TL;DR
- 场景:存量 IBM MQ/老系统并存,新系统要开源、可运维、可扩展且满足一致性与可靠性
- 结论:RabbitMQ 适合"可靠优先的业务解耦",RocketMQ 适合"交易/事务/顺序消息",Kafka 适合"数据管道/日志/流式处理"
- 产出:给出选型维度、三者能力边界、以及落地常见故障的定位与修复清单
中间件选型
在传统金融机构、银行、政府机构等关键领域,仍有许多运行多年的老系统在使用IBM MQ(原WebSphere MQ)等商用消息中间件产品。这些系统通常具有以下特点:
- 系统建设时间较早(10-20年前)
- 采用集中式架构设计
- 对事务一致性和可靠性要求极高
- 与IBM大型机等传统设备深度集成
- 受限于合规要求和技术惯性,升级换代周期较长
当前业界主流的开源消息中间件已形成较为成熟的生态体系,主要包括以下产品:
-
ActiveMQ
- 最老牌的开源消息中间件
- 支持JMS规范
- 适合中小规模应用场景
- 典型应用:企业内部系统集成
-
RabbitMQ
- 基于AMQP协议
- 轻量级、易部署
- 丰富的插件生态
- 典型应用:电商订单系统、支付系统
-
RocketMQ
- 阿里开源产品
- 高吞吐、低延迟
- 强大的事务消息功能
- 典型应用:金融交易系统、物流跟踪
-
Kafka
- 分布式流处理平台
- 超高吞吐量(百万级TPS)
- 持久化日志存储
- 典型应用:大数据分析、实时监控
-
ZeroMQ
- 轻量级网络通信库
- 无中间代理架构
- 极低延迟
- 典型应用:高频交易、物联网
其中RabbitMQ、RocketMQ和Kafka在互联网行业应用最为广泛:
- RabbitMQ在中小型企业中占据主导地位
- RocketMQ在金融科技领域表现突出
- Kafka则在大数据场景几乎形成垄断地位
这些开源产品通过持续的版本迭代,在可靠性、性能和功能丰富度方面已经达到甚至超过传统商业产品的水平。

选取原则
首先,产品必须是开源的,这一点至关重要。开源不仅意味着源代码公开透明,更重要的是赋予了用户自主权。当在队列使用过程中遇到BUG时,开发团队可以直接修改源代码快速解决问题,而不必被动等待原开发者的版本更新。比如像RabbitMQ这样的开源消息队列,用户社区中经常会有开发者贡献补丁和优化方案。此外,开源软件通常采用MIT、Apache等宽松的许可证,允许自由使用、修改和分发,这对企业级应用尤为重要。
其次,产品需要是近几年比较流行的技术方案。流行度可以从几个维度来衡量:GitHub上的star数量、Stack Overflow上的讨论热度、技术大会的提及频率等。一个活跃的社区意味着当遇到问题时,开发者可以通过论坛、issue追踪系统等渠道快速获得帮助。以Kafka为例,作为当前最流行的消息队列之一,其社区每天都会产生大量的问题讨论和解决方案。流行度还带来另一个优势:与周边系统的兼容性更好。主流的CI/CD工具、监控系统、云平台通常都会优先支持这些热门产品。
最后,作为专业的消息队列系统,必须满足以下几个核心特性:
-
消息传输的可靠性:需要提供完善的消息持久化机制,包括磁盘存储、副本备份等。例如,可以配置消息在写入时同步落盘,或者设置消息确认机制(ACK),确保即使在系统崩溃的情况下也不会丢失消息。
-
集群支持能力:要支持横向扩展,能够通过增加节点来提升处理能力。同时要具备高可用特性,当某个节点故障时,其他节点可以自动接管服务。比如RocketMQ的多副本机制,可以在主节点宕机时自动切换到从节点。
-
优异的性能表现:要能够满足业务的高并发需求,包括高吞吐量和低延迟。具体指标可以根据业务场景来设定,比如支持每秒10万条消息的处理能力,端到端延迟控制在毫秒级别。性能优化方面可以考虑采用零拷贝技术、批量发送等方案。
此外,优秀的生产级消息队列还应该具备完善的管理控制台、丰富的客户端支持(多种编程语言)、灵活的消息路由策略等特性,以满足不同业务场景的需求。
RabbitMQ
RabbitMQ 最初是由 LShift 公司开发,后被 SpringSource 收购,现归属于 Pivotal 公司。它的设计初衷是为了解决电信领域对高可靠性消息通信的需求,是最早实现 AMQP(Advanced Message Queuing Protocol) 标准的开源消息中间件之一。在 AMQP 1.0 标准发布前,RabbitMQ 就已经成为该协议的事实参考实现。
优点详解:
-
轻量高效:
- 安装包仅几十MB大小,启动快速(秒级)
- 单机部署只需运行一个 Erlang 节点进程
- 提供 Docker 镜像,支持一键部署
- 示例:在 Ubuntu 上安装仅需
apt-get install rabbitmq-server
-
灵活的路由机制:
- 提供四种交换机类型:
- Direct Exchange:精确匹配 routing key
- Fanout Exchange:广播到所有绑定队列
- Topic Exchange:支持通配符匹配
- Headers Exchange:基于消息头匹配
- 支持自定义插件实现特殊路由逻辑
- 示例场景:电商系统可用 Topic Exchange 实现订单消息按地区分发
- 提供四种交换机类型:
-
多语言支持:
- 官方维护 Java、.NET、Python 等主流语言客户端
- 社区提供 PHP、Go、Node.js 等 30+ 语言支持
- 每种语言都提供连接池、自动重连等生产级特性
缺点详解:
-
消息堆积问题:
- 当队列积压超过 10 万条消息时,吞吐量会下降 50% 以上
- 内存占用随消息堆积线性增长,可能触发 Erlang GC 导致延迟
- 解决方案:需要设置合理的 TTL 和死信队列
-
性能局限:
- 基准测试数据(单节点):
- 持久化消息:约 5万-8万 TPS
- 非持久化消息:约 10万-15万 TPS
- 对比 Kafka 可达到百万级 TPS
- 适用场景:适合对可靠性要求高于性能的场景
- 基准测试数据(单节点):
-
Erlang 技术栈限制:
- 插件开发需要掌握 Erlang 语言
- 社区贡献的 Java/Python 插件运行在 Erlang 外部节点,性能损耗大
- 核心功能修改需重新编译 Erlang 代码,维护成本高
典型应用场景:支付系统异步通知、跨系统数据同步等对消息可靠性要求高但吞吐量适中的业务场景。
RocketMQ
RocketMQ 是一个由阿里巴巴开源的高性能、高可用的分布式消息中间件,采用 Java 语言实现。它借鉴了 Kafka 的优秀设计理念,并在其基础上进行了诸多创新和改进。RocketMQ 主要应用于以下典型场景:
- 顺序消息处理(如订单状态变更)
- 分布式事务消息(如电商交易系统)
- 实时流计算(如用户行为分析)
- 消息推送(如APP通知)
- 日志流处理(如系统监控)
- Binlog分发(如数据库同步)
在阿里巴巴双11全球购物狂欢节中,RocketMQ 成功支撑了每秒百万级的消息处理,经受了海量并发场景的严苛考验,其稳定性和性能表现有目共睹。
主要优点:
-
功能全面性
- 支持发布/订阅和点对点模式
- 提供消息顺序保证、事务消息、定时消息、消息回溯等高级特性
- 完善的权限控制和消息轨迹追踪
-
开发友好性
- 采用 Java 实现,源码结构清晰(如核心模块包括namesrv、broker、client等)
- 支持通过 SPI 机制进行扩展
- 社区提供了丰富的示例代码(如顺序消息生产者的实现示例)
-
性能表现
- 针对电商场景特别优化(如消息堆积处理能力)
- 平均响应时间在 3ms 以内
- 单机可支持 10W+ TPS,集群模式下可达百万级吞吐量
- 性能基准测试显示比 RabbitMQ 高约10倍
主要缺点:
-
生态整合局限
- 与部分监控系统(如 Prometheus)的集成需要自行开发适配器
- 缺乏官方提供的 Kafka 协议兼容层
- 部分云平台(如 AWS)的托管服务支持不够完善
-
运维复杂度
- 多副本同步机制配置较为复杂
- 客户端SDK版本兼容性需要特别注意
Kafka
优点:
- 高可靠性:Kafka采用分布式架构设计,通过多副本机制保证数据不丢失,在节点故障时能自动进行故障转移,满足金融、电信等对数据可靠性要求严格的行业需求
- 卓越的稳定性:经过LinkedIn、Uber等大型互联网公司多年生产环境验证,能持续稳定处理海量数据,平均无故障时间(MTBF)可达99.99%
- 丰富的功能特性:支持精确一次(Exactly-once)语义、事务消息、消息回溯等高级功能,满足从简单消息队列到复杂流处理的各种应用场景
- 优异的生态兼容性:与Hadoop、Spark、Flink等大数据生态深度集成,提供原生的Connector支持,是构建数据管道(Data Pipeline)的首选方案
- 出色的性能表现:单机可支持10万级TPS,集群可轻松扩展至百万级TPS,满足互联网级高并发需求
技术特性详解:
-
高效可伸缩架构:
- 采用分区(Partition)设计实现水平扩展,单个Topic可分布在多个Broker上
- 通过消费者组(Consumer Group)机制实现消费能力的线性扩展
- 示例:某电商平台双11期间通过动态增加Broker节点,将处理能力从50万TPS提升至200万TPS
-
持久化存储设计:
- 消息默认保留7天(可配置),支持基于时间和大小的保留策略
- 采用顺序读写+页缓存技术,磁盘IO性能接近内存访问速度
- 应用场景:用户行为日志分析场景可回溯任意时间点的消息数据
-
副本与容错机制:
- 支持配置多副本(Replica),通常设置为3副本确保高可用
- ISR(In-Sync Replicas)机制保证数据一致性
- 故障恢复时间通常在秒级,对业务透明
性能表现:
- 基准测试表明,在标准服务器配置(32核/64G内存/SSD)下:
- 不压缩场景:单Broker可处理约80万TPS
- 开启Snappy压缩:单Broker可达200万TPS
- 集群模式下:可线性扩展至千万级TPS
- 典型延迟表现:
- 生产端延迟:99%在10ms内
- 消费端延迟:批量处理场景下可能达到100-500ms
- 不适合场景:需要毫秒级响应的实时交易系统(如证券交易)
开发语言优势:
- Java/Scala实现充分利用JVM生态,便于与主流大数据技术栈集成
- 批处理优化:
- 采用"消息集"(Record Batch)减少网络开销
- 默认批处理大小16KB,可根据业务调整
- 异步处理优势:
- 生产端支持异步发送+回调机制
- 消费端采用拉(Pull)模式,避免推送带来的资源浪费
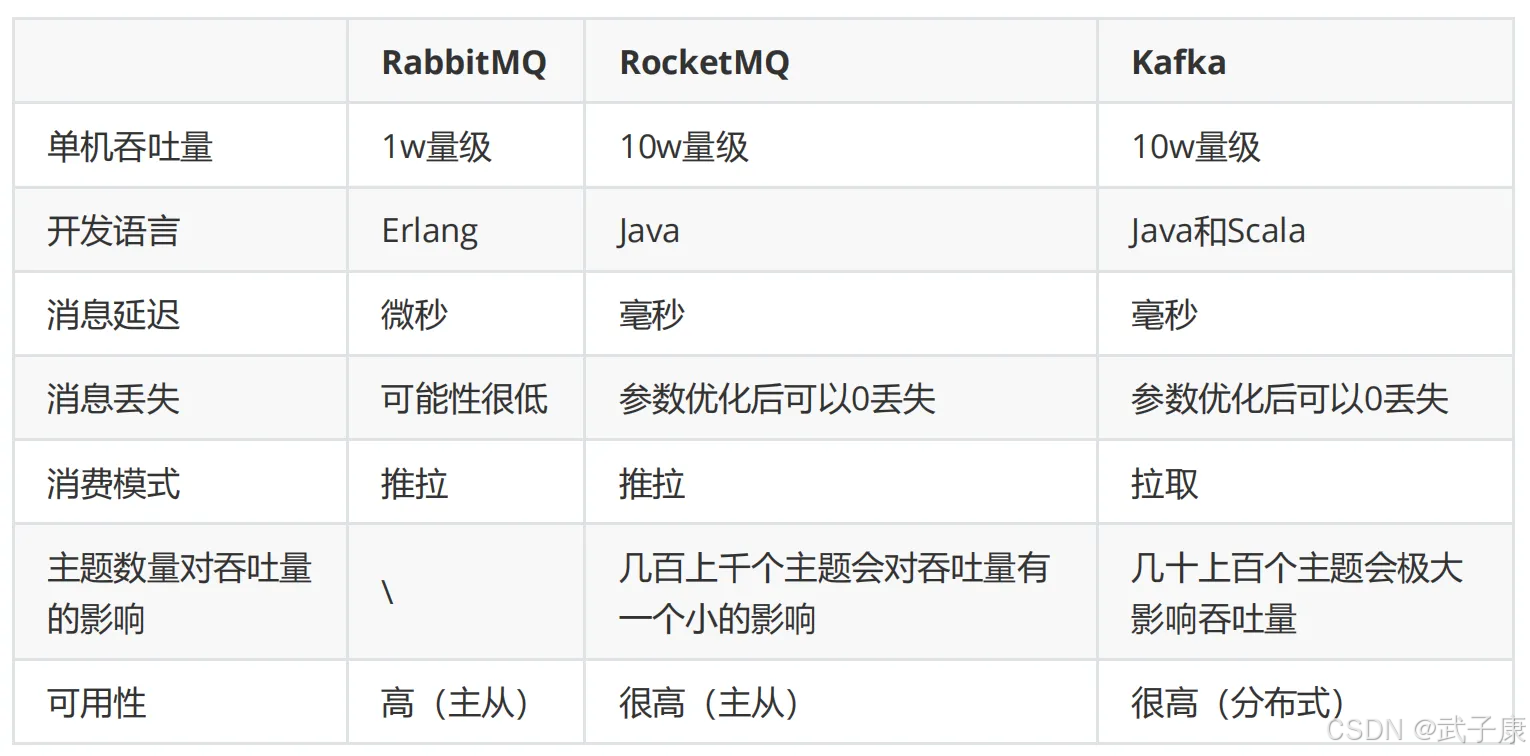
整体对比
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| RabbitMQ 吞吐突然下降、延迟抖动 | 队列堆积导致内存压力、触发内存/磁盘告警;大量 unacked;消费者 prefetch 过大或过小 | 管控台看 queue depth / unacked;rabbitmq-diagnostics status/告警状态;节点内存、磁盘水位降低 降低单队列堆积:拆队列/分片;设置 TTL+DLX;优化消费者并发与 basic.qos;增加节点并做队列类型与镜像策略评估;确保磁盘与页缓存健康 |
| RabbitMQ 连接大量断开/频繁重连 | 心跳超时、连接数过多、负载均衡/防火墙空闲连接回收 | 客户端日志看 heartbeat/timeout;RabbitMQ 连接数与 channel 数;网络设备日志 统一心跳与超时;连接池复用;限制 channel 滥用;调大连接追踪与 OS fd;对 LB/防火墙配置 idle timeout |
| RocketMQ 发送超时/偶发不可用 | NameServer 路由不一致、Broker 压力/GC、磁盘刷盘抖动、网络抖动 | Producer 端超时栈;Broker/NameServer 日志;看 Topic 路由与 Broker 负载 确保 NameServer 高可用与一致部署;Broker 分盘与参数优化;限流与批量发送;隔离大消息;压测并按业务峰值扩容 |
| RocketMQ 消费停滞、堆积快速增长 | 消费者线程被阻塞(外部依赖慢)、重试风暴、消费位点推进异常 | Consumer 端线程栈/RT;重试队列与 DLQ;Broker 消费堆积与位点 将外部依赖异步化/隔离;设置重试退避与最大重试;幂等与去重;按 topic/queue 维度扩容消费者 |
| Kafka Consumer Lag 持续上升 | 分区数不足、消费者组扩缩容导致 rebalance 抖动、下游处理慢、批量参数不匹配 | kafka-consumer-groups 看 lag;观察 rebalance 频率与处理 RT;Broker/JMX 指标 增加分区并均衡 key;优化 consumer 处理链路与批量;控制 rebalance(静态成员/合理 session/poll);隔离慢消费与重试主题 |
| Kafka ISR 缩小/Under Replicated Partitions 增多 | Broker I/O 或网络瓶颈、磁盘抖动、复制跟不上 | 监控 URP/ISR;Broker 日志;磁盘延迟与网络丢包 升级磁盘与网络;调整副本与 acks/复制参数;做容量规划;热点分区拆分与限流 |
| 选型后"功能满足但运维成本爆炸" | 只按特性选型,忽略可观测性、权限治理、升级策略、故障演练 | 看监控覆盖率(吞吐/延迟/堆积/失败率/磁盘/GC);看告警可行动性与演练记录 先定义 SLO 与告警;补齐指标与链路追踪;制定升级/回滚/演练流程;把"压测与演练结果"作为选型验收门槛 |
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接