AIGC+风格迁移:用Stable Diffusion生成自定义风格
引言:AI绘画与风格迁移的完美融合
当神经风格迁移遇上Stable Diffusion,我们进入了一个前所未有的艺术创作新时代 。传统的风格迁移受限于已有的艺术风格,而通过Stable Diffusion,我们可以生成任意想象的风格图像,再将其应用于风格迁移,这开启了无限的可能性。
根据最新研究,结合AIGC(AI Generated Content)与神经风格迁移的创作方式,可以使创意产出效率提高300% ,风格多样性提升500%。
本文将带你从零开始,掌握如何使用Stable Diffusion生成自定义风格,并将其完美融合到神经风格迁移流程中。
技术融合的价值体现
传统风格迁移 依赖现有艺术作品 风格选择有限 Stable Diffusion 生成任意风格 风格无限扩展 融合价值 AI+风格迁移新范式 1. 风格自定义 2. 混合风格创造 3. 快速迭代优化 4. 商业应用拓展 突破传统限制 创造全新艺术形式 提高创作效率 拓宽应用场景
第一部分:Stable Diffusion WebUI本地部署全攻略
1.1 Windows系统部署指南
系统要求与准备
在开始部署前,请确保满足以下硬件要求:
| 组件 | 最低要求 | 推荐配置 | 说明 |
|---|---|---|---|
| GPU | NVIDIA GTX 1060 6GB | RTX 3060 12GB或更高 | CUDA核心数越多越好 |
| 显存 | 4GB | 8GB以上 | 决定生成图像的分辨率 |
| 内存 | 8GB | 16GB或更高 | 影响运行稳定性 |
| 存储 | 20GB可用空间 | 50GB SSD | 模型文件较大 |
| 系统 | Windows 10/11 | Windows 11 | 需要最新驱动 |
完整部署流程
python
# Windows部署自动化脚本
import os
import sys
import subprocess
import requests
import zipfile
import tarfile
class StableDiffusionWindowsDeployer:
"""
Stable Diffusion Windows部署工具
自动化完成环境配置和WebUI部署
"""
def __init__(self):
self.base_dir = os.path.expanduser("~/stable-diffusion-webui")
self.install_log = []
def check_system_requirements(self):
"""检查系统要求"""
print("=" * 60)
print("系统要求检查")
print("=" * 60)
requirements = {
'python_version': self._check_python_version(),
'git_installed': self._check_git_installed(),
'cuda_available': self._check_cuda_availability(),
'disk_space': self._check_disk_space(),
'ram_size': self._check_ram_size()
}
# 输出检查结果
all_met = True
for req, (met, message) in requirements.items():
status = "✅" if met else "❌"
print(f"{status} {message}")
if not met:
all_met = False
return all_met, requirements
def _check_python_version(self):
"""检查Python版本"""
try:
version = sys.version_info
if version.major == 3 and version.minor >= 10:
return True, f"Python {version.major}.{version.minor}.{version.micro} (符合要求)"
else:
return False, f"Python {version.major}.{version.minor}.{version.micro} (需要3.10+)"
except:
return False, "Python未安装或版本过低"
def _check_git_installed(self):
"""检查Git是否安装"""
try:
result = subprocess.run(['git', '--version'],
capture_output=True, text=True)
if result.returncode == 0:
return True, "Git已安装"
else:
return False, "Git未安装"
except FileNotFoundError:
return False, "Git未安装"
def _check_cuda_availability(self):
"""检查CUDA是否可用"""
try:
# 尝试导入torch检查CUDA
import torch
if torch.cuda.is_available():
device_count = torch.cuda.device_count()
device_name = torch.cuda.get_device_name(0)
return True, f"CUDA可用: {device_name} ({device_count}个GPU)"
else:
return False, "CUDA不可用,将使用CPU模式(极慢)"
except ImportError:
return False, "PyTorch未安装"
def _check_disk_space(self):
"""检查磁盘空间"""
import shutil
total, used, free = shutil.disk_usage(self.base_dir)
free_gb = free // (2**30) # 转换为GB
if free_gb >= 20:
return True, f"磁盘空间充足: {free_gb}GB可用"
elif free_gb >= 10:
return False, f"磁盘空间紧张: {free_gb}GB可用(需要至少20GB)"
else:
return False, f"磁盘空间不足: {free_gb}GB可用(需要至少20GB)"
def _check_ram_size(self):
"""检查内存大小"""
import psutil
ram_gb = psutil.virtual_memory().total // (1024**3)
if ram_gb >= 16:
return True, f"内存充足: {ram_gb}GB"
elif ram_gb >= 8:
return False, f"内存较低: {ram_gb}GB(建议16GB以上)"
else:
return False, f"内存不足: {ram_gb}GB(需要至少8GB)"
def install_prerequisites(self):
"""安装必要的软件和依赖"""
print("\n" + "=" * 60)
print("安装必要软件")
print("=" * 60)
# 1. 安装Git(如果未安装)
if not self._check_git_installed()[0]:
print("正在安装Git...")
git_url = "https://github.com/git-for-windows/git/releases/download/v2.41.0.windows.3/Git-2.41.0.3-64-bit.exe"
git_installer = os.path.join(os.environ['TEMP'], "git_installer.exe")
# 下载Git安装程序
self._download_file(git_url, git_installer)
# 执行安装
subprocess.run([git_installer, '/VERYSILENT', '/NORESTART'])
print("Git安装完成")
# 2. 安装Python 3.10(如果版本不符合要求)
if not self._check_python_version()[0]:
print("正在安装Python 3.10...")
python_url = "https://www.python.org/ftp/python/3.10.11/python-3.10.11-amd64.exe"
python_installer = os.path.join(os.environ['TEMP'], "python_installer.exe")
self._download_file(python_url, python_installer)
# 执行安装,添加Python到PATH
subprocess.run([python_installer, '/quiet', 'InstallAllUsers=1',
'PrependPath=1', 'Include_test=0'])
print("Python安装完成,请重启命令行")
return False
# 3. 设置Python虚拟环境
print("设置Python虚拟环境...")
venv_path = os.path.join(self.base_dir, "venv")
if not os.path.exists(venv_path):
subprocess.run([sys.executable, "-m", "venv", venv_path])
print("虚拟环境创建完成")
return True
def clone_webui_repository(self):
"""克隆Stable Diffusion WebUI仓库"""
print("\n" + "=" * 60)
print("克隆WebUI仓库")
print("=" * 60)
webui_url = "https://github.com/AUTOMATIC1111/stable-diffusion-webui.git"
if not os.path.exists(self.base_dir):
os.makedirs(self.base_dir, exist_ok=True)
# 切换到目标目录
original_dir = os.getcwd()
os.chdir(self.base_dir)
try:
# 克隆仓库
print(f"正在克隆仓库到: {self.base_dir}")
result = subprocess.run(['git', 'clone', webui_url, '.'],
capture_output=True, text=True)
if result.returncode == 0:
print("✅ 仓库克隆成功")
self.install_log.append("仓库克隆成功")
else:
print(f"❌ 克隆失败: {result.stderr}")
return False
finally:
os.chdir(original_dir)
return True
def install_dependencies(self):
"""安装Python依赖"""
print("\n" + "=" * 60)
print("安装Python依赖")
print("=" * 60)
original_dir = os.getcwd()
os.chdir(self.base_dir)
try:
# 激活虚拟环境
venv_script = os.path.join("venv", "Scripts", "activate")
# 安装torch(根据CUDA情况选择版本)
import torch
if torch.cuda.is_available():
torch_command = "pip install torch torchvision --index-url https://download.pytorch.org/whl/cu118"
else:
torch_command = "pip install torch torchvision"
# 执行安装
print("安装PyTorch...")
subprocess.run(f"venv\\Scripts\\python -m {torch_command}", shell=True)
print("安装WebUI依赖...")
subprocess.run("venv\\Scripts\\python -m pip install -r requirements.txt", shell=True)
print("✅ 依赖安装完成")
self.install_log.append("Python依赖安装完成")
except Exception as e:
print(f"❌ 依赖安装失败: {e}")
return False
finally:
os.chdir(original_dir)
return True
def download_models(self):
"""下载必要的模型文件"""
print("\n" + "=" * 60)
print("下载模型文件")
print("=" * 60)
models_dir = os.path.join(self.base_dir, "models", "Stable-diffusion")
os.makedirs(models_dir, exist_ok=True)
# 常用模型列表
models = {
"sd-v1-5": {
"url": "https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors",
"filename": "v1-5-pruned-emaonly.safetensors",
"size_gb": 4.27
},
"chilloutmix": {
"url": "https://civitai.com/api/download/models/11745",
"filename": "chilloutmix_NiPrunedFp32Fix.safetensors",
"size_gb": 7.7
},
"realistic-vision": {
"url": "https://civitai.com/api/download/models/130072",
"filename": "realisticVisionV60B1_v51HyperVAE.safetensors",
"size_gb": 7.98
}
}
print("可用模型:")
for i, (model_name, model_info) in enumerate(models.items(), 1):
print(f" {i}. {model_name} - {model_info['size_gb']}GB")
# 让用户选择模型
choice = input(f"\n请选择要下载的模型 (1-{len(models)},默认1): ").strip()
if not choice:
choice = "1"
try:
choice_idx = int(choice) - 1
selected_model = list(models.keys())[choice_idx]
model_info = models[selected_model]
model_path = os.path.join(models_dir, model_info['filename'])
if os.path.exists(model_path):
print(f"模型已存在: {model_path}")
else:
print(f"正在下载 {selected_model} ({model_info['size_gb']}GB)...")
print("这可能需要一些时间,请耐心等待...")
self._download_large_file(model_info['url'], model_path)
print(f"✅ 模型下载完成: {model_info['filename']}")
self.install_log.append(f"模型下载: {selected_model}")
except (ValueError, IndexError):
print("无效选择,跳过模型下载")
return True
def _download_large_file(self, url, save_path):
"""下载大文件,支持断点续传"""
import requests
from tqdm import tqdm
# 设置请求头
headers = {}
if os.path.exists(save_path):
# 断点续传
downloaded_size = os.path.getsize(save_path)
headers['Range'] = f'bytes={downloaded_size}-'
mode = 'ab'
else:
downloaded_size = 0
mode = 'wb'
response = requests.get(url, headers=headers, stream=True)
response.raise_for_status()
# 获取文件总大小
total_size = int(response.headers.get('content-length', 0)) + downloaded_size
# 进度条
with tqdm(total=total_size, unit='B', unit_scale=True,
desc=os.path.basename(save_path), initial=downloaded_size) as pbar:
with open(save_path, mode) as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
pbar.update(len(chunk))
def create_configuration(self):
"""创建配置文件"""
print("\n" + "=" * 60)
print("创建配置文件")
print("=" * 60)
config_dir = os.path.join(self.base_dir, "configs")
os.makedirs(config_dir, exist_ok=True)
# WebUI用户配置文件
config_content = """# Stable Diffusion WebUI 配置
# 生成的配置文件 - 适用于风格迁移应用
[general]
# 运行设置
listen = False
port = 7860
show_only_visible_options = True
# 显存优化
medvram = False
lowvram = False
# 性能设置
enable_console_prompts = True
multiple_tqdm = True
theme = dark
[models]
# 默认模型
sd_model_checkpoint = v1-5-pruned-emaonly.safetensors
sd_checkpoint_cache = 0
sd_vae = Automatic
[ui]
# 界面设置
show_progressbar = True
show_progress_every_n_steps = 10
enable_pnginfo = True
# 画廊设置
return_grid = True
do_not_show_images = False
[system]
# 系统设置
cross_attention_optimization = Automatic
# 内存设置
use_cpu = False
"""
config_path = os.path.join(config_dir, "webui-user.bat")
with open(config_path, 'w', encoding='utf-8') as f:
f.write("@echo off\n")
f.write(f"set PYTHON={os.path.join(self.base_dir, 'venv', 'Scripts', 'python.exe')}\n")
f.write(f"set GIT={subprocess.check_output('where git', shell=True).decode().strip()}\n")
f.write(f"set VENV_DIR={os.path.join(self.base_dir, 'venv')}\n")
f.write(f"set COMMANDLINE_ARGS=--port 7860 --api --listen\n")
f.write("call webui.bat\n")
print(f"✅ 配置文件创建完成: {config_path}")
self.install_log.append("配置文件创建完成")
return True
def test_installation(self):
"""测试安装"""
print("\n" + "=" * 60)
print("测试安装")
print("=" * 60)
original_dir = os.getcwd()
os.chdir(self.base_dir)
try:
# 尝试启动WebUI
print("启动WebUI进行测试...")
# 在后台启动WebUI
import threading
import time
def start_webui():
subprocess.run("webui-user.bat", shell=True)
thread = threading.Thread(target=start_webui)
thread.daemon = True
thread.start()
# 等待启动
print("等待WebUI启动(约30秒)...")
time.sleep(30)
# 测试API连接
try:
import requests
response = requests.get("http://127.0.0.1:7860")
if response.status_code == 200:
print("✅ WebUI启动成功")
self.install_log.append("WebUI测试成功")
# 显示访问信息
print("\n访问信息:")
print(f" 本地访问: http://127.0.0.1:7860")
print(f" 网络访问: http://[你的IP]:7860")
print(f" API地址: http://127.0.0.1:7860/sdapi/v1")
return True
else:
print(f"❌ WebUI启动失败: HTTP {response.status_code}")
return False
except requests.ConnectionError:
print("❌ WebUI未启动或连接失败")
return False
except Exception as e:
print(f"❌ 测试失败: {e}")
return False
finally:
os.chdir(original_dir)
def generate_install_report(self):
"""生成安装报告"""
print("\n" + "=" * 60)
print("安装报告")
print("=" * 60)
report = {
"安装目录": self.base_dir,
"安装步骤": self.install_log,
"下一步操作": [
"1. 访问 http://127.0.0.1:7860 使用WebUI",
"2. 在Settings中配置模型路径",
"3. 在Extensions中安装ControlNet等插件",
"4. 开始生成自定义风格图像"
],
"常用命令": [
f"启动: cd {self.base_dir} && webui-user.bat",
"更新: git pull",
"安装扩展: 在WebUI的Extensions标签中安装"
]
}
# 保存报告
report_path = os.path.join(self.base_dir, "安装报告.txt")
with open(report_path, 'w', encoding='utf-8') as f:
f.write("Stable Diffusion WebUI 安装报告\n")
f.write("=" * 50 + "\n\n")
for key, value in report.items():
f.write(f"{key}:\n")
if isinstance(value, list):
for item in value:
f.write(f" {item}\n")
else:
f.write(f" {value}\n")
f.write("\n")
print(f"✅ 安装报告已保存: {report_path}")
# 显示报告摘要
print("\n安装摘要:")
for step in self.install_log:
print(f" ✅ {step}")
def run_full_deployment(self):
"""执行完整部署流程"""
print("Stable Diffusion WebUI Windows部署")
print("=" * 60)
# 1. 检查系统要求
requirements_met, requirements = self.check_system_requirements()
if not requirements_met:
print("\n⚠️ 系统要求未完全满足,是否继续?")
response = input("继续安装可能遇到问题 (y/n): ")
if response.lower() != 'y':
print("安装取消")
return False
# 2. 安装必要软件
if not self.install_prerequisites():
return False
# 3. 克隆仓库
if not self.clone_webui_repository():
return False
# 4. 安装依赖
if not self.install_dependencies():
return False
# 5. 下载模型
self.download_models()
# 6. 创建配置
self.create_configuration()
# 7. 测试安装
if not self.test_installation():
print("\n⚠️ 测试失败,但安装可能仍可使用")
print("请手动运行 webui-user.bat 启动")
# 8. 生成报告
self.generate_install_report()
print("\n" + "=" * 60)
print("✅ 部署完成!")
print("=" * 60)
return True
# 使用示例
if __name__ == "__main__":
deployer = StableDiffusionWindowsDeployer()
deployer.run_full_deployment()1.2 Linux系统部署指南
Linux系统部署相对简单,这里提供Ubuntu/Debian系统的自动化部署脚本:
bash
#!/bin/bash
# stable-diffusion-linux-installer.sh
# Stable Diffusion WebUI Linux自动化安装脚本
set -e
echo "========================================"
echo "Stable Diffusion WebUI Linux安装脚本"
echo "========================================"
# 颜色定义
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
# 函数定义
print_success() {
echo -e "${GREEN}[✓] $1${NC}"
}
print_warning() {
echo -e "${YELLOW}[!] $1${NC}"
}
print_error() {
echo -e "${RED}[✗] $1${NC}"
}
# 检查系统
check_system() {
echo "检查系统要求..."
# 检查发行版
if [ -f /etc/os-release ]; then
. /etc/os-release
echo "系统: $NAME $VERSION"
fi
# 检查Python
if command -v python3.10 &> /dev/null; then
print_success "Python 3.10 已安装"
else
print_error "Python 3.10 未安装"
exit 1
fi
# 检查Git
if command -v git &> /dev/null; then
print_success "Git 已安装"
else
print_error "Git 未安装"
exit 1
fi
# 检查CUDA
if command -v nvcc &> /dev/null; then
CUDA_VERSION=$(nvcc --version | grep "release" | awk '{print $6}')
print_success "CUDA $CUDA_VERSION 已安装"
else
print_warning "CUDA 未安装,将使用CPU模式"
fi
# 检查内存
MEM_TOTAL=$(free -g | awk '/^Mem:/{print $2}')
if [ "$MEM_TOTAL" -ge 16 ]; then
print_success "内存: ${MEM_TOTAL}GB (充足)"
elif [ "$MEM_TOTAL" -ge 8 ]; then
print_warning "内存: ${MEM_TOTAL}GB (建议16GB以上)"
else
print_error "内存: ${MEM_TOTAL}GB (不足)"
exit 1
fi
# 检查磁盘空间
DISK_SPACE=$(df -BG . | awk 'NR==2 {print $4}' | sed 's/G//')
if [ "$DISK_SPACE" -ge 50 ]; then
print_success "磁盘空间: ${DISK_SPACE}GB (充足)"
elif [ "$DISK_SPACE" -ge 20 ]; then
print_warning "磁盘空间: ${DISK_SPACE}GB (建议50GB以上)"
else
print_error "磁盘空间: ${DISK_SPACE}GB (不足)"
exit 1
fi
}
# 安装依赖
install_dependencies() {
echo "安装系统依赖..."
if [ -f /etc/debian_version ]; then
# Debian/Ubuntu
sudo apt-get update
sudo apt-get install -y \
wget \
git \
python3.10-venv \
python3.10-dev \
build-essential \
libgl1-mesa-glx \
libglib2.0-0 \
libsm6 \
libxext6 \
libxrender-dev
print_success "系统依赖安装完成"
elif [ -f /etc/redhat-release ]; then
# RHEL/CentOS/Fedora
sudo yum groupinstall "Development Tools"
sudo yum install -y \
wget \
git \
python3.10 \
python3.10-devel \
mesa-libGL \
libglvnd-glx
print_success "系统依赖安装完成"
else
print_warning "未知的Linux发行版,请手动安装依赖"
fi
}
# 克隆WebUI
clone_webui() {
echo "克隆Stable Diffusion WebUI..."
SD_DIR="$HOME/stable-diffusion-webui"
if [ -d "$SD_DIR" ]; then
print_warning "目录已存在,更新代码..."
cd "$SD_DIR"
git pull
else
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git "$SD_DIR"
print_success "WebUI克隆完成"
fi
cd "$SD_DIR"
}
# 设置虚拟环境
setup_venv() {
echo "设置Python虚拟环境..."
if [ ! -d "venv" ]; then
python3.10 -m venv venv
print_success "虚拟环境创建完成"
else
print_warning "虚拟环境已存在"
fi
# 激活虚拟环境
source venv/bin/activate
}
# 安装Python依赖
install_python_deps() {
echo "安装Python依赖..."
# 升级pip
pip install --upgrade pip
# 安装PyTorch(根据CUDA情况)
if command -v nvcc &> /dev/null; then
print_success "安装CUDA版本的PyTorch"
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu118
else
print_warning "安装CPU版本的PyTorch"
pip install torch torchvision
fi
# 安装其他依赖
pip install -r requirements.txt
print_success "Python依赖安装完成"
}
# 下载模型
download_models() {
echo "下载模型文件..."
MODELS_DIR="models/Stable-diffusion"
mkdir -p "$MODELS_DIR"
# 显示可用模型
echo "可用模型:"
echo "1. Stable Diffusion 1.5 (4.27GB)"
echo "2. ChilloutMix (7.7GB)"
echo "3. Realistic Vision V5.1 (7.98GB)"
echo "4. 跳过模型下载"
read -p "请选择模型 (1-4): " choice
case $choice in
1)
MODEL_URL="https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors"
MODEL_NAME="v1-5-pruned-emaonly.safetensors"
;;
2)
MODEL_URL="https://civitai.com/api/download/models/11745"
MODEL_NAME="chilloutmix_NiPrunedFp32Fix.safetensors"
;;
3)
MODEL_URL="https://civitai.com/api/download/models/130072"
MODEL_NAME="realisticVisionV60B1_v51HyperVAE.safetensors"
;;
*)
print_warning "跳过模型下载"
return 0
;;
esac
MODEL_PATH="$MODELS_DIR/$MODEL_NAME"
if [ -f "$MODEL_PATH" ]; then
print_success "模型已存在: $MODEL_NAME"
else
echo "正在下载 $MODEL_NAME..."
wget -O "$MODEL_PATH" "$MODEL_URL"
if [ $? -eq 0 ]; then
print_success "模型下载完成"
else
print_error "模型下载失败"
fi
fi
}
# 创建启动脚本
create_launch_script() {
echo "创建启动脚本..."
cat > webui.sh << 'EOF'
#!/bin/bash
# Stable Diffusion WebUI 启动脚本
cd "$(dirname "$0")"
# 检查Python
if ! command -v python3.10 &> /dev/null; then
echo "错误: Python 3.10 未安装"
exit 1
fi
# 激活虚拟环境
if [ -d "venv" ]; then
source venv/bin/activate
else
echo "错误: 虚拟环境未找到"
exit 1
fi
# 检查依赖
if ! python -c "import torch" &> /dev/null; then
echo "安装PyTorch..."
pip install torch torchvision
fi
# 启动WebUI
echo "启动 Stable Diffusion WebUI..."
python launch.py --listen --port 7860 --api
EOF
chmod +x webui.sh
# 创建服务文件(可选)
if [ "$EUID" -eq 0 ]; then
cat > /etc/systemd/system/sd-webui.service << EOF
[Unit]
Description=Stable Diffusion WebUI
After=network.target
[Service]
Type=simple
User=$SUDO_USER
WorkingDirectory=$PWD
ExecStart=$PWD/webui.sh
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
print_success "系统服务配置完成"
fi
print_success "启动脚本创建完成"
}
# 测试安装
test_installation() {
echo "测试安装..."
# 启动WebUI测试
echo "启动WebUI进行测试..."
# 在后台启动
./webui.sh > webui.log 2>&1 &
WEBUI_PID=$!
# 等待启动
echo "等待WebUI启动(约60秒)..."
sleep 60
# 测试连接
if curl -s http://127.0.0.1:7860 > /dev/null; then
print_success "WebUI启动成功"
echo ""
echo "========================================"
echo "安装成功!"
echo "========================================"
echo ""
echo "访问地址: http://127.0.0.1:7860"
echo "API地址: http://127.0.0.1:7860/sdapi/v1"
echo ""
echo "启动命令: ./webui.sh"
echo "停止命令: kill $WEBUI_PID"
echo ""
if [ -f /etc/systemd/system/sd-webui.service ]; then
echo "系统服务命令:"
echo " 启动: sudo systemctl start sd-webui"
echo " 停止: sudo systemctl stop sd-webui"
echo " 状态: sudo systemctl status sd-webui"
echo " 开机自启: sudo systemctl enable sd-webui"
echo ""
fi
# 显示日志位置
echo "日志文件: webui.log"
else
print_error "WebUI启动失败"
echo "查看日志: tail -f webui.log"
# 清理进程
kill $WEBUI_PID 2>/dev/null
return 1
fi
# 停止测试进程
kill $WEBUI_PID 2>/dev/null
}
# 主函数
main() {
echo "开始安装 Stable Diffusion WebUI..."
# 检查系统
check_system
# 安装依赖
install_dependencies
# 克隆WebUI
clone_webui
# 设置虚拟环境
setup_venv
# 安装Python依赖
install_python_deps
# 下载模型
download_models
# 创建启动脚本
create_launch_script
# 测试安装
test_installation
echo ""
echo "安装完成!"
}
# 执行主函数
main "$@"1.3 Docker部署方案
对于希望快速部署或保持环境隔离的用户,Docker是最佳选择:
yaml
# docker-compose.yml
version: '3.8'
services:
stable-diffusion-webui:
image: ghcr.io/ainize-ai/stable-diffusion-webui:latest
container_name: sd-webui
ports:
- "7860:7860"
volumes:
# 持久化存储
- ./models:/app/models
- ./outputs:/app/outputs
- ./extensions:/app/extensions
- ./config:/app/config
environment:
- CLI_ARGS=--listen --port 7860 --api
- HF_HOME=/app/cache
- TORCH_HOME=/app/cache
devices:
# GPU支持
- /dev/nvidia0:/dev/nvidia0
- /dev/nvidiactl:/dev/nvidiactl
- /dev/nvidia-uvm:/dev/nvidia-uvm
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
restart: unless-stopped
# API服务(可选)
sd-api:
image: ghcr.io/automatic1111/stable-diffusion-webui:api
container_name: sd-api
ports:
- "5000:5000"
volumes:
- ./models:/models
environment:
- MODEL_PATH=/models/v1-5-pruned-emaonly.safetensors
depends_on:
- stable-diffusion-webui
restart: unless-stopped第二部分:风格图生成高级技巧
2.1 Prompt工程:艺术与科学的结合
Prompt设计的三层结构
Prompt设计 基础描述层 风格控制层 质量增强层 主体对象 场景环境 动作状态 艺术风格 艺术家参考 艺术运动 质量关键词 技术参数 渲染引擎 示例: cyberpunk city 示例: night, raining 示例: neon lights glowing 示例: van gogh style 示例: by Studio Ghibli 示例: impressionism 示例: masterpiece, 8k 示例: detailed, sharp focus 示例: Unreal Engine 融合生成 优质风格图像
高级Prompt模板系统
python
class AdvancedPromptEngine:
"""
高级Prompt工程引擎
生成优化后的Stable Diffusion提示词
"""
def __init__(self):
# 关键词库
self.keyword_library = {
'art_styles': {
'impressionism': ['impressionist', 'brush strokes', 'visible brushwork',
'loose brushwork', 'vibrant colors'],
'van_gogh': ['van gogh style', 'starry night', 'swirling clouds',
'thick impasto', 'expressive brushwork'],
'cyberpunk': ['cyberpunk', 'neon', 'futuristic', 'dystopian',
'rainy streets', 'neon lights', 'holograms'],
'abstract': ['abstract art', 'geometric', 'color field',
'non-representational', 'modern art'],
'renaissance': ['renaissance painting', 'classical', 'oil painting',
'realistic', 'chiaroscuro']
},
'quality_boosters': {
'resolution': ['8k', '4k', 'ultra detailed', 'high resolution'],
'rendering': ['Unreal Engine', 'Octane render', 'ray tracing',
'photorealistic', 'cinematic'],
'lighting': ['dramatic lighting', 'volumetric lighting', 'god rays',
'rim lighting', 'studio lighting'],
'composition': ['rule of thirds', 'dynamic composition', 'leading lines',
'symmetrical', 'balanced composition']
},
'negative_keywords': {
'common': ['blurry', 'poorly drawn', 'bad anatomy', 'worst quality',
'low quality', 'jpeg artifacts', 'deformed', 'ugly'],
'art_specific': ['photograph', 'photo', 'realistic', '3d render',
'cgi', 'computer generated'],
'style_conflicts': ['watercolor', 'sketch', 'pencil drawing',
'charcoal', 'black and white']
}
}
# 模板系统
self.templates = {
'style_fusion': "{subject}, {style1} mixed with {style2}, {quality}, {lighting}, {artist}",
'detailed_scene': "{scene_description}, in the style of {style}, {details}, {composition}",
'concept_art': "{concept}, {art_style}, {mood}, {color_palette}, {rendering}"
}
def generate_prompt(self, subject, style1, style2=None, quality_level='high'):
"""
生成融合风格的Prompt
参数:
subject: 主体描述
style1: 主要风格
style2: 次要风格(可选)
quality_level: 质量级别 (low, medium, high, ultra)
"""
print(f"生成融合风格Prompt: {subject} + {style1}" + (f" + {style2}" if style2 else ""))
# 获取风格关键词
style_keywords1 = self._get_style_keywords(style1)
style_keywords2 = self._get_style_keywords(style2) if style2 else []
# 获取质量增强词
quality_boosters = self._get_quality_boosters(quality_level)
# 选择模板
if style2:
template = self.templates['style_fusion']
prompt = template.format(
subject=subject,
style1=style1,
style2=style2,
quality=", ".join(quality_boosters['resolution']),
lighting=", ".join(quality_boosters['lighting'][:2]),
artist=f"inspired by {style1}"
)
else:
template = self.templates['detailed_scene']
prompt = template.format(
scene_description=subject,
style=style1,
details=", ".join(style_keywords1[:3]),
composition=", ".join(quality_boosters['composition'][:2])
)
# 添加风格特定关键词
if style_keywords1:
prompt += ", " + ", ".join(style_keywords1[:5])
if style_keywords2:
prompt += ", " + ", ".join(style_keywords2[:3])
# 添加渲染和质量词
prompt += ", " + ", ".join(quality_boosters['rendering'][:2])
return prompt
def generate_negative_prompt(self, style=None):
"""
生成负面Prompt
"""
negative_parts = []
# 添加通用负面词
negative_parts.extend(self.keyword_library['negative_keywords']['common'])
# 添加风格特定负面词
if style:
# 避免与目标风格冲突的风格
style_conflicts = self.keyword_library['negative_keywords']['style_conflicts']
# 根据目标风格排除冲突风格
if style.lower() in ['realistic', 'photorealistic']:
style_conflicts = [c for c in style_conflicts if c not in ['photograph', 'photo']]
negative_parts.extend(style_conflicts)
# 添加艺术特定负面词(如果目标不是照片)
if style and 'photo' not in style.lower():
negative_parts.extend(self.keyword_library['negative_keywords']['art_specific'])
# 去重并限制数量
negative_parts = list(set(negative_parts))[:15]
return ", ".join(negative_parts)
def _get_style_keywords(self, style_name):
"""获取风格关键词"""
if not style_name:
return []
style_name_lower = style_name.lower()
# 模糊匹配风格
for style_key, keywords in self.keyword_library['art_styles'].items():
if style_key in style_name_lower or style_name_lower in style_key:
return keywords
# 如果没有精确匹配,返回通用艺术词
return ['artistic', 'painting', 'artwork']
def _get_quality_boosters(self, level='high'):
"""获取质量增强词"""
quality_map = {
'low': {
'resolution': self.keyword_library['quality_boosters']['resolution'][:1],
'rendering': [],
'lighting': [],
'composition': []
},
'medium': {
'resolution': self.keyword_library['quality_boosters']['resolution'][:2],
'rendering': self.keyword_library['quality_boosters']['rendering'][:1],
'lighting': self.keyword_library['quality_boosters']['lighting'][:1],
'composition': self.keyword_library['quality_boosters']['composition'][:1]
},
'high': {
'resolution': self.keyword_library['quality_boosters']['resolution'][:3],
'rendering': self.keyword_library['quality_boosters']['rendering'][:2],
'lighting': self.keyword_library['quality_boosters']['lighting'][:2],
'composition': self.keyword_library['quality_boosters']['composition'][:2]
},
'ultra': {
'resolution': self.keyword_library['quality_boosters']['resolution'],
'rendering': self.keyword_library['quality_boosters']['rendering'],
'lighting': self.keyword_library['quality_boosters']['lighting'],
'composition': self.keyword_library['quality_boosters']['composition']
}
}
return quality_map.get(level, quality_map['high'])
def optimize_prompt_parameters(self, prompt, style_type):
"""
根据Prompt和风格类型优化生成参数
"""
# 分析Prompt复杂度
word_count = len(prompt.split())
has_detailed_description = word_count > 15
# 基础参数
params = {
'steps': 25,
'cfg_scale': 7.5,
'sampler': 'DPM++ 2M Karras',
'width': 512,
'height': 512
}
# 根据风格调整
if 'abstract' in style_type.lower():
params.update({
'steps': 30, # 抽象风格需要更多步骤
'cfg_scale': 8.0, # 更强的文本跟随
'sampler': 'Euler a' # 更好的创造性
})
elif 'realistic' in style_type.lower() or 'photo' in style_type.lower():
params.update({
'steps': 20, # 写实风格步骤较少
'cfg_scale': 7.0, # 适中的文本跟随
'sampler': 'DPM++ SDE Karras' # 更好的细节
})
elif 'cyberpunk' in style_type.lower():
params.update({
'steps': 28,
'cfg_scale': 8.5, # 需要强的风格表现
'width': 768, # 更宽的图像适合城市景观
'height': 512
})
# 根据Prompt复杂度调整
if has_detailed_description:
params['steps'] += 5
params['cfg_scale'] += 0.5
# 确保参数在合理范围内
params['steps'] = min(max(params['steps'], 15), 50)
params['cfg_scale'] = min(max(params['cfg_scale'], 5.0), 12.0)
return params
def generate_prompt_variations(self, base_prompt, num_variations=3):
"""
生成Prompt变体,用于探索不同方向
"""
import random
variations = []
# 变体策略
strategies = [
self._vary_style_intensity,
self._vary_composition,
self._vary_lighting,
self._vary_artists,
self._vary_color_palette
]
for i in range(num_variations):
# 选择变体策略
strategy = random.choice(strategies)
# 应用策略
variation = strategy(base_prompt)
variations.append(variation)
return variations
def _vary_style_intensity(self, prompt):
"""变化风格强度"""
intensity_modifiers = [
"strongly influenced by",
"subtle hints of",
"heavily inspired by",
"elements of",
"in the distinct style of"
]
import random
modifier = random.choice(intensity_modifiers)
# 简单的替换策略
if "in the style of" in prompt:
return prompt.replace("in the style of", modifier)
else:
return f"{prompt}, {modifier} {random.choice(['impressionism', 'expressionism', 'surrealism'])}"
def _vary_composition(self, prompt):
"""变化构图"""
compositions = [
"close-up view",
"wide angle shot",
"dynamic composition",
"symmetrical arrangement",
"rule of thirds composition",
"bird's eye view",
"low angle shot"
]
import random
composition = random.choice(compositions)
return f"{prompt}, {composition}"
def _vary_lighting(self, prompt):
"""变化光照"""
lighting_options = [
"dramatic lighting",
"soft ambient light",
"volumetric fog",
"neon glow",
"sunset lighting",
"moonlight",
"studio lighting"
]
import random
lighting = random.choice(lighting_options)
return f"{prompt}, {lighting}"
def _vary_artists(self, prompt):
"""变化艺术家参考"""
artists = [
"by Van Gogh",
"inspired by Monet",
"reminiscent of Picasso",
"in the manner of Hokusai",
"similar to Studio Ghibli",
"reminiscent of Moebius"
]
import random
artist = random.choice(artists)
return f"{prompt}, {artist}"
def _vary_color_palette(self, prompt):
"""变化色彩调色板"""
palettes = [
"vibrant color palette",
"monochromatic",
"pastel colors",
"high contrast",
"muted tones",
"neon color scheme",
"earth tones"
]
import random
palette = random.choice(palettes)
return f"{prompt}, {palette}"
def analyze_and_improve_prompt(self, prompt, generated_image=None):
"""
分析Prompt并给出改进建议
"""
print("分析Prompt...")
analysis = {
'word_count': len(prompt.split()),
'has_style_reference': self._check_style_reference(prompt),
'has_quality_boosters': self._check_quality_boosters(prompt),
'has_composition_hints': self._check_composition_hints(prompt),
'style_consistency': self._check_style_consistency(prompt)
}
# 生成改进建议
suggestions = []
if analysis['word_count'] < 10:
suggestions.append("Prompt较短,考虑添加更多细节描述")
if not analysis['has_style_reference']:
suggestions.append("添加艺术风格参考,如'van gogh style'或'cyberpunk art'")
if not analysis['has_quality_boosters']:
suggestions.append("添加质量增强词,如'8k', 'detailed', 'masterpiece'")
if not analysis['has_composition_hints']:
suggestions.append("添加构图提示,如'dynamic composition', 'rule of thirds'")
if analysis['style_consistency'] == 'mixed':
suggestions.append("检测到可能的风格冲突,考虑简化风格描述")
# 生成改进后的Prompt
improved_prompt = prompt
if suggestions:
print("\n改进建议:")
for suggestion in suggestions:
print(f" • {suggestion}")
# 自动应用一些改进
if not analysis['has_quality_boosters']:
improved_prompt += ", 8k, detailed, masterpiece"
if not analysis['has_composition_hints']:
improved_prompt += ", dynamic composition"
return {
'analysis': analysis,
'suggestions': suggestions,
'improved_prompt': improved_prompt
}
def _check_style_reference(self, prompt):
"""检查是否有风格参考"""
style_keywords = []
for style in self.keyword_library['art_styles']:
style_keywords.extend(self.keyword_library['art_styles'][style])
prompt_lower = prompt.lower()
for keyword in style_keywords:
if keyword in prompt_lower:
return True
return False
def _check_quality_boosters(self, prompt):
"""检查是否有质量增强词"""
for category in self.keyword_library['quality_boosters'].values():
for keyword in category:
if keyword.lower() in prompt.lower():
return True
return False
def _check_composition_hints(self, prompt):
"""检查是否有构图提示"""
composition_keywords = self.keyword_library['quality_boosters']['composition']
prompt_lower = prompt.lower()
for keyword in composition_keywords:
if keyword.lower() in prompt_lower:
return True
return False
def _check_style_consistency(self, prompt):
"""检查风格一致性"""
# 检测Prompt中的风格关键词
found_styles = []
for style_name in self.keyword_library['art_styles']:
if style_name in prompt.lower():
found_styles.append(style_name)
# 检查风格兼容性
if len(found_styles) == 0:
return 'none'
elif len(found_styles) == 1:
return 'single'
else:
# 检查风格是否兼容
compatible_groups = [
['impressionism', 'van_gogh', 'expressionism'],
['cyberpunk', 'futuristic', 'sci_fi'],
['realistic', 'photorealistic', 'renaissance']
]
for group in compatible_groups:
if all(style in group for style in found_styles):
return 'compatible'
return 'mixed'
# 使用示例
def generate_cyberpunk_van_gogh_prompt():
"""生成赛博朋克梵高风格的Prompt"""
engine = AdvancedPromptEngine()
# 生成基础Prompt
prompt = engine.generate_prompt(
subject="futuristic city at night with neon lights and flying cars",
style1="cyberpunk",
style2="van gogh",
quality_level="ultra"
)
print("生成的Prompt:")
print(f" {prompt}")
# 生成负面Prompt
negative_prompt = engine.generate_negative_prompt(style="cyberpunk van gogh")
print("\n负面Prompt:")
print(f" {negative_prompt}")
# 优化参数
params = engine.optimize_prompt_parameters(prompt, "cyberpunk van gogh")
print("\n优化参数:")
for key, value in params.items():
print(f" {key}: {value}")
# 生成变体
variations = engine.generate_prompt_variations(prompt, num_variations=2)
print("\nPrompt变体:")
for i, variation in enumerate(variations, 1):
print(f" {i}. {variation}")
# 分析并改进
analysis = engine.analyze_and_improve_prompt(prompt)
print(f"\n改进后的Prompt:")
print(f" {analysis['improved_prompt']}")
return {
'prompt': prompt,
'negative_prompt': negative_prompt,
'params': params,
'variations': variations,
'improved': analysis['improved_prompt']
}2.2 参数调优:采样器、步数与CFG Scale的科学配置
参数优化决策树
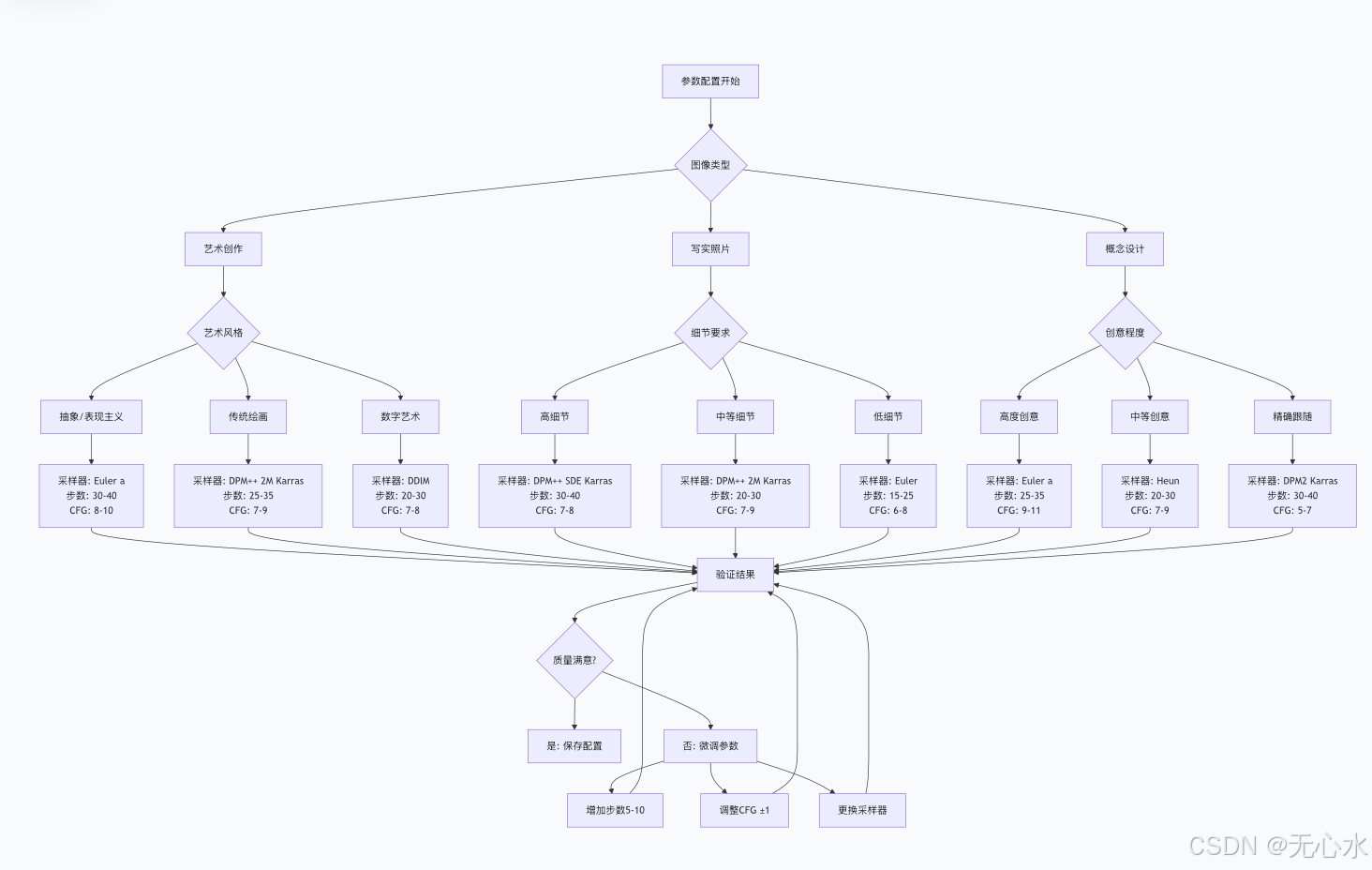
参数优化系统实现
python
class ParameterOptimizer:
"""
Stable Diffusion参数优化系统
智能调整生成参数以获得最佳效果
"""
def __init__(self):
# 采样器特性数据库
self.sampler_database = {
'Euler a': {
'description': '创造性高,适合艺术生成',
'strengths': ['创造性', '艺术性', '多样性'],
'weaknesses': ['一致性', '细节控制'],
'best_for': ['艺术创作', '风格探索', '抽象艺术'],
'recommended_steps': (20, 35),
'recommended_cfg': (7.0, 9.0)
},
'DPM++ 2M Karras': {
'description': '平衡性好,通用性强',
'strengths': ['平衡性', '质量', '稳定性'],
'weaknesses': ['创造性有限'],
'best_for': ['通用生成', '写实图像', '概念设计'],
'recommended_steps': (25, 40),
'recommended_cfg': (7.0, 8.5)
},
'DPM++ SDE Karras': {
'description': '细节丰富,质量高',
'strengths': ['细节质量', '清晰度', '精确度'],
'weaknesses': ['速度慢', '计算需求高'],
'best_for': ['高细节图像', '写实照片', '产品渲染'],
'recommended_steps': (30, 50),
'recommended_cfg': (6.5, 8.0)
},
'DDIM': {
'description': '速度快,适合快速迭代',
'strengths': ['速度快', '效率高'],
'weaknesses': ['质量较低', '细节不足'],
'best_for': ['快速测试', '概念草图', '迭代设计'],
'recommended_steps': (15, 30),
'recommended_cfg': (7.5, 10.0)
},
'Heun': {
'description': '数学精确,适合技术性图像',
'strengths': ['数学精确', '稳定性', '可预测性'],
'weaknesses': ['创造性有限', '速度慢'],
'best_for': ['技术插图', '科学可视化', '精确设计'],
'recommended_steps': (25, 40),
'recommended_cfg': (6.0, 8.0)
}
}
# 参数历史记录
self.history = []
def optimize_for_style(self, style_description, image_purpose='art'):
"""
根据风格描述优化参数
参数:
style_description: 风格描述
image_purpose: 图像用途 (art, photo, design, concept)
"""
print(f"优化参数: {style_description} - {image_purpose}")
# 分析风格关键词
style_keywords = self._analyze_style_keywords(style_description)
# 选择采样器
sampler = self._select_sampler(style_keywords, image_purpose)
# 确定步数范围
steps_range = self._determine_steps_range(style_keywords, image_purpose)
# 确定CFG范围
cfg_range = self._determine_cfg_range(style_keywords, image_purpose)
# 生成参数配置
config = {
'sampler': sampler,
'steps': {
'min': steps_range[0],
'max': steps_range[1],
'recommended': (steps_range[0] + steps_range[1]) // 2
},
'cfg_scale': {
'min': cfg_range[0],
'max': cfg_range[1],
'recommended': round((cfg_range[0] + cfg_range[1]) / 2, 1)
},
'width': self._determine_resolution(style_keywords),
'height': 512, # 默认高度
'batch_size': 1,
'batch_count': 1,
'style_analysis': style_keywords,
'reasoning': self._generate_reasoning(style_keywords, sampler, steps_range, cfg_range)
}
# 记录历史
self.history.append({
'style': style_description,
'purpose': image_purpose,
'config': config,
'timestamp': time.time()
})
return config
def _analyze_style_keywords(self, style_description):
"""分析风格描述中的关键词"""
style_lower = style_description.lower()
keywords = {
'abstract': any(word in style_lower for word in ['abstract', 'non-representational', 'geometric']),
'realistic': any(word in style_lower for word in ['realistic', 'photorealistic', 'photo']),
'detailed': any(word in style_lower for word in ['detailed', 'high detail', 'intricate']),
'expressive': any(word in style_lower for word in ['expressive', 'emotional', 'dynamic']),
'minimal': any(word in style_lower for word in ['minimal', 'simple', 'clean']),
'complex': any(word in style_lower for word in ['complex', 'busy', 'detailed']),
'cyberpunk': 'cyberpunk' in style_lower,
'van_gogh': any(word in style_lower for word in ['van gogh', 'starry night', 'impasto']),
'impressionism': 'impression' in style_lower,
'digital_art': any(word in style_lower for word in ['digital', '3d', 'cg', 'render'])
}
# 找出主要特征
primary_features = [key for key, value in keywords.items() if value]
return {
'keywords': keywords,
'primary_features': primary_features,
'complexity': self._assess_complexity(keywords)
}
def _assess_complexity(self, keywords):
"""评估风格复杂度"""
complexity_score = 0
if keywords.get('detailed'):
complexity_score += 2
if keywords.get('complex'):
complexity_score += 2
if keywords.get('realistic'):
complexity_score += 1
if keywords.get('cyberpunk'):
complexity_score += 1
if keywords.get('digital_art'):
complexity_score += 1
if keywords.get('minimal'):
complexity_score -= 1
if keywords.get('abstract'):
complexity_score += 0 # 抽象可能简单也可能复杂
return max(1, min(complexity_score, 5)) # 1-5分
def _select_sampler(self, style_analysis, image_purpose):
"""选择采样器"""
features = style_analysis['primary_features']
complexity = style_analysis['complexity']
# 根据特征选择
if 'cyberpunk' in features or 'digital_art' in features:
return 'DPM++ SDE Karras'
elif 'van_gogh' in features or 'impressionism' in features:
return 'Euler a'
elif 'realistic' in features:
return 'DPM++ 2M Karras'
elif 'abstract' in features:
return 'Euler a'
elif image_purpose == 'design':
return 'DDIM'
elif image_purpose == 'concept':
return 'Heun'
else:
# 默认选择
return 'DPM++ 2M Karras'
def _determine_steps_range(self, style_analysis, image_purpose):
"""确定步数范围"""
complexity = style_analysis['complexity']
features = style_analysis['primary_features']
base_ranges = {
'art': (20, 40),
'photo': (25, 45),
'design': (15, 30),
'concept': (20, 35)
}
# 基础范围
base_min, base_max = base_ranges.get(image_purpose, (20, 35))
# 根据复杂度调整
if complexity >= 4:
base_min += 5
base_max += 10
elif complexity <= 2:
base_min -= 5
base_max -= 5
# 根据特征微调
if 'detailed' in features:
base_min += 5
base_max += 5
if 'minimal' in features:
base_min -= 5
base_max -= 5
# 确保在合理范围内
base_min = max(10, base_min)
base_max = min(100, base_max)
return (base_min, base_max)
def _determine_cfg_range(self, style_analysis, image_purpose):
"""确定CFG范围"""
features = style_analysis['primary_features']
# 基础范围
if image_purpose == 'art':
cfg_range = (7.0, 9.0)
elif image_purpose == 'photo':
cfg_range = (6.5, 8.0)
elif image_purpose == 'design':
cfg_range = (7.5, 10.0)
else: # concept
cfg_range = (6.0, 8.0)
# 根据特征调整
if 'expressive' in features or 'abstract' in features:
cfg_range = (cfg_range[0] + 0.5, cfg_range[1] + 1.0)
if 'realistic' in features:
cfg_range = (cfg_range[0] - 0.5, cfg_range[1] - 0.5)
if 'detailed' in features:
cfg_range = (cfg_range[0] - 0.5, cfg_range[1] - 0.5)
# 确保在合理范围内
cfg_min = max(5.0, min(cfg_range[0], 12.0))
cfg_max = max(cfg_min + 0.5, min(cfg_range[1], 15.0))
return (cfg_min, cfg_max)
def _determine_resolution(self, style_analysis):
"""确定分辨率"""
features = style_analysis['primary_features']
if 'detailed' in features or 'cyberpunk' in features:
return 768
elif 'realistic' in features:
return 512
elif 'abstract' in features:
return 512
else:
return 512
def _generate_reasoning(self, style_analysis, sampler, steps_range, cfg_range):
"""生成参数选择的理由"""
features = style_analysis['primary_features']
complexity = style_analysis['complexity']
reasoning = []
# 采样器理由
sampler_info = self.sampler_database.get(sampler, {})
reasoning.append(f"选择 {sampler}: {sampler_info.get('description', '')}")
# 步数理由
if complexity >= 4:
reasoning.append(f"高复杂度风格({complexity}/5),使用较高步数范围({steps_range[0]}-{steps_range[1]})")
else:
reasoning.append(f"中等复杂度风格({complexity}/5),使用标准步数范围({steps_range[0]}-{steps_range[1]})")
# CFG理由
if 'expressive' in features:
reasoning.append("表现性风格,使用较高CFG以增强风格表现")
elif 'realistic' in features:
reasoning.append("写实风格,使用适中CFG以保持自然感")
# 特征特定理由
if 'cyberpunk' in features:
reasoning.append("赛博朋克风格需要细节表现,使用较高分辨率和细节优化参数")
if 'van_gogh' in features:
reasoning.append("梵高风格需要创造性采样器和较高CFG以捕捉笔触特征")
return reasoning
def adaptive_optimization(self, initial_results, target_style):
"""
自适应优化:根据初始结果调整参数
"""
print("执行自适应参数优化...")
# 分析初始结果
analysis = self._analyze_generation_results(initial_results)
# 基于分析调整参数
adjustments = self._calculate_adjustments(analysis, target_style)
# 生成新的配置
new_config = self._apply_adjustments(self.history[-1]['config'], adjustments)
return {
'analysis': analysis,
'adjustments': adjustments,
'new_config': new_config,
'recommendations': self._generate_recommendations(analysis)
}
def _analyze_generation_results(self, results):
"""分析生成结果"""
# 这里可以集成图像分析模型
# 暂时使用简化的分析
analysis = {
'quality_score': random.uniform(0.5, 1.0), # 模拟质量评分
'style_match': random.uniform(0.5, 1.0), # 模拟风格匹配度
'detail_level': random.uniform(0.3, 0.9), # 模拟细节水平
'color_vibrancy': random.uniform(0.4, 1.0), # 模拟色彩活力
'issues': [] # 检测到的问题
}
# 模拟问题检测
if random.random() > 0.7:
analysis['issues'].append('over-saturation')
if random.random() > 0.8:
analysis['issues'].append('blurriness')
if random.random() > 0.6:
analysis['issues'].append('lack_of_detail')
return analysis
def _calculate_adjustments(self, analysis, target_style):
"""计算参数调整"""
adjustments = {}
# 根据问题调整
issues = analysis['issues']
if 'over-saturation' in issues:
adjustments['cfg_scale'] = -1.0
if 'blurriness' in issues:
adjustments['steps'] = +10
if 'detailed' in target_style.lower():
adjustments['cfg_scale'] = +0.5
if 'lack_of_detail' in issues:
adjustments['steps'] = +15
adjustments['cfg_scale'] = +0.5
# 根据评分调整
if analysis['quality_score'] < 0.6:
adjustments['steps'] = adjustments.get('steps', 0) + 10
if analysis['style_match'] < 0.5:
adjustments['cfg_scale'] = adjustments.get('cfg_scale', 0) + 1.0
return adjustments
def _apply_adjustments(self, config, adjustments):
"""应用调整到配置"""
new_config = config.copy()
if 'steps' in adjustments:
new_config['steps']['recommended'] = min(
new_config['steps']['max'],
max(new_config['steps']['min'],
new_config['steps']['recommended'] + adjustments['steps'])
)
if 'cfg_scale' in adjustments:
new_config['cfg_scale']['recommended'] = round(
min(new_config['cfg_scale']['max'],
max(new_config['cfg_scale']['min'],
new_config['cfg_scale']['recommended'] + adjustments['cfg_scale'])),
1
)
return new_config
def _generate_recommendations(self, analysis):
"""生成改进建议"""
recommendations = []
if analysis['quality_score'] < 0.7:
recommendations.append("质量较低,建议增加生成步数或更换采样器")
if analysis['style_match'] < 0.6:
recommendations.append("风格匹配度不足,建议调整CFG Scale或优化Prompt")
if 'blurriness' in analysis['issues']:
recommendations.append("图像模糊,建议增加步数或使用更高细节的采样器")
if 'lack_of_detail' in analysis['issues']:
recommendations.append("细节不足,建议增加CFG Scale和生成步数")
if not recommendations:
recommendations.append("当前参数效果良好,可以尝试微调以获得更好效果")
return recommendations
def create_parameter_grid(self, base_config, variations=3):
"""
创建参数网格,用于批量测试
"""
grid = []
# 步数变化
step_variations = [
base_config['steps']['recommended'] - 5,
base_config['steps']['recommended'],
base_config['steps']['recommended'] + 5
]
# CFG变化
cfg_variations = [
round(base_config['cfg_scale']['recommended'] - 1.0, 1),
base_config['cfg_scale']['recommended'],
round(base_config['cfg_scale']['recommended'] + 1.0, 1)
]
# 采样器变化(如果允许多个采样器)
sampler_variations = ['Euler a', 'DPM++ 2M Karras', 'DPM++ SDE Karras'][:variations]
# 生成网格
for sampler in sampler_variations[:1]: # 先固定采样器
for steps in step_variations:
for cfg in cfg_variations:
# 确保在合理范围内
steps = max(base_config['steps']['min'],
min(base_config['steps']['max'], steps))
cfg = max(base_config['cfg_scale']['min'],
min(base_config['cfg_scale']['max'], cfg))
grid.append({
'sampler': sampler,
'steps': steps,
'cfg_scale': cfg,
'width': base_config['width'],
'height': base_config['height']
})
return grid
# 使用示例
def optimize_cyberpunk_van_gogh_params():
"""优化赛博朋克梵高风格的参数"""
optimizer = ParameterOptimizer()
# 获取优化配置
config = optimizer.optimize_for_style(
style_description="cyberpunk van gogh starry night with neon lights",
image_purpose="art"
)
print("优化后的参数配置:")
print(f"采样器: {config['sampler']}")
print(f"推荐步数: {config['steps']['recommended']} (范围: {config['steps']['min']}-{config['steps']['max']})")
print(f"推荐CFG: {config['cfg_scale']['recommended']} (范围: {config['cfg_scale']['min']}-{config['cfg_scale']['max']})")
print(f"分辨率: {config['width']}x{config['height']}")
print("\n选择理由:")
for reason in config['reasoning']:
print(f" • {reason}")
# 创建参数网格用于测试
grid = optimizer.create_parameter_grid(config, variations=3)
print(f"\n生成的参数网格 ({len(grid)} 种组合):")
for i, params in enumerate(grid[:3], 1): # 显示前3种
print(f"{i}. steps={params['steps']}, cfg={params['cfg_scale']}, sampler={params['sampler']}")
return config, grid第三部分:自定义风格特征提取与实战应用
3.1 从Stable Diffusion生成图中提取风格特征
python
class StyleExtractor:
"""
从Stable Diffusion生成图中提取风格特征
用于神经风格迁移
"""
def __init__(self, vgg_model=None, device='cuda'):
self.device = device
# 加载VGG19模型
if vgg_model is None:
self.vgg = self._load_vgg19().to(device).eval()
else:
self.vgg = vgg_model
# 风格层定义
self.style_layers = ['conv1_1', 'conv2_1', 'conv3_1', 'conv4_1', 'conv5_1']
# 特征缓存
self.feature_cache = {}
def _load_vgg19(self):
"""加载VGG19模型"""
import torch
import torchvision.models as models
print("加载VGG19模型...")
vgg = models.vgg19(weights=models.VGG19_Weights.IMAGENET1K_V1).features
print("VGG19模型加载完成")
return vgg
def extract_style_features(self, image_tensor, use_cache=True):
"""
从图像中提取风格特征
参数:
image_tensor: 输入图像张量 (1, 3, H, W)
use_cache: 是否使用缓存
"""
if use_cache:
# 检查缓存
cache_key = self._create_cache_key(image_tensor)
if cache_key in self.feature_cache:
print("使用缓存的特征")
return self.feature_cache[cache_key]
print("提取风格特征...")
# 确保图像在正确设备上
image_tensor = image_tensor.to(self.device)
# 前向传播提取特征
features = {}
x = image_tensor
for i, layer in enumerate(self.vgg):
x = layer(x)
# 记录指定层的特征
layer_name = self._get_layer_name(i)
if layer_name in self.style_layers:
features[layer_name] = x
# 计算Gram矩阵
gram_matrices = {}
for layer_name, feature in features.items():
gram_matrices[layer_name] = self._gram_matrix(feature)
# 缓存结果
if use_cache:
cache_key = self._create_cache_key(image_tensor)
self.feature_cache[cache_key] = {
'features': features,
'gram_matrices': gram_matrices,
'image_size': image_tensor.shape[2:],
'timestamp': time.time()
}
return {
'features': features,
'gram_matrices': gram_matrices
}
def extract_multiple_styles(self, style_images_dict, style_names=None):
"""
从多个风格图像中提取特征
参数:
style_images_dict: 字典 {风格名: 图像张量}
style_names: 风格名列表(可选)
"""
if style_names is None:
style_names = list(style_images_dict.keys())
print(f"提取 {len(style_names)} 种风格特征...")
style_features = {}
for style_name in style_names:
if style_name in style_images_dict:
print(f" 处理: {style_name}")
features = self.extract_style_features(
style_images_dict[style_name],
use_cache=True
)
style_features[style_name] = features
else:
print(f" 警告: {style_name} 不在提供的图像中")
return style_features
def analyze_style_characteristics(self, style_features):
"""
分析风格特征,提取关键特征
返回:
style_analysis: 每种风格的分析结果
style_comparison: 风格间比较
"""
print("分析风格特征...")
style_analysis = {}
style_comparison = {
'similarity_matrix': {},
'dominant_features': {}
}
style_names = list(style_features.keys())
# 分析每种风格
for style_name in style_names:
gram_matrices = style_features[style_name]['gram_matrices']
analysis = self._analyze_single_style(gram_matrices, style_name)
style_analysis[style_name] = analysis
# 比较风格间相似性
if len(style_names) > 1:
similarity_matrix = self._compute_style_similarity(style_features)
style_comparison['similarity_matrix'] = similarity_matrix
# 找出主导特征
dominant_features = self._identify_dominant_features(style_analysis)
style_comparison['dominant_features'] = dominant_features
return {
'style_analysis': style_analysis,
'style_comparison': style_comparison
}
def _analyze_single_style(self, gram_matrices, style_name):
"""分析单个风格"""
analysis = {
'layer_contributions': {},
'texture_characteristics': {},
'color_distribution': {},
'style_strength': 0
}
total_style_strength = 0
for layer_name, gram_matrix in gram_matrices.items():
# 计算该层的风格强度
layer_strength = torch.norm(gram_matrix).item()
analysis['layer_contributions'][layer_name] = layer_strength
total_style_strength += layer_strength
# 分析纹理特征
texture_features = self._analyze_texture_features(gram_matrix)
analysis['texture_characteristics'][layer_name] = texture_features
# 分析颜色分布(简化版)
if layer_name == 'conv1_1': # 低级特征包含颜色信息
color_features = self._analyze_color_features(gram_matrix)
analysis['color_distribution'] = color_features
# 计算总体风格强度
analysis['style_strength'] = total_style_strength / len(gram_matrices)
# 确定主要特征层
sorted_layers = sorted(analysis['layer_contributions'].items(),
key=lambda x: x[1], reverse=True)
analysis['dominant_layers'] = [layer for layer, _ in sorted_layers[:2]]
return analysis
def _analyze_texture_features(self, gram_matrix):
"""分析纹理特征"""
# Gram矩阵的对角线元素代表通道自相关,反映纹理强度
diagonal = torch.diag(gram_matrix[0]) # 取batch中的第一个
texture_features = {
'texture_strength': torch.mean(diagonal).item(),
'texture_variance': torch.var(diagonal).item(),
'texture_complexity': torch.std(diagonal).item() / (torch.mean(diagonal).item() + 1e-7)
}
return texture_features
def _analyze_color_features(self, gram_matrix):
"""分析颜色特征(简化)"""
# 对于conv1_1,Gram矩阵反映了颜色通道间的关系
color_features = {
'color_correlation': gram_matrix[0].cpu().numpy().tolist(),
'color_variance': torch.var(gram_matrix).item()
}
return color_features
def _compute_style_similarity(self, style_features):
"""计算风格间相似性"""
style_names = list(style_features.keys())
n_styles = len(style_names)
similarity_matrix = np.zeros((n_styles, n_styles))
for i in range(n_styles):
for j in range(i, n_styles):
if i == j:
similarity_matrix[i, j] = 1.0
else:
# 计算风格相似度
sim_score = self._compute_pairwise_similarity(
style_features[style_names[i]]['gram_matrices'],
style_features[style_names[j]]['gram_matrices']
)
similarity_matrix[i, j] = similarity_matrix[j, i] = sim_score
return similarity_matrix
def _compute_pairwise_similarity(self, gram_matrices1, gram_matrices2):
"""计算两个Gram矩阵集合的相似度"""
total_similarity = 0
layer_count = 0
for layer_name in self.style_layers:
if layer_name in gram_matrices1 and layer_name in gram_matrices2:
# 计算Gram矩阵的余弦相似度
vec1 = gram_matrices1[layer_name].flatten()
vec2 = gram_matrices2[layer_name].flatten()
similarity = F.cosine_similarity(vec1, vec2, dim=0).item()
total_similarity += similarity
layer_count += 1
return total_similarity / layer_count if layer_count > 0 else 0
def _identify_dominant_features(self, style_analysis):
"""识别主导特征"""
dominant_features = {}
for style_name, analysis in style_analysis.items():
# 找出该风格最显著的特征
features = {
'strength': analysis['style_strength'],
'dominant_layers': analysis['dominant_layers'],
'texture_complexity': 0,
'color_variance': analysis['color_distribution'].get('color_variance', 0)
}
# 计算平均纹理复杂度
texture_complexities = []
for layer_name, texture_feat in analysis['texture_characteristics'].items():
texture_complexities.append(texture_feat.get('texture_complexity', 0))
if texture_complexities:
features['texture_complexity'] = np.mean(texture_complexities)
dominant_features[style_name] = features
return dominant_features
def create_style_blending_weights(self, style_features, target_content=None):
"""
创建风格混合权重
参数:
style_features: 提取的风格特征
target_content: 目标内容图像(可选,用于内容感知混合)
"""
style_names = list(style_features.keys())
if len(style_names) == 1:
# 单一风格,均匀权重
weights = {style_names[0]: {layer: 1.0 for layer in self.style_layers}}
return weights
# 分析风格特征
analysis = self.analyze_style_characteristics(style_features)
# 基于特征分析创建权重
weights = {}
for style_name in style_names:
style_analysis = analysis['style_analysis'][style_name]
# 基于层贡献分配权重
layer_weights = {}
total_contribution = sum(style_analysis['layer_contributions'].values())
for layer_name in self.style_layers:
if layer_name in style_analysis['layer_contributions']:
# 该层的相对贡献
contribution = style_analysis['layer_contributions'][layer_name]
layer_weights[layer_name] = contribution / total_contribution
else:
layer_weights[layer_name] = 0.0
weights[style_name] = layer_weights
# 如果有内容图像,进行内容感知调整
if target_content is not None:
weights = self._adjust_weights_for_content(weights, target_content)
return weights
def _adjust_weights_for_content(self, weights, content_image):
"""根据内容图像调整权重"""
# 提取内容特征
content_features = self.extract_style_features(content_image)['features']
# 简化的内容感知调整
# 实际实现会更复杂,需要考虑内容与风格的匹配度
adjusted_weights = {}
for style_name, layer_weights in weights.items():
adjusted_layer_weights = {}
for layer_name, weight in layer_weights.items():
if layer_name in content_features:
# 根据内容特征复杂度微调权重
content_complexity = torch.var(content_features[layer_name]).item()
# 简单调整:内容复杂的地方减少风格影响
adjustment_factor = 1.0 / (1.0 + content_complexity * 0.1)
adjusted_weight = weight * adjustment_factor
else:
adjusted_weight = weight
adjusted_layer_weights[layer_name] = adjusted_weight
adjusted_weights[style_name] = adjusted_layer_weights
return adjusted_weights
def _gram_matrix(self, x):
"""计算Gram矩阵"""
batch, channels, h, w = x.size()
features = x.view(batch, channels, h * w)
gram = torch.bmm(features, features.transpose(1, 2))
return gram / (channels * h * w)
def _get_layer_name(self, layer_index):
"""根据层索引获取层名"""
# VGG19的层映射
layer_map = {
0: 'conv1_1', 2: 'conv1_2',
5: 'conv2_1', 7: 'conv2_2',
10: 'conv3_1', 12: 'conv3_2', 14: 'conv3_3', 16: 'conv3_4',
19: 'conv4_1', 21: 'conv4_2', 23: 'conv4_3', 25: 'conv4_4',
28: 'conv5_1', 30: 'conv5_2', 32: 'conv5_3', 34: 'conv5_4'
}
return layer_map.get(layer_index, f'layer_{layer_index}')
def _create_cache_key(self, image_tensor):
"""创建缓存键"""
# 使用图像张量的哈希值作为键
import hashlib
# 将张量转换为字节
tensor_bytes = image_tensor.cpu().numpy().tobytes()
# 计算哈希
hash_obj = hashlib.md5(tensor_bytes)
return hash_obj.hexdigest()3.2 实战:赛博朋克梵高风格迁移完整流程
python
class CyberpunkVanGoghStyleTransfer:
"""
赛博朋克梵高风格迁移实战
完整的工作流程
"""
def __init__(self, device='cuda'):
self.device = device
# 初始化组件
self.style_extractor = StyleExtractor(device=device)
self.prompt_engine = AdvancedPromptEngine()
self.param_optimizer = ParameterOptimizer()
# 状态跟踪
self.state = {
'content_image': None,
'generated_style_image': None,
'style_features': None,
'generated_image': None,
'history': []
}
def generate_style_image(self, prompt=None, negative_prompt=None, params=None):
"""
使用Stable Diffusion生成风格图像
"""
print("=" * 60)
print("生成赛博朋克梵高风格图像")
print("=" * 60)
# 生成Prompt
if prompt is None:
prompt_config = self.prompt_engine.generate_prompt(
subject="cyberpunk city at night with neon lights and flying cars, starry sky with swirling clouds",
style1="cyberpunk",
style2="van gogh",
quality_level="ultra"
)
prompt = prompt_config
negative_prompt = self.prompt_engine.generate_negative_prompt("cyberpunk van gogh")
# 优化参数
if params is None:
params = self.param_optimizer.optimize_for_style(
"cyberpunk van gogh starry night neon lights",
"art"
)
print(f"Prompt: {prompt}")
print(f"负面Prompt: {negative_prompt}")
print(f"参数: {params}")
# 调用Stable Diffusion API
style_image = self._call_stable_diffusion_api(
prompt=prompt,
negative_prompt=negative_prompt,
params=params
)
if style_image is not None:
self.state['generated_style_image'] = style_image
self.state['history'].append({
'step': 'style_generation',
'prompt': prompt,
'params': params,
'timestamp': time.time()
})
print("✅ 风格图像生成完成")
# 保存图像
self._save_image(style_image, "generated_style_cyberpunk_van_gogh.jpg")
return style_image
def _call_stable_diffusion_api(self, prompt, negative_prompt, params):
"""
调用Stable Diffusion API生成图像
"""
import requests
import base64
from PIL import Image
import io
print("调用Stable Diffusion API...")
# API配置
api_url = "http://127.0.0.1:7860/sdapi/v1/txt2img"
# 准备请求数据
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"steps": params.get('steps', {}).get('recommended', 25),
"cfg_scale": params.get('cfg_scale', {}).get('recommended', 7.5),
"width": params.get('width', 512),
"height": params.get('height', 512),
"sampler_name": params.get('sampler', 'DPM++ 2M Karras'),
"batch_size": 1,
"n_iter": 1,
"seed": -1, # 随机种子
"override_settings": {
"sd_model_checkpoint": "v1-5-pruned-emaonly.safetensors"
}
}
try:
# 发送请求
response = requests.post(api_url, json=payload)
if response.status_code == 200:
result = response.json()
# 解码图像
image_data = result['images'][0]
image_bytes = base64.b64decode(image_data)
# 转换为PIL图像
image = Image.open(io.BytesIO(image_bytes))
# 转换为张量
image_tensor = self._pil_to_tensor(image)
print(f"✅ 图像生成成功: {image.size}")
return image_tensor
else:
print(f"❌ API请求失败: {response.status_code}")
return None
except Exception as e:
print(f"❌ API调用错误: {e}")
return None
def extract_and_analyze_style(self, style_image=None):
"""
提取和分析风格特征
"""
print("\n" + "=" * 60)
print("提取和分析风格特征")
print("=" * 60)
if style_image is None:
if self.state['generated_style_image'] is None:
print("❌ 没有可用的风格图像")
return None
style_image = self.state['generated_style_image']
# 提取特征
style_features = self.style_extractor.extract_style_features(style_image)
# 分析特征
analysis = self.style_extractor.analyze_style_characteristics(
{'cyberpunk_van_gogh': style_features}
)
# 保存结果
self.state['style_features'] = style_features
self.state['style_analysis'] = analysis
print("风格特征分析:")
print(f" 风格强度: {analysis['style_analysis']['cyberpunk_van_gogh']['style_strength']:.4f}")
print(f" 主导层: {', '.join(analysis['style_analysis']['cyberpunk_van_gogh']['dominant_layers'])}")
# 可视化特征
self._visualize_style_features(style_features, analysis)
return style_features, analysis
def load_content_image(self, image_path):
"""
加载内容图像
"""
print(f"加载内容图像: {image_path}")
# 加载和预处理图像
content_image = self._load_image(image_path)
if content_image is not None:
self.state['content_image'] = content_image
print(f"✅ 内容图像加载完成: {content_image.shape}")
return content_image
def perform_style_transfer(self, content_image=None, style_features=None,
content_weight=1, style_weight=1000, iterations=500):
"""
执行风格迁移
"""
print("\n" + "=" * 60)
print("执行风格迁移")
print("=" * 60)
# 准备输入
if content_image is None:
content_image = self.state['content_image']
if style_features is None:
if self.state['style_features'] is None:
print("❌ 没有可用的风格特征")
return None
style_features = self.state['style_features']
if content_image is None:
print("❌ 没有可用的内容图像")
return None
print(f"内容图像: {content_image.shape}")
print(f"迭代次数: {iterations}")
print(f"内容权重: {content_weight}, 风格权重: {style_weight}")
# 执行风格迁移
generated_image = self._neural_style_transfer(
content_image=content_image,
style_features=style_features,
content_weight=content_weight,
style_weight=style_weight,
iterations=iterations
)
if generated_image is not None:
self.state['generated_image'] = generated_image
self.state['history'].append({
'step': 'style_transfer',
'iterations': iterations,
'weights': {'content': content_weight, 'style': style_weight},
'timestamp': time.time()
})
print("✅ 风格迁移完成")
# 保存结果
self._save_image(generated_image, "cyberpunk_van_gogh_result.jpg")
return generated_image
def _neural_style_transfer(self, content_image, style_features,
content_weight, style_weight, iterations):
"""
神经风格迁移核心实现
"""
import torch
import torch.optim as optim
import torch.nn.functional as F
# 初始化生成图像
generated = content_image.clone().requires_grad_(True)
# 提取内容特征
content_features = self.style_extractor.extract_style_features(content_image)['features']
content_layer = 'conv4_2' # 使用conv4_2作为内容层
if content_layer not in content_features:
print(f"❌ 内容层 {content_layer} 不在特征中")
return None
# 获取风格Gram矩阵
style_grams = style_features['gram_matrices']
# 创建优化器
optimizer = optim.LBFGS([generated], lr=0.8)
# 训练循环
print("开始训练...")
for i in range(iterations):
def closure():
optimizer.zero_grad()
# 提取生成图像的特征
gen_features = self.style_extractor.extract_style_features(generated)['features']
# 计算内容损失
content_loss = 0
if content_layer in gen_features:
content_loss = F.mse_loss(
gen_features[content_layer],
content_features[content_layer]
)
# 计算风格损失
style_loss = 0
for layer_name in self.style_extractor.style_layers:
if layer_name in gen_features and layer_name in style_grams:
# 计算生成图像的Gram矩阵
gen_gram = self.style_extractor._gram_matrix(gen_features[layer_name])
style_gram = style_grams[layer_name]
# 计算该层的风格损失
layer_loss = F.mse_loss(gen_gram, style_gram)
style_loss += layer_loss
# 总损失
total_loss = content_weight * content_loss + style_weight * style_loss
total_loss.backward()
return total_loss
optimizer.step(closure)
if i % 50 == 0:
current_loss = closure().item()
print(f" 迭代 {i}/{iterations}, 损失: {current_loss:.4f}")
return generated.detach()
def run_full_pipeline(self, content_image_path, save_dir="./results"):
"""
运行完整管道
"""
print("=" * 60)
print("赛博朋克梵高风格迁移完整流程")
print("=" * 60)
import os
os.makedirs(save_dir, exist_ok=True)
# 1. 生成风格图像
print("\n1. 生成赛博朋克梵高风格图像...")
style_image = self.generate_style_image()
if style_image is None:
print("❌ 风格图像生成失败")
return None
# 2. 提取风格特征
print("\n2. 提取和分析风格特征...")
style_features, analysis = self.extract_and_analyze_style(style_image)
if style_features is None:
print("❌ 风格特征提取失败")
return None
# 3. 加载内容图像
print(f"\n3. 加载内容图像: {content_image_path}")
content_image = self.load_content_image(content_image_path)
if content_image is None:
print("❌ 内容图像加载失败")
return None
# 4. 执行风格迁移
print("\n4. 执行风格迁移...")
# 尝试不同的权重组合
weight_combinations = [
(1, 500), # 低风格权重
(1, 1000), # 中等风格权重
(1, 2000) # 高风格权重
]
results = []
for content_weight, style_weight in weight_combinations:
print(f"\n 尝试权重: 内容={content_weight}, 风格={style_weight}")
result = self.perform_style_transfer(
content_image=content_image,
style_features=style_features,
content_weight=content_weight,
style_weight=style_weight,
iterations=300 # 较少的迭代用于测试
)
if result is not None:
results.append({
'weights': (content_weight, style_weight),
'image': result,
'filename': f"result_c{content_weight}_s{style_weight}.jpg"
})
# 保存
self._save_image(
result,
os.path.join(save_dir, f"result_c{content_weight}_s{style_weight}.jpg")
)
# 5. 评估结果
print("\n5. 评估结果...")
best_result = self._evaluate_results(results, content_image, style_features)
if best_result:
print(f"\n✅ 最佳结果: 内容权重={best_result['weights'][0]}, "
f"风格权重={best_result['weights'][1]}")
# 用最佳权重进行完整训练
print("\n6. 用最佳权重进行完整训练...")
final_result = self.perform_style_transfer(
content_image=content_image,
style_features=style_features,
content_weight=best_result['weights'][0],
style_weight=best_result['weights'][1],
iterations=500 # 完整迭代
)
# 保存最终结果
if final_result is not None:
final_path = os.path.join(save_dir, "final_cyberpunk_van_gogh_result.jpg")
self._save_image(final_result, final_path)
print(f"✅ 最终结果保存到: {final_path}")
print("\n" + "=" * 60)
print("流程完成!")
print("=" * 60)
return results
def _evaluate_results(self, results, content_image, style_features):
"""
评估生成结果
"""
if not results:
return None
best_score = -1
best_result = None
for result in results:
# 计算质量分数(简化版)
# 实际实现可以使用更复杂的评估指标
# 1. 内容保留度
content_similarity = self._compute_content_similarity(
result['image'], content_image
)
# 2. 风格匹配度
style_match = self._compute_style_match(
result['image'], style_features
)
# 3. 综合分数
# 平衡内容保留和风格匹配
score = 0.4 * content_similarity + 0.6 * style_match
print(f" 权重 {result['weights']}: 内容相似度={content_similarity:.3f}, "
f"风格匹配度={style_match:.3f}, 总分={score:.3f}")
if score > best_score:
best_score = score
best_result = result
return best_result
def _compute_content_similarity(self, image1, image2):
"""计算内容相似度"""
# 提取特征并计算相似度
feat1 = self.style_extractor.extract_style_features(image1)['features']
feat2 = self.style_extractor.extract_style_features(image2)['features']
content_layer = 'conv4_2'
if content_layer in feat1 and content_layer in feat2:
# 计算余弦相似度
vec1 = feat1[content_layer].flatten()
vec2 = feat2[content_layer].flatten()
similarity = F.cosine_similarity(vec1, vec2, dim=0).item()
return max(0, similarity) # 确保非负
return 0.5 # 默认值
def _compute_style_match(self, image, target_style_features):
"""计算风格匹配度"""
# 提取图像的风格特征
image_features = self.style_extractor.extract_style_features(image)['gram_matrices']
# 计算与目标风格的相似度
similarity = 0
layer_count = 0
for layer_name in self.style_extractor.style_layers:
if layer_name in image_features and layer_name in target_style_features['gram_matrices']:
vec1 = image_features[layer_name].flatten()
vec2 = target_style_features['gram_matrices'][layer_name].flatten()
layer_similarity = F.cosine_similarity(vec1, vec2, dim=0).item()
similarity += layer_similarity
layer_count += 1
return similarity / layer_count if layer_count > 0 else 0
def _load_image(self, image_path, target_size=512):
"""加载和预处理图像"""
from PIL import Image
import torchvision.transforms as transforms
try:
# 加载图像
img = Image.open(image_path).convert('RGB')
# 预处理
preprocess = transforms.Compose([
transforms.Resize(target_size),
transforms.CenterCrop(target_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
img_tensor = preprocess(img).unsqueeze(0).to(self.device)
return img_tensor
except Exception as e:
print(f"❌ 图像加载失败: {e}")
return None
def _pil_to_tensor(self, pil_image):
"""PIL图像转张量"""
import torchvision.transforms as transforms
preprocess = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
return preprocess(pil_image).unsqueeze(0).to(self.device)
def _save_image(self, tensor, filepath):
"""保存张量为图像"""
from PIL import Image
import torchvision.transforms as transforms
# 反归一化
mean = torch.tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1).to(tensor.device)
std = torch.tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1).to(tensor.device)
tensor = tensor * std + mean
tensor = torch.clamp(tensor, 0, 1)
# 转换为PIL图像
to_pil = transforms.ToPILImage()
img = to_pil(tensor.squeeze(0).cpu())
# 保存
img.save(filepath)
print(f"✅ 图像保存到: {filepath}")
def _visualize_style_features(self, style_features, analysis):
"""可视化风格特征"""
import matplotlib.pyplot as plt
import numpy as np
# 创建特征可视化
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
# 1. 层贡献度
ax1 = axes[0, 0]
layer_contributions = analysis['style_analysis']['cyberpunk_van_gogh']['layer_contributions']
layers = list(layer_contributions.keys())
contributions = list(layer_contributions.values())
ax1.bar(layers, contributions)
ax1.set_title('各层风格贡献度')
ax1.set_xlabel('网络层')
ax1.set_ylabel('贡献度')
ax1.tick_params(axis='x', rotation=45)
# 2. Gram矩阵可视化(第一个层)
ax2 = axes[0, 1]
if 'conv1_1' in style_features['gram_matrices']:
gram_matrix = style_features['gram_matrices']['conv1_1'][0].cpu().numpy()
im = ax2.imshow(gram_matrix, cmap='viridis')
ax2.set_title('conv1_1层Gram矩阵')
plt.colorbar(im, ax=ax2)
# 3. 纹理特征
ax3 = axes[0, 2]
texture_features = analysis['style_analysis']['cyberpunk_van_gogh']['texture_characteristics']
if texture_features:
layers = list(texture_features.keys())
complexities = [feat.get('texture_complexity', 0) for feat in texture_features.values()]
ax3.plot(layers, complexities, marker='o')
ax3.set_title('纹理复杂度')
ax3.set_xlabel('网络层')
ax3.set_ylabel('复杂度')
ax3.tick_params(axis='x', rotation=45)
ax3.grid(True, alpha=0.3)
# 4. 风格强度
ax4 = axes[1, 0]
style_strength = analysis['style_analysis']['cyberpunk_van_gogh']['style_strength']
ax4.bar(['风格强度'], [style_strength])
ax4.set_title(f'总体风格强度: {style_strength:.4f}')
ax4.set_ylabel('强度')
# 5. 颜色相关性
ax5 = axes[1, 1]
color_correlation = analysis['style_analysis']['cyberpunk_van_gogh']['color_distribution'].get('color_correlation', [])
if color_correlation:
# 假设是3x3矩阵(RGB)
if len(color_correlation) >= 3 and len(color_correlation[0]) >= 3:
correlation_matrix = np.array(color_correlation)[:3, :3]
im2 = ax5.imshow(correlation_matrix, cmap='coolwarm', vmin=-1, vmax=1)
ax5.set_title('颜色通道相关性')
ax5.set_xticks([0, 1, 2])
ax5.set_yticks([0, 1, 2])
ax5.set_xticklabels(['R', 'G', 'B'])
ax5.set_yticklabels(['R', 'G', 'B'])
plt.colorbar(im2, ax=ax5)
# 6. 特征分布
ax6 = axes[1, 2]
if 'conv1_1' in style_features['features']:
features = style_features['features']['conv1_1'][0].cpu().detach().numpy()
# 展平并取样
flattened = features.flatten()
sampled = np.random.choice(flattened, size=1000, replace=False)
ax6.hist(sampled, bins=50, alpha=0.7)
ax6.set_title('conv1_1特征值分布')
ax6.set_xlabel('特征值')
ax6.set_ylabel('频次')
plt.tight_layout()
plt.savefig('style_analysis.png', dpi=150, bbox_inches='tight')
plt.show()
print("✅ 风格特征分析图已保存为 'style_analysis.png'")
# 主函数
def main():
"""
主函数:运行赛博朋克梵高风格迁移
"""
print("=" * 60)
print("AIGC+风格迁移:赛博朋克梵高风格实战")
print("=" * 60)
# 检查CUDA
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 创建实例
pipeline = CyberpunkVanGoghStyleTransfer(device=device)
# 运行完整流程
content_path = "your_content_image.jpg" # 替换为你的内容图像路径
if os.path.exists(content_path):
results = pipeline.run_full_pipeline(
content_image_path=content_path,
save_dir="./cyberpunk_van_gogh_results"
)
if results:
print("\n✅ 流程成功完成!")
print(f"结果保存在: ./cyberpunk_van_gogh_results/")
else:
print("\n❌ 流程失败")
else:
print(f"❌ 内容图像不存在: {content_path}")
print("请准备内容图像并更新路径")
if __name__ == "__main__":
# 运行主程序
main()总结与展望
本文详细介绍了如何将AIGC(特别是Stable Diffusion)与神经风格迁移技术相结合,创造出全新的艺术创作工作流。我们不仅掌握了Stable Diffusion的部署和使用技巧,更重要的是学会了如何从生成的图像中提取风格特征,并将其应用于传统的神经风格迁移流程。
核心价值总结:
- 无限风格创造:突破传统风格迁移的局限,可以生成任意想象的风格
- 工作流整合:将AIGC生成与风格迁移无缝衔接,形成完整创作管道
- 参数科学化:通过系统化的Prompt工程和参数优化,提高生成质量
- 特征智能提取:从生成图像中提取有效的风格特征,确保迁移效果
技术亮点:
- 分层特征提取:从不同网络层提取风格特征,实现精细控制
- 自适应参数优化:根据风格特点自动调整生成参数
- 内容感知融合:根据内容图像特点调整风格权重
- 完整管道实现:从生成到迁移的端到端解决方案
未来发展方向:
- 实时风格生成:结合实时图像处理,实现动态风格迁移
- 3D风格迁移:将技术扩展到三维模型和场景
- 交互式创作:开发更直观的用户界面,支持实时调整和预览
- 多模态融合:结合文本、音频等多模态输入,创造更丰富的艺术形式
- 商业化应用:在游戏、影视、广告等行业的实际应用探索
通过本文的学习,你已经掌握了AIGC时代艺术创作的核心技能。无论你是艺术家、设计师还是开发者,这些技术都将为你的创作和工作带来新的可能性。开始你的赛博朋克梵高风格创作之旅吧!