探索自主信息搜索代理:WebDancer论文介绍------数据合成篇
今天我想和大家分享一篇来自阿里巴巴通义实验室的最新论文:《WebDancer: Towards Autonomous Information Seeking Agency》。这篇论文发表于arXiv(编号2505.22648v3),日期是2025年8月10日,作者包括Jialong Wu、Baixuan Li等一群核心贡献者。论文的GitHub仓库是https://github.com/Alibaba-NLP/WebAgent,感兴趣的朋友可以去看看代码和更多细节。
论文的核心目标是构建一个端到端的自主信息搜索代理(Web Agent),类似于OpenAI的Deep Research或xAI的Grok DeepSearch,能够在真实网页环境中进行多步推理和信息获取。作者从数据中心和训练阶段视角,提出了一个完整的构建范式,包括四个关键阶段:浏览数据构建、轨迹采样、监督微调(SFT)和强化学习(RL)。作为一篇数据驱动的论文,它特别强调了如何合成高质量的数据来训练代理,这也是我今天博客的重点------数据合成部分。为什么重点在这里?因为在AI代理领域,数据质量往往是瓶颈,尤其是需要多步交互的复杂任务。论文通过创新的数据合成方法,显著提升了代理的泛化能力,并在GAIA和WebWalkerQA基准上取得了不错成绩。
论文背景与整体框架
先简单介绍一下论文的背景。传统的信息搜索代理往往依赖提示工程(prompting)或简单微调,但这些方法在复杂真实场景中表现不佳。论文指出,现有的QA数据集(如2Wiki)太浅,通常只需1-2步就能解决,而真实世界需要更长的推理链条。作者的目标是"从零构建像Deep Research那样的代理",基于ReAct框架(Thought-Action-Observation循环),让代理自主调用工具(如搜索和点击)来交互网页。
整体框架分为四个步骤:
- 构建多样且挑战性的深度信息搜索QA对(数据合成,这是重点)。
- 从QA对中采样高质量轨迹。
- 监督微调(SFT)用于冷启动。
- 强化学习(RL)提升泛化。
论文在QwQ-32B骨干模型上实现的WebDancer,在GAIA基准平均得分51.5%,在WebWalkerQA平均47.9%,超越了许多开源代理框架(如WebThinker-RL的46.5%)。但更重要的是,它提供了一个系统性的指南,帮助社区从数据角度构建更强的代理。
重点:深度信息搜索数据集合成(第2节)
论文的亮点在于数据合成部分,作者强调"数据中心"视角,因为高质量QA对是代理训练的基础。现有数据集如GAIA(仅466例)或WebWalkerQA(680例)规模小且浅层,难以支持长时序训练。于是,他们开发了两种合成方法:CRAWLQA (基于网页爬取)和E2HQA(从易到难进化)。这些方法旨在创建多样性强、复杂度高的QA对,支持多步交互(例如,需要多次搜索和点击才能解答)。
论文用一张图(Figure 1)生动展示了两种管道:
- CRAWLQA管道:从根URL开始,模拟人类点击子链接,收集子页面,然后用GPT-4o生成QA对。
- E2HQA管道:从简单问题起步,迭代注入新信息,使问题逐步复杂化。
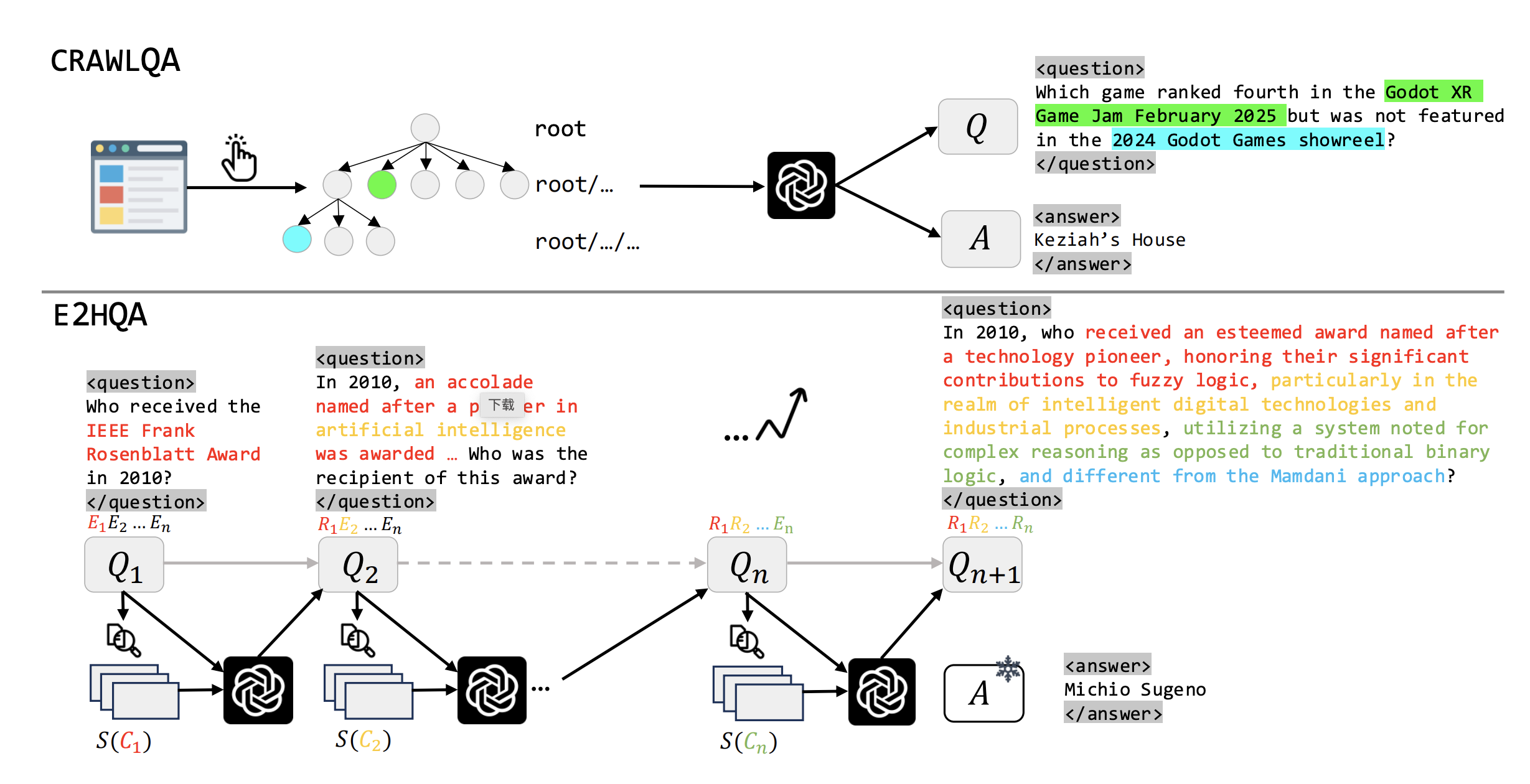
1. CRAWLQA:基于网页爬取的QA对构建
这种方法模拟人类浏览行为,目标是获取真实网页上的深层信息。步骤如下:
- 收集根URL:从知识密集型网站(如arXiv、GitHub、Wiki)获取根页面。
- 递归爬取:通过点击子链接,系统地收集子页面内容,模仿人类探索路径。
- 生成QA对:使用GPT-4o,根据预定义规则(如COUNT、多跳、交集类型)生成问题。灵感来自in-context learning,确保问题特定且相关。
为什么有效?因为它捕捉了网页的层次结构,需要代理通过"点击"行动来导航。例如,一个问题可能要求代理从根页点击到子页,提取交叉信息。这比浅层QA更接近真实搜索场景。论文提到,这种方法可扩展知识获取,支持长时序轨迹。
2. E2HQA:从易到难的QA对进化
这是我最喜欢的部分!E2HQA采用"逆向构建"策略,从简单QA起步,逐步注入复杂性,确保问题从"弱代理"到"强代理"渐进。灵感来自Wei et al.和Zhou et al.(2025)。
- 起始点 :从简单QA(如OpenAI的SimpleQA)开始,每个答案是一个简洁实体( E n E_n En)。
- 迭代过程 :
- 从问题 Q n Q_n Qn中选实体 E n E_n En。
- 用搜索引擎S查询 E n E_n En,获取相关内容 C n C_n Cn。
- 用LLM(π,这里是GPT-4o)重构 C n C_n Cn为新查询 R n R_n Rn,替换原实体。
- 新问题 Q n + 1 = Q n Q_{n+1} = Q_n Qn+1=Qn with E n E_n Enreplaced by R n R_n Rn。
- 控制复杂度:通过迭代次数n控制步骤数。答案不变,但解决问题需要先解决子问题。
公式表示: R n = π ( S ( C n ) ) R_n = π(S(C_n)) Rn=π(S(Cn))。
例如,初始问题:"谁获得了2020年诺贝尔物理奖?"(简单实体)。迭代后可能变成:"基于X事件的相关报道,谁在Y年获得了Z奖?"需要多步搜索。为什么牛?它保证了问题的连续性和有效性,避免了合成数据的噪声,还能控制深度(从2-3步到更多)。
论文强调,这些QA对的要求是:(i) 问题类型多样;(ii) 交互步骤增加。相比以往数据集(多为浅层),CRAWLQA和E2HQA规模更大,支持多跳推理和任务分解。
轨迹采样与后续训练(简要提)
在数据合成后,论文用拒绝采样(Rejection Sampling)从QA对中生成ReAct轨迹,包括短CoT(用GPT-4o)和长CoT(用QwQ-Plus)。然后通过三阶段过滤(有效性、正确性、质量)确保轨迹高质量。
训练上,先SFT冷启动(掩码观察损失,只学代理决策),再用DAPO算法RL优化(动态采样忽略噪声)。奖励设计简单:0.1格式分 + 0.9答案分,用LLM判别。
实验与启发
在基准测试中,WebDancer表现出色,尤其在中等难度任务上。分析显示,数据合成直接提升了数据效率和代理学习。
作为结语,这篇论文给我最大的启发是:构建AI代理,别只盯着模型,要从数据入手。CRAWLQA和E2HQA的方法简单却实用,适合我们这些开发者复现。如果你正研究Web Agent,不妨试试这些数据管道。欢迎评论区讨论你的看法!
数据构造
在CRAWLQA方法中,GPT-4o用于生成QA对的过程是论文的核心数据合成步骤之一,旨在从爬取的网页内容中自动创建高质量、特定类型的问题-答案对。下面我基于论文描述(特别是第2.1节)和相关引用,进行详细解释。注意,论文没有提供具体的prompt模板(可能在附录D中,但从可用文本中未找到详细示例),但它明确提到了灵感来源和机制,我会结合AI领域的常见实践来阐述。
基本原理
- 目标:生成的问题需要多样性强、复杂度高,能够支持代理的多步交互。例如,问题不应太浅(如单事实查询),而应要求代理进行"点击"导航、交叉信息提取等操作。这有助于训练代理在真实网页环境中进行长时序探索。
- 输入:爬取到的网页内容(文本),包括根页面和子页面的信息。
- 输出:QA对,即问题(Question)和对应的答案(Answer)。答案直接从内容中提取,确保准确性。
- 模型:使用GPT-4o(OpenAI的强大LLM),因为它擅长自然语言生成和理解长上下文。
详细步骤解释
论文提到:"We employ GPT-4o to synthesize QA pairs from the collected content. To ensure specificity and relevance of questions, inspired by Sen et al. (2022), we prompt LLMs to generate questions of designed types (e.g., COUNT, MULTI-HOP, INTERSECTION) via in-context learning Brown et al. (2020)。"
分解开来:
-
预定义问题类型(Designed Types):
- 论文指定了几种问题类型,以增加多样性和挑战性。这些类型不是随意选择的,而是为了模拟真实信息搜索场景:
- COUNT:计数类型。例如,从网页中提取数字统计,如"这个页面提到的项目数量是多少?" 这要求代理扫描并汇总信息。
- MULTI-HOP:多跳推理类型。需要多步逻辑链条,如"基于页面A的链接到页面B的信息,X和Y的关系是什么?" 这模拟代理需要"点击"子链接进行导航。
- INTERSECTION:交集类型。寻找共同点,如"页面中提到的两种技术有哪些共同特征?" 这鼓励代理比较多个部分的内容。
- 为什么这些类型?因为它们能捕捉网页的层次结构(根页→子页),并要求代理进行深层交互,而不是浅层搜索。论文强调,这比现有数据集(如简单QA)更复杂,能支持"long-horizon"轨迹。
- 论文指定了几种问题类型,以增加多样性和挑战性。这些类型不是随意选择的,而是为了模拟真实信息搜索场景:
-
提示工程(Prompting):
- 核心技术:In-Context Learning (上下文学习,引用Brown et al. (2020),即GPT-3论文中提出的few-shot prompting)。
- 这不是零样本(zero-shot)提示,而是提供少量示例(few-shot examples)在prompt中,让GPT-4o"学习"如何生成问题。
- 为什么有效?In-context learning允许模型从示例中推断模式,而无需额外训练。Sen et al. (2022)(可能是关于生成高质量QA的论文,灵感来源)强调这种方法能产生特定、相关的提问,避免泛化问题。
- prompt结构示例 (基于论文描述推断,实际可能类似):
- 指令部分: "基于以下网页内容,生成特定类型的问题。问题必须相关、具体,且答案能从内容中直接推导。类型包括COUNT、MULTI-HOP、INTERSECTION等。为每个类型生成1-2个QA对。"
- few-shot示例 (in-context learning的关键):
- 示例1(COUNT类型):
内容: "苹果公司有5个主要产品线:iPhone、iPad、Mac、Watch和服务。"
生成问题: "苹果公司有多少个主要产品线?"
答案: "5" - 示例2(MULTI-HOP类型):
内容: "页面1:链接到页面2。页面2:产品X于2020年发布,由Y团队开发。"
生成问题: "产品X的开发团队是什么时候发布的?"(需要从页面1点击到页面2)
答案: "Y团队,2020年" - 示例3(INTERSECTION类型):
内容: "技术A的特点:快速、安全。技术B的特点:安全、廉价。"
生成问题: "技术A和技术B的共同特点是什么?"
答案: "安全"
- 示例1(COUNT类型):
- 新内容输入:然后将爬取的网页文本插入prompt,如"现在基于以下内容生成: 插入爬取文本 "
- 输出控制:prompt可能要求输出JSON格式,如{"question": "...", "answer": "...", "type": "COUNT"},以便后续处理。
- 迭代与质量控制:论文暗示可能多次采样(rejection sampling,在第2.2节提到),如果生成的QA不满足规则(如不相关或有幻觉),则丢弃并重新生成,直到N次上限。
- 核心技术:In-Context Learning (上下文学习,引用Brown et al. (2020),即GPT-3论文中提出的few-shot prompting)。
-
为什么有效?
- 特定性和相关性:通过预定义类型和few-shot示例,生成的QA紧扣网页内容,避免随机或无关问题。例如,在arXiv页面爬取论文摘要后,可能生成"这个论文有多少位作者?"(COUNT)或"作者A和作者B的共同合作论文是什么?"(INTERSECTION,需要点击链接)。
- 可扩展性:这种自动化方式能大规模生成数据,弥补现有数据集(如GAIA只有466例)的不足。论文提到,这支持"deep queries",让代理学习点击行动。
- 灵感来源 :
- Sen et al. (2022):很可能指Pankaj Sen等人的论文(我推测可能是关于使用LLM生成多样QA的,如在QA系统测试中的应用)。它强调设计问题类型来测试模型的特定能力。
- Brown et al. (2020):GPT-3论文,引入in-context learning,证明LLM能从prompt中的示例"学习"新任务,而不需微调。
潜在局限与论文扩展
- 论文提到,生成的QA对会经过过滤(第2.2节的Trajectories Filtering),包括有效性、正确性和质量评估(如无冗余、逻辑准确),确保用于训练的高质量。
- 如果你想复现,GitHub仓库(https://github.com/Alibaba-NLP/WebAgent)可能有代码或prompt示例。实际操作中,GPT-4o的API调用成本较高,但输出一致性好。
数据集里有网址吗?
1️⃣ CRAWLQA 里的 QA 是否"保存网页地址"?
结论先行:
CRAWLQA 的"QA 对本身"通常不显式保存网页 URL,但在"代理轨迹数据(trajectory)"中是会包含 URL 的。
更细一点拆开说:
(1)纯 QA 层面(question--answer pairs)
在论文 §2.1 QA Pairs Construction 中,CRAWLQA 被描述为:
We employ GPT-4o to synthesize QA pairs from the collected content.
也就是说:
- QA 是 基于已爬取并整理后的网页内容文本生成的
- QA 对本身是"内容级"的,不是"来源级"的
👉 论文并未声称在最终 QA 数据中保留 source URL / citation
👉 QA 更像是一个 "可通过网页检索与点击得到答案的问题",而不是一个带引用的 QA(不像 HotpotQA 那种 supporting facts)
因此:
- 问题和答案字段里,一般不包含网页地址
- QA 更偏向"信息寻求任务定义",而不是"可追溯证据标注数据集"
(2)Agent 轨迹 / ReAct 数据层面(非常关键)
一旦进入 §2.2 和 §3 的 agent trajectory(ReAct 轨迹):
visitaction 的参数中 明确包含 URL- 示例结构中出现:
json
{
"name": "visit",
"arguments": {
"goal": "...",
"url_link": "https://..."
}
}并且:
- visit 的 observation 是基于该 URL 页面生成的
evidence/summary - 这些 URL 是 agent 在执行过程中真实访问的网页
👉 结论:
- URL 不属于 QA pair 的"静态标注"
- URL 属于 agent 行为数据(trajectory)的一部分
2️⃣ CRAWLQA / WebDancer 数据集的实际格式长什么样?
虽然论文没有直接给出一个 JSON Schema ,但从描述和示例可以还原出三种层级的数据形态:
🟢 Level 1:最基础的 QA 数据(用于 RL 或冷启动)
json
{
"question": "Which game ranked fourth in the Godot XR Game Jam February 2025 but was not featured in the 2024 Godot Games showreel?",
"answer": "Keziah's House"
}特点:
-
不含 URL
-
不含 evidence
-
用于:
- RL rollout
- agent 自主搜索训练
- evaluation task definition
🟡 Level 2:带 agent trajectory 的 ReAct 数据(SFT 用)
这是 WebDancer 真正用于 SFT 冷启动 的核心格式:
text
<think>...</think>
<tool_call>
{"name": "search", "arguments": {"query": "..."}}
</tool_call>
<tool_response>...</tool_response>
<think>...</think>
<tool_call>
{"name": "visit", "arguments": {"goal": "...", "url_link": "https://example.com"}}
</tool_call>
<tool_response>
Summary / Evidence extracted from the page
</tool_response>
<answer>...</answer>结构上等价于:
json
{
"question": "...",
"trajectory": [
{
"thought": "...",
"action": {
"name": "search",
"arguments": {...}
},
"observation": {...}
},
{
"thought": "...",
"action": {
"name": "visit",
"arguments": {
"url_link": "https://..."
}
},
"observation": "page summary / evidence"
}
],
"final_answer": "..."
}👉 URL 在这里是显式存在的
🔵 Level 3:原始爬取数据(论文未公开,但逻辑上存在)
在 CRAWLQA pipeline 最前面,必然存在类似:
json
{
"root_url": "https://...",
"subpages": [
{
"url": "https://...",
"html": "...",
"clean_text": "..."
}
]
}但注意:
- 这部分不是训练数据
- 也没有在论文中作为 dataset release 的一部分
- 只用于 QA 合成和 agent environment
3️⃣ 为什么 CRAWLQA 不在 QA 中保留 URL?(设计动机)
这是一个刻意的设计选择:
-
避免"捷径学习"
- 如果 QA 直接给 URL,agent 不需要 search / explore
-
更贴近真实信息寻求
- 用户提问时不会告诉你"答案在这个网页"
-
泛化能力
- 同一问题可以通过不同网页路径解决
- agent 学的是策略,不是 lookup
4️⃣ 一句话总结(可直接用在讨论或答辩中)
在 CRAWLQA 中,GPT-4o 生成的 QA 对本身通常不显式保存网页地址;URL 主要存在于后续 agent ReAct 轨迹数据中,作为
visit行为的参数,用于监督和训练信息寻求过程,而非作为 QA 的静态标注字段。
后记
2025年12月26日周五于上海。在grok 4.1 和chatgpt 辅助下完成。