论文标题:PMFSNet: Polarized Multi-scale Feature Self-attention Network For Lightweight Medical Image Segmentation
论文原文 (Paper) :https://arxiv.org/abs/2401.07579
代码 (code) :https://github.com/yykzjh/PMFSNet
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
-
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
-
- [2.1 文本背景总结](#2.1 文本背景总结)
- [2.2 动机图解分析](#2.2 动机图解分析)
- [3. 主要创新点**加粗样式**](#3. 主要创新点加粗样式)
- [4. 方法细节](#4. 方法细节)
-
- [4.1 整体网络架构](#4.1 整体网络架构)
- [4.2 核心创新模块详解:PMFS Block](#4.2 核心创新模块详解:PMFS Block)
- [4.3 理念与机制总结](#4.3 理念与机制总结)
- [4.4 图解总结](#4.4 图解总结)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验部分简单分析](#6. 实验部分简单分析)
- [7. 获取即插即用代码关注 【AI即插即用】](#7. 获取即插即用代码关注 【AI即插即用】)
-
1. 核心思想
本文提出了一种名为 PMFSNet 的轻量级医学图像分割网络,旨在解决现有 Transformer 模型计算量大、易在小样本医疗数据上过拟合的问题。其核心创新在于设计了 PMFS 模块(Polarized Multi-scale Feature Self-attention),该模块通过"极化"的方式将通道注意力和空间注意力解耦以降低计算复杂度,并结合多尺度深度卷积来增强局部特征提取能力。最终,PMFSNet 以极低的参数量(<1M)在 Tooth、MMOTU 和 ISIC 2018 等数据集上实现了 SOTA 性能。
2. 背景与动机
2.1 文本背景总结
医学图像分割的现状面临两难境地:
- 现有 SOTA 的代价:目前主流的方法(如 Transformer-based 模型)为了追求高精度(Accuracy),往往伴随着巨大的参数量和计算需求。
- 落地难:由于医疗数据集通常较小(Small scale),大型模型容易出现过拟合(Overfitting)。此外,在边缘设备(Edge devices)上部署这些庞大的模型不仅推理慢,而且集成难度大,导致了大量的冗余计算(Redundant computation)。
因此,本文的动机是:如何设计一个既能保持 Transformer 长程依赖优势,又能像 CNN 一样轻量且不易过拟合的网络?
2.2 动机图解分析
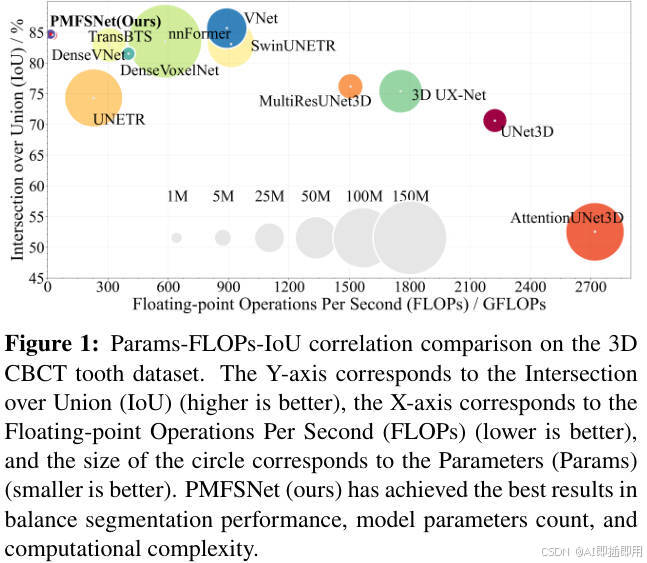
看图说话与痛点分析:
- 局限性对比 :
- 传统的 U-Net 虽然轻量,但受限于卷积核的局部感受野,难以捕捉器官的全局形状信息(语义鸿沟)。
- Swin-Unet 等 Transformer 变体虽然解决了全局信息问题,但其计算复杂度随图像分辨率呈二次方增长( O ( N 2 ) O(N^2) O(N2)),导致效率瓶颈。
- 本文的解决思路 :
- 从架构图中可以看出,PMFSNet 依然沿用了经典的 U-Shape 结构(Encoder-Decoder),这是为了保留多尺度的上下文信息。
- 关键突破 :Encoder 和 Decoder 中的核心组件被替换为 PMFS Block。这个模块的设计初衷就是为了在不增加计算负担的前提下,"同时"抓取全局依赖(通过极化注意力)和局部细节(通过多尺度卷积),从而在图中展示的每一层级上都实现高效的特征编码。
3. 主要创新点加粗样式
- 极化自注意力机制 (Polarized Self-attention):提出了一种线性复杂度的注意力机制,通过在通道和空间维度上分别进行"极化"处理,避免了庞大的矩阵乘法,显著降低了显存占用。
- 多尺度特征融合 (Multi-scale Feature Fusion):在注意力分支之外,集成了多尺度的深度可分离卷积,能够自适应地捕捉不同大小的病灶特征,解决了单一尺度卷积感受野受限的问题。
- 极致轻量化 (Lightweight Design):通过精心设计的 Bottleneck 结构和通道缩减策略,将模型参数量控制在 1M 以下(例如在 3D Tooth 数据集上仅 0.54M-0.76M 参数),同时保持了高性能。
4. 方法细节
4.1 整体网络架构
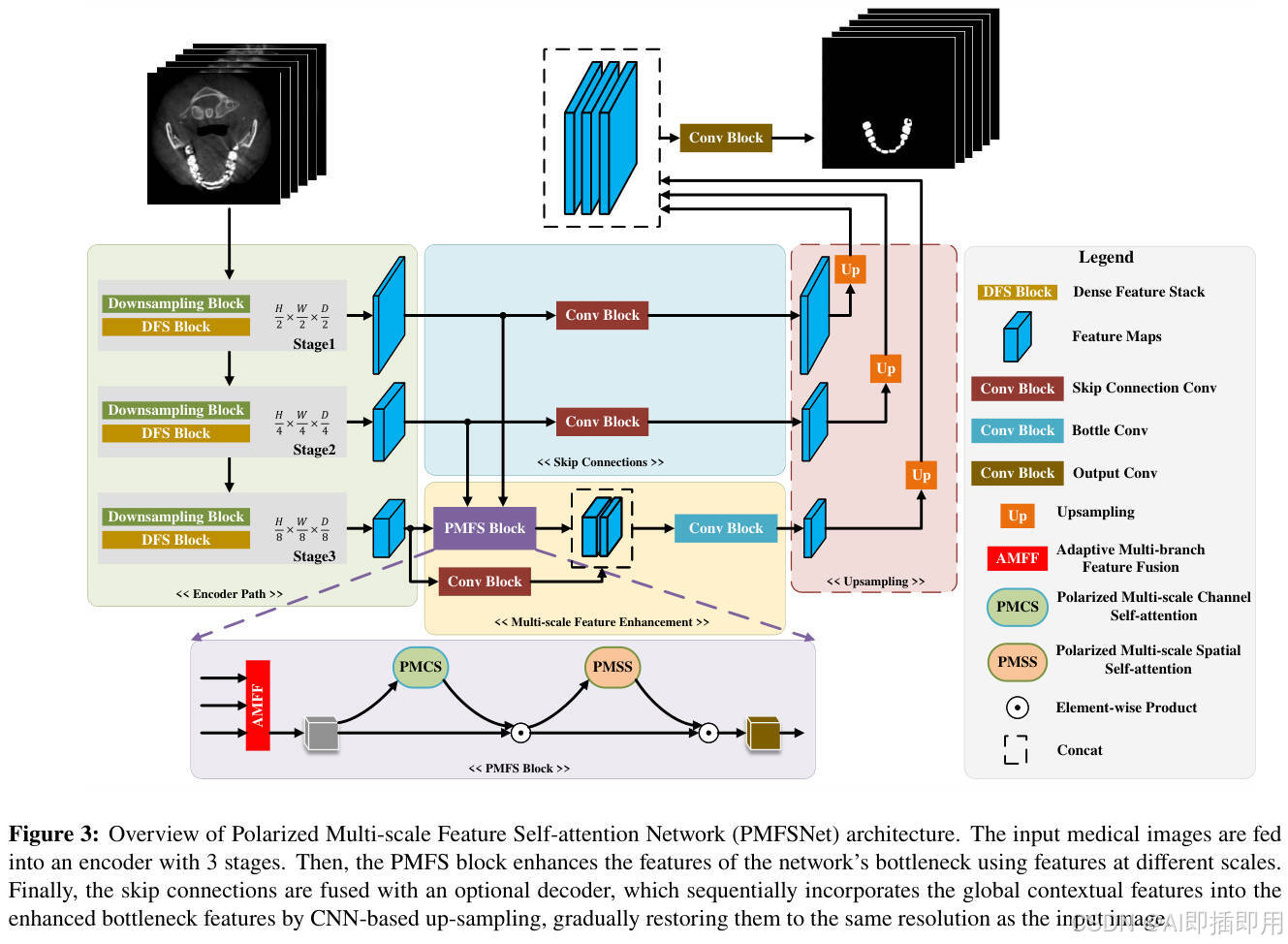
数据流详解 :
PMFSNet 采用标准的 Encoder-Decoder(U型) 架构:
- 输入 (Input):医学图像切片(2D)或体数据(3D)。
- 编码器 (Encoder) :包含 4 个阶段。每个阶段首先通过下采样层降低分辨率,然后通过堆叠的 PMFS Blocks 进行特征提取。这里,特征通道数逐渐增加(如 32 -> 64 -> ...),空间分辨率逐渐降低。
- 瓶颈层 (Bottleneck):在网络的最深处,使用 PMFS Block 捕捉最高层级的抽象语义信息。
- 解码器 (Decoder) :通过上采样层逐步恢复分辨率,并与编码器对应的特征图进行 跳跃连接 (Skip Connection) 融合,以找回丢失的空间细节。
- 输出 (Output) :经过 1 × 1 1 \times 1 1×1 卷积生成分割掩码。
4.2 核心创新模块详解:PMFS Block
这是一个双分支并行的结构,旨在结合 CNN 和 Transformer 的优势。
-
分支 A:极化注意力分支 (Polarized Attention Branch)
- 结构拆解 :输入特征经过 1 × 1 1 \times 1 1×1 卷积降维后,分为两条路径。
- 通道极化:利用 Global Average Pooling 压缩空间维度,计算通道间的依赖关系(类似 SE-Block 但更高效)。
- 空间极化 :利用 1 × 1 1 \times 1 1×1 卷积压缩通道维度,计算空间位置的依赖关系。
- 流动机制:两者通过 Sigmoid 或 Softmax 激活后,以广播(Broadcast)的方式与原始特征相乘。
- 设计目的 :模拟 Transformer 的全局感受野,捕捉长程依赖(如器官的整体轮廓),但将计算复杂度从 O ( N 2 ) O(N^2) O(N2) 降低到线性 O ( N ) O(N) O(N)。
- 结构拆解 :输入特征经过 1 × 1 1 \times 1 1×1 卷积降维后,分为两条路径。
-
分支 B:多尺度卷积分支 (Multi-scale Conv Branch)
- 结构拆解 :使用不同核大小的 深度可分离卷积 (Depth-wise Conv) (例如 3 × 3 3 \times 3 3×3, 5 × 5 5 \times 5 5×5)。
- 设计目的:医学图像中的病灶大小不一(如微小的息肉 vs 大面积的病变)。多尺度卷积提供了不同的感受野,强化了网络对局部纹理和边缘的捕捉能力。
4.3 理念与机制总结
PMFSNet 的核心理念是 "解耦与互补"。
- 解耦:将复杂的 Self-Attention 解耦为正交的 Channel Attention 和 Spatial Attention,大幅削减计算量。
- 互补 :利用 CNN 的归纳偏置(Inductive Bias)来提取局部特征,利用 Attention 机制来提取全局特征。
其数学表达可以抽象为:
Y = PolarizedAttention ( X ) ⊕ MultiScaleConv ( X ) Y = \text{PolarizedAttention}(X) \oplus \text{MultiScaleConv}(X) Y=PolarizedAttention(X)⊕MultiScaleConv(X)
其中 ⊕ \oplus ⊕ 代表特征融合。这种机制确保了网络在极低的参数量下,依然拥有"全景视野"和"显微视野"。
4.4 图解总结
回到动机图解中的核心问题:
- PMFS Block 中的 多尺度卷积 解决了 U-Net 感受野单一的问题。
- 极化注意力 解决了 Transformer 计算冗余的问题。
- 两者结合,使得 PMFSNet 在处理小样本医学数据时,既能快速收敛(不易过拟合),又能精准分割。
5. 即插即用模块的作用
本论文提出的 PMFS Block 是一个高度封装的单元,具有极强的通用性。
适用场景与应用:
- 作为 Backbone 的构建块:可以直接替换 ResNet 中的 Residual Block 或 MobileNet 中的 Inverted Residual Block,用于分类、检测或分割任务。
- 轻量化改造:对于需要部署在移动端(如皮肤癌检测 APP、便携式超声仪)的模型,可以用 PMFS Block 替换原本笨重的 Self-Attention 模块,显著降低 FLOPs。
- 多模态融合:在处理 CT 和 MRI 多模态数据时,PMFS Block 可以作为特征融合层,利用其极化注意力机制筛选不同模态的有效信息。
6. 实验部分简单分析
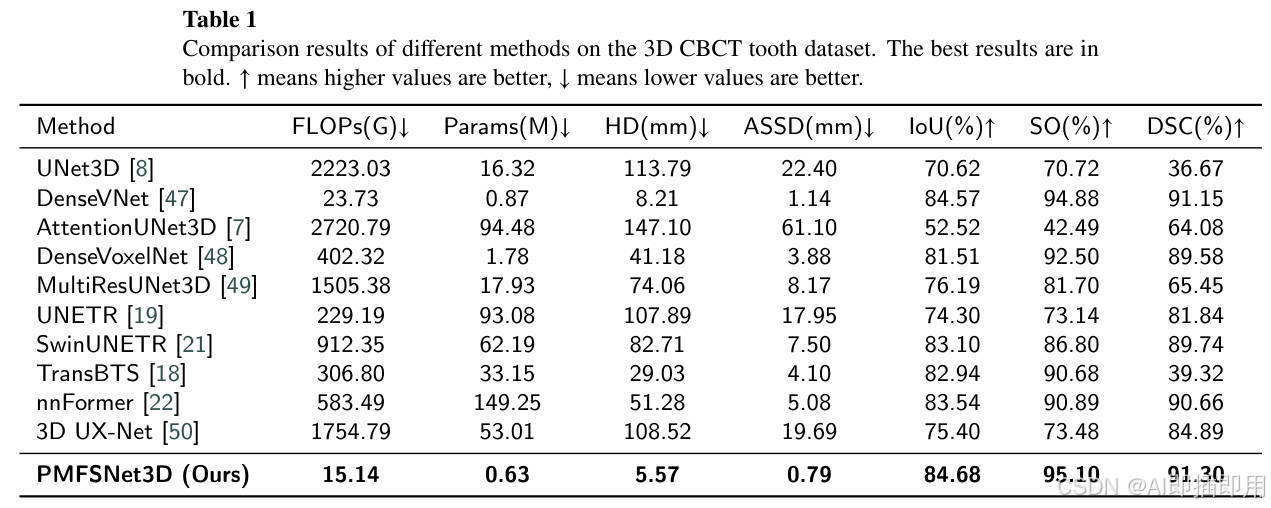
论文在多个数据集上进行了详尽的验证,包括 Tooth (3D) , MMOTU (2D) , 和 ISIC 2018 (2D)。
-
参数量对比 (Parameters):
- PMFSNet 的参数量在不同通道配置下(32, 48, 64)仅为 0.54M - 0.99M。这远低于常规的 U-Net 或 Swin-Unet(通常在 10M-50M 级别)。
-
性能对比 (Performance):
- 在 Tooth 数据集上,IoU 达到了 84.68% ;在 MMOTU 上达到了 82.02%。
- 关键发现:即便参数量极低,其精度依然优于或持平于许多重型网络。这证明了 PMFS 模块在特征表达上的高效性。
-
消融分析:
- 实验表明,内部通道数(Internal Channels)对参数量影响不大(0.54M vs 0.76M),但性能相当稳定。这说明网络不存在明显的参数冗余,主要增益来自于结构设计而非单纯堆叠通道。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
- 实验表明,内部通道数(Internal Channels)对参数量影响不大(0.54M vs 0.76M),但性能相当稳定。这说明网络不存在明显的参数冗余,主要增益来自于结构设计而非单纯堆叠通道。