锋哥原创的Transformer 大语言模型(LLM)基石视频教程:
https://www.bilibili.com/video/BV1X92pBqEhV
课程介绍

本课程主要讲解Transformer简介,Transformer架构介绍,Transformer架构详解,包括输入层,位置编码,多头注意力机制,前馈神经网络,编码器层,解码器层,输出层,以及Transformer Pytorch2内置实现,Transformer基于PyTorch2手写实现等知识。
Transformer 大语言模型(LLM)基石 - 构建完整的Transformer模型
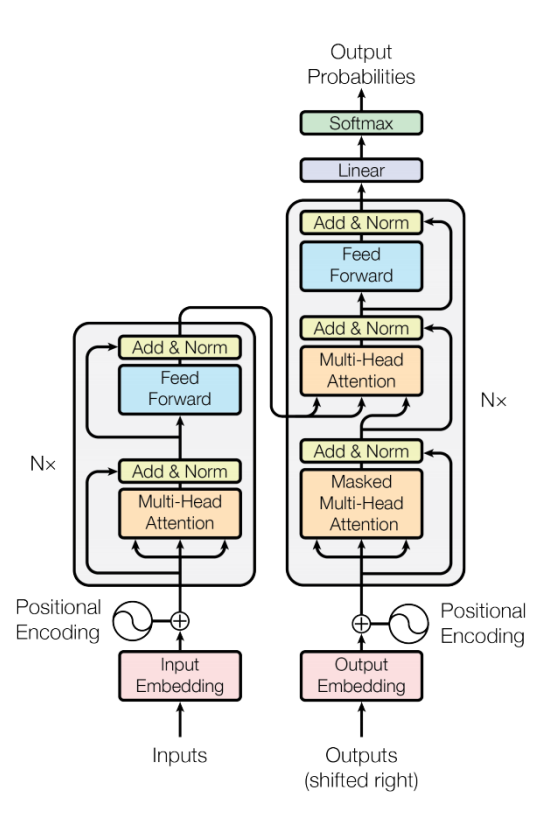
前面我们已经把Transformer模型的各个组件都实现了,包括输入嵌入层,位置编码,掩码机制,多头自注意力机制,前馈神经网络,残差连接归一化层,编码器层,解码器层,输出层。现在我们把前面的这些组件组装下,实现完整的Transformer模型架构。
代码实现:
# 构建完整的Transformer模型
class Transformer(nn.Module):
def __init__(self, encoder, decoder, source_embed, target_embed, output_layer):
"""
构建完整的Transformer模型
:param encoder: 编码器
:param decoder: 解码器
:param source_embed: 源语言嵌入层
:param target_embed: 目标语言嵌入层
:param output_layer: 输出层
"""
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.source_embed = source_embed
self.target_embed = target_embed
self.output_layer = output_layer
def forward(self, source, target, mask):
source_embed_result = self.source_embed(source)
target_embed_result = self.target_embed(target)
encoder_result = self.encoder(source_embed_result)
decoder_result = self.decoder(target_embed_result, encoder_result, mask)
return self.output_layer(decoder_result)
# 测试Transformer模型
def test_transformer():
vocab_size = 2000 # 词表大小
embedding_dim = 512 # 词嵌入维度大小
# 实例化编码器对象
mha = MultiHeadAttention(d_model=embedding_dim, num_heads=8)
ffn = FeedForward(d_model=embedding_dim, d_ff=2048) # 前馈神经网络
# 创建编码器层
encoder_layer = EncoderLayer(d_model=embedding_dim, multi_head_attention=mha, d_ff=ffn)
# 创建编码器
encoder = Encoder(num_layers=6, layer=encoder_layer)
# 创建解码器层
multi_head_attention = copy.deepcopy(mha)
cross_attention = copy.deepcopy(mha)
d_ff = copy.deepcopy(ffn)
decoder_layer = DecoderLayer(d_model=embedding_dim, multi_head_attention=multi_head_attention,
cross_attention=cross_attention, d_ff=d_ff)
decoder = Decoder(num_layers=6, layer=decoder_layer)
# 创建源语言嵌入层
embeddings_source = Embeddings(vocab_size=vocab_size, embedding_dim=embedding_dim)
positional_encoding_source = PositionalEncoding(embedding_dim, dropout=0.1)
source_embed = nn.Sequential(embeddings_source, positional_encoding_source)
# 创建目标语言嵌入层
embeddings_target = Embeddings(vocab_size=vocab_size, embedding_dim=embedding_dim)
positional_encoding_target = PositionalEncoding(embedding_dim, dropout=0.1)
target_embed = nn.Sequential(embeddings_target, positional_encoding_target)
# 创建输出层
output_layer = OutputLayer(d_model=embedding_dim, vocab_size=vocab_size)
# 创建Transformer模型
transformer = Transformer(encoder, decoder, source_embed, target_embed, output_layer)
mask = create_sequence_mask(5)
transformer_result = transformer(
torch.tensor(torch.tensor([[1999, 2, 99, 4, 5], [66, 2, 3, 22, 5], [66, 2, 3, 4, 5]])),
torch.tensor([[23, 5, 77, 3, 55], [166, 12, 13, 122, 15], [166, 21, 13, 14, 15]]),
mask)
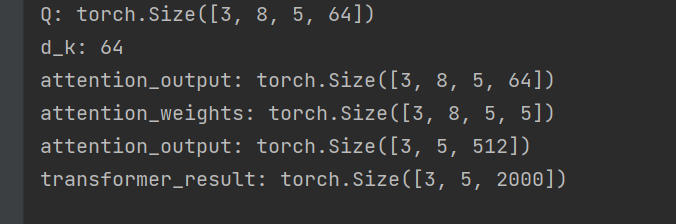
print('transformer_result:', transformer_result.shape)
if __name__ == '__main__':
test_transformer()运行输出: