TL;DR(三行:场景/结论/产出)
- 场景:电商秒杀/票务抢购等瞬时洪峰写入,读多写多并存,数据库与服务链路易被打穿。
- 结论:前置静态化与限流排队;写路径用 Redis Lua 原子预扣+MQ 异步落库;读路径多级缓存与更新策略;全链路监控与隔离降级。
- 产出:一套可落地的"秒杀前/秒杀中/读写分治/MQ 解耦"工程清单 + Kafka 生产消费示例 + Lua 扣库存脚本框架。
应用场景
消息中间件的使用场景非常广泛,比如12306、电商秒杀、大数据实时计算等等。
电商案例
高并发秒杀系统应对策略
秒杀开始前的应对策略
-
页面静态化处理
- 将商品详情页提前生成静态HTML,减少动态渲染的开销
- 使用CDN分发静态资源,减轻服务器压力
- 示例:京东秒杀页面会提前10分钟生成静态快照
-
请求限流与排队
- 实施分层限流策略:
- 前端JS限制刷新频率(如每5秒才能刷新一次)
- 网关层限制IP请求频率(如100次/分钟)
- 服务层限制接口调用频率
- 实现虚拟排队机制,给用户分配排队号
- 实施分层限流策略:
-
缓存预热
- 提前将秒杀商品信息加载到Redis缓存
- 使用多级缓存架构(本地缓存+分布式缓存)
- 示例:天猫双11会提前2小时预热热点商品数据
秒杀开始时的核心处理
- 库存扣减优化
- 采用Redis原子操作预扣减库存
- 实现方案:
lua
-- Lua脚本保证原子性
if redis.call('get', 'stock') > 0 then
redis.call('decr', 'stock')
return 1
end
return 0- 异步落库:先扣Redis库存,再异步更新数据库
-
订单处理分流
- 使用消息队列削峰填谷
- 架构:请求→快速校验→MQ→异步处理订单
- 示例:Kafka集群处理秒杀订单消息
- 实现订单ID预生成,避免ID生成成为瓶颈
- 使用消息队列削峰填谷
-
服务隔离与降级
- 独立部署秒杀服务,与主业务隔离
- 关键降级策略:
- 关闭非核心功能(如推荐、评论)
- 简化业务流程(如跳过风控校验)
- 示例:小米秒杀会临时关闭商品详情页的3D展示功能
-
监控与弹性扩容
- 实时监控关键指标(QPS、响应时间、错误率)
- 自动扩容策略:
- 基于CPU/内存使用率自动扩缩容器
- 预先准备备用服务器池
- 示例:阿里云在双11期间会自动扩容300%的计算资源
高并发读请求处理方案
1. 缓存策略优化
缓存是应对高并发读请求的第一道防线,可以有效减轻数据库压力:
-
多级缓存架构:
- 客户端缓存(浏览器/APP本地缓存)
- CDN边缘节点缓存
- 应用层缓存(Redis/Memcached)
- 数据库查询缓存
-
缓存预热:在流量高峰前预先加载热点数据到缓存
-
缓存更新策略:
- 定时刷新(适合时效性要求不高的数据)
- 失效后重新加载(Cache Aside模式)
- 写操作时同步更新(Write Through模式)
示例:电商商品详情页可使用Redis缓存,设置5分钟过期时间,同时后台定时任务每3分钟更新一次热点商品缓存。
2. 数据静态化处理
将动态内容转化为静态资源可大幅提升系统吞吐量:
-
全静态化:
- 生成HTML文件托管到CDN
- 适用于内容变更频率低的数据(如新闻文章、产品说明)
-
半静态化:
- 静态模板+动态数据片段
- 通过ESI(Edge Side Includes)或SSI(Server Side Includes)技术实现
- 例如商品详情页框架静态化,价格和库存动态加载
-
静态资源优化:
- 启用Gzip压缩
- 合理设置HTTP缓存头(Cache-Control、ETag)
- 使用内容哈希实现长期缓存
3. 智能限流机制
合理的限流策略可以保护系统不被突发流量冲垮:
-
限流维度:
- 用户ID限流(防止单个用户高频刷新)
- IP限流(防止爬虫或恶意攻击)
- 设备指纹限流(针对移动端设备)
- 接口级别限流(保护核心接口)
-
限流算法:
- 令牌桶算法(允许突发流量)
- 漏桶算法(平滑流量)
- 滑动窗口计数(精确控制单位时间请求数)
-
分级处理:
- 正常请求:放行
- 可疑请求:延迟响应
- 恶意请求:直接拒绝并加入黑名单
实现示例:使用Redis+Lua脚本实现分布式限流,针对/api/product/:id接口设置每秒100次的访问限制,超出限制的请求返回429状态码。
高并发写请求的系统处理方案
高并发写请求的挑战
在高并发场景下,如电商秒杀活动、票务系统抢购等,系统会面临大量写请求同时涌入的问题。以电商秒杀为例:
- 订单生成:每个用户请求都需要创建新订单记录
- 库存扣减:热门商品可能面临数千次/秒的库存变更
- 用户操作:包括支付、优惠券使用等关联操作
当这些请求直接到达数据库时,会导致:
- 数据库连接池迅速耗尽
- 磁盘I/O瓶颈出现
- 锁竞争加剧,响应时间急剧上升
- 最终可能导致数据库服务崩溃
消息队列解决方案
1. 流量削峰
消息队列作为缓冲层,平滑处理突发流量:
- 将瞬时1万QPS的写请求暂存到队列中
- 数据库按照自身处理能力(如2000QPS)从队列中消费
- 实现"削峰填谷",保护下游系统
典型应用场景:
- 电商秒杀:将抢购请求先存入队列,再异步处理
- 社交网络:用户发布内容时先入队列,再持久化
2. 异步处理
将业务流程拆分为多个异步阶段:
-
快速响应阶段:
- 验证用户资格
- 生成预订单
- 立即返回"抢购成功"反馈
-
异步处理阶段:
- 实际扣减库存
- 生成正式订单
- 通知支付系统
- 更新用户资产
优势:
- 前端响应时间从500ms降至50ms
- 后端处理压力被分散到不同时间段
- 失败操作可以重试,提高系统鲁棒性
3. 系统解耦
通过消息队列实现模块间松耦合:
- 订单服务只负责生成订单消息
- 库存服务独立消费库存变更消息
- 支付服务监听支付相关消息
架构优势:
- 各服务可独立扩容(如库存服务需要更多资源)
- 故障隔离(支付系统宕机不影响下单)
- 便于后期扩展新功能(如增加优惠券服务)
实现示例
以Kafka为例的典型实现:
java
// 生产者(前端服务)
public void handleSeckillRequest(UserRequest request) {
// 1. 基础验证
if(!validate(request)) return;
// 2. 生成预订单
PreOrder preOrder = createPreOrder(request);
// 3. 发送到消息队列
kafkaTemplate.send("seckill_orders", preOrder);
// 4. 立即返回响应
return Response.success("抢购请求已接收");
}
// 消费者(订单服务)
@KafkaListener(topics = "seckill_orders")
public void processOrder(PreOrder preOrder) {
try {
// 1. 扣减库存
inventoryService.reduceStock(preOrder);
// 2. 生成正式订单
orderService.createRealOrder(preOrder);
// 3. 触发支付
paymentService.preparePayment(preOrder);
} catch (Exception e) {
// 失败重试或补偿处理
retryOrCompensate(preOrder, e);
}
}削峰填谷
在高并发秒杀场景中,引入消息队列是常见的系统优化方案。具体实现流程如下:
- 请求缓冲阶段:
- 用户提交秒杀请求后,业务服务器立即生成唯一请求ID
- 将请求信息(用户ID、商品ID、时间戳等)序列化为JSON格式
- 将消息写入RabbitMQ/Kafka等消息队列的秒杀专用Topic
- 同步返回用户"秒杀请求已接收,正在处理中..."的提示信息
- 典型响应时间可控制在50ms以内,快速释放Web服务器连接
- 流量削峰机制:
- 消息队列作为缓冲区,可以平滑处理瞬间的流量高峰(如10万QPS)
- 设置队列最大积压量(如50万条)作为熔断阈值
- 超出阈值时触发限流,提示"当前参与人数过多,请稍后再试"
- 正常情况下的消息积压会产生200ms-2s的延迟,但对秒杀场景可以接受
- 并发处理优化:
- 假设秒杀商品库存为10000件,单次库存扣减耗时500ms
- 单线程处理需要5000秒(约83分钟),完全不可行
- 部署10个消费者组(Consumer Group),每个组包含:
- 5个并行消费者进程
- 独立连接池(20个数据库连接)
- 理论处理时间缩短至50秒(5000s/(10×5)=50s)
- 实际数据库QPS控制在200左右(10组×20连接),在MySQL承受范围内
- 用户体验权衡:
- 前端设计需明确提示"预计等待时间约1分钟"
- 采用WebSocket推送处理结果,避免用户主动刷新
- 最终结果包含三种状态:
- 成功:显示订单确认信息
- 失败:提示"已售罄"或"未抢到"
- 超时:提示"处理超时,请查看订单确认"
该方案在京东618、天猫双11等大型促销活动中均有成熟应用,核心优势在于:
- 将数据库写入QPS从万级降至百级
- 通过水平扩展消费者组可线性提升处理能力
- 50秒左右的延迟在秒杀场景中属于合理等待范围
- 系统稳定性提升3-5个数量级在高并发秒杀场景中,引入消息队列是常见的系统优化方案。具体实现流程如下:
- 请求缓冲阶段:
- 用户提交秒杀请求后,业务服务器立即生成唯一请求ID
- 将请求信息(用户ID、商品ID、时间戳等)序列化为JSON格式
- 将消息写入RabbitMQ/Kafka等消息队列的秒杀专用Topic
- 同步返回用户"秒杀请求已接收,正在处理中..."的提示信息
- 典型响应时间可控制在50ms以内,快速释放Web服务器连接
- 流量削峰机制:
- 消息队列作为缓冲区,可以平滑处理瞬间的流量高峰(如10万QPS)
- 设置队列最大积压量(如50万条)作为熔断阈值
- 超出阈值时触发限流,提示"当前参与人数过多,请稍后再试"
- 正常情况下的消息积压会产生200ms-2s的延迟,但对秒杀场景可以接受
- 并发处理优化:
- 假设秒杀商品库存为10000件,单次库存扣减耗时500ms
- 单线程处理需要5000秒(约83分钟),完全不可行
- 部署10个消费者组(Consumer Group),每个组包含:
- 5个并行消费者进程
- 独立连接池(20个数据库连接)
- 理论处理时间缩短至50秒(5000s/(10×5)=50s)
- 实际数据库QPS控制在200左右(10组×20连接),在MySQL承受范围内
- 用户体验权衡:
- 前端设计需明确提示"预计等待时间约1分钟"
- 采用WebSocket推送处理结果,避免用户主动刷新
- 最终结果包含三种状态:
- 成功:显示订单确认信息
- 失败:提示"已售罄"或"未抢到"
- 超时:提示"处理超时,请查看订单确认"
该方案在京东618、天猫双11等大型促销活动中均有成熟应用,核心优势在于:
- 将数据库写入QPS从万级降至百级
- 通过水平扩展消费者组可线性提升处理能力
- 50秒左右的延迟在秒杀场景中属于合理等待范围
- 系统稳定性提升3-5个数量级
异步处理
在系统设计中采用主次业务分离的处理方式,可以显著提升核心业务性能。以电商秒杀场景为例,我们可以将业务流程拆解如下:
核心业务流程(同步处理):
- 订单生成:验证用户信息、生成唯一订单号、记录订单基础信息
- 库存扣减:执行原子性库存操作,确保不超卖
- 采用乐观锁或分布式锁机制
- 记录库存变更流水
次要业务流程(异步处理):
- 优惠券发放:通过消息队列触发
- 检查用户资格
- 发放指定面额优惠券
- 记录发放日志
- 积分处理:
- 计算本次交易应得积分
- 更新用户积分账户
- 记录积分变更明细
对于数据同步的解耦方案,两种实现方式的详细对比如下:
-
直接接口调用方案:
- 实现方式:通过HTTP/RPC实时调用
- 优点:数据实时性强
- 缺点:
- 强耦合,任一服务故障都会影响整体
- 性能瓶颈明显,特别是在高并发场景
- 需要处理重试、降级等复杂逻辑
- 适用场景:对实时性要求极高的关键业务数据
-
消息队列方案:
- 实现架构:
- 生产者:秒杀服务将数据封装为消息
- 消息中间件:Kafka/RabbitMQ等
- 消费者:数据服务订阅处理
- 优点:
- 完全解耦,服务间无直接依赖
- 支持削峰填谷,应对流量高峰
- 天然支持重试机制
- 缺点:
- 存在一定延迟(通常毫秒级)
- 需要额外维护消息中间件
- 典型实现步骤:
- 秒杀服务将数据序列化为JSON格式
- 发送至指定Topic/Queue
- 数据服务消费消息
- 进行数据校验和持久化
- 确认消息处理完成
- 实现架构:
在实际项目中,通常会根据数据重要性和实时性要求混合使用两种方案。例如:
- 关键交易数据:双写+消息队列补偿
- 用户行为数据:纯消息队列方案
- 财务报表数据:定时批处理+实时消息补充
消息队列的具体选型建议:
- Kafka:高吞吐、持久化场景
- RabbitMQ:复杂路由需求
- RocketMQ:金融级事务场景
- Pulsar:多租户、云原生场景在系统设计中采用主次业务分离的处理方式,可以显著提升核心业务性能。以电商秒杀场景为例,我们可以将业务流程拆解如下:
核心业务流程(同步处理):
- 订单生成:验证用户信息、生成唯一订单号、记录订单基础信息
- 库存扣减:执行原子性库存操作,确保不超卖
- 采用乐观锁或分布式锁机制
- 记录库存变更流水
次要业务流程(异步处理):
- 优惠券发放:通过消息队列触发
- 检查用户资格
- 发放指定面额优惠券
- 记录发放日志
- 积分处理:
- 计算本次交易应得积分
- 更新用户积分账户
- 记录积分变更明细
对于数据同步的解耦方案,两种实现方式的详细对比如下:
-
直接接口调用方案:
- 实现方式:通过HTTP/RPC实时调用
- 优点:数据实时性强
- 缺点:
- 强耦合,任一服务故障都会影响整体
- 性能瓶颈明显,特别是在高并发场景
- 需要处理重试、降级等复杂逻辑
- 适用场景:对实时性要求极高的关键业务数据
-
消息队列方案:
- 实现架构:
- 生产者:秒杀服务将数据封装为消息
- 消息中间件:Kafka/RabbitMQ等
- 消费者:数据服务订阅处理
- 优点:
- 完全解耦,服务间无直接依赖
- 支持削峰填谷,应对流量高峰
- 天然支持重试机制
- 缺点:
- 存在一定延迟(通常毫秒级)
- 需要额外维护消息中间件
- 典型实现步骤:
- 秒杀服务将数据序列化为JSON格式
- 发送至指定Topic/Queue
- 数据服务消费消息
- 进行数据校验和持久化
- 确认消息处理完成
- 实现架构:
在实际项目中,通常会根据数据重要性和实时性要求混合使用两种方案。例如:
- 关键交易数据:双写+消息队列补偿
- 用户行为数据:纯消息队列方案
- 财务报表数据:定时批处理+实时消息补充
消息队列的具体选型建议:
- Kafka:高吞吐、持久化场景
- RabbitMQ:复杂路由需求
- RocketMQ:金融级事务场景
- Pulsar:多租户、云原生场景
购票程序
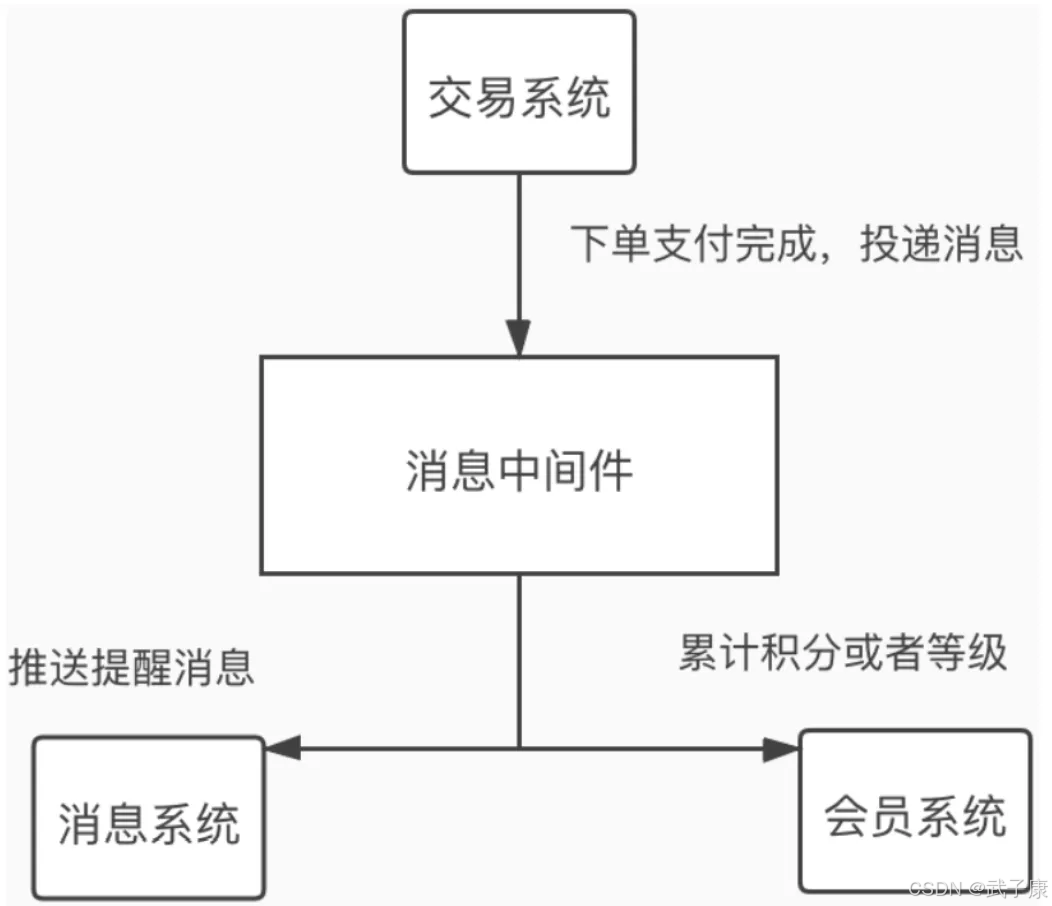
如上图,用户在支付宝购买了一张电影票之后很快就收到了消息推送和短信(电影院地址、几号厅、座位号、场次时间),同时用户会积累一定的会员积分。
这里,交易系统并不需要一直等待消息送达等动作都完成后才返回成功,允许一定延迟和瞬时不一致(最终一致性),而且后面两个动作通常可以并发执行。
如果后期监控大盘想要获取实时交易数据,只需要新增个消费者程序并订阅该消息即可,交易系统对此并不感知,松耦合。
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 出现超卖/库存为负 | 库存扣减非原子;DB 扣减在高并发下锁竞争+重试导致乱序 | 对比 Redis 库存与 DB 库存;检查扣减是否单点原子 | Redis Lua 原子预扣;DB 落库用"扣减条件更新/乐观锁";全链路幂等 |
| 用户下单成功但订单不存在/延迟很久 | MQ 积压或消费者不足;消费失败重试导致延迟拉长 | 看 Topic/Queue lag、消费速率、失败重试次数 | 增加分区/消费者并发;隔离重试队列;对失败做补偿而非无限重试 |
| 订单重复生成/重复扣减 | 至少一次投递 + 消费端无幂等;重试导致重复消费 | 检查业务唯一键(requestId/orderId)是否参与去重 | 消费端幂等:唯一索引/去重表/幂等键;处理前先判重 |
| 消息"丢了" | 生产端未确认;Broker 未持久化;消费 ACK 时机错误 | 检查 producer acks/confirm;Broker 持久化与副本;消费端提交 offset/ACK 日志 | Kafka:acks=all + 合理重试;RabbitMQ:confirm+持久化;消费端先落库再 ACK |
| 秒杀接口大量 5xx/线程池打满 | 同步链路过长(风控/库存/下单都同步);未做快速失败与排队 | 看接口 RT、线程池队列长度、下游依赖 RT | 同步只做快速校验+入队;其它异步;加排队号/快速失败 |
| Redis CPU 飙高/延迟突增 | 热 key、Lua 脚本过重、连接数过大 | Redis 慢日志、热 key 统计、客户端连接数 | 热 key 分片/本地缓存;Lua 只做最小逻辑;连接池与超时治理 |
| 限流误杀正常用户 | 粒度过粗(按 IP);规则未区分登录态/接口类型 | 统计被限流分布(IP/UID/UA/接口) | 组合维度(UID+接口);分级阈值;灰度调整与白名单 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-196 消息队列选型:RabbitMQ vs RocketMQ vs Kafka
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接