
demo: https://chat.qwen.ai
模型: https://huggingface.co/Qwen 或 https://modelscope.cn/organization/qwen
github: https://github.com/QwenLM/Qwen3-VL
论文地址:https://arxiv.org/pdf/2511.21631
Qwen3-VL 是Qwen系列中能力最强的视觉-语言模型 ,在多模态基准测试中表现优异。该模型原生支持高达256K个标记的交错上下文 ,无缝整合文本、图像和视频。模型家族包含两类:稠密模型 (2B/4B/8B/32B)和专家混合模型(30B-A3B/235B-A22B),以适应不同延迟-质量权衡。
Qwen3-VL交付三大核心支柱:
(i) 显著更强的纯文本理解能力 ,在某些场景超越同类纯文本骨干模型;
(ii) 强大的长上下文理解能力 ,原生支持256K标记窗口,适用于文本和交错多模态输入,能忠实保留、检索及跨长文档/视频交叉引用;
(iii) 先进的多模态推理能力 ,在单图像、多图像和视频任务上,于MMLU、Math-Vista和MathVision等基准测试中展现出领先的性能。
架构层面引入三项关键升级:
(i) 增强的交错-MRoPE ,提升图像和视频的时空建模;
(ii) DeepStack集成 ,利用多级ViT特征强化视觉-语言对齐;
(iii) 基于文本的时间对齐,从T-RoPE演进到显式文本时间戳对齐,实现更精确时间定位。
为平衡纯文本和多模态学习目标,应用平方根重加权 ,在不损害文本能力下提升多模态性能。预训练扩展至256K标记上下文长度,后训练分为非思考 和思考 两种变体,并分配额外计算资源以提升性能。在相同标记预算和延迟约束下,Qwen3-VL在稠密模型和专家混合(MoE)架构中均取得优异的性能 。
1 Introduction
视觉-语言模型(VLMs)已从基础视觉感知发展到高级多模态推理(如图像、视频理解)。关键要求是不削弱底层大语言模型(LLM)的语言能力,多模态模型需在语言基准测试中匹配或超越纯文本模型。
本报告介绍Qwen3-VL及其进展。基于Qwen3系列,我们实例化了:
- 四个稠密模型 (2B/4B/8B/32B)
- 两个混合专家(MoE)模型 (30B-A3B / 235B-A22B )
所有模型均使用最多256K标记的上下文窗口 训练,实现长上下文理解。通过优化训练语料库和策略,保留了底层LLM的语言能力 ,并显著提升整体性能。我们发布非思考和思考两种变体 ;思考变体 在复杂推理任务上取得显著更强的多模态推理能力。
1.1 架构改进
- 交错式MRoPE位置编码 :解决Qwen2.5-VL中嵌入维度拆分(时间t、水平h、垂直v)导致的频率谱不平衡 问题,使t/h/v在高低频段均匀分布,生成更准确的位置表示。
- DeepStack跨层融合机制 :通过轻量级残差连接 ,将视觉编码器各层标记路由至对应LLM层,增强多级视觉-语言对齐,无需增加上下文长度。
- 显式视频时间戳 :替换基于位置编码的绝对时间对齐,提供更简洁直接的时间表示 。
此外,采用平方根归一化的每标记损失,优化训练中文本与多模态数据的贡献平衡。
1.2 数据与训练优化
- 数据优化 :增强标题监督、扩展OCR覆盖、结合3D空间推理的标准化定位 ,并新增代码/长文档/时间对齐视频语料库;融入思维链推理 和高质量GUI-代理交互数据 ,实现更强的多模态理解与精确定位。
- 训练流程 :
- 预训练 :暖启动对齐(仅更新视觉-语言投影层)→ 全参数训练(上下文窗口逐步增大至8K/32K/256K序列长度)。
- 后训练 :(i) 基于长思维链的监督微调 ,(ii) 教师模型知识蒸馏 ,(iii) 强化学习。
上述创新使Qwen3-VL成为稳健的视觉-语言基础模型 和多模态智能灵活平台,无缝整合感知、推理与行动。后续章节将展示架构、训练框架及基准测试评估。
2 模型架构
Qwen3-VL采用三模块架构,包括视觉编码器 、基于MLP的视觉-语言融合器 以及大型语言模型(LLM) ,参考Qwen2.5-VL(Bai et al., 2025)。图1展示了详细模型结构。
大型语言模型 :Qwen3-VL以稠密变体(Qwen3-VL-2B/4B/8B/32B)和混合专家(MoE)变体(Qwen3-VL-30B-A3B, Qwen3-VL-235B-A22B)实现,均基于Qwen3骨干网络。旗舰模型Qwen3-VL-235B-A22B拥有 235B 总参数量,其中22B为激活参数。
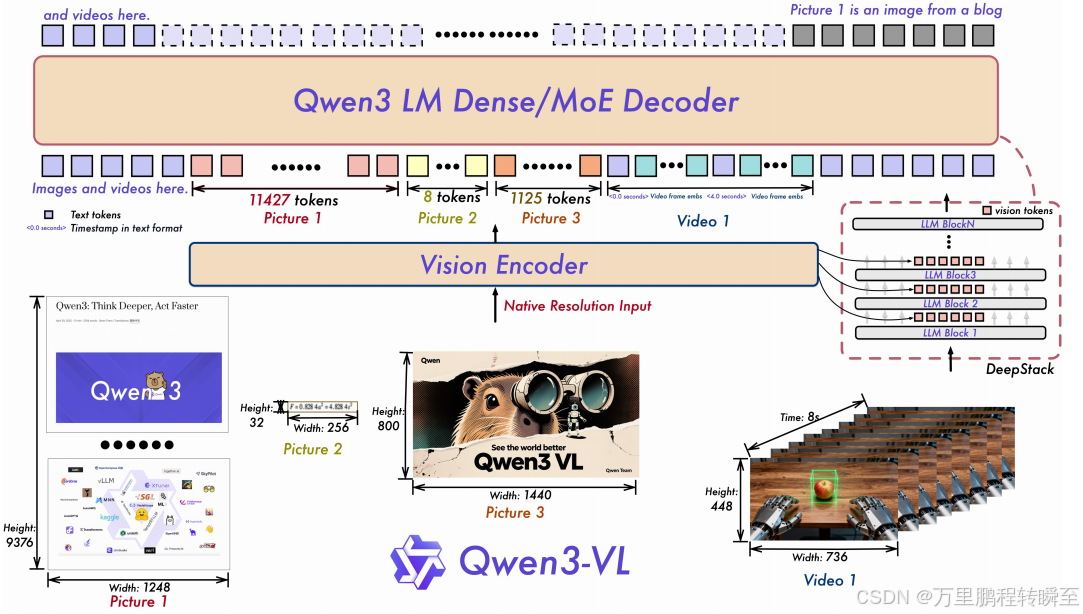
图1:Qwen3-VL框架整合视觉编码器和语言模型解码器,处理多模态输入(文本、图像、视频)。视觉编码器处理动态原生分辨率输入,映射为可变长度视觉标记。引入 DeepStack机制 将视觉编码器多层标记注入LLM对应层,增强感知能力;采用交错式MROPE 对多模态输入编码位置信息,确保频率谱平衡;引入基于文本的时间戳标记优化视频序列时间结构捕捉。
视觉编码器 :采用SigLIP-2架构(Tschannen et al., 2025),使用动态输入分辨率训练,初始化自官方预训练检查点。适配动态分辨率时,应用2D-RoPE 并插值绝对位置嵌入(遵循CoMP方法,Chen et al., 2025)。默认使用SigLIP2-SO-400M变体,小型LLM(2B/4B)采用SigLIP2-Large(300M)。
基于MLP的视觉-语言融合器:使用两层MLP将视觉编码器的2×2特征压缩为单个视觉标记,对齐LLM隐藏维度;部署专用融合器支持DeepStack机制(细节见2.2节)。
2.1 交错式MROPE
Qwen2-VL(Wang et al., 2024c)的MROPE将嵌入维度划分为时间(t)、水平(h)、垂直(w)子空间,但频率谱不平衡导致长视频理解性能下降。改进方案通过交错嵌入维度中的t、h、w组件(Huang et al., 2025)实现均匀频率分配,消除频谱偏差,显著提升视频长距离位置建模能力。
2.2 DeepStack
扩展DeepStack方法(Meng et al., 2024),将视觉标记注入LLM多层级。区别于原始堆叠多尺度标记的方式,本设计从视觉Transformer(ViT)中间层提取视觉标记,保留低级到高级的丰富视觉信息。
2.3 Video Timestamp
针对Qwen2.5-VL中时间同步MRoPE的局限性:(1) 绝对时间绑定导致长视频位置ID庞大稀疏,削弱长时序理解;(2) 需多帧率均匀采样,增加训练成本。改用基于文本的时间编码策略(Chen et al., 2024b),为视频片段添加固定格式文本时间戳(如<3.0 seconds>),并在训练中混合秒和HMS(小时:分钟:秒)格式,提升时间感知效率,优化视频预训练和密集字幕任务。
3 预训练
3.1 训练方法
Qwen3-VL模型采用三模块架构 :视觉编码器、基于MLP的视觉-语言合并模块、Qwen3大语言模型(LLM)骨干网络。预训练分为四个阶段(S0-S3),概述见表1。
<表格1/>
| Stage | Objective | Merger | Token Budget | Sequence Length |
|---|---|---|---|---|
| S0 | 视觉-语言对齐 | Merger | 67B | 8,192 |
| S1 | 多模态预训练 | All | ~1T | 8,192 |
| S2 | 长上下文预训练 | All | ~1T | 32,768 |
| S3 | 超长上下文适应 | All | 100B | 262,144 |
阶段0:视觉-语言对齐。 仅训练MLP合并模块 ,视觉编码器和LLM冻结。使用**67B标记数据集,序列长度8,192**。
阶段1:多模态预训练。 解冻所有组件进行端到端训练。使用**~1T标记数据集,序列长度8,192**。
阶段2:长上下文预训练。 序列长度扩展至**32,768**,所有参数可训练。使用**~1T**标记数据集。
阶段3:超长上下文适应。 序列长度提升至**262,144**。使用**100B**标记数据集,专为长视频和长文档理解优化。
3.2 预训练数据
3.2.1 图像标题与交错文本-图像数据
图像标题数据 :构建高保真数据集,使用Qwen2.5-VL-32B模型优化标题生成。
交错文本-图像数据:从网站收集多模态文档,使用Qwen基础评分器过滤。构建特殊子集至**256K**标记,确保页面顺序和多模态连贯性。
3.2.2 知识
构建大规模实体中心数据集,覆盖**12+语义类别。采用基于重要性的采样策略**平衡长尾分布。
3.2.3 OCR、文档解析与长文档理解
OCR :筛选**3000万份样本,支持 39种语言(含 29种新增)。
文档解析:收集 300万份PDF( 10类均匀分布)和 400万**份内部文档。
长文档理解:合成多页文档序列,构建长文档视觉问答(VQA)数据。
3.2.4 视觉定位与计数
Box-based Grounding :聚合开源数据集(COCO等),构建大规模边界框定位数据集。
Point-based Grounding :整合公开点标注和合成高精度点标注。
Counting:构建包含直接计数、边界框计数和点计数的综合数据集。采用**0, 1000**归一化坐标系统提升鲁棒性。
3.2.5 空间理解与3D识别
Spatial Understanding :构建数据集包含关系标注、亲和力标注和动作导向查询。
3D Grounding:收集公共场景数据,格式化为视觉问答,使用**9-DoF**边界框标注。
3.2.6 代码
Text-Only Coding :复用Qwen3代码语料库,覆盖广泛编程语言。
Multimodal Coding:整理数据实现UI截图转HTML/CSS、图像转SVG等任务。
3.2.7 视频
Temporal-Aware Video Understanding :采用短到长字幕合成策略,增强空间-时间定位。
Video Data Balancing and Sampling:构建多样化视频数据集,采用长度自适应采样(动态调整fps和帧数)。
3.2.8 STEM
Visual Perception Data :生成**100万点定位样本和 200万视觉问答对。
Multi-modal Reasoning Data:筛选 6000万K-12和本科练习题,合成1200万**多模态推理样本。
3.2.9 Agent
GUI :构建跨平台GUI交互数据,包含元素描述和多步骤任务轨迹。
Function Calling :合成多模态功能调用轨迹。
Search:收集多模态事实性检索轨迹,整合在线搜索工具。
4 后训练
4.1 训练流程
后训练流程采用三阶段方法,优化模型指令遵循、推理能力及人类偏好对齐。
- 监督微调 (SFT) 。第一阶段赋予模型指令遵循能力,分两阶段:初始**32K上下文长度,后扩展至256K**上下文窗口。训练数据分为标准格式(非思考模型)和思维链(CoT)格式(显式模拟推理)。
- 强到弱蒸馏。第二阶段采用知识蒸馏,教师模型将能力传递给学生模型。使用仅文本数据微调大型语言模型(LLM),显著提升推理任务性能。
- 强化学习 (RL)。最后一阶段利用RL提升性能和对齐,分为推理强化学习(Reasoning RL)和通用强化学习(General RL)。
4.2 冷启动数据
4.2.1 SFT 数据
数据集包含约**1,200,000个样本,分为单模态(1/3纯文本)和多模态(2/3图像-文本/视频-文本对)。训练策略分两阶段:初始 32K标记长度训练一个epoch,后256K**标记长度训练(含长上下文技术文档及两小时视频)。数据筛选流程包括:
- 查询筛选:利用Qwen2.5-VL剔除模糊或低质量查询,保留高挑战性样本。
- 响应筛选 :
- 规则过滤:消除重复、不完整或格式不当的响应。
- 模型过滤:使用Qwen2.5-VL奖励模型多维度评估(正确性、完整性、视觉信息利用),剔除不当语言混合或突兀文体转换的样本。
4.2.2 长思维链冷启动数据
数据集维持视觉-语言与纯文本样本1:1比例。多模态组件涵盖视觉问答(VQA)、光学字符识别(OCR)、2D/3D定位及视频分析,重点增强STEM和智能体工作流任务;纯文本部分包含数学、代码生成等挑战性问题。筛选流程:
- 难度筛选:保留基准模型通过率低的实例。
- 多模态必要性过滤:剔除Qwen3-30B-nothink模型无需视觉输入即可解决的样本。
- 响应质量控制:移除错误答案及过度重复、语言混合不当的响应。
4.3 强到弱蒸馏
蒸馏过程分两阶段:
- 离策略蒸馏:教师模型输出组合用于响应蒸馏,帮助学生模型习得基础推理能力。
- 策略内蒸馏:学生模型生成响应后,通过最小化KL散度对齐学生与教师模型的logits。
4.4 强化学习
4.4.1 推理强化学习
训练数据经严格预处理和人工标注。多模态查询使用Qwen3-VL-235B-A22B模型每查询采样16个响应,全错查询被剔除。
4.4.2 通用强化学习
奖励函数基于多任务(VQA、图像描述、OCR等)优化:
- 指令遵循:评估内容、格式及结构化输出(如JSON)的精确匹配。
- 偏好对齐 :优化有用性、事实准确性和风格恰当性。
通过可验证任务(如反直觉对象计数)纠正SFT阶段错误先验,并构建专用数据集抑制不当语言混合等行为。反馈机制: - 基于规则的奖励:为可验证任务提供高精度反馈。
- 基于模型的奖励:使用Qwen2.5-VL-72B-Instruct或Qwen3判官模型多维度评估响应质量。
4.5 图像思考
受先前工作启发,采用两阶段训练范式实现代理能力。
4.6 基础设施
基于阿里巴巴云PAI-Lingjun服务训练,预训练阶段采用混合并行策略(张量并行、流水线并行等),在 10,000 个GPU规模下保持高吞吐量。推理部署使用vLLM(分页注意力)或SGLang,实现高效稳定推理。
5 评估
5.1 通用视觉问答
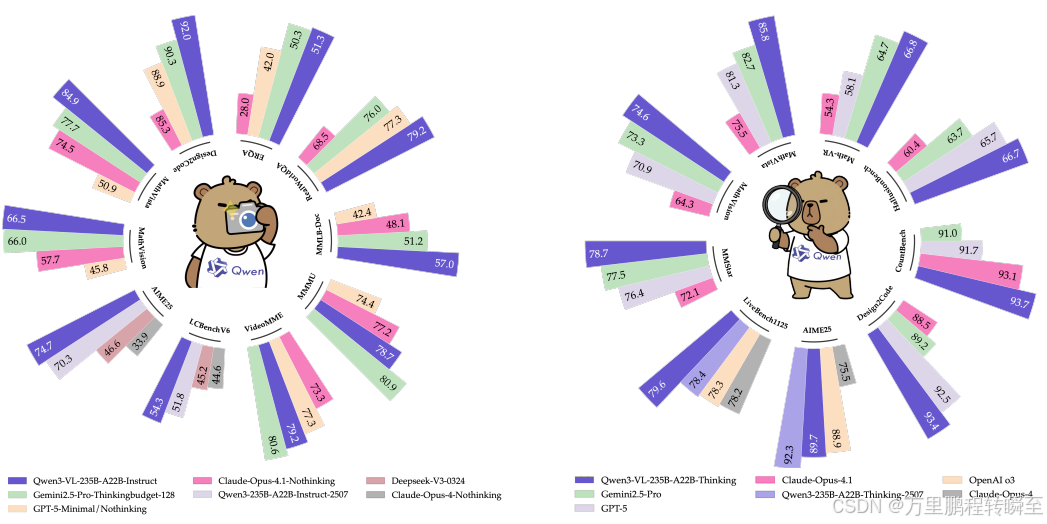
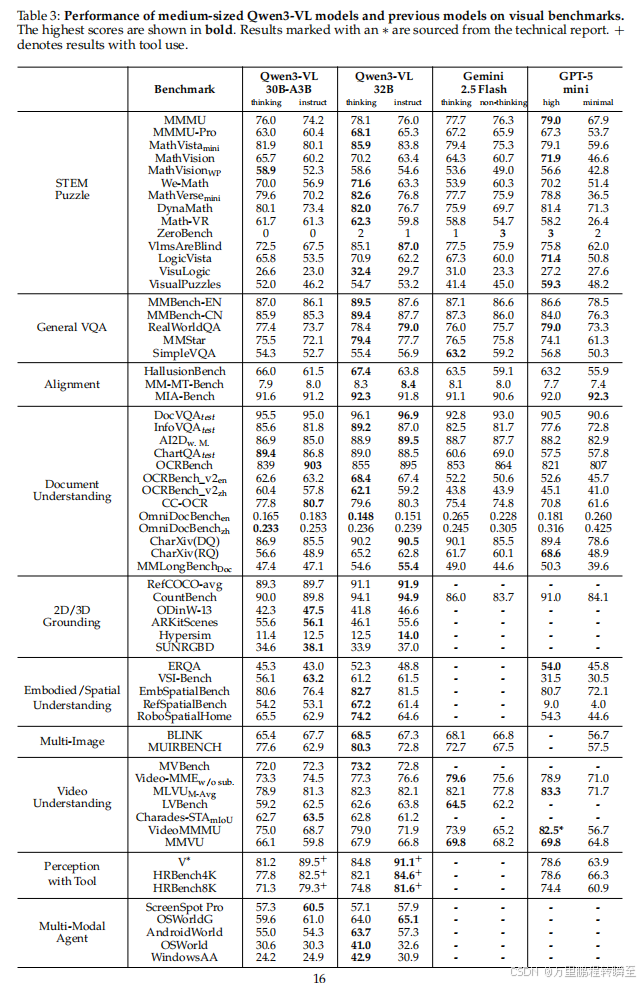
Qwen3-VL系列 在MMBench-V1.1、RealWorldQA、MMStar和SimpleVQA等基准测试上表现优异。Qwen3-VL-235B-A22B-Thinking 在MMStar上得分最高,为78.7 ;Qwen3-VL-235B-A22B-Instruct 在MMBench和RealWorldQA上分别获得89.3/88.9 和79.2 。
中等规模模型 中,Qwen3-VL-32B-Thinking 在MMBench和RealWorldQA上得分分别为89.5/89.5 和79.4 ,其Instruct变体在RealWorldQA上得分为79.0 。
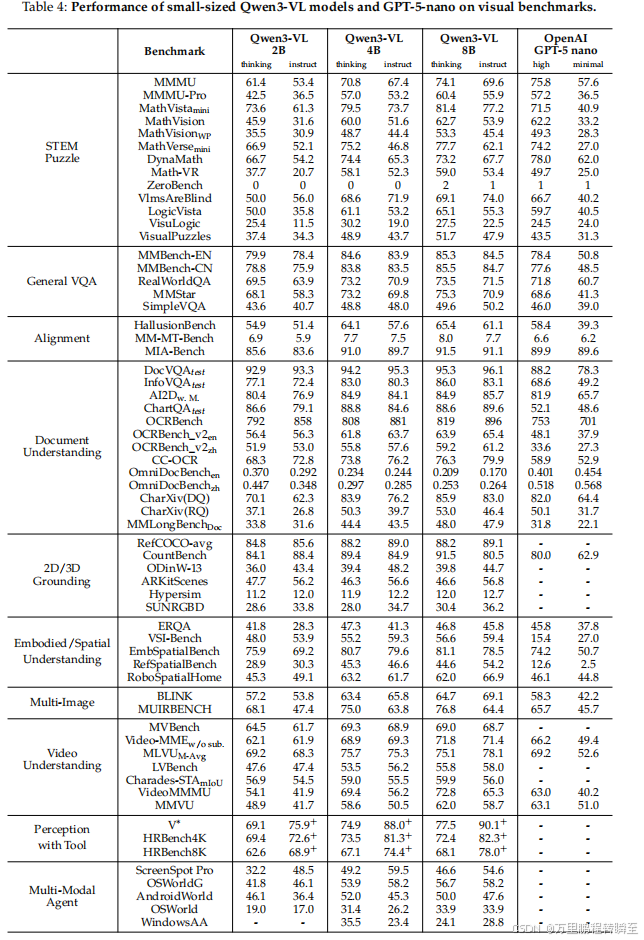
可扩展性 显著:Qwen3-VL-8B 在MMBench-EN上"thinking"模式分数从2B的79.9 提升至85.3 ;在MMStar上从68.1 提升至75.3。
5.2 多模态推理
Qwen3-VL系列 在MMMU、MathVision等STEM相关基准测试中表现突出。旗舰模型:
- Qwen3-VL-235B-A22B-Instruct在MathVista_min等基准上取得非thinking模式最佳结果。
- Qwen3-VL-235B-A22B-Thinking 在MathVista_min等基准上达到state-of-the-art 性能。
中等规模模型 :Qwen3-VL-32B 显著优于Gemini-2.5-Flash和GPT-5-mini,并超越上一代Qwen2.5-VL-72B;Qwen3-VL-30B-A3B MoE 表现具竞争力。
小型模型 :Qwen3-VL-8B 整体优势明显;Qwen3-VL-4B 在DynaMath和VisuLogic上得分最高;Qwen3-VL-2B 仍具强推理能力。
5.3 对齐与主观任务
Qwen3-VL 在MM-MT-Bench、HallusionBench和MIA-Bench上评估指令遵循与抗幻觉能力。旗舰模型 在MIA-Bench上准确率达91.5 ,展现优异对齐性能。
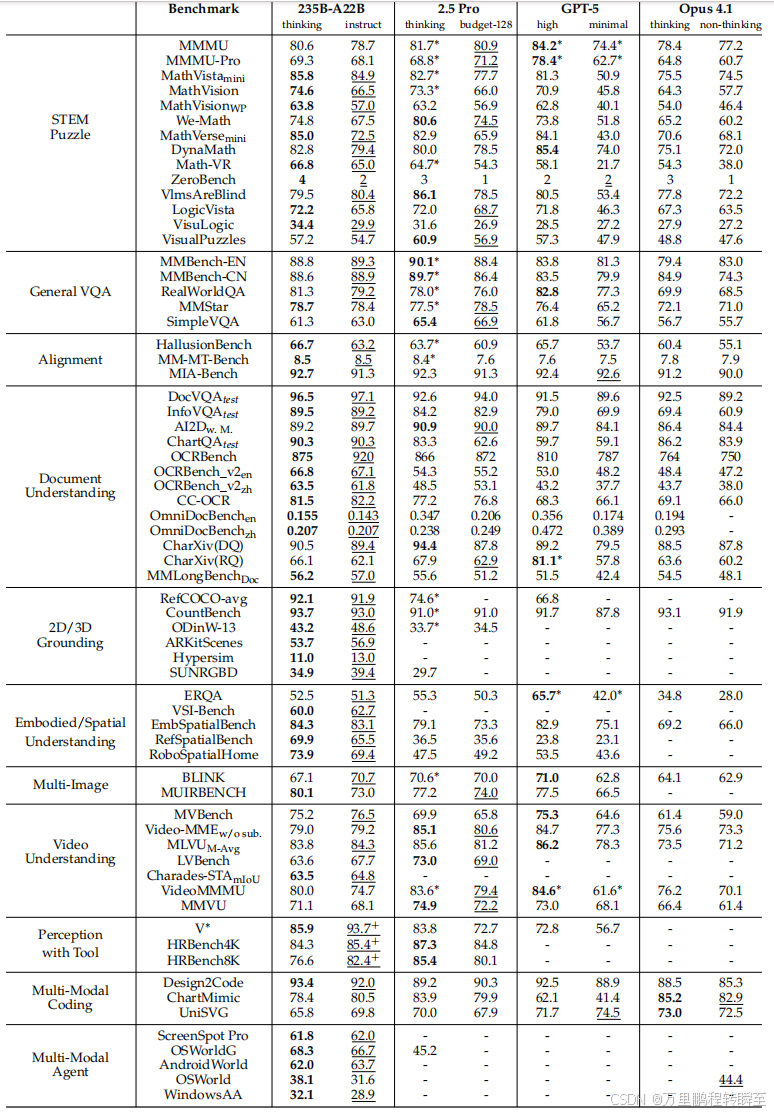
5.4 文本识别与文档理解
Qwen3-VL-235B-A22B在OCR基准(CC-OCR、OCR-Bench等)和文档QA基准(DocVQA、ChartQA等)上表现领先:
- OCR解析 :在CC-OCR上得分79.9(thinking模式)。
- 文档理解 :在CharXiv描述子集上Instruct/Thinking变体表现相当;在CharXiv推理子集上Thinking变体得分53.0,仅次于GPT5-Thinking。
- 长文档理解 :在MMLongBench-Doc上指令/思考模式准确率分别达57.0% /56.2%。
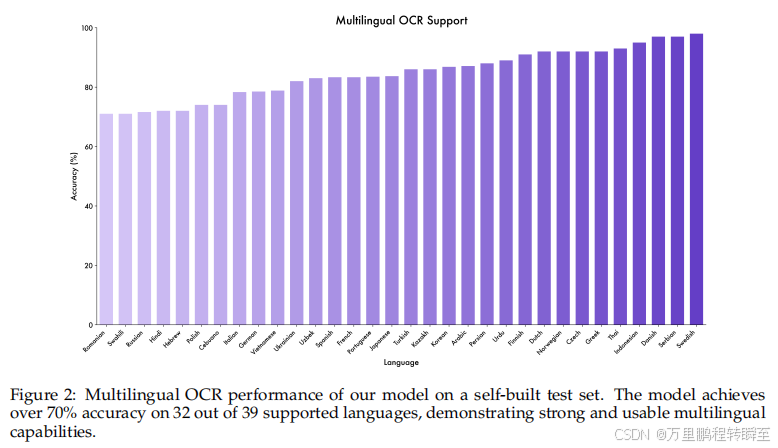
- 多语言支持 :支持39种语言,32种语言准确率超70%。
表格在5.3
5.5 2D 和 3D 定位
2D定位 :Qwen3-VL-235B-A22B 在ODinW-13上mAP达48.6 ,RefCOCO-avg得分89.1 ,均为SOTA。
3D定位 :在Omni3D基准上,Qwen3-VL-235B-A22B-Thinking 在SUN RGB-D上比Gemini-2.5-Pro高5.2 分。
小型模型 :Qwen3-VL-30BA3B等在2D/3D任务上表现具竞争力。
表格在5.3
5.6 细粒度感知
Qwen3-VL-235B-A22B在工具增强下达到SOTA:
- V* :得分93.7
- HRBench-4k :得分85.3
- HRBench-8k :得分82.3
关键发现:工具集成带来的性能提升(如V*上+5分)显著优于单纯扩大模型规模。
5.7 多图像理解
Qwen3-VL在BLINK和MuirBench上表现领先:
- Qwen3-VL-235B-A22B-Thinking 在MuirBench上得分80.1 ,超越所有模型。
表格在5.3
5.8 具身与空间理解
Qwen3-VL-235B-A22在具身空间基准上表现优异:
- EmbSpatialBench :得分84.3
- RefSpatialBench :得分69.9
- RoboSpatialHome :得分73.9
- ERQA :得分52.5
5.9 视频理解
Qwen3-VL通过交错MROPE等架构增强提升视频理解:
- Qwen3-VL-8B性能接近Qwen2.5-VL-72B。
- 旗舰模型 在MLVU上超越Gemini-2.5-Pro;在VideoMMMU上得分90.1(工具增强)。
- 长视频支持:256K上下文窗口在MLVU上表现突出。
5.10 代理能力
Qwen3-VL在GUI任务中表现卓越:
- ScreenSpot Pro :得分54.6(thinking模式)
- OSWorld :得分58.2
- AndroidWorld :得分63.7
小型模型在代理任务上具竞争力。
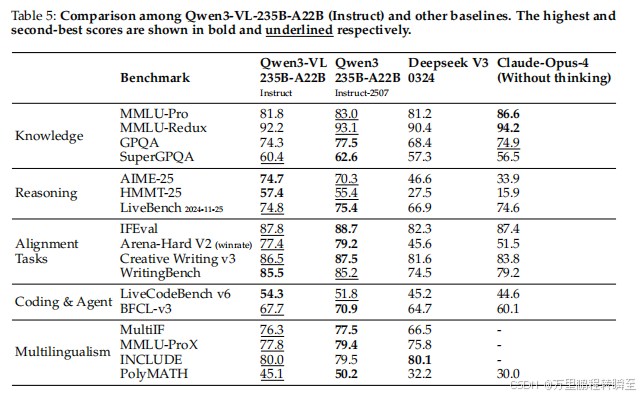
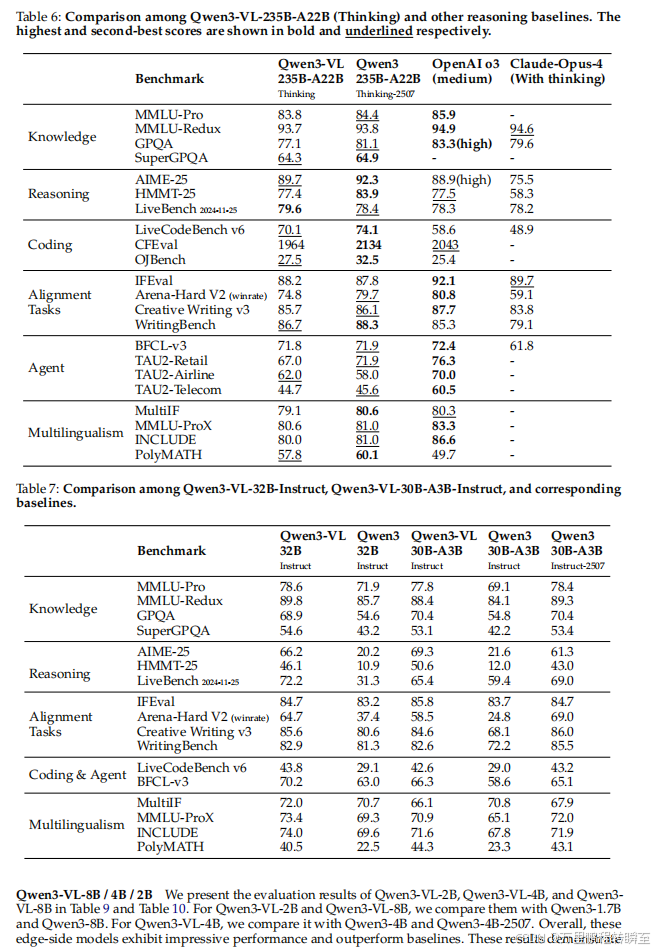
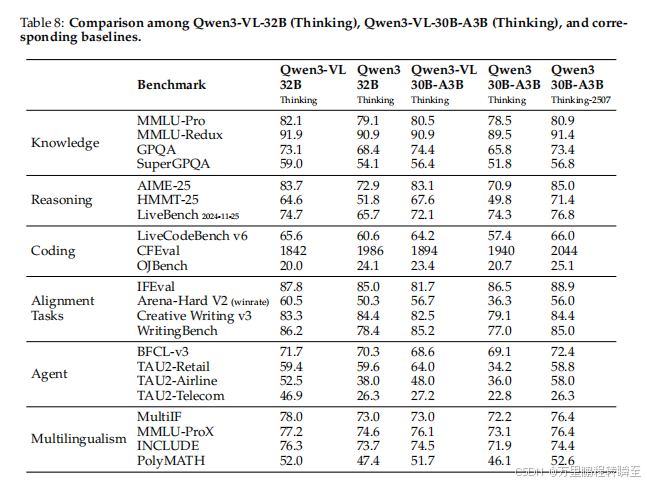
5.11 文本中心任务
Qwen3-VL-235B-A22B:
- Instruct模式:在数学/编码任务上超越DeepSeek V3等模型。
- Thinking模式 :在AIME-25上得分81.4 ,超越OpenAI o3。
中等模型 :Qwen3-VL-32B/30B-A3B 在AIME-25等任务上显著优于纯文本基线。
小型模型 :Qwen3-VL-8B/4B/2B 通过蒸馏实现高效性能。
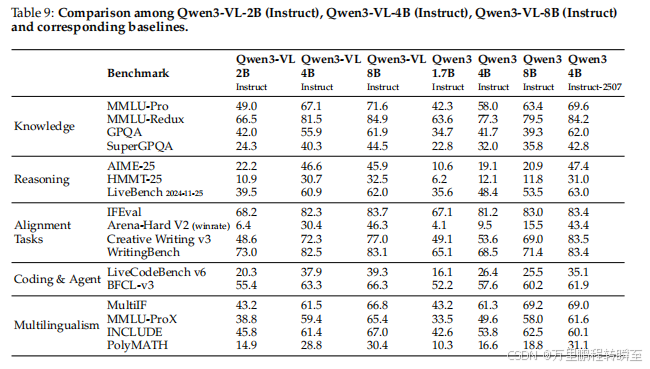
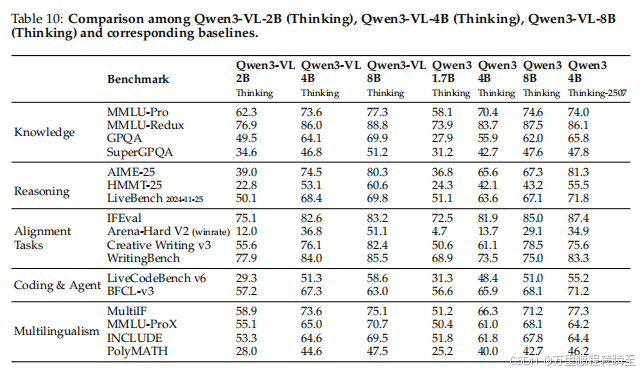
5.12 消融研究
5.12.1 视觉编码器
Qwen3-ViT 在OmniBench上显著优于SigLIP-2基线,证明其作为视觉骨干的有效性。
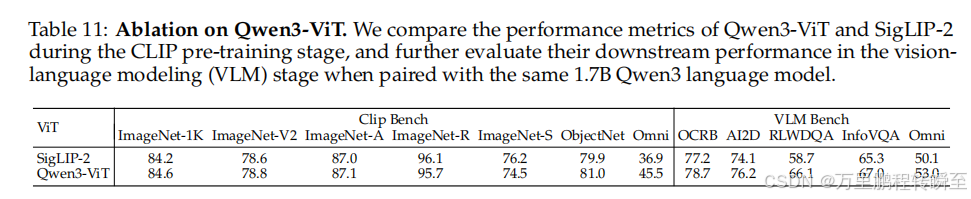
5.12.2 DeepStack
DeepStack机制 提升细粒度理解:在InfoVQA上得分86.0 ,DocVQA上96.1 。

5.12.3 长视频定位
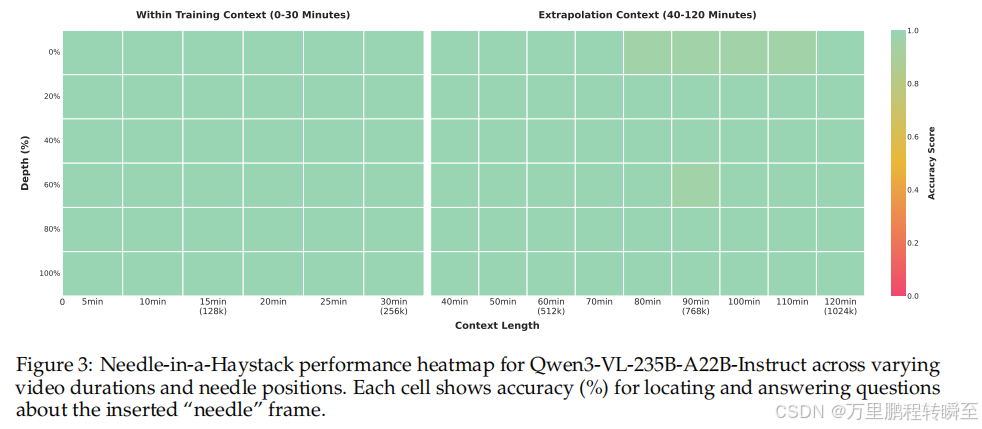
针尖上找针任务:
- 30分钟视频(256K标记)准确率100%。
- 2小时视频(1M标记)准确率99.5% ,验证强长序列建模能力。
6 结论
提出Owen3-VL 视觉-语言基础模型。通过架构创新------如增强的交错式MkRoPE 、DeepStack视觉-语言对齐 和基于文本的时间定位 ------在多模态基准测试中实现了**前所未有的性能**,并保持纯文本能力。原生支持256K标记交错序列,能对长文档、图像序列和视频进行稳健推理。提供** 密集模型和 混合专家(MoE)变体**,支持不同延迟和质量要求的灵活部署;后训练策略包括非思考模式 和思考模式 。未来工作聚焦于扩展能力实现交互式感知 、工具增强推理 和实时多模态控制 ;探索统一的理解-生成架构 ;模型以Apache 2.0许可证公开发布。