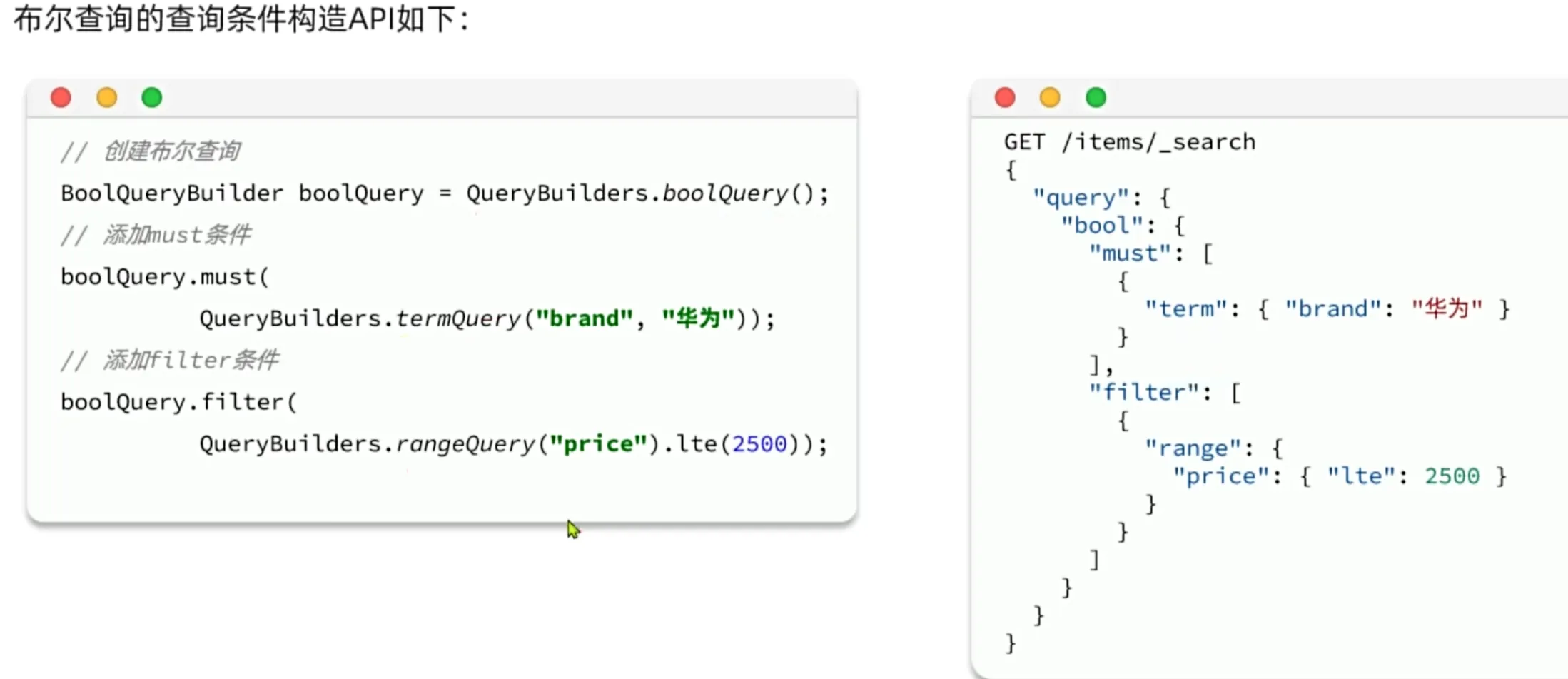
示例:
排序和分页

示例:
高亮显示

示例:

下期我们讲ES在SpringBoot中的整合。