随着物联网、工业互联网、大数据技术的深度普及,时序数据已成为企业数字化转型的核心资产------工业传感器、智能设备、运维监控、车联网等场景每天都会生成海量时序数据。据统计,2025年国内企业时序数据产生量同比增长超60%,选择一款适配业务场景的时序数据库,直接决定了数据存储效率、分析成本与业务响应速度。本文从大数据视角出发,梳理时序数据库选型的核心维度,对比国内外主流产品特性,并结合实操案例解析Apache IoTDB的核心优势,为企业级时序数据存储与分析选型提供可落地的参考。
目录
[三、Apache IoTDB实操指南(安装+核心操作+代码示例)](#三、Apache IoTDB实操指南(安装+核心操作+代码示例))
[3.1 环境准备](#3.1 环境准备)
[3.2 下载与安装(附官方下载链接)](#3.2 下载与安装(附官方下载链接))
[3.3 核心基础操作(CLI命令行)](#3.3 核心基础操作(CLI命令行))
[3.4 代码示例(Java版,生产级落地)](#3.4 代码示例(Java版,生产级落地))
[3.5 生产环境注意事项](#3.5 生产环境注意事项)
一、大数据场景下,时序数据库选型的核心维度
时序数据库的选型并非**"唯性能论"**,在大数据视角下,需综合考量以下6个核心维度,才能匹配企业长期发展需求:
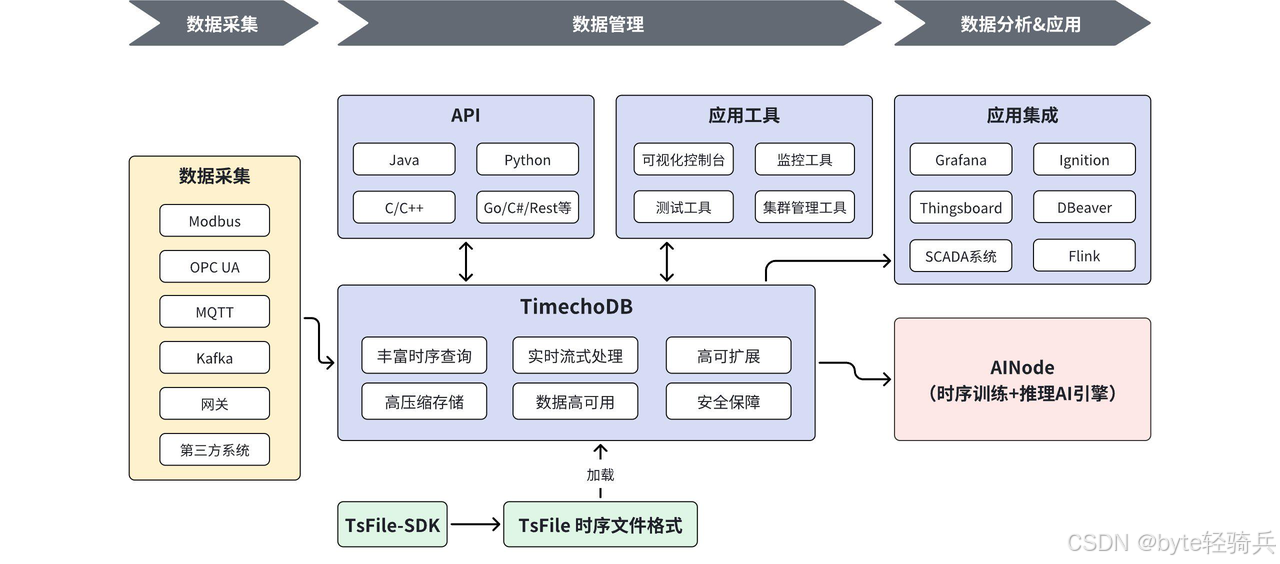
1. 海量数据写入性能
时序数据的核心特征是**"高并发、高吞吐、高增量"**,大数据场景下每秒十万级甚至百万级写入是常态,数据库的写入吞吐量、端到端延迟直接决定业务是否能实时采集数据。
2. 存储成本控制
PB级时序数据是大数据场景的标配,压缩率、冷热数据分离能力直接影响存储成本------同等数据量下,压缩率每提升10%,年存储成本可降低数万元。
3. 查询与分析效率
多维度聚合、时间范围筛选、降采样分析是时序数据的高频查询场景,需支持高效的聚合函数、设备级索引,且能快速响应复杂的关联分析需求。
4. 大数据生态兼容性
企业现有大数据架构(Hadoop、Spark、Flink、Hive)是既定基础,时序数据库需无缝融入现有体系,避免重复搭建数据链路。
5. 国产化与可控性
开源属性、社区活跃度、无厂商锁定是关键,尤其政企类场景,需适配国产化软硬件体系,规避供应链风险。
6. 企业级特性
高可用、容灾备份、权限管理、监控告警等能力,是时序数据库从"测试环境"走向"生产环境"的核心门槛。
二、国内外时序数据库对比:IoTDB的差异化优势
目前海外主流时序数据库包括InfluxDB、TimescaleDB、Prometheus等,但其在国内大数据场景下存在明显短板,而Apache IoTDB则针对性解决了这些痛点:
| 选型维度 | 海外主流产品(InfluxDB/TimescaleDB) | Apache IoTDB |
|---|---|---|
| 写入性能 | 高基数场景下吞吐量骤降 | 百万级/秒写入,设备级索引无性能衰减 |
| 存储压缩率 | 平均压缩率10:1左右 | 自研算法压缩率达20:1,成本降低50% |
| 大数据生态适配 | 对Flink/Spark适配不友好 | 原生支持批流一体,无缝接入Hadoop生态 |
| 部署运维 | 集群部署复杂,运维成本高 | 轻量化部署,支持单机/集群/边缘端 |
| 国产化支持 | 无本土化技术支持 | Apache顶级开源项目+Timecho企业级保障 |
Apache IoTDB的核心优势可总结为三点:
-
极致性能:专为时序数据设计的列式存储+时间分区架构,写入延迟低至毫秒级,聚合查询响应速度比海外产品快30%-50%;
-
成本最优:冷热数据分离机制可将冷数据迁移至廉价存储(如S3、HDFS),结合超高压缩率,PB级数据年存储成本可降低40%以上;
-
生态友好:原生支持Flink CDC、Spark SQL、Hive集成,可直接复用企业现有大数据平台资源,无需额外搭建数据中台。
三、Apache IoTDB实操指南(安装+核心操作+代码示例)
为帮助开发者快速落地,以下提供IoTDB的完整实操步骤,包含安装、基础操作与Java代码示例(适配生产环境)。
3.1 环境准备
操作系统:Linux(CentOS 7+/Ubuntu 18.04+)、Windows 10/Server 2019
依赖环境:JDK 8/11(推荐JDK 8)
硬件要求:测试环境4GB内存,生产环境16GB+内存
3.2 下载与安装(附官方下载链接)
步骤1:下载安装包
访问Apache IoTDB官方下载地址:https://iotdb.apache.org/zh/Download/,选择对应操作系统的binary安装包(推荐稳定版1.1.0)。
Linux环境下可通过命令下载:
wget https://archive.apache.org/dist/iotdb/1.1.0/iotdb-1.1.0-bin.zip步骤2:解压并配置
# 解压安装包
unzip iotdb-1.1.0-bin.zip
cd iotdb-1.1.0
# 调整基础配置(单机版默认即可,集群版需修改conf/iotdb-cluster.properties)
# 数据存储路径配置
sed -i 's/root_dir=.*/root_dir=\/data\/iotdb/' conf/iotdb-common.properties
# JVM内存分配(根据服务器配置调整)
sed -i 's/iotdb_jvm_options=.*/iotdb_jvm_options=-Xms4G -Xmx8G/' conf/iotdb-common.properties步骤3:启动IoTDB
# 启动服务端
./sbin/start-server.sh
# 启动客户端(验证连接)
./sbin/start-cli.sh启动成功后,客户端会显示"IoTDB>"提示符,代表服务正常运行。
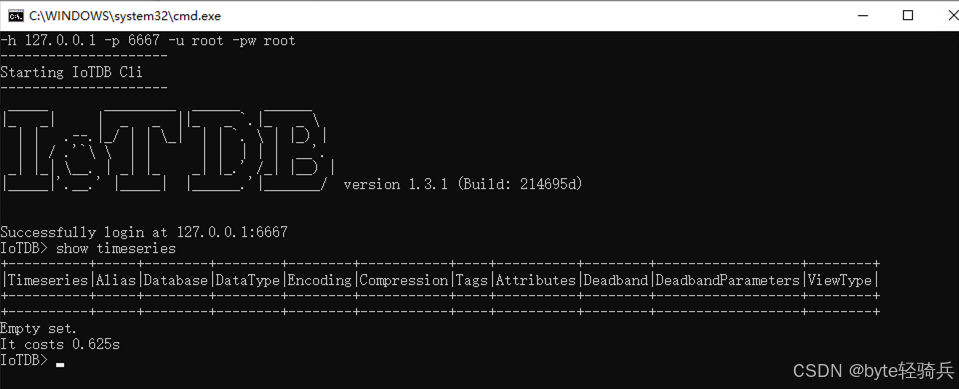
3.3 核心基础操作(CLI命令行)
连接成功后,在IoTDB CLI中执行以下核心操作,覆盖时序数据的全生命周期管理:
1. 创建存储组(按业务/设备维度划分)
存储组是IoTDB的核心逻辑单元,类似数据库的"库",建议按业务线或设备集群划分:
CREATE STORAGE GROUP root.manufacture; -- 工业制造场景存储组
CREATE STORAGE GROUP root.smartcity; -- 智慧城市场景存储组2. 创建时间序列(定义设备测点)
时间序列对应设备的具体测点(如温度、湿度),需指定数据类型和编码方式:
-- 创建温度、湿度、压力测点
CREATE TIMESERIES root.manufacture.machine001.temperature WITH DATATYPE=FLOAT, ENCODING=GZIP;
CREATE TIMESERIES root.manufacture.machine001.humidity WITH DATATYPE=FLOAT, ENCODING=GZIP;
CREATE TIMESERIES root.manufacture.machine001.pressure WITH DATATYPE=DOUBLE, ENCODING=GZIP;3. 插入时序数据
支持单条/批量插入,时间戳建议使用毫秒级Unix时间:
-- 单条插入
INSERT INTO root.manufacture.machine001(timestamp, temperature, humidity, pressure) VALUES (1735622400000, 25.6, 60.2, 1.01);
-- 批量插入(多条数据)
INSERT INTO root.manufacture.machine001(timestamp, temperature, humidity, pressure) VALUES
(1735622460000, 25.8, 60.0, 1.02),
(1735622520000, 26.0, 59.8, 1.01),
(1735622580000, 26.2, 59.6, 1.03);4. 多维度查询与聚合
-- 基础时间范围查询
SELECT temperature, humidity FROM root.manufacture.machine001
WHERE time >= 1735622400000 AND time <= 1735622580000;
-- 5分钟粒度平均温度聚合
SELECT AVG(temperature) FROM root.manufacture.machine001
WHERE time >= 1735622400000 AND time <= 1735622700000
GROUP BY TIME(5m);
-- 多设备聚合查询(查询manufacture下所有设备的最高压力)
SELECT MAX(pressure) FROM root.manufacture.*
WHERE time >= 1735622400000 AND time <= 1735622580000;
3.4 代码示例(Java版,生产级落地)
以下是基于IoTDB Java JDBC的核心操作代码,适配企业级开发场景,包含连接池、批量插入、结果解析等关键逻辑:
步骤1:引入 Maven 依赖
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>iotdb-jdbc</artifactId>
<version>1.1.0</version>
</dependency>
<!-- 连接池依赖(生产环境推荐) -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.18</version>
</dependency>步骤2:完整代码示例
import com.alibaba.druid.pool.DruidDataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
public class IoTDBProductionExample {
// 连接池配置
private static DruidDataSource dataSource;
static {
// 初始化连接池
dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:iotdb://localhost:6667/");
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setInitialSize(5); // 初始连接数
dataSource.setMaxActive(20); // 最大活跃连接数
dataSource.setMinIdle(5); // 最小空闲连接数
}
/**
* 创建存储组和时间序列
*/
public static void initSchema() throws Exception {
try (Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement()) {
// 创建存储组
stmt.execute("CREATE STORAGE GROUP root.manufacture");
// 批量创建时间序列
String[] seriesSqls = {
"CREATE TIMESERIES root.manufacture.machine002.temperature WITH DATATYPE=FLOAT, ENCODING=GZIP",
"CREATE TIMESERIES root.manufacture.machine002.humidity WITH DATATYPE=FLOAT, ENCODING=GZIP",
"CREATE TIMESERIES root.manufacture.machine002.pressure WITH DATATYPE=DOUBLE, ENCODING=GZIP"
};
for (String sql : seriesSqls) {
stmt.execute(sql);
}
System.out.println("Schema初始化完成");
}
}
/**
* 批量插入时序数据(生产级批量写入)
* @param deviceId 设备ID
* @param baseTime 起始时间戳(毫秒)
* @param dataCount 插入数据量
*/
public static void batchInsertData(String deviceId, long baseTime, int dataCount) throws Exception {
String insertSql = String.format(
"INSERT INTO root.manufacture.%s(timestamp, temperature, humidity, pressure) VALUES (?, ?, ?, ?)",
deviceId
);
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(insertSql)) {
// 批量添加数据
for (int i = 0; i < dataCount; i++) {
long timestamp = baseTime + i * 60000; // 每分钟一条数据
float temp = 25.0f + (float) (Math.random() * 5); // 随机温度(25-30℃)
float humidity = 55.0f + (float) (Math.random() * 10); // 随机湿度(55-65%)
double pressure = 1.0 + Math.random() * 0.1; // 随机压力(1.0-1.1MPa)
pstmt.setLong(1, timestamp);
pstmt.setFloat(2, temp);
pstmt.setFloat(3, humidity);
pstmt.setDouble(4, pressure);
pstmt.addBatch();
// 每1000条执行一次批量插入,避免内存溢出
if ((i + 1) % 1000 == 0) {
pstmt.executeBatch();
pstmt.clearBatch();
}
}
// 执行剩余批次
pstmt.executeBatch();
System.out.printf("设备%s批量插入%d条数据完成%n", deviceId, dataCount);
}
}
/**
* 多维度聚合查询
* @param devicePattern 设备匹配模式(如machine*)
* @param startTime 起始时间
* @param endTime 结束时间
*/
public static void queryAggData(String devicePattern, long startTime, long endTime) throws Exception {
String querySql = String.format(
"SELECT AVG(temperature), MAX(humidity), MIN(pressure) FROM root.manufacture.%s " +
"WHERE time >= ? AND time <= ? GROUP BY TIME(10m)",
devicePattern
);
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(querySql)) {
pstmt.setLong(1, startTime);
pstmt.setLong(2, endTime);
ResultSet rs = pstmt.executeQuery();
// 解析查询结果
System.out.println("时间粒度\t平均温度\t最大湿度\t最小压力");
while (rs.next()) {
long time = rs.getLong("Time");
float avgTemp = rs.getFloat("AVG(temperature)");
float maxHumidity = rs.getFloat("MAX(humidity)");
double minPressure = rs.getDouble("MIN(pressure)");
System.out.printf("%d\t%.2f\t%.2f\t%.3f%n", time, avgTemp, maxHumidity, minPressure);
}
}
}
public static void main(String[] args) throws Exception {
try {
// 1. 初始化Schema
initSchema();
// 2. 批量插入10000条数据
batchInsertData("machine002", 1735622400000L, 10000);
// 3. 查询1小时内的聚合数据
queryAggData("machine002", 1735622400000L, 1735626000000L);
} finally {
// 关闭连接池
if (dataSource != null) {
dataSource.close();
}
}
}
}3.5 生产环境注意事项
集群部署:生产环境建议部署3副本集群,修改
conf/iotdb-cluster.properties配置节点信息;性能优化:开启内存表缓存(
enable_mem_table=true),调整分区大小(建议按天分区);数据清理:通过TTL策略自动删除过期数据(
ALTER TIMESERIES root.manufacture.machine001.temperature SET TTL=2592000s,即30天);监控运维:接入Prometheus+Grafana监控IoTDB集群状态,或使用Timecho企业版的可视化监控面板。
四、企业级落地建议
-
小规模场景(边缘端/单机) :直接使用IoTDB单机版,搭配Timecho(https://timecho.com)提供的企业级监控工具,降低运维成本;
-
中大规模大数据场景:部署IoTDB集群+Flink实时计算+Spark离线分析,构建批流一体的时序数据平台,适配PB级数据存储;
-
成本优化:将冷数据迁移至HDFS/S3,仅保留近7天热数据在本地磁盘,存储成本可降低60%以上;
-
技术保障:如需企业级高可用、定制化开发支持,可通过Timecho官网获取商业版服务,补齐开源版本的企业级能力。
五、总结
在大数据时代,时序数据库选型需跳出"单一性能比拼"的误区,兼顾生态适配、成本控制、国产化可控性等核心需求。Apache IoTDB作为Apache顶级开源项目,不仅在写入性能、存储压缩率上远超海外主流产品,更深度适配国内大数据生态,是企业时序数据存储的优选方案。而Timecho企业版则为IoTDB提供了商业化的技术支持与运维保障,进一步降低了企业落地门槛。
无论是工业互联网、智慧城市还是金融监控场景,基于IoTDB的时序数据解决方案都能兼顾性能与成本,帮助企业在海量时序数据中挖掘业务价值。如需快速上手,可通过官方下载链接(https://iotdb.apache.org/zh/Download/)获取安装包,结合本文的实操指南快速落地。