这里写自定义目录标题
- [Redis (in-memory data store)](#Redis (in-memory data store))
- Redis常见的数据类型
- 持久化
本章节当中重点解释Redis当中的特性(以及面试当中的相关问题)
Redis (in-memory data store)
Redis用于分布式系统中 如果是单机程序,直接使用变量存储数据,比redis更优选择
从名称当中可以知道,Redis值存储在内存当中的,通过网络把自己的内存中的变量给别的主机使用
Redis是一个在内存当中存储数据的中间件,用于作为数据库或者是数据库缓存
Redis是一种典型的非关系型数据库
Redis特性
- In-memory data structures:在内存当中存储数据
- Programability:针对Redis操作,可以简单交互命令进行操作,也可以是脚本操作 Lua编程语言
- Extensibility:可以在Redis原有功能基础上再进行扩展,Redis提供了一组API
- Persistence:持久化,内存当中的数据是比较容易丢失的,Redis提供了两种持久化的方式:RDB与AOF(后续解释)这两种策略可以将内存当中数据保存在硬盘上
- Clustering:集群性:引入多个主机,部署多个Redis节点,每个Redis存储一份数据
- High availability:高可用性哨兵机制
- Replication:主从复制
- 基于键值对的数据存储
速度快 :
为什么Redis的速度是非常快的?
- Redis的所有的数据都是存放在内存当中的,比访问硬盘的速度要快上很多
- Redis的核心逻辑都是比较简单的逻辑,本身不会吃很多的内存资源
- 从网络角度上来说,Redis使用的是IO多路复用,使用一个线程,管理多个socket
- Redis使用的是单线程的模型,减少了不必要的线程之间的竞争开销
最大的劣势与MySQL相比 :存储空间是有限的
有没有存储的又大又快:Redis与MySQL相结合的方式
Redis的应用场景
- Real-time data store:redis作为数据库(如果只有Redis数据库,那么就需要考虑数据不能丢失的问题,但是此处应该最先考虑的是数据量的大)
- Caching&session storage:根据二八原则,把热点数据提取出来,存储在Redis当中 (cookie实现了用户信息保存,存储了用户的身份标识)
- Streaming & messaging:消息队列(基于消息队列可以实现网络当中的生产者、消费者模型)
Redis常见的数据类型
简单介绍+命令的时间复杂度,具体的使用后续会有文章专门解释
基本的全局命令
KEYS
h?llo:hello,hallo
h*ll:hllo,haaaaall
haello:表示这块可以匹配a/e
h\^ell:表示除了e其他的匹配
时间复杂度:O(N)
EXISTS
判断某个key是否存在(也可以判断多个key是否存在)
时间复杂度:O(1);有几个key,1就需要变成几
DEL
删除指定的key
时间复杂度:O(1);有几个key,1就需要变成几
EXPIRE
为指定的key添加秒级的过期时间,超出时间之后会自动被删除
时间复杂度:O(1)
TTL
存活的时间,(网络原理当中也有一个TTL那个是到达的次数)
TYPE
返回key所对应的数据类型,其实说的是value的类型,key的类型都是string
时间复杂度:O(1)
Redis数据结构
String hash list set zset
具体使用,相关底层编码问题,其他篇章介绍
常见面试题
-
过期机制是怎样实现的,Redis当中会有很多的key,怎样判读出当前这个key快要过期
定期删除 :每次抽取一部分,验证过期时间,保证抽取检查的过程足够快
惰性删除 :假设这个key已经到过期时间了,但是暂时没有删除,后面再次访问的时候恰好用到这个key,此刻就会让redis服务器触发删除key的操作也有可能会出现大量的过期key没有删除,从而占用内存空间,提供了一种内存淘汰机制
还有一种是定时删除(但是Redis没有采取这种策略):1. 基于优先级队列/堆 2. 基于时间轮
-
为什么Redis是单线程但是还会这么快(几乎是必考)
可以将其归纳为3点
纯内存访问 :所有的数据都存放在内存当中,是访问快速的基础
Redis的核心功能要比数据库核心功能会更简单 :排序,大量的存储Redis没有那么精通
单线程避免了线程切换和竞态产生的消耗 :单线程会减少竞争产生的消耗
非阻塞IO:Redis使用epoll作为I/O多路复用技术的实现Linux提供了IO多路复用主要是三套API:select,poll,epoll(相当于是事件通知/回调机制)
持久化
Redis支持RDB和AOF两种持久化机制
Redis使用的是自定义的应用层协议:RESP protocol spec
该协议的优点是:简单易实现,快速进行解析,肉眼可读,传输层基于TCP实现,但是没有强耦合
协议格式:请求,客户端给服务器发送的是redis命令(bulk string数组的形式发送的)
响应:Simple String :+ "+OK\r\n":服务器就会写入tcp,socket
Error:- "-Error message\r\n"
Integers::":1000\r\n"
Bulk String :可以传输二进制
Arrays:数组
RDB
RDB持久化是把当前进程数据生成快照保存到硬盘的过程,触发可以是手动触发/自动触发
类似于在道路上开车时,如果超速了,就会生成超速的快照,截图那种
触发机制
手动触发分别对应save与bgsave
save:阻塞当前Redis服务器,Redis全力以赴,其他的客户端命令就没有办法执行,会造成内存长时间阻塞,基本不采用
bgsave:Redis创建fork紫禁城,RDB持久化过程由子进程负责
Redis内部所有涉及RDB操作都类似与bgsave的形式
自动才是更为常见的
- 使用save配置,如"save m n"表示m秒内数据集发生了n次修改,自动进行RDB持久化
- 从节点进行全量复制,主节点自动进行RDB持久化,随后RDB文件内容发给从节点
- 执行shutdown命令时,执行RDB持久化
流程说明
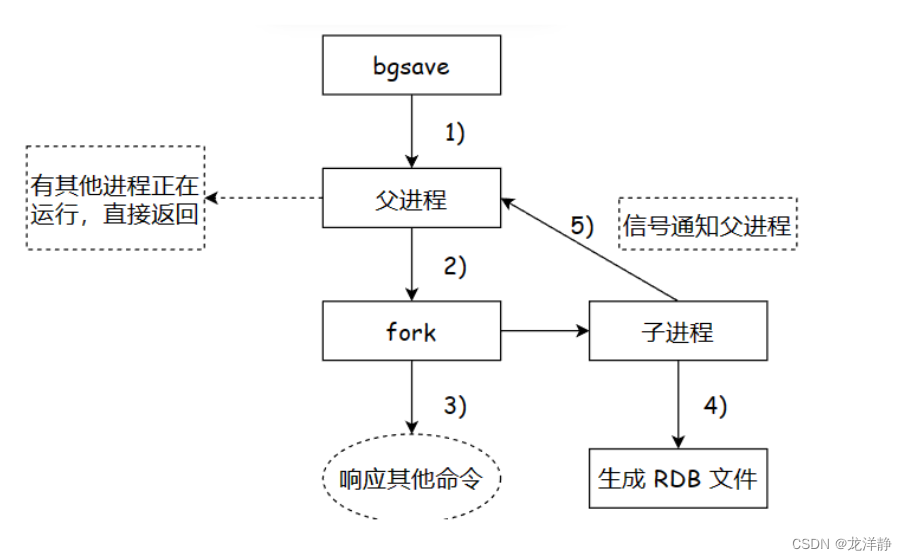
- 执行命令,会判断是否有其他进程执行RDB,如果存在直接返回
- 父进程执行fork创建子进程,父进程会阻塞,
- 父进程fork完成之后,父进程就可以进行其他的命令了
- 子进程创建的RDB文件,生成快照过程,父进程继续进行客户端的请求
- 子进程完成后会通知父进程,子进程就会结束
生成的rdb文件是存放在redis的工作目录当中的
RDB文件的处理
保存: RDB文件保存再dir配置指定的目录
压缩: Redis默认采用LZF算法对生成的RDB文件做压缩处理
RDB的优缺点
RDB是一个紧凑的二进制文件,非常适合备份,全量复制等场景
Redis加载RDB恢复数据远远快于AOF的方式
但是RDB没有办法做到实时持久化,因为需要执行fork操作,属于重量级的操作,频繁之后,执行成本会变高
AOF
配置默认时不开启的,开启AOF之后,RDB就不生效了
流程说明
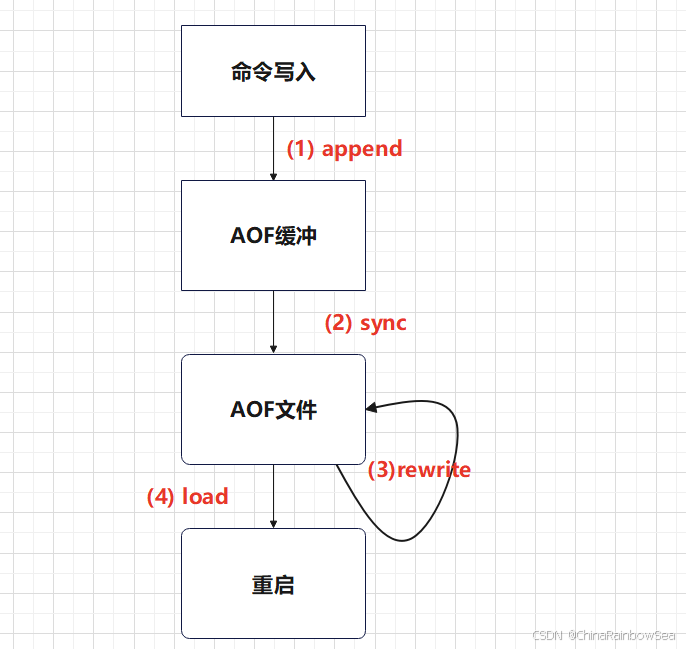
-
所有的写入命令都会追加到缓冲区当中
-
AOF会根据对应的策略向硬盘做出同步操作
-
随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的
-
当Redis服务器启动的时候,需要加载AOF文件进行数据的恢复
AOF使用缓冲区,避免了每次从内存读写变成IO读写,性能会受到影响
文件同步
AOF文件缓冲区同步策略
| 可配置的值 | 说明 |
|---|---|
| always | 命令写入缓冲区之后,调用同步,完成后返回(频率最高,可靠性最高,性能最低) |
| everysec | 写入缓冲区后write,不进行同步,每秒由同步线程进行同步(频率低一些,可靠性也降低,总能会提高) |
| no | 写入缓冲区之后执行write,由OS控制同步(频率最低,可靠性最低,性能最高) |
write与fsync说明:
write:会触发延迟机制,write操作在写入系统缓冲区之后,立刻返回,同步硬盘操作依赖与系统调度机制
fsync:针对单个文件操作,做强制硬盘同步,fsync将阻塞直到数据写入硬盘当中
重写机制
随着命令不断写入AOF,文件会越来越大,Redis引入了AOF重写机制压缩文件体积。AOF文件重写是把Redis进程内的数据转化为写命令同步到新的AOF文件
重写后的AOF为什么可以变小
-
进程内已超时的数据不再写入文件
-
旧的AOF中的无效命令,例如del、hdel等会删除,只需要保存最终版本
-
多条写操作合并为一条
AOF重写过程可以分为手动触发和自动触发:
手动触发:调用 bgrewriteaof 命令
自动触发:根据配置当中的自动触发参数,1. 表示触发重写时AOF的最小文件大小 2. 代表当前AOF占用大小相比较上次重写时增加的比例
AOF重写流程
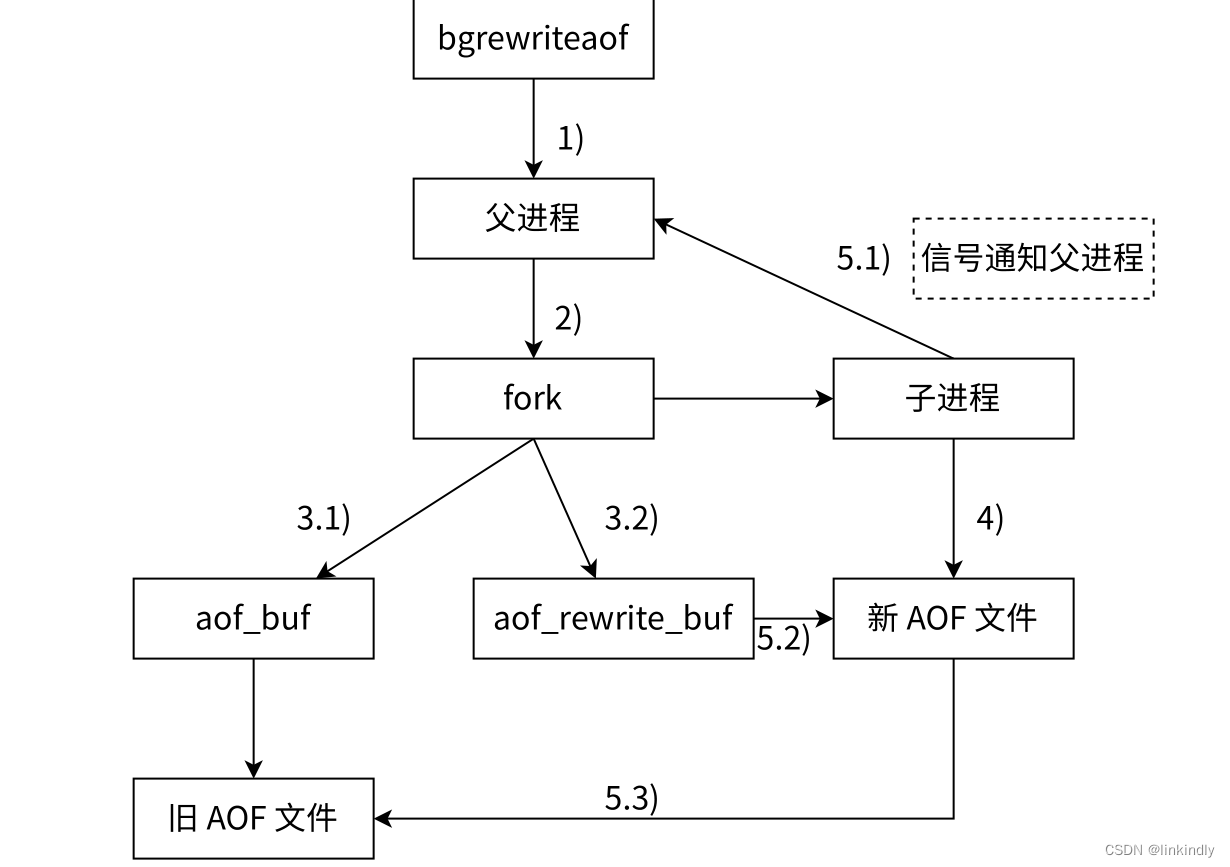
此刻时手动的情况
- 执行AOF重写请求
- 父进程执行fork创建子进程,而父进程接收处理新请求
- 重写(不关心AOF原来,只关心内存最终的数据状态)
a. 主进程fork之后,继续相应其他命令,所有修改操作写入AOF缓冲区,并根据appendfsync策略进行同步到因公安,保证旧的AOF文件机制正确
b. 子进程只有fork之前的所有的内存信息,父进程需要将fork之后这段时间的修改操作写入到AOF缓冲区当中 - 子进程根据内存快照,将命令合并到新的AOF文件当中
- 子进程完成重写
a. 新文件写入后,子进程发送信号给父进程
b. 父进程把AOF重写缓冲区内临时保存的命令追加到AOF文件当中
c. 用心的AOF文件替换老的AOF文件
启动时数据恢复
当Redis启动时,会根据RDB与AOF文件内容,进行数据恢复
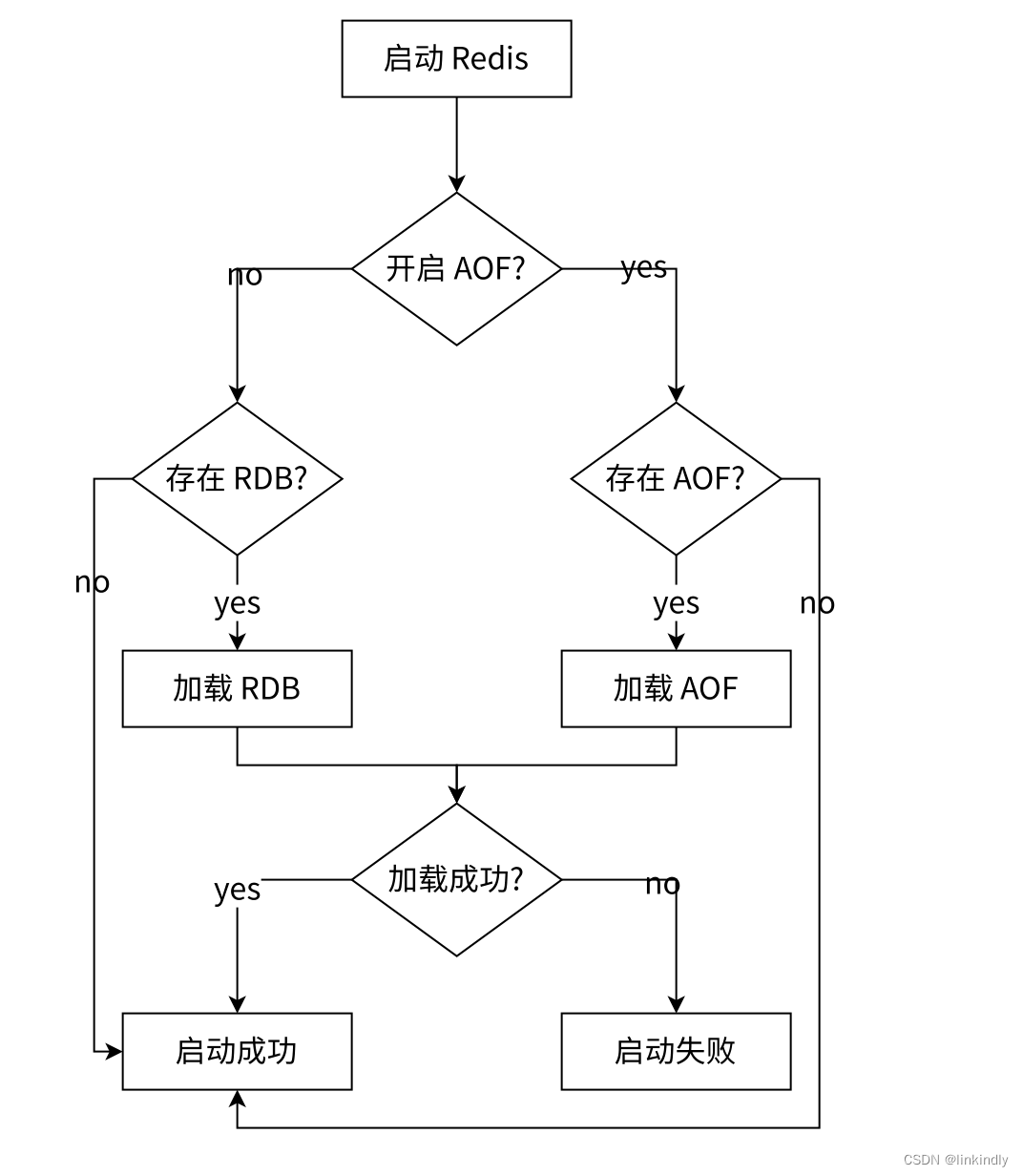
AOF按照文本方式写入文件的,但文本方式后续加载成本是比较高的
Redis引入"混合持久化"方式结合RDB与AOF的特点,按照AOF方式,每个请求/操作,记录文件
触发AOF重写之后,会把当前内存状态,按照RDB二进制格式写入新的AOF文件当中,后续操作,仍然是AOF文本追加到后面
Redis中同时有AOF与RDB:以AOF为主,RDB忽略