针对企业级ELK应用的最佳实践 ,其核心已从简单的"日志收集工具"演进为驱动系统稳定、赋能业务增长的工程体系。最佳实践可总结为:一个中心思想、三个关键阶段和六个核心实施要点。
一、核心理念与实施框架
核心理念 :日志治理不是一次性的工具部署,而是一个随业务持续迭代的工程过程 。其最终目标是让日志从"故障排查的线索"转变为 "系统运行的全息投影"和"业务洞察的驱动引擎" 。
核心框架:最佳实践遵循一个清晰的行动路径,我将其整理为下图,以便你直观地理解整个逻辑:
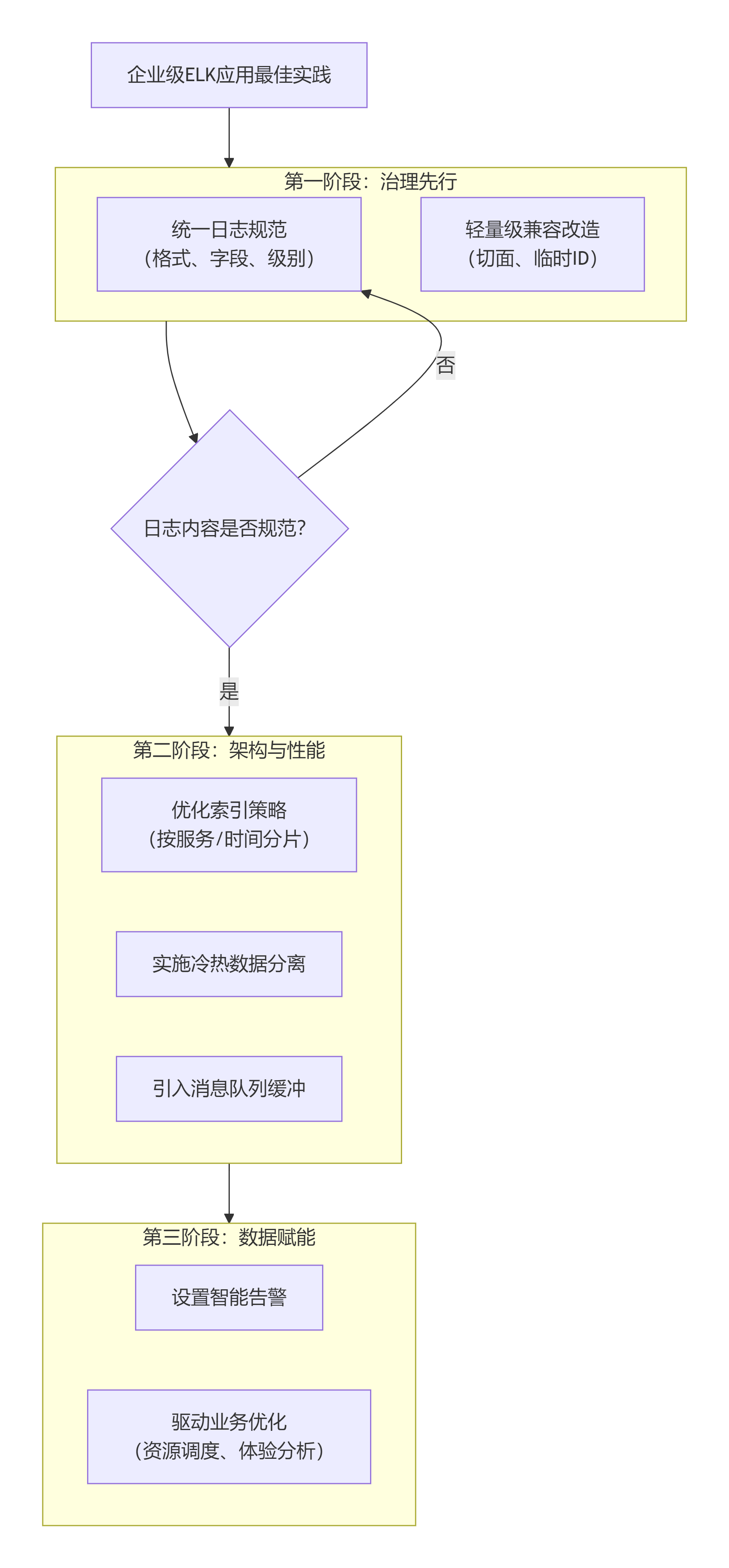
接下来,我们来详细解析图中的每一个关键环节。
二、六个关键实践要点详解
-
先规范,后存储:统一日志格式
-
为什么重要 :混乱的原始日志会严重降低存储和查询效率,是后续所有工作的基础障碍-5。规范化的日志是进行高效检索和关联分析的前提。
-
如何做 :在应用层面强制统一日志格式,必须包含
TraceID(全链路追踪) 、时间戳、服务名、日志级别、业务标识等核心字段。可以参考Elastic通用模式(ECS) 来建立标准。一个重要的原则是:线上环境应避免输出大量无意义的调试日志。
-
-
新旧兼容:渐进式改造
-
挑战:对无法直接改造的遗留系统,不能为了统一日志而重构整个模块。
-
解决方案 :采用轻量级的日志切面(AOP) 等技术手段,在尽量少改动代码的前提下,为老模块注入
TraceID等必要字段,实现与新体系的兼容。
-
-
优化索引与存储策略
-
问题:简单的按天创建大索引,在查询时需要扫描大量无关数据,导致响应缓慢。
-
最佳实践:
-
索引策略 :采用 "按服务 + 按时间(如小时)" 的模式创建索引(例如
order-service-2024121710),可以大幅缩小查询范围,将查询时间从分钟级降至秒级。 -
字段映射 :为
TraceID、订单ID等用于精确匹配的字段,在Elasticsearch中设置为keyword类型,而非默认的、会分词的text类型。 -
冷热分离:为核心数据(如近7天)配置高性能(SSD)节点,为历史数据配置大容量(HDD)节点或归档到对象存储,可以显著降低成本。
-
-
-
构建高可用与可扩展的架构
-
解耦与缓冲 :在日志采集器(如Filebeat)和处理层(如Logstash)之间引入Kafka、Redis等消息队列,可以应对流量洪峰,防止数据丢失,并实现组件间解耦。
-
集群化部署 :Elasticsearch、Logstash等核心组件均应以集群模式部署,避免单点故障,并通过分片机制实现水平扩展。
-
-
从监控到预警:主动发现问题
-
智能告警:利用Kibana或第三方监控系统的告警功能,基于日志模式设置规则。例如,监控"订单创建成功但10分钟内未支付"的日志数量异常,从而主动发现前端功能故障。
-
集成APM :将日志中的
TraceID与应用性能监控(APM) 工具(如SkyWalking)的调用链关联,实现从日志点击直接查看完整的性能链路,极大提升排障效率。
-
-
超越运维:驱动业务决策
-
业务洞察 :分析用户登录日志,可以按地域和时段识别流量高峰,为服务器弹性扩容提供精准依据。
-
性能优化 :分析任务执行日志的耗时分布,可以优化资源调度算法,提升整体资源利用率。
-
三、架构演进与新技术考量
随着业务规模扩大和技术发展,经典的ELK架构也在演进,你可以关注以下趋势:
-
从ELK到EFK :在某些需要处理复杂流式数据、要求高吞吐和精确一次处理的场景下,可以考虑用 Flink替代Logstash,构成EFK架构。Flink的集群化、状态管理和丰富计算模型在处理能力上更具优势。
-
成本与性能的平衡 :对于海量历史日志的查询,可以采用Elasticsearch的 Searchable Snapshot 等新特性,将数据存储在廉价对象存储上,同时保持可查询性,以平衡存储成本与访问需求。
四、实施路线图建议
不要追求"大而全"的一次性改造。建议按以下阶段推进:
-
试点阶段:选择一个核心业务系统,完成日志规范制定和ELK基础集群搭建。
-
推广阶段:将试点经验推广到其他关键系统,逐步引入消息队列、完善监控告警。
-
赋能阶段:打通日志与APM,建立业务分析仪表盘,让数据开始驱动优化决策。
总结来说,企业级ELK的成功不在于组件部署,而在于将日志作为系统工程来治理,通过规范先行、架构可靠、主动预警和业务赋能的闭环,使其真正成为企业的数据资产。
注:在实施过程中,系统安全和访问控制(如为Kibana和Elasticsearch配置认证授权)是必不可少的一环,必须从建设之初就予以规划。