基本信息
题目:A Survey on 3D Gaussian Splatting
来源:arXiv 2024
学校:浙江大学
是否开源:https://github.com/guikunchen/Awesome3DGS
https://github.com/guikunchen/3DGS-Benchmarks
摘要:三维高斯泼溅( GS )已成为辐射领域的一种变革性技术。与主流的隐式神经模型不同,3D GS使用数百万个可学习的3D高斯进行显式场景表示。结合可微分渲染算法,该方法实现了实时渲染和前所未有的可编辑性,使其成为三维重建和表示的潜在游戏规则改变者。在本文中,我们首次系统地综述了3D GS的最新进展和重要贡献。我们首先详细探究了3D GS产生的潜在原理和背后的驱动力,为理解其意义做了铺垫。我们讨论的一个重点是3D GS的实际应用性。 通过实现前所未有的渲染速度,3D GS开辟了大量的应用,从虚拟现实到交互式媒体等。此外,本文还对领先的3D GS模型进行了比较分析,并在各种基准任务中进行了评估,以突出它们的性能和实际效用。调查最后指出了当前的挑战,并提出了未来研究的潜在途径。通过这项调查,我们旨在为新手和经验丰富的研究人员提供有价值的资源,以促进在外显辐射领域的进一步探索和发展。
4 3D GAUSSIAN SPLATTING: DIRECTIONS
4.3 Photorealistic 3D GS
目前3D GS ( Sec。3 . 1 )的渲染管线是直接的,并且涉及到一些缺点。例如,简单的可见性算法可能会导致高斯深度/混合顺序的剧烈切换 96 。渲染图像的视觉保真度,包括锯齿、反射和伪影等方面,可以进一步优化。
最近的研究集中于解决视觉质量的三个主要方面,其中锯齿现象是3D GS渲染算法所特有的,而反射和模糊处理则代表了三维重建中更广泛的挑战。
- 锯齿现象。由于离散采样范式(将每个像素看成一个单点,而不是一个区域),3D GS在处理不同分辨率时容易发生混叠,导致边缘模糊或锯齿状。在训练和推理阶段都出现了解决方案。研究人员从采样率的角度开发了训练时间的改进,并引入了多尺度高斯 257 ,2D Mip滤波器 276 和条件逻辑函数 128 等方案。 推理时间解决方案,如2D尺度自适应滤波 207 ,提供了增强的保真度,可以集成到任何现有的3D GS框架中。
- 反射。实现反光材料的真实感绘制是三维场景重建中一个长期难以解决的问题。最近的工作介绍了各种方法来对反射材料 87、151、264 进行建模,并实现了可重读的高斯表示 191 ,尽管实现物理上精确的镜面效果仍然具有挑战性。
- 模糊。虽然3D GS在仔细检查的数据集上表现优异,但真实世界的捕获经常会遭受诸如运动模糊和散焦模糊等模糊的影响。最近的方法在训练过程中明确地结合了模糊建模,采用了一些技术,如从粗到细的核优化 172 和光度捆绑调整 296 来解决这个挑战。
虽然在3D GS ( Sec。3 . 1 )中进行的近似有助于提高其计算效率,但它们也会导致混叠、光照估计困难等问题。目前的解决方案虽然令人印象深刻,但通常是解决个别问题,而不是提供一个通用的解决方案。一种实用的中间方法包括首先检测特定问题( e.g. ,混叠,模糊),然后应用有针对性的优化策略。最终目标仍然是开发一种先进的重建系统,通过对3DGS的基本改进或通过全新的体系结构来克服这些限制。
4.4 Improved Optimization Algorithms
3DGS的优化提出了几个影响重建质量的挑战。这些问题包括收敛速度的问题,来自不合适的高斯的视觉伪影,以及在优化过程中需要更好的正则化。原始优化方法( Sec。3 . 2 )可能会导致部分区域重建过度而其他区域重建不足,从而导致模糊和视觉不一致。
改进3DGS的优化主要有三个方向:
- 附加正则化(如频率、几何形状 122 , 141 )。几何感知方法特别成功,通过结合局部锚点 141 ,深度和表面约束 23、277、282,高斯体积 22 等来保持场景结构。
- 优化过程增强 29、224、277。虽然密度控制( Sec。3 . 2 . 2 )的原始策略已被证明是有价值的,但仍有相当大的改进空间。例如,GaussianPro 29 通过一种先进的高斯稠密化策略解决了无纹理表面和大规模场景中稠密初始化的挑战。
- 约束松弛。 对外部工具/算法的依赖会引入错误并限制系统的性能潜力。例如,初始化过程中常用的SfM容易出错,难以应对复杂的场景。最近的工作已经开始探索利用流连续性 50、205 的COLMAP - free方法,这可能使从互联网规模的未放置视频数据集学习成为可能。
尽管令人印象深刻,但现有的方法主要集中在优化高斯模型以从头精确地重建场景,忽略了一个具有挑战性但很有前途的解决方案,即通过建立"元表示"以少数镜头的方式重建场景。这样的解决方案可以实现结合场景特定知识和通用知识的自适应元学习策略。参见Sec中的"从大规模数据中学习物理先验"。( 7 )进一步的洞见。
4.5 3D Gaussian with More Properties
尽管令人印象深刻,但3D高斯( Sec。3 . 1 )的性质被设计为仅用于新视角合成。通过对3D Gaussian进行扩展,使其具有额外的属性,如语言 180、202、315,语义/实例 19、268、303和时空 266 属性,3D GS展示了其彻底改变各种领域的巨大潜力。
在这里,我们列举了一些使用具有特殊性质的3D高斯的有趣应用。
- 语言嵌入场景表示 180、202、315。由于当前语言嵌入场景表示的高计算和存储需求,Shi等人 202 提出了一种量化方案,用精简的语言嵌入代替原始的高维嵌入来增强3D高斯。该方法在不确定值的指导下,通过平滑不同视图的语义特征,减轻了语义歧义,提高了开放词汇查询的精度。
- 场景理解与编辑 19、268、303。Feature 3DGS 303 从二维基础模型出发,将3D GS与特征场蒸馏集成。Feature 3DGS通过学习更低维度的特征场并应用轻量级卷积解码器进行上采样,在实现高质量特征场蒸馏的同时获得了更快的训练和渲染速度,支持语义分割和语言引导编辑等应用。
- 时空建模 131、266。为了捕获3D场景复杂的时空动态,Yang等人 266 将时空概念化为一个统一的实体,并使用4D高斯的集合来近似动态场景的时空体积。 所提出的4D高斯表示和相应的渲染管线能够建模空间和时间上的任意旋转,并允许端到端的训练。
4.6 Hybrid Representation
为了适应下游任务,另一种很有前途的方法是引入专门为特定应用量身定制的结构化信息(例如,空间MLPs和网格),而不是用附加属性来增强3D高斯。
接下来,我们展示了具有特殊设计的结构化信息的3D GS的各种迷人用途。
- 面部表情建模。考虑到在稀疏视图条件下创建高保真度3D头像的挑战,Gaussian Head Avatar 252 引入了可控的3D高斯和基于MLP的变形场。具体来说,它通过在形变场的旁边优化中性三维高斯来捕捉面部细节表情和动态,从而保证了细节保真度和表情精度。
- 时空建模。Yang等人 265 提出用可变形的3D高斯重建动态场景。可变形的3D高斯在典型空间中学习,并与变形场(即. ,a spatial MLP ),对时空动态进行建模。所提出的方法还结合了退火平滑训练机制,在不增加额外计算成本的情况下增强了时间平滑性。
- 风格迁移。Saroha等人 195 提出了GS in style,一种先进的实时神经场景风格化方法。为了在不牺牲绘制速度的情况下保持多个视图之间的内聚的风格化外观,他们使用预训练的3D高斯结合多分辨率哈希网格和小型MLP来生成风格化视图。简而言之,融入结构化信息可以作为适应与3D高斯的稀疏性和无序性不相容的任务的补充部分。
4.7 New Rendering Algorithm for 3D Gaussians
虽然基于光栅化的3DGS流水线提供了出色的实时性能,但它仍然受到固有的限制,包括对高畸变相机(对机器人技术至关重要)、二次射线(对于光学效果,如反射和阴影)和随机射线采样(在各种现有管道中需要)的低效处理。此外,在实际应用中,高斯不重叠且仅使用中心即可准确排序的假设经常被违背,导致相机运动改变排序顺序时产生时间伪影。
最近的工作 31、146、156探索了基于光线跟踪的渲染算法作为替代。例如,GaussianTracer 156 提出了一种新的高斯基元的射线追踪实现,并根据高斯基元的不均匀密度和交错性质设计了几种加速策略。EVER 146 给出了一种物理上精确的、常密度的椭球表示,它允许精确计算体绘制积分,而不是依赖于一些令人满意的近似。这一进步消除了弹出伪影。
得益于基本范式的转变,一些令人兴奋的可能性可能会出现,包括先进的光学效果(反射、折射、阴影、全局光照等。),对复杂相机模型的支持(高畸变镜头、卷帘快门效应等。),具有真实定向外观评价的物理精确渲染( vs .基于瓦片的近似)等。虽然这些能力目前伴随着额外的计算成本,但它们为未来在逆向渲染、物理材质建模、重光照和复杂场景重建等方面的研究提供必要的构建模块。
5 APPLICATION AREAS AND TASKS

在3D GS快速发展的基础上,跨越多个领域( c. f.图6)出现了广泛的创新应用,如机器人学( Sec。5 . 1 )、动态场景重建与表示( Sec。5 . 2 )、生成与编辑( Sec。5 . 3 )、化身( Sec。5 . 4 )、医疗系统( Sec。5 . 5 )、大规模场景重建( Sec。5 . 6 )、物理学( Sec。5 . 7 ),甚至其他科学学科 113 , 241 , 290 , 291。在这里,我们突出强调了3D GS的变革性影响和潜力的关键例子,并在Github中提供了更全面的集合。根据我们的分类标准,我们还提供了一组具有代表性的数据集( c. f.表1)。
5.1 Robotics
NeRF深刻地塑造了机器人学中场景表征的演变。然而,NeRF的计算成本是实时应用的关键瓶颈。从隐式表示到显式表示的转变,不仅加速了优化,而且解锁了对空间和结构场景数据的直接访问,使3D GS成为机器人技术的转换工具。其平衡高保真重建和计算效率的能力将3D GS定位为推进机器人在真实世界环境中感知、操作和导航的基石。
将GS集成到机器人系统中,在3个核心领域都取得了重大进展。在SLAM中,基于GS的方法 38、67、68、73、83、95、105、118、149、175、215、223、254、279、309在实时稠密建图方面表现优异但是面对固有的性能妥协。视觉SLAM框架,特别是RGB - D变体 95、215、279 ,利用深度监督来保证几何保真度,但在低纹理或运动退化的环境中会出现抖动。RGB - only方法 73、149、193 避开了深度传感器,但处理了尺度模糊和漂移问题。多传感器融合策略,如LiDAR集成 67、105、237 ,以牺牲标定复杂度为代价,增强了非结构化场景下的鲁棒性。语义SLAM 83、118、309 通过对象级语义扩展了场景理解,但由于基于颜色的方法中的光照敏感性或基于特征的方法中的计算开销而难以扩展。 基于3D GS的操作 2 , 81 , 140 , 203 , 299绕过了基于NeRF的方法中对辅助位姿估计的需求,通过高斯属性编码的几何和语义属性,实现了快速的单阶段任务,如静态环境下的抓取。多阶段操作 140、203 ,其中环境动态需要实时地图更新,需要对动态调整(例如,物体的运动和相互作用)、材料顺应性等进行显式建模。
3D GS在机器人领域的推进面临3个关键挑战。首先,在动态和非结构化环境中的适应性仍然至关重要:现实世界中的场景很少是静态的,需要系统在运动、遮挡和传感器噪声的情况下不断更新表示,而不牺牲准确性。其次,目前的语义映射方法依赖于昂贵的、特定场景的优化过程,限制了真实世界部署的可推广性和可扩展性。第三,不同于基于NeRF的系统可以使用MLP参数作为下游决策的输入特征,3D高斯固有的空间顺序缺失使得特征聚合变得复杂,目前还没有建立标准化的框架。 弥合高保真重建和可操作的语义/物理理解之间的鸿沟将定义3D GS的下一个前沿,超越被动映射,迈向具身智能。
5.2 Dynamic Scene Reconstruction
动态场景重建是指捕获和表示一个场景随时间 61、169、170、177变化的三维结构和外观的过程。这涉及到创建一个数字模型,以准确地反映场景中物体的几何、运动和视觉方面。动态场景重建在VR / AR、3D动画、自动驾驶 255、302、306等应用中至关重要。
3D GS适应动态场景的关键是时间维度的建模,它允许对随时间变化的场景进行表示。基于3D GS的动态场景重建方法 7、36、41、62、78、94、102、111、124、126、131、143、197、200、229、238、265、266、273总体上可以分为两大类,如第2节所述。4 . 5和SEC。4 . 6 .第一类利用附加场(如空间MLPs或网格)来模拟形变( Sec。4 . 6 )。例如,Yang等人 265 首次提出了针对动态场景的可变形3D高斯。这些3D高斯在标准空间中学习,可以用一个隐式形变场(作为MLP实现)来建模时空形变。 GaGS 142 设计了一组高斯分布的体素化,然后使用稀疏卷积提取几何感知的特征,然后用于变形学习。另一方面,第二类是基于场景变化可以编码成3D高斯表示的思想,并设计了专门的渲染流程( Sec。4 . 5 )。例如,Luiten等人 143 通过保持3D高斯的属性随时间保持不变,同时允许它们的位置和方向发生变化,引入动态3D高斯来对动态场景进行建模。Yang et al 266 设计了一种4D高斯表示,其中额外的属性用于表示4D旋转和球谐函数,以近似场景的时空体积。
虽然3D GS通过对高斯形变建模来推进动态场景重建,但其对细粒度图元的依赖限制了可扩展性和鲁棒性。目前的方法难以平衡计算效率和精度:小规模重建将动态和静态元素统一起来,但在大型环境中变得难以处理,通常需要人工先验来分割区域- -这是非结构化环境中的一个障碍。此外,缺乏物体级的运动推理会导致伪影和在长序列上较差的泛化能力。未来的工作可能优先考虑以对象为中心的框架,将高斯分组为持久性实体,以建模固有的运动解耦(动态vs .静态)。
5.3 Generation and Editing
内容生成和编辑代表了现代人工智能系统中两种基本的、内在关联的能力。虽然生成可以从零开始或条件输入 56、66、189 来合成新颖的数字内容,但编辑提供了关键的能力,以精确控制来改进、适应和操纵现有内容 287 。这些能力通过将初始内容创建与迭代精化相结合,彻底改变了创造性工作流,使应用程序从专业内容生产转变为交互式消费工具。
在生成方面的最新进展 10 , 28 , 47 , 64 , 85 , 98 , 109 , 114 , 123 , 127 , 132 , 136 , 150 , 159 , 165 , 185 , 220 , 221 , 244 , 251 , 258 , 261 , 263 , 269 , 271 , 281 , 285 , 304 , 313 , 314导致了三种主要方法的出现。
- 基于优化的方法 28、221、269提取扩散先验(梯度),用得分函数指导三维模型的更新。虽然这些方法显示出令人印象深刻的保真度,但由于在优化过程中需要比较多个视点,它们面临着巨大的计算开销。
- 基于重建的方法 109、150、220利用预训练的多视图扩散模型将生成问题重构为多视图重建任务。 虽然这种方法提供了一个直观和直接的解决方案,但它在保持视图一致性方面存在着根本的局限性。不同视点间缺乏严格的几何约束往往导致表面几何形状不一致和纹理质量下降,尤其是在视觉特征复杂的区域。
- 直接3D生成方法在3D表示 64、159、281 上训练扩散模型。虽然学习到的3D扩散模型促进了多视图一致性,但高昂的计算成本阻碍了提高生成多样性所必需的训练规模的扩大。
目前的3DGS编辑方面的工作 19、24、40、44、59、71、74、78、104、139、145、164、181、197、232、239、268、273、283、288、303、312主要分为两类。
- 第一类利用2D图像编辑模型(例如,基于扩散的编辑器)迭代优化3D高斯。早期的工作 24、44、164 采用了类似于生成方法的基于优化或重构的策略,但引入了任务特定的控制信号。然而,幼稚地在跨视图中独立应用2D编辑通常会引入多视图不一致性。随后的工作 232、233、239、288通过迭代优化或跨视图注意力来减轻这种情况,尽管这增加了对齐的计算成本。 一个值得注意的挑战是物体的非预期变形,这归因于2D编辑模型中的弱3D几何先验以及2D编辑与底层3D结构的协调困难。
- 第二类利用3D GS的显式特性,实现基于语义 19、71、181、268和关键点等嵌入属性的直接操作 78 。然而,由于本质上的挑战,这一类仍然没有得到充分的探索:固有排序的缺乏使得设计高效的索引方案变得复杂,而编辑属性(例如,纹理和几何)需要仔细的正则化和对齐以保持合理性。
5.4 Avatar
数字人,虚拟空间中用户的数字化表征,架起了物理与数字的桥梁,实现了沉浸式交互、身份表达等。横跨娱乐(博彩、虚拟影响者)、企业( AI代理、虚拟会议)、医疗保健和教育,它们支撑了元宇宙经济。AR和VR的发展放大了它们在重新定义社会、工业和创意景观方面的作用。
3DGS已经成为人体头像重建的有力工具,主要沿着两个方向发展:全身建模和以头部为中心的建模。对于全身替身 1、69、70、80、86、90、101、110、119、120、125、157、166、179、267、278、298,目前的方法通常将3D高斯锚定在标准空间中,并通过参数化的身体模型( e.g. , SMPL)或基于笼子的索具来变形它们,以模拟动态运动。这些方法采用了一种混合变形策略:线性混合蒙皮处理刚性骨骼变换,如关节旋转,而姿态条件变形场考虑了二次非刚性效应,如肌肉跳动。 对于头部化身 25、39、117、178、188、191、245、297、307,重点转移到复杂面部表情、细粒度几何图形( e.g . ,皱纹,头发)和动态语音驱动动画的建模上。技术主要是将参数化的可变形人脸模型( e.g. , FLAME)与可变形的3D高斯相结合,利用扩散策略和表情感知的形变场将刚性头部姿态与非刚性面部运动分离。这两个方向都利用了GS的速度优势和可编辑性,实现了快速训练、实时渲染和对形变的精确控制,同时解决了跨帧对应、拓扑灵活性和多视图一致性等方面的挑战。
在具有挑战性的场景(例如,遮挡、稀疏的单视图输入或松散的衣物)中重建和增强替身的交互性代表了关键的挑战和机遇。参数化的无模型方法通过直接从数据中学习蒙皮权重来绕过预定义的先验,在此类场景中表现出很好的前景。与此相辅相成的是,生成模型可以减轻欠约束设置中固有的歧义。进一步整合基于物理的约束可能会弥合静态重构与响应性、逼真的交互、元宇宙解锁应用、具身AI等之间的鸿沟。
5.5 Endoscopic Scene Reconstruction
内窥镜场景重建在机器人辅助微创手术中至关重要,通过对动态场景的精确建模来增强术中导航、规划和仿真。最近的进展集成了动态辐射场,以解决内窥镜视频中的仪器遮挡和稀疏视点等挑战。然而,在组织变形和拓扑变化方面实现高保真,以及在延迟敏感的应用中实现实时绘制,仍然是关键的 77、138、308
与一般的动态场景相比,该任务引入了不同的挑战,包括狭窄腔体中有限的相机移动性导致的稀疏训练数据、遮挡关键区域的工具遮挡以及单视图几何歧义。现有的方法主要使用额外的深度引导来推断组织 77、138、308 的几何形状。例如,EndoGS 308 将深度引导的监督与时空权重掩码和表面对齐的正则化项相结合,在解决工具遮挡的同时提高了3D组织渲染的质量和速度。Endo Gaussian 138 介绍了两种新策略:用于稠密初始化的整体高斯初始化和用于建模表面动力学的时空高斯跟踪。Zhao et al 文献 295 认为这些方法存在重建不足的问题,并提出从频率角度来缓解这一问题。此外,EndoGSLAM 228 和Gaussian Pancake 12 设计了适用于内窥镜场景的SLAM系统,并表现出显著的速度优势。
推进内窥镜三维重建需要在数据和动力学建模两方面有针对性的努力。数据限制来自于单视点视频,由于仪器遮挡和相机移动性受限,会产生不适定的重建问题,导致关键组织区域无法观测。虽然深度估计器提供了暂时的解决方法,但集成多视角相机系统解决了根本原因。此外,现有的数据集通常以截断序列( e.g. , Endo NeRF中的4⋅8 )为特征,无法捕获长时间的组织变形动态或复杂的手术工作流程。将时间覆盖范围扩展到包括更长的、具有临床代表性的序列,将有利于如前所述的下游应用。 目前的方法仍然存在建模的局限性,它们往往在高斯水平而不是对象或3D区域水平上表示组织动力学。这降低了它们编码具有语义意义的解剖学相互作用的能力,值得进一步探索。
5.6 Large-scale Scene Reconstruction
大规模场景重建是自动驾驶、航拍测量、AR / VR等领域的关键组成部分,需要同时具备真实感视觉质量和实时渲染能力。在3D GS出现之前,已经使用了基于NeRF的方法来处理该任务,这些方法虽然对较小的场景有效,但当扩展到较大的区域( e.g. ,大于1。5km2)时,细节和渲染速度往往会下降。尽管3D GS相对于NeRFs表现出相当大的优势,但直接将3D GS应用于大规模环境带来了巨大的挑战。3D GS需要大量的高斯分布来维持大范围区域的视觉质量,导致渲染过程中对GPU的内存需求非常大,计算量非常大。 例如,一个跨越2的场景。7 km2可能需要超过2 000万个高斯,甚至超过最先进的硬件(例如,内存为40GB的NVIDIA A100)的极限 137 。
为了解决这些挑战,研究人员在两个关键领域取得了重大进展:i )在训练方面,采用了分而治之的策略 97、130、137、186,将一个大场景分割成多个独立的细胞。这便于扩展环境下的并行优化。另一个挑战在于保持视觉质量,因为大规模场景通常具有无纹理的表面,这会妨碍优化的有效性,例如高斯初始化和密度控制( Sec。3 . 2 )。增强优化算法为缓解 29、130 问题提供了一种可行的解决方案。ii )在渲染方面,采用计算机图形学中的细节层次( LoD )技术已被证明是有效的。 LoD通过调整3D场景的复杂度来平衡视觉质量和计算效率。目前的实现只涉及向光栅化器 130 馈送必要的高斯,或者设计八叉树 186 和层次结构 97 等显式的Lo D结构。此外,集成像LiDAR这样的额外输入模态可以进一步增强重建过程 237、240、249 。
一个突出的挑战在于处理稀疏或不完整的捕获数据,这可以通过少样本自适应方案(见Sec . 4 . 1 )或可泛化的先验(见Sec中的"从大规模数据中学习物理先验"。7 )来缓解。同时,内存和计算瓶颈可以通过分布式学习策略来解决 294 ,例如跨GPU集群的参数划分和并行批量多视图优化。
5.7 Physics
复杂真实世界动力学的模拟,如种子扩散或流体运动,对于跨越VR、动画和科学建模的应用至关重要,其中真实感依赖于精确的物理行为。扩散模型的进步推动了4D内容生成的进展,但这些方法可能会产生违背基本物理规律的视觉上合理的结果。通过将物理约束和属性嵌入到场景表示中,3D GS成为一种有前途的解决方案,可以实现视觉上令人信服和物理上连贯的模拟。
现有方法的不同之处在于如何构建基于物理的先验,并将其整合到各自的框架中。最常用的方法是使用物理仿真引擎( e. g . , MLS-MPM 72 )来指导动力学生成。材料点方法 72 和基于位置的动力学 160 - -用于模拟流体、颗粒介质和压裂固体等材料变形的计算机图形学中的数值方法- -已经被社区通过各种定制 13、48、76、88、134、181、247、292进行了广泛的探索。分析材料模型,例如质量-弹簧系统,也证明了通过将材料特性显式地编码为3D高斯来近似变形的成功 301 。 在这些方法中,3D高斯粒子被视为离散粒子(有一个例外使用连续表示),并在所选择的模拟器中作为计算单元。未知的材料属性或物理参数通常通过基于视频的监督从条件生成模型中学习。
尽管基于物理的3D GS框架取得了进展,但仍然存在严重的局限性。目前的系统很难将多样化的物理行为(例如,刚性、弹性或软体动力学)统一到内聚模拟中,在没有人工干预的情况下处理复杂的多对象交互,并对环境反馈和动态光照变化等场景级交互进行建模。集成能够支持多对象和多材质交互的自适应物理引擎,开发兼容从大规模数据中学习到的先验信息的新仿真架构,以及扩展数据集以涵盖多样化材质和动态场景同样至关重要。
6 PERFORMANCE COMPARISON
在这一部分中,我们通过展示我们先前讨论的几种3D GS算法的性能来提供更多的经验证据。3D GS在众多任务中的多样化应用,以及为每个任务定制的算法设计,使得在单个任务或数据集上对所有3D GS算法进行统一比较变得不切实际。为了全面起见,按照图2所示的分类方法,我们在表1中提供了一组具有代表性的数据集。由于篇幅有限,我们选择了几个具有代表性的任务进行了深入的性能评估。成绩分数主要来源于原始试卷,除非另有说明。我们还为这一部分维护了一个Github存储库。
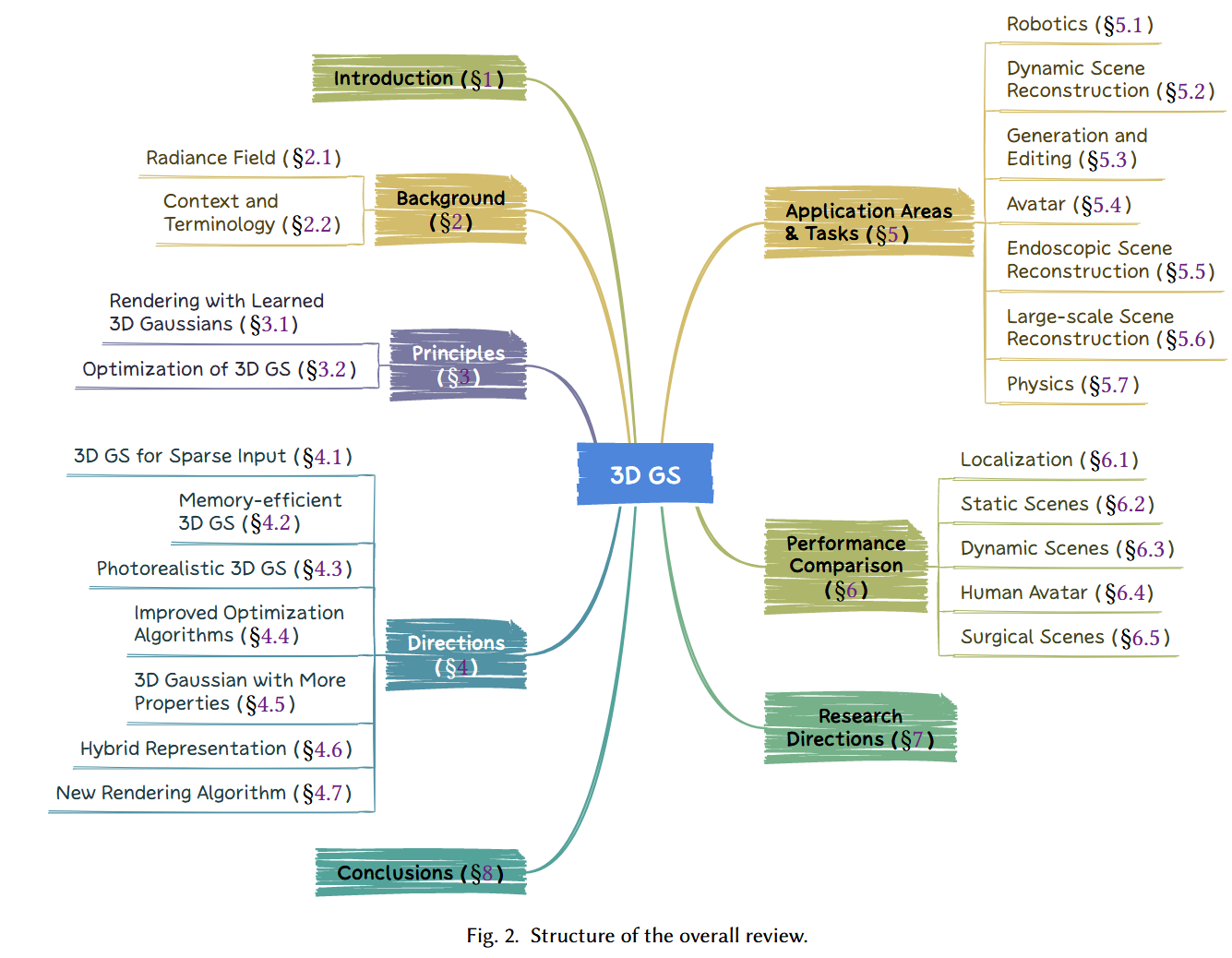
6.1 Performance Benchmarking: Localization
SLAM中的定位任务涉及确定机器人或设备在环境中的精确位置和方向,通常使用传感器数据。
- 数据集:Replica 208 数据集是18个高度详细的三维室内场景的集合。这些场景不仅在视觉上逼真,而且为每个元素提供了密集的网格、高质量的纹理和详细的语义信息。根据 211 ,我们使用了3个关于房间的序列和5个关于办公室的序列进行评估。
- 基准测试算法:为了进行性能比较,我们涉及了4个最近的基于3D GS的算法 95、149、254、279和6个典型的SLAM方法 192、311 。
- 评估指标:绝对轨迹误差( ATE )的均方根误差( RMSE )是评估SLAM系统的常用指标 209 ,它测量整个轨迹上估计位置和真实位置之间的欧氏距离的均方根。
- 结果:如表2所示,最近的基于3D高斯的定位算法与现有的基于NeRF的稠密视觉SLAM相比具有明显的优势。例如,SplaTAM 95 实现了50 %的轨迹误差改善,从0降低。52Cm降至0 . 36cm,高于之前的最先进水平( SOTA ) 192 。我们将这归因于为场景重建的稠密且精确的3D高斯,它可以处理真实传感器的噪声。 这说明有效的场景表征可以提高定位任务的精度。
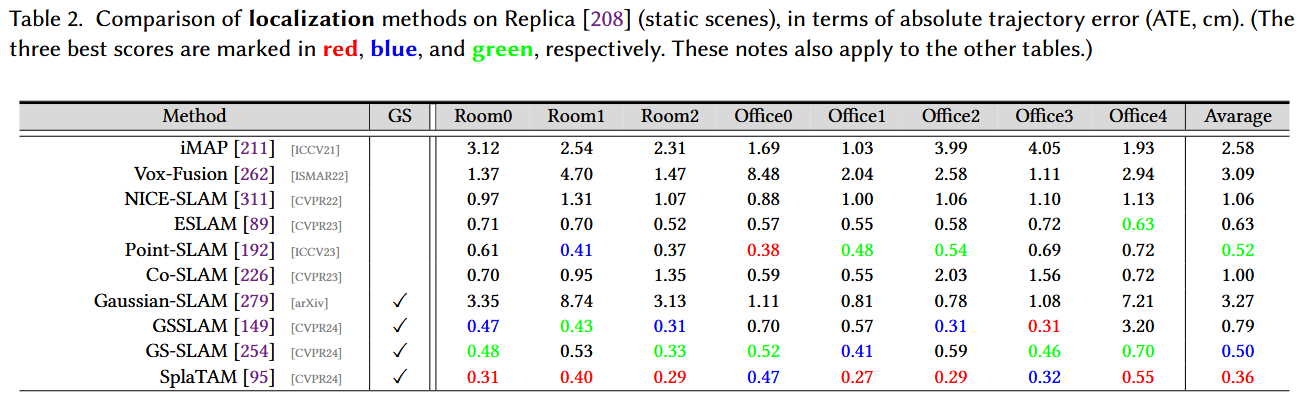
6.2 Performance Benchmarking: Static Scenes
渲染的重点是将计算机可读的信息(例如,场景中的3D物体)转换为基于像素的图像。本部分主要对静态场景下的渲染结果进行质量评价。
- 数据集:与Sec中相同的数据集。6 . 1,即Replica 208 ,用于比较.测试视图与 211 收集的视图相同。
- 基准测试算法:为了性能比较,我们涉及四篇最近的论文,将3D高斯引入其系统 95、149、254、279,以及三种稠密SLAM方法 192、311 。
- 评价指标:峰值信噪比( PSNR ),结构相似性( SSIM ) 234 和学习的感知图像块相似性( LPIPS ) 289 用于测量RGB渲染性能。
- 结果:表3显示,基于3D高斯的系统通常优于三个稠密SLAM竞争者。例如,Gaussian-SLAM 279 建立了新的SOTA,并且大大优于以前的方法。 与Point - SLAM 192 相比,GSSLAM 149 在达到非常有竞争力的精度方面快了约578倍。与以前依赖于深度信息的方法 192 相比,例如深度引导的光线采样,用于合成新的视图,基于3D GS的系统消除了这一需求,允许对任何视图进行高保真渲染。
6.3 Performance Benchmarking: Dynamic Scenes
本部分主要对动态场景中的渲染质量进行评估。
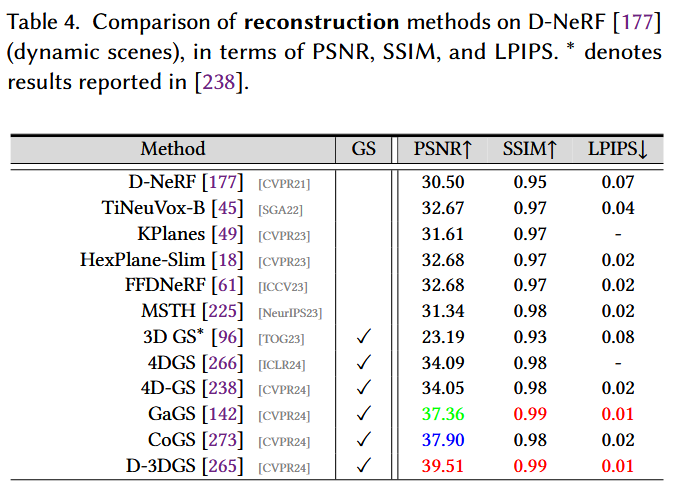
- 数据集:D-NeRF 177 数据集包括从独特视角拍摄的50 ~ 200帧视频。它以复杂场景中的合成、动画物体为特征,采用非朗伯材料。该数据集每个场景提供50 ~ 200张训练图像和20张测试图像,用于在单目场景下评估模型。测试视图与原文 177 相同。
- 基准测试算法:为了性能比较,我们涉及5篇最近的论文,它们使用3D GS 142、238、265、266、273建模动态场景,以及6个基于NeRF的方法 61、177、225。
- 评估度量:与Sec中的相同度量。6 . 2,即PSNR,SSIM 234 和LPIPS 289 ,用于评估。
- 结果:从表4中我们可以观察到,基于3D GS的方法明显优于现有的SOTA。静态版本的3D GS 96 无法重建动态场景,导致性能急剧下降。通过建模动态物体,D-3DGS 265 比SOTA方法FFDNeRF 61 提高了6 . 83dB。这些结果表明了引入附加属性或结构化信息对高斯形变进行建模从而对场景动态进行建模的有效性。
6.4 Performance Benchmarking: Human Avatar
人体替身建模旨在从给定的多视点视频中创建人体替身的模型。
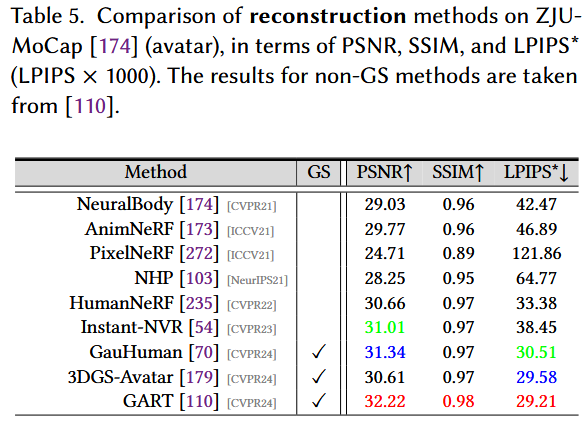
- 数据集:ZJU-MoCap 174 是一个流行的基于视频的人体建模基准,由23个同步摄像机以1024 × 1024的分辨率捕获。6名受试者(即377、386、387、392、393和394)用于评估 235 。采用了与 54 相同的测试视图。
- 基准测试算法:为了性能比较,我们涉及了最近的三篇使用3D GS 70、110、179 建模人体头像的论文,以及六种人体渲染方法 54、174、235。
- 评估指标:PSNR,SSIM 234 和LPIPS * 289 用于测量RGB渲染性能。
- 结果:表5给出了人体头像建模中顶尖解决方案的数值结果。 我们观察到,将3D GS引入到框架中会导致渲染质量和速度的一致性能提升。例如,GART 110 比目前的SOTA,Instant-NVR 54 提高了1。21dB。考虑到增强的逼真度、推理速度和可编辑性,基于3D GS的化身建模可能会给3D动画、交互游戏等领域带来革命性的变化。
6.5 Performance Benchmarking: Surgical Scenes
基于内窥镜视频的三维重建对机器人辅助微创手术至关重要,可以实现术前规划、医生培训等。
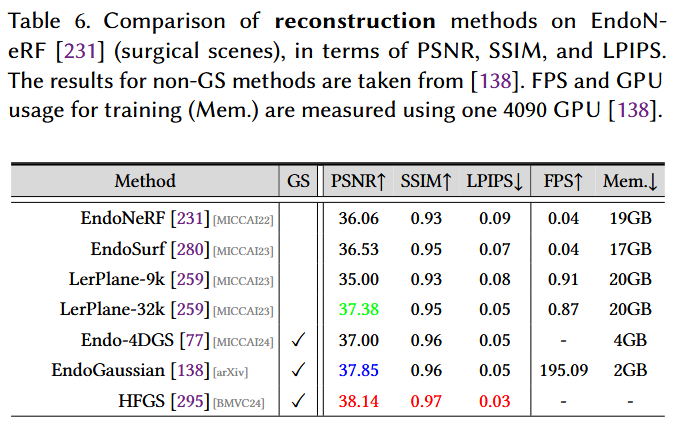
- 数据集:EndoNeRF 231 数据集提供了一个专门的立体相机捕获的集合,包括两个在体前列腺切除术的样本。它是为了表示真实的手术复杂性而定制的,包括具有工具遮挡和明显非刚性变形的挑战性场景。使用与 280 中相同的测试视图。
- 基准测试算法:为了进行性能比较,我们涉及三个使用GS 77、138、295 重建动态3D内窥镜场景的工作,以及三个基于NeRF的手术重建方法 231、280 。
- 评估指标:采用PSNR,SSIM 234 和LPIPS 289 进行评估。
- 结果:从表6可以看出,引入三维高斯的显式表示有几个显著的改进。例如,在所有指标中,Endo Gaussian 138 优于强基线Endo Surf 280 。特别地,Endo Gaussian在仅消耗10 %的GPU资源的情况下,速度提高了近200倍。这些令人印象深刻的结果证明了基于GS的方法的高效性,不仅加快了处理速度,而且最大限度地减少了GPU的负载,从而减轻了对硬件的需求。这些属性对于真实世界的手术应用部署至关重要,其中优化的资源使用可能是实际效用的关键决定因素。
7 FUTURE RESEARCH DIRECTIONS
就像3D GS的后续工作一样令人印象深刻,就像3D GS已经或可能革命性地改变了那些领域一样,人们普遍认为3D GS仍有相当大的改进空间。
- Physics- and Semantics-aware Scene Representation
作为一种新的、显式的场景表示技术,3D Gaussian提供了超越单纯增强新视角合成的变革性潜力。通过设计物理和语义感知的3D GS系统,它有可能为同时推进场景重建和理解铺平道路。虽然物理( Sec。5 . 7 )和语义 30、82、84、129、182、227各自取得了重大进展,但它们的协同集成还有相当大的潜力可挖。这将为一系列领域和下游应用带来革命性的变化。 例如,融入物体的一般形状等先验知识,可以在改进几何/表面重建 60、122 的同时,减少对广泛训练视点 21、218的需求。评估场景表示的一个关键指标是生成场景的质量,它包含了几何、纹理和光照保真度 24、51、78 方面的挑战。通过在3D GS框架内融合物理原理和语义信息,可以预期质量将得到提高,从而促进动力学建模 88、247 、编辑 19、303 、生成 221、269 和其他。 总之,追求这种先进和通用的场景表示为计算创造力和跨不同领域的实际应用的创新开辟了新的可能性。
- Learning Physical Priors from Large-scale Data
随着我们探索物理和语义感知的场景表示的潜力,利用大规模数据集学习可泛化性,物理先验成为一个很有前途的方向。目标是对嵌入在真实世界数据中的固有物理特性和动态进行建模,将其转化为可操作的见解,可应用于各种领域,如机器人技术和视觉效果。建立一个学习框架来提取这些可泛化的先验,能够以少量的方式将这些洞察应用到特定的任务中。例如,它允许以最少的数据输入快速适应新的对象和环境。 此外,融合物理先验不仅可以提高生成场景的精度和质量,还可以提高场景的交互性和动态性。这一点在AR / VR环境中尤其有价值,因为在AR / VR环境中,用户与虚拟物体的交互方式与他们在真实世界中的对应物一致。然而,从广泛的2D和3D数据集中捕获和提取基于物理的知识的现有工作仍然很少。相关领域的显著成果包括基于连续介质力学的GS系统( Sec。5 . 7 ),以及基于多视图立体的广义高斯表示 135 。对real2sim和sim2real的进一步探索可能为该领域的发展提供可行的途径。
- Modeling Internal Structures of Objects with 3D GS.
尽管3D GS能够产生高度真实感的渲染效果,但在当前GS框架下建模物体(例如,对于计算机断层扫描中的被扫描物体)的内部结构是一个显著的挑战。由于抛雪球和密度控制过程,目前的3D高斯表示是无组织的,不能很好地与物体的实际内部结构对齐。此外,在各种应用中,将对象描述为卷(如计算机断层扫描)有很强的偏好。然而,3D GS的无序性使得体积建模变得尤为困难。Li等人 121 使用具有密度控制的3D高斯作为体积表示的基础,并没有涉及抛雪球过程。 X-Gaussian 16 使用抛雪球过程进行快速训练和推理,但不能生成体积表示。利用3D GS对物体内部结构进行建模仍未得到解答,值得进一步探索。
- 3D GS for Simulation in Autonomous Driving and beyond
为自动驾驶收集真实世界的数据集既昂贵又具有逻辑上的挑战性,但对训练有效的基于图像的感知系统至关重要。为了缓解这些问题,模拟作为一种具有成本效益的替代方法应运而生,它能够在不同的环境中生成合成数据集。然而,开发能够产生逼真和多样化合成数据的模拟器充满了挑战。其中包括实现高水平的质量,容纳各种控制方法,准确模拟一系列照明条件。虽然 255、302、306在3D GS重建城市/街道场景方面的早期努力是令人鼓舞的,但就全部能力而言,它们只是冰山一角。 仍然有许多关键的方面需要探索,例如用户自定义对象模型的集成,物理感知场景变化的建模( e.g. ,车辆车轮转动),以及增强(例如,在不同的光照条件下)的可控性和质量。掌握这些能力不仅可以促进自主系统,而且可以重新定义对物理空间的计算理解- -这是对世界模型、空间智能、具身AI和超越的影响的飞跃。
- Empowering 3D GS with More Possibilities
尽管3D GS具有巨大的潜力,但3D GS的全部应用范围在很大程度上仍未得到开发。一种很有前途的探索方法是增加带有附加属性(例如, Sec中提到的语言和时空特性。4 . 5 )的3D高斯,并引入针对特定应用的结构化信息(例如, Sec .中提到的空间MLPs和网格。4 . 6 )。此外,最近的研究已经开始揭示3D GS在几个领域的能力,例如,点云配准 20 ,图像表示和压缩 293 和流体合成 48 。这些发现为跨学科学者进一步探索3D GS提供了重要机会。
8 CONCLUSIONS
据我们所知,这项研究首次对3D GS进行了全面的综述,这项开创性的技术革新了显式辐射场、计算机图形学和计算机视觉。它描述了从传统的基于NeRF方法的范式转换,突出了3D GS在实时渲染和增强可编辑性方面的优势。我们的深入分析和大量的定量研究证明了3D GS在实际应用中的优越性,特别是那些对潜伏期高度敏感的应用。我们对这一领域的原则、未来的研究方向和尚未解决的挑战提出了见解。 总体而言,3D GS是一项变革性技术,将对未来3D重建和表示的发展产生重大影响。这项调查旨在作为一项基础性资源,推动这一迅速发展的领域的进一步探索和进展。