视觉Transformer实战 | Pooling-based Vision Transformer(PiT)详解与实现
-
- [0. 前言](#0. 前言)
- [1. PiT 技术原理](#1. PiT 技术原理)
-
- [1.1 核心思想](#1.1 核心思想)
- [1.2 与传统 ViT 对比](#1.2 与传统 ViT 对比)
- [2. PiT 网络架构](#2. PiT 网络架构)
- [3. 使用 PyTorch 实现 PiT](#3. 使用 PyTorch 实现 PiT)
-
- [3.1 模型构建](#3.1 模型构建)
- [3.2 模型训练](#3.2 模型训练)
- 相关链接
0. 前言
Vision Transformer (ViT)在计算机视觉领域取得了巨大成功,但标准的 ViT 架构在处理不同尺度的视觉特征时存在一定局限性。Pooling-based Vision Transformer (PiT) 通过引入池化操作来改进 ViT 架构,使其能够更有效地处理多尺度特征,同时减少计算复杂度。本节将详细介绍 PiT 的技术原理,并使用 PyTorch 从零开始实现 PiT 模型。
1. PiT 技术原理
1.1 核心思想
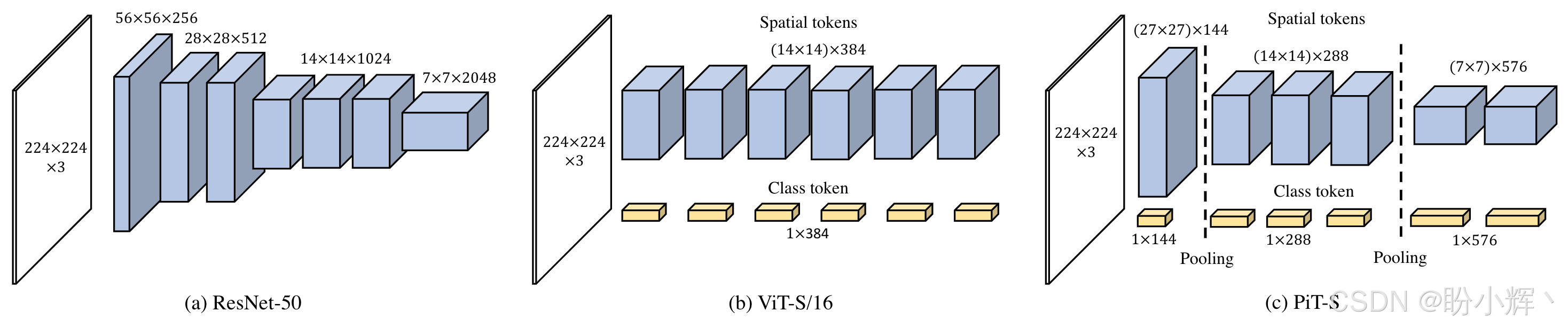
PiT 的核心创新点在于将卷积神经网络 (Convolutional Neural Network, CNN) 的金字塔结构设计思想引入 Pooling-based Vision Transformer (PiT) ,通过动态调整空间分辨率和通道维度,实现更高效的多尺度特征提取。PiT 架构如下所示,其核心思想具体体现在以下三个方面:
- 空间池化层 (
Pooling Layer) 的引入:传统ViT的token数量在全程保持固定(即图像分割后的patch数量不变),而PiT在Transformer块之间插入空间池化层,逐步减少token数量(即降低空间分辨率)。例如,输入图像经patch embedding后生成14×14的token序列,通过池化可逐步降为7×7、4×4等 - 通道维度的动态扩展:随着空间分辨率的降低,
PiT逐步增加每个token的通道维度(特征深度),形成类似CNN的"金字塔结构"(如ResNet的通道数随层数增加),这种设计平衡了计算开销与特征表达能力 - 多尺度特征融合:通过分层降低空间分辨率,
PiT在不同尺度下捕获特征,浅层保留细节信息(高分辨率),深层提取语义信息(低分辨率),这种结构与CNN的层次化特征提取机制一致,更适合视觉任务
1.2 与传统 ViT 对比
ViT 模型使用固定 token 数量,缺乏多尺度建模能力,可能丢失局部细节。ViT 在第一个嵌入层将图像按块 (patch) 划分,并将其嵌入到 token 中。该结构不包括空间缩减层,并且在网络的整个层中保持相同数量的空间 token。虽然自注意操作不受空间距离的限制,但参与注意的空间区域的大小受特征的空间大小的影响。
PiT 模型通过池化实现层级结构,更高效地处理不同尺度的视觉模式。由于 ViT 以 2D 矩阵而不是 3D 张量的形式处理神经元响应,因此池化层应该分离空间 token 并将它们重塑为具有空间结构的 3D 张量。在整形之后,通过深度卷积来执行空间大小减小和通道增加。
2. PiT 网络架构
PiT 的完整架构由以下关键组件构成:
Patch Embedding:输入图像被分割为固定大小的非重叠patch(如16×16像素),每个patch通过线性投影(全连接层)映射为token,初始通道维度为 C 1 C_1 C1,例如:224×224图像 →14×14个patch→196个token,每个token维度为 C 1 C_1 C1Pooling Transformer Block,每个Block包含两个核心操作:Transformer层使用多头自注意力 (Multi-head Self Attention,MSA) 和MLP层,结构与标准ViT一致,但增加了深度可分离卷积;空间池化层 (Pooling) 在特定阶段对token序列进行空间池化。假设当前token排列为 H × W × C H×W×C H×W×C,池化窗口为 k × k k×k k×k,则输出分辨率降为 H k × W k \frac Hk×\frac Wk kH×kW,通道数扩展至 k 2 C k^2C k2C (通过调整MLP实现),池化操作通常采用平均池化或最大池化,论文中采用深度可分离卷积 (Depth-wise Convolution) 实现,兼顾位置信息保留与计算效率Depth-wise Convolution的位置编码:PiT摒弃了ViT的固定位置编码,改用深度可分离卷积 (3×3卷积,分组数为通道数)隐式编码位置信息,该卷积应用于每个Transformer块的MLP之前,增强局部性建模能力(类似CNN的局部感受野)- 分类头 (
Classifier Head):最终阶段的token序列通过全局平均池化 (Global Average Pooling,GAP) 压缩为 1 × 1 × C n 1×1×C_n 1×1×Cn,然后接全连接层输出分类结果
3. 使用 PyTorch 实现 PiT
3.1 模型构建
(1) 首先,导入所需库:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange(2) 实现深度可分离卷积,用于位置编码:
python
class DepthWiseConv2d(nn.Module):
def __init__(self, dim_in, dim_out, kernel_size, padding, stride, bias=True):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(dim_in, dim_in, kernel_size=kernel_size, padding=padding,
groups=dim_in, stride=stride, bias=bias),
nn.BatchNorm2d(dim_in),
nn.Conv2d(dim_in, dim_out, kernel_size=1, bias=bias)
)
def forward(self, x):
return self.net(x)(3) 实现 Transformer 中的前馈网络:
python
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)(4) 实现多头注意力机制:
python
class Attention(nn.Module):
def __init__(self, dim, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
# 生成查询、键、值
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.heads), qkv)
# 计算注意力分数
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
# 注意力权重
attn = self.attend(dots)
attn = self.dropout(attn)
# 应用注意力权重到值上
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)(5) 使用注意力机制和前馈网络,实现完整的 Transformer 块:
python
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
nn.LayerNorm(dim),
Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout),
nn.LayerNorm(dim),
FeedForward(dim, mlp_dim, dropout=dropout)
]))
def forward(self, x):
for norm1, attn, norm2, ff in self.layers:
x = x + attn(norm1(x))
x = x + ff(norm2(x))
return x(6) 构建带池化操作的 Transformer 块:
python
class PoolingTransformer(nn.Module):
def __init__(self, dim, dim_out, pool_size=3, stride=2, padding=1):
super().__init__()
self.pool = DepthWiseConv2d(dim, dim_out, pool_size, padding, stride)
self.norm = nn.LayerNorm(dim_out)
def forward(self, x):
# x的形状: (batch_size, num_tokens, dim)
# 转换为2D图像形式以应用池化
h = w = int(x.shape[1] ** 0.5)
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
# 应用池化
x = self.pool(x)
# 转换回序列形式
h, w = x.shape[-2:]
x = rearrange(x, 'b c h w -> b (h w) c')
x = self.norm(x)
return x(7) 构建基于池化的 Vision Transformer 完整模型:
python
class PiT(nn.Module):
def __init__(self, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim,
pool_size=3, stride=2, dim_head=64, dropout=0., emb_dropout=0.):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
# 参数设置
num_patches = (image_size // patch_size) ** 2
patch_dim = 3 * patch_size ** 2
# Patch Embedding
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_size, p2=patch_size),
nn.Linear(patch_dim, dim),
)
# 位置编码
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches, dim))
self.dropout = nn.Dropout(emb_dropout)
# 计算各阶段维度
dim1 = dim
dim2 = dim1 * (stride ** 2) # 池化后通道数增加
dim3 = dim2 * (stride ** 2) # 再次池化后通道数增加
# Transformer阶段
self.transformer1 = Transformer(dim1, depth[0], heads[0], dim_head, mlp_dim, dropout)
self.pooling1 = PoolingTransformer(dim1, dim2, pool_size, stride)
self.transformer2 = Transformer(dim2, depth[1], heads[1], dim_head, mlp_dim, dropout)
self.pooling2 = PoolingTransformer(dim2, dim3, pool_size, stride)
self.transformer3 = Transformer(dim3, depth[2], heads[2], dim_head, mlp_dim, dropout)
# 分类头
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim3),
nn.Linear(dim3, num_classes)
)
def forward(self, img):
# Patch Embedding
x = self.to_patch_embedding(img)
b, n, _ = x.shape
# 添加位置编码
x += self.pos_embedding[:, :n]
x = self.dropout(x)
# Transformer阶段1
x = self.transformer1(x)
x = self.pooling1(x)
# Transformer阶段2
x = self.transformer2(x)
x = self.pooling2(x)
# Transformer阶段3
x = self.transformer3(x)
# 全局平均池化并分类
x = x.mean(dim=1)
return self.mlp_head(x)(8) 构建不同规模的 PiT 模型:
python
def pit_tiny(num_classes=1000):
"""创建小型PiT模型"""
return PiT(
image_size=224,
patch_size=16,
num_classes=num_classes,
dim=256,
depth=[2, 4, 3],
heads=[3, 6, 12],
mlp_dim=512
)
def pit_small(num_classes=1000):
"""创建中型PiT模型"""
return PiT(
image_size=224,
patch_size=16,
num_classes=num_classes,
dim=384,
depth=[2, 6, 4],
heads=[6, 12, 24],
mlp_dim=768
)
def pit_base(num_classes=1000):
"""创建大型PiT模型"""
return PiT(
image_size=224,
patch_size=16,
num_classes=num_classes,
dim=512,
depth=[3, 6, 4],
heads=[8, 16, 32],
mlp_dim=1024
)3.2 模型训练
(1) 获取训练和验证数据加载器,本节使用 CIFAR-10 数据集:
python
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
def get_dataloaders(batch_size=64):
transform_train = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
transform_val = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform_train)
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform_val)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False, num_workers=4)
return train_loader, val_loader(2) 定义模型训练和评估函数:
python
from matplotlib import pyplot as plt
def train_model(model, train_loader, val_loader, epochs=20, lr=0.001):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs)
best_acc = 0.0
history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}
for epoch in range(epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
train_loss = running_loss / len(train_loader)
train_acc = 100. * correct / total
# 验证阶段
val_loss, val_acc = evaluate_model(model, val_loader, criterion, device)
# 学习率调整
scheduler.step()
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_acc'].append(val_acc)
# 打印统计信息
print(f'Epoch [{epoch+1}/{epochs}], '
f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%, '
f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), 'best_model.pth')
print(f'Training finished. Best validation accuracy: {best_acc:.2f}%')
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history['train_loss'], label='Train Loss')
plt.plot(history['val_loss'], label='Val Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history['train_acc'], label='Train Acc')
plt.plot(history['val_acc'], label='Val Acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.show()
return model
def evaluate_model(model, val_loader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
val_loss = running_loss / len(val_loader)
val_acc = 100. * correct / total
return val_loss, val_acc(3) 初始化模型,并训练模型:
python
# 获取数据加载器
train_loader, val_loader = get_dataloaders(batch_size=64)
# 初始化模型
model = pit_tiny(num_classes=10) # CIFAR-10有10个类别
# 训练模型
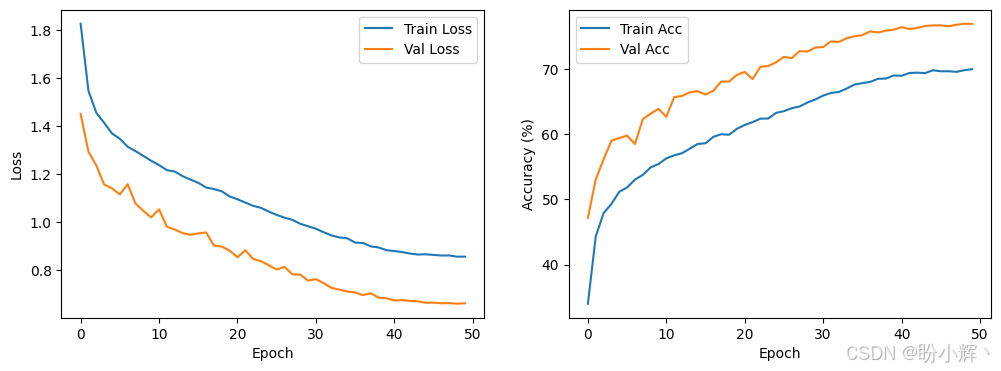
trained_model = train_model(model, train_loader, val_loader, epochs=50, lr=0.0001)训练过程模型损失和准确率变化情况如下:
相关链接
视觉Transformer实战 | Transformer详解与实现
视觉Transformer实战 | Vision Transformer(ViT)详解与实现
视觉Transformer实战 | Token-to-Token Vision Transformer(T2T-ViT)详解与实现