TL;DR
- 场景:用 Java 并发快速实现"队列缓冲 + 异步解耦"的最小可运行消息模型
- 结论:BlockingQueue 能讲清 MQ 的核心交互,但离生产级 MQ 还差持久化、ACK、重试、集群与可观测性
- 产出:一套可跑的 Producer/Consumer Demo + 一份企业级差距清单(可作为扩展路线图)
版本矩阵
| 项目 | 状态 | 说明 |
|---|---|---|
| JDK 版本 | 未验证 | 正文未给出;BlockingQueue/ArrayBlockingQueue 逻辑在 JDK 8/11/17 语义一致(行为差异点主要在异常与阻塞语义上) |
| Lombok | 未验证 | 使用了 @Data/@Builder/@AllArgsConstructor/@NoArgsConstructor,未给出 Lombok 版本与构建工具 |
| 运行环境 | 未验证 | 单进程/单 JVM 内线程模型;不涉及跨进程、跨机器网络通信 |
| 队列实现 | 已验证 | ArrayBlockingQueue<>(20) 已明确;公平锁(fairness)未设置,默认 false |
消息中间件
基本概念
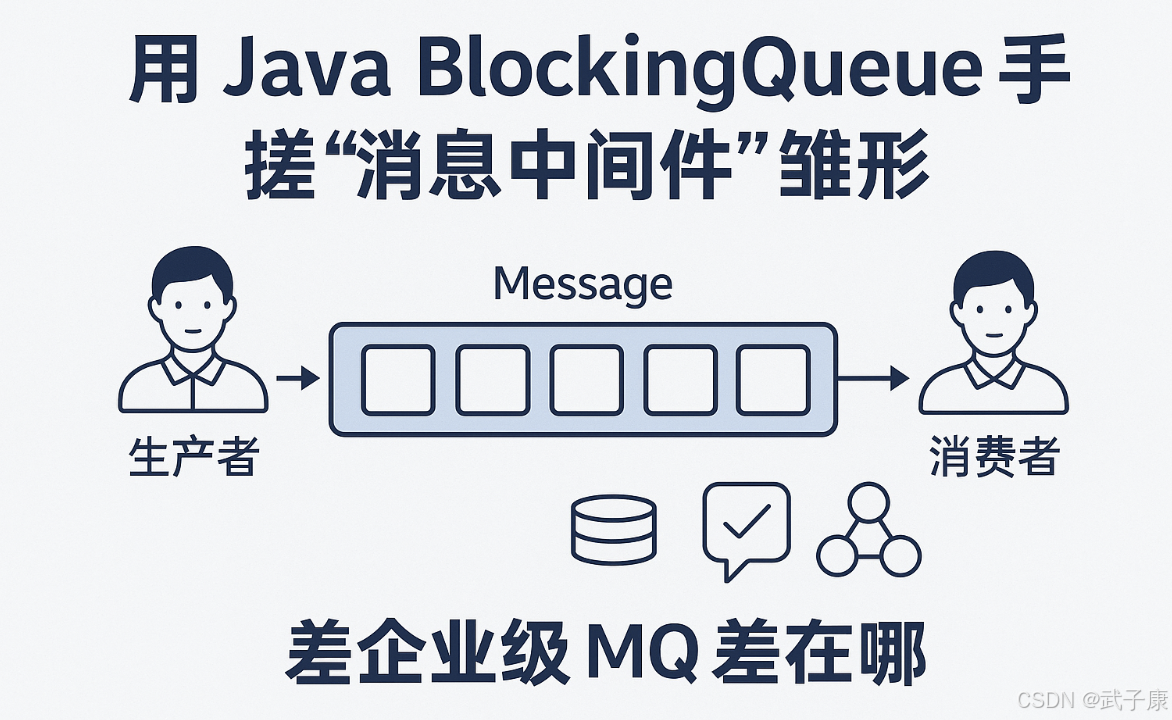
面向消息的系统(Message-Oriented Middleware,简称MOM),又称消息中间件或消息队列(Message Queue),是分布式系统架构中实现异步通信的核心组件。它通过高效可靠的消息传递机制,为不同平台、不同语言构建的分布式应用提供统一的数据交换服务。
典型特征与技术实现:
- 异步通信机制:采用"发送后不管"(fire-and-forget)模式,生产者发送消息后无需等待消费者响应,显著提高系统吞吐量
- 消息持久化:通过磁盘存储或复制机制确保消息不丢失,如RabbitMQ的持久化队列、Kafka的分区副本
- 协议支持:通常支持AMQP、MQTT、STOMP等标准协议,例如RabbitMQ实现AMQP 0-9-1协议
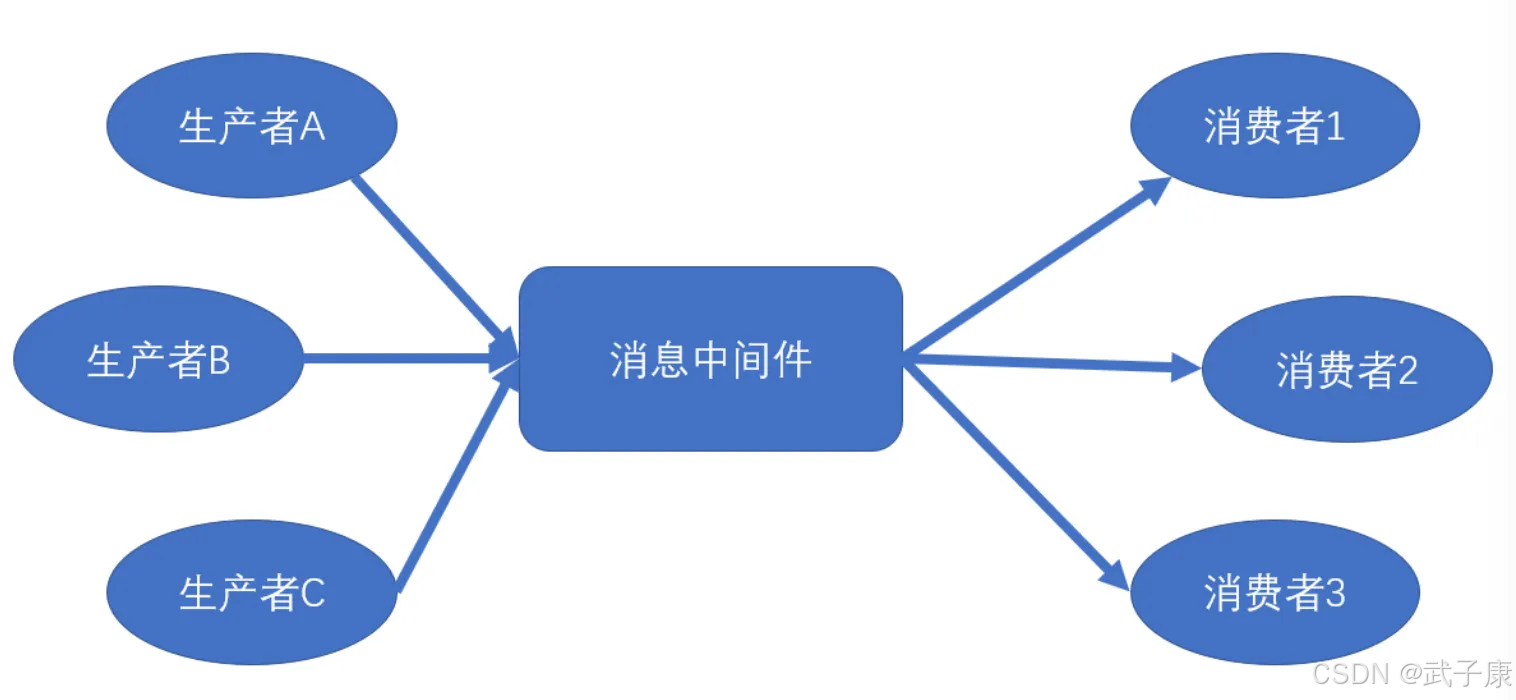
- 消息路由:提供灵活的路由策略,包括点对点(Queue)、发布订阅(Topic)等模式
核心应用场景:
- 服务解耦:电商系统中订单服务与库存服务通过消息队列异步通信
- 流量削峰:秒杀场景下将瞬时请求暂存到队列中逐步处理
- 最终一致性:分布式事务场景通过可靠消息实现最终一致性
- 日志收集:Kafka等系统实现大规模日志的实时采集与分发
主流实现对比:
| 系统 | 吞吐量 | 延迟 | 持久化 | 适用场景 |
|---|---|---|---|---|
| RabbitMQ | 中 | 低 | 支持 | 企业级消息路由 |
| Kafka | 高 | 中 | 强支持 | 大数据流处理 |
| RocketMQ | 高 | 低 | 支持 | 金融级交易场景 |
| ActiveMQ | 低 | 中 | 可选 | 传统企业集成 |
消息中间件通过提供可靠传输、消息堆积、顺序保证等特性,有效解决了分布式系统面临的网络不可靠、服务异构性、系统扩展性等挑战,成为现代微服务架构不可或缺的基础设施。
自定义消息中间件
并发编程中很经典的问题:用Java实现生产消费者模式
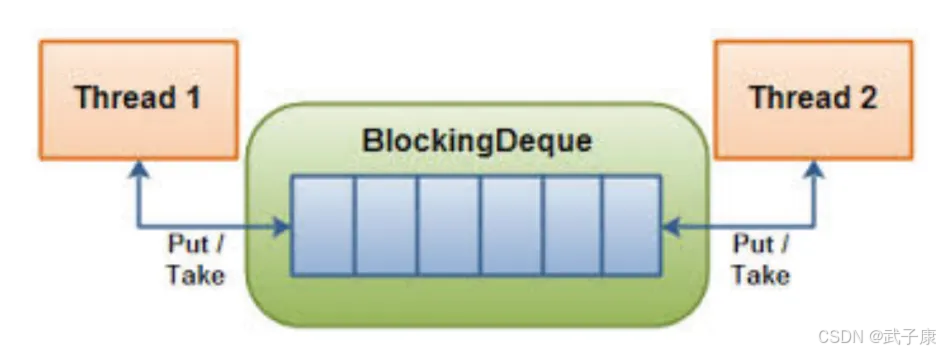
生产消费者模式是多线程编程中的经典同步问题,它描述了生产者和消费者通过共享缓冲区进行协作的场景。生产者负责生成数据并放入缓冲区,消费者则从缓冲区取出数据进行处理。这种模式可以有效平衡生产者和消费者的处理速度差异,提高系统整体吞吐量。
在Java中,BlockingQueue(阻塞队列)是实现生产消费者模式的理想选择。BlockingQueue是Java并发包(java.util.concurrent)中提供的一种线程安全的队列实现,它内置了线程同步机制,特别适合多线程环境下的数据交换。
BlockingQueue的主要特点和工作原理:
- 自动阻塞机制:
- 当队列已满时,生产者线程调用put()方法会被自动阻塞,直到队列中有可用空间
- 当队列为空时,消费者线程调用take()方法会被自动阻塞,直到队列中有新元素
- 这种机制避免了显式的线程等待和唤醒操作,简化了编程复杂度
- 常用实现类:
- ArrayBlockingQueue:基于数组的有界阻塞队列
- LinkedBlockingQueue:基于链表的可选有界阻塞队列
- PriorityBlockingQueue:支持优先级排序的无界阻塞队列
- SynchronousQueue:不存储元素的特殊阻塞队列
- 典型应用场景:
- 线程池任务队列(如ThreadPoolExecutor使用的工作队列)
- 消息中间件的缓冲区
- 高并发系统的请求缓冲
- 多阶段流水线处理系统
- 基本操作方法:
- put(E e):插入元素,队列满时阻塞
- take():获取并移除队首元素,队列空时阻塞
- offer(E e):非阻塞插入,成功返回true
- poll():非阻塞获取,失败返回null
示例代码片段:
java
// 生产者线程
public void run() {
while(true) {
Object item = produceItem();
queue.put(item); // 自动阻塞直到有空间
}
}
// 消费者线程
public void run() {
while(true) {
Object item = queue.take(); // 自动阻塞直到有数据
processItem(item);
}
}使用BlockingQueue实现生产消费者模式相比传统wait/notify方式具有以下优势:
- 代码更简洁,无需手动处理线程同步
- 更安全,避免了常见的同步错误
- 性能更好,底层采用优化的并发控制算法
- 可扩展性强,支持多种队列策略选择
Model
java
package icu.wzk.model;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class Good {
private String id;
private String type;
}Producer
java
package icu.wzk;
import icu.wzk.model.Good;
import java.util.UUID;
import java.util.concurrent.BlockingQueue;
public class WzkProducer implements Runnable {
private final BlockingQueue<Good> blockingQueue;
public WzkProducer(BlockingQueue<Good> blockingQueue) {
this.blockingQueue = blockingQueue;
}
@Override
public void run() {
try {
while (true) {
Thread.sleep(2000);
if (blockingQueue.remainingCapacity() > 0) {
Good good = Good
.builder()
.id(UUID.randomUUID().toString())
.type("吃的")
.build();
blockingQueue.add(good);
System.out.println("加入了食物 库存: " + blockingQueue.size());
} else {
System.out.println("库存已满: " + blockingQueue.size());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}Consumer
java
package icu.wzk;
import icu.wzk.model.Good;
import java.util.concurrent.BlockingQueue;
public class WzkConsumer implements Runnable {
private final BlockingQueue<Good> blockingQueue;
public WzkConsumer(BlockingQueue<Good> blockingQueue) {
this.blockingQueue = blockingQueue;
}
@Override
public void run() {
try {
while (true) {
Thread.sleep(1000);
long startTime = System.currentTimeMillis();
Good good = blockingQueue.take();
long endTime = System.currentTimeMillis();
System.out.println("吃了食物: " + good + ", " + (endTime - startTime) + " ms");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}Main
java
package icu.wzk;
import icu.wzk.model.Good;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class WzkMain {
public static void main(String[] args) throws Exception {
BlockingQueue<Good> blockingQueue = new ArrayBlockingQueue<>(20);
WzkProducer wzkProducer = new WzkProducer(blockingQueue);
WzkConsumer wzkConsumer = new WzkConsumer(blockingQueue);
new Thread(wzkProducer).start();
Thread.sleep(10_000);
new Thread(wzkConsumer).start();
}
}暂时分析
上述代码到生产环境显然是不行的,因为它缺乏企业级应用所需的关键特性。以下是一些需要重点考虑的问题:
-
消息持久化
- 需要支持消息持久化存储,防止系统崩溃时消息丢失
- 示例:可采用WAL(Write-Ahead Log)或数据库存储机制
- 应用场景:金融交易等对数据可靠性要求高的业务
-
消息可靠性保证
- 发送确认机制:实现ACK/NACK机制确保消息一定发送成功
- 消费确认机制:消费者处理完成后需显式确认
- 示例:类似RabbitMQ的消息确认机制
-
高并发处理
- 需要支持水平扩展的集群架构
- 采用多级缓存和负载均衡策略
- 性能指标:至少支持10万级QPS
-
系统可靠性
- 故障转移机制:主从切换、自动恢复
- 多机房部署:异地多活容灾方案
- 监控告警:完善的健康检查和监控体系
-
消息模式支持
- 发布/订阅模式:支持多消费者订阅同一主题
- 点对点模式:确保消息只被一个消费者处理
- 示例:Kafka的Topic/Partition机制
-
流量控制
- 限流机制:令牌桶或漏桶算法
- 熔断降级:防止系统过载
- 应用场景:秒杀等高并发场景的流量削峰
-
其他企业级特性
- 消息重试和死信队列
- 消息顺序性保证
- 消息追踪和审计
- 完善的权限管理和安全机制
这些特性都是构建生产级消息系统必须考虑的关键要素,需要根据具体业务场景进行设计和实现。
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 生产者在队列满时抛异常或线程退出(偶发) | 使用 blockingQueue.add(good):队列满会抛 IllegalStateException;你用 remainingCapacity()>0 做了预判,但并发下存在 TOCTOU 竞态(判断后立刻被别的线程填满) |
看日志/堆栈是否有 IllegalStateException: Queue full;检查 Producer 是否打印到"库存已满"后仍异常退出 把 add() 改为 put()(阻塞等待)或 offer(timeout)(超时退避);避免依赖 remainingCapacity() 作为可靠门禁 |
消费者 take() 阻塞看似"卡死" |
队列为空时 take() 必然阻塞;这在语义上是正常行为,不是死锁 |
线程 dump:消费者线程停在 ArrayBlockingQueue.take;同时队列 size=0 预期行为无需修;若要可停机/超时:用 poll(timeout) + 退出条件/中断处理 |
| 无法优雅停机,只能强杀进程 | while(true) 无限循环 + 捕获 Exception 吞掉中断语义(打印后继续循环或行为不明) |
发送中断(interrupt)后仍在跑;线程状态不退出 用 while(!Thread.currentThread().isInterrupted());捕获 InterruptedException 时恢复中断标志并 break;加入 stop flag |
| 吞吐与延迟不稳定 | 人为 Thread.sleep(2000/1000),不是负载控制;打印 IO 也会主导延迟 |
观察日志频率与 CPU/IO;把 println 注释后性能明显变化 Demo 说明"sleep/println 仅用于演示";要测性能:去掉 sleep/日志,改用统计指标上报消费耗时 |
| 消费耗时打印极小或不可信 | 你测的是 take() 等待时间,不是业务处理时间(processItem 并不存在) |
看到 "xx ms" 主要反映队列空时等待,而不是消费逻辑 明确指标含义;若要测端到端:在消息里带时间戳或在 consumer 里包住真实处理逻辑计时 |
| 队列堆积无法溯源 | 只有 size 输出;缺少生产/消费速率、滞留时间、失败率等观测 |
只能看到"库存: N",无法判断瓶颈在生产/消费/锁竞争/IO 增加最小指标:enqueue/dequeue TPS、队列滞留时间分位数、失败计数;日志改结构化 |
| "自定义消息中间件"表述引发误解 | 该实现是 JVM 内并发队列,不含网络协议、跨进程传输、持久化与消费语义 | 读者按"MQ"预期去理解,会问"重启后消息呢/多机呢/ACK 呢" 在正文明确定位:这是"MQ 交互模型 Demo",不是可替代 Kafka/RabbitMQ 的中间件实现;后文用差距清单承接 |
| 数据可靠性为 0(重启即丢) | 内存队列无持久化、无副本、无重放 | 杀进程后重新启动,队列消息消失 在"生产级差距"里明确:WAL + checkpoint/段文件 + 重放机制;或直接引导使用成熟 MQ(保留你现有差距清单) |
| 重复消费/消息丢失不可控 | 无 ACK、无重试、无幂等、无死信 | 故意让 consumer 抛异常:消息已出队但未完成处理,直接丢 定义消费语义:至少一次/至多一次/恰好一次(工程上多为至少一次 + 幂等);引入 ACK + 重试 + DLQ 设计点(正文可先列接口级伪码) |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接