1、常用函数汇总
👏
下表是探索数据过程中一些常用的函数:
| 函数 | 解释 |
|---|---|
01、df.head() |
查看前 5 行 |
02、df.tail(3) |
查看后 3 行 |
03、df.copy() |
复制数据框 |
04、df.sample(3) |
随机查看 3 行 |
05、df.shape |
行\列数 |
06、df.columns |
列名称 |
07、df.index |
行索引 |
08、df.dtypes |
数据类型 |
09、df.count() |
非缺失计数 |
10、df.info() |
概况 |
11、df.describe() |
数值变量统计量 |
12、df.quantile() |
数值变量分位数 |
13、df.skew() |
偏态系数 |
13、df.kurt() |
峰态系数 |
14、np.unique(df['C']) |
唯一值 |
14、df['C'].unique() |
唯一值 |
15、df['C'].nunique() |
唯一值计数 |
16、df.value_counts() |
分组计数 |
17、df.sort_values() |
按列排序 |
18、df.sort_index() |
按轴排序 |
19、df.sum() |
求和 |
20、df.mean() |
均值 |
21、df.median() |
中位数 |
22、df.min() |
最小值 |
23、df.max() |
最大值 |
24、df.mode() |
众数 |
25、df.var() |
方差 |
26、df.std() |
标准差 |
| ...... |
2、常用函数案例
(01)df.head()
python
import pandas as pd
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 查看前 5 行数据
df.head()
(02)df.tail()
python
import pandas as pd
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 查看后2行
df.tail(2)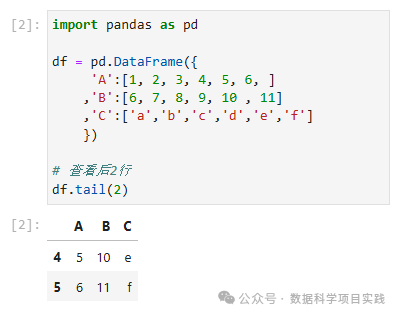
(03)df.copy()
python
import pandas as pd
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 使用copy方法复制数据框
df_copy = df.copy()
# 查看df_copy前5行
df_copy.head()
(04)df.sample()
python
import pandas as pd
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 随机查看3行
df.sample(3)
(05)df.shape()
python
import pandas as pd
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 查看数据集的行数和列数
df.shape
(06)df.columns
python
import pandas as pd
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 查看列名称
df.columns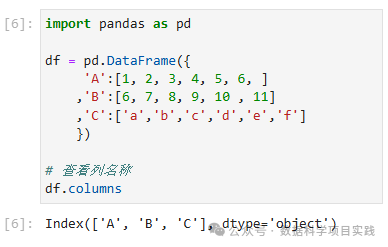
(07)df.index
python
import pandas as pd
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 查看行索引
df.index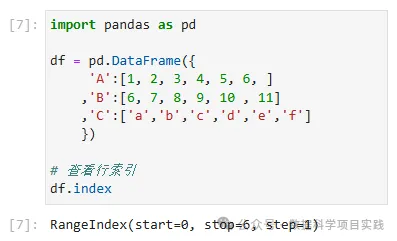
(08)df.dtypes
python
import pandas as pd
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 查看数据类型
df.dtypes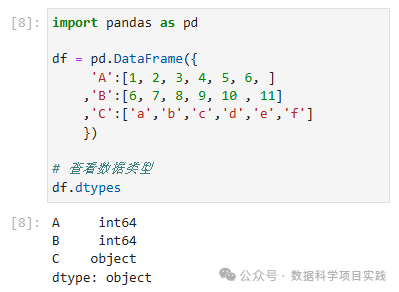
(09)df.count()
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
df.loc[df['A']==2, 'B'] = np.nan
# 列非缺失计数
df.count()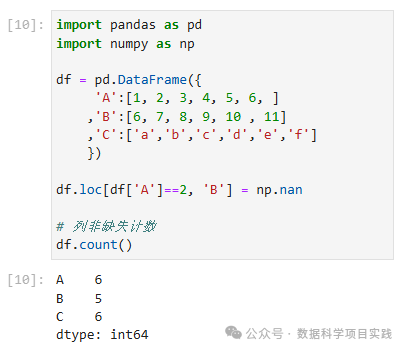
(10)df.info()
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
df.loc[df['A']==2, 'B'] = np.nan
# 数据概况
df.info()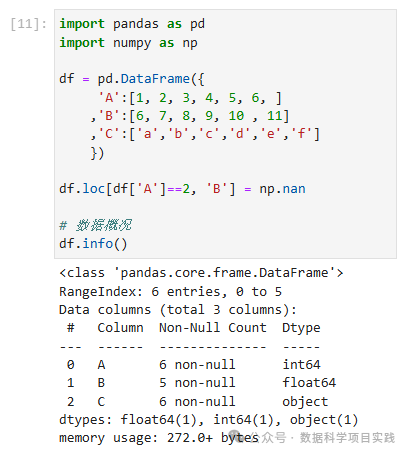
(11)df.describe()
👏
查看数值变量的描述性统计量:count, mean, std, min, max
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
df.loc[df['A']==2, 'B'] = np.nan
# 查看数值变量的描述性统计量
df.describe().T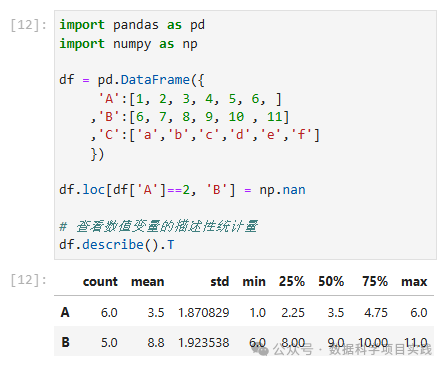
👏
查看分类变量的描述性统计量:count, unique, top, freq
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6, ]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
df.loc[df['A']==2, 'B'] = np.nan
# 查看分类变量的描述统计
# df.describe(include='object').T
df.describe(include='O').T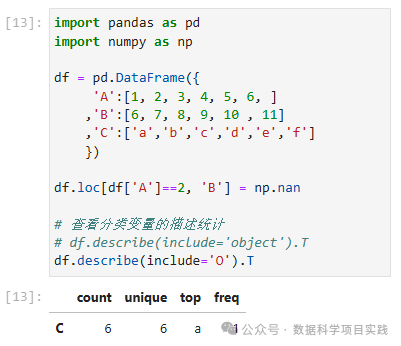
(12)df.quantile()
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
df.loc[df['A']==2, 'B'] = np.nan
# 查看数值变量中位数、50%分位数
print(df['A'].quantile())
print(df['A'].quantile(q=0.5), '\n')
# 查看数值变量上\下四分位数
print(df['A'].quantile([0.25, 0.75]))
(13)df.skew\kurt()
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
df.loc[df['A']==2, 'B'] = np.nan
# 查看数值变量的分布情况
print(df['B'].skew()) # 偏度系数
print(df['B'].kurt()) # 峰度系数
(14)np.unique()\df.unique()
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
print(np.unique(df['C'])) # 查看唯一值
print(df['C'].unique()) # 查看唯一值
(15)df.nunique()
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
print(df['C'].nunique()) # 查看唯一值个数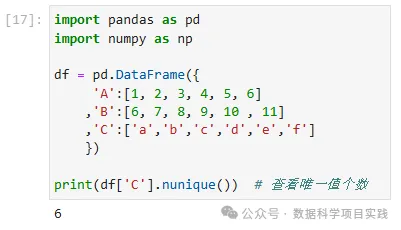
(16)df.value_counts()
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 查看唯一值个数
print(df['C'].value_counts()) 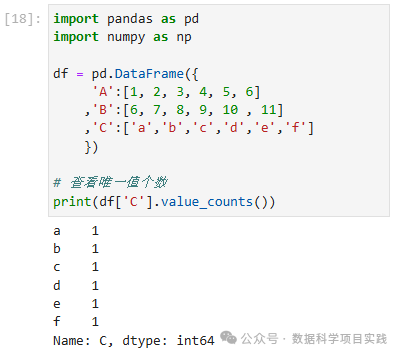
(17)df.sort_values()
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
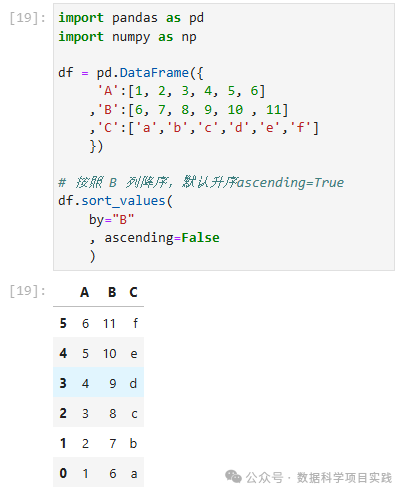
# 按照 B 列降序,默认升序ascending=True
df.sort_values(
by="B"
, ascending=False
)
(18)df.sort_index()
👏
按照行索引降序
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 按照行索引降序
df.sort_index(
axis=0
, ascending=False
)
👏
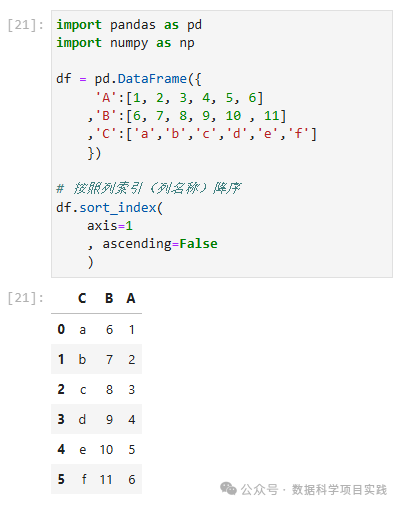
按照列索引(列名称)降序
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 3, 4, 5, 6]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','e','f']
})
# 按照列索引(列名称)降序
df.sort_index(
axis=1
, ascending=False
)
(19)一些常见聚合函数(均值...)
python
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A':[1, 2, 2, 4, 5, 6]
,'B':[6, 7, 8, 9, 10 , 11]
,'C':['a','b','c','d','d','f']
})
# 连续变量常见统计量:均值、中位数、众数......
A=df['A']
print('Mean: ',A.sum(),'\n') # 求和
print('mean: ',A.mean(),'\n') # 均值
print('median: ',A.median(),'\n') # 中位数
print('min: ',A.min(),'\n') # 最小值
print('max: ',A.max(),'\n') # 最大值
print('mode: ',A.mode(),'\n') # 众数
print('var: ',A.var(),'\n') # 方差
print('std: ',A.std(),'\n') # 均方差
# 分类变量常见统计量:众数
print('mode: ',df['C'].mode(),'\n') # 众数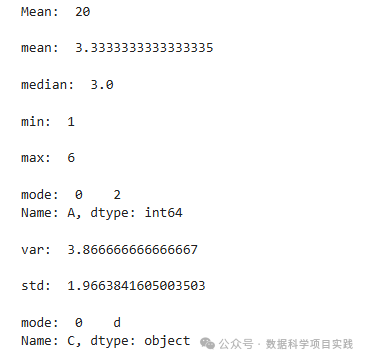
👏
总结: 以上介介绍了 pandas 中一些探索数据常用的函数,下一篇将尝试自定义模块,将上面这些函数结合在一起使用。更多的
pandas函数可以查看 pandas 函数
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| #### Python 端到端的机器学习 AI入门:详细介绍机器学习建模过程,步骤细节;以及人工智能的分阶段学习线路图。 🚀 点击查看 |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| #### 统计学习\机器学习\深度学习算法 介绍有关统计学习,机器学习,深度学习的算法。 🚀 点击查看 |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| #### SQL + Pandas 练习题 SQL 练习题目,使用 Pandas 库实现,使用 Sqlalchemy 库查看 SQL 代码血缘关系。 🚀 点击查看 |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| #### Python 数据可视化 介绍了有关 Matplotlib,Seaborn,Plotly 几个 Python 绘图库的简单使用。 🚀 点击查看 |