三维重建【5】3D Gaussian Splatting:3R-GS论文解读
-
- [1. 原文](#1. 原文)
- [2. 译文](#2. 译文)
-
[三、相关工作(Related Work)](#三、相关工作(Related Work))
-
- [3.1 从图像估计相机姿态](#3.1 从图像估计相机姿态)
- [3.2 新视角合成(NVS)](#3.2 新视角合成(NVS))
- [3.3 联合NVS和姿态估计](#3.3 联合NVS和姿态估计)
-
- [4.1 概况](#4.1 概况)
- [4.2 基于MCMC的姿态优化](#4.2 基于MCMC的姿态优化)
- [4.3 基于MLP的全局位姿细化](#4.3 基于MLP的全局位姿细化)
- [4.4 免渲染几何约束](#4.4 免渲染几何约束)
- [4.5 最终训练目标](#4.5 最终训练目标)
-
- [5.1 虚拟环境搭建](#5.1 虚拟环境搭建)
- [5.2 数据集准备](#5.2 数据集准备)
- [5.3 训练](#5.3 训练)
-
论文地址: 3R-GS: Best Practice in Optimizing Camera Poses Along with 3DGS
-
原文github地址: 3R-GS: Best Practice in Optimizing Camera Poses Along with 3DGS
一、摘要(Abstract)
1. 原文
3D Gaussian Splatting (3DGS) has revolutionized neural rendering with its efficiency and quality, but like many novel view synthesis methods, it heavily depends on accurate camera poses from Structure-from-Motion (SfM) systems. Although recent SfM pipelines have made impressive progress, questions remain about how to further improve both their robust performance in challenging conditions (e.g., textureless scenes) and the precision of camera parameter estimation simultaneously. We present 3RGS, a 3D Gaussian Splatting framework that bridges this gap by jointly optimizing 3D Gaussians and camera parameters from large reconstruction priors MASt3R-SfM. We note that naively performing joint 3D Gaussian and camera optimization faces two challenges: the sensitivity to the quality of SfM initialization, and its limited capacity for global optimization, leading to suboptimal reconstruction results. Our 3R-GS, overcomes these issues by incorporating optimized practices, enabling robust scene reconstruction even with imperfect camera registration. Extensive experiments demonstrate that 3R-GS delivers high-quality novel view synthesis and precise camera pose estimation while remaining computationally efficient.
2. 译文
3D Gaussian Splatting以其效率和质量彻底革新了神经渲染,但与许多新型视图合成方法一样,它高度依赖于Structure-from-Motion(SfM)系统的精确相机姿态。尽管近期的SfM流程取得了显著进展,但如何同时进一步提高其在挑战性条件(例如无纹理场景)下的鲁棒性能和相机参数估计的精度仍然存在问题。本文提出3R-GS,一种3D Gaussian Splatting框架,它通过联合优化来自大型重建先验MASt3R-SfM的3D Gaussian和相机参数来弥补这一差距。我们注意到,只是天真地执行联合3D Gaussian和相机优化面临两个挑战:对SfM初始化质量的敏感性,以及其全局优化能力有限,导致重建结果不理想。本文提出的3R-GS通过结合优化实践克服了这些问题,即使在相机配准不完善的情况下也能实现稳健的场景重建。大量实验表明,3R-GS可以提供高质量的新颖视图合成和精确的相机姿态估计,同时保持计算效率。
二、前言(Introduction)
近几十年来,从2D图像构建3D表示一直是一个长期存在的研究挑战。最近,神经辐射场(NeRF)和3D高斯分布(3DGS)等方法已成为3D场景表示的强大方法,特别是对于新颖的视图合成。这些基于NeRF和3DGS的方法需要准确的相机参数来正确建立3D-2D投影关系,这项任务通常依赖于运动结构 (SfM) 技术(例如 COLMAP)。然而,SfM 过程通常非常耗时,有时对于具有无特征区域的场景或对象(例如室内环境)来说并不稳健,这使得它们不太可靠。
基于学习的前馈密集重建方法(例如 DUSt3R和MAST3R)的最新进展已经证明了大型模型在从未校准图像中推断 3D 结构方面的巨大潜力。它们比传统的SfM流程更强大,尤其是在纯旋转运动、无纹理区域和稀疏视图场景等具有挑战性的条件下。尽管有这些改进,但由于前馈范式的限制或过度简化的全局优化策略,这些基于3R的方法估计的相机姿势仍然缺乏完美的准确性。因此,这些缺陷可能会降低后续 3DGS 训练的性能,这需要具有像素级精度的相机姿势。
在本文中,我们引入了3R-GS,这是一种从 MASt3R 相机的不完美输出中重建高质量 3D 高斯表示的稳健方法。我们的方法建立在同时学习相机姿势和 3D 高斯表示的想法之上。然而,在不完美配准的相机帧上直接应用 3DGS 联合学习方法会带来一些挑战。
第一个挑战是对初始化的敏感性。训练 3DGS 需要先进的工程启发式方法,例如分割/克隆和不透明度重置,这需要大量的超参数调整。当相机姿势不完美时,联合优化很容易陷入局部最小值。最近的前馈密集重建方法(例如 DUSt3R 45)使这个问题变得更加严重。由于训练数据中存在高度模糊性,这些方法通常在背景区域生成精度较低的点云。
第二个挑战是低效的姿态优化。与 NeRF 类似的方法(使用光线行进以像素级精度进行渲染)不同,3DGS 缺乏在单个训练步骤中有效优化多个摄像机的内置机制。相反,3DGS 使用可微分光栅器,在每个训练步骤中,将所有点转换到相同的标准化设备坐标 (NDC) 空间,然后将它们投影、排序并渲染到图像空间上,从而生成全图像级渲染。虽然这种机制一次渲染大量像素,但所有像素都来自单个相机,这意味着优化每个训练步骤仅影响一个相机。相比之下,类似 NeRF 的方法可以更有效地优化相机,因为每个训练步骤都可以合并从多个相机渲染的像素。
为了解决第一个问题,我们建议采用 3DGS-MCMC 来增强针对不完美初始化的鲁棒性。我们将 3D 高斯视为从准确表示场景的分布中抽取的 MCMC 样本。通过状态转换,高斯基元被重新定位,帮助它们逃离局部极小值并提高收敛性。这减少了该方法对高质量点云和相机姿态初始化的依赖。此外,通过 3DGS-MCMC,我们消除了 3DGS 中启发式致密化和修剪策略的需要,消除了超参数微调的负担。
为了解决第二个问题,我们从 PoRF 和 ACE0 中汲取灵感,通过使用多层感知器 (MLP) 对相机姿势之间的相关性进行建模来改进相机姿势优化。具体来说,我们联合训练一个全局共享的 MLP 以及每个相机的嵌入来完善相机姿势。此外,为了进一步增强相机姿态优化,我们将极距损失作为几何约束来细化相机姿态。这种方法直接利用成对对应图像匹配来优化相机姿势。通过利用所有可用的成对对应关系,我们可以使用更直接的几何监督信号更好地优化相机姿势。据我们所知,我们的方法是第一个应用 MLP 位姿建模和极线损失来解决联合 3DGS 和相机位姿优化的独特挑战的方法。
总而言之,我们的贡献是:
- 我们提出了 3R-GS,这是一种从 MASt3R 不完美的输出相机重建高质量 3D 高斯和姿势的稳健方法;
- 提出一种有效的解决方案,结合3DGS-MCMC、基于 MLP 的姿态细化器和极距损失来解决定义的两个挑战;
- 我们的实验证明了 3R-GS 在新颖的视图合成和相机姿态估计方面的优越性能。
三、相关工作(Related Work)
3.1 从图像估计相机姿态
仅使用 RGB 图像稳健而准确地估计相机姿势是一项长期存在的基本挑战。根据图像是以有序还是无序序列捕获的,可以采用运动结构 (SfM) 或同时定位和建图 (SLAM) 等方法来实现精确的姿态估计。
在本文中,我们主要关注无序设置,例如运动结构方法。传统的 SfM 方法,例如 COLMAP ,是一个很长的流程,涉及特征匹配、相机配准和捆绑调整等多个阶段,非常复杂,并且对于无纹理区域和纯旋转等一些具有挑战性的情况来说不稳健。最近基于学习的稀疏特征提取和匹配方法试图改进传统的特征匹配,但其鲁棒性仍有改进的空间。与复杂的流程不同,DUSt3R 及其变体等最新方法已经证明了使用大型模型直接预测 3D 结构的能力。然而,尽管它们具有鲁棒性,但这些方法缺乏像素级精度,这导致下游重建结果不理想。
3.2 新视角合成(NVS)
新颖的视图合成,顾名思义,旨在利用输入图像从看不见的视点生成图像。这种能力在虚拟现实、远程呈现等应用中至关重要。近年来,神经辐射场(NeRF)和3D高斯溅射(3DGS)极大地提高了新颖视图合成的质量,实现了逼真的结果。特别是,类 3DGS 方法由于其清晰、明确的表示和实时渲染能力,最近一直处于 NVS 研究的前沿。人们已经提出了 3DGS 的几种变体,每种变体都针对问题的特定方面,例如大规模重建方法、前馈模型、表面重建以及处理反射物体的方法。然而,这些 NVS 方法通常依赖于通过 SfM 流程获得的密集、准确的相机位姿。当输入相机姿势不准确时,合成视图中可能会出现未对准和伪影。
3.3 联合NVS和姿态估计
为了解决上述依赖已知相机姿态的挑战,最近的方法集成了姿态优化,设计了用于联合相机姿态估计和 NVS 的端到端框架。例如,郭等人提出了一种两阶段网络,直接从 6-DoF 相机姿态合成新颖的视图,解耦几何映射和纹理渲染,以增强针对可变操作条件的鲁棒性。
NeRF 的早期工作试图消除这种要求。其中,NeRFmm 通过经验性的两阶段流程演示了相机参数和 NeRF 参数的联合优化。相比之下,BARF 在基于坐标的场景表示上引入了从粗到细配准的单一过程。 GARF 和 48 采用特殊的激活函数,分别缓解了 NeRFmm 中的高频位置编码和系统次优问题。 NoPe-NeRF采用额外的单视图深度估计来提供强大的几何线索。 SPARF、SC-NeRF和 PoRF在联合优化中结合了图像对应。尽管取得了令人印象深刻的结果,但这些方法仅限于前向场景或具有简单轨迹的短视频剪辑。此外,NeRF 表示使得这些方法收敛缓慢。
最近的研究已将重点从 NeRF 转移到 3DGS,因为它可以实现实时渲染、提高渲染质量和更快的训练速度。在联合 NVS 和姿态估计的范围内,CF-3DGS和 39 假设顺序视频帧输入并以顺序方式处理帧,逐步训练 3DGS。 InstantSplat 利用 DUSt3R进行相机姿势初始化,但仅限于很少的图像。 ZeroGS利用预训练模型作为数字场景表示,能够从数百个未摆姿势和无序图像中训练 3DGS。然而,它们也具有渐进式训练的特点,并且需要一个两阶段的收敛策略。 BAD-Gaussian和 10 也在训练 3DGS 中考虑相机优化,但重点关注解决运动模糊问题。
我们的工作很大程度上受到 NeRF 开创性工作的启发。例如,PoRF 和 ACE0 引入了 MLP 位姿细化器,SC-NeRF 和 PoRF 也使用了极距损失函数。然而,与它们不同的是,我们使用这些方法来有效地处理捆绑调整 3DGS 中的独特问题。与 3DGS 中的渐进式方法相比,我们的方法只需稍微修改标准 3DGS 训练流程,开销可以忽略不计,并且可以应用于短视频剪辑和完整视频序列。
四、方法(Method)
4.1 概况
给定在具有挑战性的场景中在未知姿势下捕获的一组图像,我们的目标是重建高质量的 3D 高斯表示和准确的相机姿势。现有的 3D 高斯重建方法严重依赖于准确的相机姿态------通常从传统的运动结构技术(例如 COLMAP)作为输入获得,并且通常在无纹理的室内环境等场景中遇到困难。
为此,我们建立在融合大型重建先验的最新技术的基础上,具体来说,我们采用 MASt3R-SfM来稳健地估计相机姿势。
虽然 MASt3R-SfM 在各种条件下的鲁棒性方面优于 COLMAP 等传统 SfM 方法,但由于缺乏像素级精度,其估计的相机位姿仍然不完善,这给下游 3DGS 重建带来了挑战。我们的 3RGS 是一个联合 3DGS 和相机的学习框架,来自 MASt3R-SfM,旨在解决上述问题。然而,在 3DGS 训练期间天真地优化不完美的相机姿势只会带来有限的改进,引入两个挑战:对初始化的敏感性和低效的姿势优化,如简介中所述。
为了应对这些挑战,我们引入:(1)利用马尔可夫链蒙特卡罗的稳健姿态细化策略,(2)使用基于 MLP 的细化器的全局相机相关模型,以及(3)基于极线损失的免渲染几何约束。
4.2 基于MCMC的姿态优化
动机: Vanilla 3DGS 优化对初始化高度敏感,因为高斯基元的适应性有限并且依赖于准确的初始点云。例如,如图 3(a) 所示,如果由于初始化不完善,高斯基元最初放置得稍微远离其理想位置,它可能很难自我纠正。发生这种情况是因为光度渲染损失仅在较小的局部区域内提供梯度,使得图元很难逃脱局部最优并到达正确的位置。因此,不良的初始化可能会导致收敛不佳和场景重建质量下降。
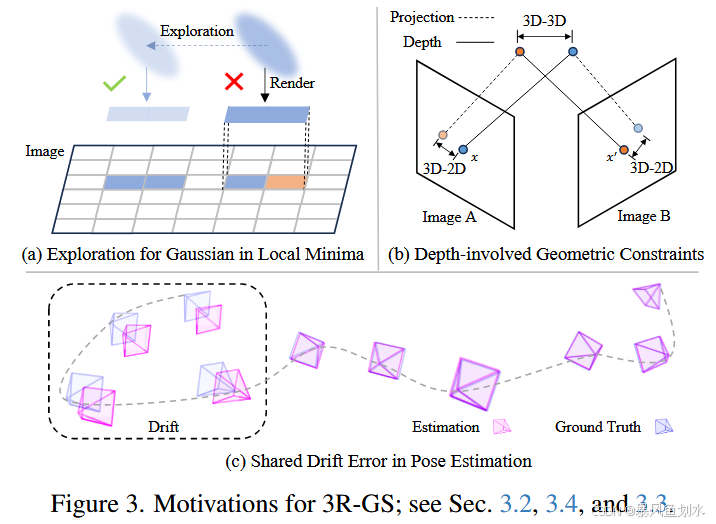
此外,3DGS 中的自适应密度控制取决于基于梯度幅度的阈值,这在引入新的训练目标时需要手动调整或调整致密化策略。这种依赖不仅使优化变得复杂,而且在与 3DGS 联合优化相机姿势时也带来了额外的挑战。
解决方案: 我们采用 3DGS-MCMC,通过将 3D 高斯分布重新表述为马尔可夫链蒙特卡罗 (MCMC) 采样来提高初始化的鲁棒性。该方法将训练过程阐述为对分布 p ( G ) p(G) p(G)的采样过程,此分布会为那些能精准重建训练图像的高斯集合分配较高的概率。研究表明,标准的3DGS优化过程与随机梯度之万动力学更新具有相似性:
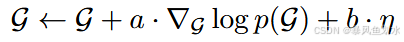
其中 η \eta η 为探索噪声(在优化或采样过程中引入的随机性扰动,用于避免模型陷入局部最优,确保对解空间的充分探索),参数 a a a和 b b b用于平衡收敛性与探索能力。借助该噪声,即可实现图 3 (a) 所示的探索效果。此外,3DGSMCMC 方法摒弃了基于启发式规则的高斯体增密与剪枝策略,转而采用原理明确的状态转移过程取而代之。我们还引入了该方法中的正则化项,以此促使模型以精简的方式使用高斯体。
通过 3DGS-MCMC,我们实现了相机位姿和 3DGS 的鲁棒联合优化,解决了"初始化敏感性"问题。在下面的部分中,我们将介绍两种技术来解决"低效姿势优化"的挑战。
4.3 基于MLP的全局位姿细化
动机: 在实践中,多个摄像机经常共享共同的漂移误差------虽然它们的相对位姿可能是正确的,但它们共同偏离地面实况,具有共享的旋转和平移误差,如图 3© 所示。然而,直接优化各个相机位姿将它们视为独立的,这可能会扭曲原本正确的局部相对位姿,并由于问题固有的非凸性而使优化更容易出现局部极小值。
解决方案: 我们引入了一种基于 MLP 的全局姿态细化器,它学习从潜在相机表示中预测姿态修正量 Δ T i \Delta T_i ΔTi:
Δ T i = R M L P ( z i ) ΔT i =RMLP(z i ) ΔTi=RMLP(zi)
其中 z i z_i zi是一个可学习的相机嵌入向量,会与 MLP 精修器联合优化。位姿修正量包含平移 Δ t i ∈ R 3 \Delta t_i \in \mathbb{R}^3 Δti∈R3和旋转 Δ r i ∈ R 6 \Delta r_i \in \mathbb{R}^6 Δri∈R6两个分量。为保证精修过程的稳定性,我们为该 MLP 初始化了零均值先验。该方法通过在所有视角间共享一个 MLP,实现了对全局位姿关联关系的建模,从而能够更精准地完成相机位姿调整。在实际应用中,其效果显著优于直接对单个相机位姿进行优化的方案。
4.4 免渲染几何约束
动机: 除了前面提到的导致相机优化效率低下的因素之外,另一个问题是仅仅依靠渲染损失缺乏对相机姿势的直接几何监督。实施直接几何监督的一种直接方法是使用基于对应的几何损失。我们注意到 MASt3R-SfM 提供了匹配对应关系,这可以用于我们的几何优化。具体而言,MASt3R-SfM 构建了一个稀疏场景图 G = ( V , E ) G=(V,E) G=(V,E),其中每个顶点 I ∈ V I \in V I∈V代表一张图像,每条边 e = ( n , m ) ∈ E e=(n,m)\in E e=(n,m)∈E则表示两幅大概率存在重叠区域的图像 I n I_n In与 I m I_m Im之间的无向连接关系。基于该场景图,MASt3R-SfM 进一步计算出图像间的匹配对应关系 M n , m M_{n,m} Mn,m。
为了利用这些对应关系,常见的选择包括 3D-2D 投影损失和 3D-3D 损失,两者都依赖于深度,如图 3(b) 所示。 3D-3D 损失通过使用深度和相机参数将图像对中的对应点反向投影到 3D 空间来计算图像对中对应点之间的距离; 3D-2D 损失将这些 3D 点重新投影到图像平面上,以计算与其对应的 2D 距离。这些方法通常需要多个图像对来模拟全局捆绑调整,以确保梯度更加一致。然而,将这些优化目标集成到 3DGS 训练中会带来重大挑战,主要是因为 3DGS 采用透视深度排序进行渲染(RGB 和深度),并且需要数万次迭代进行训练。这种计算限制严重限制了每个步骤中可以处理的视图数量。合并额外的视图会大大增加训练时间和内存消耗到令人望而却步的水平。因此,在应用上述几何约束时,每个步骤只能考虑图像对的子集,从而阻止执行真正的全局目标并最终导致次优结果。
解决方案: 我们提出了一种基于极线距离的无渲染全局几何约束方法。给定由 MASt3R-SfM 得到的图像匹配对应关系 M n , m M_{n,m} Mn,m,我们将损失函数定义为:
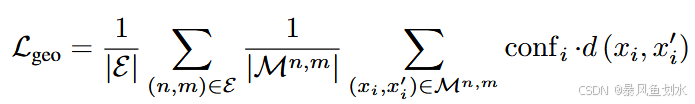
其中 conf i \text{conf}_i confi是 MASt3R 为匹配对 ( x , x ′ ) (x,x') (x,x′)提供的置信度, d ( x i , x i ′ ) d(x_i,x'_i) d(xi,xi′)是基于基础矩阵F计算得到的对称极线距离,而该基础矩阵F由相机位姿与内参推导而来。不同于 PoRF 方法,我们在每次训练迭代中,都会纳入 MASt3R-SfM 构建的图中所有图像对 ( n , m ) ∈ E (n,m)\in E (n,m)∈E的匹配对应关系。这一设计使得相机位姿的联合优化能够纳入更多全局信息,从而提升优化精度。尽管 MASt3R-SfM 可为每对图像提供数千组匹配对应关系,但我们通过实验发现,仅需数百组匹配对即可满足需求,因此我们对这些匹配对进行了均匀下采样。
4.5 最终训练目标
我们的完整训练目标函数,整合了原始 3D 高斯泼溅(3DGS)的渲染损失、源自 3DGS-MCMC 方法的额外正则化项,以及公式中提出的几何约束损失 L g e o L_{geo} Lgeo。
L t o t a l = L o r i g + λ g e o ⋅ L g e o + L r e g L_{total}=L_{orig} +λ_{geo} ⋅L_{geo}+L_{reg} Ltotal=Lorig+λgeo⋅Lgeo+Lreg
完整的总损失函数由三部分构成:原始损失、几何约束损失与正则化损失。
五、本地数据集训练
5.1 虚拟环境搭建
python
conda create --name 3rgs python=3.11 -y
conda activate 3rgs
conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia -y
pip install -r requirements.txt5.2 数据集准备
按照论文中的描述,本文的数据集准备依赖于MASt3R,具体步骤如下:
1)Clone MASt3R
python
git clone --recursive https://github.com/naver/mast3r
cd mast3r2)Create the environment
python
conda create -n mast3r python=3.11 cmake=3.14.0
conda activate mast3r
conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia
pip install -r requirements.txt
pip install -r dust3r/requirements.txt
pip install -r dust3r/requirements_optional.txt3)compile and install ASMK
python
pip install cython
git clone https://github.com/jenicek/asmk
cd asmk/cython/
cythonize *.pyx
cd ..
pip install . # or python3 setup.py build_ext --inplace
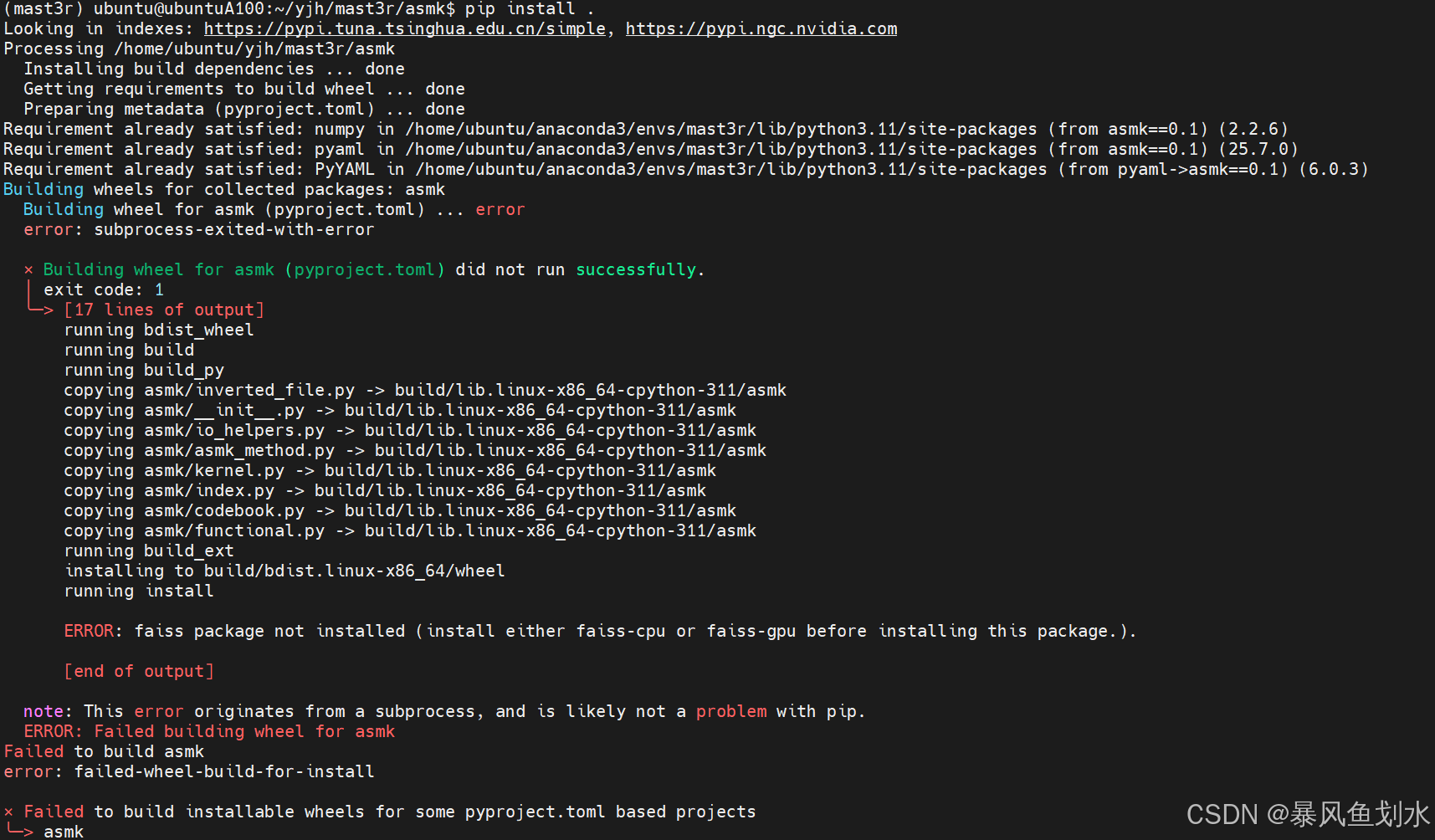
cd ..注意: 在安装ASMK时出现如下问题:
解决方案:
conda activate mast3r
pip install setuptools wheel cython -i https://pypi.tuna.tsinghua.edu.cn/simple
cd /home/ubuntu/yjh/mast3r/asmk
python setup.py install --force
4)预训练权重下载与demo执行
预训练权重下载:MASt3R_ViTLarge_BaseDecoder_512_catmlpdpt_metric
执行:python demo.py --weights ./checkpoints/MASt3R_ViTLarge_BaseDecoder_512_catmlpdpt_metric.pth
打开网页端,上传图像并运行:
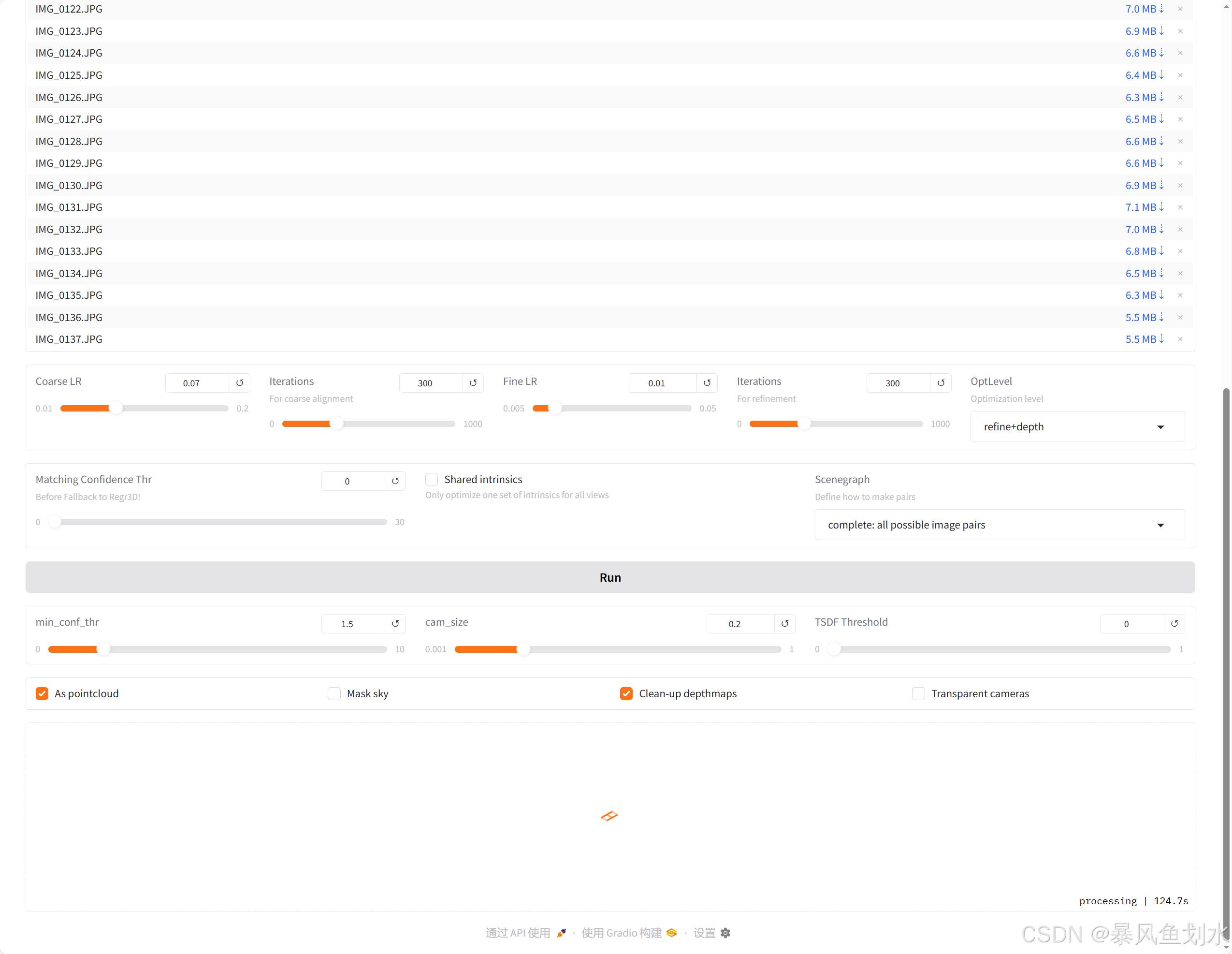
输出如下:

5)生成3rgs所需的数据
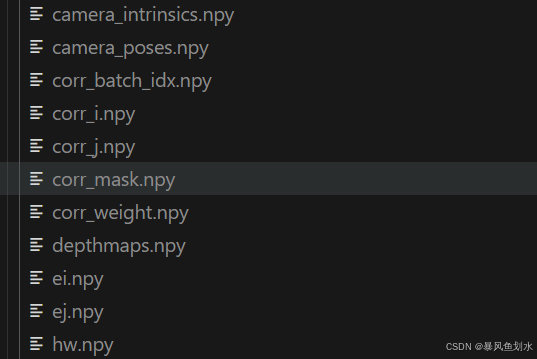
根据作者在github中的回答,其所需的mast3r所需的数据如下,需编写代码生成:

基于本地数据生成的文件如下:
5.3 训练
在训练时,我遇到了问题,目前分析看来是数据集准备与作者不同,但我暂时未找到区别,先记录一下,后续进行补充修改。(如果有哪位已实现本地数据集训练,请指教!!!)