论文标题:RMT: Retentive Networks Meet Vision Transformers
论文原文 (Paper) :https://arxiv.org/abs/2309.11523
代码 (code) :https://github.com/qhfan/RMT
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
-
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
-
- [2.1 文本背景总结](#2.1 文本背景总结)
- [2.2 动机图解分析](#2.2 动机图解分析)
- [3. 主要创新点](#3. 主要创新点)
- [4. 方法细节](#4. 方法细节)
-
- [4.1 整体网络架构](#4.1 整体网络架构)
- [4.2 核心创新模块详解:MaSA (Manhattan Self-Attention)](#4.2 核心创新模块详解:MaSA (Manhattan Self-Attention))
- [4.3 理念与机制总结](#4.3 理念与机制总结)
- [4.4 图解总结](#4.4 图解总结)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验部分简单分析](#6. 实验部分简单分析)
- [7. 获取即插即用代码关注 【AI即插即用】](#7. 获取即插即用代码关注 【AI即插即用】)
-
1. 核心思想
本文提出了一种名为 RMT (Retentive Mask Transformer) 的通用视觉骨干网络。它旨在解决标准 Vision Transformer (ViT) 计算复杂度呈二次方增长( O ( N 2 ) O(N^2) O(N2))以及缺乏显式空间先验的问题。核心思想是将 NLP 领域高效的 Retentive Network (RetNet) 引入视觉,并针对图像的二维特性,设计了基于 曼哈顿距离(Manhattan Distance) 的显式空间衰减机制。这使得 RMT 既拥有 Transformer 的全局建模能力,又具备 CNN 的平移不变性,同时保持了线性( O ( N ) O(N) O(N))的计算复杂度。
2. 背景与动机
2.1 文本背景总结
在视觉领域,CNN 凭借其强大的归纳偏置(如局部性和平移不变性)长期占据主导,但难以捕捉长程依赖。ViT 虽然解决了长程依赖问题,但其自注意力机制(Self-Attention)带来了沉重的计算负担,且缺乏对图像空间结构的固有感知。
最近,NLP 领域的 RetNet 提出了一种"既能像 Transformer 一样并行训练,又能像 RNN 一样推理"的机制。然而,直接将 RetNet 用于视觉存在两个问题:
- 因果限制:RetNet 是为文本生成的单向(因果)逻辑设计的,而图像理解需要双向(全向)上下文。
- 一维衰减:RetNet 的指数衰减是基于 1D 序列距离的,不适配 2D 图像的空间结构。
2.2 动机图解分析
看图说话与痛点分析:
- 左图 (ViT/Self-Attention) :注意力矩阵是密集的(Dense),每个像素都与所有其他像素交互。虽然全局性好,但没有距离概念,且计算量巨大(红色全连接线),导致了效率瓶颈。
- 中图 (Original RetNet) :虽然引入了衰减,但它是基于 1D 序列的(Causal Decay),且具有因果遮蔽(只能看过去,不能看未来)。这对于图像来说,破坏了空间的连续性,导致了 "语义鸿沟"(例如,上方像素无法感知下方像素)。
- 右图 (RMT - 本文方法) :RMT 打破了因果限制,并引入了基于 曼哈顿距离 的 2D 空间衰减。你可以看到,中心像素与周围像素的交互强度随着距离增加而衰减(颜色由深变浅),模拟了 CNN 的局部感知,同时保留了全局连接的可能性。
3. 主要创新点
- 基于曼哈顿距离的 2D 空间先验:将 RetNet 的一维指数衰减扩展到二维图像空间,利用曼哈顿距离构建显式的空间衰减矩阵,完美契合图像的网格结构。
- 高效的注意力分解机制 :为了避免计算巨大的 N × N N \times N N×N 衰减矩阵,作者巧妙地将 2D 衰减分解为两个正交的 1D 衰减(水平和垂直方向),使得计算复杂度降低至线性 O ( N ) O(N) O(N)。
- 动态衰减率 (Dynamic Decay):不同于 RetNet 的固定衰减,RMT 引入了与输入内容相关的动态衰减率,使其能够根据图像内容自适应地调整感受野大小。
- 全能的视觉骨干:RMT 在图像分类、目标检测和语义分割等多个下游任务上均取得了优异的性能,证明了该架构的通用性。
4. 方法细节
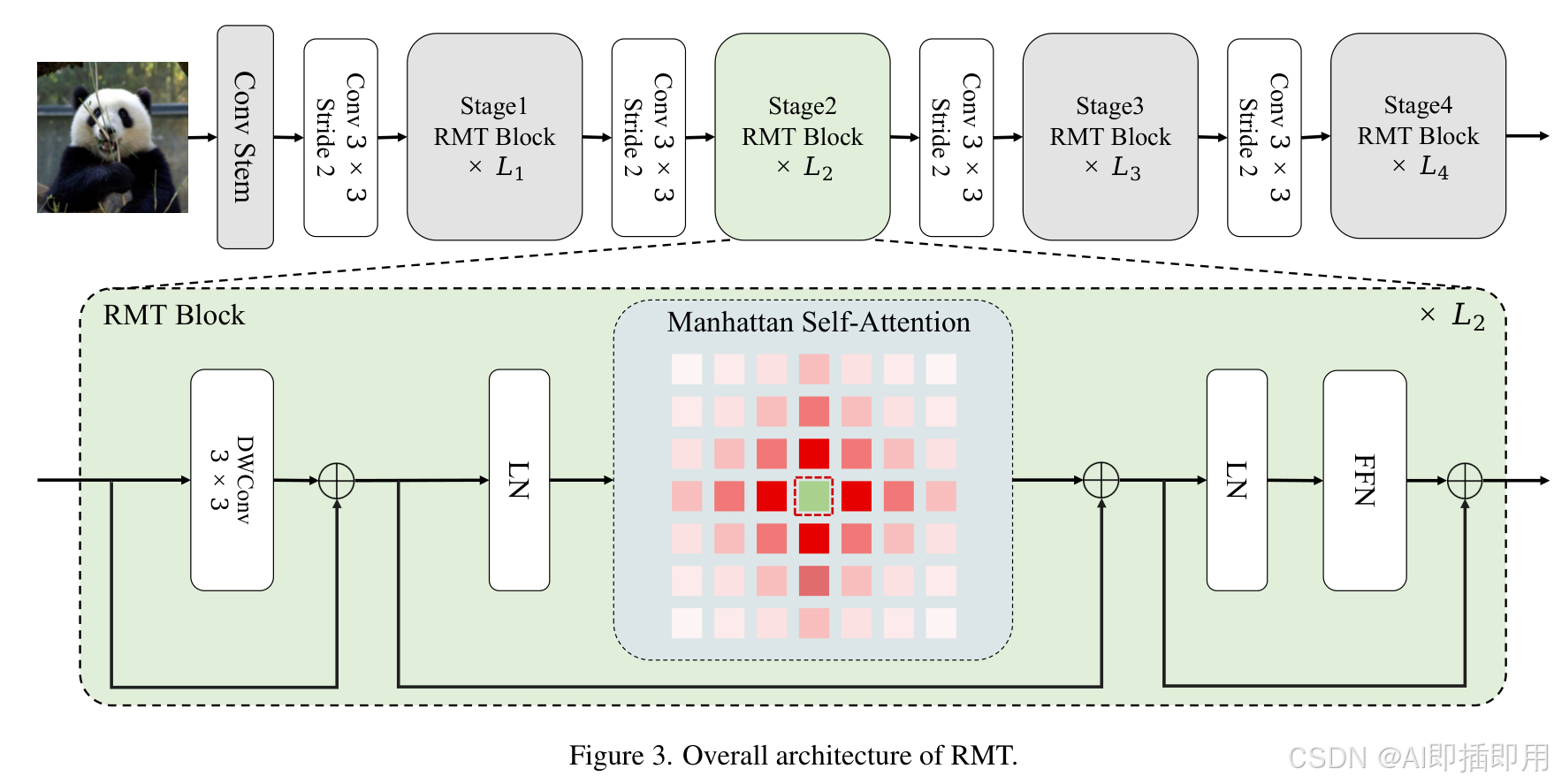
4.1 整体网络架构

数据流详解 :
RMT 采用了类似 ResNet/Swin Transformer 的 分层(Hierarchical)架构,包含 4 个阶段(Stage):
- 输入 (Input) :原始图像 H × W × 3 H \times W \times 3 H×W×3。
- Patch Embedding:通过卷积层将图像切块并映射为 Token,此时分辨率降低(如 1/4),通道数增加。
- RMT Block 堆叠 :
- 在每个 Stage 中,堆叠多个 RMT Block。
- 每个 Block 包含两个核心子层:Retentive Self-Attention (MaSA) 和 Feed-Forward Network (FFN)(通常包含 LKA 或其他局部增强模块)。
- 数据流在 Block 之间通过残差连接(Residual Connection)和层归一化(LayerNorm)传递。
- 下采样 (Downsampling):在 Stage 之间,通过 Patch Merging 或步长卷积降低分辨率(H, W 减半),通道数(C)翻倍。
- 输出 (Output):最终输出用于分类的全局特征或用于检测/分割的多尺度特征图。
4.2 核心创新模块详解:MaSA (Manhattan Self-Attention)
模块 A:显式空间先验的引入
- 传统 SA : A t t e n t i o n ( Q , K , V ) = Softmax ( Q K T ) V Attention(Q, K, V) = \text{Softmax}(QK^T)V Attention(Q,K,V)=Softmax(QKT)V。
- RMT 的做法 :引入衰减矩阵 D D D。公式变为类似 A t t e n t i o n = ( Q K T ⊙ D ) V Attention = (QK^T \odot D)V Attention=(QKT⊙D)V(简化版)。
- 核心设计 : D i j D_{ij} Dij 的值取决于 token i i i 和 j j j 在图像上的 曼哈顿距离 ∣ x i − x j ∣ + ∣ y i − y j ∣ |x_i - x_j| + |y_i - y_j| ∣xi−xj∣+∣yi−yj∣。这种设计使得距离近的 Token 交互更强,距离远的交互更弱,天然赋予了模型局部性。
模块 B:轴向分解与高效计算
直接计算 D D D 并进行点乘依然是 O ( N 2 ) O(N^2) O(N2)。作者利用指数函数的性质 e − ( a + b ) = e − a ⋅ e − b e^{-(a+b)} = e^{-a} \cdot e^{-b} e−(a+b)=e−a⋅e−b,将 2D 曼哈顿衰减分解为:
D 2 D = D h e i g h t ⊙ D w i d t h D_{2D} = D_{height} \odot D_{width} D2D=Dheight⊙Dwidth
- 流动机制 :
- 垂直扫描:先沿着高度方向应用 1D RetNet 机制(利用 RNN 式的递归或分块计算),捕捉垂直方向的衰减关系。
- 水平扫描:再沿着宽度方向应用同样的机制。
- 融合 :通过这种正交分解,模型只需进行两次 O ( N ) O(N) O(N) 的扫描,就等效地完成了全图的 2D 空间衰减建模。这不仅保留了全局信息,还极大地节省了显存。
4.3 理念与机制总结
RMT 的核心理念是 "受限的全局性 (Constrained Globality)"。
- 机制:它不完全抛弃 Transformer 的长程连接,而是给它加上一个"衰减器"。
- 公式解读 : O u t = Retention ( X ) Out = \text{Retention}(X) Out=Retention(X)。在这个过程中,权重不再仅仅由内容相似度( Q ⋅ K Q \cdot K Q⋅K)决定,而是由 内容相似度 和 几何距离 共同决定。
- 这种机制让 RMT 在浅层像 CNN 一样关注纹理边缘(强局部性),在深层又能像 ViT 一样捕捉语义关联(长程依赖),实现了两者的完美平衡。
4.4 图解总结
回到 动机图解 (Figure 1) :RMT 通过 MaSA 模块,成功地在右图中画出了那个基于曼哈顿距离的辐射状热力图。分解机制(Figure 3)则是实现这一效果的"加速器",确保了在生成这张热力图时,计算成本不会随着图像分辨率爆炸,从而解决了 Efficiency Bottleneck。
5. 即插即用模块的作用
RMT 中的核心组件具有很高的通用性,可以作为即插即用模块改进现有的 ViT:
- MaSA (Manhattan Self-Attention) 模块 :
- 适用场景:任何需要处理高分辨率图像的 Transformer 架构(如分割、检测任务的 Backbone)。
- 应用:可以替换 Swin Transformer 中的 Window Attention,从而移除"窗口"的硬性限制,实现真·全局且线性的交互。
- 显式空间先验策略 :
- 应用:在轻量级模型设计中,如果发现纯 ViT 难以收敛或数据量不足,可以引入这种基于距离的衰减矩阵作为一种正则化手段(Inductive Bias),帮助模型更快学到物体结构。
6. 实验部分简单分析
论文在 ImageNet-1K、COCO 和 ADE20K 上进行了全面验证。
-
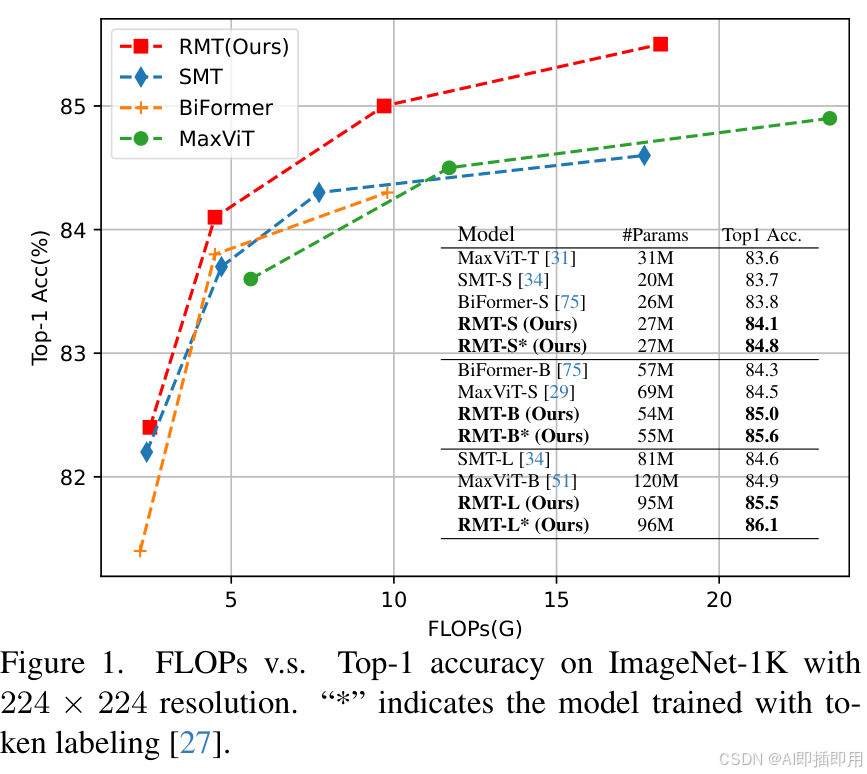
ImageNet 分类:
- 结果 :RMT-S (Small) 达到了 84.x% 的 Top-1 准确率,在相同参数量和 FLOPs 下,优于 Swin Transformer 和 ConvNeXt。
- 分析:这证明了显式空间先验对于特征提取的有效性,尤其是在中等规模数据上。
-
COCO 目标检测:
- 结果:作为 Mask R-CNN 的 Backbone,RMT 相比 Swin 带来了显著的 AP 提升(+1.0 AP 以上)。
- 原因:检测任务对空间位置非常敏感。RMT 的曼哈顿距离机制天然保留了精确的位置信息,而标准 ViT 的位置编码(Positional Encoding)往往在深层会模糊掉。
-
效率分析:
- 分析:随着图像分辨率的增加(从 224 到 1024),RMT 的推理延迟增长远慢于标准 ViT,体现了线性复杂度的巨大优势。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。