为什么需要用transformer?
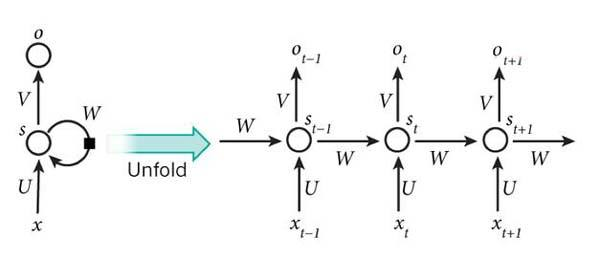
在没有transformer的时候,我们都是用什么来完成这系列的任务的呢?
其实在之前我们使用的是RNN(或者是其的单向或者双向变种LSTM/GRU等) 来作为编解码器。RNN模块每次只能够吃进一个输入token和前一次的隐藏状态,然后得到输出。它的时序结构使得这个模型能够得到长距离的依赖关系,但是这也使得它不能够并行计算,模型效率十分低。
transformer模型
2017年google的机器翻译团队在NIPS上发表了Attention is all you need的文章,开创性地提出了在序列转录领域,完全抛弃 CNN和RNN,只依赖Attention-注意力结构的简单的网络架构,名为Transformer;论文实现的任务是机器翻译。
Transformer进行机器翻译的结构仍然是编码器-解码器结构,但是在编码器和解码器内部采用了Self-Attention机制。这个想法是在语言的翻译过程中,不只有从目标语言到源语言的联系,目标语言和源语言内部同样存在联系(可以认为语法也包括在内),因此可以通过一个自注意力机制来捕捉这种联系
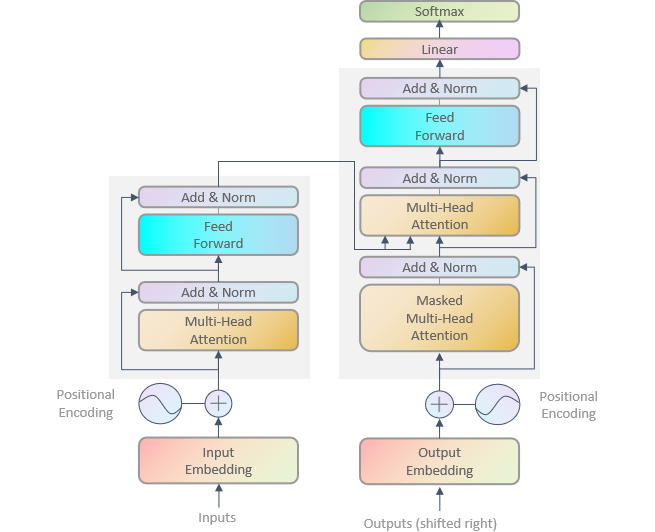
Transformer的结构如图,左侧即为编码器,右侧为解码器: 编码器由N个block堆叠而成;每个block有两层,第一层是论文提出的Multi-Head Attention,模型的Self-Attention就是由这个模块学习的,之后经过残差连接和LayerNorm输入下层,第二层是一个前向网络,同样经过残差连接和LayerNorm输入下个Block;如此反复,第N个Block的输出会输入到解码器的各层中。解码器同样由N个Block堆叠而成;但是每个Block分为三层,第一层是和编码器一样的Self-Attention,第二层是接收编码器输出的Multi-Head Attention,这一层是目标语言对源语言的Co-Attention,第三层是和编码器第二层一样的前向层。
基本结构
Transformer 结构可一句话概括:由输入、6 层堆叠的编码器块)、6 层堆叠的解码器块,以及经线性层和 Softmax 的输出组成 ,实现序列到序列的转换。
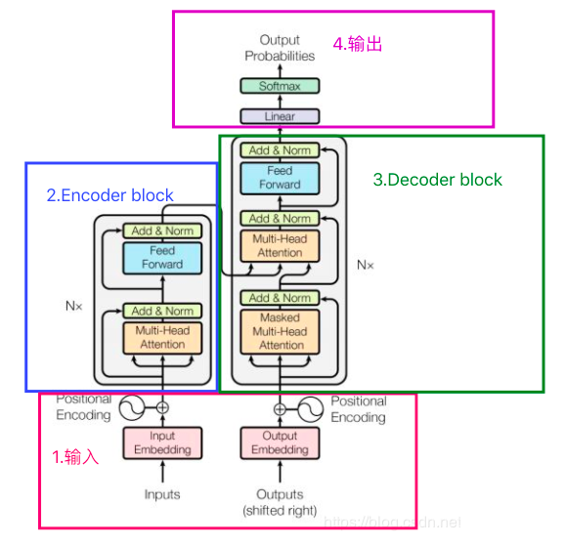
输入模块
输入模块要解决两个关键问题:词的语义怎么表示? 以及 词的顺序怎么体现? 对应到模块里,就是词向量化(词 Embedding + 位置 Embedding) 的组合。以"我有一只猫"为例,此句一共有4个词,比如句子 "我 有 一只 猫",每个词(token)都要转换成向量。具体的转换过程:
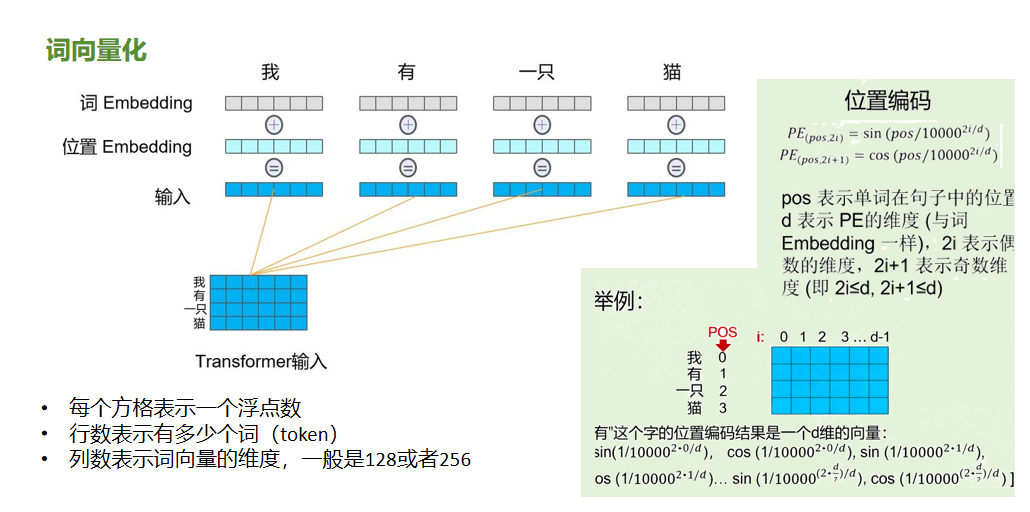
灰色方格:这些字,经过词 Embedding,会变成一组浮点数
浅蓝色方格:语言光有语义还不够,顺序也很重要,所以得给每个词的位置加编码。
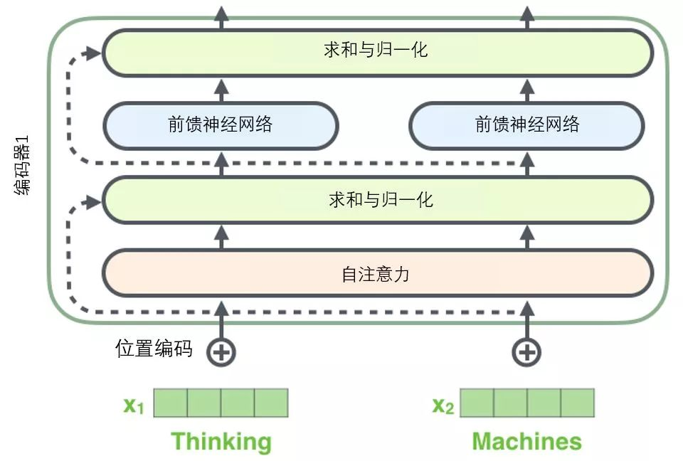
右侧的公式就是就是用正弦、余弦函数给位置做标记,区分一句话里词的先后顺序。 蓝色方格:最后,词 Embedding 和位置 Embedding 相加,得到每个词的最终输入向量 最后形成的输入,行数是词的数量,列数是词向量维度。每个方格的浮点数,就是融合了语义 + 位置的编码结果,模型后续的注意力机制、前馈网络,都基于这些向量 "理解" 句子
enconder block
enconder block是6个堆叠在一起组成的。每一个小的encoder有包括自注意力、前馈神经网络,以及他们的中间链接部分。 下面将详细介绍 一个编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中
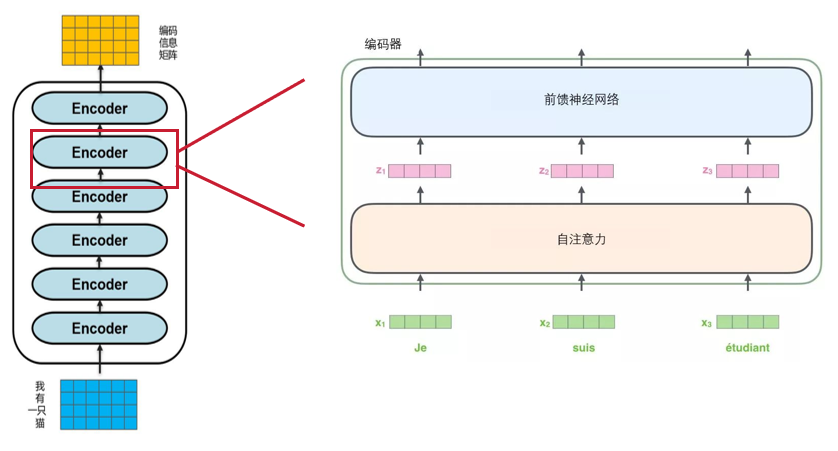
在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个"层-归一化"步骤。
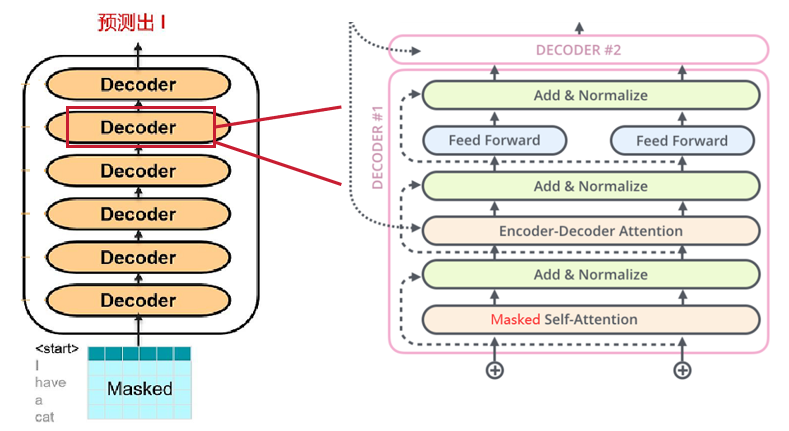
Decoder block
同encoder一样,Decoder解码器:Transformer的解码器由6个相同的层组成,每层包含三个子层:掩蔽自注意力层、Encoder-Decoder注意力层和逐位置的前馈神经网络。每个子层后都有残差连接和层归一化操作,简称Add&Norm。这样的结构确保解码器在生成序列时,能够考虑到之前的输出,并避免未来信息的影响。
Encoder-Decoder 工作过程
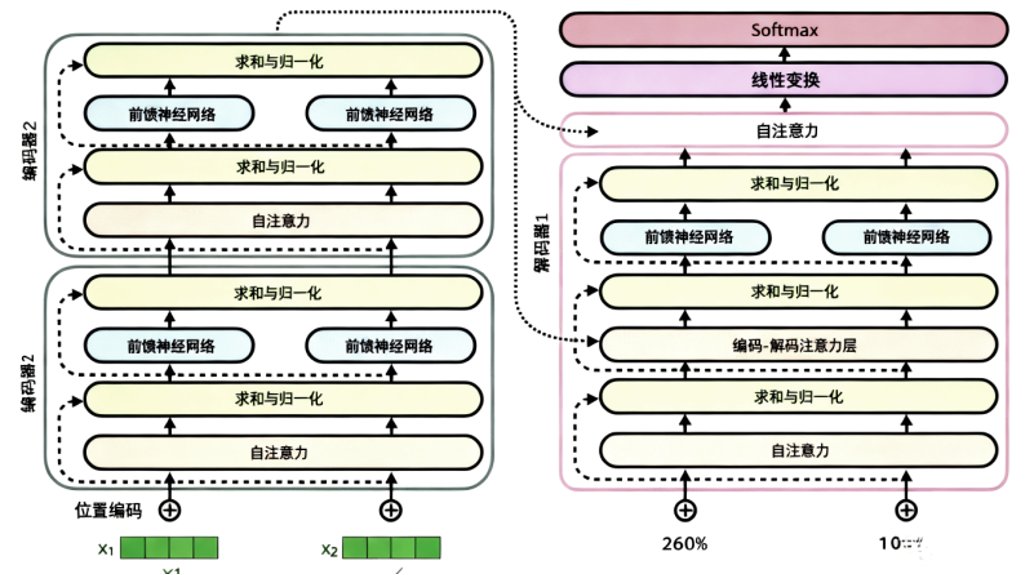
编码器输出:编码器处理完输入序列后,会生成一组上下文向量。这些向量被分解成 键向量 K 和 值向量 V Encoder-Decoder :解码器在生成每个词时,会基于当前的隐藏状态生成 查询向量 Q。计算方式与自注意力类似,只不过这时:Q 来自解码器本身,K,V 来自编码器的输出。这样解码器就能"对齐"输入序列,决定应该关注输入的哪些部分。 逐步生成;解码器利用跨注意力层得到的上下文信息,结合已生成的部分,预测下一个词。 每生成一个新词,就把它作为输入反馈给解码器,直到生成终止符号。
输出层
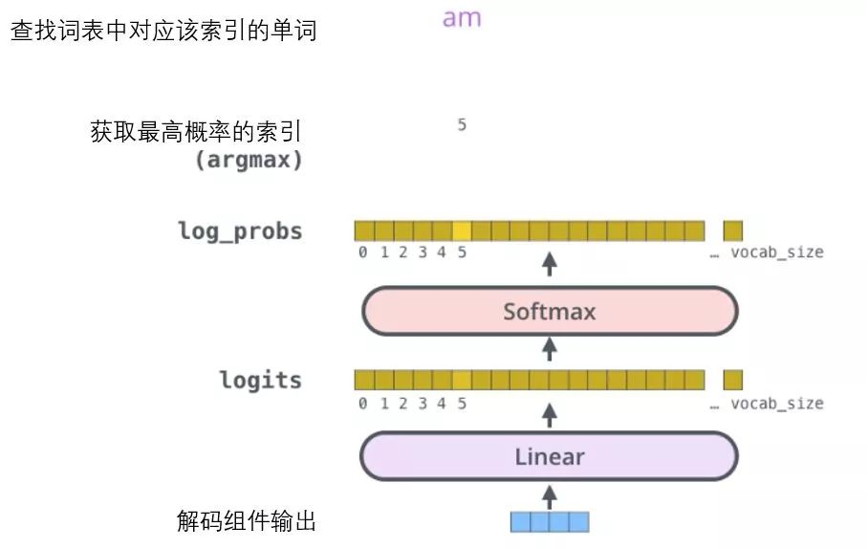
解码组件最后会输出一个实数向量。我们如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。
此页的图片是:从底部以解码器组件产生的输出向量开始。之后它会转化出一个输出单词。