文章目录
-
- 一、简介
-
- [1、 AnalyticDB](#1、 AnalyticDB)
- 2、MaxCompute
- 3、DataWorks
- 二、同步方式
-
- 1、通过DataWorks导入
- 2、通过外表导入MaxCompute数据
-
- [2.1 数据准备](#2.1 数据准备)
- [2.2 操作步骤(数仓版)](#2.2 操作步骤(数仓版))
一、简介
1、 AnalyticDB
云原生数据仓库 AnalyticDB MySQL 版(以下简称AnalyticDB for MySQL)是全托管的PB级实时数仓,支持毫秒级数据更新和亚秒级查询响应,高度兼容MySQL协议。
AnalyticDB for MySQL基于湖仓一体架构,无论是数据湖中的非结构化或半结构化数据,还是数据仓库中的结构化数据,都能统一高效地处理,帮助企业构建全面的数据分析平台。它不仅支持大规模离线数据处理以满足深度洞察需求,同时也提供高性能在线分析能力,帮助企业快速响应业务变化,实现降本增效。
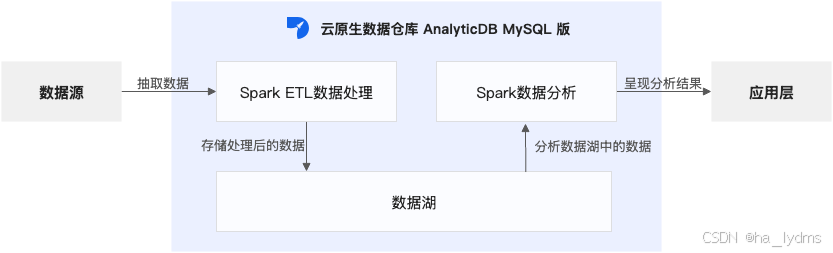
- 离线ETL处理
从数据源抽取数据,并经过清洗转换后,加载到AnalyticDB for MySQL。通过调度工具(DMS、DataWorks、Airflow、DolphinScheduler和Azkaban等)实现周期性ETL处理。

- Spark数据分析
AnalyticDB for MySQL集成了Spark计算引擎。您可以基于Spark SQL查询结构化数据,利用Spark JAR包开发复杂批处理任务,或通过PySpark执行机器学习及数据科学计算。
2、MaxCompute
云原生大数据计算服务(MaxCompute)是一种快速、完全托管的TB/PB级数据仓库解决方案。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
云原生大数据计算服务MaxCompute(原名ODPS)是阿里云自主研发的集高性价比 、多模计算 、企业级安全 和AI驱动 于一体的企业级SaaS化智能云数据仓库(AI-Native Datawarehouse)。
- 产品简介
MaxCompute是面向分析的企业级SaaS模式智能化云数据仓库,以Serverless架构提供全托管、开箱即用的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制。
计算存储的智能优化能力、开放的湖仓一体架构、近实时和交互式查询加速能力以及Data+AI一体化建设,使用户最小化运维投入、经济并高效地分析处理海量数据。
数以万计的企业正基于MaxCompute进行数据计算与分析,将数据高效转换为业务洞察。
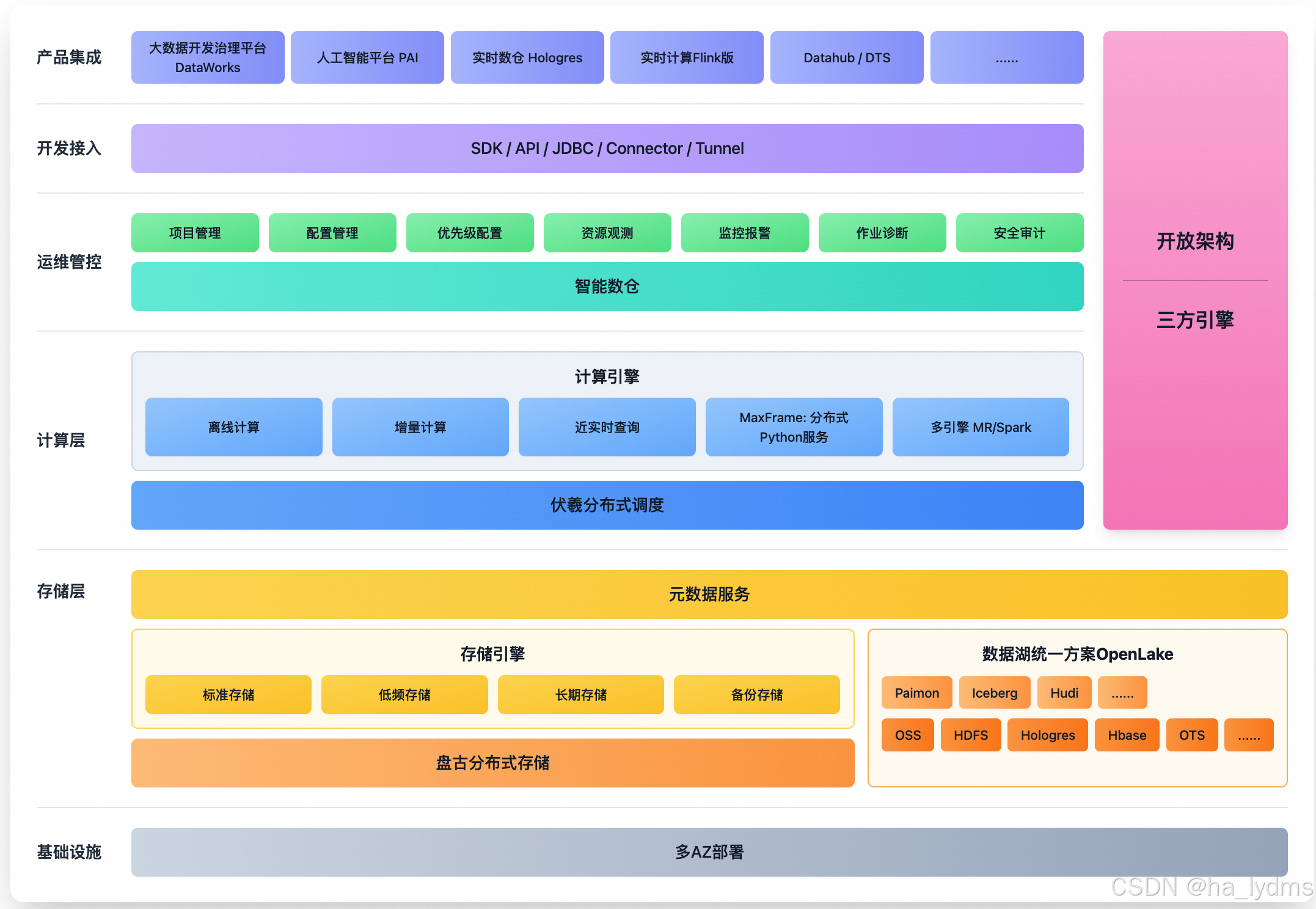
- 产品架构
MaxCompute的架构主要由存储层、计算层和统一的运维管控平台构成,共同构建在多可用区部署的稳固基础设施之上。
- 存储层通过其存储引擎,整合了由标准、低频、长期等存储类型构成的原生存储体系,并支持开放的湖仓一体(OpenLake)架构。
- 计算层通过多种引擎支持离线、近实时、Data+AI等多种计算任务。
- 运维管控层作为平台的管理与控制核心,提供从项目、配额到优先级的资源治理,从资源观测、监控报警到作业诊断的全方位监控,以及完整的安全审计能力。
- 整个平台通过标准的开发接入接口(如SDK/API/JDBC)与上层的DataWorks、PAI等产品集成。
3、DataWorks
DataWorks是一站式智能大数据开发治理平台,适配阿里云MaxCompute、E-MapReduce、Hologres、Flink、AnalyticDB、StarRocks、PAI 等数十种大数据和AI计算服务,为数据仓库、数据湖、湖仓一体、Data+AI解决方案提供全链路智能化的数据集成、大数据AI一体化开发、数据分析与主动式数据资产治理服务,帮助企业进行全生命周期数据管理。自2009年以来,DataWorks以阿里巴巴集团大数据建设方法论为基础,不断沉淀数据治理最佳实践,现已广泛应用于包括政务、金融、零售、互联网、汽车、制造等众多行业,数以万计的客户信赖并选择DataWorks进行数字化升级和价值创造。

二、同步方式
1、通过DataWorks导入
已完成数据源配置。您需要在数据集成同步任务配置前,配置好您需要同步的源端和目标端数据库,以便在同步任务配置过程中,可通过选择数据源名称来控制同步任务的读取和写入数据库。
- 操作步骤
- 新增MaxCompute数据源。具体操作,请参见配置MaxCompute数据源。
- 新增AnalyticDB for MySQL数据源。具体操作,请参见配置AnalyticDB for MySQL 3.0数据源
- 创建数据同步任务。具体操作,请参见数据集成侧同步任务配置
2、通过外表导入MaxCompute数据
云原生数据仓库 AnalyticDB MySQL 版支持通过外表读取并导入MaxCompute数据。通过外表导入数据可以最大限度地利用集群资源,实现高性能数据导入。
2.1 数据准备
本文示例中的MaxCompute项目为odps_project,示例表odps_nopart_import_test。示例如下:
sql
CREATE TABLE IF NOT EXISTS odps_nopart_import_test (
id int,
name string,
age int)
partitioned by (dt string);在odps_nopart_import_test表中添加分区,示例如下:
sql
ALTER TABLE odps_nopart_import_test
ADD
PARTITION (dt='202207');向分区中添加数据,示例如下:
sql
INSERT INTO odps_project.odps_nopart_import_test
PARTITION (dt='202207')
VALUES (1,'james',10),(2,'bond',20),(3,'jack',30),(4,'lucy',40);2.2 操作步骤(数仓版)
-
连接目标AnalyticDB for MySQL集群。详细操作步骤,请参见连接集群。
-
创建目标数据库。
sqlCREATE database test_adb; -
创建MaxCompute外表。本文以
odps_nopart_import_test_external_table为例。sqlCREATE TABLE IF NOT EXISTS odps_nopart_import_test_external_table ( id int, name string, age int, dt string ) ENGINE='ODPS' TABLE_PROPERTIES='{ "endpoint":"http://service.cn.maxcompute.aliyun-inc.com/api", "accessid":"yourAccessKeyID", "accesskey":"yourAccessKeySecret", "partition_column":"dt", "project_name":"odps_project1", "table_name":"odps_nopart_import_test" }';参数 说明 ENGINE='ODPS'外表的存储引擎。读写MaxCompute数据时,取值为ODPS。 endpointMaxCompute的EndPoint(域名节点) 。说明 目前仅支持AnalyticDB for MySQL通过MaxCompute的VPC网络Endpoint访问MaxCompute。查询各地域VPC网络的Endpoint,请参见VPC Endpoint。 accessid阿里云账号或者具备MaxCompute访问权限的RAM用户的AccessKey ID。如何获取AccessKey ID和AccessKey Secret,请参见账号与权限。 accesskey阿里云账号或者具备MaxCompute访问权限的RAM用户的AccessKey Secret。如何获取AccessKey ID和AccessKey Secret,请参见账号与权限。 partition_column本文使用的示例是创建分区表的示例,所以需要配置 partition_column。如果MaxCompute的表是非分区表,那么AnalyticDB for MySQL中也需要创建非分区表,此时无需配置partition_column。project_nameMaxCompute中的工作空间名称。 table_nameMaxCompute中的数据源表名。 -
在
test_adb数据库中创建表adb_nopart_import_test,用于存储从MaxCompute中导入的数据。sqlCREATE TABLE IF NOT EXISTS adb_nopart_import_test ( id int, name string, age int, dt string, PRIMARY KEY(id,dt) ) DISTRIBUTED BY HASH(id) PARTITION BY VALUE('dt') LIFECYCLE 30; -
导入数据。
-
方式一:执行
INSERT INTO导入数据,当主键重复时会自动忽略当前写入数据,不做更新,作用等同于INSERT IGNORE INTO,详情请参见INSERT INTO。示例如下:sql
INSERT INTO adb_nopart_import_test
SELECT * FROM odps_nopart_import_test_external_table;
通过SELECT查询写入表中的数据,示例如下: ```sql SELECT * FROM adb_nopart_import_test;返回结果如下:
sql+------+-------+------+---------+ | id | name | age | dt | +------+-------+------+---------+ | 1 | james | 10 | 202207 | | 2 | bond | 20 | 202207 | | 3 | jack | 30 | 202207 | | 4 | lucy | 40 | 202207 | +------+-------+------+---------+如果需要将特定分区的数据导入
adb_nopart_import_test,可以执行:sqlINSERT INTO adb_nopart_import_test SELECT * FROM odps_nopart_import_test_external_table WHERE dt = '202207';-
方式二:执行
INSERT OVERWRITE导入数据,会覆盖表中原有的数据。示例如下:sqlINSERT OVERWRITE adb_nopart_import_test SELECT * FROM odps_nopart_import_test_external_table; -
方式三:异步执行
INSERT OVERWRITE导入数据。通常使用SUBMIT JOB提交异步任务,由后台调度,可以在写入任务前增加Hint加速写入任务。详情请参见异步写入。示例如下:sqlSUBMIT JOB INSERT OVERWRITE adb_nopart_import_test SELECT * FROM odps_nopart_import_test_external_table;返回结果如下:
sql+---------------------------------------+ | job_id | +---------------------------------------+ | 2020112122202917203100908203303****** |关于异步提交任务详情请参见异步提交导入任务。
-