目录
一:简述哈希表
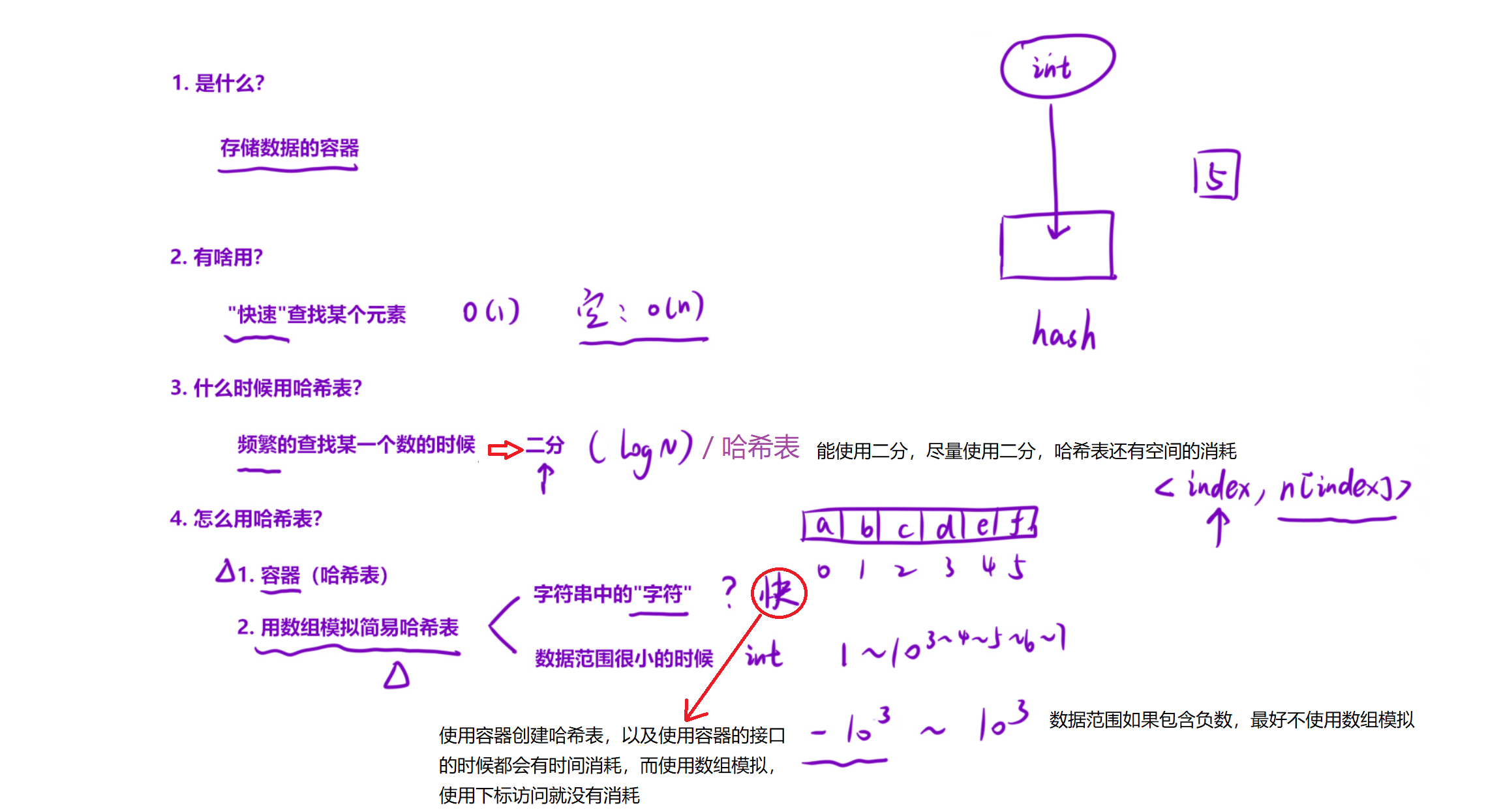
二::两数之和
2.1题目
题目链接:https://leetcode.cn/problems/two-sum/description/
2.2算法原理

2.3代码
解法一:暴力枚举,时间复杂度O(N)
cpp
//暴力枚举:固定一个数,找这个数之前的数字与该数的和
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target)
{
for (int i = 0; i < nums.size(); i++)
{
for (int j = 0; j < i; j++)
{
if (nums[i] + nums[j] == target)
return { j,i };
}
}
return {};
}
};解法二:哈希表,时间复杂度O(N)
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target)
{
unordered_map<int,int> hash;
for(int i = 0; i < nums.size();i++)
{
if(hash.count(target-nums[i])) return {hash[target-nums[i]],i};
hash.insert({nums[i],i});
}
return {};
}
};三:判定是否互为字符重排
3.1题目

题目链接:https://leetcode.cn/problems/check-permutation-lcci/description/
3.2算法原理

3.3代码
cpp
class Solution {
public:
bool CheckPermutation(string s1, string s2)
{
if(s1.size() != s2.size()) return false;
//优化:只使用一个hash数组
int hash[26] = {0};
for(int i = 0; i < s1.size();i++)
hash[s1[i]-'a']++;
for(int i = 0; i < s2.size();i++)
{
hash[s2[i]-'a']--;
if(hash[s2[i]-'a'] < 0)
return false;
}
return true;
}
};四:存在重复元素
4.1题目

题目链接:https://leetcode.cn/problems/contains-duplicate/description/
4.2算法原理
和二:两数之和的算法原理思路一样,使用哈希表,遍历数组固定数组一个数,然后找它前面有没有数字和它相等(在哈希表中找),如果没有就把自己加入哈希表中,如果有返回true
其中题目中数字范围有正有负,最好使用容器,而且本次添加不需要添加数组下标或者出现次数,使用unordered_set即可
4.3代码
cpp
class Solution {
public:
bool containsDuplicate(vector<int>& nums)
{
unordered_set<int> hash;
for(int i = 0; i < nums.size();i++)
{
if(hash.count(nums[i])) return true;
hash.insert(nums[i]);
}
return false;
}
};五:存在重复元素II
5.1题目

题目链接:https://leetcode.cn/problems/contains-duplicate-ii/
5.2算法原理
本题和四:存在重复元素唯一的区别就是多了一个判断条件,数组下标的差的绝对值不大于k,所以此时我们使用unordered_map,其他思路和上一道题目一样
细节:如果遇到两个重复元素,1(0)和1(3)它们下标的差大于2,此时再把{1,3}加入哈希表的时候,会覆盖之前{1,0}的数据,没有关系,因为求的下标差小于等于k,所以两个重复数字肯定是越近越好,把之前远的数据覆盖不会影响结果
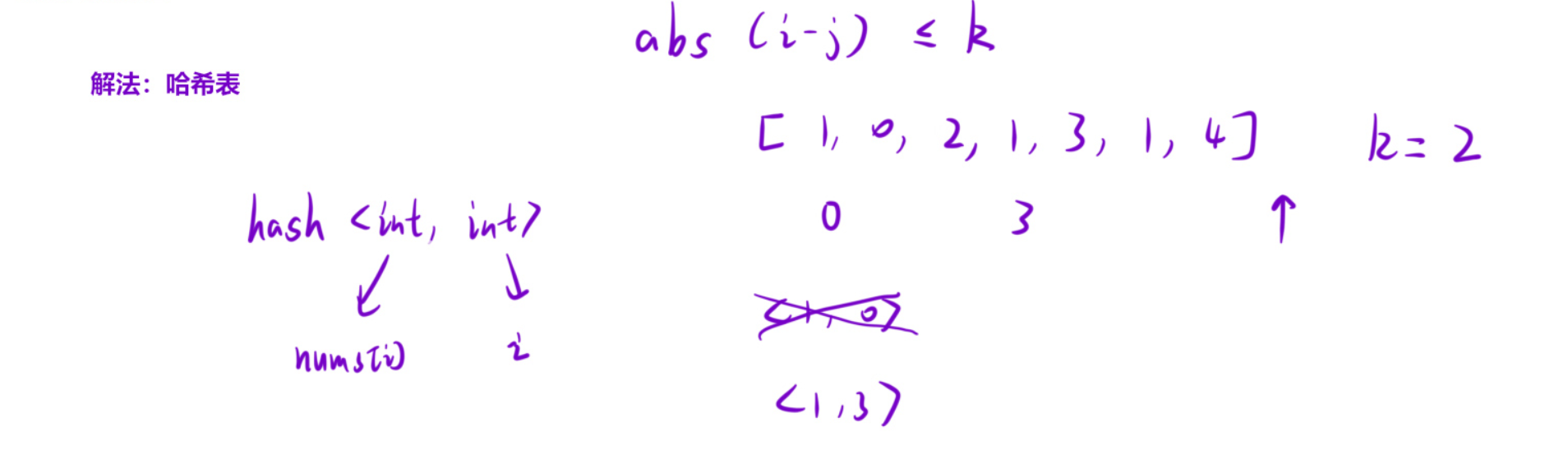
5.3代码
cpp
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k)
{
unordered_map<int,int> hash;//<nums[i],i>
for(int i = 0;i < nums.size();i++)
{
if(hash.count(nums[i]) && i - hash[nums[i]] <= k)
return true;
hash[nums[i]] = i;
}
return false;
}
};六:字母异位词分组
6.1题目

题目链接:https://leetcode.cn/problems/group-anagrams/description/
6.2算法原理

6.3代码
cpp
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs)
{
vector<vector<string>> ret;
unordered_map<string,vector<string>> hash;
//1.把所有的字母异位词排序
for(auto& s :strs)
{
string tmp = s;
sort(tmp.begin(),tmp.end());
hash[tmp].push_back(s);
}
//2.把结果提取出来
for(auto &[x,y] : hash)
ret.push_back(y);
return ret;
}
};