- 第一部分 (1-15) :Transformer 核心基础 (聚焦 Attention Is All You Need 原文,包括 QKV 计算、复杂度、结构细节)。
- 第二部分 (16-28) :架构演进与注意力变体 (Encoder/Decoder 对比、MHA/MQA/GQA 详解、大模型架构选型)。
- 第三部分 (29-40) :位置编码与推理优化 (RoPE、ALiBi、KV Cache、位置编码外推等进阶难题)。
下面是 第一部分 (1-15/40):Transformer 核心原典。这部分是所有大模型面试的"必考题"。
第一部分:Transformer 核心基础
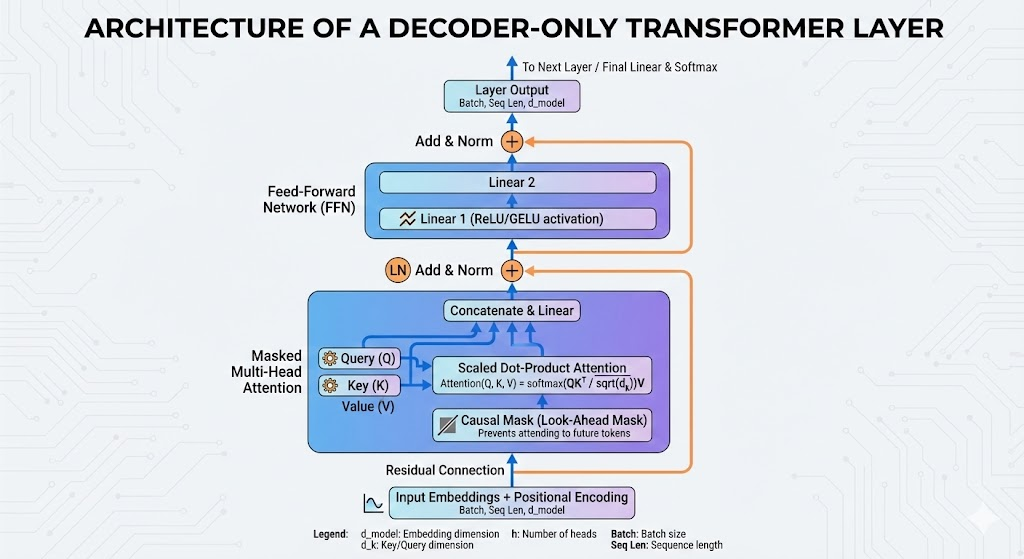
1. Self-Attention 的核心公式与物理含义
问题: 请写出 Scaled Dot-Product Attention 的计算公式,并解释 Q, K, V 的物理含义。
答案:
-
公式:
-
物理含义:
-
Q (Query):查询向量,代表当前 token 想要去"寻找"什么信息。
-
K (Key):键向量,代表当前 token"拥有"什么特征,用于被 Q 匹配。
-
V (Value):值向量,代表当前 token 包含的实际内容信息。
-
过程 : 计算的是相关性(注意力分数), 进行缩放,Softmax 归一化为概率分布,最后加权求和 ,得到融合了上下文信息的当前 token 表示。
面试官视角:
"不要只背公式。你要能解释清楚:这本质上是一个基于内容的寻址 (Content-based Addressing) 过程,类似数据库查询,但匹配是'软'的(概率性的)。"
2. 缩放因子 的作用
问题: 为什么在计算 后需要除以 ?如果不除会怎样?
答案:
-
原因:
-
假设 Q 和 K 的分量服从均值为 0、方差为 1 的独立分布,那么 的点积的均值为 0,方差为 。
-
如果不除以 ,随着 (head dimension) 的增大,点积结果的方差会变得很大,导致 Softmax 的输入值差异巨大。
-
后果:
-
Softmax 函数在输入值绝对值很大时,会进入饱和区 (Saturation Region),此时梯度的导数趋近于 0。
-
这会导致梯度消失,使得训练难以收敛。 的作用是将方差拉回 1,保持梯度稳定。
面试官视角:
"这是一个考察数学敏感度的点。关键在于'Softmax 的梯度敏感性'。有些面试官会让你简单推导一下方差扩大的过程。"
3. Multi-Head Attention (MHA) 的意义
问题: 为什么要使用多头注意力 (Multi-Head Attention)?是头越多越好吗?
答案:
- 意义:
- 多子空间表示 (Subspace Representation):不同的 Head 可以关注不同的特征子空间。例如,一个 Head 关注语法结构,另一个关注语义指代,互不干扰。
- 集成效应:类似 Ensemble Learning,通过多个独立的注意力机制增强模型的鲁棒性。
- 是否越多越好:不是。Head 过多会导致每个 Head 的维度 过小,难以承载足够的信息;同时计算开销增加,且可能引入冗余信息。
面试官视角:
"你可以类比 CNN 中的多个卷积核 (Filters)。每个 Head 就像一个 Filter,负责提取不同的特征模式。"
4. Transformer 的时间复杂度
问题: Self-Attention 层的时间复杂度和空间复杂度是多少?与 RNN 相比有什么优劣?
答案:
- 假设序列长度为 ,特征维度为 。
- 时间复杂度:。主要来自 ( 乘 得到 ) 和 的计算。
- 相比 RNN:
- RNN 的复杂度是 。
- 当 时,Transformer 快;当 非常大 (长序列) 时,Transformer 的 计算量成为瓶颈。
- 核心优势 :Transformer 可以并行计算 (Parallelization),而 RNN 必须串行。
面试官视角:
"这是'为什么 Transformer 不能无限处理长文本'的理论根源。引出 FlashAttention 或 Linear Attention 等优化也是加分项。"
5. Decoder 的 Mask 机制
问题: Transformer 的 Decoder 中使用了 Masked Multi-Head Attention,这里的 Mask 有什么作用?
答案:
- 作用 :因果遮蔽 (Causal Masking) 或 Look-ahead Masking。
- 原理:在训练阶段,虽然 Decoder 可以看到整个目标序列 (Ground Truth),但在预测第 个 token 时,不仅要依赖 Encoder 的输出,还只能依赖 时刻之前的输出 ( 到 )。
- 实现 :将 矩阵的上三角区域(不含对角线)置为 ,经过 Softmax 后变为 0,从而阻断来自"未来"的信息流,保持自回归 (Autoregressive) 属性。
面试官视角:
"注意区分 Padding Mask (处理变长序列) 和 Sequence Mask (因果遮蔽)。Decoder 中通常两者同时存在。"
6. 位置编码 (Positional Encoding)
问题: Transformer 为什么要引入位置编码?原始论文中的正弦位置编码有什么特点?
答案:
- 原因 :Self-Attention 机制具有排列不变性 (Permutation Invariant)。如果不加位置编码,打乱句子中单词的顺序,输出结果完全一样。这就丢失了序列信息。
- 正弦编码特点:
- 相对位置表达:对于固定偏移 , 可以表示为 的线性函数。这使得模型理论上能学习到相对位置关系。
- 归纳偏置:无需训练,可扩展到未见过的序列长度(泛化性优于可学习的位置嵌入)。
面试官视角:
"现在的大模型(如 LLaMA)大多不再使用这种绝对位置编码,而是转向 RoPE。但这道题是基础。"
7. 为什么要用 Add & Norm?
问题: Transformer 每个子层后都有 Residual Connection (残差连接) 和 Layer Normalization,为什么?
答案:
- Residual Connection :解决深层网络的梯度消失 和退化问题。它允许梯度直接流向浅层,使得堆叠深层网络成为可能。
- Layer Normalization (LN):
- 相比 BN,LN 对 batch size 不敏感,且能很好地处理变长序列 (RNN/Transformer 的标配)。
- 它对每个样本的特征向量进行归一化,稳定了神经元的输入分布,加速收敛。
面试官视角:
"一定要提到:CV 领域常用 BN,而 NLP 领域常用 LN,核心原因在于 NLP 数据的序列长度不一致,且 Batch Size 通常较小(大模型训练时)。"
8. Pre-Norm vs Post-Norm
问题: 原始 Transformer 使用 Post-Norm,而现在的 LLM (如 GPT-3, LLaMA) 多使用 Pre-Norm,区别是什么?
答案:
-
Post-Norm (Original):
Output = Norm(x + Sublayer(x))。 -
特点 :放在残差相加之后。如果不配合 Warmup,深层网络梯度容易消失或爆炸,训练难收敛。
-
Pre-Norm (Modern):
Output = x + Sublayer(Norm(x))。 -
特点:放在子层输入之前,残差连接是一条纯粹的"直通大道"。
-
优势 :梯度流更加通畅,训练非常稳定,允许使用更大的学习率,不需要繁琐的 Warmup 调参。
面试官视角:
"虽然 Pre-Norm 训练稳定,但有研究指出其效果上限略低于精调的 Post-Norm。不过为了在大规模训练中不炸梯度,Pre-Norm 是目前的主流选择。"
9. Feed Forward Network (FFN) 的结构与作用
问题: FFN 层的结构是怎样的?它在整个网络中起什么作用?
答案:
-
结构:两层线性变换,中间夹一个激活函数 (ReLU 或 GELU)。
-
公式:
-
通常通过先将维度扩大 4 倍 (4d),再压缩回原维度 (d)。
-
作用:
-
非线性增强:Self-Attention 操作主要是线性的 (矩阵乘法),FFN 引入了非线性能力。
-
记忆能力 :有研究认为,FFN 的参数 (Key-Value Pairs) 存储了大量的事实性知识 (Factual Knowledge),而 Attention 更多是在处理 token 间的关系。
面试官视角:
"在 MoE (混合专家) 模型中,被替换和扩展的正是这个 FFN 层。"
10. Transformer 中的 Dropouts 使用位置
问题: 为了防止过拟合,Transformer 在哪些位置使用了 Dropout?
答案:
主要在三个地方:
- Embedding 后:Input Embedding + Positional Encoding 之后。
- Attention 后:Softmax 计算出的权重之后 (Drop attention weights),以及 线性投影之后 (Residual 相加之前)。
- FFN 后:第二层 Linear 输出之后 (Residual 相加之前)。
面试官视角:
"Drop Attention weights 意味着随机切断了一些 token 之间的联系,这是一种很强的结构性正则化。"
11. Cross-Attention 的 Q, K, V 来源
问题: 在 Encoder-Decoder 架构中,Cross-Attention (Encoder-Decoder Attention) 的 Q, K, V 分别来自哪里?
答案:
- Q (Query) :来自 Decoder 的上一层输出。代表 Decoder 当前想要查询什么信息。
- K (Key) 和 V (Value) :来自 Encoder 的最终层输出。代表源序列提供的完整上下文信息。
- 含义:Decoder 用自己的状态去 Encoder 的输出中查询相关信息,以辅助当前的生成。
面试官视角:
"这是 Encoder-Decoder 架构能够做翻译、摘要等 Seq2Seq 任务的核心接口。"
12. 归纳偏置 (Inductive Bias) 问题
问题: 相比 CNN 和 RNN,Transformer 的归纳偏置是强还是弱?这意味着什么?
答案:
-
结论 :Transformer 的归纳偏置非常弱。
-
CNN 假设了局部性 (Locality) 和 平移不变性。
-
RNN 假设了时间连续性。
-
Transformer 对 token 的空间位置和顺序几乎没有假设 (全靠位置编码和 Attention 学习)。
-
意味着什么:
- Transformer 需要海量数据来学习这些在 CNN/RNN 中预设好的规律。
- 一旦数据量足够,它的上限更高,因为它不受限于预设的假设,能捕捉更复杂的全局依赖。
13. 为什么 Q 和 K 使用不同的权重矩阵生成?
问题: 计算 Attention 时,为什么不能直接令 ,也就是直接计算 ?
答案:
- 打破对称性:如果 ,则 是一个对称矩阵。这意味着 token A 对 token B 的注意力等于 token B 对 token A 的注意力。
- 实际需求 :语言中的关系往往是非对称的。例如,"我"是主语,"苹果"是宾语,"我"对"苹果"的关注(动作发出者)与"苹果"对"我"的关注(动作承受者)在语义空间中应该是不同的。使用不同的 和 投影可以将它们映射到不同的空间,从而建模这种非对称关系。
14. 激活函数 GELU vs ReLU
问题: 为什么 BERT 和 GPT 等后续模型常用 GELU 而不是原始论文中的 ReLU?
答案:
- ReLU: 时梯度为 0。在负区间缺乏随机性,容易造成神经元死亡。
- GELU (Gaussian Error Linear Unit):
- 。它在 较小时趋近于 0,但在负区间有平滑的非零梯度。
- 它结合了 ReLU (非线性) 和 Dropout (随机正则化) 的思想(基于概率的激活)。
- 对于大模型训练,GELU 通常能带来更快的收敛和更好的泛化。
15. 参数量估算 (必考)
问题: 假设模型维度 ,层数 ,词表大小 。请估算一个 Transformer Decoder 模型的参数量。
答案:
主要参数集中在两个块:
- Attention 层: 个矩阵 (),每个大小 。参数量 。
- FFN 层:两个矩阵, 和 。参数量 。
- 单层总计:。
- Embedding 层:。
- 总参数量:。
面试官视角:
"对于 12 层 base 模型,。 约为 700万。12层就是 8500万,加上 Embedding 正好约 1.1亿 (BERT-Base 的大小)。这是一个常用的速算公式:**参数量 ** (忽略 Embedding 时)。"
第二部分:架构演进与注意力变体 (Architecture & Attention Variants)
16. Transformer 三大架构流派
问题: 请简述 Transformer 的三种主要架构流派 (Encoder-only, Decoder-only, Encoder-Decoder) 的区别及代表模型。
答案:
- Encoder-only (双向):
- 特点:使用全向 Attention (无 Mask),能同时看到上下文。适合理解任务(分类、实体识别)。
- 代表 :BERT, RoBERTa。
- Decoder-only (自回归):
- 特点:使用 Causal Mask,只能看到上文。适合生成任务。
- 代表 :GPT 系列, LLaMA, BLOOM。
- Encoder-Decoder (序列到序列):
- 特点:Encoder 理解输入,Decoder 生成输出。适合翻译、摘要。
- 代表 :Transformer 原作, T5, BART。
面试官视角:
"面试官可能会问:'T5 也是生成模型,为什么现在的 LLM 不用 T5 的架构了?' 答案通常涉及训练效率和 Zero-shot 泛化能力的差异。"
17. 为什么大模型 (LLM) 普遍选择 Decoder-only 架构?
问题: 既然 Encoder 能够看到双向信息,理论上理解能力更强,为什么 GPT-3、LLaMA、PaLM 等主流大模型全部采用了 Decoder-only 架构?
答案:
主要有三个原因:
- 训练效率与工程实现:Decoder-only 架构在预训练时通过 Shift 标签即可复用输入矩阵,计算效率略高。且在推理时 KV Cache 管理更简单。
- 低秩 (Low Rank) 问题:有研究指出,Attention 矩阵在经过 Softmax 后容易出现秩塌陷 (Rank Collapse)。Encoder-only 的双向注意力使得 Attention 矩阵更稀疏,秩更低,表达能力受限;而 Decoder-only 的下三角 Mask 结构在一定程度上保持了满秩,保留了更强的表达能力。
- 任务对齐 (Alignment) :生成任务 (Next Token Prediction) 天然符合人类语言产生的过程。Decoder-only 在 Zero-shot / Few-shot 的上下文学习 (In-Context Learning) 能力上展现出了显著优势。
面试官视角:
"这是一个开放性问题,但'低秩假设'和'上下文学习能力'是两个高分回答点。"
18. KV Cache (键值缓存)
问题: 什么是 KV Cache?为什么推理阶段需要它?它带来了什么问题?
答案:
- 定义:在自回归推理 (生成) 过程中,Transformer 是逐个 token 生成的。生成第 个 token 时,第 到 个 token 的 (Key) 和 (Value) 向量已经计算过了。
- 作用:为了避免重复计算,我们将这些 向量缓存在显存中,称为 KV Cache。每一步只计算当前新 token 的 ,然后取回缓存的旧 进行拼接计算 Attention。
- 问题 :显存占用巨大。
- 公式: (2代表K和V,B是batch, L是层数, H是头数)。
- 这成为了制约大模型推理 Batch Size 和 上下文长度 的最大瓶颈。
面试官视角:
"没有 KV Cache,Transformer 推理的时间复杂度是 ;有了 KV Cache,是 。这是必须用的,但也引出了 MQA/GQA 的必要性。"
19. MHA (Multi-Head Attention) 的瓶颈
问题: 经典的多头注意力 (MHA) 在推理时有什么性能瓶颈?
答案:
- 结构 : 个 Query 头,对应 个 Key 头 和 个 Value 头。即 Q:K:V 比例为 1:1:1。
- 瓶颈 :内存带宽 (Memory Bandwidth)。
- 在推理阶段,计算量 (Compute) 相对较小,主要时间花在从显存中读取庞大的 KV Cache 到计算单元上。
- MHA 的 KV Cache 体积最大,导致推理速度受限于内存带宽 (Memory Bound),而非计算速度 (Compute Bound)。
20. MQA (Multi-Query Attention)
问题: 什么是 MQA?它如何优化推理速度?有什么缺点?
答案:
- 结构 :保留 个 Query 头,但所有 Query 头共享同一组 Key 头和 Value 头 。即 Q:K:V 比例为 H:1:1。
- 优点:
- 显存占用极低:KV Cache 缩小了 倍。
- 推理速度快:数据读取量大幅减少,极大缓解了内存带宽压力。
- 缺点 :模型容量下降,精度受损。强制所有头关注同样的信息子空间,导致模型表现(尤其是微调后)往往不如 MHA。
- 代表模型:Falcon, PaLM。
面试官视角:
"MQA 是极端优化的代表。面试官可能会问:'MQA 训练时会比 MHA 快吗?' 答案是:训练时加速不明显,优势主要在推理。"
21. GQA (Grouped-Query Attention)
问题: 什么是 GQA?为什么 LLaMA-2/3 选择了 GQA?
答案:
-
结构 :MHA 和 MQA 的折中方案。将 个 Query 头分成 组,每组共享一个 Key 头和一个 Value 头。
-
例如:32 个 Query 头,分成 4 组,每组 8 个 Q 共享 1 个 K/V。总共有 4 个 K/V 头。
-
Q:K:V 比例为 H:G:G (其中 )。
-
优势:
-
平衡之道:在保留了大部分 MHA 的精度 (Capacity) 的同时,获得了接近 MQA 的推理速度和显存节省。
-
代表模型 :LLaMA-2 (70B), LLaMA-3 (全系)。
面试官视角:
"这是目前的业界标准。如果问你具体怎么选,可以说:GQA 使得我们可以在保持高性能的前提下,支持更长的 Context Window (上下文窗口)。"
22. MHA/MQA/GQA 显存占用计算对比
问题: 假设模型 ,Head数 ,Head维度 。请对比 MHA, MQA, GQA (8组) 生成一个 token 所需加载的 KV 参数量比例。
答案:
-
MHA:
-
K 头数 = 32,V 头数 = 32。
-
参数量比例 。
-
GQA (Group=8):
-
K 头数 = 8,V 头数 = 8。
-
参数量比例 。
-
节省 :显存占用是 MHA 的 1/4。
-
MQA:
-
K 头数 = 1,V 头数 = 1。
-
参数量比例 。
-
节省 :显存占用是 MHA 的 1/32。
面试官视角:
"通过这道计算题,你可以直观地展示 GQA 是如何用 1/4 的显存代价换取精度的。"
23. MHA (Multi-Head Attention) 的参数量详细计算
问题: 给定 Transformer 的嵌入维度 ,头数 ,每个头的维度 。请详细计算一个 MHA 层的参数量。是否与头数 有关?
答案:
- 结论 :参数量与头数 无关。
- 详细计算:
- 输入投影 ():
- 对于每个头 ,我们需要三个矩阵 ,尺寸均为 。
- 所有 个头拼接起来,总参数量为:。
- 输出投影 ():
- 将所有头的输出拼接 (Concat) 后,维度为 。
- 经过一个线性变换 映射回 ,尺寸为 。
- 参数量为:。
- 偏置 (Bias):
-
共有 4 个偏置向量,总量为 。
-
总计:。
-
分析:无论你把 切成多少个头,只要 恒成立,总参数量就是固定的 。
面试官视角:
"很多同学会误以为头数越多参数越多。这道题就是为了考察你是否理解 MHA 在实现上其实就是一个大的矩阵乘法,然后再 reshape/split 成多头。"
24. MHA 的计算量 (FLOPs) 与序列长度的关系
问题: 假设输入序列长度为 ,维度为 。请推导 MHA 前向传播的计算量 (FLOPs),并指出哪一部分导致了长文本推理的瓶颈?
答案:
计算量主要由线性投影 (Linear) 和 注意力核心 (Attention Core) 两部分组成。这里按乘加算 2 次操作 () 估算:
- 线性投影阶段 ():
- 计算 :。FLOPs 。
- 输出投影 :。FLOPs 。
- 小结 :。这部分与序列长度 呈线性关系。
- 注意力核心阶段 ( 和 ):
-
计算 (矩阵乘法 和 ):得到 矩阵。FLOPs 。
-
计算 (矩阵乘法 和 ):得到 矩阵。FLOPs 。
-
小结 :。这部分与序列长度 呈平方关系。
-
总计算量:。
-
瓶颈分析:
-
当 较小 (如 BERT 的 512) 时, (如 768) 占主导,线性投影是主要开销。
-
当 很大 (如 GPT-4 的 128k) 时, 项迅速爆炸,注意力核心计算成为绝对的算力瓶颈。
面试官视角:
"如果这道题你能把 这个项写出来,面试官就会顺势问你:FlashAttention 是如何优化这一步的?(虽然它主要优化 IO,但也利用了分块计算)。"
25. Scaling Laws (缩放定律)
问题: OpenAI 提出的 Scaling Laws 核心结论是什么?它对架构选择有何影响?
答案:
- 核心结论 :模型的性能 (Loss) 与 计算量 (Compute) 、数据集大小 (Dataset Size) 、参数量 (Parameters) 呈幂律 (Power-law) 关系。
- 重要发现 :在计算资源有限的情况下,模型架构的微小调整 (如层数、宽度的比例) 对性能影响很小 ,真正重要的是把模型做大、把数据量做大。
- 影响:这促使业界停止了对复杂架构的"魔改",转而专注于利用 Decoder-only 架构堆叠参数和清洗数据。
26. Pre-Training vs Fine-Tuning 的计算模式差异
问题: 在 Transformer 架构下,预训练 (Training) 和 推理 (Inference) 的计算模式有什么本质区别?
答案:
-
预训练 (Training):
-
并行计算 :因为输入是完整的 Ground Truth 序列,我们可以并行计算所有 token 的 Attention 和 Loss。
-
Compute Bound:主要瓶颈在于矩阵乘法 (GEMM) 的计算速度。
-
推理 (Inference):
-
串行生成:Token 必须一个接一个生成 (Auto-regressive)。
-
Memory Bound:每生成一个 token 都要搬运整个 KV Cache,主要瓶颈在于显存带宽。
27. 稀疏注意力 (Sparse Attention)
问题: 为了解决 Transformer 的复杂度,除了 MQA,还有哪些稀疏注意力机制?(简述一两种)
答案:
- Local/Window Attention (局部注意力):每个 token 只关注自己周围窗口大小为 的 token (如 Longformer)。复杂度降为 。
- BigBird / ETC:结合了局部注意力 + 随机注意力 + 全局 token (Global tokens)。
- 现状 :虽然稀疏注意力理论上降低了复杂度,但在现代大模型中,由于 GPU 对密集矩阵运算 (Dense Matrix Multiplication) 的优化极好,稀疏操作反而可能因为内存访问不连续而变慢。目前主流方案更多是 FlashAttention (硬件优化) + GQA,而非修改 Attention 的数学定义。
28. U-Net 架构 (Diffusion Transformer)
问题: 最近火热的 Sora (DiT) 结合了 Transformer 和 Diffusion,这里的 Transformer 起什么作用?
答案:
- 传统 Diffusion:使用 U-Net (基于 CNN) 作为去噪骨干网络。
- DiT (Diffusion Transformer) :将 U-Net 替换为 Transformer。
- 将图像切成 Patch (类似 ViT)。
- Transformer 能够更好地捕捉图像的全局依赖关系,且参数扩展性 (Scaling) 远好于 CNN。
- 这证明了 Transformer 架构在多模态生成领域的通用性。
第三部分:位置编码进阶与推理极致优化
29. RoPE (Rotary Positional Embedding) 的核心思想
问题: LLaMA 等主流大模型为什么普遍放弃了绝对位置编码,改用 RoPE (旋转位置编码)?它的核心思想是什么?
答案:
-
核心痛点 :传统的绝对位置编码 (Add PE) 难以捕捉 token 间的相对距离关系;而传统的相对位置编码 (如 T5) 需要在 Attention 矩阵上加偏置,计算效率低且难以缓存。
-
RoPE 思想 :通过绝对位置编码的方式,实现相对位置编码的效果。
-
它不改变向量的模长,而是将 token 的 Embedding 向量在复数平面(或二维子空间)中进行旋转。
-
旋转的角度 由 token 的绝对位置 决定。
-
效果:当计算 和 的内积时,结果中自然包含了一个只与位置差 有关的项,从而完美捕获相对位置信息。
面试官视角:
"一句话总结 RoPE:绝对位置编码的实现,相对位置编码的核。"
30. RoPE 的数学性质 (为什么能外推?)
问题: 请写出 RoPE 在二维情况下的变换公式。为什么说它使得 Attention score 只依赖于相对距离?
答案:
-
公式:假设二维向量 ,位置为 ,旋转角度为 。
-
内积性质:
-
由于旋转矩阵是正交矩阵,且 。
-
因此,Attention score () 的值只取决于 (相对距离),而与绝对位置 无关。
面试官视角:
"虽然 RoPE 理论上支持无限外推,但实际上由于训练数据的长度限制,直接外推会导致 Attention 分布熵值剧烈波动 (Attention Sink)。因此才有了 NTK-Aware 等插值方法。"
31. ALiBi (Attention with Linear Biases)
问题: ALiBi 也是一种位置编码,它和 RoPE 有什么不同?为什么说 ALiBi 的外推性 (Extrapolation) 更好?
答案:
-
机制 :ALiBi 完全不使用 Embedding 层的位置编码。
-
它直接在计算出的 Attention Score 矩阵上加上一个静态的、预设的线性偏置罚项。
-
罚项大小与 token 距离成正比:。
-
外推性:
-
RoPE 在超出训练长度时,旋转频率可能会遇到未见过的相位,导致性能下降。
-
ALiBi 施加的是一个简单的线性惩罚,这种"距离越远注意力越弱"的归纳偏置非常强且稳定,因此在从未见过的超长序列上也能保持较好的 PPL (困惑度)。
面试官视角:
"ALiBi 的缺点是表达能力稍弱(强制距离衰减),因此在需要长距离依赖的任务(如代码生成)上,LLaMA 还是选择了 RoPE。"
32. 长度外推 (Length Extrapolation) 技巧
问题: 如果一个模型只在 4k 长度上训练,如何让它在推理时处理 16k 的长度?简述 线性插值 (Linear Interpolation) 的原理。
答案:
- 问题:直接外推会导致 RoPE 的旋转角度超出训练见过的范围 (高频分量震荡)。
- 线性插值 (PI):
- 原理:将推理时的长序列位置索引 进行"压缩",映射回训练时的 范围内。
- 操作:将位置索引 变为 。
- 效果:对于模型来说,通过插值,看到的旋转角度依然在训练分布内。虽然分辨率降低了,但至少能"跑通"且不崩坏。
面试官视角:
"更高级的方法是 NTK-Aware Interpolation。它不均匀插值,而是对高频分量不插值(保持分辨力),对低频分量进行插值(解决外推)。这是 LLaMA 扩充上下文的标准做法。"
33. FlashAttention V1 的核心原理
问题: FlashAttention 是如何加速 Attention 计算的?这里的 IO-Aware 是什么意思?
答案:
- 瓶颈 :标准 Attention 计算需要生成巨大的 矩阵 和 ,这些中间矩阵需要频繁在 HBM (显存) 和 SRAM (计算单元缓存) 之间读写,导致显存带宽 (Memory Bandwidth) 成为瓶颈。
- FlashAttention V1 核心:
- 分块 (Tiling):将 切分成小块,使得计算可以在快速的 SRAM 中完全进行,而不需要把巨大的中间矩阵写回 HBM。
- 重计算 (Recomputation):在反向传播时,不存储前向的 Attention 矩阵,而是利用 SRAM 中的块重新快速计算一遍。
- 结果 :虽然计算量 (FLOPs) 甚至略有增加(重计算),但 HBM 读写量 (IO) 减少了数倍,总体速度提升显著。
面试官视角:
"关键词是 SRAM。FlashAttention 的本质是用'多算的计算时间'换取了'昂贵的 IO 时间'。"
34. FlashAttention V2 的改进
问题: FlashAttention V2 相比 V1 做了哪些关键改进?
答案:
- V1 的短板 :V1 主要是沿着 Batch Size 和 Head Dimension 并行,但在 Sequence Length (序列长度) 维度上是串行的。
- V2 的改进:
- 序列并行:调整了算法循环顺序,使得外层循环可以并行处理不同的序列块。
- 减少非矩阵运算:优化了 Softmax 等非矩阵乘法操作。
- 效果:V2 在长序列下的 GPU 利用率更高,通常能达到理论峰值的 50%-70%。
35. PagedAttention (vLLM 核心)
问题: vLLM 提出的 PagedAttention 解决了什么问题?它借鉴了操作系统的什么思想?
答案:
-
问题 :KV Cache 的显存碎片化 (Fragmentation)。
-
传统 KV Cache 需要预分配连续的显存空间。由于输出长度不可知,通常会预留最大长度,导致大量显存浪费 (预留了没用)和碎片(中间有空隙塞不进新请求)。
-
PagedAttention:
-
借鉴思想 :操作系统的 虚拟内存 (Virtual Memory) 与 分页 (Paging)。
-
机制:将 KV Cache 切分成固定大小的 Block (如 16 tokens/block)。这些 Block 在物理显存中可以是不连续的,通过一个"页表"来管理逻辑顺序。
-
效果 :显存利用率接近 100%,极大地提升了推理时的 吞吐量 (Throughput)。
面试官视角:
"PagedAttention 并不加速单个请求的推理延迟 (Latency),它提升的是并发吞吐量。这对于服务端的 GPU 利用率至关重要。"
36. Continuous Batching (Orchestration)
问题: 在大模型推理服务中,Continuous Batching (连续批处理) 是如何工作的?相比 Static Batching 有什么优势?
答案:
-
Static Batching:等待凑齐一个 Batch 的请求,然后一起推理。问题是,如果 Batch 中有一个请求生成很长,其他请求生成完了也得等着 (Padding 浪费),导致 GPU 空转。
-
Continuous Batching (Iteration-level):
-
一旦 Batch 中的某个请求生成结束 (输出 EOS),立即将该槽位释放,插入一个新的请求继续生成。
-
它是迭代级的调度,而不是请求级的。
-
优势:消除了 Padding 带来的计算浪费,大幅降低了排队延迟。
37. 显存估算题 (7B 模型)
问题: 假设部署一个 LLaMA-2-7B 模型 (FP16 精度)。
- 模型权重占用多少显存?
- 如果不使用量化,KV Cache (序列长度 4096, Batch=1) 需要多少显存?
(提示: )
答案: - 模型权重:
- 参数量 。
- FP16 每个参数 2 Bytes。
- 显存 。
- KV Cache:
-
公式: (单位是参数个数)。
-
参数个数:。
-
显存占用 (FP16):。
-
总计:约 16 GB+。所以一张 24GB 的 3090/4090 可以跑。
面试官视角:
"如果 Batch Size 变成 32?KV Cache 就会变成 。这时候 KV Cache 成了显存大头,必须用 GQA 或量化。"
38. 量化技术 (Quantization)
问题: 简述 PTQ (Post-Training Quantization) 和 QAT (Quantization-Aware Training) 的区别。FP16 转 INT8 会损失什么?
答案:
- PTQ (训练后量化):模型训练完后,通过校准数据集 (Calibration Data) 统计激活值的分布,计算缩放因子 (Scale),直接将权重截断量化。方便快捷。
- QAT (感知量化训练):在训练过程中插入伪量化节点 (Fake Quantization),让模型在训练时就"适应"量化带来的误差。精度更高,但成本大。
- FP16 -> INT8:
- 动态范围 (Dynamic Range) 大幅缩小。
- 精度损失 :对于离群点 (Outliers) 非常敏感。大模型中常出现激活值极大的"特异特征",直接量化 INT8 会导致模型崩坏 (LLM.int8() 论文的核心发现)。
39. 采样策略:Top-k vs Top-p (Nucleus)
问题: 在生成文本时,Temperature, Top-k, Top-p 分别起什么作用?
答案:
-
Temperature ():调整 Softmax 的概率分布平滑度。
-
:分布变尖锐,更倾向于高概率词 (保守)。
-
:分布变平缓,低概率词被选中的机会增加 (创造性)。
-
Top-k:只从概率最高的 个词中采样。缺点是 是固定的,无法适应分布变化 (有时前 10 个都很合理,有时前 100 个都垃圾)。
-
Top-p (Nucleus Sampling) :截断概率累加和达到 (如 0.9) 的词表。这是动态的截断,效果通常优于 Top-k。
40. 幻觉 (Hallucination)
问题: 为什么 Transformer 架构的大模型会产生幻觉?从训练目标和数据角度解释。
答案:
- 训练目标 :Next Token Prediction 本质上是在拟合概率分布 ,而不是在验证事实真伪。模型只是选择了统计学上"最可能出现"的词,而不是"最正确"的词。
- 数据源:训练数据本身包含大量互联网噪声、虚构小说、错误信息。模型无法区分 Wikipedia 和 Reddit 帖子的可信度差异(除非做 RLHF 对齐)。
- 知识压缩损耗:模型试图将海量知识压缩到有限的参数中,类似于有损压缩 (JPEG)。在解压(推理)时,对于长尾知识,容易出现"张冠李戴"的模糊重构。