太长了有点,看完太累了。
设计的文献有点忒多了,不所有都贴上去了,就贴一些跟我方向相关的,还有我觉得比较重要的。其他的如果以后需要看了,再贴上去。
基本信息
题目:3D Registration in 30 Years: A Survey
来源:arXiv 2024
学校:西北工业大学
是否开源:https://github.com/Amyyyy11/3D-Registration-in-30-Years-A-Survey
摘要:三维点云配准是计算机视觉、计算机图形学、机器人学、遥感等领域的一个基本问题。在过去的三十年里,我们目睹了这一领域的惊人进步,并提出了各种各样的解决方案。尽管已经开展了少量的相关调查,但其覆盖范围仍然有限。在这项工作中,我们对三维点云配准进行了全面的调查,涵盖了成对粗配准、成对精配准、多视图配准、跨尺度配准和多实例配准等一系列子领域。本文从数据集、评价指标、方法分类、优缺点讨论、未来发展方向等方面进行了较为全面的介绍。
1 Introduction
将三维点云配准到统一的坐标系下,称为三维点云配准,是计算机视觉、计算机图形学、机器人和遥感等众多领域的一个基本问题。对齐后的点云提供了两个关键结果:1 )用于重建、信息融合和误差测量的更完整的点云;2 )六自由度( 6-DoF )位姿,用于鲁棒的位姿估计、3D跟踪、物体/位置定位和运动流估计。随着三维主被动获取技术(例如,英特尔的RealSense、苹果的iPhone系列等)的发展,三维点云配准在过去三十年中引起了越来越多的研究关注。
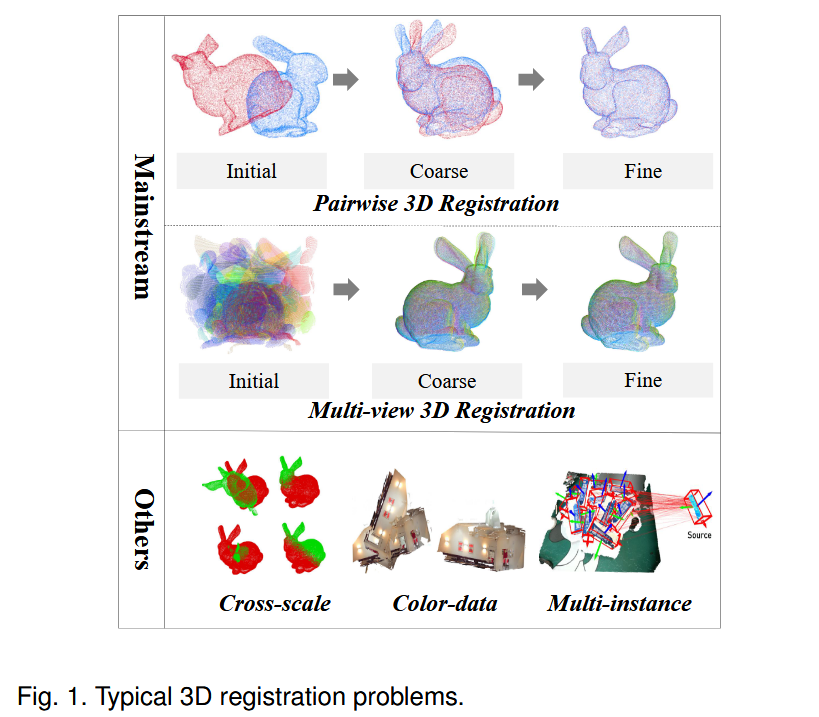
特别地,根据数据采集或应用场景的不同,有几个子分支致力于稳健的三维点云配准(图1 )。从处理的数据序列来看,成对配准侧重于对齐两个点云,而多视图配准则对齐两个以上连续或无序的多个点云。从误差最小化的角度来看,粗配准大致对齐位姿变化相对较大的点云,而精配准通常侧重于最小化较小的残差。从方法论的角度来看,早期的方法设计手工优化或启发式方法。最近采用深度学习的方法。还有其他角度用于研究配准问题,例如特征学习,对应学习和鲁棒的6 - DoF姿态估计。因此,在三维点云配准领域有很多方法和研究课题。
现有的研究要么集中在不同的部分,要么集中在有限范围内的点云配准任务。例如,早期的综述 1 涵盖了点云配准的各个方面,但缺乏对子领域之间相互联系的透彻分析,未能系统地揭示它们之间的内在关系和相互作用。最近的综述 2 总结了常用的数据集和评价指标,但缺乏在统一实验环境下的性能比较,未能在一致的条件下展示不同方法的优势和局限性。因此,他们未能从一个更全面的角度涵盖近三十年来的研究。为了填补这一空白,我们对过去几十年的3D配准方法进行了全面的综述。主要贡献概括如下:
-
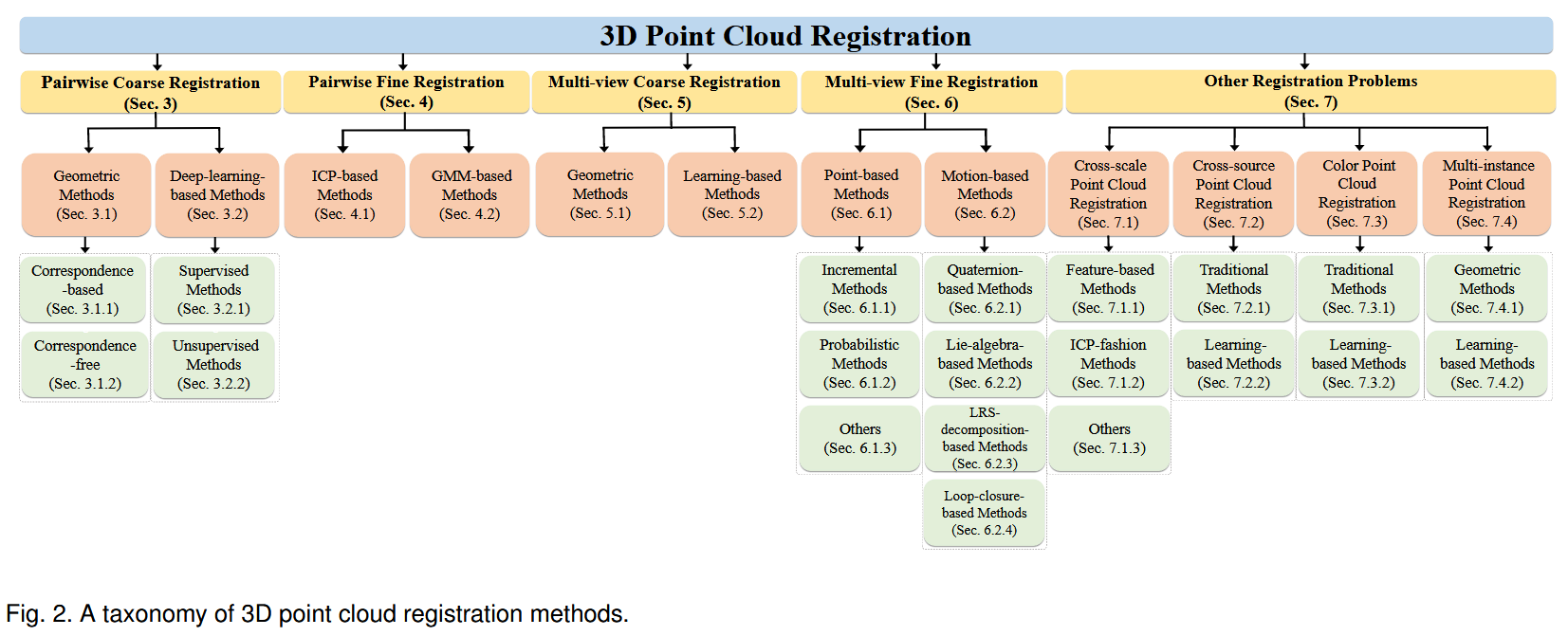
全面的综述和新的分类学。据我们所知,如图2所示,这是第一个全面综述点云配准方法的调查报告,涵盖了成对粗配准、成对精配准、多视图配准、跨尺度配准和多实例配准等一系列子区域。它提供了系统的分类法和广泛的文献覆盖范围。
-
基准概述和性能比较。系统地总结了点云配准的常用基准数据集和性能评价指标。还报告了一组在标准基准上具有代表性的最先进方法的比较结果。
-
对未来方向的展望。 突出了现有方法的特点、优点和不足。我们还对当前面临的挑战和未来的几个研究方向进行了深入的讨论,以启发该领域的后续工作。
1 X. Huang, G. Mei, J. Zhang, and R. Abbas, "A comprehensive survey on point cloud registration," arXiv, 2021.
2 M. Lyu, J. Yang, Z. Qi, R. Xu, and J. Liu, "Rigid pairwise 3d point cloud registration: a survey," PR, p. 110408, 2024
2 BACKGROUND
2.1 Basic Concepts

点云是啥,balabala
点云配准是啥,balabala
2.2 Datasets
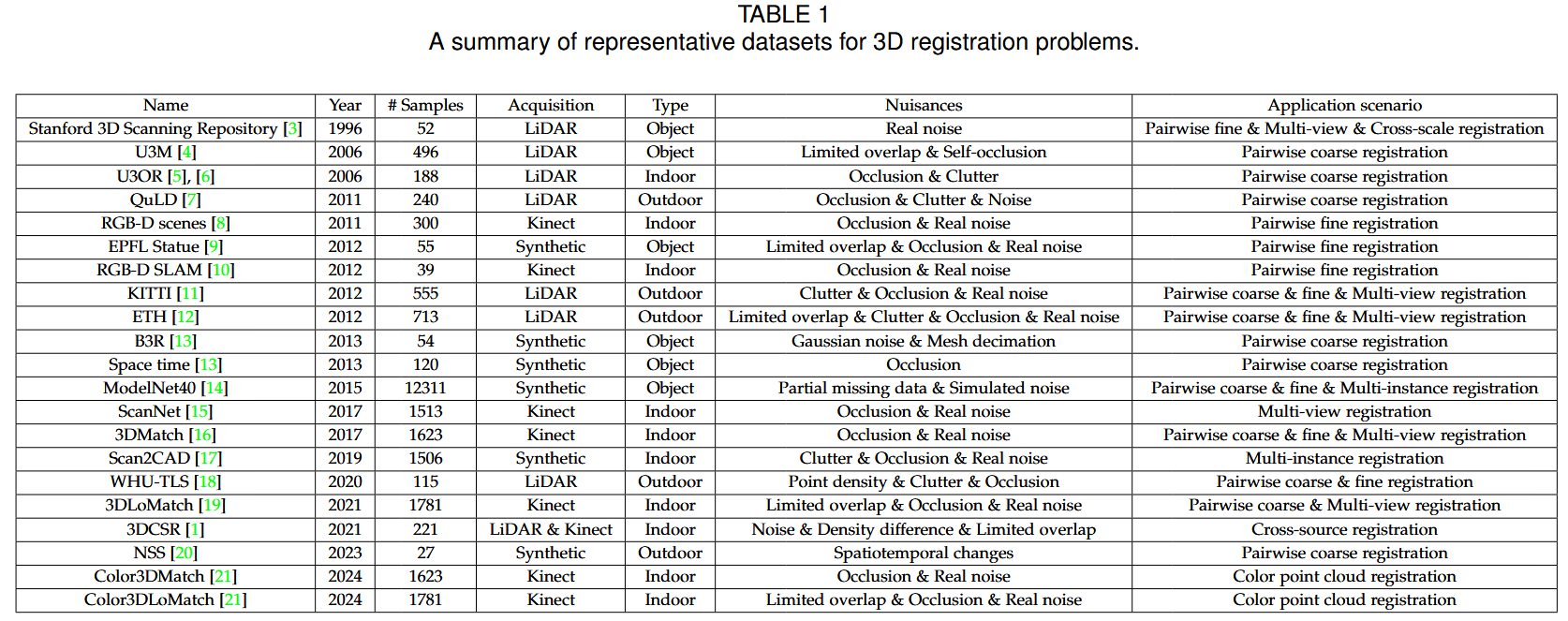
2.3 Metrics
为了评估3D注册的性能,人们提出了各种各样的评价指标。例如,配准的召回率( Recall,RR )、均方根误差( Root Mean Square Error,RMSE )、平均绝对误差( Mean Absolute Error,MAE )、均方误差( Mean Squared Error,MSE )、平均各向同性误差( Mean Isotropic Error,MIE )、旋转误差( Rotation Error,RE )和平移误差( Translation Error,TE )是评价大多数配准任务精度的基本指标。特别地,对于多视粗配准任务,额外使用最大对应误差( MCE )来评估表面上任意点相对于其地面真实位置的最大位移,并使用经验累积分布函数( ECDF )来评估误差分布的函数。
还有一些指标用于评估配准管线中的某些模块。例如,查全率-查准率曲线( recall versus precision curve,RPC )是评价局部描述符性能最常用的指标。内点查全率( IR )、内点查准率( IP )和F1值( F1 )是评价对应优化方法性能的常用指标。
3 PAIRWISE COARSE REGISTRATION
3.1 Geometric Methods
该部分总结了基于几何方法的成对粗配准pairwise coarse registration方法,分类和时间概述分别见图4和图6。
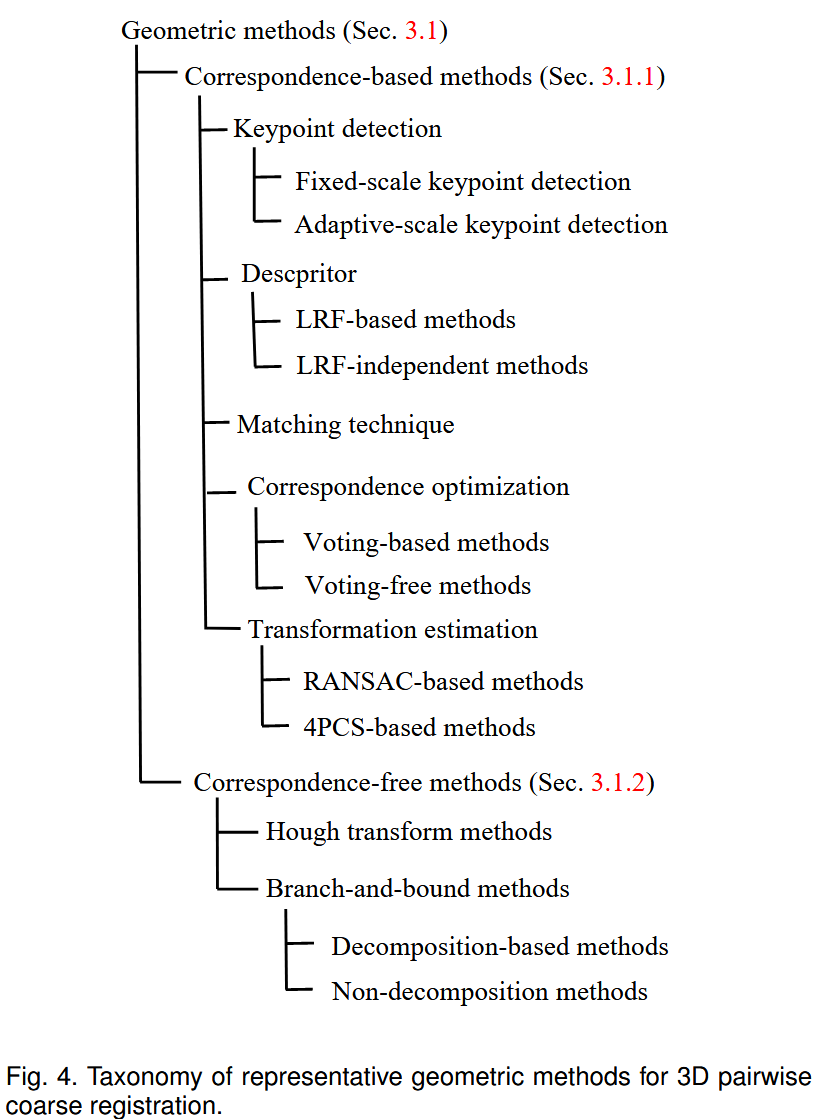
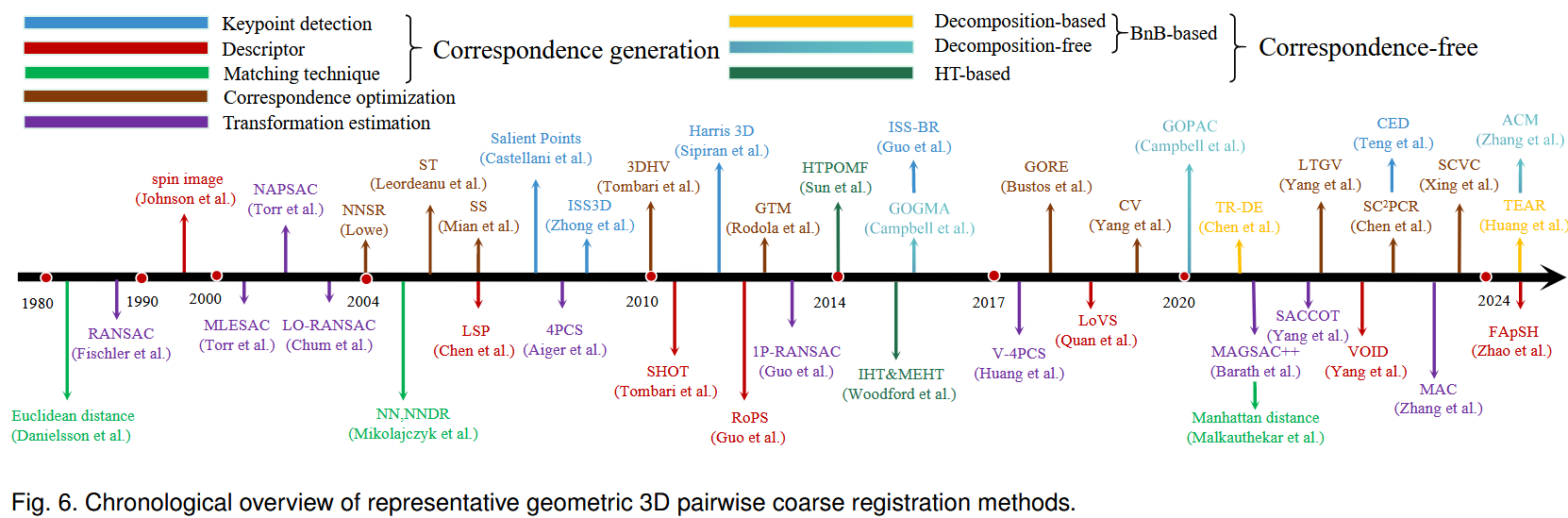
3.1.1 Correspondence-based Methods
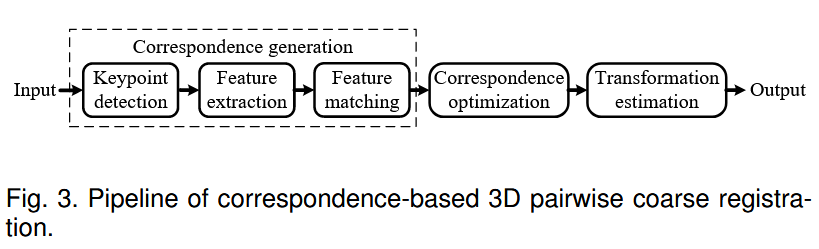
在基于对应关系的方法中,如图3所示,对应关系的生成对于配准过程的准确性和鲁棒性至关重要。
(i) Keypoint detection
其目的是找到一组稀疏但有区别的点进行匹配。文献 13 给出了一个比较性的评价。一个分支的方法检测语义一致的3D关键点 22 , 23 , 24 ,这将在这里详细介绍,因为它们不是专门为配准而设计的。我们将现有的用于三维配准的关键点检测器分为固定尺度和自适应尺度两类。
1 )Fixed-scale keypoint detection methods
这些检测器在识别整个场景中的关键点或特征时以固定的尺度进行操作,而不需要根据物体大小或与传感器的距离调整尺度。 固定尺度检测器的主要优势在于其较快的处理速度和较低的计算需求。这些方法大致可以分为两类:基于显著性的方法和基于签名的方法。基于显著性的关键点检测方法 6 , 25 , 26 , 27 , 28 , 29 定义了一个显著性度量来识别具有独特几何或视觉特性的区域,通常关注局部表面变化以进行有效的关键点选择。Chen等人 25 和卡斯泰拉尼等人 26 利用局部表面patches和3D saliency来检测具有显著表面形状变化的区域中的关键点。在表面形状变化显著的区域检测关键点。同时,Mian等人 27 提出了一种在3D人脸上检测具有显著形状变化的关键点的方法,能够提取高度描述的、姿态不变的特征。还有一些方法可以解决特定的挑战,例如尺度不变性 6 和计算效率 28 。最近,Teng等人 29 引入了质心距离( CED )检测器,它在几何和颜色空间中唯一地识别关键点,而不需要正常估计或特征值分解。
13 F. Tombari, S. Salti, and L. Di Stefano, "Performance evaluation of 3d keypoint detectors," IJCV, vol. 102, no. 1-3, pp. 198--220, 2013.
29 H. Teng, D. Chatziparaschis, X. Kan, A. K. Roy-Chowdhury, and K. Karydis, "Centroid distance keypoint detector for colored point clouds," in Proc. WACV, 2023, pp. 1196--1205.
基于签名的关键点检测方法 30 , 31 依靠特定的几何特征来识别关键点,保证了鲁棒性和可重复性。例如,Sun等 30 提出了热核特征( HKS )检测器来捕获多尺度邻域信息,提高了形状扰动下的稳定性。Zhong 31 提出了内蕴形状特征( Intrinsic Shape Signature,ISS ),它提供了一种局部和半局部区域的视图无关的表示方法,用于高效的形状匹配和位姿估计。还有一些工作分别由Guo等 32 和Zhang等 33 改进了ISS。上述方法虽然高效,但在复杂场景下普遍表现出有限的可重复性能。
2 )Adaptive-scale keypoint detection methods
这些检测器根据局部几何或外观动态地调整关键点识别的尺度,以确保在不同的物体大小、距离或细节层次上鲁棒地捕获特征。一个直观的想法是将2D检测器扩展到3D。例如,Sipiran和Bustos 34 将广泛使用的2D Harris算子改进为3D Harris算子,通过分析顶点邻域实现鲁棒的关键点检测。一些检测器只适应于3D网格 35 , 36 , 37 。例如,扎哈雷斯库等 35 开发了一种基于标量场的方法MeshDOG,该方法检测对旋转、平移和尺度不变的关键点,用局部几何特性描述特征。此外,Knopp等人 37 引入了局部特征提取与扩展的SURF描述符和概率霍夫变换相结合的方法,显著提高了三维形状识别精度。一些检测器是专门为三维点云设计的 38 , 39 , 40 ,乌尼克里希南和Hebert 39 提出了一种多尺度算子方法,用于从原始点云直接检测关键点,避免了预定义的结构。Steder等人 40 通过发展法向对齐径向特征( Normal Aligned Radial Feature,NARF )方法,进一步增强了关键点检测,该方法融合了物体边界信息,具有更好的稳定性和精度。虽然自适应尺度方法提高了对尺度变化的鲁棒性,但其计算复杂度有时会限制实时效率。
(ii) Descriptors.
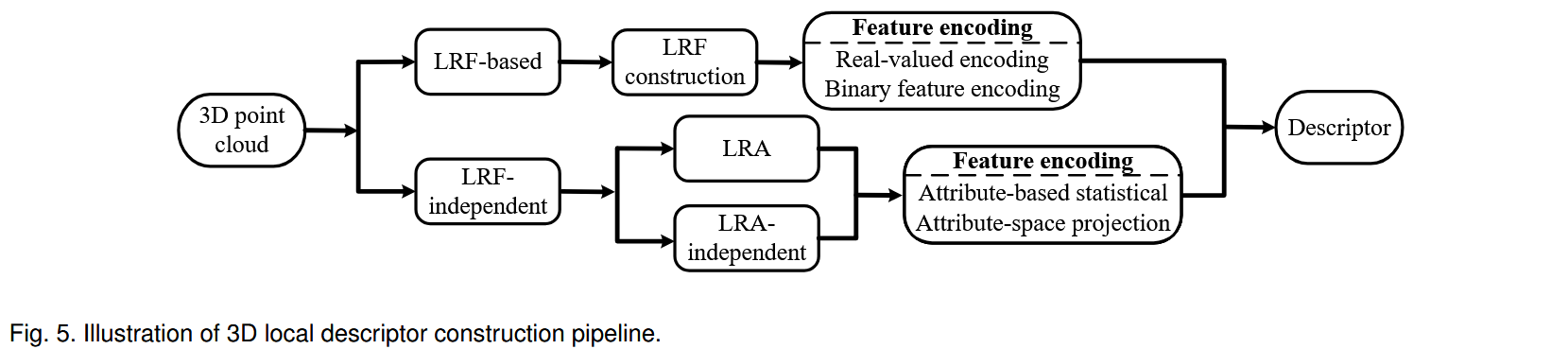
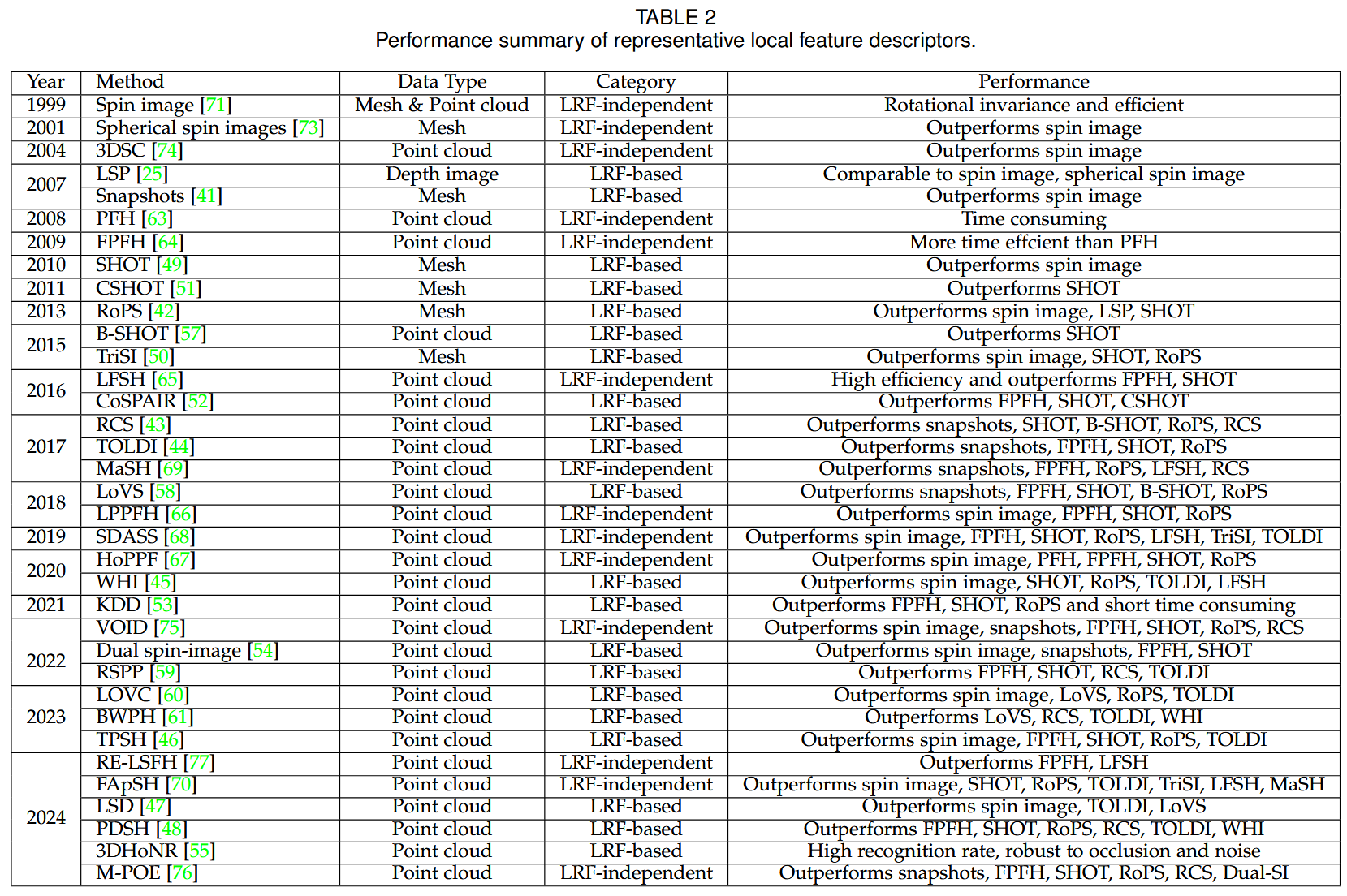
一旦检测到关键点,就可以提取周围局部表面的几何特征,生成局部特征描述子。如图5所示,根据点云局部表面是否建立局部参考框架( local reference frame,LRF ),这些局部特征描述子可以进一步分为两类:基于LRF的和不依赖于LRF的。表2给出了局部表面特征描述方法的性能概述。
1) LRF-based methods.
这些描述符首先在局部表面构建一个LRF,然后基于LRF编码表面的空间和几何信息。这些方法可以进一步分为两类,即实值编码和二进制特征编码。
实值编码方法一般生成具有2D投影属性、3D点属性或3D体素属性的描述符。基于2D投影属性的方法 41 , 42 , 43 , 44 , 45 , 46 , 47 , 48 通过将3D结构简化为2D表示,将局部表面投影到2D平面上,以有效地捕获几何分布。例如,Malassiotis和Strintzis 41 提出了快照,将局部曲面投影到相机平面上,而Guo等 42 提出了旋转投影统计量( RoPS ),保证了多视图投影信息的更全面的特征编码。继RoPS之后,Yang等人 43 引入了旋转轮廓特征( Rotational contour signature,RCS ),通过二维轮廓投影捕获多视图信息。 相比之下,基于三维点属性的方法 25 , 49 , 50 , 51 , 52 , 53 , 54 , 55 利用三维邻域内的空间和几何关系来描述局部表面特征。值得注意的例子包括Chen等人 25 的局部表面块( LSP )表示,它将角度关系编码成2D直方图,以及通巴里等人 49 的方向直方图签名( SHOT ),它将邻域划分为子空间以增强描述性。3D体素属性方法将局部区域划分为体素网格以编码占有率或密度信息,有效地表示复杂的空间结构。例如,Tang等 56 提出了签名几何形心( SGC )描述子,使用基于体素化形心的特征对几何图形进行编码。Zhang等人 53 提出了基于核密度估计的描述子( KDD ),利用核密度估计来平衡鲁棒性和描述性。
对于二进制编码方法,它们侧重于简化几何和空间信息在二进制格式中的表示,从而显著减少内存使用并加速特征匹配。我们进一步将其分为描述符空间二值化方法和属性空间二值化方法。对于描述子空间二值化,Prakhya等人 57 引入了方向直方图的二进制签名( Binary Signature of Histograms of Orientations,B-SHOT ),它使用二进制量化来提高存储效率和匹配速度,而不影响SHOT的性能。另一方面,属性空间二值化方法 58 , 59 , 60 , 61 ,如Quan等人提出的局部体素化结构( LoVS )描述符 58 ,直接比较LRF内的几何属性值,提高了紧凑性和效率。
基于LRF的方法通常在干净数据上表现出优越的描述性性能,然而,由于LRF的不稳定性,它们对噪声和部分重叠等干扰的鲁棒性有限。
2) LRF-independent methods.
LRF - independent描述符通过利用点云的几何特性,如法向量和点密度来捕获局部形状信息。这些方法大致可以分为两类:基于属性的统计方法和属性空间投影方法。基于属性的统计方法 62 、 63 、 64 、 65 、 66 、 67 、 68 、 69 、 70 通过对单个属性(例如,距离和角度)或其组合进行统计分析,重点捕捉局部点云的分布特征。这些描述符,如点特征直方图。( PFH ) 63 ,快速点特征直方图( FPFH ) 64 ,使用距离关系来描述局部几何结构。一些方法同时编码多个属性,如局部特征统计直方图( LFSH ) 65 和完全属性对统计直方图( FApSH ) 70 。另一方面,属性空间投影方法 71 , 72 , 73 , 74 , 75 , 76 , 77 将点云转化为具有结构化形式的属性空间,例如三维网格或体素网格。一些方法在二维属性空间上进行投影。例如,旋转图像 71 和球面旋转图像 73 将局部点云数据投影到结构化空间,从而能够更好地处理遮挡和杂波。还有一些方法构造了投影的3D属性空间。 例如,不变距离空间( VOID )描述符 75 中的体素化通过计算关键点及其邻近点的3个不变距离属性,使用体素化编码鲁棒特征。
近年来,不依赖于LRF的方法已经成为三维局部形状描述的一个很有前途和越来越重要的趋势。
63 R. B. Rusu, N. Blodow, Z. C. Marton, and M. Beetz, "Aligning point cloud views using persistent feature histograms," in Proc. IROS. IEEE, 2008, pp. 3384--3391.
64 R. B. Rusu, N. Blodow, and M. Beetz, "Fast point feature histograms (fpfh) for 3d registration," in Proc. ICRA. IEEE, 2009, pp. 3212--3217.
(iii) Matching technique
匹配的主要目的是通过对关键点提取的特征描述子进行比较,准确地识别出相应的匹配点对。一种常用的方法是使用不同的距离度量来执行最近邻( NN )或最近邻距离比( NNDR )匹配。为此,人们使用了各种距离度量,如欧氏距离和曼哈顿距离 63 。
为了提高匹配速度,一些加速技术被引入。一些研究人员专注于使用2D索引表等数据结构来优化最近邻的搜索 71 。哈希表 5 , 74 , 78 使用哈希函数将特征描述子快速映射到特定位置,从而实现快速检索。局部敏感树 31 将相似的数据点聚集在一起以促进更快的匹配,而K - d树 42 , 79 , 80 常用来加速高维空间中的最近邻搜索。这些方法显著提高了匹配过程的速度和可靠性。
(iv) Correspondence optimization.
由于描述符的限制和点云数据中的杂乱、遮挡等挑战,初始对应集往往包含许多错误的匹配(离群点)。为了解决这个问题,研究人员开发了各种优化技术,通常被分类为基于选举的和免投票。表3给出了对应优化方法的性能概述。
1) Voting-based methods.
受霍夫变换 102 在2D图像处理中的成功启发,早期的3D方法通过将3D对应变换到霍夫空间进行投票来扩展这种方法。例如,通巴里和斯特凡诺 103 旨在检测Hough空间中由内点形成的紧密簇。为了进一步提高存储效率和精度,伍德福德等人 104 引入了本征Hough和最小熵Hough,改进了投票滤波,使其更适用于3D应用。Xing等人 99 提出了单点对应投票和聚类( SCVC ),用单个对应来预测变换,同时应用霍夫投票来确定剩余的自由度。
近年来,引入几何约束的方法被提出用于优化对应关系。Buch等人 105 提出了内点搜索( SI ),它利用低层几何不变量进行局部评估,利用协变约束进行全局投票。基于此,萨赫卢勒等人 106 提出了一种局部和全局几何一致性稠密评估和排序的两阶段投票方案。Wu等人 107 进一步改进了该方法,首先使用PPF约束生成几何一致性点对投票集,然后选择相容的对应三元组来估计假设位姿,从而得到更鲁棒的最终位姿投票集。
最近,研究转向利用图空间中内点之间的一致性。Yang等人 108 提出了一致性投票( Consistency Voting,CV ),它基于刚性和LRF亲和力来评估每个初始对应与预定义投票集的一致性。基于这一思想,Yang等人 109 提出了松紧几何投票( LTGV ),通过在动态投票方案中使用互补的松紧几何约束来平衡精确率和召回率。Sun和Deng 90 提出了一致性最大化三层投票( TriVoC ),将最小3点集的选择分解为3层,每层采用有效的投票和基于成对等长约束的对应排序。最后,Yang et al 文献 95 提出了相互投票( MV ),将图节点和边建模为候选人和投票人,并对两者进行细化,以实现更可靠的评分用于对应关系评估。
2) Voting-free methods
最初,这些方法通过特征相似度优化对应关系 5 , 110 。假设正确的对应关系形成强连通的聚类,谱技术( ST ) 82 和几何一致性( GC ) 25 等方法通过谱聚类和空间聚类识别匹配。Chen等人 91 提出了SC2 - PCR,它利用二阶空间相容性在早期阶段进行更有特色的聚类。除了基于聚类的方法,一些方法利用博弈论进行内点选择。Albarelli等人 111 提出了一个基于全局几何相容性的博弈理论框架来实现精细的表面配准。在此基础上,Rodola et al 80 引入了博弈论匹配( Game Theory Matching,GTM ),引入了尺度不变性,增强了在复杂场景中的鲁棒性。
其他方法则侧重于利用分枝定界( Bn B )等技术在参数空间中寻找全局最优解 112 。例如,Bustos和Chin 84 提出了保证离群点移除( GORE ),它使用几何操作来拒绝离群点,BnB作为子程序。Li 89 以效率而非保证全局最优性为目标,定义了紧边界对应矩阵( CM )和增广对应矩阵( ACM )。为了进一步加速GORE,Li等人 113 提出了二次时间GORE ( Quadratictime GORE,QGORE ),它采用基于选举的几何一致性方法,在保持鲁棒性和最优性的同时,实现了更快的上界估计。
**最近的无投票方法也旨在实现全局最大共识。**Zhou等人 83 提出了快速全局配准( FGR ),使用German -麦克卢尔损失和梯度非凸性( GNC )进行非凸优化。在图论框架中,TEASER 88 和Segregator 114 等方法使用最大团对离群点进行剪枝,其中离析剂融合了语义和几何信息。Lusk等人 115 提出了CLIPPER,它放宽了可伸缩和最优解的组合约束。进一步扩展这些概念,Li等人 116 基于可靠边的最大团构造了一个无向图来选择偏好的对应关系。qiao等人 98 提出了G3Reg,它利用几何图元和金字塔相容图来求解多个最大团。 图可靠性离群点移除( GROR ) 94 和超核最大化和灵活阈值化( SUCOFT ) 97 并不是只关注最大团,而是使用可靠度和K -超核概念来获得鲁棒共识集。此外,Zhang等人 117 结合图信号处理来加速变换估计的速度。
83 Q.-Y. Zhou, J. Park, and V. Koltun, "Fast global registration," in Proc. ECCV. Springer, 2016, pp. 766--782.
88 H. Yang, J. Shi, and L. Carlone, "Teaser: Fast and certifiable point cloud registration," Trans. Robot., vol. 37, no. 2, pp. 314--333, 2020.
尽管取得了这些进展,但在速度和精度之间实现最佳权衡仍然具有挑战性,特别是在复杂场景中。未来的工作可能集中在利用多阶几何一致性来提高鲁棒性、准确性和效率。
(v) Transformation estimation.
在对应点优化之后,估计对齐点云的变换,通常是通过采样对应子集生成候选变换,这些变换可以是基于RANSAC或4PCS的。表3给出了转换估计方法的性能概览。
1) RANSAC-based methods.
随机抽样一致性 81 ( RANSAC )迭代地找到将输入数据拟合到模型的参数,同时抛弃异常值,如图7所示。多年来,出现了许多RANSAC变体,主要集中在3个主要的改进领域:Sampling Strategy、evaluation criteria 、local optimization。
Sampling Strategy:
一些方法旨在增强采样过程,特别是在数据有噪声或高维度的情况下。Torr等人 118 提出了N邻近点样本共识( NAPSAC ),它优先考虑邻近点,假设内点更靠近。Barath等人 87 在此基础上引入了渐进邻域抽样,提出了渐进NAPSAC ( Progressive NAPSAC,P-NAPSAC )。Chum和Matas 119 提出了渐进样本一致性( Progressive sample consensus,PROSAC ),对对应关系进行排序,以提高匹配预测的准确性。基于类似的想法,Quan和Yang 86 提出了相容性引导的样本一致性( CG-SAC ),通过根据相容性分数对对应对进行排序来减少随机性。Ni等人 120 引入了GroupSAC,通过关注有希望的群来优化少内点采样。Yang et al Kim等 92 提出了具有相容性三角形的样本共识( SAC-COT ),利用相容性三角形( COT )产生准确的假设。为了更灵活的约束,Zhang等人 96 引入了MAC,通过使用极大团放松了之前的最大一致性要求,充分考虑了每个局部一致性,以实现精确的注册。虽然一个刚性变换通常至少需要三个对应 121 ,但有些方法样本较少。例如,Guo等人 122 提出了单点RANSAC ( 1P-RANSAC ),它使得单次匹配与其对应的LRF足以估计位姿变换。Yang等人 69 提出了具有全局约束( 2SACGC)的基于2点的样本一致性,它采样与局部参考轴( Local Reference Axis,LRAs )相关的两个对应。另外,Li等 123 提出了一种RANSAC方法,该方法使用没有特征信息的单点样本估计缩放和平移参数。
Evaluation Criteria
RANSAC变体在评价候选变换质量的方式上也存在差异。Torr等人 124 提出了MLESAC,它采用了一个最大化似然的准则,而不仅仅是内点的数量。Chum和Matas 125 提出了最优随机RANSAC ( R-RANSAC ),它通过改进的序贯概率比检验( SPRT )得到了最优性。Rusu等人 64 使用Huber惩罚函数进行评估,提出了样本一致性初始对准( Sample consensus initial alignment,SAC-IA )。针对现有度量方法的局限性,Yang等人 126 在分析内点和离群点贡献的基础上提出了几种度量方法。
Local Optimization
该领域的技术旨在通过对变换进行局部优化来细化变换。Chum等人 127 提出了一种局部优化的RANSAC ( LORANSAC )来减少最小子集带来的噪声。Barath和Matas 85 提出了图割RANSAC算法( GC- RANSAC ),它使用图割技术来执行局部优化步骤,以获得更精确的结果。
尽管对RANSAC进行了改进,但这些方法往往效率较低,精度有限,特别是在极低内点率的情况下。未来的研究可以集中在更鲁棒的方法来处理高维数据和严重的离群点,而并行处理和自适应采样的进步可以进一步提高RANSAC的速度和鲁棒性。
2) 4PCS-based methods.
四点一致集( 4PCS ) 128 方法通过使用具有固定仿射比的点集,采样4个共面点而不是随机选择来增强配准鲁棒性。为了提高效率,人们提出了多种改进方案:基于关键点的4PCS ( K-4PCS ) 129 利用关键点特征加速共面点集匹配,Super4PCS 130 考虑角度并使用3D网格限制搜索区域,广义4PCS ( G-4PCS ) 131 扩展到非共面点。结合Super4PCS和G - 4PCS的优点,穆罕默德等人 132 提出了融合自适应阈值技术和动态搜索空间约束的超广义4PCS。在Super4PCS的基础上,Huang et al 文献 133 利用体积4PCS ( V-4PCS )融合了体积信息,进一步减少了计算时间。
基于4PCS的方法受限于识别相似点集和验证变换的高计算需求。虽然改进的变体提供了更快、更准确和可扩展的注册,但它们仍然无法满足实时应用的需求。将4PCS与其他通信优化技术结合可以减少计算量。
3.1.2 Correspondence-free Methods
这些方法通过最优参数搜索进行两两粗配准,不需要进行对应生成或进一步处理,如图8所示。此外,非对应方法可以大致分为两类,即基于Hough变换( HT-based )和基于BnB的方法。
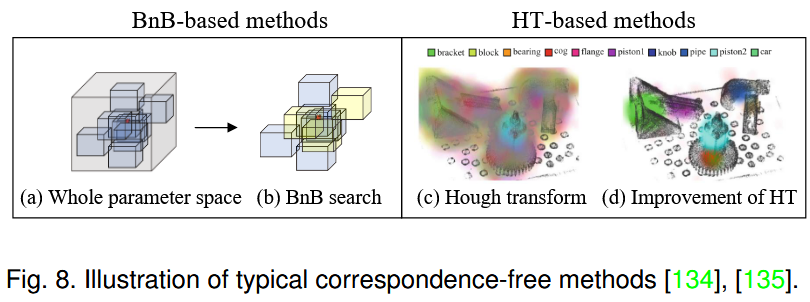
(i) HT-based methods.
基于HT的方法的核心思想是将整个参数空间离散为一组bin,然后从给定的对应关系中选择支持度累积最高的bin作为解。Hough等人 136 首先提出了HT的概念。随后伍德福德等人 134 分别引入了降低内存和计算需求的本征HT和提高精度和鲁棒性的最小熵HT。Sun等人 137 提出了仅相位匹配滤波( POMF )用于部分重叠信号的配准,它将输入扫描变换到霍夫域。然而,这些基于HT的方法不仅需要大量的内存和计算量,而且可能会陷入局部最优。 因此,这种方法并不广泛流行。
(ii) BnB-based methods.
基于BnB的方法不像基于HT的方法那样直接搜索和投票,而是递归地将参数空间划分为更小的分支,通过评估边界来修剪那些次优解。然而,6 - DoF的高维搜索空间导致了指数级的时间复杂度。根据所采用的具体加速技术,这些方法可以大致分为基于分解的方法和无分解的方法。
1) Decomposition-based methods.
他们通常将6 - DOF参数空间分解为多个子问题,从而加速BnB过程。Liu等人 138 和Wang等人 139 引入了旋转不变特征来分解变换。然而,3 - DoF旋转的高非线性仍然限制了BnB的效率。随后,Chen等 140 提出将6Do F参数空间分解为旋转轴上的(2+1)和(1+2) DoF,然后通过两阶段搜索策略得到最优解。与之不同的是,Huang等人 141 采用了不同的策略,分别使用截断项绝对残差和启发式引导采样 135 将6 - DoF问题分解为一系列子问题。
2) Decomposition-free methods
他们通常利用额外的约束来缩小参数搜索空间,从而加速BnB过程。一些方法 142 , 143 , 144 , 145 通过BnB和现有技术的结合来实现最优解。例如,Li等人 143 将共识集最大化问题转化为一个混合整数规划( MIP )问题,并采用BnB方法进行求解。Yang等 144 将经典的ICP方法与Bn B方法相结合,用于求解全局优化问题。Campbell等人 145 提出了采用BnB方法解决三维刚性高斯混合对齐问题的GOGMA方法。此外,一些方法 146 , 147 , 148 旨在识别更加新颖和健壮的约束。例如,Olsson等 146 提出了一种框架,利用多种类型的对应关系结合Bn B方法来实现各种位姿和配准问题的最优解。Bustos等人 147 提出了一种新的边界函数,使用赤平投影到预计利息,并对所有可能的点匹配进行空间索引来解决旋转问题。最近,Zhang等人 148 提出了一种通用技术,对Bn B分支的空间进行1Do F缩减,以加速确定性一致性最大化。 剩余维度采用区间刺破方法求解。最后,一些方法旨在通过Bn B方法解决特定场景。一些Bn B方法也被提出来解决具体的应用问题。例如,Cai等 149 针对地面LiDAR扫描对的4 - DOF场景,提出了一种带多项式时间子程序的快速Bn B方法。Campbell等人 150 使用BnB方法搜索相机位姿和对应关系估计的6D空间,并使用SE ( 3 )的几何结构来寻找基于内点数量的上下界。
最后,correspondence-free方法的性能如表4所示。
3.2 Deep-learning-based Methods
该部分总结了基于深度学习的成对粗配准方法。分类法、年代概述和性能比较见图9,图10和表。5 .


3.2.1 Supervised Methods
点云配准的监督学习方法依赖于各种类型的监督信号,例如真值对应关系或变换参数,来有效地训练模型 2 。基于学习范式,相关方法可分为Non-end-to-end-based方法和End-to-end-based方法。前者侧重于特定阶段,如匹配生成或匹配优化,后者则在单个深度学习网络内对整个点云配准过程进行建模。
(i) Non-end-to-end-based methods.
这些方法通常侧重于点云配准的特定方面,如特征提取、对应关系搜索和离群点去除。它们大致可以分为两类:匹配生成和匹配优化。
1) Matching generation paradigm
在该范式中,特征提取网络起着至关重要的作用,它用于构建用于匹配关键点的局部描述符。与传统方法类似,一些方法采用以局部面片为输入和输出描述符的面片网络。通常,分块网络在进行特征提取之前,需要通过人工的方法将输入的局部块变换到旋转不变的空间。例如,一些方法 189 151 通过将高维手工设计的描述符处理成紧凑的低维表示来增强特征压缩能力。其他一些方法 16 190 155 利用LRFs提取规范位姿中的特征。 最近的一些提案 157 191 192 使用旋转等效网络直接从原始点云或体素中提取特征,而不依赖于预处理。
虽然patch - wise网络是有效的,但其固定的感受野会导致高层语义信息的丢失。为了解决这个问题,一些工作 154 166 170 转移到从整个点云作为输入构建逐点描述符。然而,这些方法往往绕过关键点检测步骤,而是随机采样点进行特征描述。这种随机性可能会导致来自非显著区域的描述符,从而在后期的匹配步骤中引入噪声。为了解决这个问题,其他方法 193 194 19 195 169 将关键点检测和描述子提取整合到一个统一的框架中。 这些方法联合预测所有点的显著性得分和描述符,然后根据关键点的得分,使用得分最高的点生成特征对应。
2) Matching optimization paradigm
在该范式中,研究者们始终关注于从输入的噪声特征对应中学习一个准确的转换。例如,Pais等人 196 设计了一个分类骨干来分类初始匹配中的内点对应,紧接着 197 158 。Lee等人 198 和Jiang等人 199 引入了深度学习投票方法来提高异常值拒绝率。Guo等人 200 在特征空间中引入了二阶一致性。Yan等人 183 结合了一个语义分割网络来建立过滤式对应的多级语义一致性。对于鲁棒的位姿估计,Gao等人 201 设计了一个轻量级的基于学习的位姿估计器,以增强低重叠场景下位姿选择的准确性。
(ii) End-to-end-based methods.
在这些方法中,传统点云配准的每个阶段都由网络内不同的模块表示,使其能够直接输出估计变换。这种结构更好地利用了深度学习技术的潜力。这些方法大致可以分为一阶段、两阶段和多阶段范式。
1) One-stage paradigm
在端到端点云配准的早期阶段,大多数方法仅对点云间的匹配关系进行一次搜索,或者直接从输入对中估计变换。对于执行单一匹配搜索的端到端方法,在特征提取和匹配优化等方面进行了改进。例如,一些方法引入手工设计的描述符来增强特征区分度 202 ,而另一些方法结合点云对之间的特征交互来提高区分度和匹配可靠性 203 204 205 。另一些工作 206 175 207 208 直接预测重叠区域或估计重叠分数,以增强对应点的搜索。 为了提高匹配点的可重复性,一些工作直接预测对应点的坐标进行变换估计 209 210 。为了增强内点选择过程,Zhang等人 211 和Chen等人 212 对匹配矩阵进行了优化,以增加内点对应的置信度。一阶段的方法直接从特征估计变换矩阵。例如,Deng等人 213 利用FoldingNet 214 来学习旋转不变和旋转感知的描述符,这些描述符用于搜索匹配和估计特征空间中的变换。随后,Chen等人 215 和Jiang等人 216 对变换进行解耦,以实现更可靠的变换估计。
2) Two-stage paradigm
两阶段范式通常采用由粗到精的机制,其优越性在图像匹配任务中得到了证明 217 。如图11所示,这些方法通常将输入点云降采样为超点,并将其匹配以获得粗对应点,然后根据邻域关系将这些对应点传播到个别点。它们最终产生稠密的点对应。
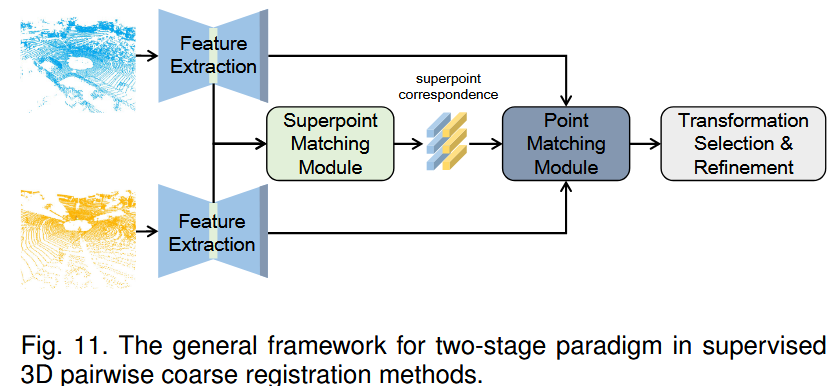
据我们所知,Co Fi Net 160 是最早将该机制引入点云配准的,为后续的发展铺平了道路。对于由粗到精的方法,超点匹配精度直接决定了最终的配准性能。因此,大多数方法集中于提高粗对应的内点比率。例如,GeoTransformer 164 利用几何关系来增强超点的判别能力,在优化超点匹配方面做了一系列的后续工作 218 219 182 。其他工作 172 220 221 ,如PEAL 172 ,结合了显式重叠区域识别来更有效地识别内点对应。 DCATr 180 引入渐进式更新机制来提高粗对应的空间一致性。Pos DiffNet 222 、HReg Net 159 和Regformer 174 引入多级对应关系来提高粗匹配阶段的内点率。
近年来,来自其他领域的深度学习创新丰富了两阶段范式。Chen等人 173 使用迁移学习来实现从合成场景到真实世界场景的泛化。Hatem等人 171 提出了一个带有三个自监督辅助任务的测试时间自适应框架。Yao等人 181 和Pertigkiozoglou等人 223 引入了旋转等变网络来提高配准性能。Chen等人 185 在数据增强中引入了生成式模型,创建各种输入对来改进训练。
3) Multi-stage paradigm
受迭代最近点( Iterative Closest Point,ICP )的启发,多阶段范式对点云对进行迭代配准,其中每次迭代构成网络的前向通道。每次传递后,利用估计的变换对齐输入对,并作为下一次迭代的输入。一些方法侧重于基于特征的匹配精化。Wang等人 153 和Yew等人 224 利用软匹配矩阵估计变换,迭代生成加权对应。扩散模型已被Jiang等人 225 和Chen等人 177 采用,将配准描述为一个去噪过程,以逐步细化变换。
其他一些方法侧重于增强特征表示。Wu等人 226 使用多层特征交互来增强学习特征的判别能力。Li等人 227 提出了一种语义感知的评分模型来利用语义和几何信息,突出感兴趣区域以获得更好的配准结果。Fu等人 228 对此进行了扩展,通过结合深度图匹配和嵌入高阶几何关系来提高对噪声和异常值的鲁棒性。
不同的工作线绕过中间匹配,直接在特征空间中估计变换。例如,Aoki等人 229 和Li等人 230 将Lucas & Kanade算法与全局特征差异相结合进行迭代对齐。Mei等人 176 使用高斯混合模型( GMMs )引入了概率配准,而FINet 231 设计了双分支框架用于平移和旋转的直接回归。
3.2.2 Unsupervised Methods
上述有监督的方法都表现出了令人印象深刻的性能。然而,它们的大部分成功主要依赖于输入对之间大量的基-真值转换,这显著增加了它们的训练成本。此外,由于传感器误差或对传统SfM流水线的依赖而没有收敛性保证,获得准确的转换标签可能是具有挑战性的 232 。为了避免这种情况,最近的努力集中在开发无监督注册网络。基于输入类型,无监督方法可以大致分为两类:基于成对视图和基于单视图。
(i) Pair-view-based.
这些方法通常使用点云对训练网络,并在没有真实信息的情况下设计损失函数。我们可以将其归纳为两种范式进行讨论,即迭代范式和一次性范式。
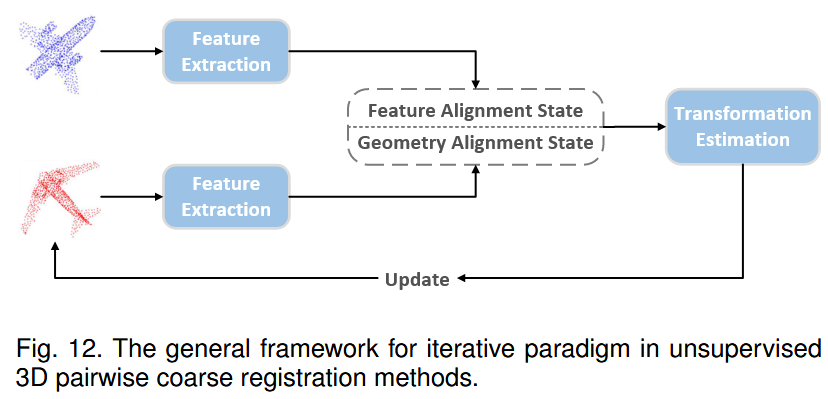
1) Iterative paradigm.
这些方法类似于监督方法中常用的多阶段范式,在训练和推断阶段迭代地进行点云配准。此外,两种策略,即特征对齐和几何对齐,用于对齐输入对,如图12所示。
在特征对齐策略中,研究者 233 234 163 235 通常基于特征投影误差来估计刚性变换。这些方法强调提取的特征需要与输入的刚性位姿相关。例如,Huang等人 233 设计了一个自动编码器框架来提取几何和变换信息,随后 234 和 163 相继提出。Yuan et al Zhang等 235 在特征提取模块中进一步最大化多层互信息,以获得判别性和较少冗余的表示。Zhang等 187 直接利用SE ( 3 ) -等变特征进行直接特征空间配准。
相反,几何对齐策略需要获得点级的对应关系,以使用SVD算法来估计变换。例如,Jiang等人 236 引入了软对应来生成伪目标,并将几何对准误差纳入到损失函数中。基于此,Shen等人 167 在伪目标生成和损失函数定义中提出了局部邻域一致性和空间一致性,以提高内点对应的比率,紧接着 237 179 238 。Jiang等人 239 和Zheng等人 240 结合输入对之间的特征交互机制进行内点对应识别。为了提高效率,Xie等 188 构建了一系列的配准块。 这些块随着时间循环地级联和展开,以实现效率和精度之间的平衡。同时,聂辉华等 241 在最小对应集合内进行变换估计。迭代范式通常会产生更精确的配准结果,但需要更大的计算资源,这也是大多数方法专注于物体点云数据集的原因。
2) One-shot paradigm
与迭代范式不同,该范式通常只以一次性的方式对输入对进行注册。因此,这些方法在训练过程中往往侧重于挖掘先验信息或从无标签数据中生成伪标签,以提升配准性能。如图13所示。
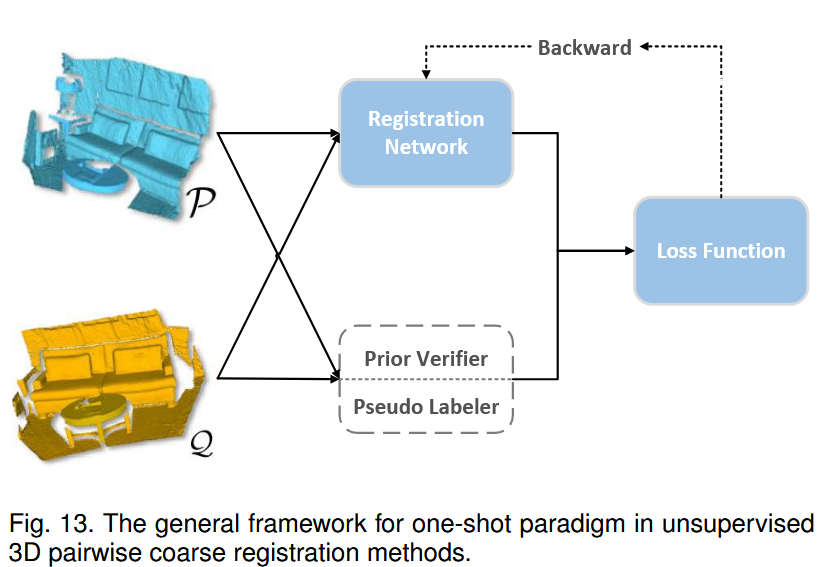
对于伪标号,Yang等人 162 和Lowens等人 242 提出了教师-学生框架,其中教师模块生成点对应作为伪标号。然后,在学生模块训练阶段之前,通过验证器对这些标签进行过滤,以去除低置信度的对应项。Liu等人 186 进一步将该框架以渐进的方式扩展到远距离点云配准。
对于先验信息,一些研究者选择挖掘几何先验。例如,Kadam等 243 在其Point Hop 244 框架的基础上,引入LRF来捕获变换不变信息,构建多尺度下的匹配对应。Zhang等人 245 训练了他们的网络来对齐输入对和一个标准姿态。Li等人 246 结合刚性变换的正交性和循环一致性来指导网络训练。Huang等人 247 和Mei等人 178 使用GMMs对局部几何进行建模,以评估损失函数中注册的质量。另一些研究者引入了语义信息,如形状先验和颜色信息。例如,Hao等 248 和Li等 249 通过部分分割和形状补全获得形状先验,以提高物体点云配准的性能。Banani等人 161 250 结合RGB - D信息来辅助训练他们的室内点云配准网络。与迭代范式相比,只出一期的杂志范式更加灵活,更适用于多样且复杂的数据集。近年来,Liu等人 251 将只出一期的杂志范式扩展到大规模LiDAR点云数据集。
(ii) Single-view-based
这些方法旨在仅使用一个点云作为输入来训练它们的网络,这就消除了对"配对数据"的需求,显著降低了数据获取的难度。根据其训练策略的不同,这些方法可以大致分为重建驱动和成对生成驱动。
1) Reconstruction-driven
这些方法通常设计一个自动编码器框架来重构输入数据,从而学习输入的紧凑表示。例如,Deng等 152 在PPFNet 151 和FoldingNet 214 的基础上开发了PPF - FoldNet。该方法采用一种编码器-解码器框架,其中编码器以局部块的PPF表示 252 作为输入。与基于折叠的自动编码器框架相同,Marcon等人 168 使用球形CNN作为编码器,直接从关键点的原始局部块中提取旋转等价的局部描述符,保证了输入信息的完整性。
2) Pair-generation-driven.
这些方法通过从单视图输入中生成合适的配准对来训练配准网络。例如,Sun等人 253 通过对输入点云施加随机刚性变换来生成配准对。Wang等人 156 通过随机抽样模拟了部分重叠场景。然而,由于真实世界场景中的噪声、部分重叠和遮挡种类繁多,成对生成范式难以在不同条件下产生大量的点云对用于配准。近年来,一些工作 254 185 181 将成对生成融入到数据增强管线中,以扩大监督学习的数据集规模。
3.3 Summary
下面概述两两粗配准方法在三维点云配准中的发展及特点。
- 基于对应的几何方法。与几何局部特征检测器和描述子相比,近年来更多的研究关注于对应优化和变换估计。现有方法处理低内点比率问题仍然具有挑战性。
- 无对应几何方法。这些方法通常通过参数搜索来求解最优的最大一致解。然而,6 - DoF的高维搜索空间导致了指数级的时间复杂度。因此,基于BnB的方法由于其全局最优解和有效性而越来越受欢迎。
- 基于学习的方法。现有的大多数针对这条线的研究都是有监督的,取得了很大的精度提升。然而,提高泛化能力和培养无监督方法值得进一步研究。
会分节介绍PAIRWISE FINE REGISTRATION 、MULTI-VIEW COARSE REGISTRATION、 MULTI-VIEW FINE REGISTRATION、OTHER REGISTRATION PROBLEMS、CHALLENGES AND OPPORTUNITIES