你是否好奇,人类是如何轻松识别出眼前的人脸、花朵或风景的?当目光聚焦,视网膜先把外界景象转化成无数像素信号,就像给世界拍了张 "像素快照"。紧接着,大脑皮层的特殊细胞化身 "视觉侦探",从杂乱像素里敏锐捕捉边缘、方向,把画面拆解成基础线条。
这套从底层像素到高层语义的递进处理逻辑,给人工智能带来巨大启发------能不能模仿人类视觉的分层智慧,让机器也拥有 "看懂" 图像的能力?于是,卷积神经网络(CNN)应运而生,它像为 AI 打造的 "数字视觉系统",复刻生物视觉的分层抽象,开启了机器智能识别的全新篇章。
CNN的主要结构
卷积神经网络一般由以下结构组成:①卷积层(后面常跟随激活函数)②池化层 ③全连接层。
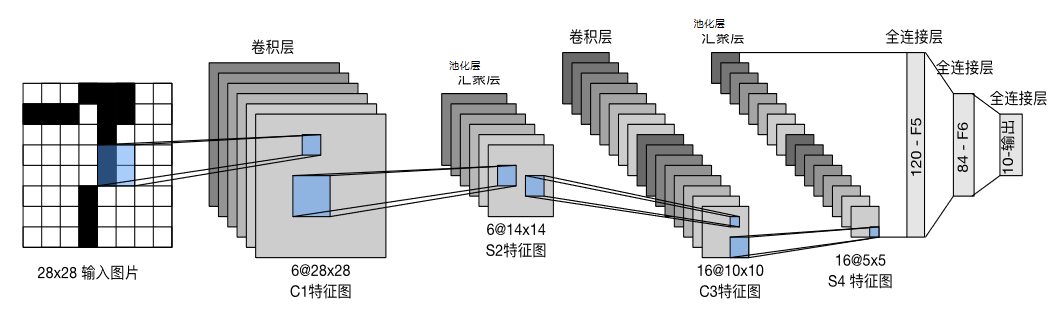
输入
当我们用 CNN 处理一张猫咪图片时,像素就是计算机 "看见" 的最基础单元。
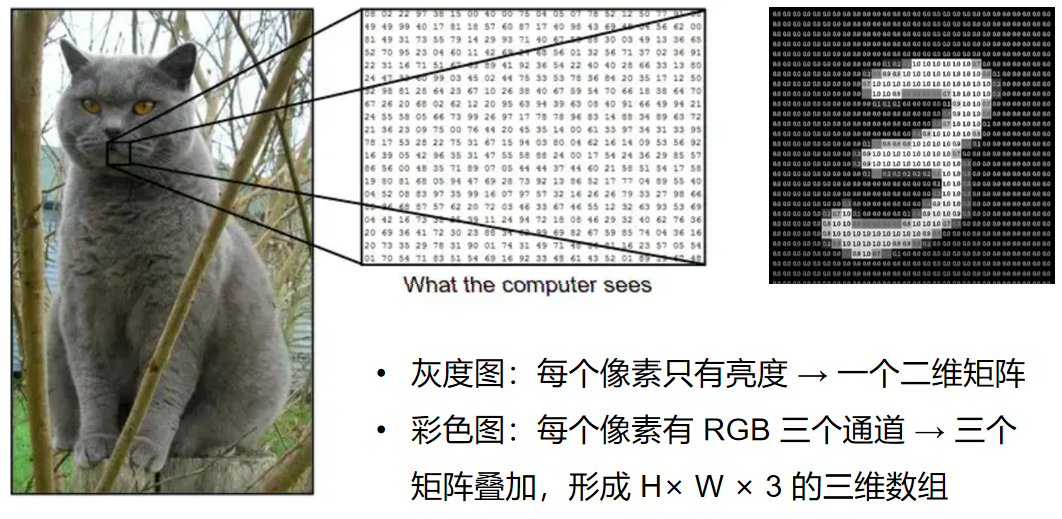
对人类来说,这是毛茸茸的可爱猫咪;但在计算机眼里,它是密密麻麻的数值矩阵------
- 若图片是灰度图,每个像素仅记录 "亮度" 信息,整幅图会被转化成一个二维矩阵,矩阵里的每个数字,对应着像素点的明暗程度(比如 0 代表最暗,255 代表最亮 );
- 要是彩色图(像常见的 RGB 图 ),每个像素会拆成红(R)、绿(G)、蓝(B)三个通道,相当于三张 "灰度矩阵" 叠加,最终形成一个 H×W×3 的三维数组(H 是高度、W 是宽度 )。
这些由像素数值组成的矩阵 / 数组,就是 CNN 真正 "吃进去" 的输入。后续 CNN 的卷积、池化等操作,本质上都是对这些像素数值的 "智能筛选与抽象",一步步从基础像素里挖出 "边缘、纹理、形状",最终让模型认出 ------"这是一只猫" 。
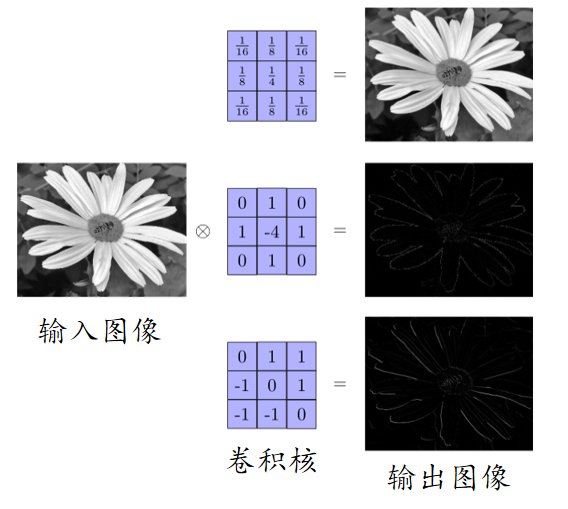
卷积层
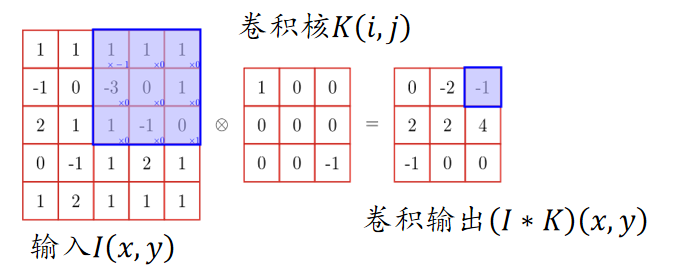
卷积层的作用是提取特定的特征,例如特定的纹理或者边缘。 卷积核的输出图像常被称为特征图(feature map)。 根据卷积核的不同,提取到的特征也不相同。
卷积操作是 CNN 的核心,它可以看作是一种滑动匹配和加权求和的操作
具体操作:
- 把一个小的卷积核(滤波器)在输入图像上滑动;
- 每个位置上,把卷积核的权重和对应的图像像素相乘再求和,得到一个数值;
- 将所有位置的结果组成新的矩阵,这个矩阵就是特征图。
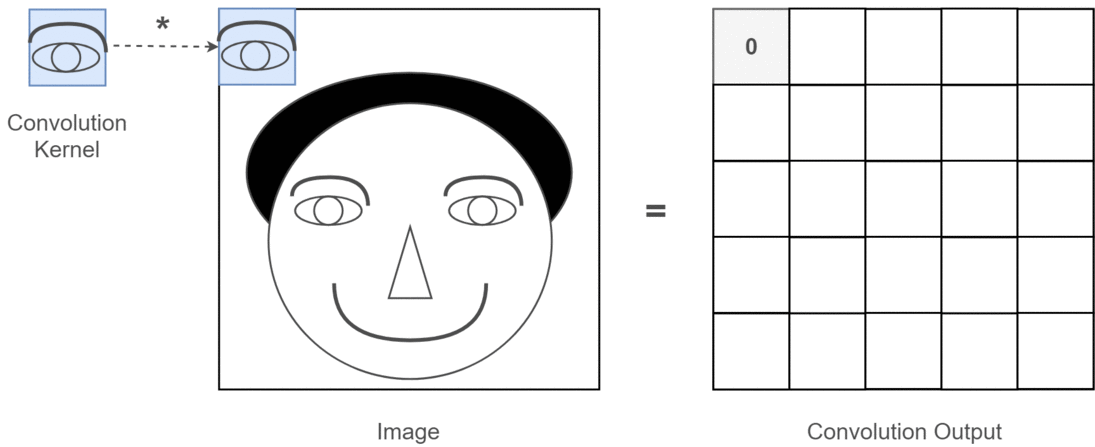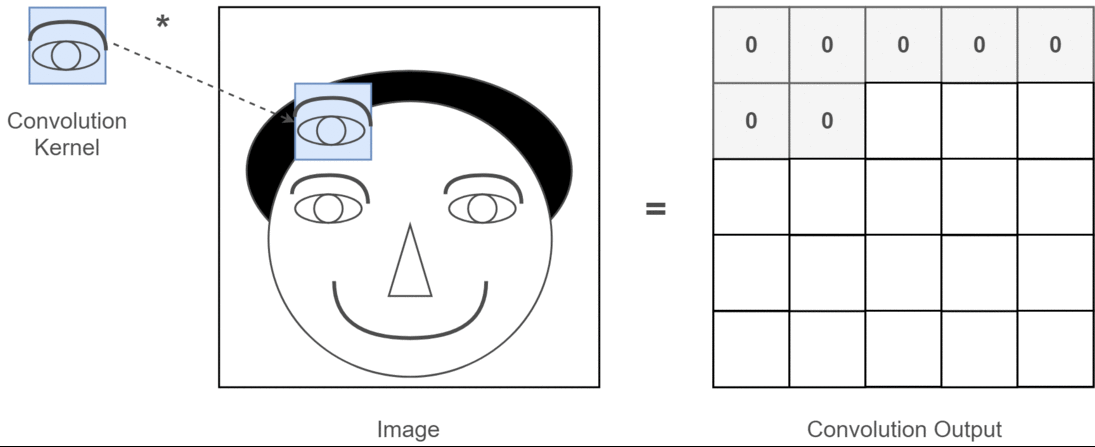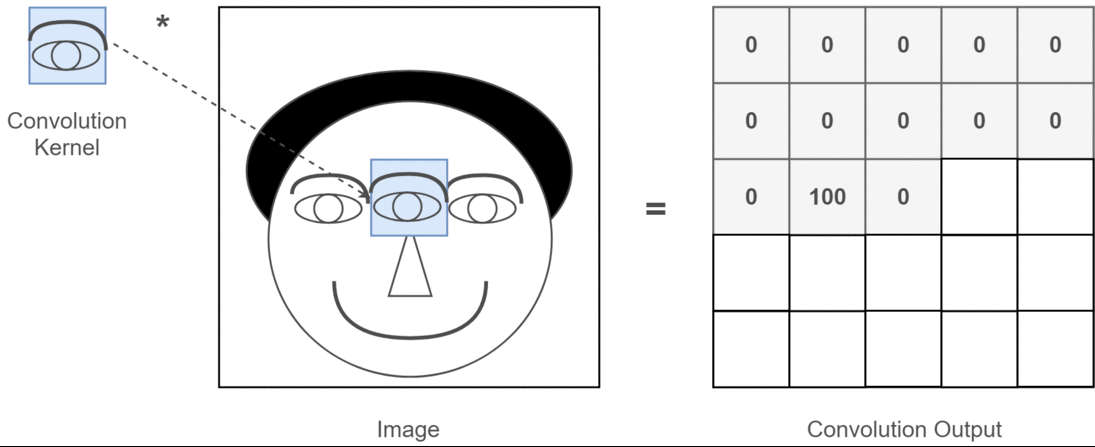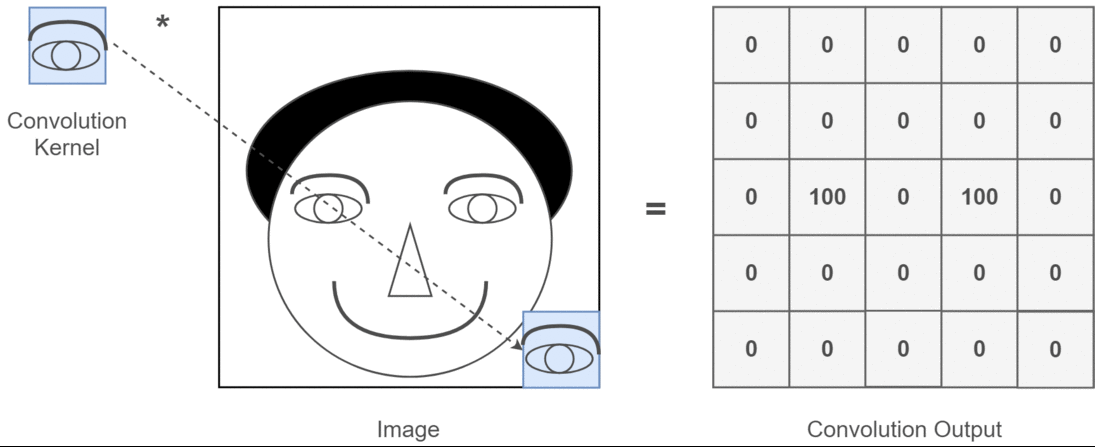
卷积神经网络中,常使用二维离散卷积,用于提取输入数据(通常是图像)的特征。卷积操作即将卷积核在输入数据上滑动,并计算卷积核与输入数据的局部区域之间的点积:
其中: 是输入,例如图像;
是卷积核
是输出特征图的坐标;
是卷积核的坐标
卷积的基本属性:
- 卷积核:卷积操作的感受野,直观理解就是一个滤波矩阵
- 步长:卷积核遍历特征图时每步移动的像素
- 填充:处理特征图边界的方式,一般有两种方式:不填充卷积,只对输入像素操作,输出特征图会变小;或对边界填充(通常为0),输出特征图可保持与输入相同尺寸
- 通道:卷积层的通道数(层数)
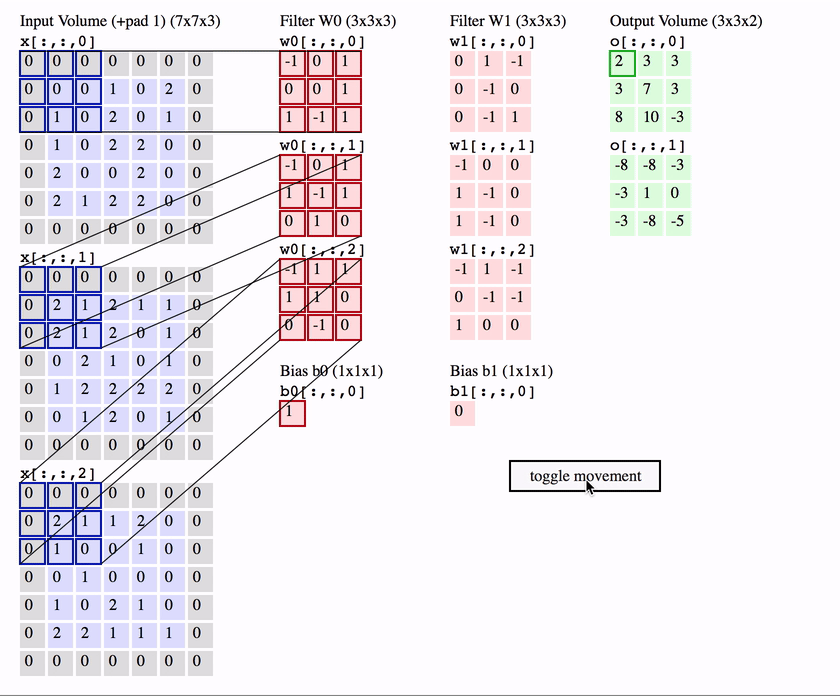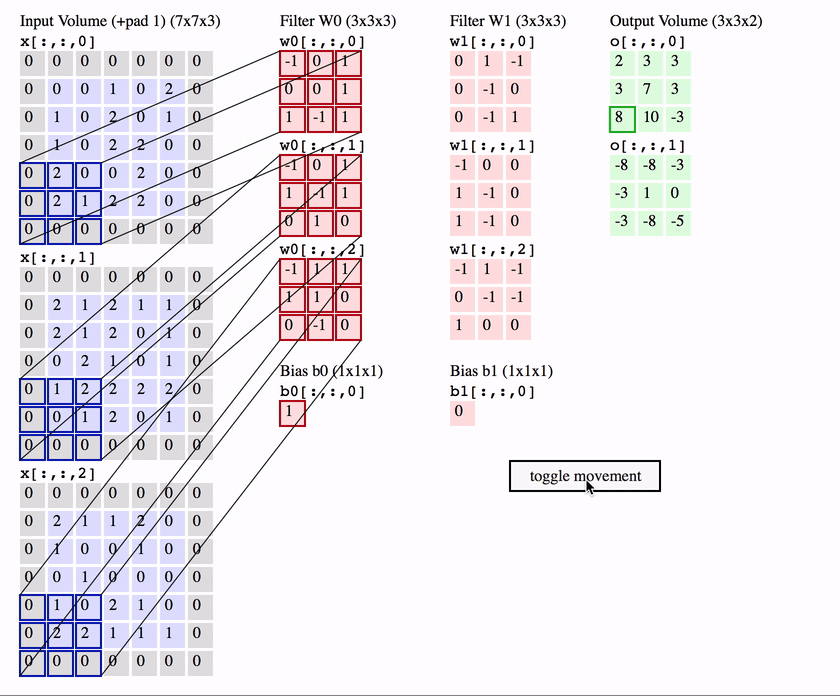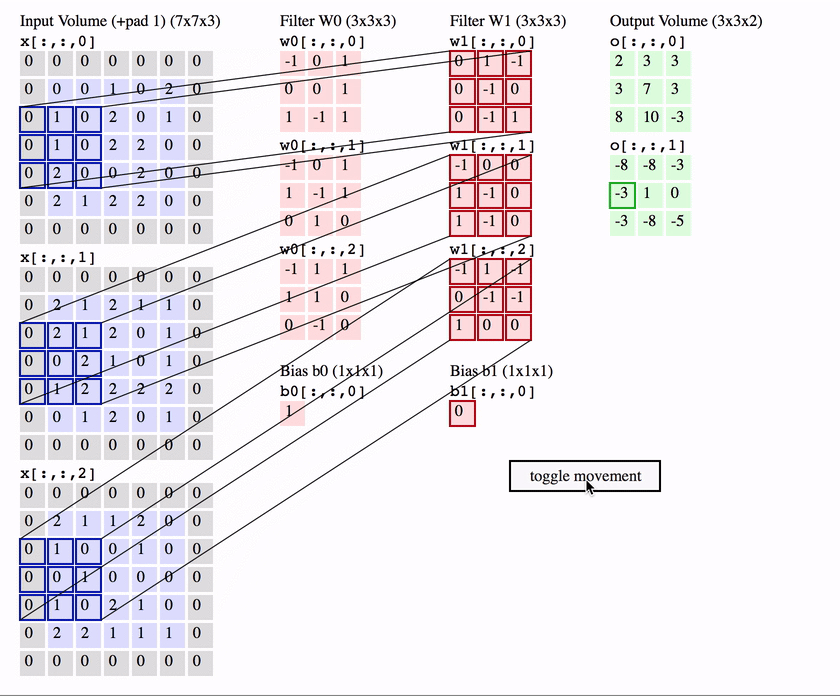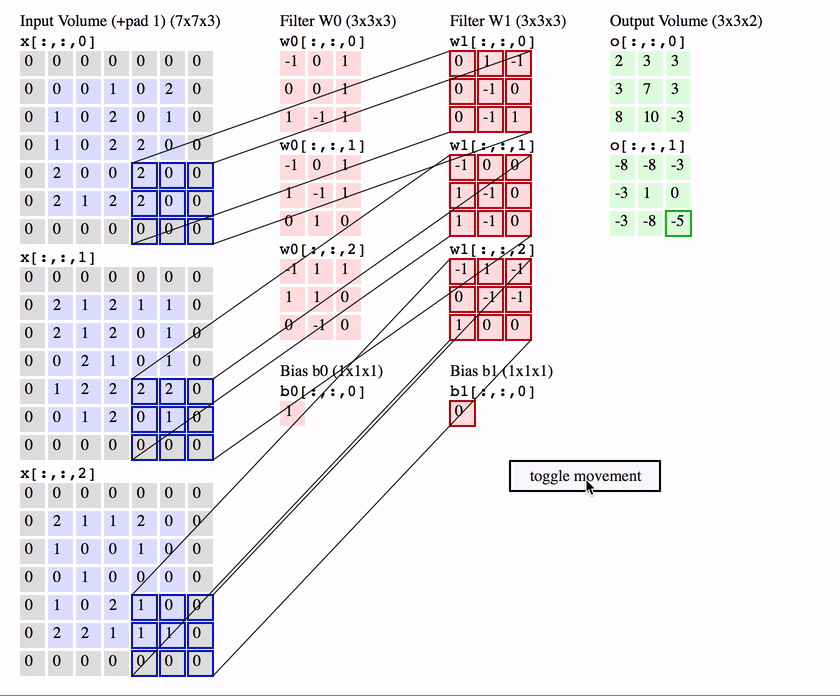
但是这样也会出现一个问题,可以观察一下:
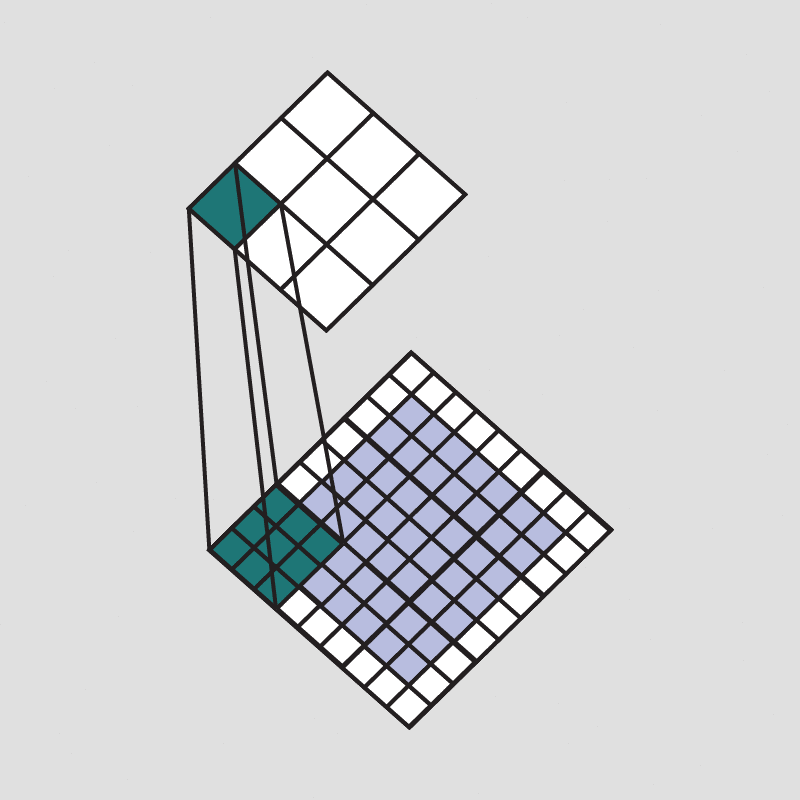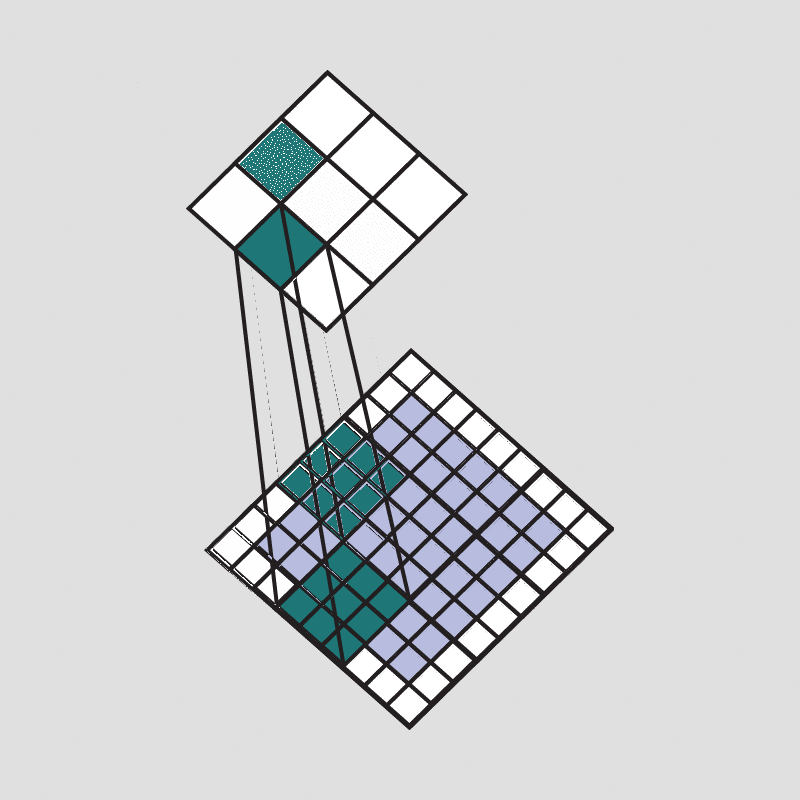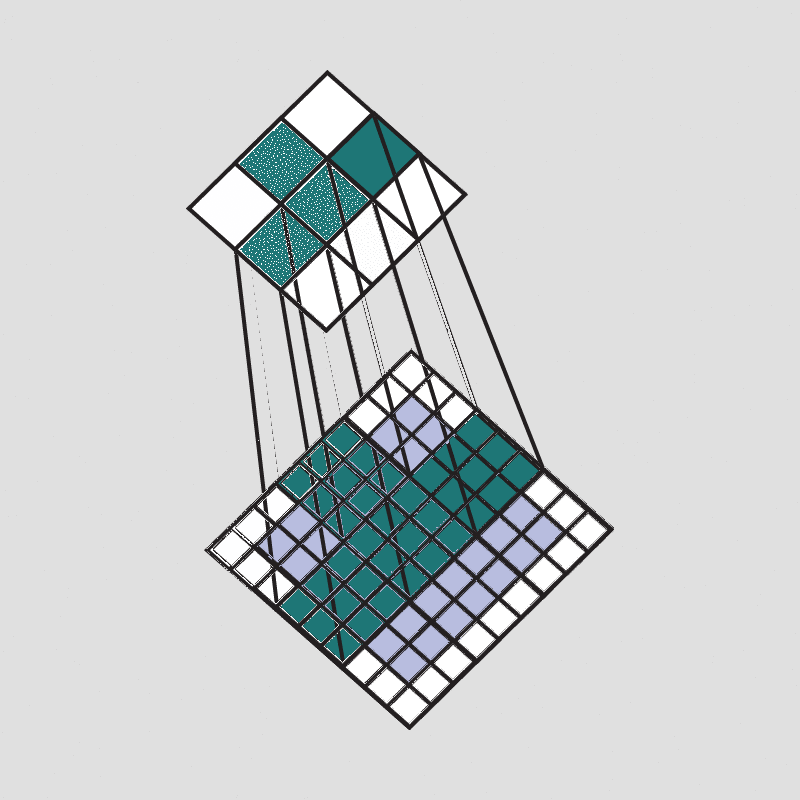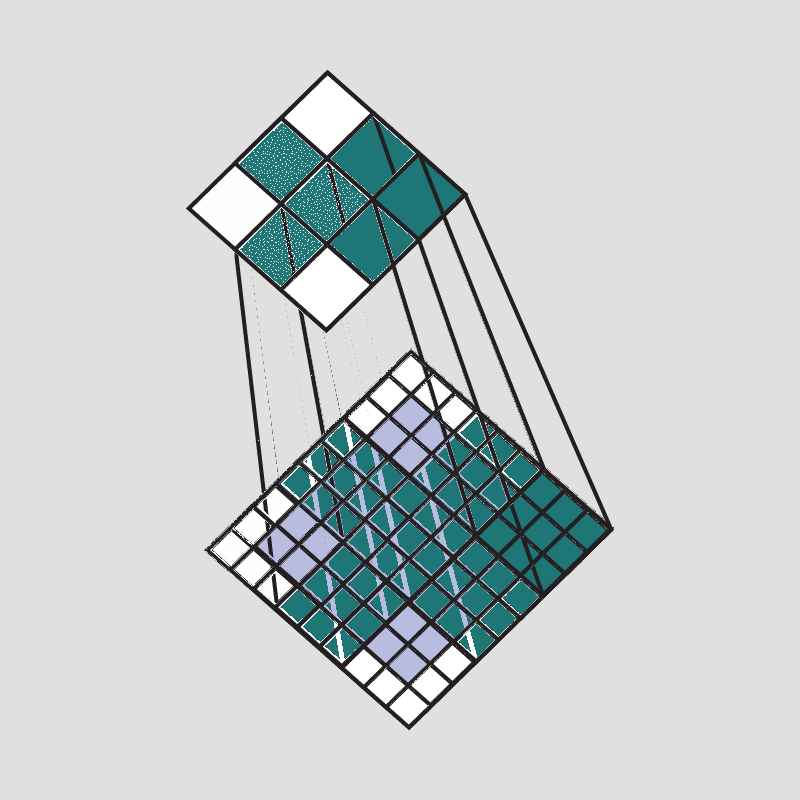
可以看到,随着每次卷积计算操作,图像信息会不断的因卷积而被缩小,最后甚至缩小到1。 对此,常采用填充来解决该问题。
想让输出特征图和输入一样大?需要用填充实现。
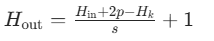
p 是填充数,s 是步幅,Hk 是卷积核高度
常见填充类型:
- 零填充(Zero Padding):最基础也最常用,填 0 简单直接,不会引入额外信息,适合大多数场景。
- 对称填充(镜像填充):填的是边缘像素的 "镜像",比如图像最上边是 1,2,3,填充后上边可能变成 3,2,1,1,2,3 。能更好保留边缘视觉信息,常用在图像分割、边缘检测任务。
- 反射填充:类似对称填充,但更 "平滑",把边缘像素当 "镜子" 反射出去,避免额外信息干扰,在分类、检测任务里也很常见。
现在又有另一个问题,如果是PGB图像,应该怎么做呢?这就要引入多通道卷积了:
多通道卷积:拥有多个通道的卷积,例如处理彩色图像时,分别对R, G, B这3个层处理的3通道卷积,再将三个通道的卷积结果进行合并。
每个卷积核都按 "单输出通道" 的方式,和输入图像做卷积,得到 1 个单通道特征图;N 个卷积核就会输出 N 个特征图,组成多通道输出(形状 H′×W′×N )。关键规则:
- 卷积核通道数 ≡ 输入通道数(必须对齐 );
- 输出通道数 = 卷积核个数(用多少核,出多少通道 )。
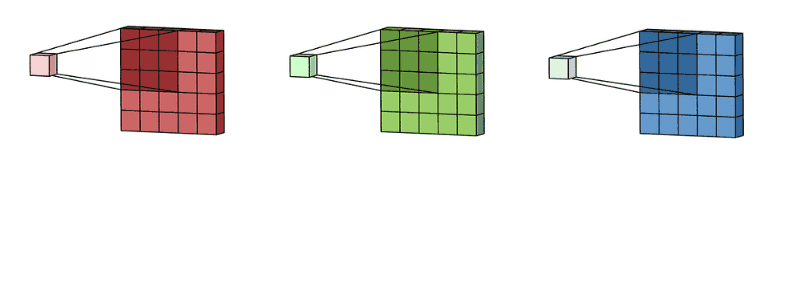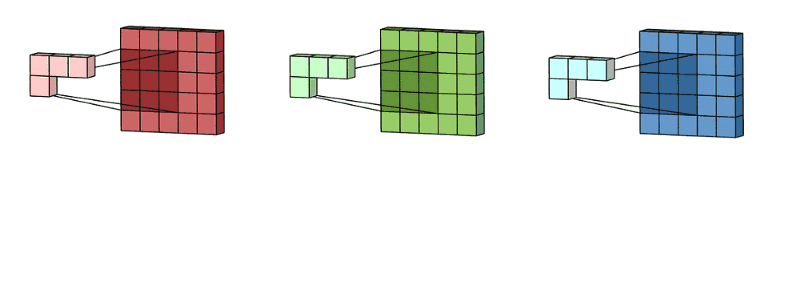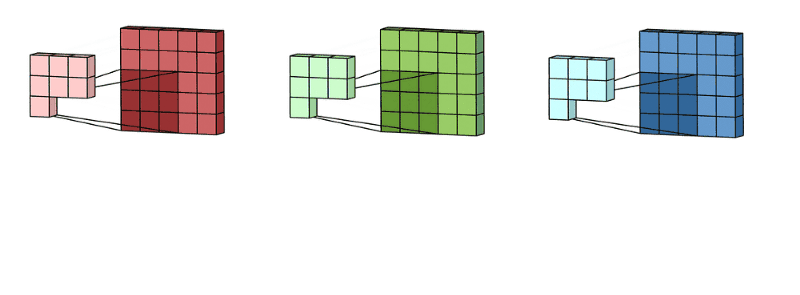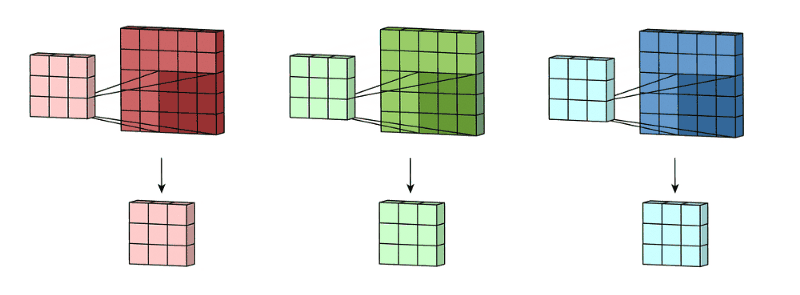
卷积的效果:
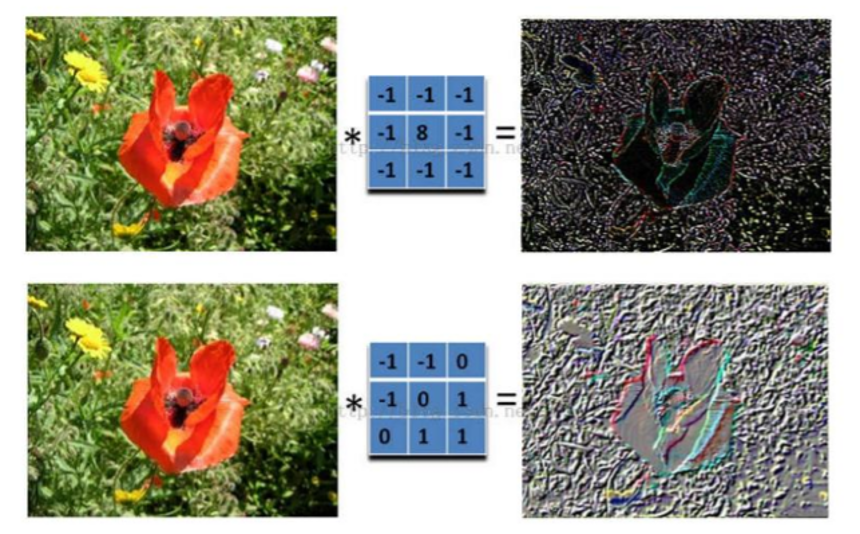
具体来说,左边是图像输入,中间部分就是卷积核,不同的会得到不同的输出数据,比如颜色深浅、轮廓 相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓
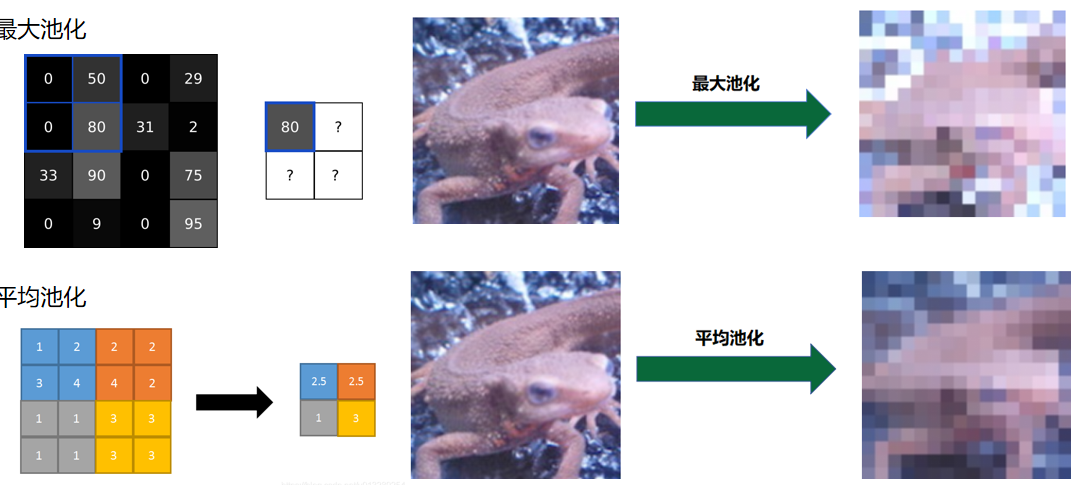
池化层
池化层(Pooling Layer)是卷积神经网络(CNN)里的 "瘦身师" 与 "特征提炼器",专门对特征图做下采样,用 "抓大放小" 的思路压缩数据、提取关键信息,下面从核心逻辑、类型和价值展开介绍:
池化层会用一个固定大小的窗口(比如 2×2、3×3 ),像卷积核一样在特征图上滑动。不过它不做 "逐点相乘求和",而是对窗口覆盖的局部区域做聚合运算,把多个像素 "浓缩" 成 1 个值,让特征图尺寸变小,实现降维。
池化的类型:
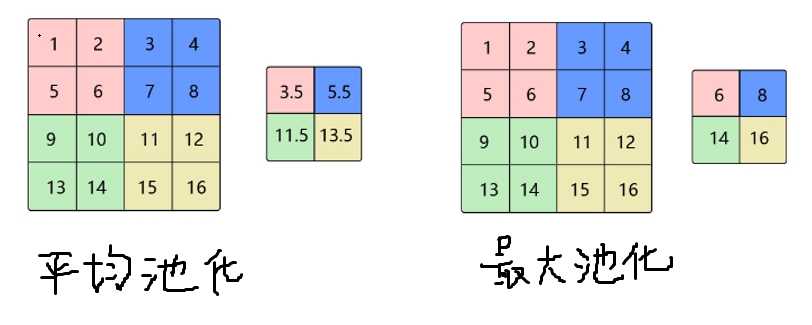
最大池化(Max Pooling)
- 操作:选窗口内的最大值作为输出。比如 2×2 窗口里有 1,2; 3,4,就输出 4 。
- 效果:只留最 "突出" 的特征(像图像边缘、纹理的强响应 ),过滤次要细节,让模型记住 "最关键的样子"。
平均池化(Average Pooling)
- 操作:算窗口内的平均值输出。同样 1,2; 3,4,输出 (1+2+3+4)/4 = 2.5 。
- 效果:让特征更 "平滑",能过滤小噪声(比如医学影像里的细碎干扰 ),但会弱化尖锐特征。
全局池化(Global Pooling)
- 操作:把整张特征图压缩成一个值(全局最大 / 平均 ),常放在分类任务最后一层。比如 100×100 的特征图,直接缩成 1 个数。
- 效果:极大减少参数,强化全局特征(比如判断 "这是猫" 而不是局部毛 ),适合分类任务收尾。
全连接层
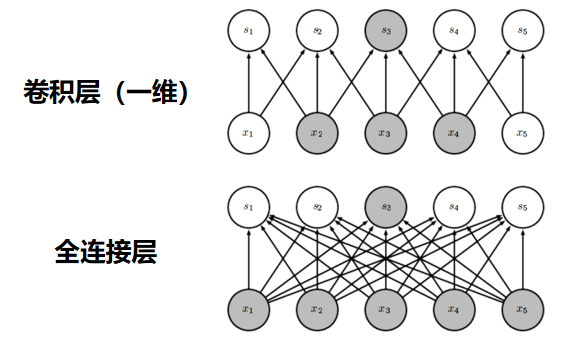
全连接层(Fully Connected Layer,简称 FC 层 )是神经网络里 "承上启下" 的关键结构,常作为 "决策大脑" 收尾,也能在中间层整合特征。全连接层里,前一层的每个神经元,都会和当前层的所有神经元相连 。比如前一层输出是 100 维向量,当前层要输出 10 维,那连接数就是 100×10=1000 条,每个连接都对应一个可学习的权重。
数学上,它的计算是矩阵乘法 + 偏置 + 激活函数:假设输入向量是 x(长度为 n ),权重矩阵是 W(形状 m×n ,m 是输出维度 ),偏置是 b(长度为 m ),激活函数是 f ,那么输出 y 就是:
全连接层的与全局输入关联的特性使得其通常用于整合和转换特征,以及在网络的末端进行最终的分类或回归预测。
更复杂的CNN:
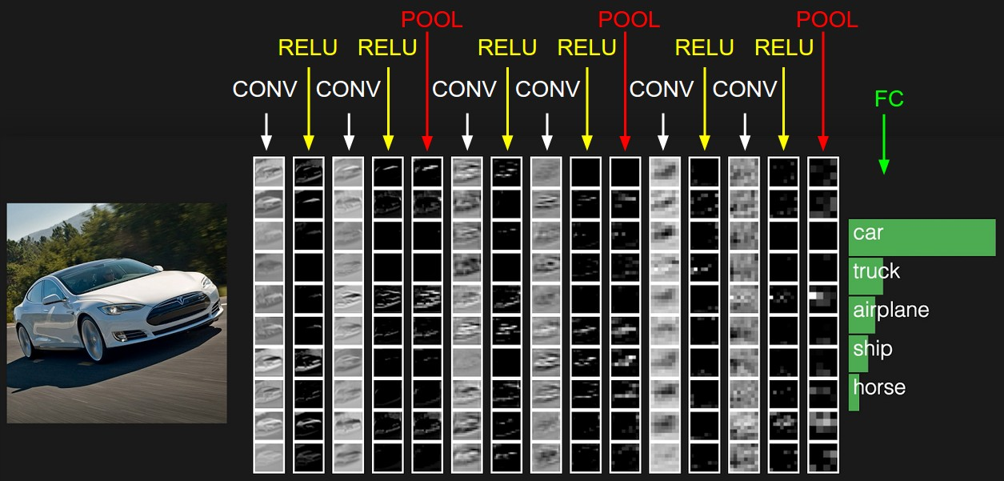
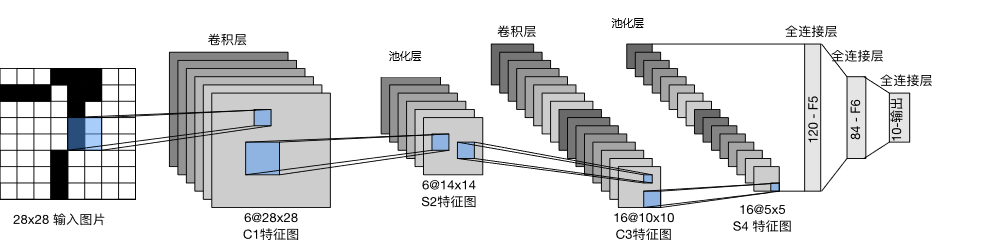
上述介绍的是简单的CNN。深度CNN通常由很多层组成,如图所示。核心是通过多轮 "卷积 + 激活 + 池化" 的重复堆叠,让网络从浅到深、从局部到全局地提取特征,最终用全连接层完成分类。。可以拆解为 "特征提取流水线"+"决策输出" 为什么要堆叠很多层?浅层学基础特征,深层学高阶语义。层数越多,网络能 "抽象" 出越复杂的模式
典型的CNN网络
AlexNet
AlexNet是具有里程碑意义的 CNN,在 2012 年 ImageNet 大规模视觉识别挑战赛(ILSVRC )中大放异彩 首次把 CNN 做到 8 层深度(5 卷积 + 3 全连接),突破浅层限制; 用 ReLU 激活、Dropout 正则化、数据增强解决 "难训练、易过拟合" 问题 借助 GPU 并行计算,让百万级图像训练从 "不可行" 变 "可行"
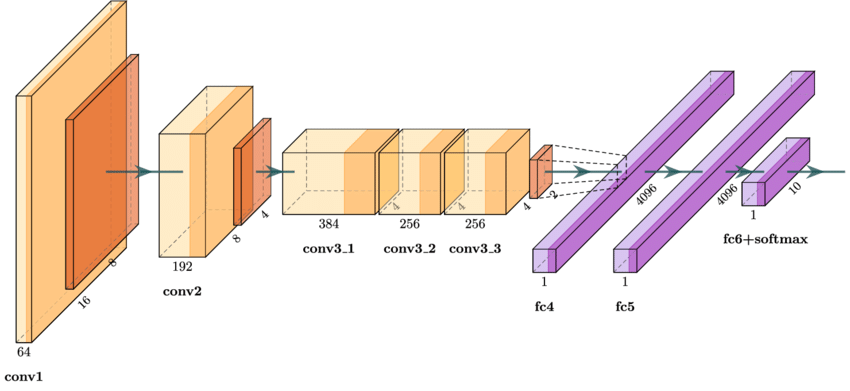
AlexNet
AlexNet使用了的池化技术,利用步长小于窗口的池化层保留更多的信息。 在特征图压缩后,后续的卷积层窗口尺度缩减为5×5和3×3。 为对抗过拟合,在前两个全连接层后加入了Dropout,增强了模型的泛化能力。 在网络最后的是3个全连接层,用于汇聚特征信息。
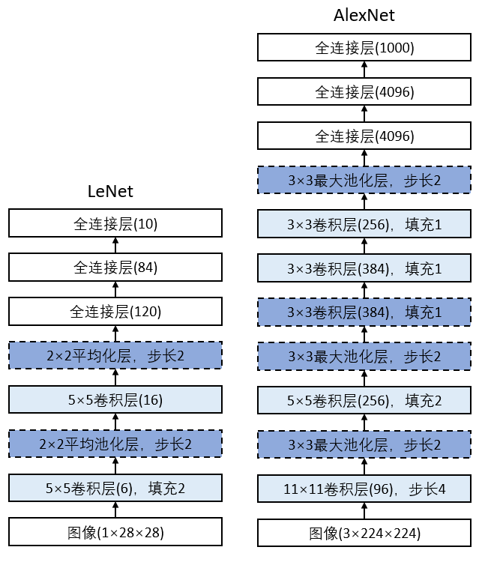
VGG
VGG由牛津大学的视觉几何组在 2014 年提出。VGG-16 因其结构的简洁性和一致性而著名 极简架构:仅用 3×3 卷积核和 2×2 池化层堆叠,通过增加层数(如 16 层的 VGG-16)提升性能,结构标准化易复现。 深度价值:首次验证网络深度与性能正相关迁移学习基石
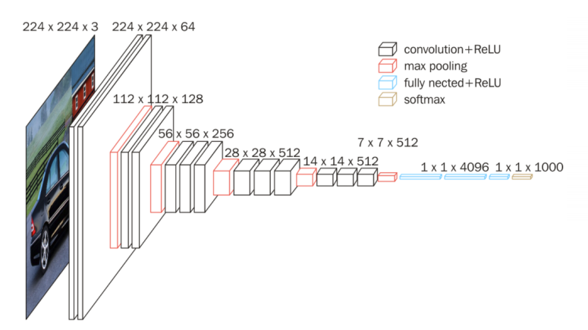
GoogLeNet
2014 年,GoogleNet 在 ImageNet 竞赛夺冠,核心是 Inception 模块 ,开启 CNN 从 "堆深度" 到 "多尺度融合" 的变革。
- Inception 模块:并行使用不同大小卷积和池化,同时捕获细节与全局特征,不同尺度信息互补,提升模型对复杂图像的表征能力。
- 1×1 卷积降维:通过 1×1 卷积压缩通道数,再进行大卷积操作,大幅减少参数量,提升计算效率。
- 轻量化架构:用全局平均池化替代全连接层,移除冗余参数;中间层设辅助分类器,稳定训练并缓解梯度消失
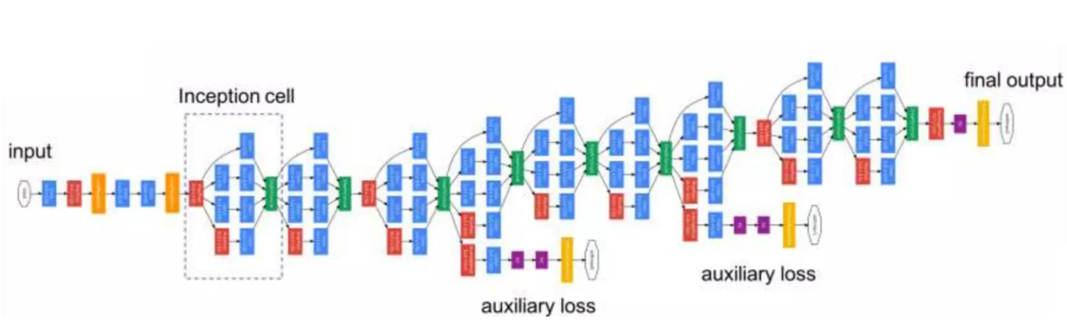
inception模块
将特征矩阵同时输入到多个分支进行处理,并将输出的特征矩阵按深度进行拼接,得到最终输出。解决因深度增加导致的参数爆炸和梯度消失问题
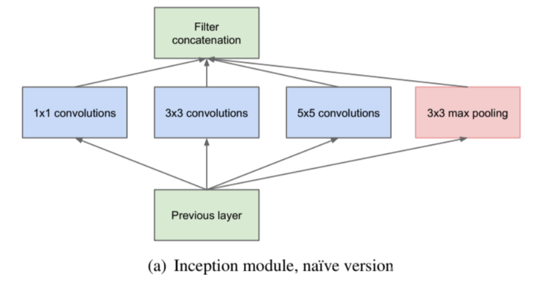
inception+降维
在原始 inception 结构的基础上,在分支 2,3,4 上加入了卷积核大小为 1x1 的卷积层。可以降维,减少模型训练参数,减少计算量。
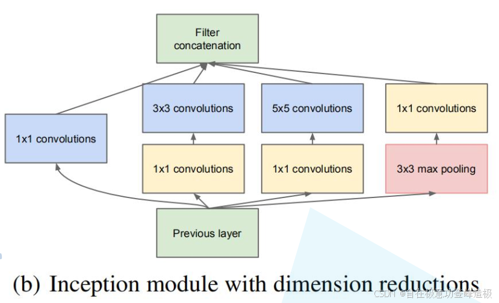
Resnet
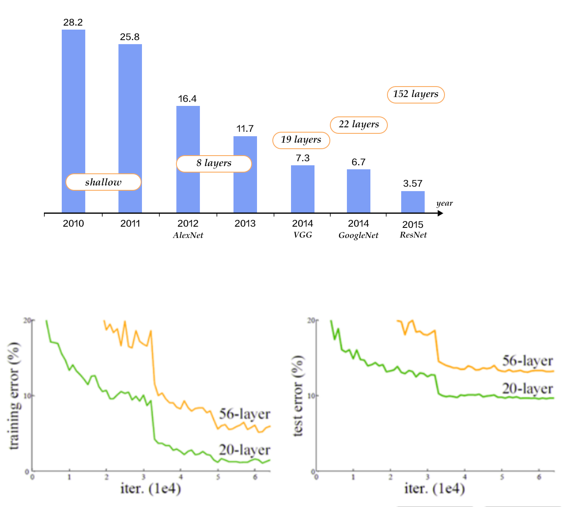
VGG等深度网络的成功让研究者认为,更深的模型可以取得更好的结果。(上图) 但是,随着网络深度的增加,模型精度并不总是提高的,网络加深后不仅测试误差变高了,它的训练误差也变高了,这种的现象称为退化问题。(下图) 左边是训练误差,右边是测试误差。可以看到,黄色(56层)错误率一直比20层高。深层网络不仅难训练,还因拟合能力下降,导致测试性能更差。这就是退化的体现
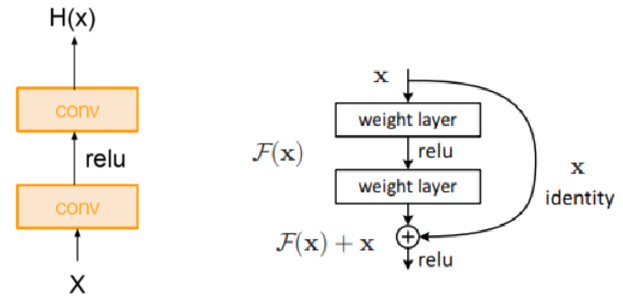
2015 年由何恺明团队提出,解决传统 CNN 因深度增加导致的梯度消失 / 爆炸和性能退化问题。
- 提出残差连接,通过 "恒等映射 + 残差学习" 解决深层网络因梯度消失导致的性能退化问题
- 定义深层网络设计标准,其 "短路连接" 思想被广泛复用
- 凭借 ImageNet 超高性能,推动深度学习进入 "深度竞赛" 时代,;高效的特征提取能力广泛应用于自动驾驶、医学影像等场景,至今仍是工业界最常用的基础模型之一。
残差块
传统网络直接学习输入 x 到输出 H(x) 的完整映射,当网络过深时,梯度反向传播易衰减(梯度消失),导致模型难优化、性能退化。残差块引入恒等映射,让输出为 H(x)=F(x)+x,其中 F(x) 是残差映射。反向传播时,捷径使梯度稳定传递,且学习残差比直接学完整映射更简单,保障深层网络可训,解决退化问题。
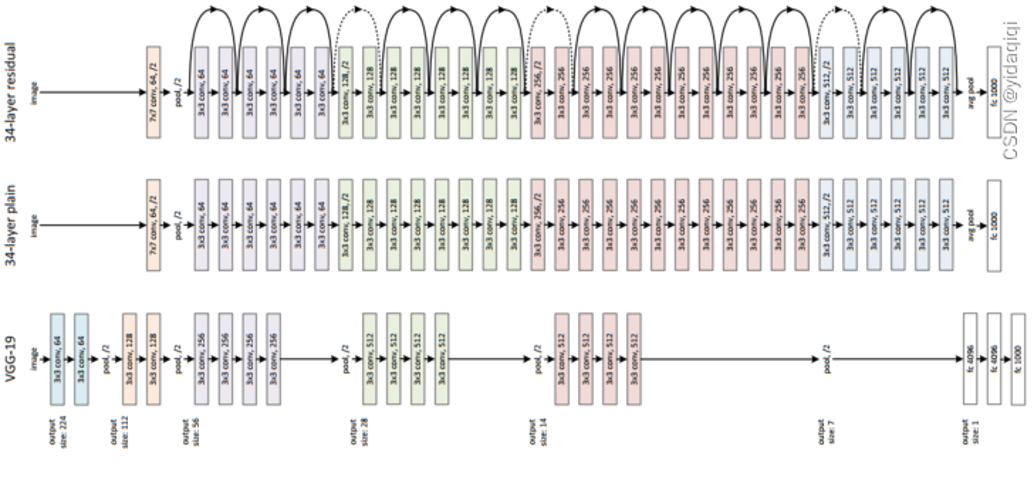
ResNet与传统网络、VGG - 19 的结构对比