一、研究背景与核心问题
1. 3D 目标检测的重要性与标注困境
3D 目标检测作为自动驾驶、嵌入式机器人等核心视觉任务的关键技术,其性能直接影响智能体对环境的感知能力。传统 3D 目标检测方法依赖海量精确标注数据,而 3D 点云标注不仅耗时耗力(需标注目标边界框、类别等信息),还面临室内外场景差异带来的额外挑战 ------ 室外场景(如自动驾驶)目标类别相对固定(车、行人、自行车等),而室内场景存在场景特异性类别(如卫生间的马桶、客厅的沙发),难以用统一的标注策略覆盖所有类别。
2. 现有有限监督方法的局限性
为降低标注成本,学界提出了弱监督、半监督和稀疏监督三类方法,但均存在明显不足:
- 弱监督方法24,44:使用点级标注(如框中心)等弱监督信号,但无法提供精确的边界框属性,仍需少量精确标注或合成 3D 形状辅助训练;
- 半监督方法7,9,34,51:依赖部分场景的全标注数据,但标注整个场景的成本依然高昂,且标注与未标注场景间的领域差距会导致信息传递失效;
- 稀疏监督方法20,42:仅在每个场景中标注少量目标,是目前最具性价比的方案,但现有方法采用 GT Sampling 策略(确保单个场景覆盖所有类别),仅适用于室外场景。如图 1 (a) 所示,该策略在室内场景中完全失效 ------ 将卫生间的 "马桶" 强行放入客厅场景违背常识(图 2),导致室内稀疏监督 3D 检测任务长期缺乏有效解决方案。
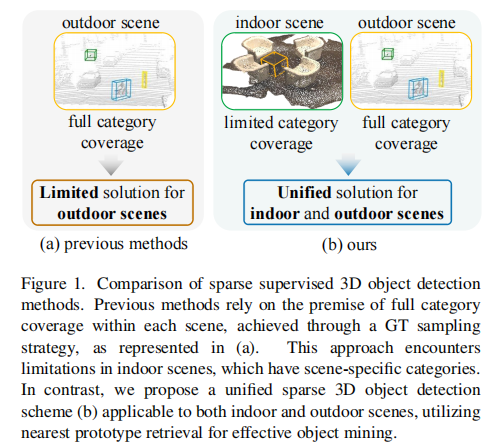
图 1:(a) 现有方法依赖单场景全类别覆盖的 GT Sampling 策略,仅适用于室外;(b) 本文方法通过原型匹配实现室内外统一的稀疏监督检测。
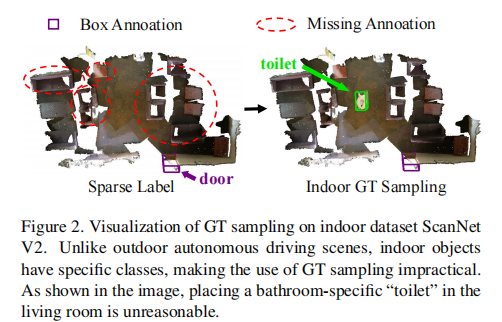
图 2:ScanNet V2 数据集上的 GT Sampling 示意图。室内物体具有场景特异性,将卫生间的 "马桶" 放入客厅场景不具备合理性,证明现有室外导向方法无法迁移至室内。
3. 本文核心贡献
针对上述问题,本文提出CPDet3D(Class Prototype-based 3D Detector),一种面向室内外统一的稀疏监督 3D 目标检测方法,核心贡献包括:
- 首次实现室内外场景的统一稀疏监督检测,打破现有方法的场景局限性;
- 设计基于原型的目标挖掘模块,通过跨场景类别原型学习,突破单场景类别覆盖限制,为未标注目标分配原型标签;
- 提出多标签协同优化模块,融合稀疏标注、伪标签和原型标签,有效弥补漏检问题,无需复杂的阈值迭代设计;
- 实验验证:在单场景仅标注 1 个目标的稀疏设置下,ScanNet V2、SUN RGB-D 和 KITTI 数据集上分别达到全监督性能的 78%、90% 和 96%,且优于现有半监督和稀疏监督 SOTA 方法。
原文链接:Learning Class Prototypes for Unified Sparse Supervised 3D Object Detection
代码链接:https://github.com/zyrant/CPDet3D
沐小含持续分享前沿算法论文,欢迎关注...
二、方法详解
CPDet3D 的整体架构如图 3 所示,核心分为三个部分:基于原型的目标挖掘模块、多标签协同优化模块,以及两阶段训练策略。
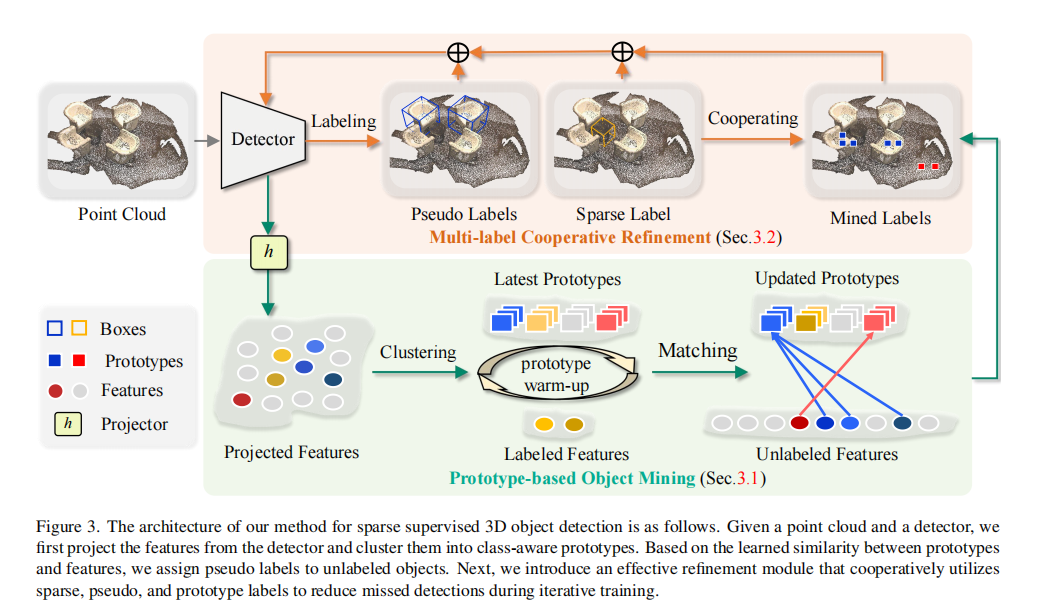
图 3:方法整体流程。输入点云和稀疏标注后,先通过投影器生成特征并聚类得到类别原型;再通过原型匹配挖掘未标注目标的原型标签;最后通过多标签协同优化模块融合稀疏标签、伪标签和原型标签,迭代提升检测性能。
1. 基于原型的目标挖掘模块(Prototype-based Object Mining)
该模块的核心思想是:跨场景学习类别原型,将未标注目标挖掘转化为特征与原型的匹配问题,从而突破单场景类别覆盖限制。模块分为类别感知原型聚类和原型标签匹配两个子步骤。
1.1 类别感知原型聚类(Class-aware Prototype Clustering)
目标是学习跨场景的类别特异性原型,捕捉每个类别的特征分布。具体步骤如下:
-
特征投影 :将检测器输出的候选区域特征
(N 为候选区域数,C 为特征维度)通过多层感知机(MLP)投影得到
-
类别特征筛选 :通过类别掩码
-
最优传输匹配 :将原型与特征的匹配建模为最优传输问题,使用 Sinkhorn-Knopp 迭代求解匹配矩阵
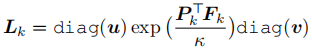
其中 u 和 v 为归一化向量, -
原型动量更新:基于匹配矩阵,用动量更新策略迭代优化原型,确保原型能稳定捕捉类别特征分布:
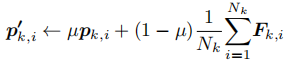
其中 -
对比损失约束:引入原型 - 特征对比损失(Info-NCE 损失 10),迫使同类特征靠近、异类特征远离,增强原型的判别性。
该过程的伪代码如算法 1 所示:

1.2 原型标签匹配(Prototype Label Matching)
初始原型由截断正态分布初始化,类别区分度低(图 4 (a)),因此需先进行 1000 轮热身迭代(warm-up),待原型收敛后(图 4 (b))再进行标签匹配:
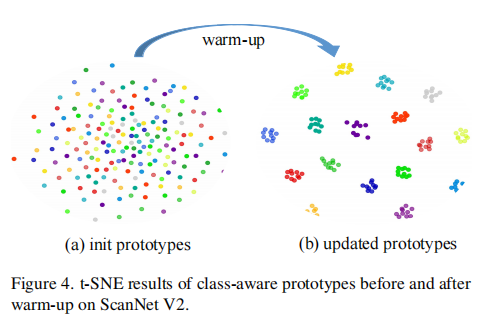
图 4:ScanNet V2 数据集上的原型 t-SNE 结果。热身前原型混叠(a),热身後类别边界清晰(b)。
- 亲和矩阵计算 :对第
- 传播概率融合 :融合检测器的分类分数
- 原型标签分配 :对每个特征,选择传播概率最大的类别作为原型标签
- 标签过滤:通过三个掩码过滤无效标签:
- 前景掩码
- 稀疏标签掩码
- 范围掩码
- 前景掩码
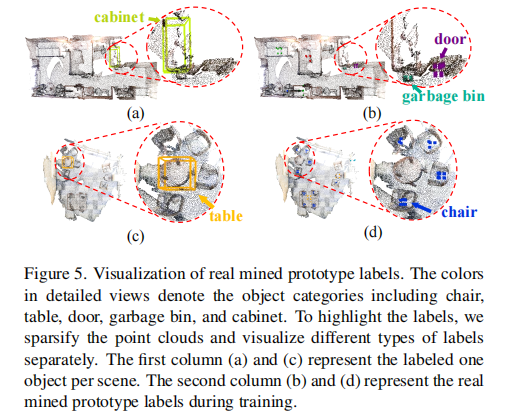
图 5 展示了原型标签的挖掘效果,可见即使场景中未标注某类目标(如 (a) 中未标注 "垃圾桶"),模块仍能准确挖掘出该类未标注目标((b) 中红色区域)。
2. 多标签协同优化模块(Multi-label Cooperative Refinement)
该模块的核心是融合稀疏标签、高质量伪标签和原型标签,解决高阈值伪标签导致的漏检问题,同时避免复杂的阈值调整。模块分为迭代伪标签生成和原型标签协同两个子步骤。
2.1 迭代伪标签生成(Iterative Pseudo Labeling)
生成高质量伪标签的关键是过滤噪声,步骤如下:
- 分数过滤 :设定分类分数阈值
- IoU 过滤 :设定 IoU 阈值
- 冲突过滤 :设定冲突阈值
最终伪标签为:
其中 为检测器对第
个场景的原始预测。
2.2 原型标签协同(Prototype Label Cooperating)
高阈值伪标签虽保证质量,但会导致漏检。该步骤通过原型标签填补漏检区域:
- 基于分类分数分离前景 / 背景;
- 标记已被稀疏标签或伪标签覆盖的区域;
- 对剩余前景区域,分配原型标签作为补充,从而恢复漏检目标。
与 MixSup 46、WS3D 24 等多标签方法相比,CPDet3D 仅需部分 3D 边界框标注,无需额外 BEV 标签,进一步降低了标注成本。
3. 两阶段训练策略
CPDet3D 采用两阶段训练,逐步提升模型性能:
阶段 1:初始检测器训练
使用稀疏标注训练初始检测器,同时训练基于原型的目标挖掘模块。损失函数为:
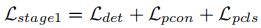
阶段 2:多标签迭代优化
使用阶段 1 的检测器生成伪标签,融合稀疏标签、伪标签和原型标签进行迭代训练。损失函数为:
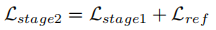
三、实验设置与结果分析
1. 数据集与评估指标
数据集
- 室内数据集:
- ScanNet V2 4:18 类目标,1201 个训练场景,312 个验证场景,单场景仅保留 1 个标注目标;
- SUN RGB-D 30:10 类目标,约 5000 个训练 / 验证场景,单场景仅保留 1 个标注目标;
- 室外数据集:
- KITTI 8:3 类目标(车、行人、自行车),7481 个场景,按 2% 标注成本划分训练 / 验证集(3712/3769)。
评估指标
- 室内:mAP(IoU 阈值 0.25 和 0.5);
- 室外:3D AP(40 个召回阈值,R40)。
基线模型
- 室内:TR3D 28、FCAF3D 27;
- 室外:Voxel-RCNN 5(含 CenterPoint 47 头)、CenterPoint 47。
2. 与 SOTA 方法的对比
2.1 稀疏监督方法对比
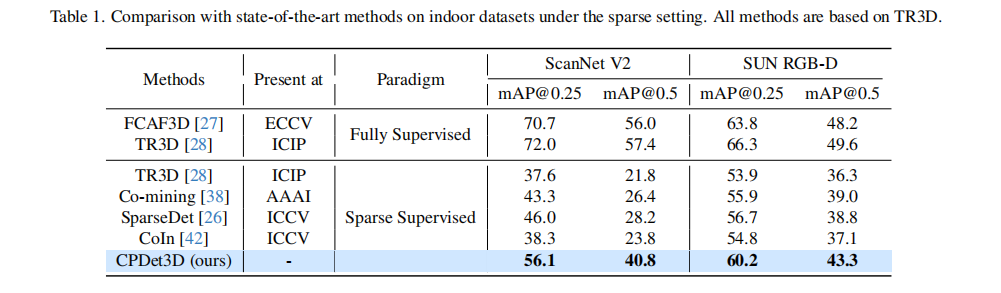
- 室内场景(表 1):
- ScanNet V2:CPDet3D 的 mAP@0.25 达 56.1,比 SparseDet 26 提升 11.3,达到全监督性能的 78%;
- SUN RGB-D:mAP@0.25 达 60.2,比 SparseDet 提升 4.0,达到全监督性能的 90%。
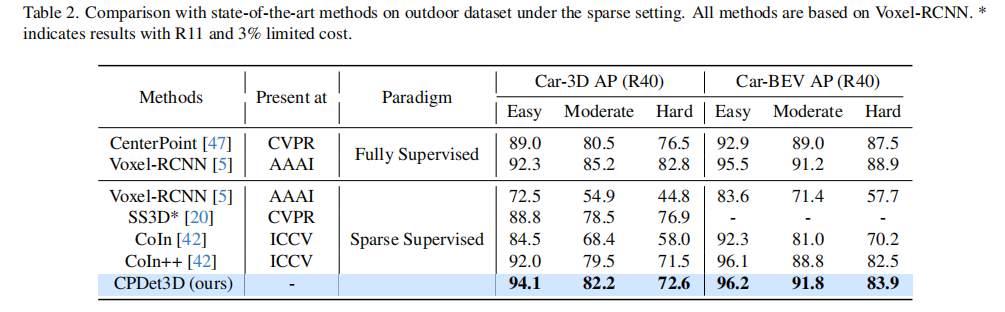
- 室外场景(表 2):
- KITTI 车类 3D AP(中等难度)达 82.2,比 CoIn++42 提升 2.7;BEV AP 达 91.8,提升 3.0;
- 达到全监督性能的 96%,远超其他稀疏监督方法。
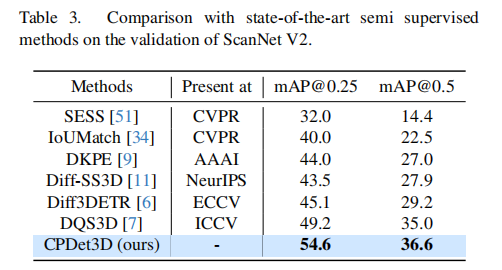
2.2 半监督方法对比
为验证稀疏监督的优越性,在 ScanNet V2 上与半监督 SOTA 方法 DQS3D 7 对比(保证标注目标数一致:半监督 5% 场景标注 vs 稀疏监督单场景 1 个标注,均约 1200 个标注目标):
- CPDet3D 的 mAP@0.25 达 56.1,比 DQS3D 高 5.4;
- mAP@0.5 达 36.3,比 DQS3D 高 1.6,证明稀疏监督在标注效率相当的情况下性能更优。
3. 消融实验与参数分析
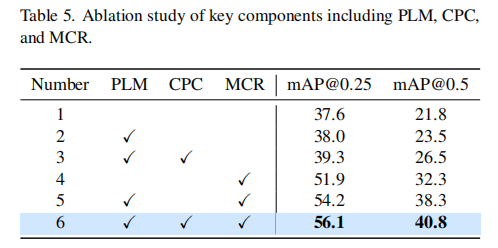
3.1 关键组件消融
在 ScanNet V2 上验证各模块的有效性(表 5):
- 仅添加原型标签匹配(PLM):mAP@0.25 从 37.6 提升至 38.0,证明仅基于分类分数的标签分配效果有限;
- 添加类别感知原型聚类(CPC):mAP@0.25 提升至 39.3,mAP@0.5 提升至 26.5,证明融合特征相似度的原型学习能提升标签质量;
- 添加多标签协同优化(MCR):mAP@0.25 达 51.9,mAP@0.5 达 32.3,证明迭代伪标签的有效性;
- 全组件(CPC+PLM+MCR):mAP@0.25 达 56.1,mAP@0.5 达 36.3,验证各模块的协同作用。
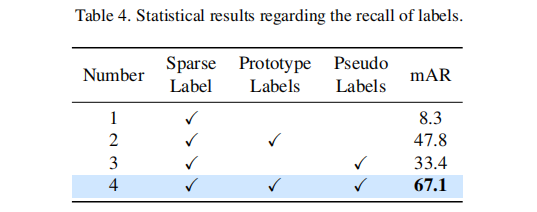
3.2 标签质量分析
- 精度:伪标签与真实标注的重叠率达 95.5%,原型标签达 71.1%,低质量标签可通过 NMS 过滤;
- 召回率(表 4):
- 仅用稀疏标签:mAR=8.3(覆盖率极低);
- 稀疏标签 + 原型标签:mAR=47.8(显著提升);
- 稀疏标签 + 伪标签:mAR=33.4(伪标签质量高但覆盖有限);
- 三者融合:mAR=67.1(标签互补性最大化)。
3.3 参数敏感性分析
- 原型数量(图 6 (a)):每个类别 10 个原型时性能最优,过少无法覆盖同类特征多样性,过多导致原型冗余;
- 热身迭代次数(图 6 (b)):1000 轮热身时原型收敛,性能最佳;
- 动量系数 (图 6 (c)):
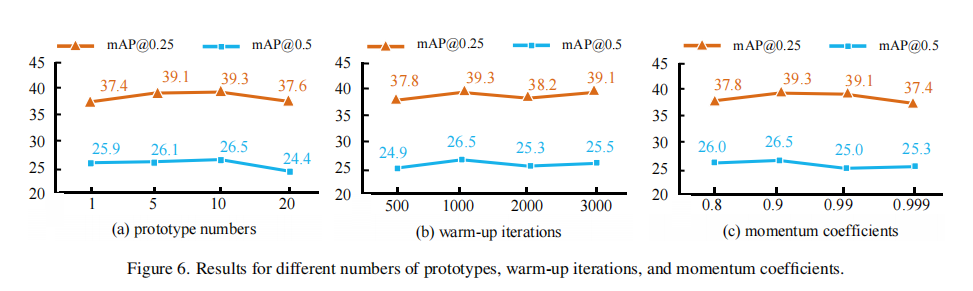
图 6:(a) 原型数量、(b) 热身迭代次数、(c) 动量系数对性能的影响(ScanNet V2 mAP@0.5)。
4. 扩展性验证
4.1 不同标注设置扩展
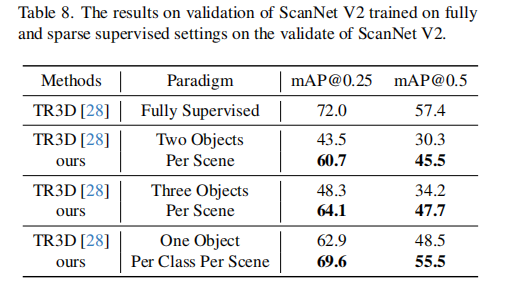
- 多标注目标:单场景标注 2 个 / 3 个目标时,CPDet3D 分别达到全监督性能的 82%/87%,证明方法在更多标注下仍有扩展性;
- 单类别单标注:单场景每个类别标注 1 个目标时,CPDet3D 达到全监督性能的 96%,远超基线模型的 88%(表 8)。
4.2 不同检测器扩展
- 室内 FCAF3D:CPDet3D 在 ScanNet V2 上 mAP@0.25 提升 17.0,SUN RGB-D 提升 3.8;
- 室外 CenterPoint:无需修改即可适配,3D AP(中等难度)达 82.2,接近全监督性能(表 10),证明方法的通用性。
5. 定性结果
图 7、11-13 展示了 CPDet3D 在三个数据集上的检测效果,可见其能准确检测出未标注目标,且对室内外不同场景、不同点云扫描技术具有鲁棒性。
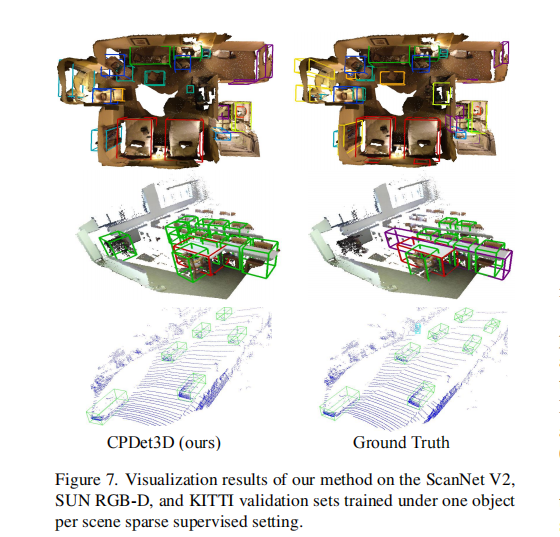
图 7:ScanNet V2、SUN RGB-D、KITTI 数据集上的检测结果(红色框为预测,绿色框为真实标注)。
四、总结与展望
1. 工作总结
CPDet3D 通过类别原型学习 和多标签协同优化,首次实现了室内外统一的稀疏监督 3D 目标检测。核心创新在于:
- 跨场景原型学习突破单场景类别覆盖限制,解决室内场景特异性问题;
- 多标签融合策略在保证标签质量的同时弥补漏检,无需复杂阈值设计;
- 性能远超现有稀疏监督和半监督方法,在极低标注成本下接近全监督性能。
2. 局限性与未来方向
- 局限性:原型标签的精度(71.1%)仍低于伪标签,部分小众类别(如 "浴缸")的检测性能有待提升;
- 未来方向:
- 结合语言模型增强原型的语义判别性,进一步提升小众类别的检测效果;
- 扩展至开放词汇场景,实现未见过类别的零样本检测;
- 优化原型更新策略,降低对超参数(如原型数量、热身迭代)的敏感性。
五、代码与资源
论文代码已开源:https://github.com/zyrant/CPDet3D,基于 mmdetection3d 和 OpenPCDet 框架实现,支持室内外数据集的快速复现。