1、Generator-Evaluator重排模型在淘宝流式场景的实践
Generator-Evaluator重排模型在淘宝流式场景的实践【2023】
GE架构介绍
GE架构由generator+evaluator两部分组成,在强化学习中generator也可以称为actor(agent),evaluator也可以称为simulator。在我们的实现中,generator是基于pointer network的seq2seq生成式模型,它负责基于一个输入序,端到端地输出一个新的重排序。
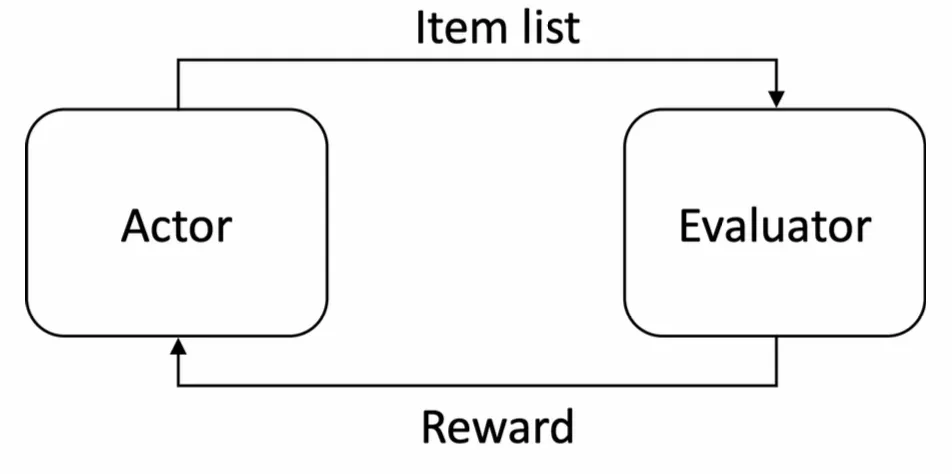
EG架构的重排模型相比于监督学习的重排模型的一个优势是,generator不需要使用监督学习的方式训练,人为指定一个"最优序"作为label供模型学习,generator不需要学习生成我们人为给定的排序结果,因为人为给定的结果肯定是次优的。如果有一个evaluator模型能够近乎模拟线上用户的真实反馈,那么generator通过强化学习的方式,对着这个evaluator模型给出的反馈去训练是更合理的,不断尝试最大化获得的reward。如果数据中有一些非贪心排序范式的排序结果能够获得更好的线上指标,generator也会趋向生成这种模式的排序结果,从而突破贪心排序的范式,生成一些创造性的排序。
EG架构的重排模型,还有一个优势是能够方便地实现店铺打散、曝光宽度、曝光占比控制等业务目标,因为常用的贪心排序范式的模型,模型在打分的过程是不知道最终曝光的序列是怎样的,因此没办法端到端控制商家连续重复、某些类型曝光占比不足等问题,只能在按照模型分排序后做后处理。而EG架构这种生成式重排,generator模型在打分的过程中是直接生成最终排序的,因此在生成的过程中能够感知到生成的序列中商家是否重复、某些类型的曝光占比是否不足等问题。
Generator
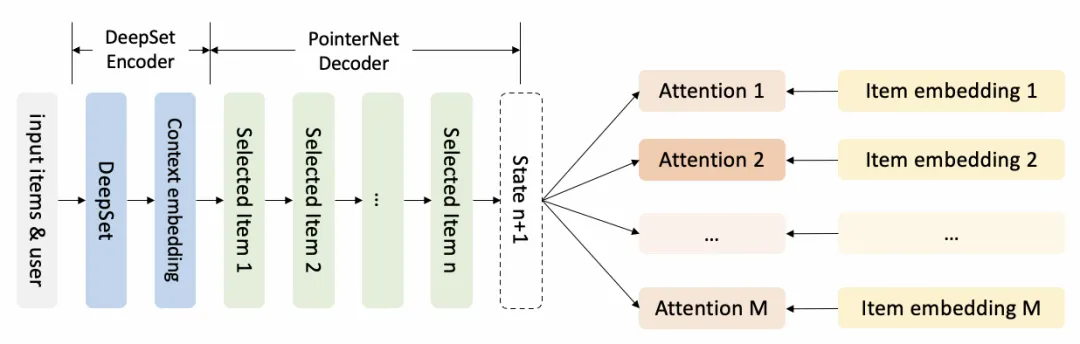
Generator是一个encoder-decoder结构的模型,它的主要作用是从M个候选item中生成出长度为N的序列,其框架图如下所示。encoder负责对输入序进行编码,得到每个商品编码后的embedding,以及输入序整体的embedding,decoder会将输入序整体的embedding作为初始state,使用rnn一步一步地生成出最终的排序结果。
Encoder
在把候选商品集合输入给encoder之前,首先需要进行特征增强和embedding lookup的操作。一个商品的增强特征来源于候选集合,比如商品的历史点击率在整个候选集合中的排名。这是一个非常有效且简单的方式,告诉模型每个商品与它所在的候选集合之间的关系。然后ID特征会被转成实值embedding以方便数值计算。
Encoder是DeepSet的结构,因为它对输入商品的顺序不敏感,其结构图如下所示。DeepSet对于复杂的应用场景可能是更合适的encoder结构,因为要想找到一个好的混合了文本、图片、视频的初始输入序列是不容易的,差的初始输入序可能会伤害重排模型的效果。
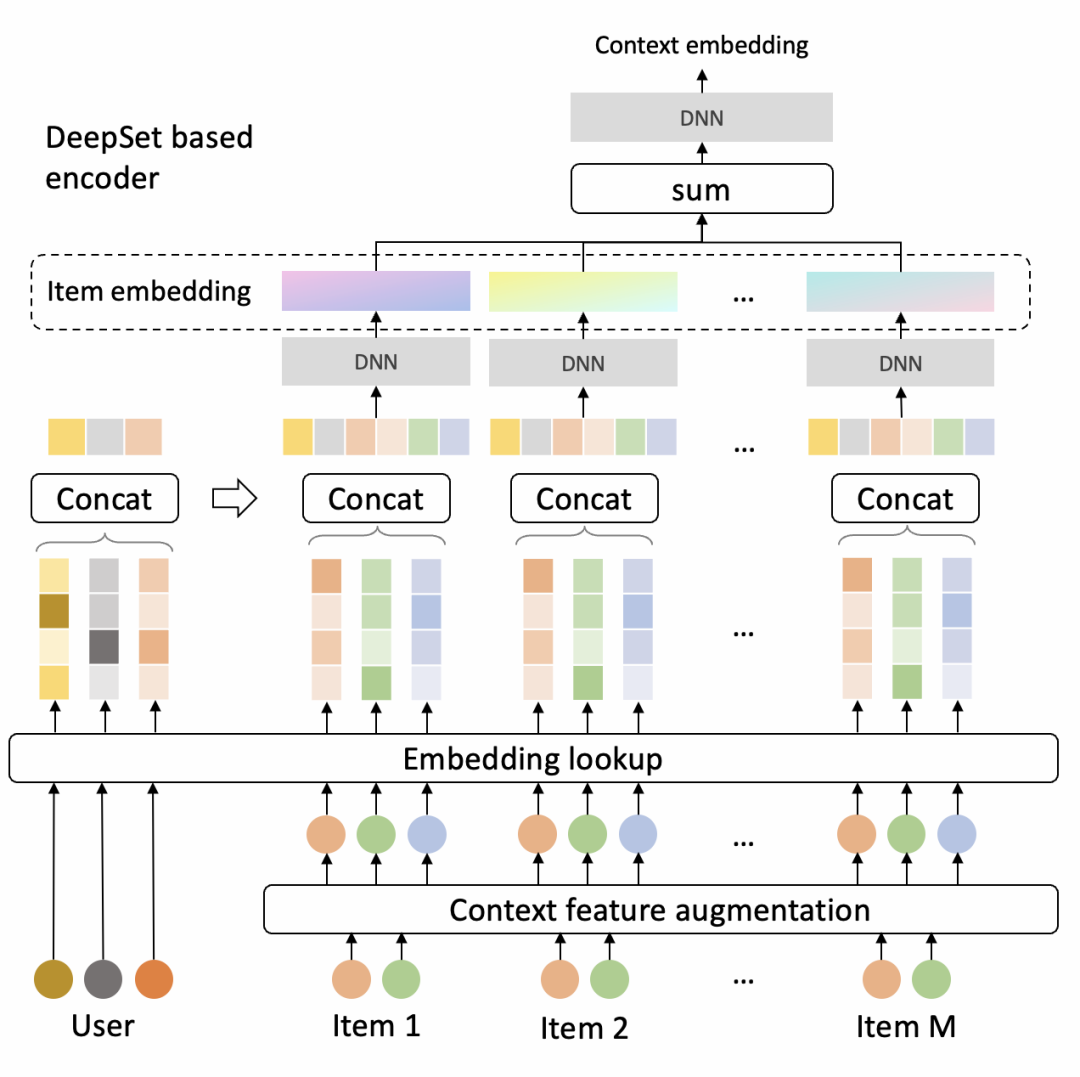
Encoder的输入的User和候选商品集合,输出是一个中间状态的Context embedding。
Decoder
Decoder是基于Pointer Network的结构,其结构图如下所示。它每次会从候选集合中选择一个商品,然后立即更新上下文信息,然后选择下一个商品。
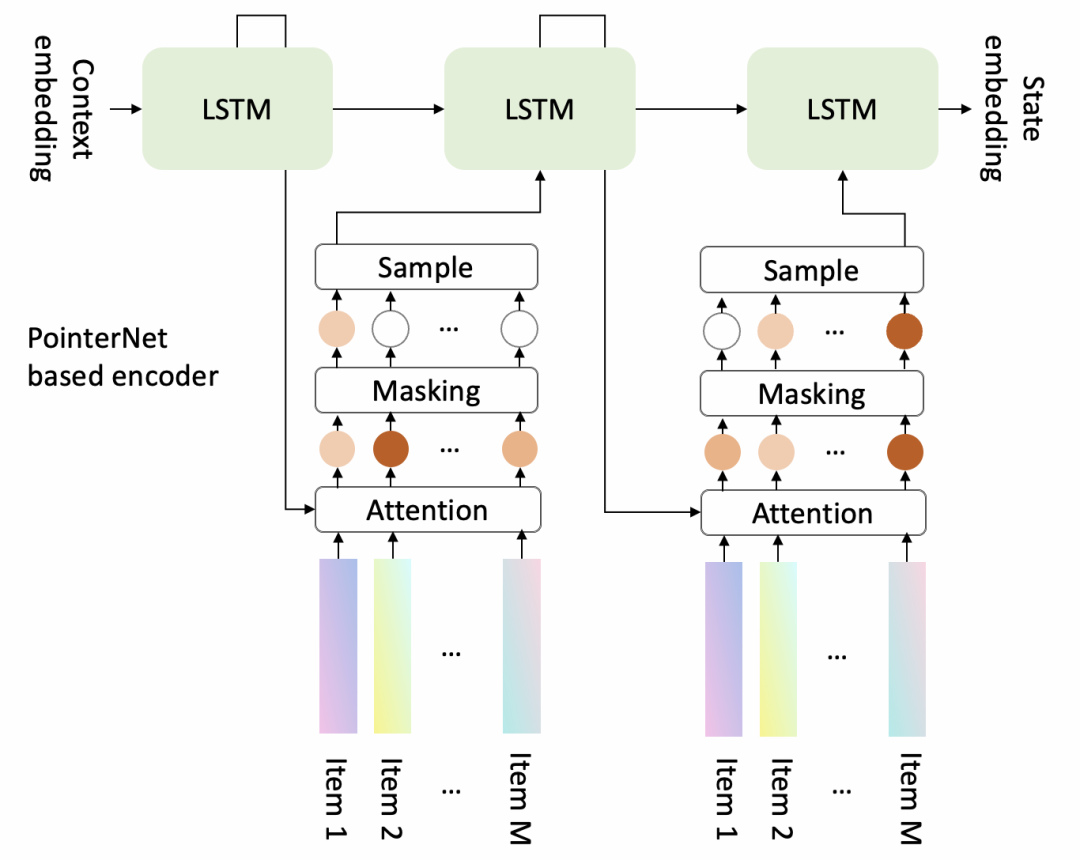
Trick:对计算出的attention概率分布会采用Masking机制,主要有两点原因。首先,一个在前序步骤中已经被选出的商品不应该再被选择了,所以已被选出的商品的attention值需要被mask成0。其次,业务规则可能会要求模型在结果列表中的一些特定位置放一些特定的商品。因为一个顾客可能是通过点击一个trigger商品来到当前推荐场景的,所以需要把trigger商品强制放在推荐列表的最前面,以便提供更多关于trigger商品的信息给用户。在这种情况下,除了trigger的所有商品的attention值应该被mask成0。
同时,generator使用一个采样机制选择商品是至关重要的,因为这会让generator在相似的state尝试不同的action,最终能够帮助generator找到更优的序列生成策略。最简单的选择是Thompson Sampling,会依据每个商品mask后的attention值成比例地选择商品。一个更好的选择可能是Random Network Distillation,倾向于选择一个在之前相似的state下很少被选择的商品。
Evaluator
Evaluator包含了一系列的效用函数,一个效用函数U是从一个商品序列到一个实数的映射,表示在某种视角下这个序列的质量分数,在相关工作中这通常被描述为一个任务。
一些效用函数通常来自于业务规则以及好的排序结果应该满足的先验知识,比如商品多样性,这些效用函数有解析公式,能够被直接计算出来。其他的一些效用函数,比如用户对序列的交互概率,则不得不需要使用模型预测,模型会通过离线数据训练出来。模型一旦训练好后,会被用作为预先定义好的效用函数。
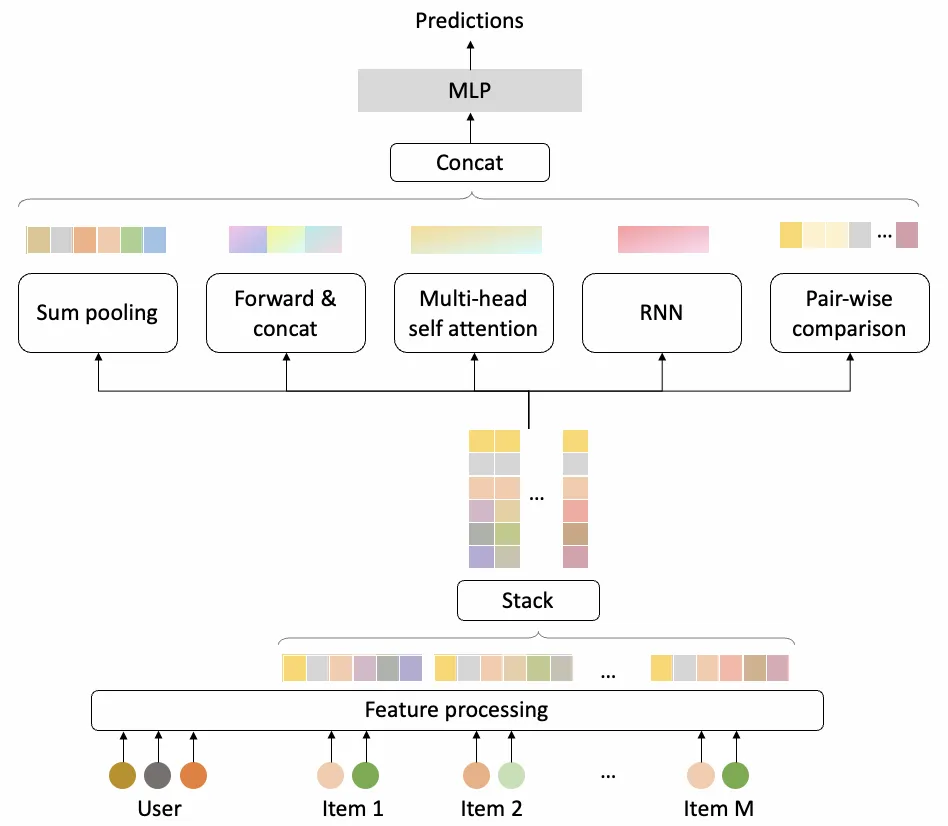
Evaluator的模型结构如上图所示。在经过与generator一样的特征处理后,会被5个聚焦于商品序列不同方面的模型channel处理,5个channel的输出结果会被concat起来,然后通过一个MLP转变成最终的预测分。
模型训练方法
在generator训练之前,会首先使用纯正的监督学习方式充分训练evaluator。目前对于evaluator,我们使用经典的交叉熵损失函数训练得到一个分类模型:
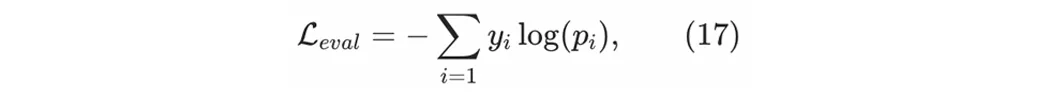
其中y_i是一个类别的one-hot label,p_i是对应类别的模型预测值。evaluator可能会预测生成的推荐结果列表是否会引导到某种特定的用户交互行为,比如点击以及各种交互的兴趣强度。
GE架构中的generator不会按照监督学习的方式,最大化某一个人为指定的输出序列的联合概率,而是像强化学习一样,generator通过一些带有随机性的探索机制,尝试让自己的生成结果能够最大化获得的reward。
这个reward,既包含evaluator对生成序列点击率的模型预估分,又包含一些规则性的判断生成序列是否满足各项业务规则的评分,然后将这些分数通过加权求和的方式,融合到一个最终整体的reward上,这个reward是一个序列整体的reward,然后generator的训练目标就是不断最大化这个reward,手段是根据reward正负和大小调节生成具体序列的概率。(E的训练目标是最大化整体的reward)
对于generator的训练,我们使用一个基于REINFORCE的方法。REINFORCE是一个经典的policy gradient算法。在强化学习中,policy是一个state到所有可能action的概率分布的一个映射,期望能够最大化total reward。简单来说,policy告诉我们在给定state下应该采取哪个action。

基于RL训练G的好处
强化学习训练方式的两个好处:
1、不需要显式地指定label,在重排场景下,就是不需要显式地指定模型应该输出怎样的重排序。因为我们根本不知道最优的重排序是什么,或者是有可能存在较多种优秀的重排序,没法知道哪个更好。这种情况下,我们就不需要去让模型模仿监督信号,而是要直接面向reward也就是最终效果进行优化,只要是能够获得更高reward的行为,就是更好的行为,有可能找到比贪心排序更好的组合更优的排序结果。
2、由于这个reward R是环境给予的反馈,在实践中就是evaluator给予的反馈,它跟generator的模型参数是没关系的,因此我们调整generator的模型参数,去最大化这个最终获得的总reward R,是不需要对reward R算gradient的。也就意味着,如果假设reward是一个函数产生的,就算产生reward的这个函数是不可导的也没关系,因为我们不需要对产生reward的这个函数进行求导,就算它是一个黑盒,我们不知道它的计算式子也没关系,只要我们拿到它最终的值就可以了。因此这个reward函数可以任意复杂,既可以是模型预估分,也可以是根据业务规则计算出来的分数,方便融入各种业务要求,因此非常适用于我们这个业务规则约束较多的场景。
实践应用
G模型的输入是混排后分数最高的20个候选item,这20个item中会包含不同类型的供给,它们会作为一个集合送进G模型(也就是actor)打分,然后G生成一个长度为10的重排后的序列。 训练结束后,我们只将训练好的序列生成器G上线,E不上线。
E是判别式模型,给每个序列打一个分,希望用户反馈更多的序列的evaluator分数比用户反馈更少的序列的evaluator分数要高,因此E离线评估看的是auc指标。在淘宝实验中,E的auc大概为0.75左右。
G的离线评估指标是better percentage,含义是所有请求的样本中,generator生成的重排序获得的evaluator score,比线上真实曝光序的evaluator score更高的比例。在实践中,generator的better percentage通常能达到70%+左右,也就是说如果E的评判打分是靠谱的,那么大概有70%的请求,G能够生成出比之前的线上曝光序更好的序列。
2、重排序在快手短视频推荐系统中的演进
快手短视频推荐
快手推荐系统包括了传统的召回、粗排、精排、LTR的多目标排序、多目标预估等技术环节。而在这些模块之后的技术环节就属于重排序,主要包括手机端和服务端两部分。服务端通过传统服务器部署重排服务,包括序列重排、多源内容混排、多样性模块。端上部分包括端上重排模型和端上重排策略两部分。重排技术是快手十分重要的技术环节,它的发展速度远快于其他排序环节,属于较新的技术范畴。
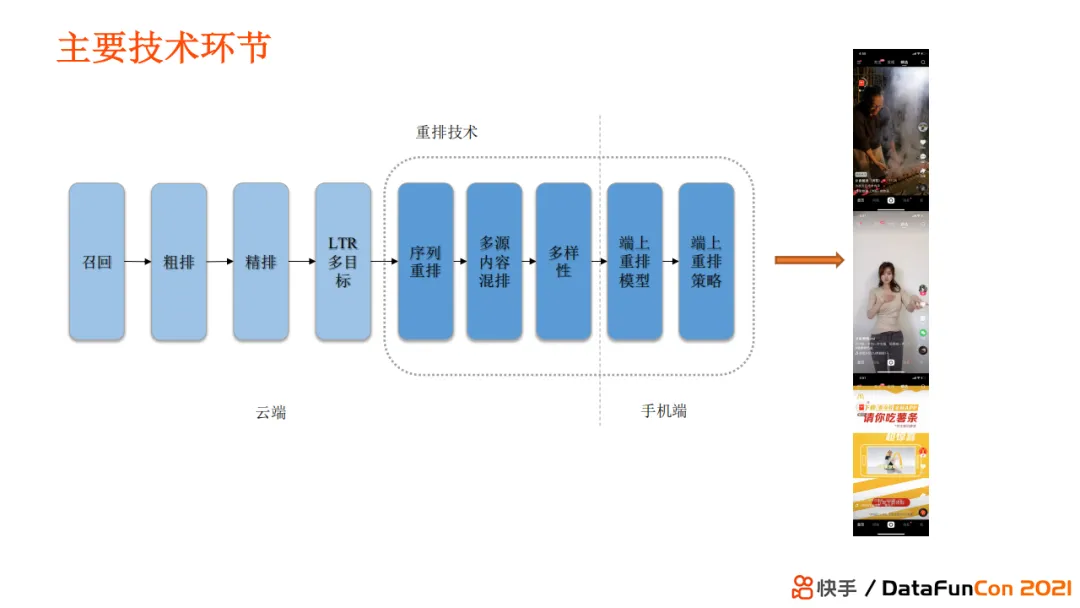
重排阶段处理的问题包括:
-
整个序列的价值并非单 item 效果的累计,如何使得序列价值最大化;
-
沉浸式场景中,什么是好的多样性体验,业务意志如何体现;
-
同一个场景下越来越多的业务参与其中,如何恰当地分配流量和注意力,达成业务目标和整体最优;
-
如何更加及时、更加细微地感知用户状态,及时调整我们的推荐策略和内容。
序列重排
序列重排基于两个认知。