论文标题:EM-Net: Efficient Channel and Frequency Learning with Mamba for 3D Medical Image Segmentation
论文原文 (Paper) :https://arxiv.org/abs/2409.17675
代码 (code) :https://github.com/zang0902/EM-Net
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
1. 核心思想
本文提出了一种名为 EM-Net 的新型 3D 医学图像分割框架,旨在解决传统 CNN 感受野受限和 Transformer 计算开销过大的问题。核心思路是将 Mamba (状态空间模型) 引入分割任务,并设计了两个关键模块:CSRM 模块 (通道挤压-增强 Mamba)通过通道选择机制来捕捉区域间的注意力交互;EFL 层(高效频域学习)利用 FFT 在频域中协调多尺度特征的学习。EM-Net 在保持 SOTA 分割精度的同时,将参数量减少了近一半,并将训练速度提升了 2 倍。
2. 背景与动机
背景:3D 分割的效率瓶颈
在 3D 医学图像分割中,主流方法主要分为两类:
- CNNs (如 nnU-Net):擅长提取层级特征,但受限于局部感受野,难以捕捉长程依赖。
- Transformers (如 Swin UNETR):通过自注意力机制擅长捕捉全局关系,但其二次复杂度在处理高分辨率 3D 体数据时显存和计算压力巨大。
虽然 Mamba (SSM) 凭借线性复杂度在序列建模上表现出色,但直接将其应用于 3D 视觉任务仍面临空间关系建模困难 (Mamba 是 1D 序列模型)和显存消耗的挑战。
动机图解分析
看图说话:
- 现有局限性:传统的 Encoder-Decoder 结构(如 U-Net)在深层特征提取上往往依赖堆叠卷积或 Transformer Block。这导致了要么感受野不足(CNN),要么计算太重(Transformer)。
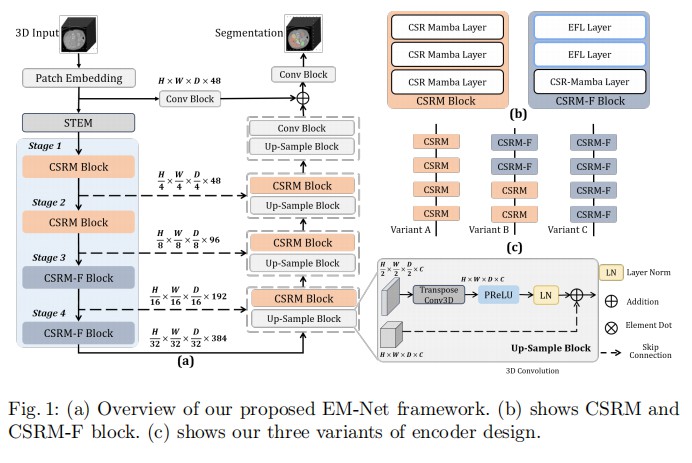
- 本文的破局点 :观察架构图,EM-Net 的核心在于其 Encoder 和 Decoder 并未沿用标准组件,而是替换为 CSRM Block 和 CSRM-F Block 。
- CSRM Block (浅层/解码器) :针对 Mamba 难以捕捉空间信息的弱点,作者并没有单纯依赖位置编码,而是通过通道维度(Channel Dimension)的挤压与增强来辅助 Mamba 聚焦特定区域。
- CSRM-F Block (深层) :针对分割任务对全局(低频)和局部(高频)信息平衡的需求,作者引入了频域学习(Spectral Gating),利用 FFT 的对数线性复杂度来降低深层特征的计算负担。
3. 主要创新点
- CSRM 模块 (Channel Squeeze-Reinforce Mamba):提出了一种双分支结构(Squeeze & Reinforce),通过压缩和扩展通道维度来过滤冗余特征,并利用共享权重的 Mamba 模块自适应校准被忽略的特征,有效增强了 Mamba 的空间感知能力。
- EFL 层 (Efficient Frequency-domain Learning):设计了一个基于 FFT 的频域学习层,通过可学习的频域权重(Gating)来动态平衡全局轮廓和局部纹理特征,同时保持极低的计算复杂度。
- Mamba-Infused Decoder:打破了仅在 Encoder 使用高级模块的惯例,在 Decoder 中也集成了 CSRM 模块。实验证明,相比简单的上采样卷积,这种设计能更好地恢复空间细节且不显著增加计算负担。
- 高效性 (Efficiency) :在 Synapse 和 BTCV 数据集上,EM-Net 以仅约 39M 的参数量(SOTA 模型的一半)和 10.68 Iter/s 的训练速度(SOTA 的 2 倍),达到了最优的 DSC 精度。
4. 方法细节
整体网络架构
EM-Net 采用了经典的 U-Shaped 架构:
- 输入 (Input):3D 图像切块。
- Encoder (编码器) :
- STEM:使用 4x4x4 的卷积进行下采样,获得 1/4 分辨率特征。
- Stage 1 & 2 :堆叠 CSRM Blocks,负责提取高分辨率下的空间细节特征。
- Stage 3 & 4 :堆叠 CSRM-F Blocks(包含 EFL 层),负责在低分辨率下高效提取全局语义特征。
- Bottleneck:深层特征融合。
- Decoder (解码器) :包含 4 个阶段。每个阶段先通过反卷积进行 2 倍上采样,然后接入 CSRM Block 进行特征恢复与整合(不同于常见的纯卷积解码器)。
- Skip Connections:编码器与解码器特征通过加法或拼接融合。
- 输出 (Output):最终通过卷积块输出分割掩码。
核心创新模块详解
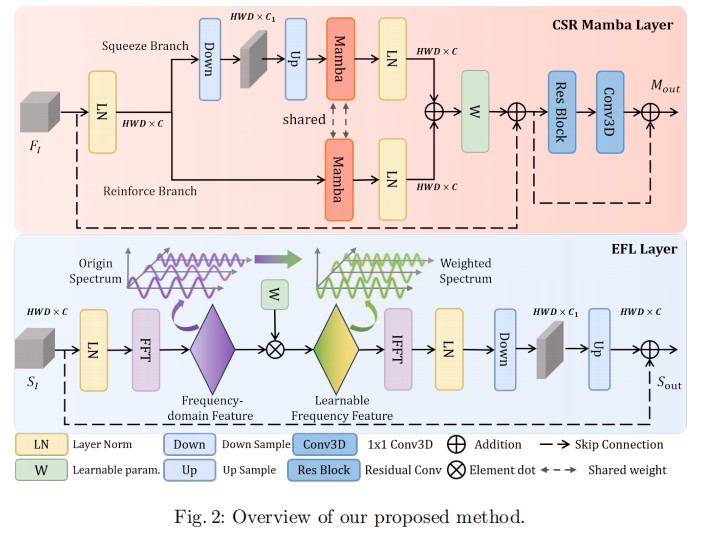
1. CSR Mamba Layer (模块 A)
该模块旨在解决 Mamba 空间建模弱的问题,利用通道注意力机制。
- 输入流:特征分为两个分支。
- Squeeze Branch (压缩分支) :通过
Down->Up操作压缩通道维度,筛选关键特征,然后输入 Mamba。 - Reinforce Branch (增强分支):直接将原始特征输入 Mamba,用于保留被压缩分支忽略的信息。
- 共享 Mamba:两个分支共享同一个 Mamba 模块的权重,减少参数量。
- 融合:两个分支的输出通过可学习参数进行加权求和。
- 设计目的:利用通道维度的压缩与恢复,强迫 Mamba 关注对分割任务更重要的特定区域特征。
2. EFL Layer (模块 B)
该模块利用频域特性进行高效的全局/局部特征平衡。
- FFT 变换:将空间域特征通过 3D FFT 变换到频域。
- Spectral Gating (频谱门控):将频域特征与一个可学习的权重图(Parameter Map)进行逐元素相乘。这相当于一个自适应滤波器,网络自动学习保留哪些频率分量。
- IFFT 逆变换:将滤波后的特征变换回空间域。
- 设计目的:利用 FFT 的全局感受野特性(频域中的一点对应空域的全局)来捕获长程依赖,同时复杂度远低于 Transformer 的自注意力。
理念与机制总结
EM-Net 的核心理念是 "扬长避短"。
- 利用 Mamba 的线性复杂度处理长序列,但通过 CSRM 的通道交互机制弥补其空间感知能力的不足。
- 利用 Transformer 的全局观念,但通过 EFL (频域操作)替代昂贵的 Self-Attention,实现"低成本的全局视野"。
这种组合使得模型既能"看得全"(Global),又能"算得快"(Efficient)。
5. 即插即用模块的作用
本论文提出的模块具有很强的通用性,适用于以下场景:
-
CSRM Block (通道挤压-增强 Mamba):
- 适用场景 :适用于任何需要特征选择 或轻量化注意力的 3D 视觉任务(如 3D 检测、配准)。
- 应用:可以替换现有 U-Net 架构中的标准卷积块或 SE-Block,特别是在显存受限但需要提升空间敏感度的场景下。
-
EFL Layer (高效频域学习):
- 适用场景 :适用于需要捕捉全局上下文但计算资源有限的任务。
- 应用:可以作为 Transformer Block 的替代品,插入到 CNN 的深层(Bottleneck)位置,用于以极低的计算成本引入全局感受野,解决 CNN 感受野不足的问题。
6. 实验分析
- 数据集:Synapse (腹部多器官) 和 BTCV (多器官 CT)。
- 性能对比 :
- 在 Synapse 数据集上,EM-Net 的平均 DSC 达到 83.95%,优于 U-Mamba (82.83%) 和 Swin UNETR (83.06%)。
- 在 BTCV 数据集上,EM-Net 取得了 78.97% 的 DSC,显著优于 nn-UNet (76.31%)。
- 效率分析 :
- 参数量 :EM-Net 仅有 39.41M 参数,而 Swin UNETR 为 62.19M,U-Mamba 为 58.47M。
- 训练速度 :训练速度达到 10.68 Iter/s ,是 U-Mamba (8.14 Iter/s) 的 1.3 倍,是 Swin UNETR (4.94 Iter/s) 的 2 倍以上。
- 可视化 :定性结果显示,对于胃 (Stomach) 等低对比度器官和胰腺 (Pancreas) 等小器官,EM-Net 的分割边界更贴合 Ground Truth。
在这里插入图片描述


到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。